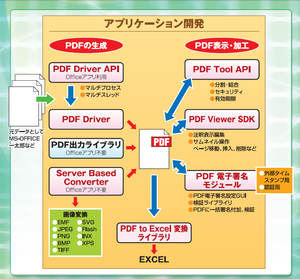
「自在眼11SDK」を紹介させて頂きます。
「MultiViewer SDK for 自在眼11 (自在眼11 SDK)」は、弊社パッケージ製品「マルチ・ファイルユーティリティ自在眼」のビューア機能を、様々なWindowsアプリケーションに組み込んでご利用いただくための開発キットです。
様々な形式のファイルや画像を、アプリケーションを必要とせず、表示・印刷することができます。セキュリティの面から広く利用されております。
また、各種ファイルを画像に変換することが出来ます。
表示対応フォーマット形式および画像に変換時の指定できる画像フォーマットにつきましては、下記をご参照下さい。
https://www.antenna.co.jp/oem/JanSDK/JanSDKFormat.html
シンクライアント環境: VMware、Hyper-Vにも対応しております。
評価版を用意しておりますので、その旨ご連絡、頂きますようお願い致します。
お待ちしております。
「TextPorter」を紹介させて頂きます。
「TextPorter」は、さまざまなアプリケーションのファイルからテキストを抽出する、クラウドコンピューティング時代のサーバ組込用テキスト抽出エンジンです。
テキストマイニング、全文検索などを行うシステムで、インデックス作成などに利用されております。
言語対応は、日本語、英語、中国語(繁体語、簡体語)、国際標準(UTF8、UTF-16、UCS-2、UCS-4)をサポートしております。
64bitネイティブライブラリの対応
TextPorterは64bitのライブラリも用意しております。TextPorterの64bit版は、2006年からWindows64bit版の販売を開始しております。
32bitのライブラリでも64bit環境で使用できますが、TextPorterを組み込む上位アプリケーションが64bit化する場合は、ライブラリも64bit版を使用しないと動作できません。
CPU版、OEMライセンス(再配布可能ライセンス)版共に、プラットフォーム追加のご契約で64bit版を追加することができます。
下記をご参照下さい。
https://www.antenna.co.jp/axx/
評価版は以下よりダウンロードが出来ます。
https://www.antenna.co.jp/axx/trial.html
お問合せは、oem@antenna.co.jpにて承ります。