電子書籍、電子出版のCAS-UBブログ でも案内しているとおり、アンテナハウスは、クラウド型EPUB/電子文書リーダ“AH Reader Preview”を公開しました。お使いいただくには、次のAH Readerについてのページにアクセスして、「AH Reader Preview を使ってみる」をクリック。
○AH Readerについて http://r.cas-ub.com/
これでお使いのブラウザがEPUBリーダーになります。Webアプリケーションなのでインストールは不要です。
“AH Reader Preview”は、組版エンジンとして AH Formatterをサーバー側で使用しています。
AH Formatterの最新開発中バージョンが使われているので、その機能を試すのに“AH Reader Preview”を利用することもできます。
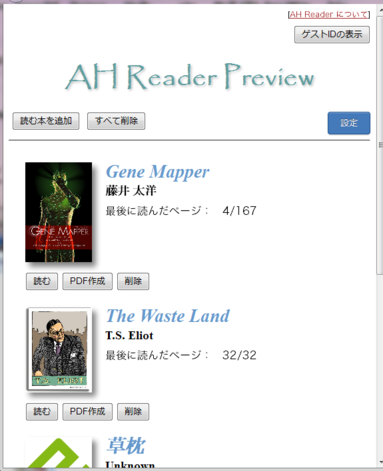
AH Reader Previewのホーム画面:
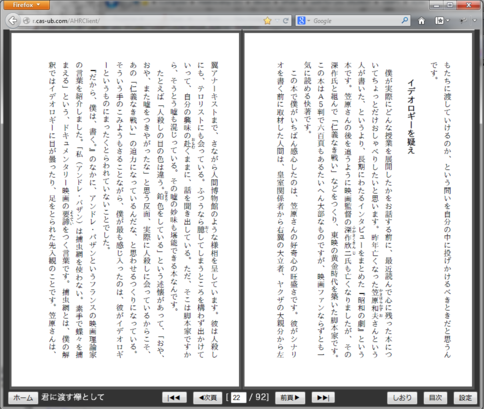
縦書き/横書きの切り替えが可能
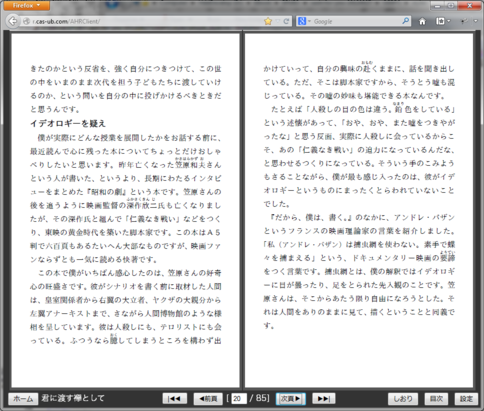
AH Readerは、EPUB3の縦書きと横書きのスタイルシートの切り替えのしくみに対応しています。
「設定」から「組み方向」の縦/横の切り替えができます。
IDPFで公開されているEPUB3サンプルの次のものが縦/横の両方のスタイルが切り替えられます:
縦書きの表示と横書きの表示の切り替えの例(サンプルは sash-for-you-20120827.epub):
このほか、AH Readerにはユーザーが表示スタイルを自由にカスタマイズして表示できるようにユーザースタイルシートの設定機能があります。次回はその紹介をしたいと思います。
(AH Readerの使用上の注意や制限事項などは「AH Readerについて」ページにありますので、ご使用前にお読みください)