先日社内でプレゼンの機会がありました。プレゼンといえばスライドですね。プレゼンには身振り手振りやデモなどもありますが、制作期間や発表時間といった制限時間、不測の事態や資料の提出などを考えるとスライドは安定性が違います。欲をいえばプレゼン時にスクリーンに出す資料と頒布する資料は対応を取りつつ情報量を変えたいなどもありますが、こういったものはリソースとの戦いですね。
スライドといえばMicrosoft PowerPoint、macOSであればKeynoteもあります。
これらのスライドを、PDFに別で保存することがあります。PDFであれば、会議の進行役に念のため予備を渡しておいて「表示環境がない」ということもそうありません。先に挙げたようなオフィスツールでPDF出力をしてもよいし、作り方にもよりますがHTMLスライドもWebブラウザなどからPDFとして出力できます。
今回なぜか発表本番2、3日前にXSL-FOを直接書いてスライドをPDF出力していました。せっかくなのでそのときのFOを一部ご紹介します。
スライドを作成するとき、コンテンツはスライドのコンテンツとして都度作成しなければなりません。構成や情報量は、発表時間やオーディエンス、発表環境などによって、練り直さなければならないためです。「スライドの一部を書き換えて何度も利用する」というのはよくあるかもしれませんが、媒体の方向性としては一品ものと捉えてもよいでしょう。1からスライドを作るのにXSL-FOを直接書くというのは個人的におススメできないことはあらかじめお伝えしておきます。
テキスト内容などは変更しています。また動作などについて保証するものではありません。使用したのはAntenna House XSL Formatter V7.0 MR5 となります。
ページレイアウトと背景
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format"
xmlns:axf="http://www.antennahouse.com/names/XSL/Extensions"
font-size="28pt"
line-height="1.8"
font-family="sans-serif"
color="white">
<fo:layout-master-set>
<fo:simple-page-master master-name="slide"
background-image="linear-gradient(to left, rgba(0,0,0, .7) 0%,rgba(0,0,0, .9) 100%) )"
page-width="1920px" page-height="1080px"
margin="0"
>
<fo:region-before extent="2cm" />
<fo:region-after region-name="footer" extent="2cm"/>
<fo:region-body region-name="body" margin="2cm 3cm" />
</fo:simple-page-master>
</fo:layout-master-set>
ページサイズは幅1920px、高さ1080pxのFHDサイズにしました。これはPDF出力時に物理的なサイズに変換されます。
ヘッダーとフッターの領域を2cmずつ用意し、本文区画は上下2cm、左右3㎝のマージンをとっています。
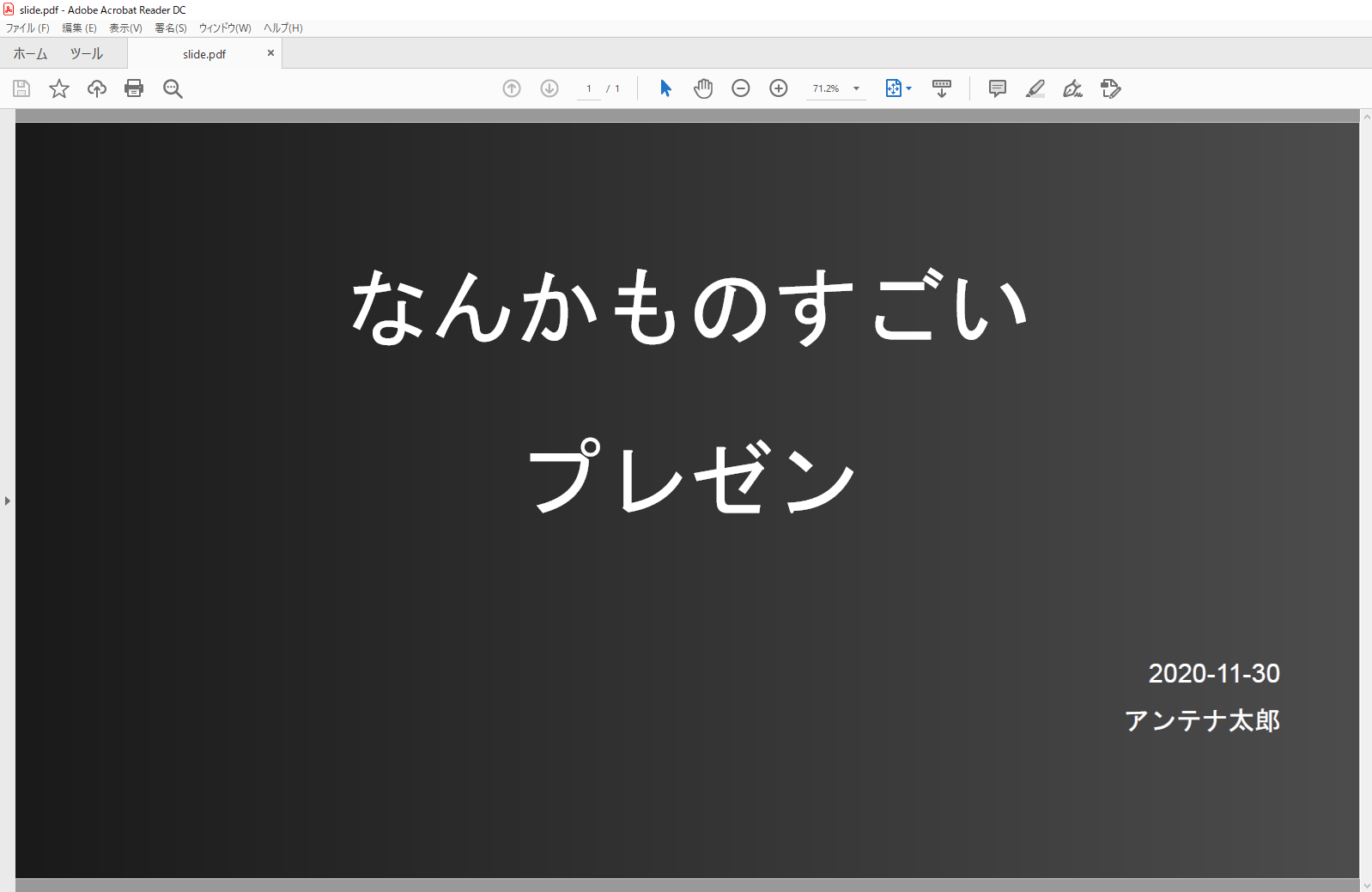
タイトルページ
タイトルページ
<fo:page-sequence master-reference="slide">
<fo:flow flow-name="body">
<fo:block-container id="title"
<fo:wrapper font-size="92pt" line-height="2" text-align="center">
<fo:block margin-top="2cm" >
なんかものすごい<fo:block />プレゼン</fo:block>
</fo:wrapper>
<fo:block-container space-before="3cm"
text-align="end">
<fo:block>2020-11-30</fo:block>
<fo:block>アンテナ太郎</fo:block>
</fo:block-container>
</fo:block-container>
</fo:flow>
</fo:page-sequence>
タイトルページではヘッダーとフッターを表示しないよう、その後のページとページシーケンスを分けていますが、参照しているページマスターは同じです。ページマスターを分けるほど複雑な構成は必要なかったためこのようにしています。
ヘッダーとフッター
ヘッダーに社のロゴ、フッターにスライドのページ番号を表示することにします。
ヘッダーとフッター、箇条書き
<fo:page-sequence master-reference="slide" initial-page-number="2">
<fo:static-content flow-name="header" >
<fo:block-container><fo:block text-align="end">
<fo:external-graphic src="url(https://www.antenna.co.jp/img/ah_headerlogo.svg)" width="8cm" height="1lh"/>
</fo:block>
</fo:block-container>
</fo:static-content>
<fo:static-content flow-name="footer">
<fo:block-container>
<fo:block
text-align="end" space-before="1cm" end-indent="2cm">
<fo:inline font-family="serif"> p-<fo:page-number font-variant="oldstyle-nums"/> </fo:inline>
</fo:block>
</fo:block-container>
</fo:static-content>
...
<fo:page-sequence>
ヘッダーのロゴの高さを行の高さにしました。このスライドでは使用していませんが、スライドの見出しをマーカーで参照し、ヘッダーで表示することを想定したサイズ指定です。SVGのロゴ画像なのでサイズ変更が容易で助かりました。
本文がサンセリフなのに対し、フッターのページ番号はセリフにすることで本文と区別できるようにしています。ついでにページ番号の数字はオールドスタイルにしてみました。ページ番号の前に接頭辞をつけるにはページシーケンスでfo:folio-prefixをつける方法がありますが、
initial-page-number=”auto”では前のページ番号を引き継ぐので、上で記述されているページの開始番号のように指定しなくとも問題ありません。
箇条書き
スライドでは定番の箇条書き表現。GUIのプレゼンテーションツールやHTMLとXSL-FOでかなり書き心地が異なります。
<fo:block-container break-before="page">
<fo:wrapper font-size="62pt" font-weight="bold">
<fo:block>
XSL-FOの関連仕様
</fo:block>
</fo:wrapper>
<fo:list-block provisional-distance-between-starts="0.5em"
provisional-label-separation="0em"
>
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<fo:block xml:lang="en">•</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>Extensible Markup Language
</fo:block>
</fo:list-item-body>
</fo:list-item>
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<fo:block>•</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>XMLNamespace</fo:block>
</fo:list-item-body>
</fo:list-item>
<fo:list-item>
<fo:list-item-label end-indent="label-end()">
<fo:block>•</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>XML Transformations</fo:block>
</fo:list-item-body>
</fo:list-item>
</fo:list-block>
<fo:block>
</fo:block>
</fo:block-container>1つの箇条書き項目を表すために記述がリストブロック、リストアイテム、リストアイテムラベル、リストアイテムボディの要素と、ラベルとボディ間の間隔を指定する必要があります。入れ子のリストブロックや長さがバラバラのリストアイテムなどがあるとき真価を発揮する箇条書き用の構造ですが、これくらいの内容であれば項目ごとにブロックで記述した方が簡単です。
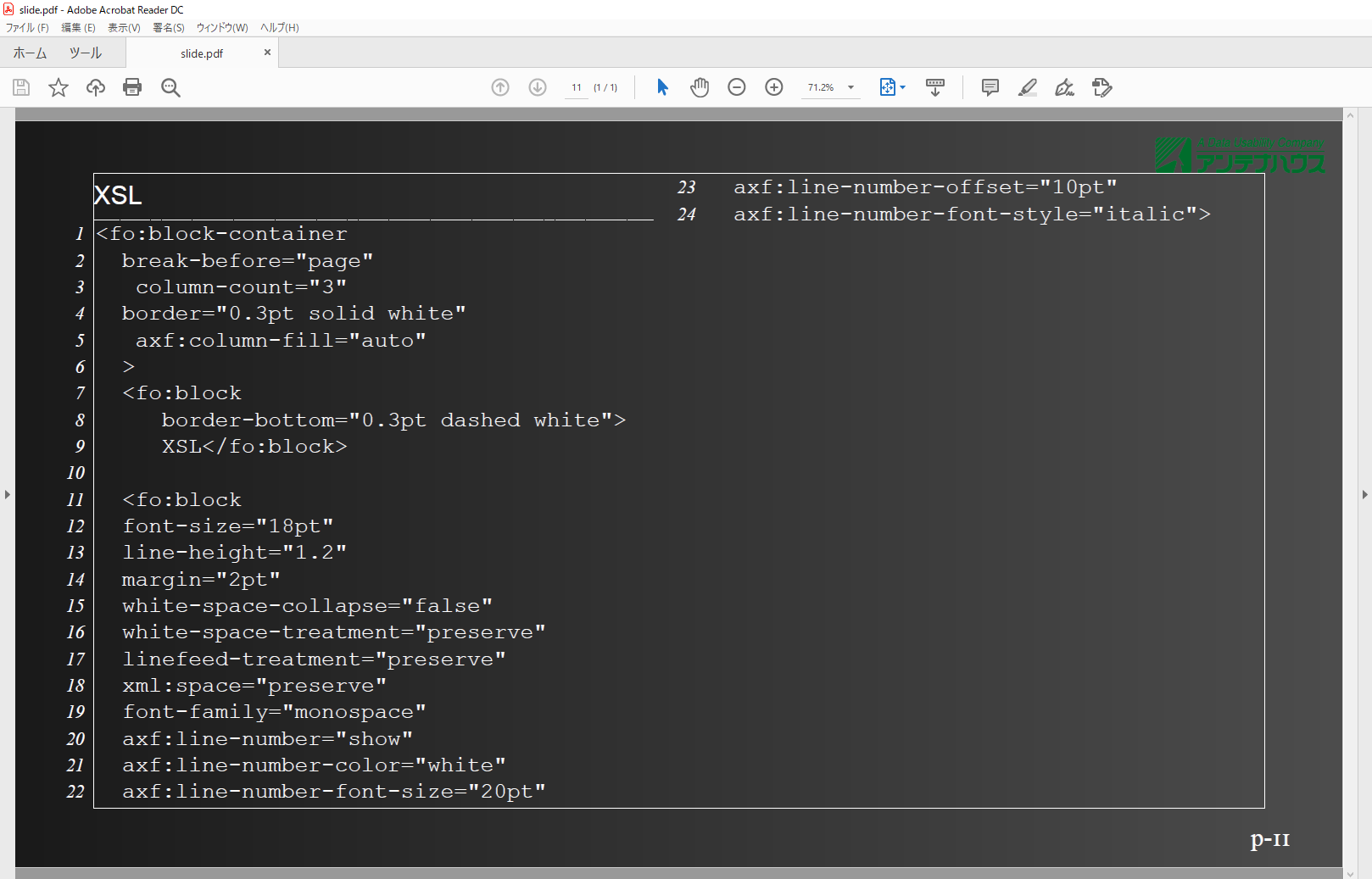
ソースコードを複数段表示する
ソースコード
スライドはスクリーンなどの都合もあり幅の方を長くとることが大半であると思います。これは改行で整えられた行数の多いコードを表示するのにあまり向きません。ブロックコンテナ―に段組を指定し、スライド1枚に詰め込めるソースコードを増やしてみました。
<fo:block-container break-before="page" column-count="2"
border="0.3pt solid white"
axf:column-gap="2em" axf:column-fill="auto"
>
<fo:block border-bottom="0.3pt dashed white">XSL</fo:block>
<fo:block
font-size="24pt"
line-height="1.2"
axf:line-number="show"
axf:line-number-color="white"
axf:line-number-font-size="20pt"
axf:line-number-offset="10pt"
axf:line-number-font-style="italic"
margin="2pt"
white-space-collapse="false" white-space-treatment="preserve"
linefeed-treatment="preserve"
xml:space="preserve" font-family="monospace">
..</fo:block>
</fo:block-container>ということでXSL-FOで直接作成したスライドとその記述の一部を紹介しました。今回のように直接書くのはやはりおススメできませんが、他のXML文書などからスライドを用意するのであればなかなか悪くないのでは、と感じました。