『AH PDF Server V3』の新オプション「オフィス変換オプション」を営業環境にインストールして使ってみました。
「オフィス変換オプション」とは、PDFや画像ファイルを、サーバサイドでWord、Excel、PowerPointや一太郎に変換する、『AH PDF Server V3』のオプション製品です。
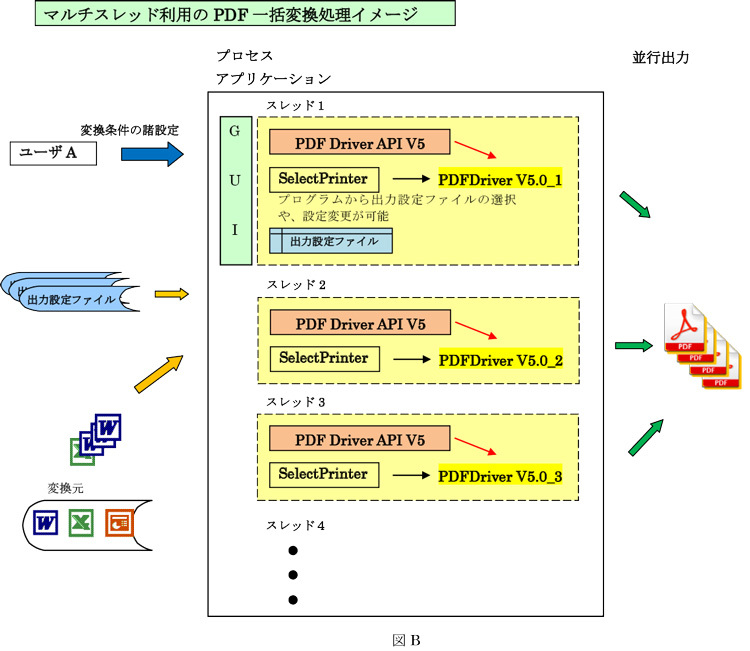
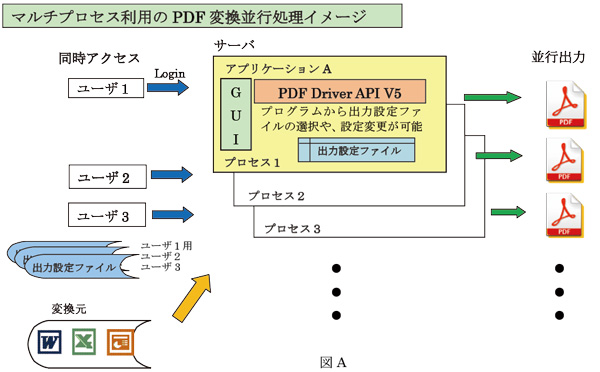
これを利用すれば、社内や社外から入手したPDFや画像ファイルを監視フォルダーに入れれば、下図の様な設定情報を反映して自動変換します。
5種類のPDFや紙原稿を投入して、サクッと逆変換してくれました。
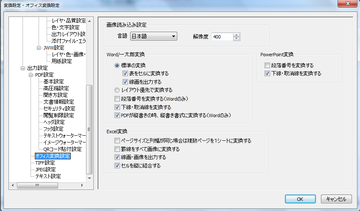
特に、文字コードが埋め込まれているPDF(WordやExcelから作成したもの)で、さらにフォントサイズが指定されていれば、より高度な解析により、高品質・高精度なファイル変換を実現します。
また、文字が画像化されていたものでも、OCR処理による文字認識をしてファイル変換します。
●評価版
『AH PDF Server V3 オフィス変換オプション』 は、Webから評価版を入手できます!
AH PDF Server 評価版のお申し込み
より入手できます。
是非ともご利用下さい。
サーバでPDFからOffice文書へ高精度「逆」変換!『AH PDF Server V3 オフィス変換オプション』


瞬簡PDF 統合版 2024
アンテナハウスPDFソフトの統合製品!

瞬簡PDF 変換 2024
PDFをOffice文書へ高精度変換