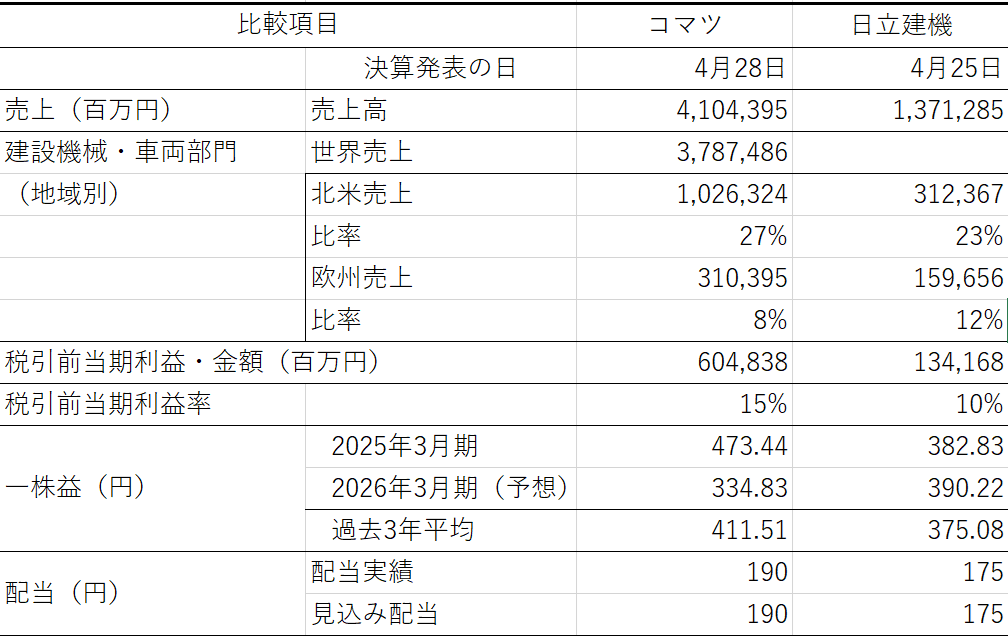
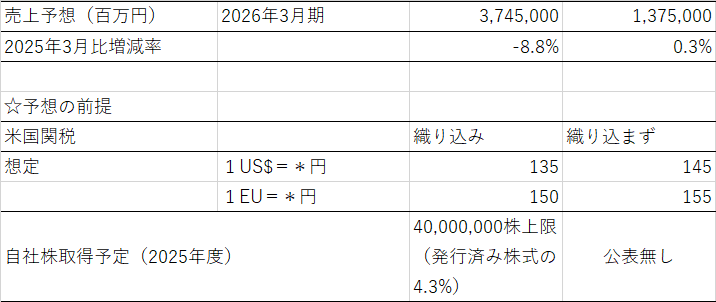
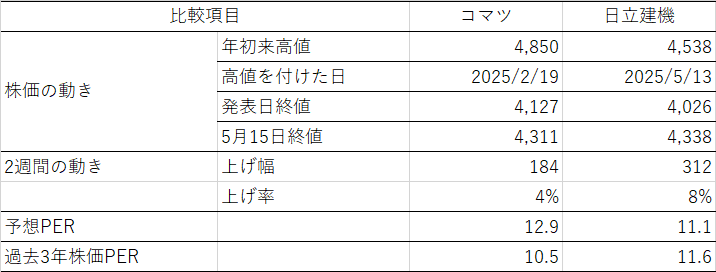
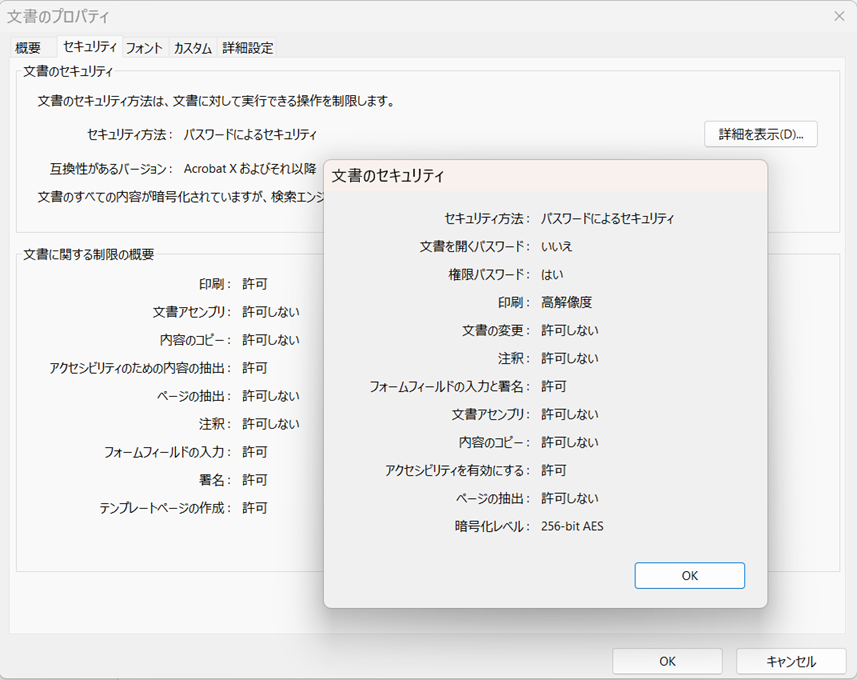
今週は日米の中央銀行の金融政策決定会合が開催され、大方の予想どおり、政策金利の据え置きが決まった。会合後の会見では、日銀の植田総裁、およびFRBのパウエル議長は、ともにトランプ政権の政策の影響で各国の経済・景気の見通しが極めて不確実になっているという見解を示している。
トランプ関税の概要とその影響
第2次トランプ政権の政策の中で、世界経済にもっとも大きな悪影響を与える可能性があるのは関税であることは間違いない。経済ニュースを大雑把にまとめると、(1) 2月4日から中国からの輸入に10%の追加関税、(2) 3月4日からカナダ、メキシコからの輸入に25%一律関税を賦課(3月6日に『アメリカ・メキシコ・カナダ協定』(USMCA)に含まれる品目は4月2日まで猶予と修正[1])、中国にさらに10%の関税上乗せ、(3) 3月12日から鉄鋼・アルミニウムに25%の関税を賦課、(4) 4月2日から自動車に25%の関税を賦課するといったスケジュールになっている。この他、4月2日に相互関税の発表が予定されている。
米国の輸入関税は製品価格の上昇による需要の減少などを通じて米国のGDPを下振れさせる。また、コスト増と需要減、サプライチェーンの混乱などによる企業収益の減少となる。一方、輸出国側も輸出数量減によるGDP低下となる。その上に、相手国側が報復関税を掛ければ悪影響のスパイラル効果が生まれる。こうして世界全体の2025年経済見通しは厳しく変更されつつある[2]。
いまのところ各種統計データには明確な影響が表れていないようだ。これは最大の懸念である自動車関税はアナウンスされただけで完全には実行されておらず、その他の関税も実行されてからの期間がまだ短いためである。統計データで確認するなら、早くて4月の月次統計、あるいは4月以降に発表される上場企業の会計報告を待たなければならない。
景気変動と株式投資
短期的な株式投資リターンを最大に上げようとするなら、こうした報告を待っていたのでは遅すぎる。バイアンドホールド(一度買ったら売らないで長く保有)という長期投資を目指すなら、そんなに急がず、株価に現れる結果をみて、十分安くなったことを確認してから動いても大丈夫だろう。但し、その長期投資家が下落時に買うつもりなら、いまのうちにある程度持ち株を売却して資金を用意し、腹を空かせておく必要がある。満腹では新たに買い難いからだ。
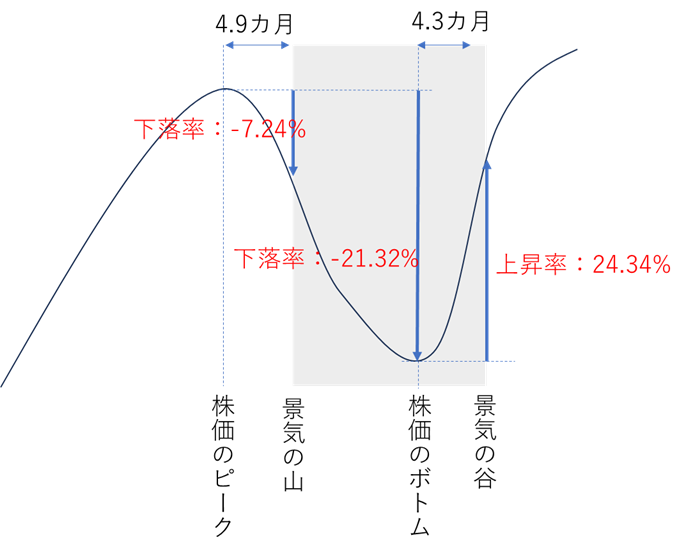
『株式投資 第6版』の第19章 株式と景気循環によると「ほぼ例外なく、株価は景気後退の前に下落し、景気回復の前に上昇する」。そして米国で第二次大戦後に12回あった景気後退期では、景気後退が始まる直前から13か月前(平均4.9カ月前)に株価インデックスがピークとなっているという説明と図表が掲載されている(pp. 292~293)。
12回の景気後退期において株式インデックスのピークからの最大下落率は平均21.32%、そのうち株式インデックスのピークから景気のピークまで(先行期間)に平均7.24%下げているということだ[4]。
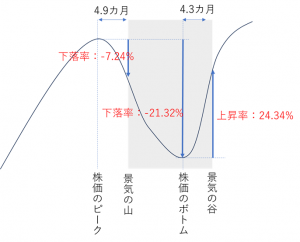
株価が大きく下落しても必ずしも景気後退にはならない。しかし、景気後退の前には必ず株価が下落する。つまり株式インデックスの下落は、景気後退の必要条件だが、必要十分条件ではない。
昨今の株価インデックスの状況をみると、トランプ大統領の意図が明らかになるにつれて主に米国株は大きく下げている。これをみると株価インデックスの動きからは景気後退の必要条件が満たされていると言える。
日米主要株価インデックスの動き
以下では、日経平均225、TOPIX、ダウ平均、S&P500、NASDAQの5種類のインデックスについて、2024年5月20日から2025年3月19日までの10カ月(200営業日強)の日次終値データを使って、もう少し詳しく分析してみたい。
最初に各インデックスの平均と標準偏差を計算すると次の表のとおりである。
|
日経平均(225) |
TOPIX |
ダウ平均 |
S&P500 |
NASDAQ |
| データ数 |
|
205 |
205 |
208 |
208 |
208 |
| 平均 |
|
38,589.29 |
2,717.78 |
41,897.68 |
5,728.52 |
18,369.27 |
| 標準偏差 |
|
1,300.12 |
85.45 |
1,927.92 |
253.97 |
1,011.97 |
これを使って、各インデックスの日々の終値を偏差値に換算(ノーマライズ)してグラフにしたのが次の図である。
日本株は昨年8月の暴落から戻ったあと、ほぼ横ばいとなっている。日経平均はピークから10%ほど下げた状態である。3月は日経平均とTOPIXの動きが乖離しているのが目を引く。
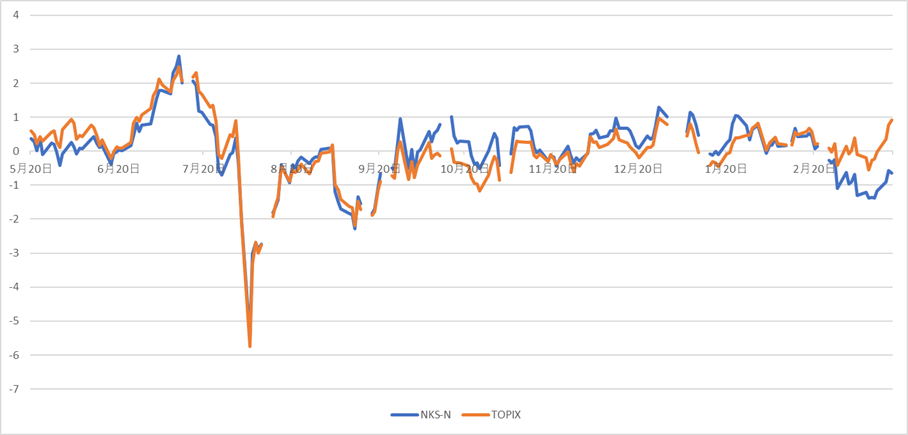
図 日本株の期中推移(ノーマライズ値)
米国株は2022年から右肩あがりの傾向だったが、ここにきてかなり大きく下げている。
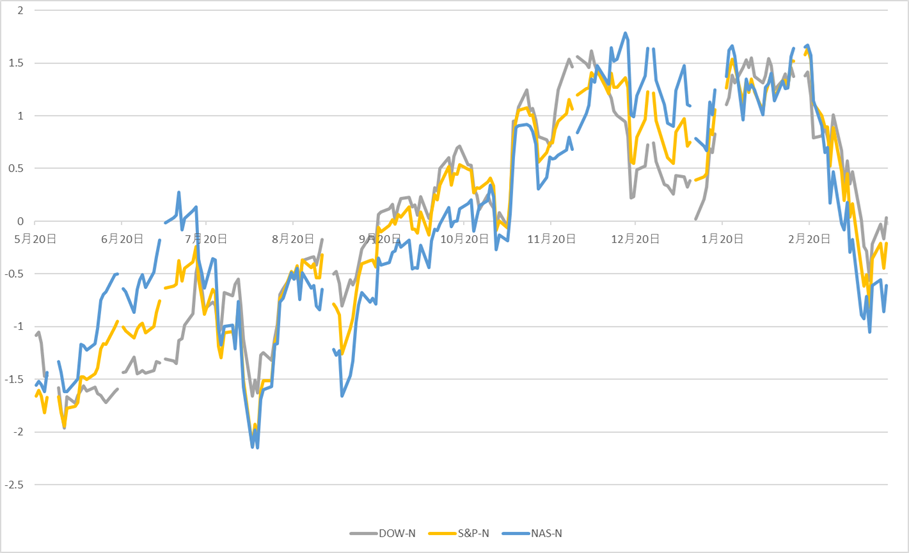
図 米国株の期中推移(ノーマライズ値)
この10カ月間の最小(ボトム)と最大(ピーク)、インデックスがピークを付けた日とピークから3月19日までの日数、および下落率をみると次の表のとおりである。
|
日経平均(225) |
TOPIX |
ダウ平均 |
S&P500 |
NASDAQ |
| 最小(ボトム) |
|
31,458.42 |
2,227.15 |
38,111.48 |
5,186.33 |
16,195.81 |
| 最大(ピーク) |
|
42,224.02 |
2,929.17 |
45,014.04 |
6,144.15 |
20,173.89 |
| ピークを付けた日 |
|
2024年
7月11日 |
2024年
7月11日 |
2024年
12月4日 |
2025年
2月19日 |
2024年
12月16日 |
| ピークを付けた日から3月19日までの経過日数 |
|
251 |
251 |
105 |
28 |
95 |
| ピークからの下げ |
|
-4,472.14 |
-133.21 |
-3,049.41 |
-468.86 |
-2,423.10 |
| ピークからの下落率 |
|
-10.6% |
-4.5% |
-6.8% |
-7.6% |
-12.0% |
まとめ
いまのところ、暴落という状態ではないが、いまが景気の転換点だとするとさらに10%以上は下がることになる。
『株式投資 第6版』では「景気の転換点を正確に予測することから得られる利益は大きいが、エコノミストの多大な努力にもかかわらず、予測の精度はあがっていない。」とする一方、「投資家が最もとってはいけない行動は景況感を後追いすることである。」(p.299)と戒めている。
景気が悪くなってから株を売り、景気が良くなってから株を買うのでは遅すぎるということなのだろう。下げた後で売り、上げた後で買う、という行動がもっとも良くないのだ。
これからトランプ不況が来る可能性があり、もし来たならば株価はさらに大きく下落し、そのときが投資家には絶好の買い場となるでしょう。但し、この予想があたるかどうかは神のみぞ知るです。信じすぎないようご注意ください。
参考資料
[1]「USMCAはメキシコからの輸入品の約半分とカナダからの輸入品の38%に適用されている」(NHKニュース)
[2] トランプ関税の米国経済への悪影響に注目が集まる:25%の関税の応酬で米国のGDPは1.8%、日本のGDPは0.9%低下
[3]『株式投資 第6版』(ジェレミー・シーゲル他著、株式会社日経BP、2025年3月10日発行)本書は米国株式市場を対象としており、このブログで引用したデータはすべて米国のものである。
[4] 図は『株式投資 第6版』の表19-1、表19-3を元に作成した模式図