Copilotに聞いてみました。
質問
無料のPDF編集ツールはどんなものがありますか
回答
もちろんです!PDFを編集するための無料のツールがいくつかあります。以下はいくつかのオプションです。
Smallpdf:
オンラインで直接使える無料のPDFエディターです。
テキストの編集や画像の追加、図形やハイライトの挿入などが簡単に行えます
<以下、略>
Copilotに限らず、無料のPDF編集ツ―ルとしてSmallpdfがよく挙げられます。Smallpdfは結構人気があるようです。そこでSmallpdfってどんなものなのかちょっと調べてみました。
まず、Webページです。Smallpdfのトップページはこちらです:
https://smallpdf.com/jp
画面右上で「ログイン」すると次のような画面になります。
メニューにリストされている機能を一覧表に整理すると次のようになります。
| 分類 | 機能リスト | 概要説明 |
|---|---|---|
| 変換&圧縮 | PDF 圧縮 | PDFのサイズを縮小 |
| PDFコンバーター | Word、Excel、ppt、および画像ファイルがPDFに変換されます。PDFファイルは選択されたファイルタイプに変換されます。 | |
| PDFスキャナー | PDFをモバイルでスキャン | |
| 整理 | PDF 結合 | PDFドキュメントをマージ |
| PDF 分割 | ページずつ分割したり、特定のページを切り取って新しいPDFファイルを作成 | |
| PDFを回転 | 回転するページを選んだり、すべてのページを一度に回転 | |
| PDFページを削除 | PDFからページを削除 | |
| PDFページの抽出 | 1つのPDFとしてページを抽出できます。また、選んだページごとに個別のPDFを作成することも | |
| 表示&編集 | PDF編集 | テキストや画像、ハイライト、描画の追加やドキュメントの整理 |
| PDF注釈 | 注釈が追加されたPDFを透かしなしでエクスポートし、さまざまなファイル形式に変換したり、圧縮 | |
| PDFリーダー | 自由に解析、編集、共有、印刷 | |
| ページ番号を付ける | 各ページのヘッダーまたはフッターに自由にページ番号を付ける | |
| AI PDF要約 | 50MBのファイルサイズと50,000ワードの文字数を上限に、PDFドキュメントをお好きな数だけ要約 | |
| PDFから変換 | PDF Word 変換 | PDFをワードファイルに変換 |
| PDF Excel 変換 | PDFファイルをExcelスプレッドシートにすばやく変換。OCRも可能 | |
| PDF PPT 変換 | PDFをPPTファイルに変換 | |
| PDF JPEG 変換 | 「全てのページを変換」または「画像を1枚ずつ抽出」 | |
| PDFに変換 | Word PDF 変換 | DOCとDOCXを数秒以内にPDFに保存 |
| Excel PDF 変換 | xls/xlsxファイルをPDFに自動変換 | |
| PPT PDF 変換 | PPT も新しい PPTX フォーマットもどちらも変換 | |
| JPEG PDF 変換 | 文字のサイズ、ページの向き、ページ余白を自由に調整 | |
| PDF OCR | OCRなら、選択可能なテキストを含む検索可能なPDFを作成 | |
| 署名&セキュリティ | EサインPDF | 署名と署名者を検証するためのLTV(長期検証)タイムスタンプが付与 |
| PDF ロック解除 | PDFからパスワードを解除 | |
| PDFを保護 | PDFにパスワードを追加 | |
| PDFをフラット化する | 内容がドキュメントに恒久的に埋め込まれる |
ざっくりみると、PDF編集ツールとしてはかなり機能が充実しているように見えます。もう少し詳細なところは後ほどチェックすることにして、「価格」を見てみましょう。
価格には次の4つのメニューがあります。
①無料
②プロ(月額1,013円)
③チーム(月額825円)
④ビジネス(カスタム価格)
プロとチームは、それぞれ、7日間のトライアル期間があります。トライアル期間を開始するにあたっては、クレジットカード情報の登録が必要で、7日間の試用が終わると課金されることになります。
有償ツールのトライアル期間は無料ツールには含めないとすると、「①無料」でどこまで使えるかがチェックポイントとなります。実際に使ってみると、多くのメニューは確かに無料で使えますが、しかし、重要な制限があります。
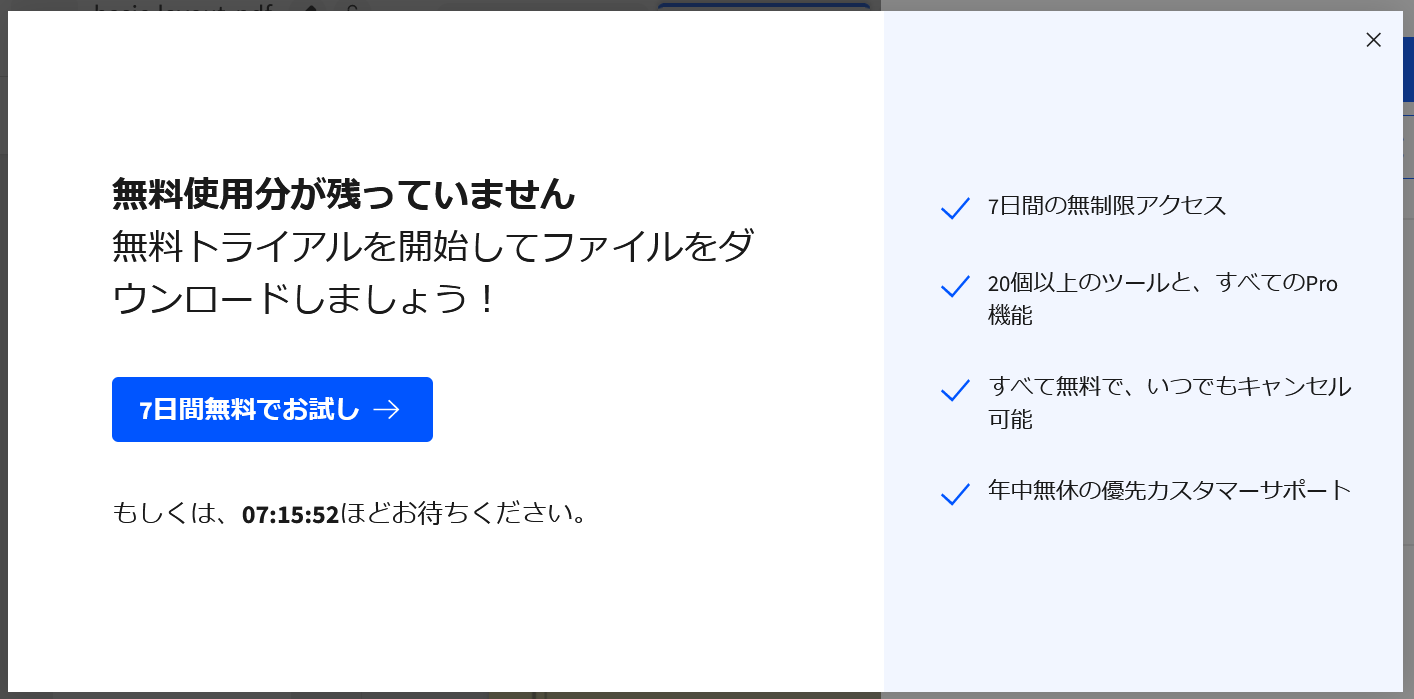
1.無料で使用するとき「ダウンロード」の制限があります。今回試した範囲では二つのPDFファイルを作成してダウンロードできました。しかし、三つ目をダウンロードしようとしたら、もう1日の制限容量を超えてしまったということで、次の画面のメッセージがでてダウンロードできません。1日にたった2ファイルしかダウンロードできないのでは、少なくとも仕事には使えないでしょう。
2.メニューでは一通りの機能があるように見えます。しかし「PDF編集」の中の「テキストや画像、ハイライト、描画の追加」をみると、ほぼ注釈の編集機能です。PDF本文編集では、本文への「テキスト」の追加機能があります。これを使おうとすると、次のダイアログが表示されます。
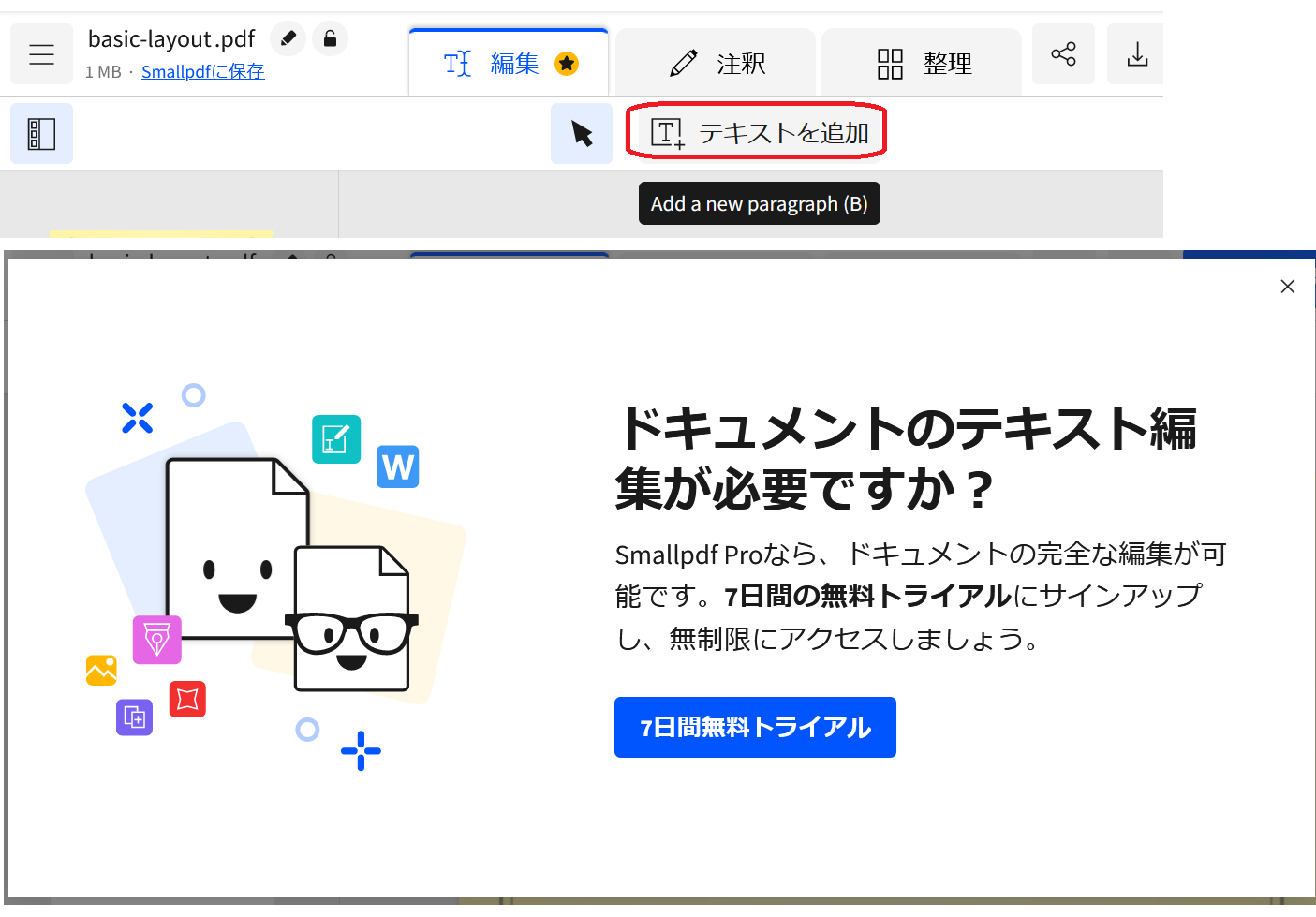
どうやら、これはSmallpdf proの機能のため「無料」では使えないようです。
Smallpdfツールは機能がかなり充実していて魅力的を感じる点もあるサービスです。
しかし、上記の1、2の制約を考えると「無料のPDF編集ツール」かもしれませんが、Smallpdfを「無料で実用に使える」とは言えないでしょう。無料はPR効果を狙った宣伝用語に過ぎないといえそうです。
弊社の有償ツールとの比較
結局、PDF編集を実用的に使いこなそうとするならば、有料のSmallpdf Proを契約するしかなさそうです。Smallpdf Proは、弊社製品で比較するならば『瞬簡PDF統合版』が機能的には一番近くなります。
契約体系が全く異なっているので価格は比較しにくいですが、次の表のとおり、1年と少しを超えて使用する予定があるなら『瞬簡PDF統合版』の方がお安くなります。
無料という宣伝文句に踊らされないようにしっかり比較してみましょう。
| Smallpdf pro | 瞬簡PDF統合版 シングルライセンス |
|
|---|---|---|
| 契約方式 | サブスクリプション | 永続ライセンス |
| 月間利用料 | 非課税(?)1,013円 | パッケージ版 税込15,950円 ダウンロード版 税込14,190円 価格は値引きなし標準価格 値引きが適用されとさらにお安くなります。 |
| 1年間使用 | 非課税(?)12,150円 | |
| 2年間使用 | 非課税(?)24,300円 | |
| 3年間使用 | 非課税(?)36,450円 |
PDF資料室へ