日本語の文章を英語に翻訳するためにツールとして、機械翻訳がかなりいいレベルまで来ているのは周知のとおりです。では、HTMLでタグ付けされたWebページの翻訳にも機械翻訳を使えるでしょうか?
HTMLファイル機械翻訳の課題
日本語HTMLファイルは大きくわけるとテキストコンテンツと画像やマークアップ(タグなど)から構成されます。
タグにはいろいろな種類があります[注1]。メタ情報を表すタグ、見出し、段落、箇条書き、表などのブロックの区別を表すタグ、強調、アンダーライン、上付き・下付きなどテキストの意味合いを表すインラインタグ、リンクや画像を埋め込むタグ、などです。
WebページのレイアウトはCSSで指定します。このため多くのタグに、CSSによるレイアウトを制御するための属性が付加されます。また、HTMLファイル内にはブラウザで表示する際のダイナミックな動作を表現するためにJavaScriptが埋め込まれます。このためHTMLファイルは、コンテントのテキストと比べてかなり複雑になり、通常はマークアップ作業に多大な時間がかかります。
機械翻訳のシステムでHTMLファイルを日本語から英語に翻訳するとき、(1)テキストコンテンツの翻訳の品質に関わる課題と、(2)タグの扱いが適切かどうかという課題があります。
タグの扱いについての要件
ここでは、主にタグの取り扱いを考えてみます。まず、タグの扱いは基本的には次の条件を満たす必要があります。
1.タグ自体は翻訳せず、タグのツリー構造は保持されなければならない。つまりタグの順序が変更されないこと。開始タグと終了タグの対が保持されること。タグの親子関係(入れ子関係)が崩れないことなどが満たされること。
2.開始タグには属性と属性値が付随することがあります。属性は翻訳せず、属性値は多くの場合、翻訳しない方が望ましいが、翻訳してほしいこともある。
日本語のHTMLファイルを機械翻訳した結果、タグのツリー構造が壊れてしまったり、マークアップが不適切になってしまうと、機械翻訳の出力として得られたHTMLファイルのタグ付けを修正する作業が必要になります。もし、タグの構造が完全に破壊されてしまうと、プレーンテキストにゼロからタグ付け作業をする方が手間が少ないということになります。
特に、インラインタグは翻訳テキスト中に混在するのでタグのツリー構造を維持するのが難しい場合がありそうです。そこで機械翻訳システムがテキストコンテントとタグを分離してうまく扱えるかどうかは詳しく調べてみる必要があります。
機械翻訳のHTMLファイル形式サポート
機械翻訳システムによってはタグでマークアップしたテキストを翻訳対象にできないことがあります。ここで使用するDeepLは、Free版ではHTML形式ファイルを扱えません。一方、Pro版とAPI版がHTMLファイル形式を翻訳対象としてサポートしています。
・Which file formats can I translate?
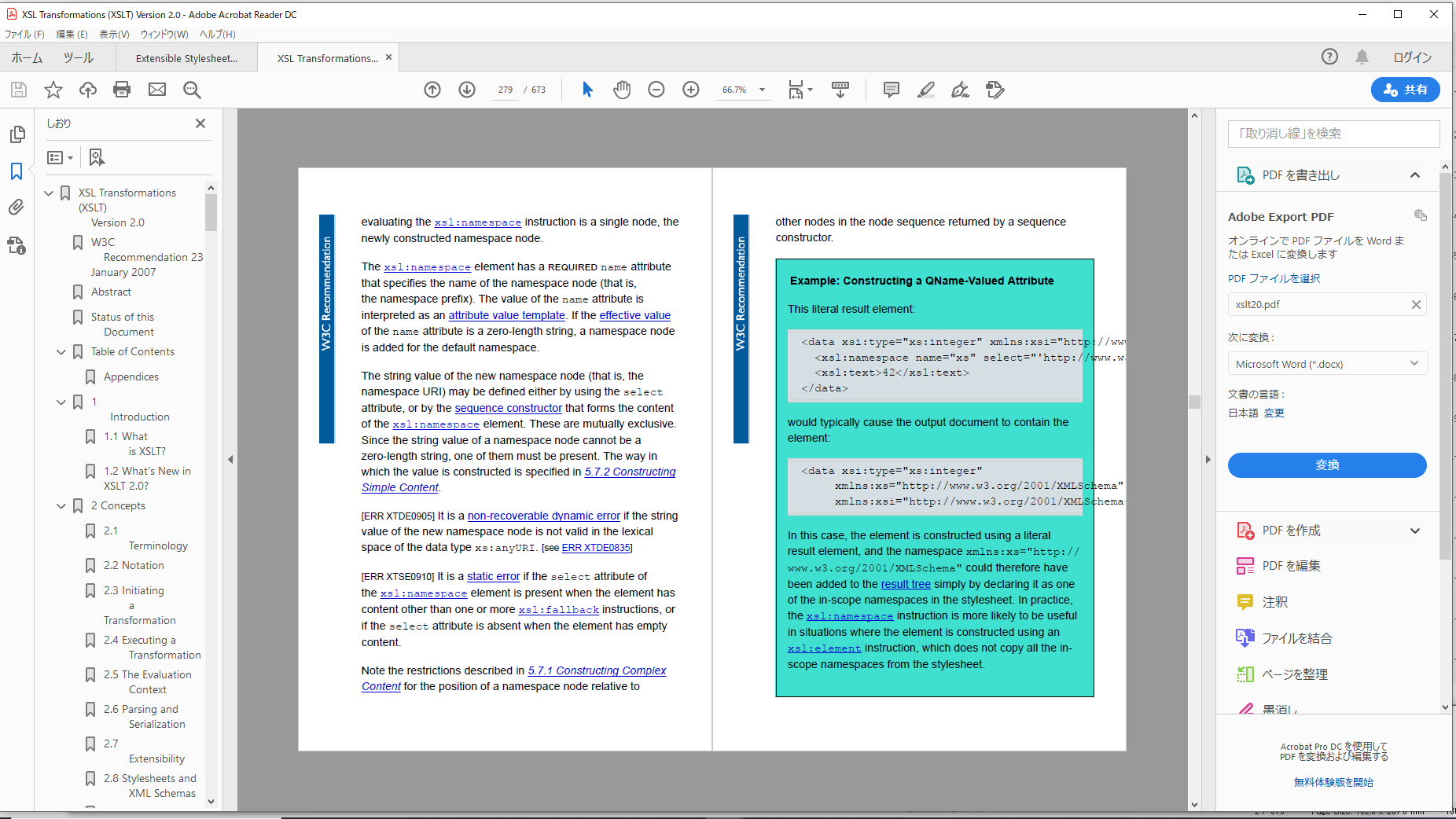
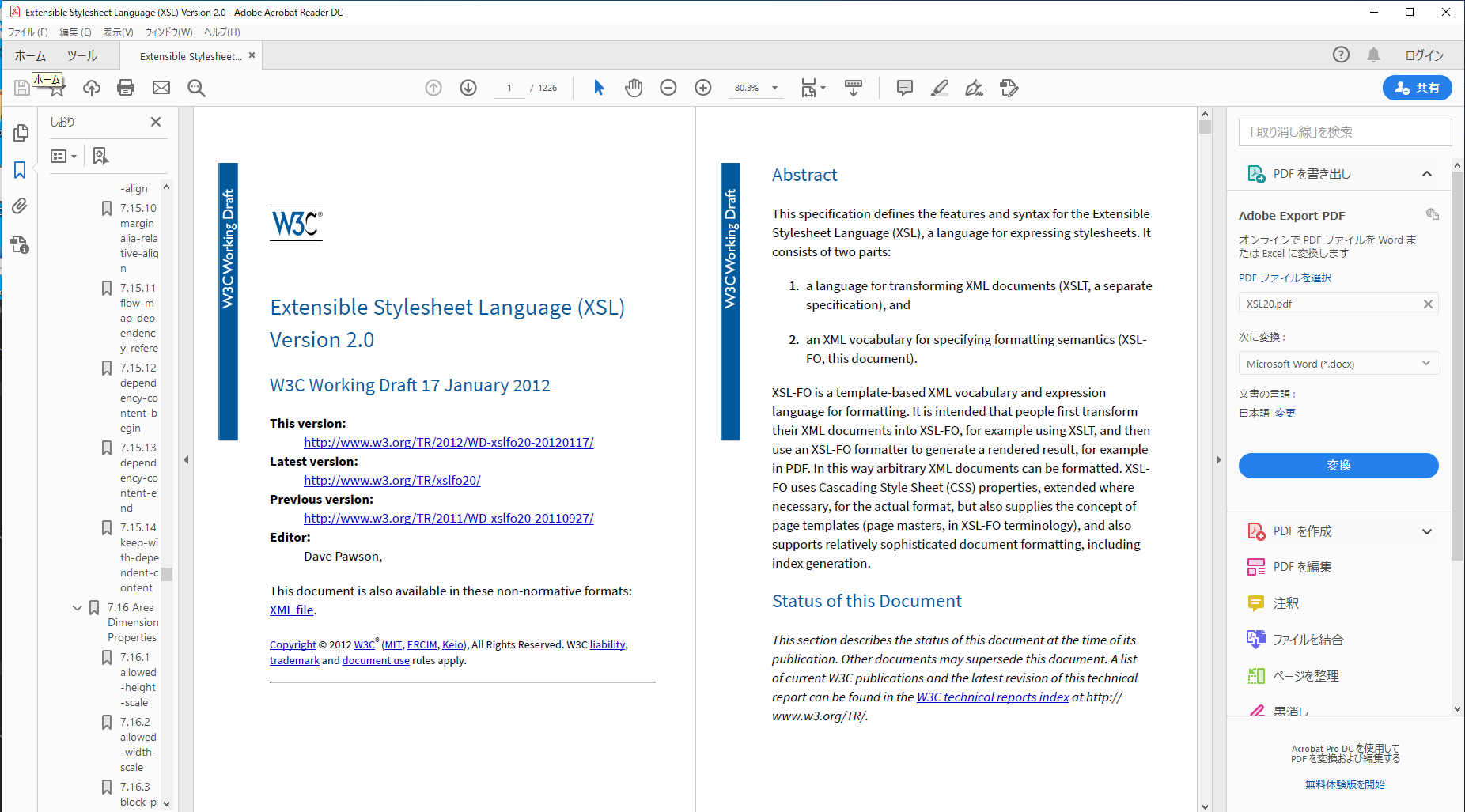
DeepLによる日本語HTMLファイルの英語への翻訳例
そこで、今回、DeepLでHTMLを翻訳したときタグが正しく扱われるかを調べてみました。翻訳の対象としたのは、Formatter V7.4(開発中)の日本語HTMLマニュアル(XSL/CSS拡張)です。
Formatterのマニュアルは、日本語と英語版のWebヘルプとして作成されています。V7.3(現行バージョン)についてはこちらからご覧いただけます。現在、翻訳は社内の専門スタッフが行っており、機械翻訳は使っていません。
・Antenna House Formatter V7 日本語版マニュアル
・Antenna House Formatter V7 日本語版マニュアル・XSL/CSS拡張
・Antenna House Formatter V7 英語版マニュアル
・Antenna House Formatter V7 英語版マニュアル・XSL/CSS Extensions
DeepL翻訳結果・第一印象
日本語のHTMLをDeepLで英語に翻訳翻訳した結果はいちおうHTMLなのでブラウザで表示できます。最初に、翻訳元の日本語HTMLファイルと、DeepLで翻訳した英語HTMLファイルのブラウザ表示を比較してみます。
1)目次部分
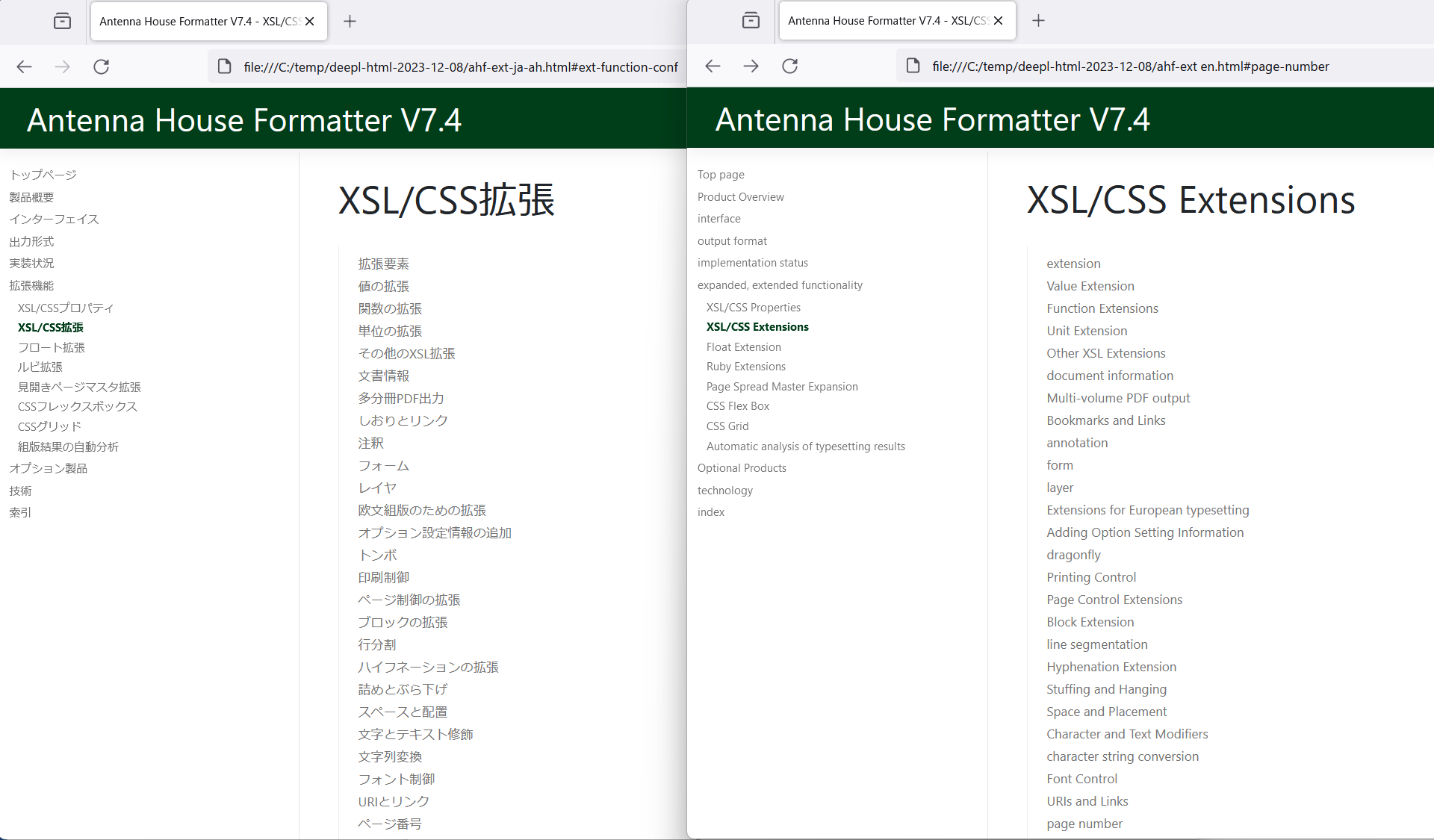
翻訳元日本語目次(左)、翻訳結果の目次(右)
2)見出し、本文や表
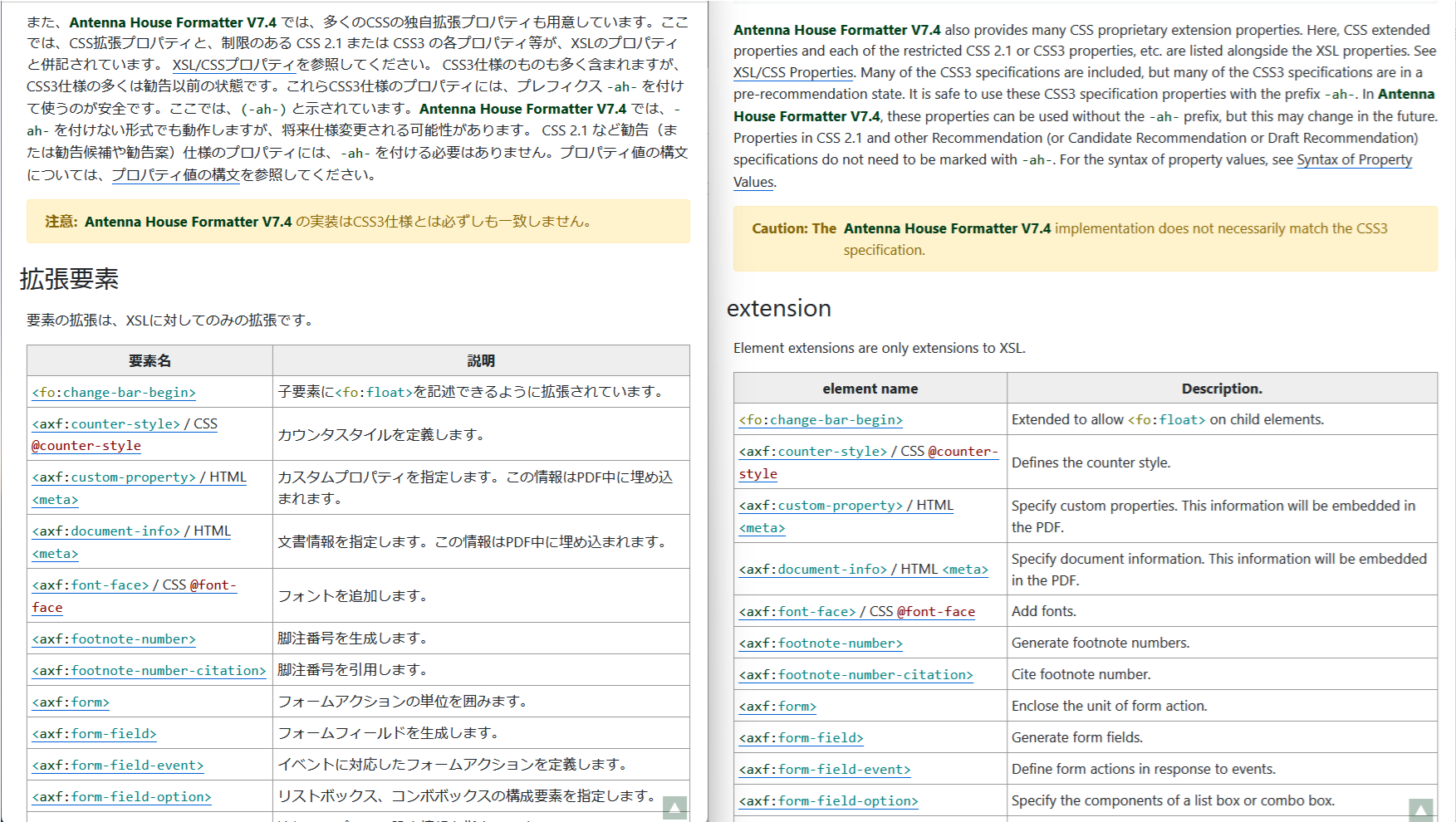
見出し、本文(太字)、リンク、表
3)表と箇条書き
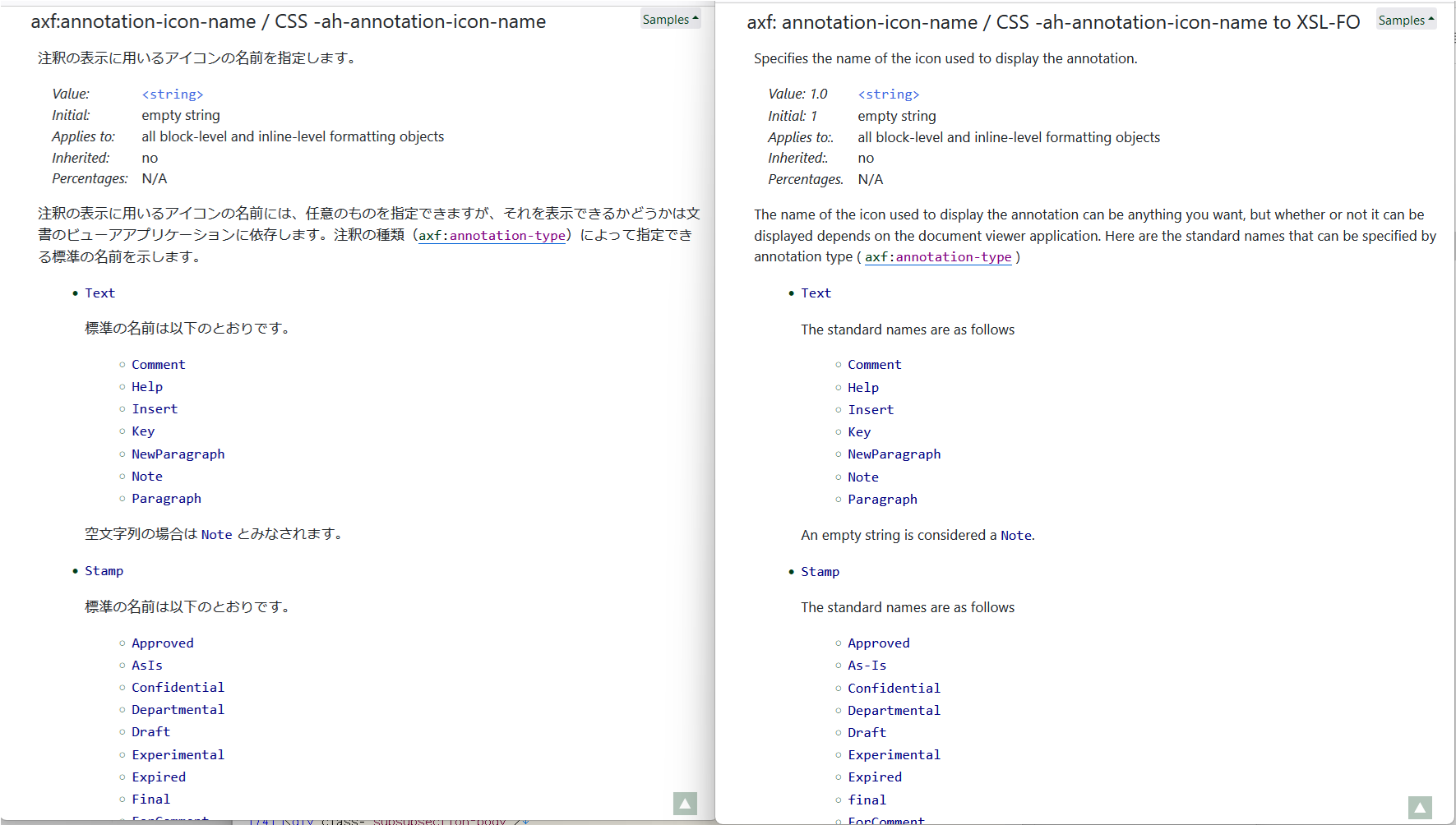
表と箇条書き
こうしてみますと、ブラウザで表示して比較できるレベルでタグが付いているようです。ただし、ブラウザはHTMLファイルのタグが正しくなくても表示できるように作られているので、ブラウザで表示できるからと言って、タグが完全に適切に付けられているとは言い切れません。
また、翻訳された内容を詳しく見ると、細かい点に問題が見つかります。
では、HTMLタグがどの程度まで適切に設定されているでしょうか? これを確認するにはHTMLファイルのタグを詳細にチェックする作業が必要になります。そこで、次回は、DeepLのHTML翻訳結果のタグ付けについて詳細に検討してみることにします。
[注1]
HTMLのタグの種類やタグ付けの規則については次の標準仕様で規定されています。
HTML Living Standard