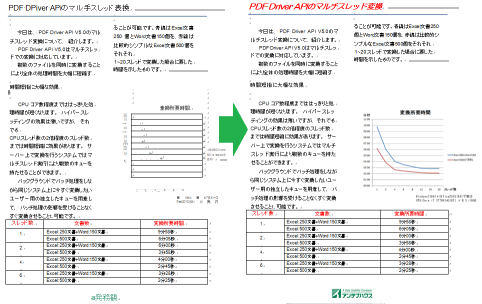
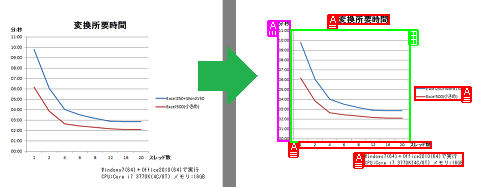
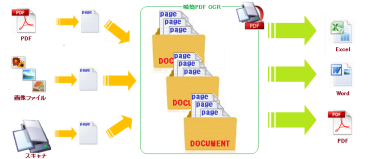
Server Based Converterは、Microsoft Office, PDFなどのファイルを、PDF, Flash, SVG, 各種画像形式にダイレクトに変換する変換エンジンです。
ダイレクト変換の意味は、たとえば、Microsoft Officeがない環境でも、ファイルさえあれば、それをダイレクトに内容を見える形式に変換できるのです。
Server Based Converterは、Windows Server 2012に対応するかというお問い合わせを頂戴しています。
Server Based Converterは、Windows Server 2012に対応いたします。
現在、動作検証を進めている状況です。
現在の最新版は、V4.0 MR2ですが、これで動作確認を行います。動作に問題がなければ、その旨、ウェブなどでお知らせいたします。
もし、動作に問題が起きたときは、改良を加えて、V4.0 MR3としてリリースすることになります。
いずれにしましても、最新バージョンの最新MRで、Windows Server 2012に対応することになります。
それ以前のバージョンにつきましては、まことに勝手ながら動作保証の対象外とさせていただきたく存じます。
どうしてもという場合は、弊社にお問い合わせ下されば、善後策を協議することができると考えております。
よろしくお願いいたします。
Server Based Converterに関する詳しい情報は、
Server Based Converter 製品ページ
を、ぜひ、ご覧ください。
評価版もご用意しております。
サーバベース・コンバーター 評価版のお申し込み
から、お申し込みください。
アンテナハウスのシステム製品につきましては、事前に技術相談会を行っております。お気軽にお問い合わせください。
詳しくは、
アンテナハウス システム製品技術相談会
をご覧の上、お申し込みください。
Server Based ConverterのWindows Server 2012対応について


瞬簡PDF 変換 2024
PDFをOffice文書へ高精度変換

瞬簡PDF 作成 2024
ドラッグ&ドロップでPDF作成