Microsoft Excelのワークシートから印刷/PDFを作成するときのページ作成機能について、ほとんどのExcelユーザーは、日ごろ、あまり細かいことは気にしないで利用していることでしょう。このページ作成・分割機能は細かくみると非常に高度かつ複雑です。
ここでは、より詳しく知りたいという方のために、Excelの「印刷」モードのページ作成機能について、できるだけ網羅的に紹介してみましょう。
なお、本記事で使用する用語などは主に、Microsoft Excelスタイル探索(3)Excelのワークシートを可視化(レンダリング)する多様なモードを使いこなすの説明をご参照ください。
ワークシートの画面表示
Excelのワークシートでは行と列から構成される表形式でデータを編集します。ワークシートで使用可能な最大行数・列数は決まっています。実際には制限いっぱいの巨大な表を作成することはまずないでしょう。データ編集するときは、ワークシートの一部を使用し、それ以外は空となります。ワークシートで、1列目から実際に使われている列の最大値、1行目から実際に使われている行の最大値までの矩形領域を、ここでは「有効範囲」といいます。
ワークシートに入力した文字にはフォントの大きさを自由に設定でき、セルには行の高さ、列の幅などを自由に設定できます。
文字の大きさはポイント単位で設定します。行の高さや列の幅は、概ね文字の大きさを基準にして自動的に設定されますが、リボン「ホーム」の「書式」メニューで設定もできます。1ポイントは72分の1インチで約0.353㎜です。11ポイントなら約3.88mmとなります。こうして、行の高さや列の幅をポイント数に換算し、ワークシートの有効範囲の幅と高さをポイント単位またはmm単位で計算できます。
こうして計算した寸法を、とりあえず、「原寸」といいます。
ワークシートをPDF化するときの設定
リボン「ページレイアウト」の「拡大/縮小」メニューで、ワークシートからPDFを作成するとき原寸のままPDF化するか拡大・縮小するかを指定できます。既定値は原寸(Excelのメニューでは「100%」)です。

PDFを画面で閲覧するときは、実寸法を意識することはないでしょう。しかし、PDFは紙の電子版であり、紙と同様に縦方向と横方向の用紙寸法が設定されています。例えば、A4サイズ用紙を縦長方向で使用する場合、縦は297㎜、横は210㎜という値が設定されています。
通常、用紙の上下・左右に余白を確保するため、ワークシートの有効範囲を配置できる紙面の範囲は、用紙の縦寸法から上下余白を除外、用紙の横寸法から左右余白を除外した領域となります。この領域のことを「基本版面」といいます。
ワークシートを印刷する時、印刷範囲は既定値(印刷範囲を設定していない状態)では有効範囲です。なお、リボン「ページレイアウト」の「印刷範囲」メニューで有効範囲とは異なる設定もできます。
「印刷」モードで印刷処理を実行して、ワークシート上の印刷範囲のデータを基本版面に配置する都度、1ページが作成されることになります。
印刷範囲が原寸で一つの「基本版面」に収まるときは、そのまま1ページのPDFを作成すれば良いのですが、原寸で1ページに入りきらないときは、次の選択肢があります。
1.原寸のまま複数のページに分割して印刷する
2.拡大・縮小して印刷する
「拡大・縮小して印刷する」の拡大・縮小設定はさまざまで複雑です。そこで、次回に扱うこととします。以下では、原寸のまま複数のページに分割する仕組みについて整理してみます。
ワークシートをページ分割したときの区切り位置とページの出力順序
ワークシートに強制的な改ページ位置を入力していないときは、次のように、ワークシートの印刷範囲がページに分割されます。
列の進行方向では、列の区切り位置が分割点(候補)となります。つまり、列自体が二つに分割されることはありません[1]。そして列幅を左から合計していき基本版面の幅に入る限りは1ページになります。基本版面幅に入りきらない列は次のページに送られます。行の進行方向では、分割位置は行の区切り位置です。そして、行の高さを上から合計していき、基本版面の高さに入るまで1ページになります。基本版面の高さに入らない行は次のページに送られます。
このとき、ページを進める方向は次の図のように二つあります。

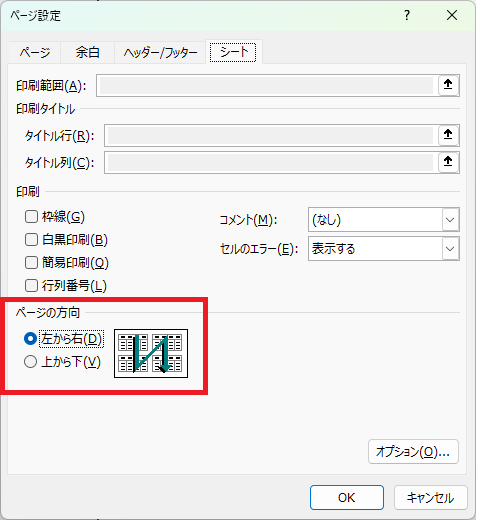
図左) 最初に、行方向にページを進め、次に列方向にページを進める(Excelのダイアログでは「左から右」)
図右) 最初に、列方向にページを進め、次に行方向にページを進める(Excelのダイアログでは「上から下」
既定値では図左のように、先に行方向にページを進める設定になっています。ページを進める方向は、Excelのメニューでは、「印刷」の「ページ設定」ダイアログの「シート」タブで設定を変更できます。または、リボン「ページレイアウト」のシートのオプショングループの右下の矢印をクリックして「シート」タブを表示できます。
ワークシートで、特定のセル以降の行または列から新しいページを始めたいときは、そのセルに「改ページ」を入力します。次の図は、セル:E5に「改ページの挿入」を行っている例です。
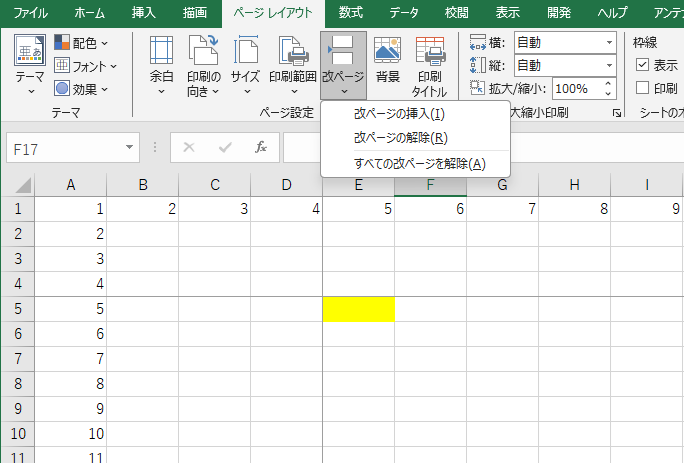
「標準」モードの改ページプレビューで確認すると、セル:E5の行位置と列位置で新しいページが始まっていることを確認できます。

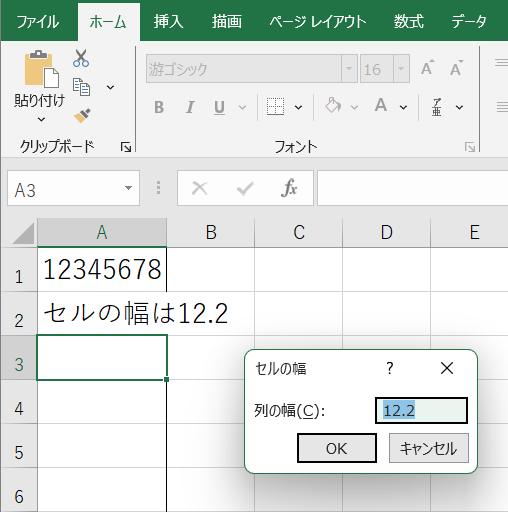
[1] 例えば、「標準」モード「書式」の「セルの幅」ダイアログで、列の幅の値として、1ページに入りきらないような大きな幅を設定できます。しかし、「印刷」モードではそのような列も複数ページには跨らないようです。
前回:Microsoft Excelスタイル探索(5)Excelのテーマと標準フォントの関係
参考資料:
Microsoft Excelの標準フォントの基本 標準フォントとはなにか? どのような役割があるのか?