
Antenna House PDF Viewer SDKはPDF表示のためのSDKですが、表示以外にも PDFファイル内のテキストを抽出することができます。今回はこの機能をご紹介したいと思います。
テキスト抽出に利用するのはSDKの PDFViewerAPI です。
開発言語は C/C++ が利用できます。
矩形内テキスト取得(getTextInRect)
ページとそのページの矩形を指定してテキストを抽出します。
例)矩形 (4535, 3798)-(7933, 4535) → テキスト “UVWXYZ”
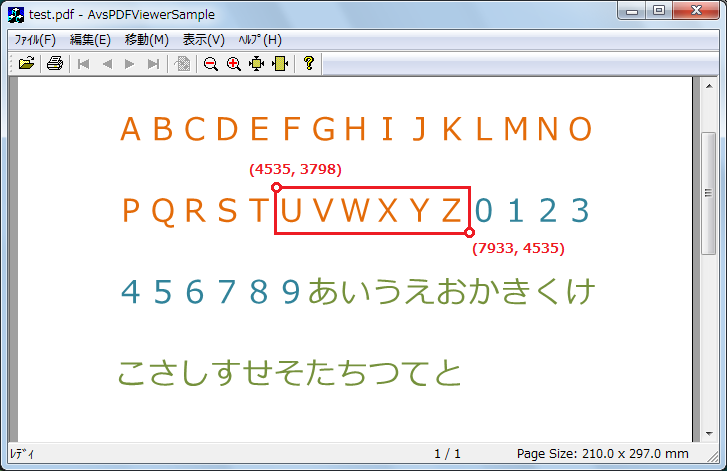
座標系は、原点は左上、x軸は右方向、y軸は下方向に増加します。
長さの単位はTWIPで1/20ポイント、1/1440インチに相当します。
TWIP は「Twentieth of an Inch Point」の略だそうです。
1インチは 25.4mm ですので、
1 mm = 1440/25.4 TWIP ≒ 56.69 TWIP の計算になります。
例1 の矩形は、mm 単位では (80.0, 67.0) – (141.0, 80.0) になります。
文字単位でのテキストおよび座標の抽出(getPageTextString/getPageTextRegion)
ページと、そのページ内での文字の開始位置と終了位置を指定して、テキスト(getPageTextString)もしくはテキスト領域(getPageTextRegion)を取得します。
- 例)開始位置 20、終了位置 26 → テキスト “UVWXYZ”
- 例)開始位置 0、終了位置 1 → テキスト “A”
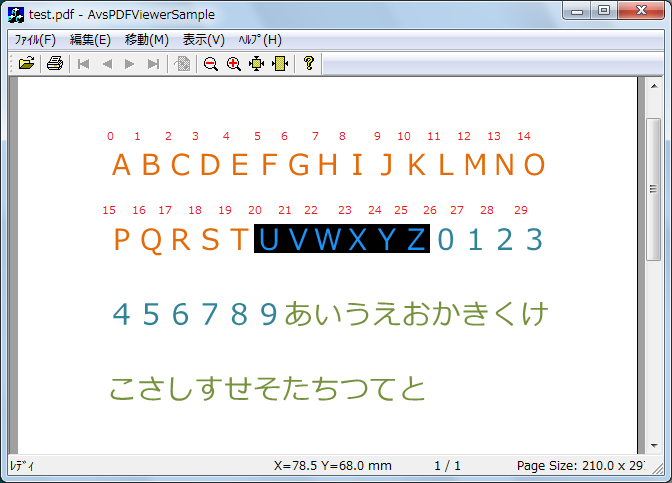
文字単位でのテキストおよび座標の抽出
(getPageTextString/getPageTextRegion)
(開始位置, 終了位置)=(0, 1), (1, 2)のように進めることで、PDF内の文字との文字領域を順に取得することもできます。
なお、テキストの順序は PDFのページに文字コードが現れる順になります。
PDFによっては必ずしも見た目の順と一致しない場合がありますので、注意が必要です。
以上、PDF表示以外での利用方法のご紹介でした。
評価版のお申し込み:
https://www.antenna.co.jp/oem/ViewerSDK/trial.html
お問い合わせ:
SDKはOEM販売となります。OEMご相談窓口へお問い合わせください。

Office Server Document Converter
サーバーサイドでダイレクト文書変換!

Formatter
XML文書組版の最高峰!


