前回[1]はパス(ロケーションパス)の構成法を学びました。続いてパスの使い方を調べてみます。
スタイルシートで重要な役割を果たす要素の一つにxsl:apply-templatesがあります。XSLT[2]の5.4 Applying Template Rulesを見ますと、xsl:apply-templatesの定義は次のようになっています。
<xsl:apply-templates
select = node-set-expression
mode = qname>
<!– Content: (xsl:sort | xsl:with-param)* –>
</xsl:apply-templates>
select属性を省略すると、xsl:apply-templatesはカレントノードのすべての子供を処理します。select属性の値に式を記述することで、処理対象とするノードの集合を限定できます。この式はどのように評価されるのでしょうか?
XSLTの5.1 Processing Modelを読むと、ノードにmatchするテンプレート規則の中から、あるテンプレート規則が選択されると、テンプレート規則はそのノードをカレントノードとして起動されるとあります。
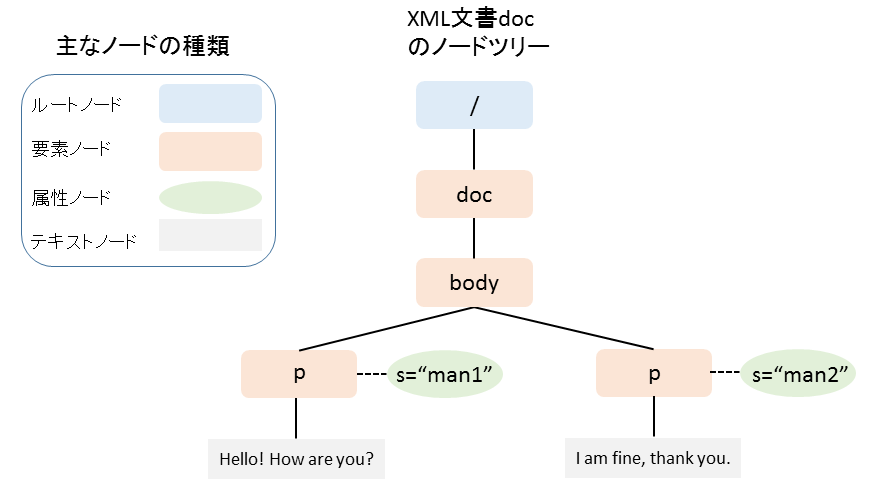
本書[3]には次のような例(2.18の一部)が出ています。
<xsl:template match=”body”>
<fo:page-sequence master-reference=”main”>
<fo:flow flow-name=”xsl-region-body”>
<xsl:apply-templates select=”p”/>
</fo:flow>
</fo:page-sequence>
</xsl:template>
<xsl:template match=”p”>
<fo:block>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
最初のブロックのテンプレート規則(xsl:template)は、(要素ノード)bodyにmatchしています。従って、最初のブロックではbodyがカレントノードです。
XPath[4]の式は文脈ノードで評価されます。XSLTの4 Expressionsを見ますと、最も外側の式(ある式の一部でない式)は文脈を次のように取得します。
a. 文脈ノードはカレントノードから
b. 文脈ノードの位置は、カレントノードリストにおけるカレントノードの位置から
c. 文脈ノードの大きさは、カレントノードリストの大きさから
こうして、最初のxsl:apply-templatesのselect属性の値である式p(child::pの省略記法)の文脈ノードはbodyになることが分かります。こうしてselect属性によりbodyの子であるpを選択したノード集合を作ることになります。(bodyの子のpではない要素ノードや、bodyの兄弟p要素ノードは対象になりません)。
[1] XSLTを学ぶ (3) パスとは
[2] XSL Transformations (XSLT) Version 1.0
[3] 『スタイルシート開発の基礎』
[4] XML Path Language (XPath) Version 1.0
前回:
XSLTを学ぶ (3) パスとは
初回:
XSLTを学ぶ(1)XMLのツリーモデルとXPath/XSLTのツリーモデルではルートの意味が違う