
[8/4追記]社内で「Chrome出力ではなくAcrobat Readerの対応外のタグ使用によって表示が壊れている可能性がある」と指摘を受けました。記事内での表現を修正します。
当初の記事タイトルは「タグ付きPDFがGoogle Chromeのデフォルトに?」だったのですが、現状としては「今後Google Chromeでタグ付きPDF出力が可能になるかもしれない」あたりのようです。
今回使用した環境は次になります。
- Windows 10 Home 1909
- Google Chrome バージョン: 86.0.4221.0(Official Build)canary (64 ビット)
- Acrobat Reader DC – Japansese (20.009.20074)
- 検証に使用したページ*: https://www.w3.org/TR/xsl11/
2020年8月リリースのGoogle Chrome 85から、タグ付きPDFの出力がサポートされます[1]。関連する情報発信自体は以前からあったようですが、実際にリリースされるこのタイミングで俄かに活気づいているようです。活気づいてますよね?
早速Google Chromeをサイトからダウンロードしてみましたが、バージョンを確認すると2020年8月3日時点では84のようです。Google ChromeにはCanaryバージョンがあるのでこちらをダウンロード。試験運用版ですので、同様に検証される方はくれぐれも自己責任でお願いします。(84でもExperimentalの設定として「Export Tagged PDF」を有効化できます。)
バージョンを確認。86……86ですね。85ではありませんが、検証には問題ないでしょう†。
† この後Chrome 84でのtagged PDF出力も確認しましたが、同様の結果になりました。
タグ付きPDFとは
ざっくりとまとめると「タグ付きPDFは、内部に文書構造を指定するタグを付与したPDFのこと」になります。
通常PDFは印刷物のデジタル表現、つまり視覚的な表現として文書構造が見られればよいわけですが、
PDF内部のデータを別の目的で使うときにこの情報だけでは不足することがあります。
別の目的としては、データの読み上げ、PDFから他形式への再変換などがあります。
また、PDFをHTMLのようにリフローで表示したいときにも、タグを用いることで文書の表示順序などを壊さないようにできます。
「HTMLのように」と書きましたが、このタグ付きPDFで設定できるタグの多くはHTMLでのタグと類似したものになります。
概要は[2][3]、詳細は[4][5]をご覧ください。
新ビューアは今のところリフロー表示に対応していないらしい
Canaryだと、PDF出力オプションの他に「PDF Viewer Update」オプションがあるんですね。
chrome://flags/#pdf-viewer-update
これを有効化すると、84ではExperimentalのオプションである「PDF Two-up View」もついでに使えるようになります。

ウインドウ画面と表示をフィットさせる場合に上下と左右どちらを優先するか、回転表示、PDF注釈の表示のオンオフ、アウトライン表示など、色々改善がされていることがわかります。とはいえ、全体的なPDFの表示機能についてはまだまだ頑張ってほしいところです。
さて、タグ付きPDF対応と聞いて真っ先に期待してしまうであろうリフロー表示ですが、とりあえず86の新ビューアではできないようです。
「タグ付きPDFの出力」と「PDFのリフロー表示」は重なる部分もあるものの別の話なので、そういうこともありますね。
今回の新バージョンについて、ChromiumのブログにChrome Accessibilityのリーダーからコメントがあります。improving Chrome’s built-in PDF reader to better consume tagged PDFs
とあるので、それなりに可能性はあるのではないでしょうか。
> While this is an important milestone, we’re not done. Future work includes both improving the quality of generated tagged PDFs, and also improving Chrome’s built-in PDF reader to better consume tagged PDFs.
タグ付きPDFをChromeで出力する
本題のタグ付きPDF出力です。Experimentalな設定で次を指定するとタグ付きPDFが出力できるようになるとあります。
chrome://flags/#export-tagged-pdf
では、PDFを出力してみます。*のページを「PDFで保存」します。さて、本来はこれをAcrobat Readerで開いてみて「おおー」となる予定だったのですが、「表示」「折り返し」を有効にしたAcrobat Readerでのリフロー表示がうまくいってないようです。

W3Cのページはあまり変なマークアップのHTMLはないはずです。タグ付きPDFは検証した日時でのGoogle ChromeとしてはExperimentalな機能なので、こちらが原因でしょうか。タグ付きPDFとリフロー表示についてはAcrobat Readerの対応状況も関連するので、Chromeの出力が原因ではないかもしれないとの指摘をいただきました。Google Chromeには自分の出力の正しさを証明するためにもPDFリフロー表示に対応してほしいですね。
PDFの内部を確認したい方は、アンテナハウスのデスクトップ製品『
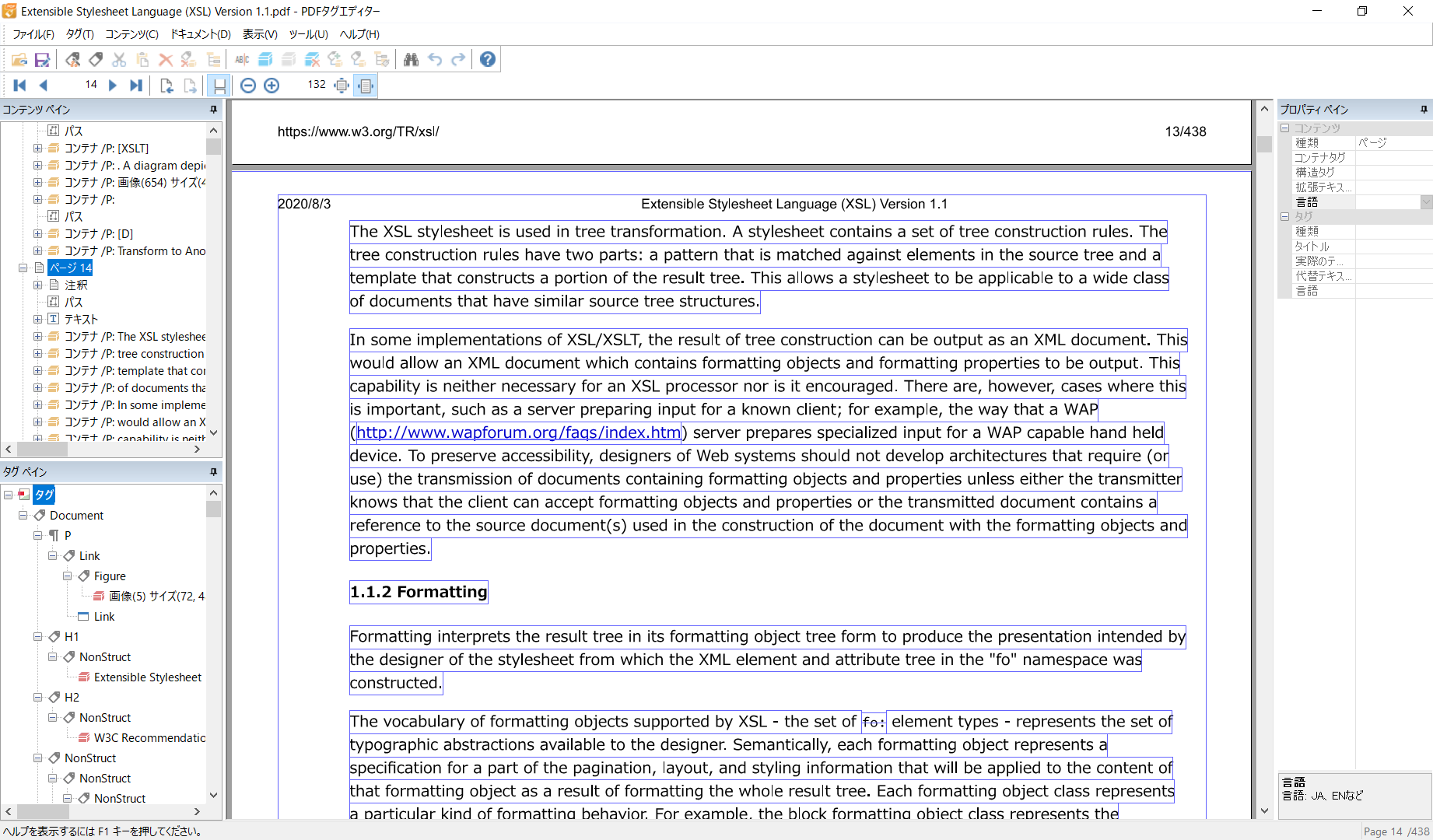
瞬簡PDF 編集 9』[6]付属の『タグ編集ツール PDFタグエディターVer.2』を使うとよいかもしれません。
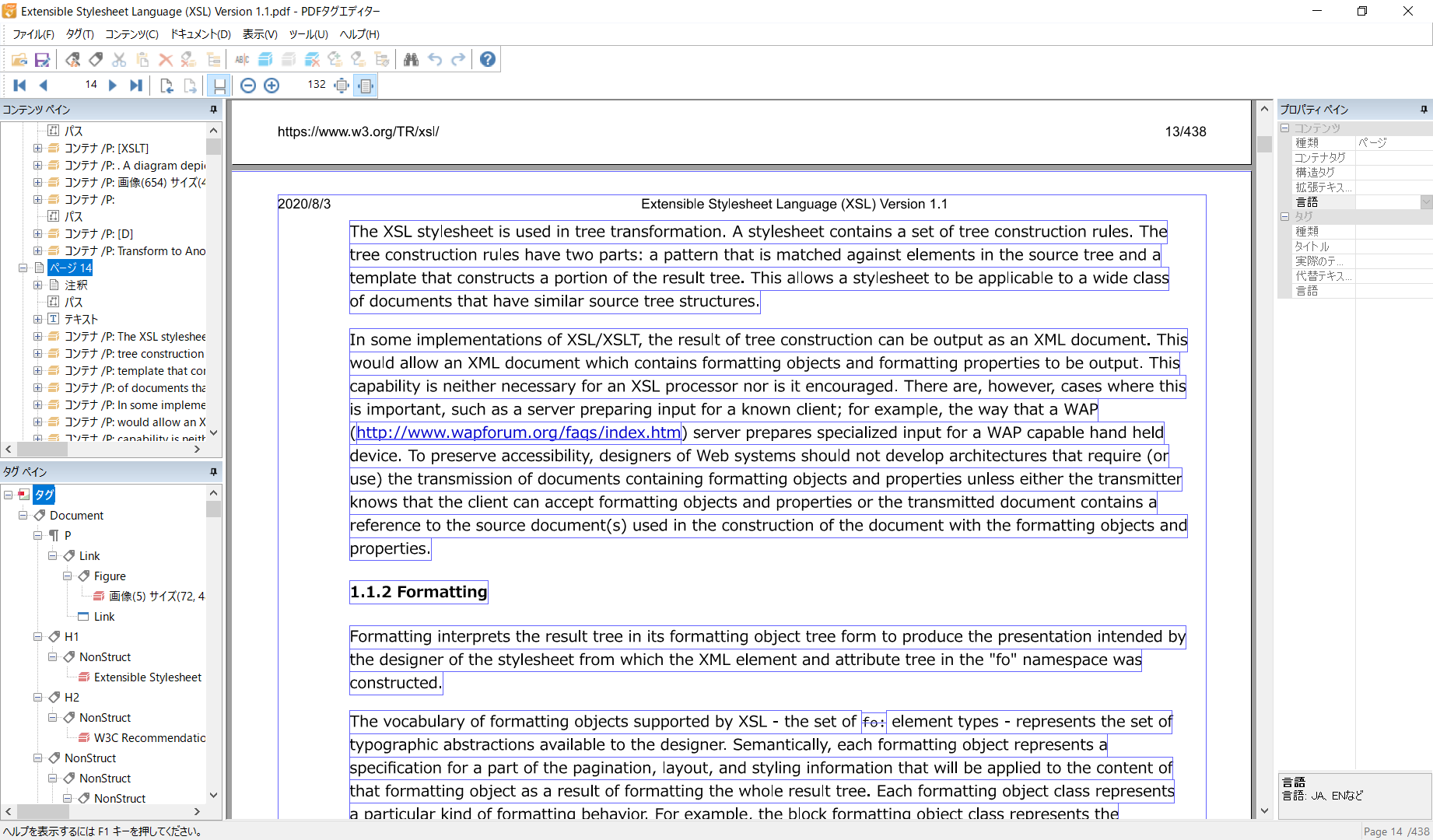
他に数件確認してみましたが、ページが上のように壊れることはないものの、「いきなり何もかも上手く出力できる」とはいかないようです。Experimentalな機能なので詳細な検証をすることを避けました。
ちなみに、Chromeでのタグ付きでないPDF出力をAcrobat Readerの折り返し表示したときは、とりあえずは表示されています。
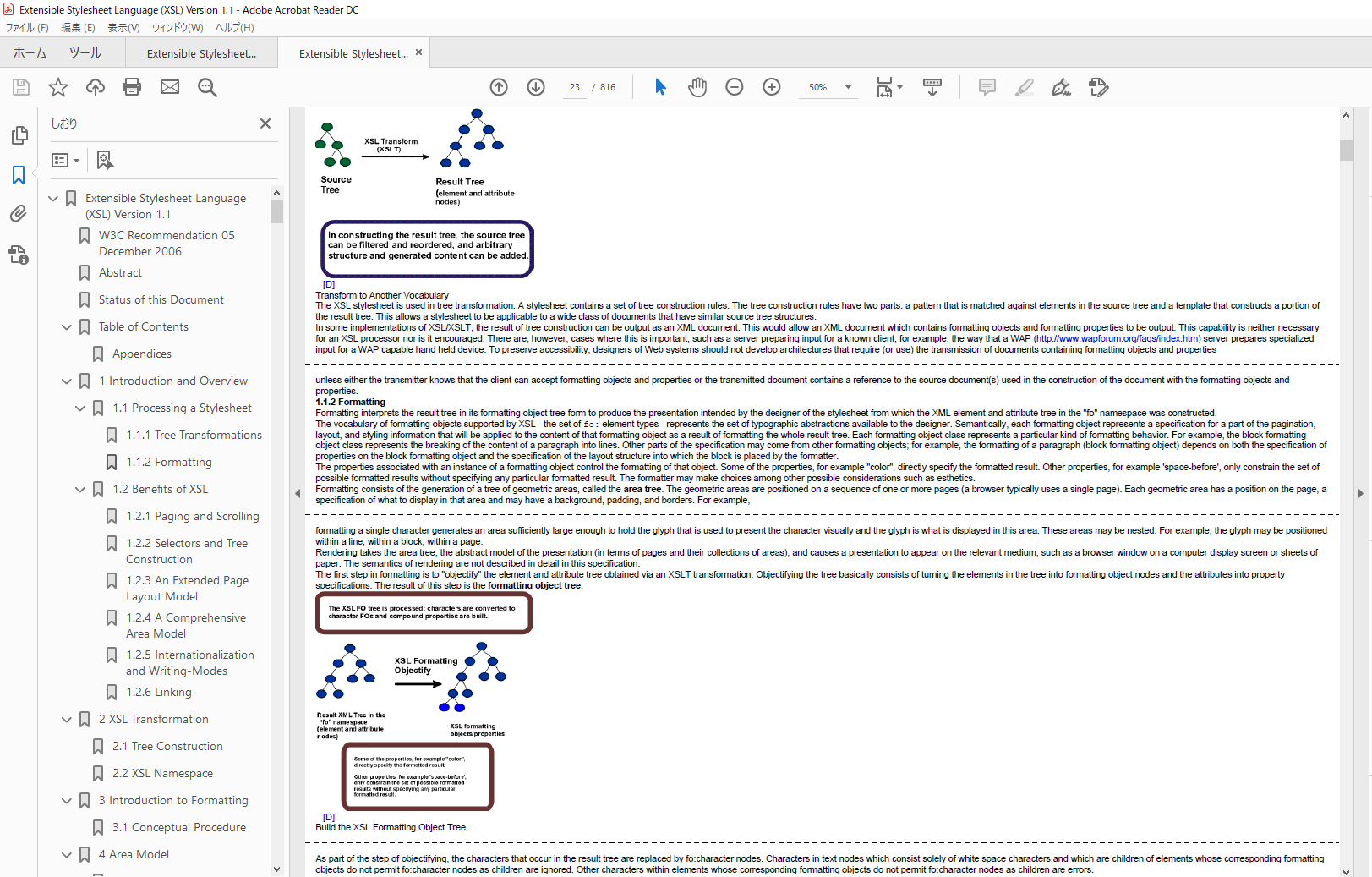
ちなみに、同じWebサイトをAntenna House Formatter V7.0 MR3でタグ付きPDFを出力した場合、折り返し表示でも問題はないようです(フォントサイズや余白、分割アルゴリズムの違いなどがあるので同じ条件にはなっていません。)。
ChromeでのHTMLとタグ付きPDFの補足資料
Chromiumのタグ付きPDF機能開発におけるデザイン資料[7]によればこれはマークアップを元にタグを付与するものなので(AIが何もかもやってくれるような話ではない)、求められるタグを出力できるかはページ製作者次第です。Chromeの開発過程で実際にはどうなったかは確認していませんが(資料中のメーリスやバグトラッカーを確認していけばよさそうです)、DOMツリーと描画用ツリー、そしてARIA属性などを基にした「Accessibility tree」を利用するデザインのようです。
The accessibility tree computed in Blink is another good possibility. The accessibility tree is derived from the DOM and the Layout Tree and also takes accessibility attributes such as ARIA attributes into account.
Chromium Tagged PDF Export Design Doc
We think the accessibility tree is the best fit and that’s the design proposed here.
Chromium Tagged PDF Export Design Doc
つまり出力が完璧だったとして、現在のところ多くのWebページについて実用的かと言われれば疑問の残るところ。残念ながら、ページによってはむしろ不要なノイズだらけになってしまうでしょう。[7]に次のようにありますが、こういった機能を機にアクセシブルなWebページを作ろうという気運が再燃したりすれば幸いです。
正常に出力されるページもあるかもしれませんが、現在Experimentalとある機能ですので、今回はここまでとします。
タグ付きPDFにご興味を持たれた方は、アンテナハウスのPDF製品を是非チェックしてみてください。
if you visit a web page that’s compliant with WCAG accessibility guidelines, then export it as PDF, then open that PDF in Chrome, the PDF in Chrome should have the same level of accessibility, modulo the limitations of a PDF file.Chromium Tagged PDF Export Design Doc
- [1] Using Chrome to generate more accessible PDFs – Chromium Blog
- [2] タグ付きPDFとはどんなもの
- [3] PDFのリフロー表示。タグ付きPDFとタグの付いていないPDFの比較。
- [4] 『タグ付きPDF 仕組と制作方法解説』
- [5] 『PDFインフラストラクチャ解説』
- [6] かんたん操作でPDFを自由自在に編集 瞬簡PDF 編集 9
- [7] Chrome Tagged PDF Export – Authors: dmazzoni[at]chromium.org
November 2019









