『アウトライナー 2.6』の改定内容(その1)
『アウトライナー』の基本コンセプトは、デジタル納品・デジタル配信などのデジタル形式で利用するPDFの制作支援ツールです。
電子納品PDF制作ではPDF分割関連機能が重要です。現在開発中である次バージョンV2.6では、「PDF分割機能」を追加し、「PDF結合機能」を強化します。今回はPDF分割機能について説明します。
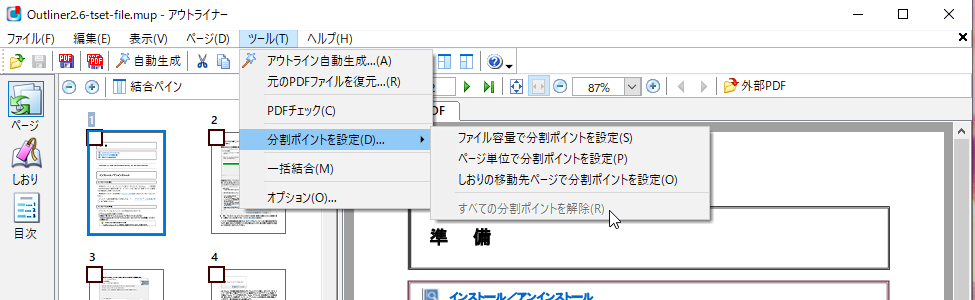
[分割ポイントを設定]
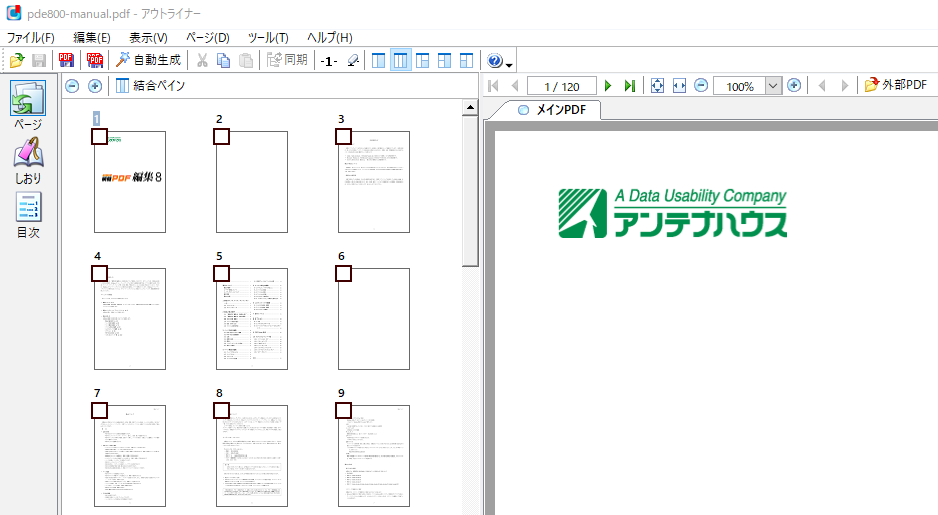
「ページモード」の「サムネイルペイン」です。サムネイルの左上にチェックボックスが追加されています。有効状態に設定したページは「分割ポイント」となりPDF分割時に先頭ページとなります。分割ポイントの設定には4つの方法があります。
- チェックボックスをマウスでクリック
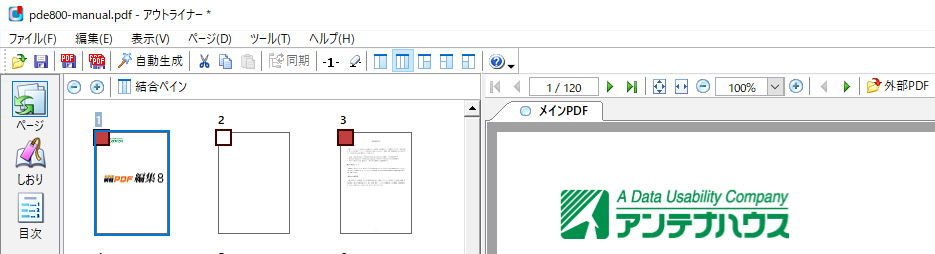
- ファイルメニュー、ツール、分割ポイントを設定、「ファイル容量で分割ポイントを設定」
編集中のPDFの保存時のサイズを計測して、指定したファイル容量で分割ポイントを設定します。
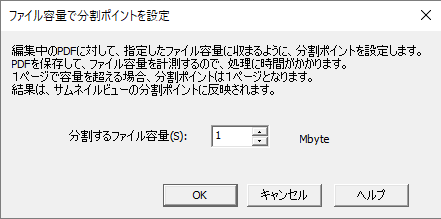
- ファイルメニュー、ツール、分割ポイントを設定、「ページ単位で分割ポイントを設定」
指定したページ単位で分割ポイントを設定します。
- ファイルメニュー、ツール、分割ポイントを設定、「しおりの移動先ページで分割ポイントを設定」
編集中PDFのしおりに設定された飛び先ページが変化したページに分割ポイントを設定します。

[分割してPDF出力]
ファイルメニュー、ファイル、「分割してPDF出力」または、ツールバーの「分割してPDF出力」ボタンをクリックします。
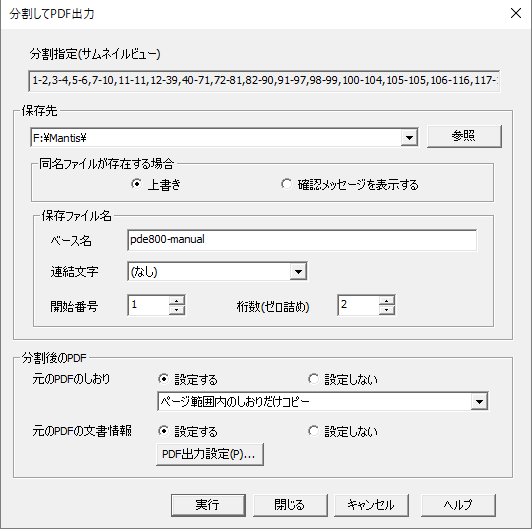 保存先フォルダ
保存先フォルダ
分割したPDFの保存先フォルダを設定します。
- 同名ファイルが存在する場合
「上書き」または「確認メッセージを表示する」を選択します。 - 保存先ファイル名
ベース名、連結文字、連番の開始番号、桁数(ゼロ詰め)を設定します。 - 分割後のPDF、元のPDFのしおり
分割先PDFに、しおりを「設定する」または「設定しない」を指定します。- ページ範囲内のしおりだけコピー
移動先が分割先PDFのページとなるしおりをコピーします。しおりは、文章内のページリンクを設定します。
移動先が分割先PDFのページに含まれないしおりは、コピーしません。 - ページ範囲内(内部)と階層レベル1(外部)のしおりをけコピー
移動先が分割先PDFのページとなるしおりをコピーします。しおりは、文章内のページリンクを設定します。
移動先が分割先PDFのページに含まれないしおりは、階層レベル1のみコピーします。しおりは、外部PDFのページリンクを設定します。 - すべてのしおりをコピー
移動先が分割先PDFのページとなるしおりをコピーします。しおりは、文章内のページリンクを設定します。
移動先が分割先PDFのページに含まれないしおりもコピーします。しおりは、外部PDFのページリンクを設定します。
- ページ範囲内のしおりだけコピー
- 分割後のPDF、元のPDFの文書情報
分割先PDFに、文書情報を「設定する」または「設定しない」を指定します。
分割の「実行」を選択すると、経過ダイアログが表示されます。
今回追加している「PDF分割機能」は、国土交通省の電子納品用PDF制作に利用することを考慮しています。ファイル容量を自動計測して、分割ポイントを設定する。分割先PDFにページが含まれる、含まれないに応じて、ページリンクを内部リンクまたは外部リンクに自動設定する。出力先PDFファイル名の自動連番を設定する。など、便利な機能を用意しております。
製品に関するご質問は
outliner@antenna.co.jp(アウトライナーサポート)
まで、お気軽にお問い合わせください。
評価版のお申込
評価版のお申し込み