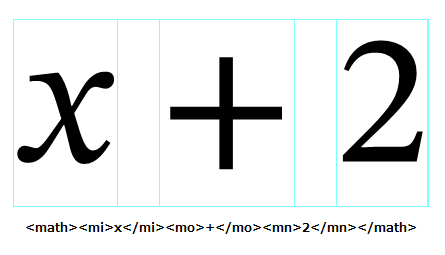XML自動組版は「猫の手」となりうるか?
路面のあちこちに水たまりができているのは、今しがたの通り雨のせいでしょう。
いよいよ、関東も梅雨明け間近といったところですが、皆様いかがお過ごしでしょうか。
夏といえば祭り!夏といえば夏フェス!
ということで、来る 8月22~23日に公益社団法人日本印刷技術協会(JAGAT)主催の「JAGAT Summer Fes 2019 (夏フェス 2019)」が開催されます。
冬に大規模に開催される「page」に対して、夏の暑い盛りにこじんまりと(失礼)セミナー中心で開催される「Summer Fes」に、アンテナハウスも出展いたします。
夏フェスは今年で3回目を迎えますが、意外や意外、弊社の出展はこれが初めて。
諸々の大人の事情も有り無しというところですが、今回は「for Business ゾーン」に展示ブースを出すとともに、併設の「ミニセミナー」では「人手不足時代と自動組版 ~最近のXML動向と事例紹介を交えて~」と題して暑苦しく語らせていただきます。
組版工程の省力化と効率化は、ひと昔もふた昔も前から叫ばれている課題です。
従来はコスト削減のための人減らしを目的としたものが主でしたが、今や減らすべき人さえいない「人手不足の時代」に突入しています。
作業プロセスのRPA導入やAI化の提案もありますが、属人性の高い組版行程でそれはどうなのという声も聴きます。
というわけで、いま一度自動組版を見直してみてはいかがでしょうか。
何やら面倒くさいプログラムが必要で敷居が高いと思われるかもしれませんが、自動組版の目指すところは、人(のスキル)を選ばない作業の平準化と、コンテンツの再利用を可能にするデータベース化です。そう、人と地球にやさしい!
データベースからの組版と電子媒体への展開というワンソースマルチユース(懐かし感満載)も、紙への印刷よりもwebへの展開が主流となる中でどのような対応がされているのか。
今時、あたり前過ぎてちょっと忘れられかけている「コンテンツのXML化」の近況なども交えて、その事例をご紹介させていただきます。
★ JAGAT Summer Fes 2019 for Businessゾーン ミニセミナー
【FB-13】人手不足時代と自動組版 ~ 最近のXML動向と事例紹介を交えて~
- 開催日:2019年8月23日 12:30~13:00
- 場所 :公益社団法人日本印刷技術協会(JAGAT)4F「for Businessゾーン」
杉並区和田1-29-11 - お申込み用セミナー番号:FB-13
- お申込みURL:https://summerfes.jagat.or.jp/cms/contact/entry2019
ご参加には、事前に参加お申込が必要です。
ご希望の方は、お手数ですが、上記 URL よりお申し込みくださいますよう、お願いいたします。
- 展示ブース:4F for Businessゾーン
- 展示製品 :AH Formatter(19年目を迎えた自動組版エンジンの定番)
https://www.antenna.co.jp/AHF/
バリアブルPDF印刷(PDFにデータの差し込みの一括処理サービス)
https://www.antenna.co.jp/merge_svr/
XML自動組版は人手不足時代に「愛の手」を差し伸べられるのか?
はたまた、「猫の手」を差し伸べるのか?
ご来場をお待ち申し上げます。