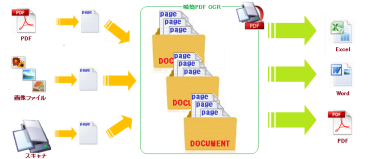
PDFを再利用する場合、元となるPDFは内容によって以下の2種類に分けることができます。
1)テキストが含まれているPDF
2)テキストが含まれない画像だけのPDF
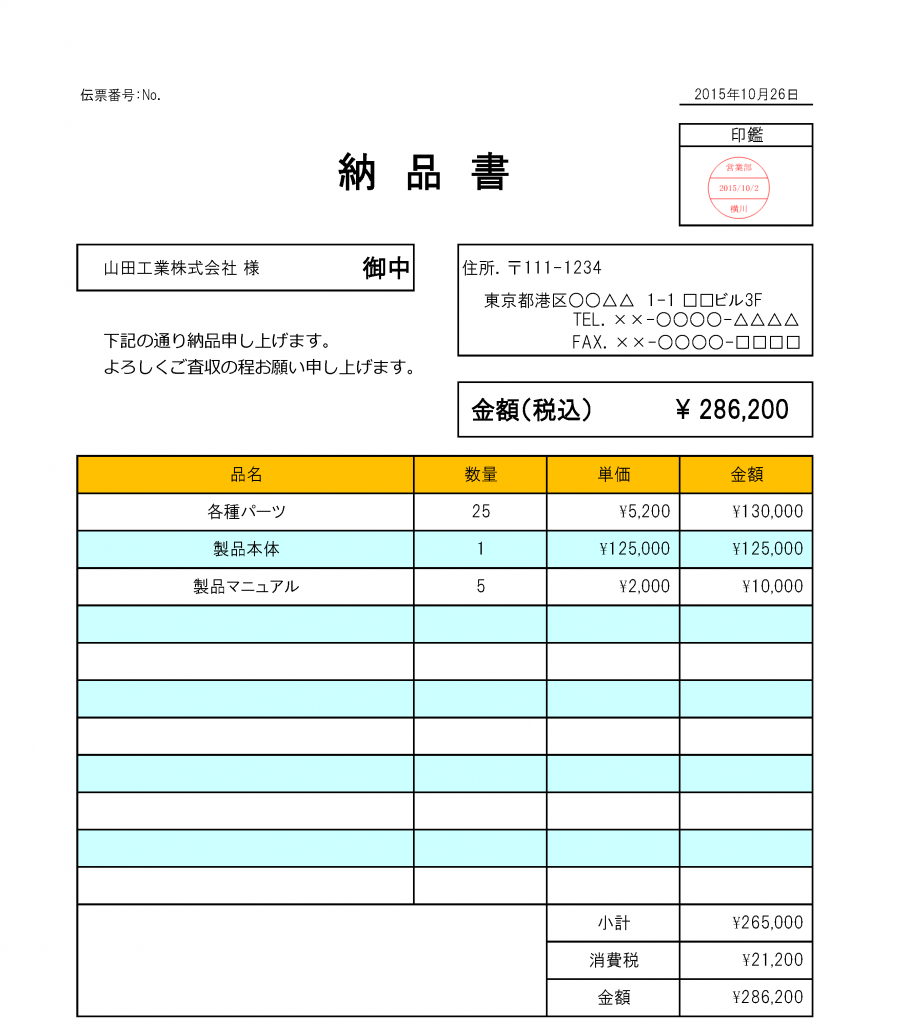
1)の「テキストが含まれているPDF」とは、WordやExcelなどで文字入力しPDF化したものが該当します。
このようなPDFからの変換には、『瞬簡PDF 変換 9』が適しています。
『瞬簡PDF 変換 9』は、PDFにテキスト・データが含まれていればそれを解析してWordやExcelに変換します。テキスト・データをそのまま変換するため文字化けしたりすることなくWordやExcel形式に移して再利用可能になります。
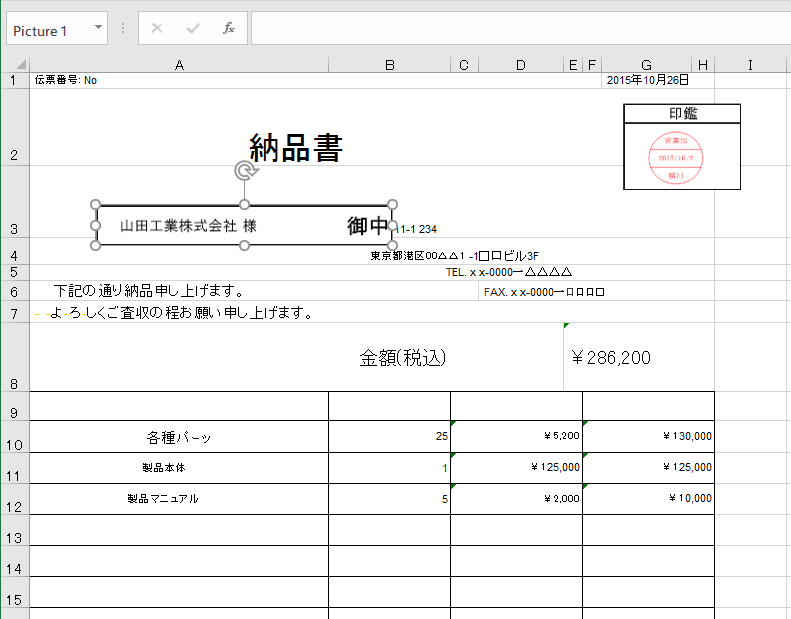
変換されたいPDFにテキスト・データが含まれるかどうかは、Adobe Reader などでPDFを表示して[編集]メニューから[すべて選択]をクリックしてみてください。
テキスト・データが以下のように反転表示されれば、テキストが含まれるPDFだと判別できます(※)。

テキストをすべて選択
※ スキャナーで作成された画像には、スキャナーがOCR処理をかけてテキスト・データをPDFに埋め込むことがあります(透明テキストつきPDF)。この場合は同じようにテキスト部分が反転して表示されます。
2)の「テキストが含まれない画像だけのPDF」とは、紙の書類をスキャナーで読み取ってPDF化したものなどが該当します。
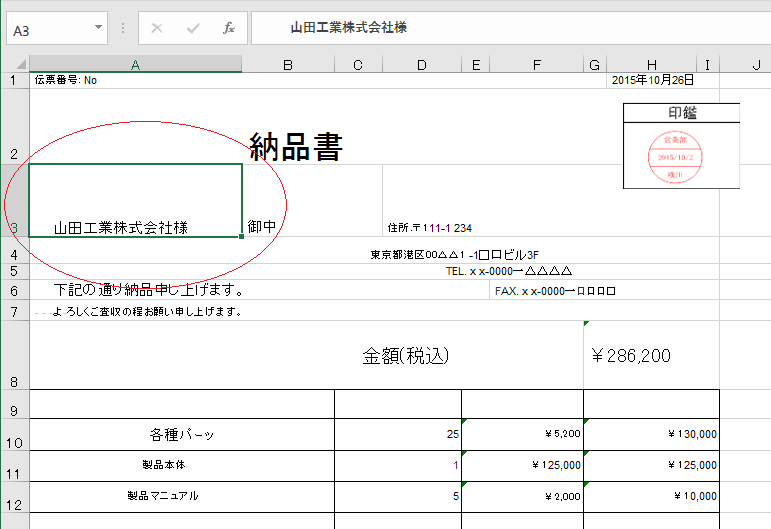
このようなPDFは文字と見える部分も画像でしかないため、そのままWordやExcel形式に変換しても編集のできない画像が貼り付きます。
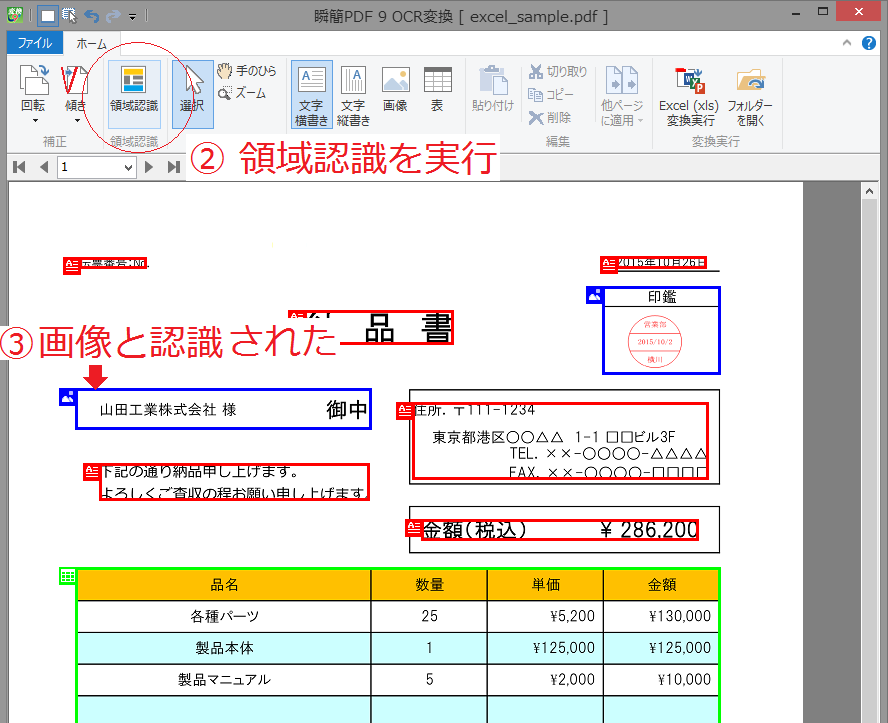
このようなデータに対しては「OCR」といって画像から文字を認識する機能を使うことでテキスト・データを取り出すことができます。ただし、OCR処理では画像の状態により文字が正しく認識できず、文字化けしてしまうことがあるため注意が必要です。
紙に印刷された内容をWordやExcelで再利用されたい場合は、『瞬簡PDF OCR』が適しています。
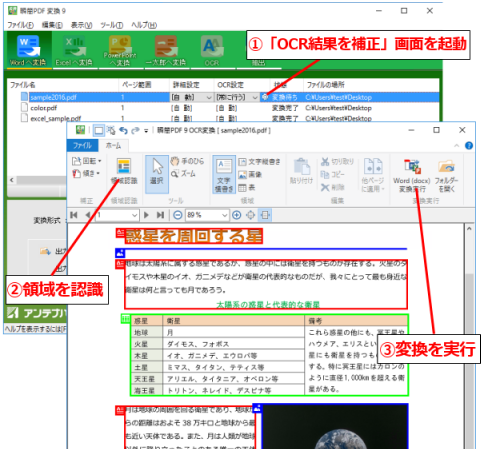
『瞬簡PDF OCR』はOCR専用製品で、スキャナーからの直接読み込みにも対応しています。
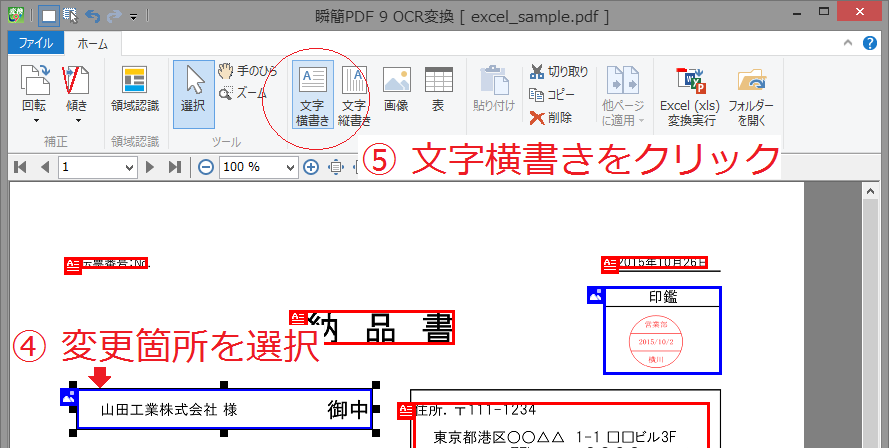
読み込んだ画像はOCR処理し、誤認識した文字を画面上で修正したり編集したりしながら、変換結果に反映させることができます。
(製品の仕様上、常にOCR処理をかけるため、テキスト・データがあらかじめ含まれているPDFを変換する用途には適しません。)
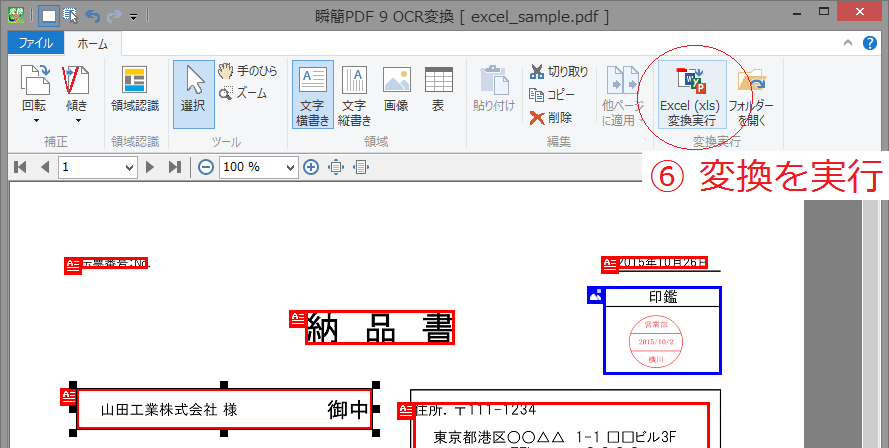
なお、『瞬簡PDF 変換 9』にもOCR機能があり、画像データからテキスト・データを認識して変換することができます。
ただし、スキャナーからの読み込み機能や誤認識した文字を画面上で修正する機能はありません。
『瞬簡PDF OCR』は紙の書類の再利用をされたい場合に適しているのに対し、『瞬簡PDF 変換 9』は内容に関わらず複数のPDFを一括して変換されたいような場合に適していると言えます。
どういったPDFを再利用されたいかによって、いずれの製品を選択するかご検討いただければ幸いです。
PDFをWordやExcelに変換したいけれど、望み通りに変換してくれるか心配…
PDFをWordやExcelに変換したいとお考えの場合、どれだけ正確に変換できるかが気になることと思います。
上記2つの製品にはそれぞれ体験版をご用意しておりますので、その変換精度や使い勝手を事前にご確認いただくことができます。
ただし、体験版では以下のような制限がありますので、あらかじめご了承ください。
- インストールしてから 15日を過ぎると利用できなくなります。
- ひとつのPDFについて、3ページまで変換可能です。
- 評価以外の目的で日常業務に利用することはできません。
体験版に関する詳細は、『瞬簡PDF 変換 9 体験版のお申し込み』、または『瞬簡PDF OCR 体験版のお申し込み』をそれぞれご参照ください。