本日は、紙の情報をコンピューターに取り込む手段としてのOCR技術について説明いたします。
OCRとは、Optical Character Recognition(あるいはReader)という英語の略で、日本語では光学的文字認識(あるいは光学的文字読み取り装置)と訳されます。
紙に印刷された文字をイメージスキャナやデジタルカメラなどで読み取り、画像化された情報から文字情報を識別し、コンピュータで処理可能な情報(文字コード)を抽出する技術またはその装置を指します。
こう書くとなんだかややこしいですが、要は人間が新聞や雑誌など紙に書かれた文字を読んで内容を理解するのと同じようなことをコンピュータにもやらせようとするための技術のひとつと言えます。
実はOCR技術は身近なところで使われています。割と古くからあってOCRの老舗といえるのは「郵便番号読み取り装置」でしょう。日本では1968年の郵便番号導入とともに使われたといいますから、既に40年以上の実績があるわけです。
また、試験の際にお目にかかるマークシート方式の回答用紙も採点のためにOCR技術が応用されている身近な例といえます。
これらは大量の情報を一括で高速に処理する必要があるのでOCR装置も専用の高精度、高価格なものが使用されますが、私たちがパソコンを使って汎用に使用する場合には、市販のスキャナとOCRソフトとの組み合わせで取り込むのが一般的です。
さて、実際に紙の原稿からパソコンにデータを取り込み、文字を認識する場合には、概略次のことが行われます。
- 画像で取り込み:スキャナでスキャンした紙の原稿は画像データとしてパソコンに取り込まれます。画像データの種類はお使いのスキャナの仕様によって異なりますが、最近はPDF形式が使用されることが多いようです。PDFであっても内部には画像データのみ格納されています。
- 領域の識別:取り込んだ画像には、当然のことながら紙の原稿のレイアウトが移されています。それは文字であったり、図形であったり、画像であったりします。人間が紙に書かれたこれらの範囲を区別するのと同じようにOCRも識別をします。これを領域(レイアウト)認識または領域解析と呼びます。
- 文字の認識:上記で文字領域と識別された部分について文字データの読み込み(抽出)を行います。
ただし、人間が文字を読み取るのと比較して、コンピュータが文字を読むことは簡単なことではありません。人間の脳は、乱暴に書かれた手書き文字やかすれた文字などを読む場合、曖昧な部分を的確に補って正しく認識する能力を備えていますが、コンピュータはこうした認識が大の苦手です。
例えば、以下は、元の文字画像が鮮明でないために、文字の誤認識が出てしまう例です。
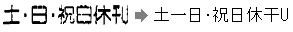
このため、さまざまな方法が考案されて文字の認識率を高める努力がされていますが、文字の認識率が100%(つまり完全)ということにはなかなかなりません。文字のかすれやつぶれがないなどコンディションの良い活字を認識した場合、一般に98%くらいの認識率であれば正確といえるようです。
- 認識結果の保存:OCR処理された結果はそのままでは利用することができません。認識された文字や画像などの情報をパソコン・ユーザーが扱える形式、たとえばWordやExcelなどのOffice文書やテキストファイル、透明テキスト付きPDFなどに保存することで、文字の検索に利用したり、編集して別の文書に再生したりといったことが可能になります。
以上、簡単にアウトラインだけをご説明しました。実際にはOCR技術はもっと複雑で、具体的な文字識別の方法などは興味のつきないところですが、これ以上は専門的な話題となってしまいますのでここでは割愛させていただきます。