本日は、9月に発売を開始したばかりのニューフェイス、『瞬簡PDF OCR』をご紹介します。
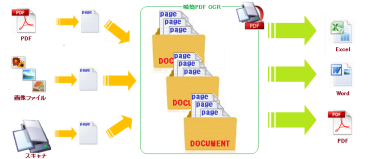
『瞬簡PDF OCR』は、紙に印刷された文書をスキャナーなどで読み取り、WordやExcelなどのOffice文書に変換する、いわゆる「汎用OCRソフト」のカテゴリに分類される製品です。
このカテゴリには、既に以前から多くのソフトウェア・メーカーさんが進出され、バージョンを重ねた老舗のソフトもいくつか見られます。
変換一筋25年を標榜するアンテナハウスが、今回ここに新製品を投入した狙いは、ズバリ、「編集しやすい変換結果を提供することで、より簡単に紙の原稿の再活用が可能であることを体験していただきたい」というものです。
このことは、『瞬簡PDF OCR』が、OCR汎用ソフトにおける文字認識精度などの入力側ではなく、Officeへの変換精度という出力側に焦点をあてた製品コンセプトであることを意味します。
以下では、具体的な例を通して説明してみたいと思いますので、どうぞ今しばらくお付き合いください。
みなさんは、マイクロソフト・ワードなどのワープロソフトで文書を作るとき、どんなふうに文字を配置していかれるでしょうか?
おそらく多くの方が、新規文書を開き、そこに示されたカーソルに従ってそのまま文字を入力していくことと思います。
これは、ワープロ上に本文領域が既定値で設定されていて、そこに文字を配置していく操作に他なりません。
つまり、普通に文書を作成する場合は、本文にテキストを配置し、必要であれば、やはり本文内に図や表を配置していくのが自然な操作であると言えます。
さて、次の図の例をみてください。

(画像をクリックすると拡大します)
これは、上の青い枠で囲まれた原稿(スキャナで作成されたPDF)をWordに変換した結果を示したものです。
左の赤枠で囲まれた結果はOCRソフトでは比較的よく見かける変換方法で、OCR処理した結果をWord上にテキストボックスで配置しています。
テキストボックスで文字を配置するのは、レイアウトの再現という面では有効な手法です。
しかしひとつながりの段落を段組レイアウトで配置しているような場合には、テキストボックスで段落のつながりが切れてしまうため、テキストの手直しが面倒になります。
Wordには、テキストボックスをリンクしてつなげる機能が備わっていますが、ひとつずつ手作業で指定するなど、使い勝手はあまりよくないようです。
右の赤枠で囲まれた方は、『瞬簡PDF OCR』でWord上に本文としてテキストを変換した結果です。
本文で変換することにより、文字の挿入・削除といった編集操作を違和感なく行うことができます。
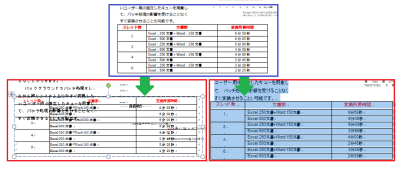
もうひとつ、同じような事例ですが、次の図をご覧ください。
(画像をクリックすると拡大します)
最初の例と同様、青い枠で囲まれた、表を含む段落をWordに変換した例です。
左の赤枠で囲まれた方は、やや見づらいですが、テキストを本文で変換し、表をテキストボックスで変換した例です。
表をテキストボックス内で変換して配置した場合は、Word上で本文と分離して置かれますので、そのままでは本文に重なって表示されます。
これに対し、右の赤枠で囲まれた方は『瞬簡PDF OCR』でWord上に表を変換したもので、本文内に表を置いています。
本文でテキスト行を追加したり削除すると、表も本文と一緒に移動します。
どちらが編集しやすいか、お分かりいただけるかと思います。
OCRの文字認識精度が高ければ文字を正確に抜き出せるので、あとはOffice上で自由に編集すればいい、という考え方も当然できます。
しかし、元の原稿が長文であったりレイアウトが複雑であったりするほど、後工程での編集にも時間がかかるだろうことは容易に予想されます。
せっかく貴重なお金を消費してOCRソフトを購入し、紙原稿をOffice上に写したものであれば、その後の再利用に要する時間は節約できた方が満足度も増すのではないでしょうか?
以上、『瞬簡PDF OCR』の目指すところを簡単に述べさせていただきました。
次回は『瞬簡PDF OCR』をご理解いただくための、より深い情報をご紹介したいと思います。
もし本製品にご興味をお持ちいただけた場合は、是非明日もこちらのブログを覗いてみてください。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。