これまでに、PDF/A(ISO 19005)ファミリの仕様を順次紹介してきました。
PDF/A-3については、前回の紹介時点(2012/05/09~2012/05/11)ではまだ国際標準になっておらず、Draftの仕様で記載しましたが、その後、2012/10に正式に初版が発行されています。
今回はそのPDF/Aファイルの作成方法について書いてみます。
以前、説明しましたように、PDF/Aファミリには準拠レベルが存在します。長期間に渡ってファイルの視覚的な外観を維持できることを目的とするレベルB、これに加えて、ドキュメントの論理構造、意味といった情報を格納できるPDF/A仕様完全準拠のレベルAがあります(PDF/A-2,PDF/A-3ではこの中間にあたるレベルUが定義されます)
今日は、Pドキュメントの論理構造を必要としない準拠レベルB対応ファイルの作成方法を紹介します。
PDFファイルの作成方法として、アプリケーションからの印刷時に指定するプリンタにPDF出力用の仮想プリンタドライバを指定する方法、PostScriptファイルからPDFへ変換する方法などがあります。
前者では、PDF/A出力に対応している仮想プリンタドライバを指定することでPDF/Aファイルを作成することができます。プリンタドライバが、渡された印刷データからPDF/Aファイルを作成しますが、印刷データには元のドキュメントの論理構造に関する情報は含まれていないため、レベルAに準拠したPDF/Aファイルの作成はできません。PostScriptファイルからの場合も同様です。
■仮想プリンタを使用してPDF/Aファイルを作成する方法
PDF/A対応の仮想プリンタの例として、当社のAntenna House PDF Driver,アドビシステムズのAdobe PDFの使用方法です。いずれもPDF/A-1bファイルの作成に対応しています。
- ●Antenna House PDF Driver
- これは、瞬簡PDF作成6,瞬簡PDF編集4、および瞬簡PDF 統合版6に同梱されているAntenna House PDF Driver です。
現在では、ひとつ前のバージョンになっていますが、以前の記事で、使用方法を説明しておりますので、参照ください。 - ●Adobe PDF
- こちらは、アドビシステムズのAcrobat 製品に含まれる仮想プリンタドライバです。
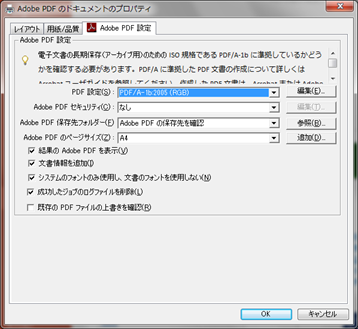
- アプリケーションの印刷で表示される印刷ダイアログのプリンタの選択で、Adobe PDFを選択し、詳細設定をクリックして、印刷設定ダイアログを表示します。
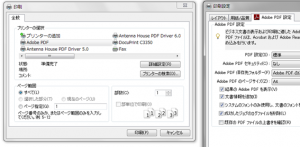
- 印刷設定ダイアログの「PDF設定」で、PDF/A-1b:2005(RGB)(CMYKカラースペースを使用する場合は PDF/A-1b:2005(CMYK))を選択します
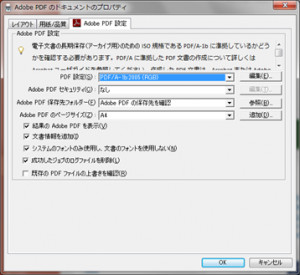
この「PDF/A-1b:2005(RGB)」は、Adobe PDFで設定可能な各種項目に対して、PDF/A-1b出力用に適切な値を定義したプリセットになります。「PDF設定」の右側の「編集」ボタンをクリックすると、プリセット値の内容を参照することができますが、設定内容を見てみると、「互換性のある形式」として、PDF/A-1bのベースである「PDF 1.4」、フォントには「すべてのフォントを埋め込む」、カラーマネージメントポリシーには、「すべてsRGB色に変換」、準拠する規格には、「PDF/A1-b(Acrobat 5.0互換)」などが設定されていることがわかります。
- 以上を指定して、印刷処理を行うことで、PDF/A-1bに準拠したPDFファイルが作成されます。フォントによっては埋め込みを禁止しているものが存在しますので、ドキュメント内でこのようなフォントが使用されていると、エラーが発生します。このような場合は、フォントの変更などドキュメント側の修正が必要となります。
- アプリケーションの印刷で表示される印刷ダイアログのプリンタの選択で、Adobe PDFを選択し、詳細設定をクリックして、印刷設定ダイアログを表示します。
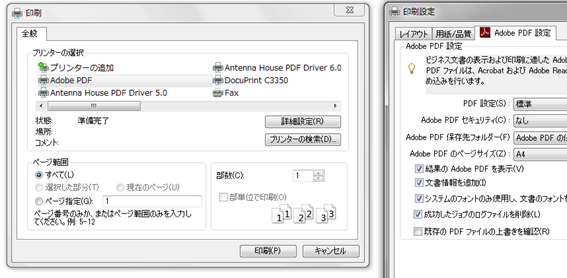
■PostScriptからPDFへ変換する方法
PostScriptファイルから、PDF/A-1bファイルへの変換は Acrobatに付属するDistillerを使用することができます。また、フリーソフトとして配布されているGhostscriptもPostScriptからPDFへの変換機能を持っていますが、変換時に -dPDFAオプションを指定することで、PDF/A-1bファイルを作成することができます。
このほか、当社製品では以下の製品がPDF/A-1bの出力をサポートしています。
- PDF Server V3
- Server Based Converter V5
- Antenna House Formatter V6
次回は、準拠レベルAのPDF/Aファイル作成方法を説明します。