Windows 10 では Microsoft Edge の一機能として PDF 表示が行えるようになっています。
http://ondoc.logand.com/d/223/pdf
の表示を試します。

赤丸で示した場所に少しエラーがあるようです。
CMYK Color と 縦書きのテキストの部分です。

以前 Windows 8 の Windows Reader を試した時と同じようです。
→ PDF 表示機能の比較

Windows 10 では Microsoft Edge の一機能として PDF 表示が行えるようになっています。
http://ondoc.logand.com/d/223/pdf
の表示を試します。
赤丸で示した場所に少しエラーがあるようです。
CMYK Color と 縦書きのテキストの部分です。
以前 Windows 8 の Windows Reader を試した時と同じようです。
→ PDF 表示機能の比較


アンテナハウスブログ「I love software」で、2005年10月~2008年7月の1000日間に亘って連載された「PDF 千夜一夜」に、2015年までに集めたPDF関連の情報やオリジナルの内容を加筆修正し、網羅的にまとめあげたものが、『PDFインフラストラクチャ解説:電子の紙PDFとその周辺技術を語り尽す』として出版します。
現段階では、Kindle ダイレクト・パブリッシング(KDP)で出版開始され、もう間もなくペーパーバックでも出版される予定です。
さて、そんなPDFに関する知識が満載された『PDFインフラストラクチャ解説』の出版を記念し、2月16日(火)、講演会を開催します。
PDFにおけるあれやこれを、いろいろ訊けるチャンスです!
『PDFインフラストラクチャ解説』出版記念特別講演会
ゲスト
松木眞氏(画像電子学会フェロー):PDFの国際規格ISO32000やPDF/Xなどの派生規格の作成等に参加。
ISO32000:PDFの国際規格の現状と将来について(仮)、いろいろ語っていただきます。

目次・書籍詳細
https://www.antenna.co.jp/pdf/reference/pdf-infra.html
(青い「目次紹介」をクリックすると、目次が表示されます)
本書のご購入は、こちらからどうぞ!
Amazon Kindleストア
エンドユーザーではなく、「技術者向け」の内容です。
(もちろん、技術者でない方でもPDFの成り立ちや、なぜそこにPDFが使われるのかなど、仕事仲間と話題にできる蘊蓄を仕入れられます)
PDFの仕様、製品に実装するための必要な技術情報など、PDFを中心に組版に必須のフォントや文字などの関連項目について解説。PDF登場の経過や歴史的側面の解説も多いので、読みごたえはあるかと思います。
昨今話題の電子署名やタイムスタンプ、長期保存、PDFから別のファイル形式(Officeやimgなど)への逆変換などにも解説しています。
●PR●
PDFに関する疑問にお答えします。「PDF資料室」:https://www.antenna.co.jp/pdf/reference/


【質問】「PDFとはなんですか? PDFにするとどんなメリットがありますか?」
仕事でパソコンを使っている人はもとより、自分の趣味で Webページを検索したり、メールで情報を交換しはじめた人が最初に面食らうのが、PDFファイルではないでしょうか? ここではPDFとは何かという素朴な疑問に答えてみました。
PDFを作成して配布したり、あるいはメールでの受け渡しが広く行なわれています。受け取ったPDFに文字や図形を書き込んだり、削除・追加するなどのいわゆる編集をしたいとき、どのような方法があるか、気を付けたい点などを整理しました。
【質問】PDFをWordやExcelの文書に変換できますか? また、具体的にはどのような方法がありますか?
PDFファイルをWordやExcelなどのオフィスファイルに変換して、他の人からもらったPDFや、自分や会社の同僚が昔作ったPDFの文章や画像を利用し、編集を加えたり、あるいは自分の作る文書への取り込みができます。その方法と注意事項を整理してみました。
PDFは日本語の扱えない海外のパソコンや携帯端末でも日本語が表示できるなど、環境に依存しない電子文書を実現できます。そこで使われている鍵となる技術がフォントの埋め込みです。コンピューター上で電子文書を実現するために文字コードやフォントの技術は欠かせないものです。私たちが日ごろ当たり前のように接している文字が、コンピューター上でどのように扱われているのかを知ることは、PDFのメリットのひとつであるフォント埋込機能の理解にもつながります。ここでは、千年後でも読める電子文書の実現の肝となるフォント埋込技術についてわかりやすくご紹介します。
【質問】PDFへコメントを記入できますか? 文字を追記できますか?
PDFには注釈(Annotation)という機能があります。注釈はコメントや図形、校正記号などのマークアップをあとからPDFに付加する用途で使うものです。PDFの注釈には用途別に様々な種類があります。注釈の概要やPDFへの文字の追記(コメントの追加)で注意すべき点をまとめてみました。
【質問】PDFを作成する仕組みを知りたいので、わかりやすく教えてください
PDFの作成方法は、アドビシステムズ、サード・パーティ製品を含めて非常に多岐に渡っています。ここでは、それらを技術的な仕組みという観点でまとめてみました。この文書は、「PDF千夜一夜」からPDFの作成関連の話題をピックアップして整理したものです。説明不足や誤りはできる限り加筆訂正に努めましたが、内容を保証するものではございません。
【質問】オフィス文書やPDFをWebブラウザだけで作成するサービスがありますが、詳しく教えてください。
PDFもクラウドが主戦場、新たな戦国時代の始まりです!! PDFという切り口から関連する様々なWebサービスをご紹介します。
【質問】PDFの記入用紙に書き込む良い方法はないでしょうか?
他の人から受け取ったりWebからダウンロードしたPDFを、紙に印刷するのではなく、画面上でそのまま文字や図形を記入したいと思った方は多いのではないでしょうか。Yahoo!知恵袋などの質問サイトにも「PDFに記入したいがどうしたら良いか」といった質問が多数見受けられますが、注釈での記入など長期保存や印刷用に不向きな方法が多く紹介されています。ここでは、既存の記入方法の問題点を整理し、それらとは違う弊社製品『瞬簡PDF 書けまっせ』の手法についてご紹介します。『瞬簡PDF 書けまっせ』を使うとPDF用紙に超簡単な手順で記入ができます。PDF用紙への記入に特化した各種機能は、業務用途での高度な記入作業も強力にサポートします。

2011年にUSアンテナハウスのサポートチームはAntenna House Formatter のリリース時の社内テスト用に自動のリグレッションテストシステムの開発をスタートしました。当時はおよそ1,000程の文書(10,000ページ以上)を使ってテストを行っていましたが、数人で作業して2,3日は掛かりました。スクリーン上の目視で、正しいPDF表示との見比べを左右並べて行っていたからです。
リグレッションテストは開発やリリースの過程で重要なステップですが、時間と人手間が掛かり、目視によるためそれほど正確ではありませんでした。
リグレッションテストのプロセス自動化を行うに当たって、次の様な課題が持ち上がりました。
こういった要求を満たすツールを探したがなかなか見つからなかったので、独自のソリューションの開発を始めたわけです。六か月ほどして、サポートチームはPDFをビットマップに変換しページをピクセルで比較するシステムを開発しました。この初版のツールを使っていままで何日もかかっていたテストが一日でできるようになりました。次のワークフローはこのシステムの詳細な過程を示しています。このシステムを使って、PDF単体の比較や、PDFを格納してあるディレクトリ単位でもテストが可能となりました。

レポートは実際にはAntenna House Formatterで生成され、3つのパネルに配置されます。

左のパネルはベースラインから抽出したオリジナルのPDFで、右のパネルは新しい文書から抽出したPDFです。AH Formatterの機能を使って個々のページをPDFから選択して一つのPDFにマージすることも可能です。真ん中のパネルは2つのページの差異をハイライトで示したビットマップの合成です。オリジナルと新規の文書でどんな種類の違いが生じたのか特定できるよう、その差異を色別に示しています。違いを含んだページのみをレポートに含むことが重要と考え、その方針で、もし500ページ中4ページだけ差異がある場合、その4ページのみを見るだけで済むようになっています。
その後更に開発を続けパーフォーマンスは飛躍的に改良されました。ユーザーフレンドリーなGUIを立ち上げインストーラを作成し、5分以内でソフトウェアをインストールが可能になりました。また、Windowsに加えて、Linux Macにも対応しました。
現在では、このシステムを使って2時間以内でテストを終えることができ、どんな差異も見つけることができると自負しています。弊社のFormatterの定期リリースや、改訂リリースがテストのために遅延するということはなくなりました。また、この上質なテストを行うことで、品質がかなり良くなっていることが判明しました。
リグレッションテストシステムは現在Antenna Houseの商品として販売しています。詳しい情報についてはこちらをご参照ください。
http://www.antennahouse.com/antenna-house-regression-testing-system/

先日、学術情報XML推進協議会さん主催のセミナーにお招きいただき、「XML自動組版を実践する」というテーマで2時間近くお話させていただく機会がありました。いつもは30分とかせいぜい1時間くらいお話しさせていただくことが多いのですが、2時間というのは相当長い時間をいただいたことになります。
ご参加者者は35名くらいだったでしょうか。お申し込みはもっとあったようですが、会場のキャパの関係で途中で受付を打ち切られたそうです。そういうお話を聞かされたらこちらも気合が入ります(笑)。
まずXMLの一般的な話題から入って、それをPDFにするための手段について話を進めます。

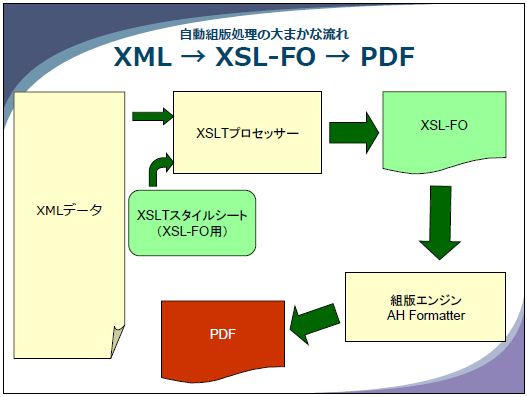
そしてXSL-FOの概要説明を経て、XSLTスタイルシートの説明。

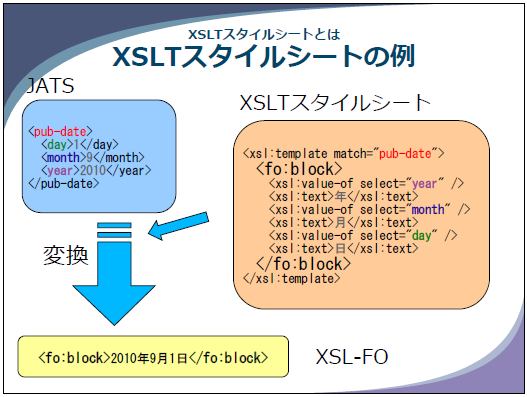
XSLTスタイルシートの例
最後に、どうやってJATSを入力するのか、ということで今回はoXygenを使って実際に入力するところをご覧いただきました。
昨年も、学術情報XML推進協議会さんにはセミナーにお招きいただき、そのときは主にHTMLに変換するためのXSLTスタイルシートの作り方のお話をさせていただいています。
JATSに限らず、もしXMLの自動組版について話が聞きたいという方がいらっしゃいましたら、いつでもご連絡ください。お待ちしております。
前回、PDFのデバイスカラースペースの3種類について説明しました。これらはその名前にある通りデバイスに依存したカラーの表現方法でした。そのため同じRGB値、あるいはCMYK値でも、デバイスが異なると違って見えることになります。同じ写真を2つの違うプリンタで印刷したり、同じ番組を違うテレビで見たり、といった身近なところでも経験することが多いかと思います。PDFの場合にあてはめれば、何か文書を作成してPDF化し、他の人にそのPDFを送って参照してもらうような場合に、作成した人が見ている画面と、送った先の人が見ている画面(あるいは印刷した紙)では別の色が表示されている、という現象になります。
このあたりを解決する、つまり異なるデバイス間で、同じカラー指定に対して同じ出力を行うことを目的としたカラースペースがCIEベースのカラースペースとなります。同じ出力といっても、当然ながら「そのデバイスの制限範囲内で」という制限がつきます。ディスプレイにしてもプリンタにしても、デバイスによって可能な色の再現範囲は異なりますので、その中で、指定に近い出力を得る(カラー値やカラースペースをどう調整しても、モノクロプリンタでカラー写真を印刷はできませんし)ことが目標となります。
前回記載したPDFで定義されている CIEベースカラースペース として、CalGray、CalRGB、Labおよび ICCBased の4種類を記載しました。これらのカラースペースの内容、指定されたカラー値を再現する方法の説明となるわけですが、PDFの仕様以前に、色とは何か、という非常にやっかいな説明が必要となってしまいます。わかる範囲で少し説明を試みてみたいと思います(デバイスカラースペースは、光の3原色、あるいは、プリンタのインクというような身近なところから、なんとなく理解できそうなので、色とは、などという説明抜きでなんとなく説明できましたが)。
おおざっぱにいえば、なんらかの光源から発した光が、物体にあたって反射し、人間の目に入り、人間がその物体の色として認識する、ということになります。赤いクルマといっても、太陽光の下で見る場合と、トンネル中の証明で見る場合と違うのは光源の発する光の性質が異なっていることによります。この光ですが、波としての性質を持つ、空中を伝わる振動エネルギーの束と考えることができるようです。波の性質として波長がありますが、高エネルギーの光の波長は短く(たとえば、X線では 1nm)、低エネルギーの光の波長は長く(ラジオの中波は100m~1km)なります。人間の目がとらえることができる可視光の波長は380nm~700nmのきわめて狭い領域ですが、この短波長側の光を紫、長波長側の光を赤として認識します。その外側がそれぞれ紫外線、赤外線と呼んだりします。また、虹などでは紫から赤までを適当に区切って7色と数えたりします。太陽光のような実際の光はいろいろな波長が混在した光です。可視光内で、緑の波長(国際照明委員会の規定では546.1nmだそうです)が多く含まれていれば緑、各波長の光が均等に含まれていると白と認識します。
ちょっと先走って、人間が赤とか紫とか認識すると書きましたが、人の目に入ってきた光は角膜、水晶体を通過して網膜にあたります。網膜上には光に反応する受容体として桿体、錐体というものが存在します。この錐体に可視光内の長波長(赤)に反応するもの、中波長(緑)に反応するもの、短波長(青)に反応するものがあり、それぞれの錐体がどのくらい反応するかで光の色を認識することになります。
色の話になってしまって、PDFのCIEベースカラースペースの話まで進めませんでした。こういう色というものをコンピュータ上でどう表現するか、さらにPDFではどう表現するか、また続きを記載したいと思います。
これまで、PDFの関連仕様としてPDF/X,PDF/A などについて説明してきました。これらの各仕様の中には「カラーの再現性を保証」するために、PDFがサポートする各種カラースペースに対して制限を設けているものがありました。たとえば、PDF/X-1およびPDF/X-1aでは、使用できるカラースペースをCMYK(およびグレースケール)に限定しています。今回からPDFで使用できる色について、説明してみたいと思います。
PDFの作成者側では、PDF内の各種オブジェクトに対して色を指定し、PDFの表示・印刷などの使用者側では、指定された色を解釈し、対象のデバイスで使用可能な機能を用いて指定された色を再現することになります。PDFの色指定には様々な方法が用意されています。表示する特定のデバイスに依存しない方法で色を指定することもできます。
PDF内で、各カラースペースを混在して指定することができます。たとえば黒でABCと3文字表示されていても「A」はDeviceGrayの0、「B」はDeviceRGBの(0,0,0)、「C」はDeviceCMYKの(1,1,1,0)という場合もあり得ます。(PDF/XやPDF/Aではこのあたりの混在使用を禁止しています)
次回、CIEベースカラースペースについて説明したいと思います。
今回は PDF/Aの作成方法(準拠レベルA) でAcrobat/Wordが出力したPDF/A-1aの内容、主にタグ部分について少し見てみたいと思います。
レベルAではレベルBが持たない情報である文書の論理構造、言語などの情報を持つ必要がありました。PDFでは、文書の論理構造を表現するためにタグと呼ばれる仕組みを用意しています。
このあたりをつかって元文書がどのように表現されているか、Wordで簡単なサンプル文書を作成して、PDF/A-1aに変換したものを見てみます。

Word文書
章、節、項の部分はWordの組み込みスタイルである「見出し1」~「見出し3」を使用し、
リスト番号を付加したものです。他に、箇条書き、表、画像 などを入れてみました。
Acrobat XIでは 「表示メニュー」の「表示切り替え」-「ナビゲーションパネル」-「タグ」とすることで、ドキュメント内につけられているタグの様子を見ることができます。左側にタグが階層表示され、ここをクリックすると本文内の対応する箇所がハイライト表示されます。
Word 2013で「PDF/A」および「アクセシビリティ用のドキュメント構造タグ」を指定して作成したPDFの場合
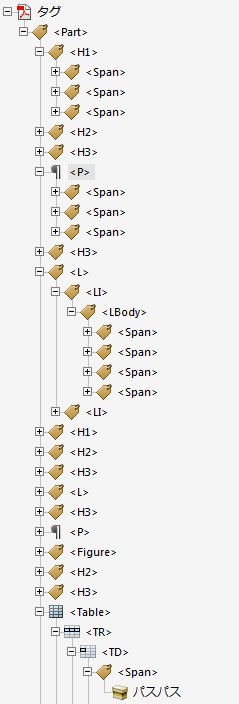
このように表示されます。
一方、Word 2013から Acrobat XIのWord用PDFMakerでPDF/A-1aを指定して作成したPDFの場合
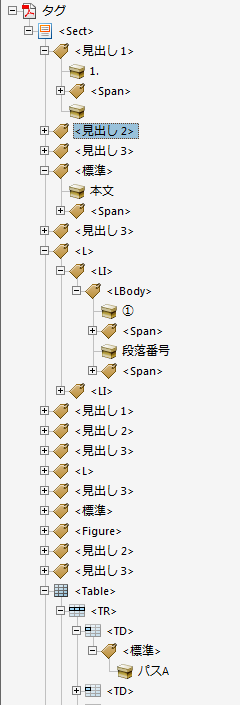
となりました。
主なところだけ展開したキャプチャです。似たような構造ですが、タグの名前をはじめとして、細部では若干タグのつけ方も異なっていることがわかります。
PDFMakerでは「見出し1」など、Wordのスタイル名をそのままタグ名に使用しています。これら独自のタグ名をPDF仕様が用意している標準的なタグ名に割り当てる「ロールマップ」という仕組みがPDFに用意されていて、Acrobatでも表示させることができます。

これを参照すると、スタイル名の「見出し1」を標準タグの「H1」に対応づけていることがわかります。
このような形でタグを使用して元文書の論理構造をPDFで表現します。
また、比較のために、Wordの「見出し1」などのスタイルを使わずに、表示だけ似たような形の文書を作成してPDF/A-1a出力してみます。

ここの 章番号 1. 、1.1.1 などはWordのリスト番号ではなく、通常のテキスト入力したものです。
PDF/A-1aに変換した結果のタグを見てみます。

これはWordのPDF保存の場合ですが、このように、こちらでは文書構造を取得するヒントとなるものが存在しないため、単純に〈P〉タグだけで出力されていることがわかります。
以上、簡単なタグ付け内容の参照方法となります。
先日、JR東海から2027年度に開業が予定されるリニア新幹線の概要が発表されました。多くのメディアで取り上げられましたので興味を持って見られた方も多かったのではないでしょうか?
弊社の伊那支店がある長野県南部にもリニア新幹線の新駅ができる計画で、地元紙でも大々的に記事が掲載されました。これまで夢としてしか語られなかったことがにわかに現実味を帯びてきたことで、谷あいののどかな地方にこれからどのような風が吹きこむのか、住人としても目が離せない気がします。
閑話休題。
昨年の7月頃に『OCRのよもやま話』という記事を書きました。
今回はその続きということで、OCRにまつわる話題をいくつか追加したいと思います。
OCRと解像度
OCRとは、Optical Character Recognition(あるいはReader)の略で、紙に印刷された文字をイメージスキャナなどで読み取り、画像化された情報から文字情報を抽出する技術であることを以前の記事でご紹介しました。
OCRで文字を正確に取り出すために必要な要素を考えると、おおよそ以下の点が挙げられると思います。
このうち、2)の「解像度」について取り上げます。
OCRで使う解像度はスキャナなどで取り込む画像の品質を表すもので、dpi(ディーピーアイ)という単位を使います。これは、1インチ(2.54cm)の間隔にどれだけ物理的な点(画素)が配置されているかを示すもので、同じ大きさの画像で比べた場合は、解像度の値が大きいほど高精細な画像が得られます。
解像度は別の言い方をすると、1インチあたりの画素の密度を表すということができます。密度が濃ければそれだけ細かい描写が可能になります。以下はそれを模式図にしたものですが、文字のサンプルにあるように解像度が小さいと曲線などで滑らかな表現ができなくなります。
解像度
では、実際に異なる解像度でスキャナから取り込んで比較してみましょう。
以下は、スキャナの設定でそれぞれ 200dpi/400dpi に解像度を変更してJPEG形式に保存したデータの一部を示しています。

解像度の違い
ちょっと分かりづらいかも知れませんが、ブラウザの表示倍率をあげて見ていただくと両者の違いが分かります。
以下は、この二つの画像を弊社のOCR変換製品『瞬簡PDF OCR』でテキストファイルに変換した結果です。

変換結果
解像度が200dpiだと文字化けしてしまう箇所が、400dpiでは(完全ではないですが)おおむね正しく認識できていることが確認できます。
そうすると、もっと解像度を高くしてスキャンすれば更に良い結果が出せそうに思えます。ところが、これがさにあらず、なのです。
以下は、スキャナの設定を600dpiにして変換を行った結果です。
600dpiで変換
解像度を上げても、あまり変換結果に影響がないことが確認できるかと思います。
一般にOCR処理では、300~400dpiの範囲が適切なOCR結果を得る解像度だと言われています。それ以上解像度を上げてもファイルサイズが大きくなるばかりで、OCRの変換精度はあまり変わらないか、逆に悪くなってしまう場合もあります。ちなみに今回使用したJPEGデータの場合、400dpiのときのファイルサイズは約1.4MBですが、600dpiでは約2.7MBでした。
OCR処理を使って文字の取り出しを行う際には、スキャンの段階から適切な解像度を設定していただくことでより良い結果が得られます。ご参考にしていただければ幸いです。
※『瞬簡PDF 変換8』、『瞬簡PDF OCR』は製品の体験版を公開しております。是非、お試しください。
PDF/UAの紹介の最後になります。
ここまで、ファイルフォーマットの要件、リーダの要件を記載しましたが、最後はAT(Assistive Technology:支援技術)の要件になります。
このATにはPDF/UAを使用するスクリーンリーダや、音声入力をサポートするデバイス、キーボード入力を容易にする装置、点字に変換して印刷するソフトウェアなど広範なソフトウェア、ハードウェアが含まれます。
ATに求めら得る要件とは、大きくは下記となります。
PageLabelとは、たとえば、目次部分は小文字のアラビア数字、本文はローマ数字といったページ番号を持つ文書がありますが、PDFでそのような表現をする機能です。ナビゲーションに、このPageLabelや、文書の章・項といった論理構造の階層情報を使用する機能が必要とされます。
ATの要件については、あまり詳細なことは定められていません。
以上、PDF/UAの紹介となりますが、フォーマットの要件部分で、関連仕様に W3Cの Web Content Accessibility Guidelines(WCAG) 2.0 があることを記載しました。
これまで説明したPDF/UAファイルの作成、使用の双方に必要とされる要件は、PDFファイルをW3Cの勧告であるWCAGに沿って利用するために必要とされるPDFの機能の使用方法となります。
PDF/UAの理解には、WCAG 2.0 (およびその関連ドキュメント)で解説される内容を理解する必要があります。
WCAGのW3Cの勧告は下記にありますので、興味のある方は参照ください。
http://www.w3.org/TR/2008/REC-WCAG20-20081211/
(日本語訳)
http://www.jsa.or.jp/stdz/instac/commitee-acc/W3C-WCAG/WCAG20/
