いま、いちばんホットな領域といえばもちろんAIです。当社でもAIをどのように活用できるかを検討しており、そのひとつとして、「当社の製品を利用するソリューションの作成にAIを活用する」という課題があります。
当社の製品の中で、特にシステム製品は、ユーザー企業が作成するソリューションに組み込んで使っていただくことを想定しています。ソリューションはプログラミング技術を熟知した専門家が開発します。この開発の日数や費用がかかるためどうしても市場が限られます。
専門家の代わりにあるいは専門家の生産性を高めるためにAIを活用する、例えばAIにプログラムを書かせてソリューションを実現できれば迅速・低コストを実現できます。このため、いろいろなソリューションを想定して試しています。ここで得られたノウハウを紹介することで、当社の開発ツールをより多くの方に利用していただけるようになるでしょう。
前置きが長くなりましたが、最初にシンプルなバッチファイルをAIに作成させた例を紹介します。
ここでの課題は「アウトライナー」の評価版をダウンロードされたお客様からの次の問合せです。
Q. フォルダ単位でしおりを抽出(csvなど)する機能はありますでしょうか。
アウトライナーはデスクトップ製品です。対話型グラフィック・ユーザー・インターフェイス(GUI)を使ってメニューから操作します。残念ながら現在のGUIにはフォルダ単位で、フォルダ内の複数のPDFからしおりを抽出するメニューはありません。
しかし、アウトライナーの機能の一部は、コマンドラインから使用できます。コマンドライン機能を使うと、PDFからしおりを抽出して外部ファイル(CSV、XML、JSON)に出力できます。詳細は、アウトライナーのオンライン・マニュアル「3–17 コマンドライン」を参照してください。
コマンドラインはWindowsのDOS窓からプログラムの名前を指定してプログラムを動かす仕組みです。メニューの代わりにプログラムの引数(パラメータ)で処理を指定します。
DOS窓で、次のように入力すると、入力したPDF(OutlinerManualJ.pdf)に設定されているしおりの情報がBookmark.csvに保存されます。

このままでは、ひとつのPDFファイルしか処理できません。そこで、これを連続的に動かして、フォルダにある多数のPDFファイルを順番に読み込んで、しおり情報を取得し、CSVファイルとして出力するプログラムを作ります。フォルダ内のPDFファイルを探して、みつかったらそれを読んでCSVを出力する操作を繰り返します。このような処理をバッチ処理といいます。
ここではGeminiを使って作ってみました。Geminiに次のような指示(プロンプト)を与えます。
「アウトライナー」のコマンドラインで、特定のフォルダ内にあるPDFに対して、既存のしおりをCSVに吐き出すバッチファイルを作りたいです。 アウトライナーの実行フォルダは、「C:\Program Files\Antenna House\OutlinerV3.3」で、特定のフォルダは、「D:\temp」とします。 アウトライナーのコマンドラインについては、下記のURLを参照してください。 なお、コードが作れればOKです。
https://www.antenna.co.jp/mpd/download/onlinemanual/i01-0025.html
Geminiが作成したバッチプログラムは次のとおりです。
@echo off
setlocal enabledelayedexpansion
rem -- 設定項目 --
set "OUTLINER_DIR=C:\Program Files\Antenna House\OutlinerV3.3"
set "TARGET_DIR=D:\temp"
echo --------------------------------------------------
echo アウトライナー しおりCSVエクスポート処理 開始
echo --------------------------------------------------
rem アウトライナーの起動フォルダへ移動
cd /d "%OUTLINER_DIR%"
rem 指定フォルダ内のPDFファイルを1つずつループ処理
for %%F in ("%TARGET_DIR%\*.pdf") do (
set "INPUT_PDF=%%~fF"
set "OUTPUT_CSV=%%~dpnF.csv"
echo 処理中: "%%~nxF"
rem アウトライナーのコマンドライン実行
rem /I @CSV : 既存のしおりをCSV形式で出力
rem /D : 入力PDFの指定
rem /O : 出力CSVの指定
OutlinerCmd.exe /I @CSV /D "!INPUT_PDF!" /O "!OUTPUT_CSV!"
if !errorlevel! equ 0 (
echo --- 成功: "!OUTPUT_CSV!" を出力しました。
) else (
echo [エラー] "%%~nxF" のしおり抽出に失敗したか、しおりが存在しない可能性があります。
)
echo --------------------------------------------------
)
echo すべての処理が完了しました。
pause
コードの解説とポイント
パスの設定:
ご指定の通り、アウトライナーの実行フォルダ(%OUTLINER_DIR%)と、PDFが格納されている対象フォルダ(%TARGET_DIR%)を変数として定義しています。環境に合わせてここを変更するだけで再利用可能です。
コマンドの構成:
マニュアルの仕様に準拠し、既存のしおりをCSVでエクスポートする引数 /I @CSV を使用しています。
/D: 入力PDFパス(例: D:\temp\sample.pdf)
/O: 出力CSVパス(例: D:\temp\sample.csv)
出力ファイル名:
%%~dpnF.csv という記述により、元のPDFと同じフォルダに、「元のPDFファイル名.csv」という名前でしおりデータが保存されます。
注意点:
アウトライナーの仕様上、「対象のPDFに最初からしおりが1つも含まれていない場合」はコマンドがエラー(またはファイルが出力されない状態)になります。そのため、バッチファイル側で成否を判定し、失敗した場合は画面上にエラーの旨を表示するようにしてあります。
ーーーここまでがGeminiの回答ーーー
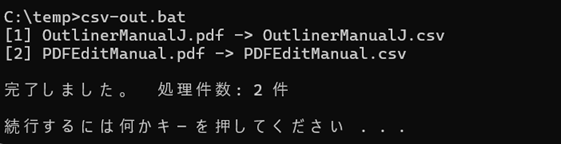
Geminiが出力したコードを、テキストエディタにコピー&ペーストして、CSV-OUT.BATという名前で保存します。TEMPフォルダの中に二つのPDFファイルを保存して実行すると、次のように、連続してCSVファイルができます。
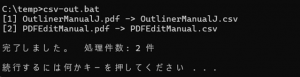
このような簡単なプログラムでも、従来なら専門家が時間をかけて作成したものですが、Geminiに作らせれば瞬時にできます。しかし、実際にプログラムを動かしてみると、バッチプログラムをコマンドラインで動かすというだけでも、若干の基礎知識が必要なことがわかります。ITリテラシーがある程度ないと使いこなせないかもしれない、という懸念も生まれました。