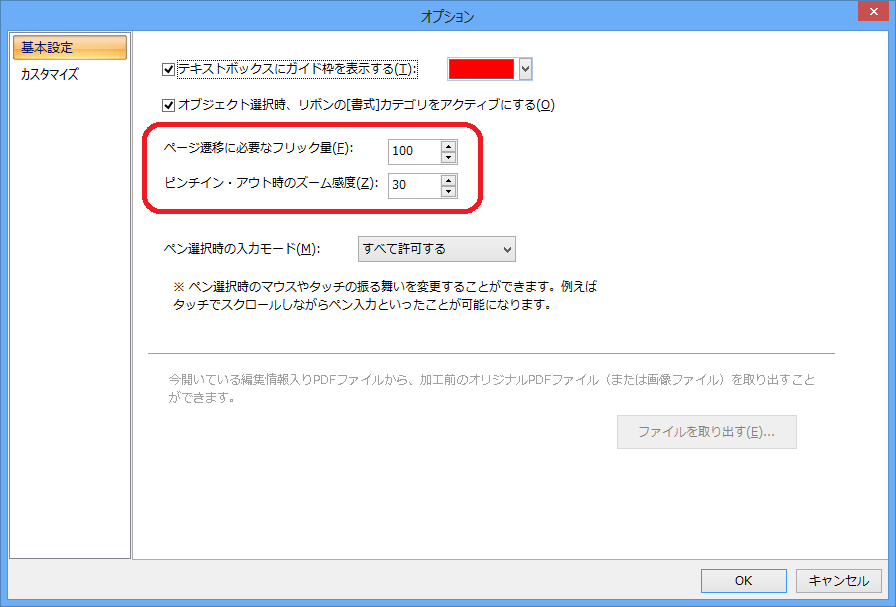
『瞬簡PDF 編集 4』はPDFのページ編集のほかに、PDFに文字列やページ番号、捺印などを追記したり、コメントやマーカー、図形などの注釈をつけることができます。これらは専用の編集用ビューアを使用して、ページに直接書き込むような感覚で操作することができます。
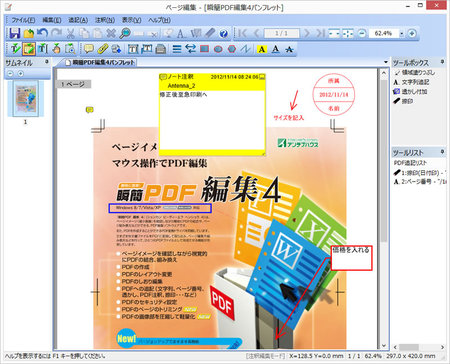
[PDF編集用ビューア 画面]
前バージョン『瞬簡PDF 編集 3.1』の改訂版で、注釈を追加したときの操作性などを改善しましたが、新しい『瞬簡PDF 編集 4』ではモードの切り替えや各種注釈の追加、編集がすぐに行なえるように、画面の上部のツールバーに専用のボタンアイコンを追加しました。
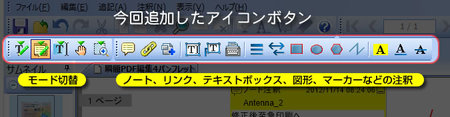
[モード切替/注釈用ボタンアイコン]
いままで無かったのでちょっと不便をお掛けしていましたが、今回の改訂でこれらのツールがかなり使いやすくなったかと思います。
どのようなことができるか、使ってみないとピンとこないと思いますので、『瞬簡PDF 編集 4』をご利用いただいている方はぜひお試しください。「これは便利!!」という発見があるかもしれません。
⇒ 『瞬簡PDF 編集 4』について詳しくはこちら
PDF編集用ビューアが使いやすくなりました!


瞬簡PDF 変換 2024
PDFをOffice文書へ高精度変換

アウトライナー
PDFを解析して しおり・目次を自動生成