
5月18日に『AH XSL Formatter拡張仕様使いこなしガイド』が公開・発売したことは
当日の記事で述べました。
『Antenna House XSL Formatter 拡張仕様使いこなしガイド』を公開・発売しました I Love Software2!
『XSL-FO 試行錯誤』連載ではこれまで密かに「AH XSL Formatterの拡張仕様はメインの対象にしない」という縛りでやってきたのですが、めでたく書籍が公開されましたので、これからは拡張仕様についても対象にしていきます。『AH XSL Formatter 拡張仕様使いこなしガイド』に載せられなかった話題について扱うかもしれません。たとえばAH XSL FormatterではCSS3にあるような装飾表現が可能であったりするのですが「CSS3を紹介したWebサイトを見れば良いのでは」となってボツにしたものがそこそこあります。
制作のXSL-FO以外の面についての話についても折を見て記事などで展開する予定です。気になった点などがあればコメントやSNSなどで言及していただければ反映できるかもしれません。
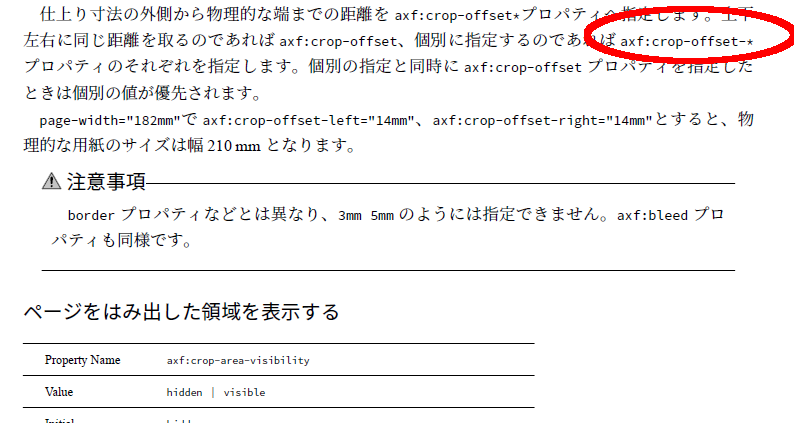
最初からハイフンのある語の制御
ということで、本記事の話題は見出しの通り。どういったものがあるかというと、コマンドラインのオプション引数(-optionとかですね)、XSL-FOの要素、プロパティ名など(border-top-styleなど)ですね。
そもそもこれらは行分割位置に来ないようにするのがおそらく理想的ですが、ページ数の制約などで妥協することもあるかもしれません。
もとからハイフンがある語は分割によるハイフンを追加しない
<fo:block ...
hyphenate="true"
axf:hyphenate-hyphenated-words="false">...
</fo:block>サンプルFOのページのサンプルでもよく使われています。プロパティ名など、もともとハイフンを含む語にハイフンが追加されてしまうと、元からあったハイフンなのか、分割時に追加されたハイフンなのか分からなくなってしまうかもしれませんからね。
他の回避手段としては、ハイフネーションとして追加される記号を変更するという方法も考えられます。
ハイフンを含む特定の文字列を、分割可能でないハイフンに置き換える
(XSL-FOの標準仕様として、「行分割でハイフンが追加され得る単語で、分割前後の文字数によって分割位置を調整する」ことができるhyphenation-remain-character-count、hyphenation-push-character-countがあります。)
さて、元からハイフン(-)を含む語があり、初期設定でこのハイフンの後では分割可能であるとします。しかし、この文字の後が1字のみのとき(「UTF-8」など)のとき、「8」だけ次の行にいくのはあまり望ましくないですね。
「分割しないハイフン(NON BREAKING HYPHEN)」(U+2011)という文字があります。この文字でハイフンを置き換えてあげれば、ハイフンの前後で行分割は通常起こりません。
では、すべてのハイフンを置換しますか? それはそれで文字数の調整が狂ってしまいかねません。
また、元のファイルが500ファイル以上になっていたので、時間的に個別に置換するのはちょっと困難だとします。
今回は「特定の文字の組み合わせ(-*)でのみ、1字の次行送りが発生する」ことが分かっていたので、axf:text-replaceを使うことにしました。
axf:text-replace / CSS (-ah-)text-replace AH Formatter マニュアル
<xsl:attribute-set name="code">
<xsl:attribute name="axf:text-replace" select="'-∗' '‑∗'"/>
</xsl:attribute-set>
指定に確認していない漏れがなければ上手く行っているはず。
この成果(書籍全体で適用されているか)は『AH XSL Formatter 拡張仕様使いこなしガイド』で確認してください!
(XMLファイルを処理するときにXSLTは経由したわけで、XSLT 2.0の正規表現などによる置換なども可能ですが、その辺りをあまり変更したくない、変更できない場合、ありますよね?)
 『AH XSL Formatter 拡張仕様使いこなしガイド』
『AH XSL Formatter 拡張仕様使いこなしガイド』
XSL-FO試行錯誤記事


PDF Driver
印刷からPDFを生成。PDF 変換ドライバー!

PDF Viewer SDK
PDF表示と編集ライブラリ



UTF-8のハイフンで分割するのが好ましくないということですが、ではUTF-16なら分割しても良いのでしょうか?
コメントいただきありがとうございます。
> UTF-8のハイフンで分割するのが好ましくないということですが、
これは「本記事で書いた事例の場合」という但し書きを付ける必要があるでしょう。今回の事例では「UTF-16」に相当するような「文字列」「-」「2文字」で構成されるような語で分割されないようにする処理を行っていませんので、とくに分割の可否について判断を行っていません。