こんにちは。DITAの話は今日でいったんおしまいにします。
昨日までの4日間で漏れてしまった話題について、軽く紹介しておきます。
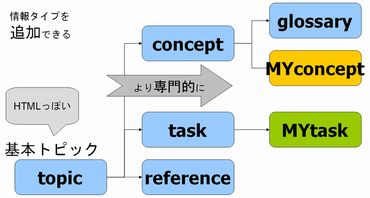
■conref
昨日、条件処理を使ってコンテンツの一部を出したり出さなかったりをする方法を紹介しましたが、conrefは他のトピックの中のほんの一部を流用する機能です(フラグメント単位での再利用)。
製品名とかコピーライト表記をひとつのトピックファイルにまとめておいて、それを参照したりするような使い方をします。
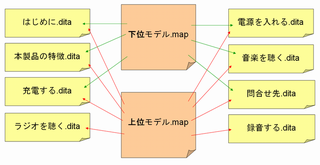
■関連テーブル
どのトピックとどのトピックが関連し合っているのかを、それぞれのトピックの中ではなくマップの中に記述することができます。
トピックの中に関連情報を書くこともできますが、そうするとトピック間の関連関係が変更されたとき、トピックをこつこつと変更しなくてはなりません。それはそれで大変なので、マップに追いやってしまおうというわけですね。こうすることでマップだけを修正すればいいことになります。
■keyref
これは参照先をマップで解決しようという機能です。言葉で説明するのは難しいのですが、図式化すると次のようになります。
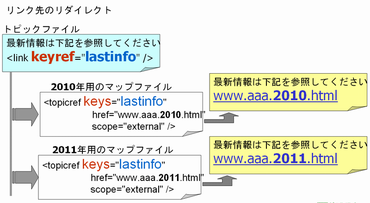
トピックの中には具体的な参照先は書かないで、マップに書いてしまおうということですね。
この機能は最新のDITA1.2仕様で追加された機能です。一度書いたトピックはできるだけ変更しなくてもいいようにしよう、可変データは可能な限りマップに追いやってしまおう、というDITAの設計思想が感じられます。
■DITA Open Tookit
せっかくマップやトピックが用意できたのに、これをどうやってHTMLやPDFにすればいいんだろう、という疑問がありますよね。大丈夫です。マップやトピックを処理して最終成果物を作ってくれる「DITA Open Tookit」という処理系がすでにあります。オープンソースで誰でも無償で使うことができます。入手先は下記です。
http://sourceforge.net/projects/dita-ot/
Open Toolkitは
* トピックファイルや画像などの素材を集める
* 条件処理を解決する
* conrefやkeyrefを解決する
* PDFやHTMLを作る
といったことを自動的にやってくれます。
■期待するレイアウトを実現するには
Open Toolkitを使えばPDFを作ることはできるのですが、あくまでもサンプル程度です。
これを期待したレイアウトにするにはそれなりのカスタマイズが必要になります。具体的にはPDF生成用のXSLTスタイルシートを作らないといけないのですが、弊社ではこのスタイルシート作成を請け負っていますので、ぜひご相談ください。
また、Open Toolkitには標準で自動組版エンジンが付いてくるのですが、正直な話、機能的にいまいちです。特にまじめに日本語組版をしたいということであれば、Antenna House Formatterが必須になります。
■お問い合わせ
DITA導入についてのお問い合わせをお待ちしております。
営業担当:小林(guten@antenna.co.jp)までよろしくお願いいたします。
では、5日間ありがとうございました。
最後に関連情報のリンクを少しだけ
OASIS DITA仕様(英語サイト)
DITA News(英語サイト)
DITAコンソーシアムジャパン(日本語サイト)
アンテナハウスDITAサービス(日本語サイト)
DITA超入門 ― まとめ


瞬簡PDF 統合版 2024
アンテナハウスPDFソフトの統合製品!

アウトライナー
PDFを解析して しおり・目次を自動生成