Breaking Paragraphs into Lines は、Donald E. Knuth と Michael F. Plass の行分割に関する論文で、40年近く前のものです。ここで示されているアルゴリズムは、パラグラフ全体を Box/Glue/Penalty という要素(Paragraph Item)でモデル化して、行分割位置を決定するものです。処理の流れは次のようになります。
- アプリケーションが、文書から Paragraph Items を構築する。
- 分割可能位置に対して、そこで行分割したときの不具合度を示すデメリット値と呼ばれる値を計算する。
- もっともデメリット値の合計の少ない位置を選択し、行分割位置とする。
Paragraph Item の要素 Box/Glue/Penalty は、それぞれが幅を持っています。
- Box は常に幅が確保される。伸縮性はない。
- Glue も幅が確保されるが、そこで分割が起こったとき幅がなくなる。Glue には伸縮性がある。
- Penalty はその逆で、通常は幅が確保されないが、そこで分割が起こったとき前の行末にその幅が確保される。Penalty に伸縮性はない。また、行分割の起こり易さを調整するペナルティ値という値を持っており、分割不可では ∞ を、分割必須では −∞ を与えることになっている。 ハイフネーションは Penalty を利用して実現されている(通常の Penalty と区別するために Flagged Penalty と呼ばれる)。
次のような文書(論文に出てくるグリム童話)を例に、このアルゴリズムがどのように行分割位置を決定するのかをざっと見てみましょう。

これから次のような Paragraph Items が構築されます。
x は要素、t は要素の種別、w は要素の幅、y は伸ばせる幅、z は縮められる幅、p はペナルティ値を示しています。
| x0 |
empty box for indentation |
t0 |
= box |
w0 |
= 20 |
| x1 |
box for ‘In’ |
t1 |
= box |
w1 |
= 17.44 |
| x2 |
glue for space U+0020 |
t2 |
= glue |
w2 |
= 4.54 |
y2 |
= 5 |
z2 |
= 2 |
| x3 |
box for ‘old’ |
t3 |
= box |
w3 |
= 25.68 |
| x4 |
penalty for hyphenation |
t4 |
= flagged-penalty |
w4 |
= 7.12 |
p4 |
= 100 |
| x5 |
box for ‘en’ |
t5 |
= box |
w5 |
= 19.44 |
| x6 |
glue for space U+0020 |
t6 |
= glue |
w6 |
= 4.54 |
y6 |
= 5 |
z6 |
= 2 |
| x7 |
box for ‘times’ |
t7 |
= box |
w7 |
= 43.7 |
| x8 |
glue for space U+0020 |
t8 |
= glue |
w8 |
= 4.54 |
y8 |
= 5 |
z8 |
= 2 |
| x9 |
box for ‘when’ |
t9 |
= box |
w9 |
= 43.88 |
...... |
| x24 |
glue for space U+0020 |
t24 |
= glue |
w24 |
= 4.54 |
y24 |
= 5 |
z24 |
= 2 |
| x25 |
box for ‘lived’ |
t25 |
= box |
w25 |
= 38.54 |
| x26 |
glue for space U+0020 |
t26 |
= glue |
w26 |
= 4.54 |
y26 |
= 5 |
z26 |
= 2 |
| x27 |
box for ‘a’ |
t27 |
= box |
w27 |
= 8.78 |
| x28 |
glue for space U+0020 |
t28 |
= glue |
w28 |
= 4.54 |
y28 |
= 5 |
z28 |
= 2 |
| x29 |
box for ‘king’ |
t29 |
= box |
w29 |
= 35.5 |
| x30 |
glue for space U+0020 |
t30 |
= glue |
w30 |
= 4.54 |
y30 |
= 5 |
z30 |
= 2 |
| x31 |
box for ‘whose’ |
t31 |
= box |
w31 |
= 50.64 |
...... |
| x51 |
box for ‘young’ |
t51 |
= box |
w51 |
= 49.76 |
| x52 |
penalty for hyphenation |
t52 |
= flagged-penalty |
w52 |
= 7.12 |
p52 |
= 100 |
| x53 |
box for ‘est’ |
t53 |
= box |
w53 |
= 21.84 |
| x54 |
glue for space U+0020 |
t54 |
= glue |
w54 |
= 4.54 |
y54 |
= 5 |
z54 |
= 2 |
| x55 |
box for ‘was’ |
t55 |
= box |
w55 |
= 29.82 |
| x56 |
glue for space U+0020 |
t56 |
= glue |
w56 |
= 4.54 |
y56 |
= 5 |
z56 |
= 2 |
| x57 |
box for ‘so’ |
t57 |
= box |
w57 |
= 17.7 |
| x58 |
glue for space U+0020 |
t58 |
= glue |
w58 |
= 4.54 |
y58 |
= 5 |
z58 |
= 2 |
| x59 |
box for ‘beau’ |
t59 |
= box |
w59 |
= 38.36 |
| x60 |
penalty for hyphenation |
t60 |
= flagged-penalty |
w60 |
= 7.12 |
p60 |
= 100 |
| x61 |
box for ‘ti’ |
t61 |
= box |
w61 |
= 11.56 |
| x62 |
penalty for hyphenation |
t62 |
= flagged-penalty |
w62 |
= 7.12 |
p62 |
= 100 |
| x63 |
box for ‘ful’ |
t63 |
= box |
w63 |
= 21.82 |
...... |
| x143 |
box for ‘old’ |
t143 |
= box |
w143 |
= 25.68 |
| x144 |
glue for space U+0020 |
t144 |
= glue |
w144 |
= 4.54 |
y144 |
= 5 |
z144 |
= 2 |
| x145 |
box for ‘lime-‘ |
t145 |
= box |
w145 |
= 42.34 |
| x146 |
penalty for inter-word |
t146 |
= flagged-penalty |
w146 |
= 0 |
p146 |
= 100 |
| x147 |
box for ‘tree’ |
t147 |
= box |
w147 |
= 30.46 |
| x148 |
glue for space U+0020 |
t148 |
= glue |
w148 |
= 4.54 |
y148 |
= 5 |
z148 |
= 2 |
| x149 |
box for ‘in’ |
t149 |
= box |
w149 |
= 16.3 |
...... |
| x267 |
box for ‘her’ |
t267 |
= box |
w267 |
= 26.52 |
| x268 |
glue for space U+0020 |
t268 |
= glue |
w268 |
= 4.54 |
y268 |
= 5 |
z268 |
= 2 |
| x269 |
box for ‘fa’ |
t269 |
= box |
w269 |
= 14.7 |
| x270 |
penalty for hyphenation |
t270 |
= flagged-penalty |
w270 |
= 7.12 |
p270 |
= 100 |
| x271 |
box for ‘vor’ |
t271 |
= box |
w271 |
= 26.48 |
| x272 |
penalty for hyphenation |
t272 |
= flagged-penalty |
w272 |
= 7.12 |
p272 |
= 100 |
| x273 |
box for ‘ite’ |
t273 |
= box |
w273 |
= 19.6 |
| x274 |
glue for space U+0020 |
t274 |
= glue |
w274 |
= 4.54 |
y274 |
= 5 |
z274 |
= 2 |
| x275 |
box for ‘play’ |
t275 |
= box |
w275 |
= 33.42 |
| x276 |
penalty for hyphenation |
t276 |
= flagged-penalty |
w276 |
= 7.12 |
p276 |
= 100 |
| x277 |
box for ‘thing.’ |
t277 |
= box |
w277 |
= 47.02 |
| x278 |
finishing glue |
t278 |
= glue |
w278 |
= 0 |
y278 |
= ∞ |
z278 |
= 0 |
| x279 |
forced break |
t279 |
= flagged-penalty |
w279 |
= 0 |
p279 |
= −∞ |
次の位置が分割可能位置となります。上の例では、x2、x4 などです。
- xb が Penalty であり pb < ∞ である xb
- xb が Glue であり xb-1 が Box である xb
デメリット値は、そこで行分割するとどの程度よろしくないのかを示す値であり、この値が小さいほどよい分割位置と判断されます。 あまりに大きなデメリット値のときは分割位置の候補から除外されます。 デメリット値の算出方法の詳細はここでは触れませんが、外部から与えるいくつかのパラメタによって、デメリット値を調整できるようになっています。
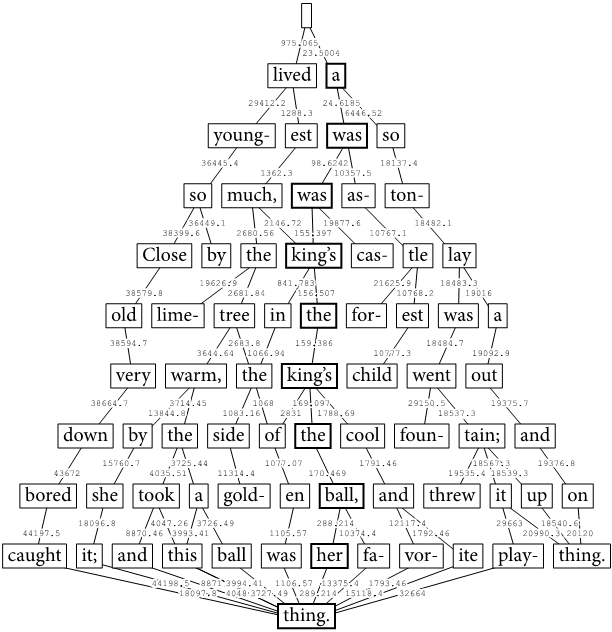
上の例では、x2 や x4 のデメリット値は非常に大きく、候補から除外されます。最初(1行目)の分割位置候補となるのは x26 と x28 で、デメリット値を d とすると、d26 = 975.065、d28 = 23.5004 となっています。
x26 で行分割したとき、次の行(2行目)の分割位置候補は、x52 と x54 で、d52 = 29412.2、d54 = 1288.3 です。
x28 で行分割したときは、x56 と x58 が次の候補となり、d56 = 24.6185、d58 = 6446.52 です。
パラグラフ全体にこれを繰り返すと、次のようなネットワークができ上がります(パスのいくつかは省略されています)。数値は、下に示された語の後で分割したときのデメリット値を示しています。この例では、太い枠の語で分割するのが最良となっています。
現在の AH Formatter はこのアルゴリズムを利用していません。そこで、このアルゴリズムを利用すると、どのように行分割位置が変化するのかを見てみます。
AH Formatter の結果 — ハイフネーションなし
 |
Knuth-Plass アルゴリズム の結果 — ハイフネーションなし
 |
これは、行あたりの単語数の少ない文書です。つまり、分割可能位置が少ない。 行末のアキの幅がより均等に近いのは、Knuth-Plass アルゴリズム の方であるのが見て取れます。
ハイフネーションをしたときは次のようになります。
AH Formatter の結果 — ハイフネーションあり
 |
Knuth-Plass アルゴリズム の結果 — ハイフネーションあり
 |
AH Formatter はハイフネーションが多く発生しています。
Knuth-Plass アルゴリズム は、ハイフネーションの発生を少なく抑えるように作られていますが、パラメタを調整して、もう少しハイフネーションが起こり易くすると、次のようにもなります。
Knuth-Plass アルゴリズム の結果 — ハイフネーション多め
 |
行あたりの単語数が多いときは分割可能位置も多いので、結果に差はなくなってきます。
AH Formatter の結果 — ハイフネーションなし
 |
Knuth-Plass アルゴリズム の結果 — ハイフネーションなし
 |
Knuth-Plass アルゴリズム には、いろいろ制約があることがわかっています。例えば以下のようなものです。
- 空白によって分かち書きされる英語などの文書を想定しているので、日本語のように分かち書きせず、ほとんどの文字間で分割可能な言語のことは考慮されていない。
- 非矩形の領域を扱えるが、そのとき行の高さが一定であることが仮定されている。つまり、途中で大きな文字が入っていたりすると処理できない。
- ドロップキャップ、letter-spacing、カーニング、リガチャ、綴りの変化するハイフネーション、ルビなどは考慮されていない。
- ページ分割は処理しないので、widows/orphans は処理できない。
AH Formatter にこのアルゴリズムを導入することが検討されています。







