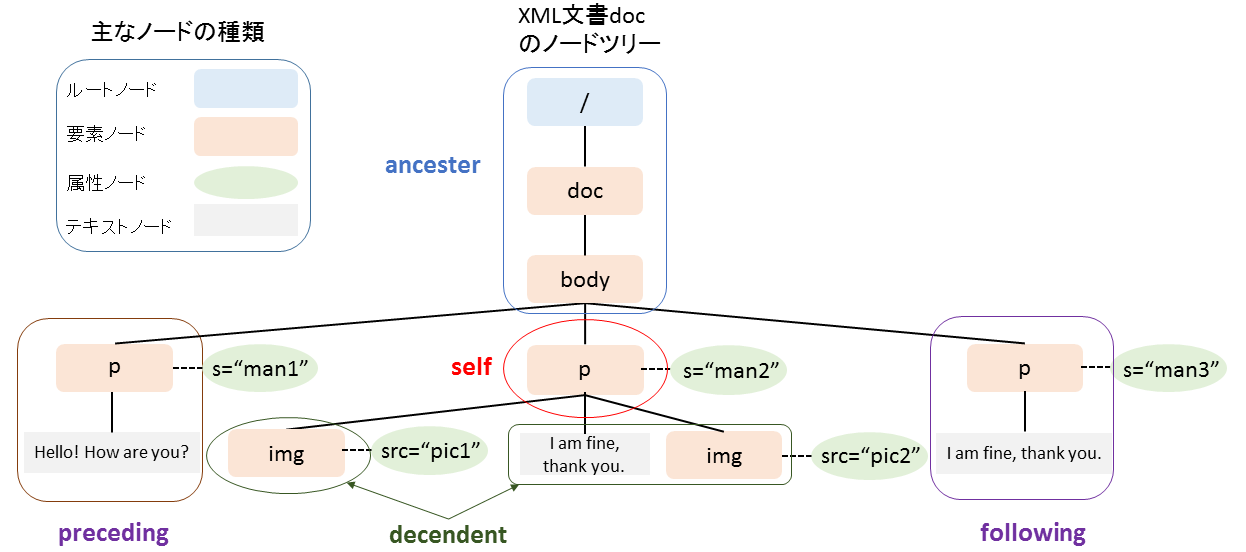
第9回[1]では、式の生成規則を辿っている途中に幾つかわからない項目が出てきました。その一つは、ノード集合に対する演算の扱いです。ここでは論理演算や比較の演算におけるノード集合の扱いを調べてみます。
論理値(Booleans)[2]。
or式は左辺と右辺の両方のオペランドをboolean関数と同じように論理値に変換して評価します。どちらかが真であれば真となり、そうでないとき偽となります。boolean関数はXPathで規定するコア関数の一種であり、引数を論理値に変換します。ノード集合は空でないとき真となります(詳しくは下に紹介しました)。
and式は両方のオペランドをboolean関数と同じように論理値に変換して評価します。両方が真であれば真となります。そうでないとき偽となります。
第9回の規則[23]の関係式(RelationalExpr)すなわち <=、<、>=、>、および等価式(EqualityExpr)すなわち=または!=、は左辺と右辺の二つのオペランドを次のように比較します。(ノード集合が関係するときだけを取り上げてみます。)
ノード集合同士を比較するときは、最初のノード集合と二つ目のノード集合の中に、ノードの文字列値同士を比較したときに真になるようなノードが含まれている時に限り、その比較は真になります。
ノード集合と数値の比較では、ノードの文字列値をnumber関数で数値に変換し、数値同士として比較します。ノード集合の中に、数値同士を比較して真になるようなノードが含まれていれば、比較が真になります。
ノード集合と文字列値の比較では、ノードの文字列値と他方の文字列値を比較し、文字列値同士を比較して真になるようなノードが含まれていれば、比較が真になります。
ノード集合と論理値の比較では、ノード集合をboolean関数で論理値にして、他方の論理値と比較します。
XPathには基本的な関数が規定されています。次に今日出てきた関数を紹介します。
boolean関数[3]
形式: boolean boolean(object)
boolean関数は引数を次のように論理値に変換します。
・数値は、ポジティブゼロでもネガティブゼロでもなく、NaN(Not-a-Number:数値でない)でもないとき真となります。
・ノード集合は空でないとき真となります。
・文字列は、長さがゼロでないとき真となります。
・四つの基本型以外のオブジェクトはその型依存の方法で論理値に変換されます。
number関数[4]
形式: number number(object?)
number関数は引数を次のように論理値に変換します。
・数値の後が空白で、前にオプションのマイナス記号、さらにその前のオプションの空白から構成される文字列は、その文字列によって表現される数学的値に最も近いIEEE 754数に変換されます。それ以外の文字列はNaNに変換されます。
・論理値の真は1に変換され、論理値の偽は0に変換されます。
・ノード集合は最初にstring関数を使ったように文字列に変換され、次いで引数が文字列のときと同様に数値に変換されます。
・四つの基本型以外のオブジェクトはその型依存の方法で数値に変換されます。
もし、引数が省略されたときは、既定値として文脈ノードのみから成るノード集合が使われます。
string関数[5]
形式: string string(object?)
文字列関数はオブジェクトを次のように文字列に変換します。
・ノード集合はノード集合の中で文書順で最初のノードの文字列値を返すことで文字列値に変換されます。ノード集合が空のときは空文字列が返されます。
・数値は次のように文字列に変換されます。
・NaNは文字列NaNに変換されます。
・ポジティブゼロは文字列0に変換されます。
・ネガティブゼロは文字列0に変換されます。
・ポジティブな無限大は文字列Infinityに変換されます。
・ネガティブな無限大は文字列-Infinityに変換されます。
・数値が整数型のときは、小数点や先行するゼロのない十進数で表現されます。数値がマイナスのときは、マイナス記号が先行します。
・整数でないときは、小数点を含み、小数点の前に少なくとも1個の十進数があり、小数点の後に少なくとも1個の十進数があり、マイナスのときは、マイナス記号が先行する形式となります。不要な先行するゼロがあってはならず、少数点の後には他のIEEE 754と区別するのに必要なだけの数値がなければなりません。
・論理値の偽は文字列falseになり、論理値の真は文字列trueになります。
・四つの基本型以外のオブジェクトはその型依存の方法で文字列に変換されます。
もし、引数が省略されたときは、既定値として文脈ノードのみから成るノード集合が使われます。
なお、string 関数は表示用に整形するために用意されているものではありません。整形にはXSLTのxsl:number要素を使います。
[1] XSLTを学ぶ(9)ステップの文法を追求する-述部(Predicates)と式
[2] 3.4 Booleans
[3] boolean関数
[4] number関数
[5] string関数
前回:
XSLTを学ぶ(10)式によるノード集合の作成、ノード集合の和集合、フィルター式
初回:
XSLTを学ぶ(1)XMLのツリーモデルとXPath/XSLTのツリーモデルではルートの意味が違う