
時々お客様から「変換速度が遅い」とのご指摘を頂戴する事があります。特に旧バージョンとなる「クセロ PDF Server V1.x」を使われていたお客様にはそう思われる方が多いようです。
この両者を見比べた場合、動作ログ(PDF Serverがどんな処理をしたかを記録したもの)の動きを同じファイルの変換で見比べてみると、V1.xの方はかなり流れが速いのですがV2.3の方はゆっくりに感じます。この辺の感覚的なものも「遅い」と感じる要因なのだと感じます。
動作ログに関してはV2.xではV1.xに比べて記録する情報は少ないのと、変換動作を優先させるため、動作ログに関しては「後回し」にしているために見た目には遅く感じる部分はあると思います。また、PDF Server自体「高速化」を追求している訳ではなくむしろ「安定化」の方に重点を置いている事もあります。
ただ、V1.xとV2.0以降ではMS-Office変換などを行うPDF DriverやPDFを処理する部分の基盤技術が異なるため、同列にして比較する事は出来ませんし、そもそも設定内容は良く似ていても細かい部分では異なるために比較してもあまり意味はないとも感じます。
では、PDF Serverの変換速度はV1.xと比較して本当に遅いのでしょうか?
正解はケースバイケースとなります。PDF Server のV1.xは「ページ単位」で処理を行う事を基本としています。それに対してV2.xでは「ファイル単位」を基本としています。この違いはどういう感じで速度に表れるかと言えば、ページ数が少なければ少ないほどV1.xの方が速いのですが、逆にある程度ページ数が多いとV2.xの方が速くなります。
実際に同じマシン(CPU:Pentium4 2.8GHz/メモリ2GB)で計測してみました。V1.5を使用するため、やや古いマシンでの計測になります。2つのExcelファイルをV1.5とV2.3で同じような設定を行って変換した場合です。1つは3シート/3ページ、もう1つは8シート/56ページです。
【3シート/3ページのExcelファイル】
V1.5:約7秒
V2.3:約38秒
【8シート/56ページのExcelファイル】
V1.5:約56秒
V2.3:約41秒
変換速度は画像やグラフなどの数によっても変換速度は異なりますが、V2.3ではページ数が変わってもさほど変化はありません。この傾向は他のファイルでも同様となります。
PDF Serverは設定を見てもらえば分かると思いますが、かなり複雑な設定が出来ます。どの程度の設定を行うかにもよりますが、速く処理を行う事よりもどのような設定でも同じように安定して変換動作が出来る事を優先しています。
そうは言っても次期バージョンでは多少「高速化」も意識しながら現在開発を行っていますが、そのあたりのバランスもあるためご理解頂けると幸いです。
PDF Serverの変換速度は遅いのか


瞬簡PDF 作成 2024
ドラッグ&ドロップでPDF作成

アウトライナー
PDFを解析して しおり・目次を自動生成








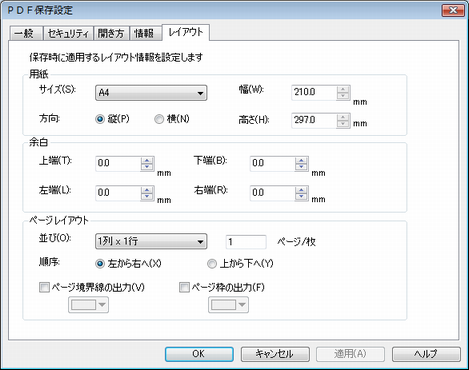
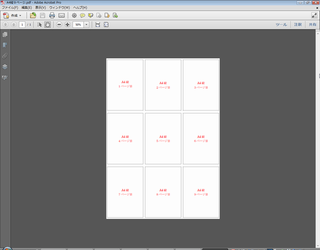 9ページ割り付けした結果
9ページ割り付けした結果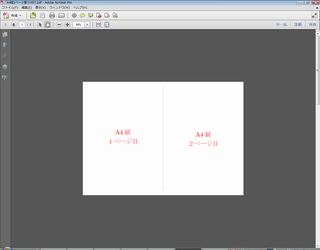 A4縦をA4横に割り付けした結果
A4縦をA4横に割り付けした結果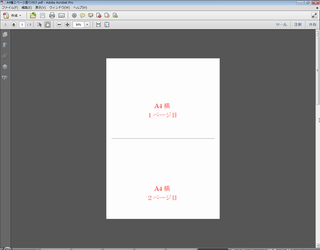 A4横をA4縦に割り付けした結果
A4横をA4縦に割り付けした結果
 ページの移動のオペレーション
ページの移動のオペレーション ページの移動結果
ページの移動結果 ページの回転結果:3ページ目の回転
ページの回転結果:3ページ目の回転 ページの削除選択:2-3ページの選択
ページの削除選択:2-3ページの選択 ページの削除結果:2-3ページを削除した結果
ページの削除結果:2-3ページを削除した結果
 結合先ファイルの表示位置に結合する
結合先ファイルの表示位置に結合する 結合先ファイルの先頭または最後に結合する
結合先ファイルの先頭または最後に結合する 結合先ファイルの先頭または最後に結合する
結合先ファイルの先頭または最後に結合する