
日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』を使った変換について、昨日の続きから説明します。
『瞬簡PDF OCR』は、以下の手順で画像からの変換処理を行います。
- 画像データの読み込み
- 領域解析
- 文字認識
- 変換先ファイル形式への保存
昨日は、OCRソフトでは誤変換が避けられないというお話をしました。
本日は、誤変換を回避する方法として、画像データの「領域解析」から説明していきます。
下記は、サンプルのPDFを既定値で変換した例です。
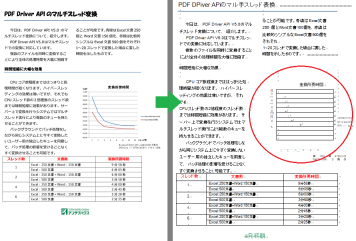
(画像をクリックすると拡大します)
自慢にならないですが、ひと目みて、おかしな変換や文字の誤変換があることがお分かりになるかと思います。
特に赤い丸をつけたグラフ部分がまったく再現されていません。これは、Word上では表に変換されているためです。
この原因は、OCR処理でこの部分の領域を間違えて認識しているためです。
『瞬簡PDF OCR』に戻って、ツールバーにある「領域解析」というボタンをクリックすると、OCR処理でどのような認識が行われたかが分かります。
以下は、問題部分の領域解析結果です。
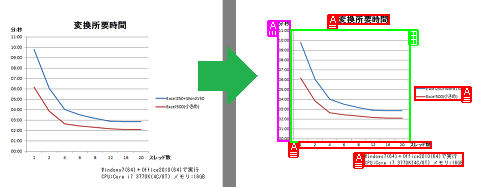
図で、赤枠で囲まれた箇所は横書きテキスト、ピンク色の枠で囲まれた箇所は縦書きテキスト、緑色の枠で囲まれた箇所は表領域にそれぞれ認識されています。表と認識されたのは、グラフにある横の目盛りを表の罫線と認識したためです。
これでは、Word上で修正しようがないので、元の認識処理に遡ってやり直す必要があります。
誤認識した範囲を画像領域に変更する例を図で示します。
(1)誤認識している領域範囲をマウスでドラッグ→(2)選択された領域をすべて解除→(3)範囲を選択し直し、一括で画像領域に変更
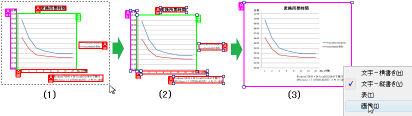
(画像をクリックすると拡大します)
領域を変更したところで、いったんWordに変換して結果を確認してみましょう。いったん「文字認識」を行い、「Wordへ変換」ボタンをクリックします。
以下は、Wordに変換しなおした結果です。先ほどのグラフ部分に注目してください。

(画像をクリックすると拡大します)
さて、変換結果をみると、まだ不具合があります。文書の先頭のタイトル部分が文字を誤認識しておかしなことになっています。
誤認識した文字の修正方法は、また明日の回で説明しましょう。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。


