

PDFには、レイヤーという便利な機能があります。
レイヤーは、PDFの内容をまとめて、表示を切り替えたり印刷を切り替えたりします。 Acrobatでは次のようなダイアログでコントロールします。
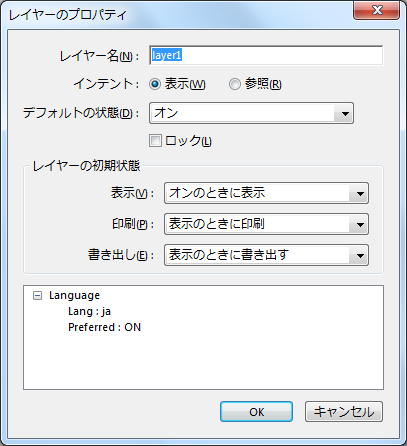
AH Formatter には、このレイヤーを出力する機能があります。
今回は、PDFのレイヤーでの言語指定について取り上げます。
レイヤーで指定した言語は、どのように振る舞うのでしょうか。
仕様では次のように書かれています(PDF 32000-1:2008)。
| Language | dictionary | (Optional) A dictionary specifying the language of the content controlled by this optional content group. It may contain the following two entries:
|
Language については、次のようにも書かれています。
Language: This category shall allow the selection of content based on the language and locale of the application. If an exact match to the language and locale is found among the Lang entries of the optional content groups in the usage application dictionary’s OCGs list, all groups that have exact matches shall receive an ON recommendation. If no exact match is found, but a partial match is found (that is, the language matches but not the locale), all partially matching groups that have Preferred entries with a value of ON shall receive an ON recommendation. All other groups shall receive an OFF recommendation.
PDFに指定されたLanguageは、アプリケーションの言語と地域に基づくと書かれています。アプリケーションとは、PDFのビューア、例えばAcrobatのことです。アプリケーションがレイヤーをサポートしていなければ、もちろん何も起こりません。Acrobatはサポートしています。
PDFに、日本語用のレイヤーと英語用のレイヤーを用意しておけば、アプリケーションの言語によって自動的に一方が表示され、他方が表示されないということができます。では、アプリケーションの言語とは何でしょう。仕様書中でそのことについて書かれている部分はありません。
そこで、どうすれば言語によるコントロールが意図どおりにできるのかを、Acrobatを用いて、試行錯誤を交えながらいろいろ探ってみました。
PDFには、Catalog辞書に言語を明示することができます。これは、文書のプロパティで確認することができます。AH Formatter では、<fo:root> に記述した言語がそこに反映されます。
<fo:root ... xml:lang="ja" ...>
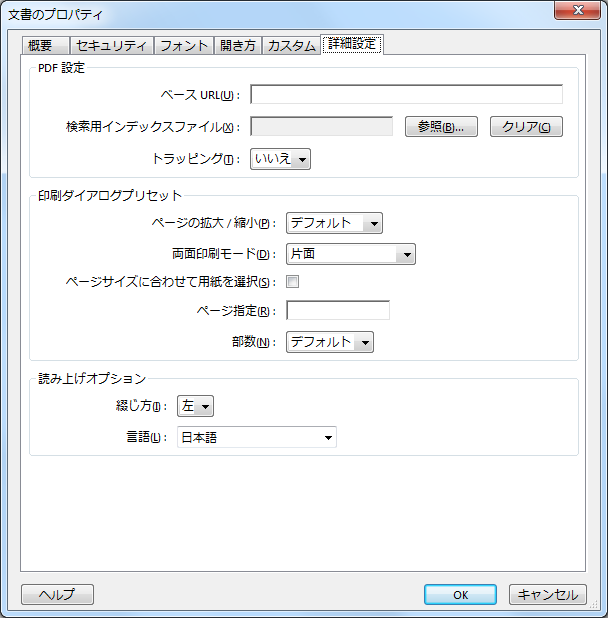
アプリケーションの言語とは、これのことでしょうか。
いいえ、この言語はレイヤーの言語とは関係ありません。
これは、PDFの言語であってアプリケーションの言語ではありません。
アプリケーションの言語とは、Acrobatでは環境設定の言語環境にあるアプリケーションを表示する言語に対応することがわかりました。
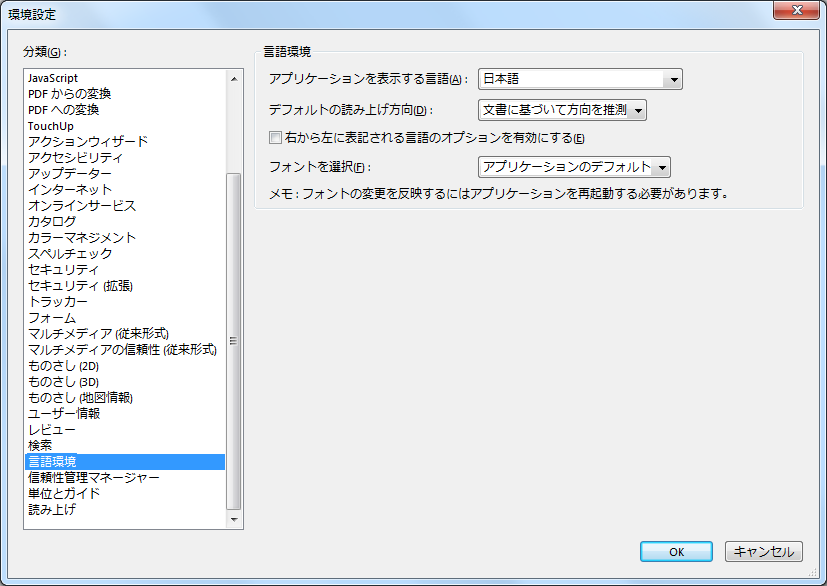
では、アプリケーションの言語は、具体的にはどう表記されているのでしょうか。14.9.2.2 Language Identifiers には次のような記述があります。
A language identifier shall either be the empty text string, to indicate that the language is unknown, or a Language-Tag as defined in RFC 3066, Tags for the Identification of Languages.
Although language codes are commonly represented using lowercase letters and country codes are commonly represented using uppercase letters, all tags shall be treated as case insensitive.
ざっくり言えば、PDFに書かれるLangの値は、RFC 3066 に従っていて大文字小文字は区別しない、ということです。RFC 3066 の言語コードは ISO 639、国コードは ISO 3166 によります。アプリケーションの言語も、ISO 639 と ISO 3166 で表現されているはずです。
実際にAcrobatでアプリケーションを表示する言語を変更すると、どこにどういう情報が書かれるのかはわかりませんでした。しかし、日本語なら ja とか ja-JP などが設定されると、常識的には予想するでしょう。
Preferredを指定していないと、Langに指定したものとアプリケーションの言語の間では完全一致性が判断されることになっています。そこで、日本語環境のとき、どういう指定をしたら完全一致するのかを調べました。
- ja ⇒ NG
- jpn ⇒ NG
- ja-JP ⇒ NG
- jpn-JP ⇒ NG
- jpn-JPN ⇒ NG
- ja_JP ⇒ NG
- jpn_JP ⇒ NG
- jpn_JPN ⇒ NG
- ja-jp ⇒ OK
結果は、まったく想定外でした。仕様には大文字小文字区別しないと明記してあるし、国コードは大文字で表記するのが普通とも明記されています。これはどういうことでしょうか。Acrobatは仕様どおりに動作しているようには見えません。Acrobatの不具合なんでしょうか。仕様の見落としがあるのでしょうか。
完全一致させるのにこんな試行錯誤した上、それが正しいのかどうか裏づけも取れないのでは、完全一致を使うのは現実的ではない気がします。Preferredを指定すると、かなりあいまいな指定でもマッチします。
日本語は、それを話す国は日本しかないですが、英語やポルトガル語スペイン語などはそんなことはありません。例えば、en-US(米国英語)と en-GB(英国英語)を区別したいこともあるはずです。Preferredでは、それらを区別させることはできませんでした。どちらもすべての en にマッチしてしまうようです。つまり、国コードを明示したいなら、Preferredを指定できないということになります。
次に Preferred な ja と、そうでない ja-jp の指定を混在させたらどうなるか見てみます。
日本語環境ではどちらも表示されそうなものですが、ja-jp の方だけ表示されて、ja は表示されません。完全一致するものが見つかったらそれしか表示されない、ということになっているからのようです。このことは、en-US と en-GB を用意し、両者の共通部分を en として表現したくても、できないということを意味します。
AH Formatter V6.4 では、次のようにレイヤーへの言語指定を行ないます。
実際には重なり合った領域に内容を配置するでしょうから、<fo:block-container> などを利用することになります。
<?xml version="1.0"?>
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format"
xmlns:axf="http://www.antennahouse.com/names/XSL/Extensions"
axf:layer-settings="'Japanese layer' lang 'ja' preferred,
'English layer' lang 'en' preferred">
...
<fo:block axf:layer="'Japanese layer'">
こんにちは
</fo:block>
...
<fo:block axf:layer="'English layer'">
Hello
</fo:block>
...
AH Formatter V6.4 MR3 以降を利用してください。





