本日は、度々お問い合わせのある、Antenna House Formatterでの異体字の使用についてお話しします。
異体字とは
・同じ意味/発音を持っているが、異なる表記の字体の文字
・新字と旧字による違いや、手書きによる個人差から生じたものなどもある
・人名や屋号、地名に多く使われる
JISやUnicode仕様においては、基本的に異体字ごとに異なるコードを割り振るようなことは行っていません。(ただし例外もあります)
Unicodeでは異体字セレクタという名称でタグを付けることにより、先行する一文字と組み合わせて定義付けされた字体を選択する方法をとります。
2006年1月13日に漢字で異体字セレクタを使うための漢字字形データベース(Ideographic Variation Database)への登録手続きが定められ、2007年12月14日に最初の異体字コレクションとしてAdobe-Japan1が登録されました。
Antenna House Formatterはこの異体字に対応しています。
異体字選択機能を持っているCIDフォント(OpenTypeフォント)と組み合わせて使うことで、Antenna House Formatter から、PDFへの異体字出力が可能です。(PDF出力のみ、他の出力オプションは未対応)
Antenna House Formatter での使用方法
Antenna House Formatterで、これらを使うには次のようにします。
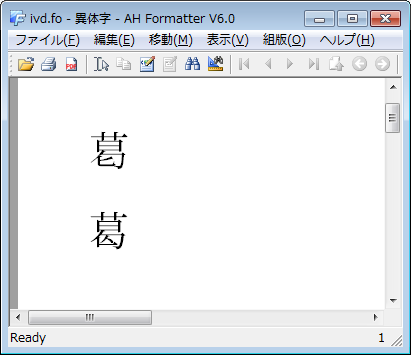
例えば、葛飾区と葛城市の「葛」には、二つの字形があります。
どちらの文字も、U+845Bという符号位置に統合されています。
異体字セレクタを使って、次のように区別することができます。
1. U+845B U+E0100
2. U+845B U+E0101
XSL-FOでは、次のように書きます。
<fo:block>葛󠄀</fo:block>
<fo:block>葛󠄁</fo:block>
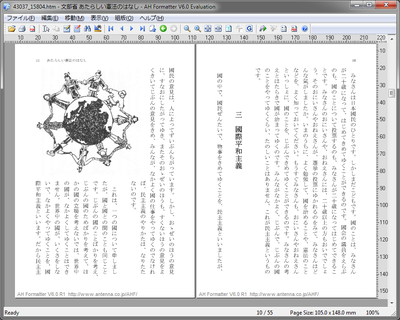
これを小塚明朝 Pr6N フォントを使用した場合、出力は次のようになります。
皆さんも試してみてください。
Antenna House Formatter での異体字の使用


瞬簡PDF 統合版 2024
アンテナハウスPDFソフトの統合製品!

瞬簡PDF 編集 2024
かんたん操作でPDFを自由自在に編集