
10月14日から販売開始した『瞬簡PDF 変換 7』では、OCR処理を見直し、画像化されたPDFから従来の製品より正確な文字認識処理を行うことができるようになりました。さらにOCR変換時の処理速度も大幅にアップしました。
下のグラフは、旧製品(リッチテキストPDF6.1)と『瞬簡PDF 変換 7』を使用して、画像データを既定の条件でWordへ変換した結果を比較したものです。
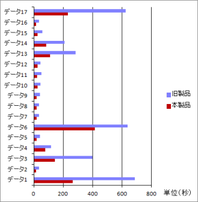
旧製品と『瞬簡PDF 変換 7』のOCR変換速度比較
(画像をクリックすると拡大します)
平均して、OCRを使用した変換では旧製品比で40~50% の速度アップを実現しています。この数値は、実行環境や元画像の状態、自動で回転や傾き補正を行うかどうかなどの条件によっても異なってきますが、多くの場合で処理速度の向上を実感していただけるものと思います。
また、操作画面においてもOCR処理がしやすくなる改善を行っております。
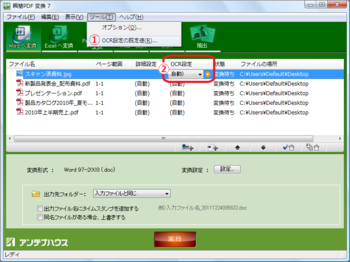
(画像をクリックすると拡大します)
これまで、OCRを行う際の変換条件は、画面上に登録された複数のファイルに対して一括で適用されるようになっていましたが、今回これを見直して、ファイル個別に変換条件を指定できるようにしました。
手順としては、
- 最初にメニューバーから[ツール]→[OCR設定の既定値…]を選択します。これにより全体のOCR変換条件を指定できます。
例えば、日本語文書を変換する機会が多い場合は、言語指定で[日本語]を選択して置きます。 - 次に登録されたファイル欄に表示された[OCR設定]ボタン(上図で赤枠内にあるオレンジ色のボタン)をクリックします。これによりファイル毎に異なるOCR変換条件を指定できます。
例えば、選択したファイルが他と違い英文の文書であったなら、OCR変換条件で言語指定を[英語]に変更します。
このように指定を行ってから[実行ボタン]をクリックすると、ファイル毎に指定した条件により、OCRを利用した変換処理が一括で実行できます。
『瞬簡PDF 変換 7』について、詳細は製品紹介サイトをお訪ねください。
明日は透明テキスト付きPDF作成時の改善についてご説明します。

アウトライナー
PDFを解析して しおり・目次を自動生成

瞬簡PDF 編集 2024
かんたん操作でPDFを自由自在に編集

