PDFが登場してからほぼ4半世紀経過しました。PDFはもともと紙に印刷していたレイアウトのデジタル版として電子的に共有・閲覧するために開発されたものです。しかし、4半世紀経過し、PDFが日常的に使われるようになるとともに、PDFとして作成されたデータを再利用したいというニーズがどんどん増えています。
本日はPDFのデータ再利用の形態別に、弊社でご提供しておりますツール類をご紹介致します。
テキストを再利用
PDFの再利用の基本は、文字をテキストファイルとして取り出したいという用途でしょう。シンプルなレイアウトのものとしては契約書などの文字だけの文書があります。複雑なレイアウトのものとしては新聞の紙面、雑誌の誌面として作成されたPDFから文字を取り出したいというニーズがあります。
PDFの閲覧ソフトは画面に表示された文字を選択してコピーする機能がありますので、これを使うと簡単にできそうです。しかし、実際にやってみますとなかなか思い通りにはなりません。
これについては、なぜ思い通りにはならないかを整理してPDF資料室に用意しております。
簡単そうで簡単ではないPDFのテキスト抽出
HTMLにして再利用
また、ときどきお問い合わせをいただくのはPDFの内容をWebページ(HTML)にしたい、というニーズです。この場合の難易度はWebページの仕組みをどうするかに掛かってきます。この仕組みを大きく分類しますと、Webページの内容をHTMLで直接マークアップするか、それとも、コンテンツ管理システム(CMS)にデータを登録して、WebページをCMSで生成するかになりそうです。CMSを使う場合は、PDFからテキストと画像を取り出すことになります。PDFの内容をHTMLにして利用したいというときはPDFの内容をどのように構造化するか、という課題が付け加えられます。なお、HTMLはWebページだけではなく、社内でのデータ蓄積・分析のために使われることも多いようです。
PDFをHTML変換するツールは世の中に幾つかあります。しかし、HTMLファイルとしてからの利用形態や利用目的が多様なため、市販のツールは帯に短し襷に長しという状態になってしまうことがあるようです。
アンテナハウスでは、残念ながら、現在PDFからHTML変換ツールは用意しておりません。但し、PDFをXML形式に変換するツールとしてAHPDFXMLを提供しています。
AHPDFXML:PDFの内部のテキスト、表、図をXML形式に変換!
AHPDFXMLの特長はPDFの表を認識して、表としてマークアップして出力できることです。こうした特長を評価して採用していただいているケースがあります。
PDFの画像を取り出して再利用
PDFに入っている画像を再利用するのは簡単です。
例えば、『瞬簡PDF変換』では、PDFの中にある画像をファイルとして取り出せます(次の図)。
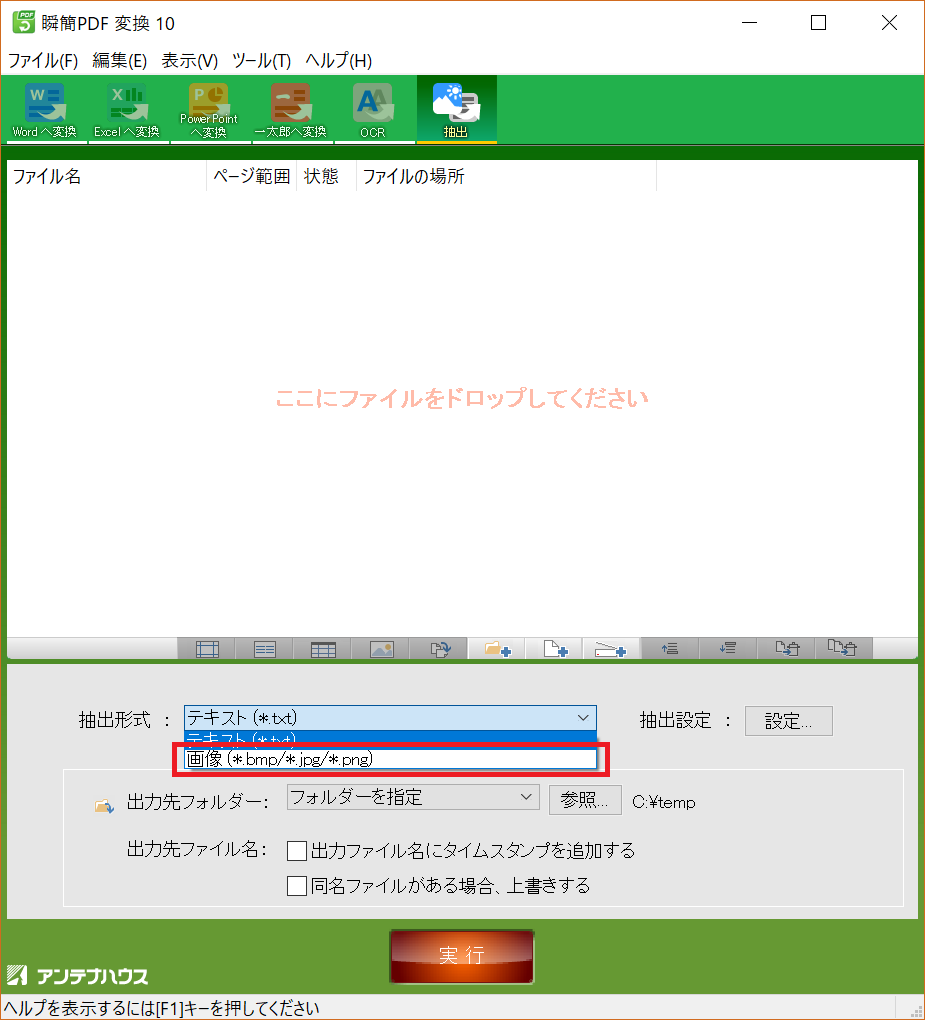
『瞬簡PDF変換』
PDFから画像を取り出す機能をシステムに組み込んで利用するのはPDF Tool APIをお使いいただけます。
PDF Tool API
PDF CookBook V3:2.1 画像抽出
PDFの一部を線画で切り出して再利用
PDFの一部を線画(SVG)の形式で切り出して再利用もできます。
PDF Viewer SDKには、画面で選択した範囲を線画として切り出す機能があります。
PDF Viewer SDK
PDF Viewer SDKの線画切り出し機能と同じですが、PDF加工画像化ツールもあります。こちらはもう少し高機能で数式などを選択してSVG画像化もできます。
PDFからSVGを切り取りできる PDF加工画像化ツール
お問い合わせは
こうしたツール類の他に、お客様のご要望に応じてカスタム開発なども承っております。なにかお困りのことがございましたら、ぜひご相談ください。
お問い合わせ










