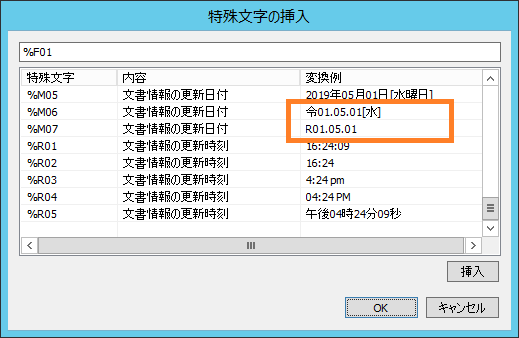
弊社システム製品の利用方法をわかり易く説明する方法として【マンガ】で作成してみました。
昨年に第一弾として
『マンガでわかる!! PDF作成、及びテキストボックス注釈編』
を作成、公開しており、現在は、
『マンガでわかる!! PDF編集編 PDF Tool API』
『マンガでわかる!! XMLからHTMLとPDF/Aを出力編 AH Formatter』
『マンガでわかる!!PDF自動出力編 PDF Driver』
『マンガでわかる!!OSDCでオフィス文書の変換にOfficeは必要無し編 Office Server Document Converter』
『マンガでわかる!!PDFXMLでPDFを再利用編 AHPDFXML』
の6話を公開しております。
PDFにかかわる身近な問題へのソリューションとして、是非ご参照いただきご活用ください。

また、上記システム製品のご活用に関して、その周辺開発を弊社で積極的に行うようになりました。
詳しくは、『受託開発(PDF)』をご覧ください。

〒103-0004
東京都中央区東日本橋2-1-6 東日本橋藤和ビル5F
アンテナハウス株式会社
◆ご購入に関するお問い合わせ(祝日を除く月~金曜日9:30~18:00)
TEL : 03-5829-9021
FAX : 03-5829-9023
E-mail: sis@antenna.co.jp
URL : https://www.antenna.co.jp/