

「行先番2」サービスパック5.2を公開しました。
本サービスパックは行先番をご利用されている方を対象に配布するものです。
行先番サーバがインストールされているPCに本サービスパックを上書きインストールしていただくことで、プログラムが最新版に更新されます。
クライアント側はサーバの更新に伴い自動アップデートされますのでとくに何もする必要はありません。
ただまれに自動アップデートに失敗する場合があります。その場合はクライアントもダウンロードしてインストールをおこなってください。
※現在のバージョンを確認するには行先番クライアントを起動してメニューから[ツール]-[オプション]を選択、オプションダイアログが表示されたら、[サーバ]タブをクリック、サーバ一覧から該当のサーバを選択して「接続テスト」ボタンを押してください。
バージョンが2.20.02以前の場合、このサービスパックを適用してください。
●改訂内容
5.2
・検索に失敗したときに表示されるダイアログが検索ダイアログの後ろに入って選択できないことがある問題を修正しました。
・プロパティのデータ編集画面で登録ユーザ欄にユーザ名が表示されないようにしました。
5.1
・検索できたにも関わらずエラーが表示されることがある問題を修正しました。
・同一データの編集ウィンドウを複数ださないようにしました。
・Administratorのパスワード変更ができない問題を修正しました。
サービスパックのダウンロードおよび導入方法はこちらからどうぞ。
カテゴリー別アーカイブ: デスクトップ製品

『瞬簡PDF OCR』を使ってみましょう(その3)
本日は、日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』のご紹介の最終回です。
昨日は、『瞬簡PDF OCR』で領域の誤認識を直す方法について説明をしました。
本日は、文字の誤変換を回避する方法として、画像データの「文字認識」について説明します。
これまでの変換例では、文書の先頭のタイトル部分が文字を誤認識しておかしな結果になっていました。
元の文字を見ると、丸文字系のフォントが使われていてデザインを優先した文字であることが分かります。
実は、こういった文字の認識はOCR処理の苦手とする部分です。人間の眼でみればなんということもないのですが、画像化された点の集まりから文字の形を拾い出して元の文字コードを推測するというOCR処理の論理からすると、文字の形状や方向が変化している画像は元の文字を特定しにくくて誤変換しやすいものとなるのです。
OCRソフトを使った変換では、こうした誤変換を変換前に修正する機能を用意しています。
再び『瞬簡PDF OCR』に戻って、ツールバーにある「文字認識」というボタンをクリックします。OCR処理で文字認識した結果が右のテキストビューに表示されますので、誤変換している文字を選択します。
すると、いくつか文字の一覧が傍らにポップアップで表示されるので、そこに正しい文字があれば選択して置き換えます。

同様に他の文字についても置き換えを行っていきます。
また、『瞬簡PDF OCR』では、テキストのフォント種類やサイズ、色、強調表示なども合わせて指定できます。
変換したいテキスト範囲を選択して、「文字のプロパティ」で文字属性を簡単に変更することが可能です。
<
(画像をクリックすると拡大します)
このように文字の認識結果について気になるところがあれば、変換前にある程度修正を行うことが可能です。
さて、以上の修正を行った上であらためてWordに変換した結果を示します。左側の既定値での変換結果と比較してみてください。
(画像をクリックすると拡大します)
一度紙に固定された文書からテキストや画像を取り出し再利用可能にするOCRソフトは、非常に有用なツールです。
オフィスや家庭には、これまであまり再利用されなかった紙の資産がたくさん眠っているのではないでしょうか?
『瞬簡PDF OCR』をご活用いただくことで、皆さまの資産の有効利用に多少なりともお役に立つことができれば、開発・販売を行っているものとして、たいへん嬉しく存じます。
今後とも弊社製品をご愛用いただけますよう、よろしくお願いいたします。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。
『瞬簡PDF OCR』を使ってみましょう(その2)
日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』を使った変換について、昨日の続きから説明します。
『瞬簡PDF OCR』は、以下の手順で画像からの変換処理を行います。
- 画像データの読み込み
- 領域解析
- 文字認識
- 変換先ファイル形式への保存
昨日は、OCRソフトでは誤変換が避けられないというお話をしました。
本日は、誤変換を回避する方法として、画像データの「領域解析」から説明していきます。
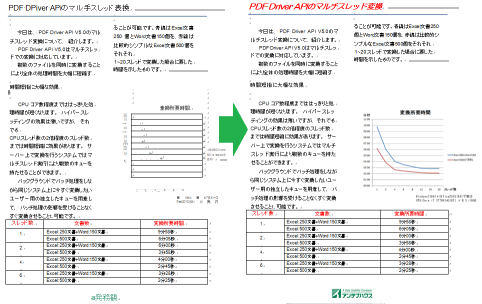
下記は、サンプルのPDFを既定値で変換した例です。
(画像をクリックすると拡大します)
自慢にならないですが、ひと目みて、おかしな変換や文字の誤変換があることがお分かりになるかと思います。
特に赤い丸をつけたグラフ部分がまったく再現されていません。これは、Word上では表に変換されているためです。
この原因は、OCR処理でこの部分の領域を間違えて認識しているためです。
『瞬簡PDF OCR』に戻って、ツールバーにある「領域解析」というボタンをクリックすると、OCR処理でどのような認識が行われたかが分かります。
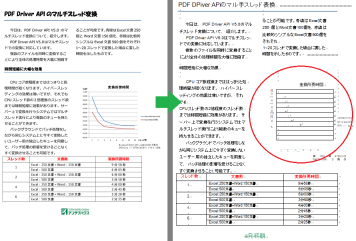
以下は、問題部分の領域解析結果です。
図で、赤枠で囲まれた箇所は横書きテキスト、ピンク色の枠で囲まれた箇所は縦書きテキスト、緑色の枠で囲まれた箇所は表領域にそれぞれ認識されています。表と認識されたのは、グラフにある横の目盛りを表の罫線と認識したためです。
これでは、Word上で修正しようがないので、元の認識処理に遡ってやり直す必要があります。
誤認識した範囲を画像領域に変更する例を図で示します。
(1)誤認識している領域範囲をマウスでドラッグ→(2)選択された領域をすべて解除→(3)範囲を選択し直し、一括で画像領域に変更
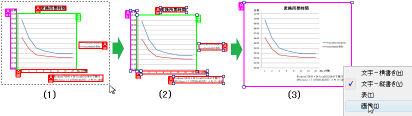
(画像をクリックすると拡大します)
領域を変更したところで、いったんWordに変換して結果を確認してみましょう。いったん「文字認識」を行い、「Wordへ変換」ボタンをクリックします。
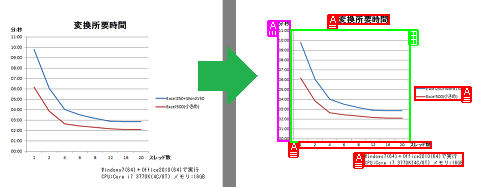
以下は、Wordに変換しなおした結果です。先ほどのグラフ部分に注目してください。

(画像をクリックすると拡大します)
さて、変換結果をみると、まだ不具合があります。文書の先頭のタイトル部分が文字を誤認識しておかしなことになっています。
誤認識した文字の修正方法は、また明日の回で説明しましょう。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。
『瞬簡PDF OCR』を使ってみましょう(その1)
日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』を使って変換するまでの概略を何回かに分けてご紹介します。
『瞬簡PDF OCR』は、以下の手順で画像からの変換処理を行います。
- 画像データの読み込み
- 領域解析
- 文字認識
- 変換先ファイル形式への保存
これまでOCRソフト製品を使用してこられた方であれば、お馴染みの手順かと思います。
それでは、まず画像データの読み込みから始めましょう。
- イメージスキャナ:イメージスキャナは一般的にTWAINと呼ばれる標準規格を採用しています。『瞬簡PDF OCR』もこの規格を採用したスキャナであれば基本的に扱うことができます。
また、TWAIN規格ではないですが、「ScanSnap」というドキュメントスキャナの機種で読み込んだデータも受け取ることができます。 - PDF:PDFには、スキャナで作成される画像だけのPDFもありますし、一般的にPDFドライバと呼ばれる仮想プリンタ形式のソフトを使って、Wordなどのアプリケーションから作成されるテキストが含まれたPDFもあります。
『瞬簡PDF OCR』はいずれのPDFであっても読み込みできます。ただし、後者のテキストが含まれたPDFはいったん画像にした上でOCR処理しますので、元あったテキストデータは消えてしまいます。この点はご注意ください。 - 画像ファイル:イメージファイルとして一般的なビットマップ形式や写真でよく使われるJPEG形式など、広く使用されている画像形式をサポートしています。また、クリップボードにコピーした画像データも対象にできます。
ここでは、手近にあるPDFを読み込む手順を説明しましょう。ファイルの読み込みは、単にWindowsのエクスプローラなどから任意のPDFをつかんで、『瞬簡PDF OCR』の上にドラッグ&ドロップするだけです。
この際に、既に何か読み込みされたデータがあると、以下のような確認画面が表示されるのが他のOCRソフトと違ったところです。
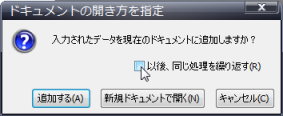
これが昨日説明した、『瞬簡PDF OCR』独特のドキュメントの扱い方に関連するものです。既にあるドキュメントに同じ仲間としてページを追加するか、あるいは別物として新規にドキュメントを作成し、そちらに格納するかを問い合わせているわけです。
ここでもし「追加する」を選択し、画面中にある「以後、同じ処理を繰り返す」にチェックをいれると、次に新しいデータを取り込んでも問い合わせをしないで、ひとつのドキュメントに「追加」し続けます。この指定は、1枚づつしか取り込みできないスキャナから連続して原稿を取り込みたいときなどに便利です。
画像の読み込みが終わると、内容が画面に表示されます。
下記は、PDFを読み込んだ直後の状態です。
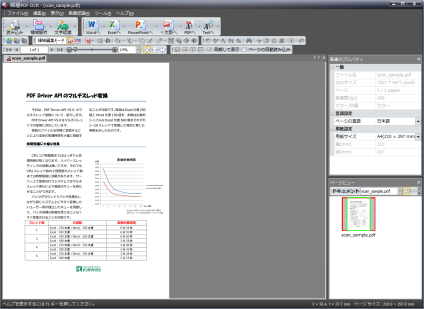
(画像をクリックすると拡大します)
結果を急ぐ人は、ここでいきなり変換してしまうこともできます。
元の画像の条件がよい場合は、いきなり変換してそのまま再利用ができるほどの変換結果が得られるかも知れません。
OCR処理で「条件がよい」というのは、元の画像の解像度が高くて、画像の傾き、ゴミなどのノイズがなく、文字は活字で余分な飾りもなく、レイアウト自体も単純、といったような場合をさします。しかし、そういった原稿など現実にはあまりなさそうですね。
通常、OCR処理で変換したい画像は、たいてい文字が化けたり元と違う文字に置き換わったりするなど、誤変換が避けて通れないものです。
元と違う文字が変換される程度であれば、変換後にワープロソフトを使って修正可能ですが、画像で変換したい箇所を文字と誤認識してひどい文字化けになるなど、変換後では修正しきれない場合もあります。
このような事情から、OCRソフトには誤変換を回避するための処理が備わっています。
その詳細は、明日の回で説明することにしましょう。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。
『瞬簡PDF OCR』のマルチドキュメント・インタフェースとは?
昨日に続いて、日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』をご紹介します。
『瞬簡PDF OCR』は、マルチドキュメント・インタフェースというちょっと聞き慣れない用語でその操作性をアピールしております。
これは何かといいますと、平たく言えば、いくらでもデータを読み込んでお好きな変換先に変換できますよ、ということです。
もちろんパソコンの物理的な制限というのはありますから、「いくらでも」というのは言い過ぎですね。
しかし、スキャナからでも、PDFからでも、ビットマップやJPEGなどのイメージからでも、クリップボードからでも、画像データであればとりあえず『瞬簡PDF OCR』の画面上に放り込んでおいて、いつでもWordやExcelに変換できるような作りになっています。
以下では、そのあたりを説明してみたいと思います。
『瞬簡PDF OCR』では、原稿データの1枚を「ページ」と言っています。
スキャナで紙の原稿を読み込むときの原稿1枚、1枚がそれぞれ1ページになります。
画像ファイルを読み込んだ場合はひとつの画像ファイルが1ページとなり、 PDFを読み込んだ場合はPDFに含まれる各ページがそれぞれ1ページになります。
次に、ページをひとつにまとめたものを「ドキュメント」と言います。
『瞬簡PDF OCR』では、ひとつのドキュメントが『Word』や『Excel』の1文書に変換されます。 また、作業ファイルに保存する場合も「ドキュメント」毎に行います。
これを図に表すと以下のようになります。
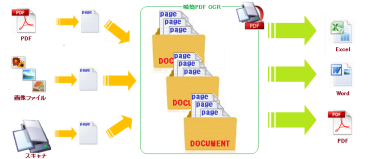
(画像をクリックすると拡大します)
これをどんなふうに使うかというと、例えばスキャナで複数の原稿を取り込む場合を考えてみます。
紙の原稿にはいろいろな種類があると思いますが、報告書であるとか、申請書のような形式の文書はWordで編集した方が何かと便利です。
一方、表形式になった月次売上だとか名簿などは、Excelで編集するのが向いていると言えます。
これらを一度にスキャンして、別々のドキュメントにまとめて取り込んでおけば、片方はWordに、もう片方はExcelに分けて変換することができます。
また、Wordに変換する場合でも、報告書は報告書でまとめてひとつのWordファイルに変換し、申請書は申請書で種類毎に別のWordファイルにしたいと思いませんか?
そのような場合でも、『瞬簡PDF OCR』では、報告書のドキュメント、申請書Aのドキュメント、申請書Bのドキュメントというように、原稿を取り込んだ時点で分類しておけるので、後はそれぞれのドキュメント単位で変換できます。
これを整理しますと、以下のようになります。
- スキャンした原稿や、PDFの内容などをひとつのドキュメントにしたり、それぞれを別のドキュメントに分けたりすることで、目的に応じた変換結果を簡単に得ることができます。
- ドキュメントに含まれるページは、サムネイルを使って順序を入れ替えたり、不要なら削除したりが簡単に操作できます。また、ドキュメント間でページに含まれる任意の範囲をコピーして貼り付けたり、移動することも可能です。
- ドキュメント毎にその状態を保存できますので、途中で作業を中断して『瞬簡PDF OCR』を終了しても、次回起動時に再び前回の中断時点から作業を再開することが容易です。
(画像をクリックすると拡大します)
以上、『瞬簡PDF OCR』の操作画面について、簡単に説明しました。
次回は実際に取り込んだ画像データから変換を行うまでの操作方法についてご紹介したいと思います。
是非明日もこちらのブログをご覧ください。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。
日本語/英語活字OCR変換ソフト『瞬簡PDF OCR』のご案内
本日は、9月に発売を開始したばかりのニューフェイス、『瞬簡PDF OCR』をご紹介します。
『瞬簡PDF OCR』は、紙に印刷された文書をスキャナーなどで読み取り、WordやExcelなどのOffice文書に変換する、いわゆる「汎用OCRソフト」のカテゴリに分類される製品です。
このカテゴリには、既に以前から多くのソフトウェア・メーカーさんが進出され、バージョンを重ねた老舗のソフトもいくつか見られます。
変換一筋25年を標榜するアンテナハウスが、今回ここに新製品を投入した狙いは、ズバリ、「編集しやすい変換結果を提供することで、より簡単に紙の原稿の再活用が可能であることを体験していただきたい」というものです。
このことは、『瞬簡PDF OCR』が、OCR汎用ソフトにおける文字認識精度などの入力側ではなく、Officeへの変換精度という出力側に焦点をあてた製品コンセプトであることを意味します。
以下では、具体的な例を通して説明してみたいと思いますので、どうぞ今しばらくお付き合いください。
みなさんは、マイクロソフト・ワードなどのワープロソフトで文書を作るとき、どんなふうに文字を配置していかれるでしょうか?
おそらく多くの方が、新規文書を開き、そこに示されたカーソルに従ってそのまま文字を入力していくことと思います。
これは、ワープロ上に本文領域が既定値で設定されていて、そこに文字を配置していく操作に他なりません。
つまり、普通に文書を作成する場合は、本文にテキストを配置し、必要であれば、やはり本文内に図や表を配置していくのが自然な操作であると言えます。
さて、次の図の例をみてください。

(画像をクリックすると拡大します)
これは、上の青い枠で囲まれた原稿(スキャナで作成されたPDF)をWordに変換した結果を示したものです。
左の赤枠で囲まれた結果はOCRソフトでは比較的よく見かける変換方法で、OCR処理した結果をWord上にテキストボックスで配置しています。
テキストボックスで文字を配置するのは、レイアウトの再現という面では有効な手法です。
しかしひとつながりの段落を段組レイアウトで配置しているような場合には、テキストボックスで段落のつながりが切れてしまうため、テキストの手直しが面倒になります。
Wordには、テキストボックスをリンクしてつなげる機能が備わっていますが、ひとつずつ手作業で指定するなど、使い勝手はあまりよくないようです。
右の赤枠で囲まれた方は、『瞬簡PDF OCR』でWord上に本文としてテキストを変換した結果です。
本文で変換することにより、文字の挿入・削除といった編集操作を違和感なく行うことができます。
もうひとつ、同じような事例ですが、次の図をご覧ください。
(画像をクリックすると拡大します)
最初の例と同様、青い枠で囲まれた、表を含む段落をWordに変換した例です。
左の赤枠で囲まれた方は、やや見づらいですが、テキストを本文で変換し、表をテキストボックスで変換した例です。
表をテキストボックス内で変換して配置した場合は、Word上で本文と分離して置かれますので、そのままでは本文に重なって表示されます。
これに対し、右の赤枠で囲まれた方は『瞬簡PDF OCR』でWord上に表を変換したもので、本文内に表を置いています。
本文でテキスト行を追加したり削除すると、表も本文と一緒に移動します。
どちらが編集しやすいか、お分かりいただけるかと思います。
OCRの文字認識精度が高ければ文字を正確に抜き出せるので、あとはOffice上で自由に編集すればいい、という考え方も当然できます。
しかし、元の原稿が長文であったりレイアウトが複雑であったりするほど、後工程での編集にも時間がかかるだろうことは容易に予想されます。
せっかく貴重なお金を消費してOCRソフトを購入し、紙原稿をOffice上に写したものであれば、その後の再利用に要する時間は節約できた方が満足度も増すのではないでしょうか?
以上、『瞬簡PDF OCR』の目指すところを簡単に述べさせていただきました。
次回は『瞬簡PDF OCR』をご理解いただくための、より深い情報をご紹介したいと思います。
もし本製品にご興味をお持ちいただけた場合は、是非明日もこちらのブログを覗いてみてください。
※『瞬簡PDF OCR』は製品の体験版を公開しております。『瞬簡PDF OCR』のユーザー体験を、製品紹介サイトでお試しください。
アンテナハウスのデスクトップ製品
PDFを作りたい、PDFをWordで編集したい、PDFに文字を記入したいなど、PDFに関してお客様の使用用途は様々ですが、どの製品を使えばご自分の行いたい作業ができるのかわからないという方もいらっしゃいます。
弊社サポートでも、稀にそのような問い合わせをお受けすることがございますが、アンテナハウスの製品は大きく3つの用途に分類することができます。
●PDFを作成できるソフト
・瞬簡PDF 作成
・瞬簡PDF 編集
●PDFからOfficeへの変換ができるソフト
・瞬簡PDF 変換
・瞬簡PDF OCR
●PDFに直接文字を書き込めるソフト
・書けまっせPDF
・瞬簡PDF タッチ
・瞬簡PDF 編集
このように、様々なソフトがございますが、例えば同じPDFからOfficeへの変換ソフトでも、『瞬簡PDF 変換』ではPDF内部に文字情報の入ったデータの変換に強く、『瞬簡PDF OCR』ではスキャナから取り込んだような画像PDFの変換に強いなど、ソフトよって特化した機能がありますので、作業効率を上げるためにも、適切なソフトを選択することが大切です。
アンテナハウスでは、上にご紹介した以外にも、PDFにしおりや目次を付ける『アウトライナー』や、PDFを画像に変換する『瞬簡PDF to Image』など、PDFに関する様々なソフトを用意しておりますので、用途に合わせてご検討頂けたらと思います。
「瞬簡PDF OCR」9月の新製品
9月に新製品として「瞬簡PDF OCR」の販売を開始いたします。
この製品は、スキャナから取り込んだ紙の原稿データ、PDF、画像ファイルにOCR(光学式文字認識)処理を行い、Office(Word、Excel、PowerPoint)ファイル、透明テキスト付きPDF、一太郎に変換することができます。
「瞬簡PDF 変換 7」となにが違うの?という疑問を持たれるかもしれません。
もちろん「瞬簡PDF 変換 7」でOfficeファイル、透明テキスト付きPDF、一太郎に変換できますが、大きく異なる点は、
OCR処理された領域を目で確認しながら編集できるという点にあります。
OCR処理で誤認識された文字の修正や、領域の属性変更(ここは表として読み取りたい等)、変換したくない範囲の指定
などきめ細かな設定が可能です。
「瞬簡PDF 変換 7」は複数のPDFを一括変換する場合に適しているのに対して、「瞬簡PDF OCR」は1データづつ目で確認しながらきめ細かな設定を行って変換することができます。

機能の詳細や応用機能などは、後日発売日が近づきましたら紹介させていただきます。
瞬簡PDF 編集 3.1 ベクタープロレジ大賞ノミネート&セール中!

おかげさまで、PDF編集ソフト『瞬簡PDF 編集 3.1』を現在開催中の第18回 Vectorプロレジ大賞の「PDF作成 部門」にノミネートして頂きました。皆様のご愛顧賜り、感謝いたします。
8月16日まで投票を受け付け中ですので、よろしければ『瞬簡PDF 編集 3.1』にご投票いただければ幸いです。
アンテナハウスのオンラインショップでは、上記ノミネートを記念して『瞬簡PDF 編集 3.1』のダウンロード版を特価販売中です!この機会にぜひお買い求め下さい!

⇒ アンテナハウス オンラインショップ
●『瞬簡PDF 編集 3.1』について
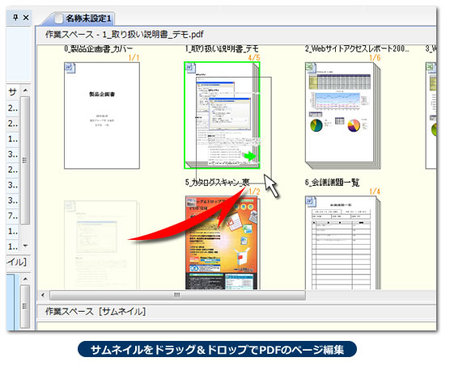
『瞬簡PDF 編集 3.1』はPDFのページのサムネイル(縮小画像)をドラッグ&ドロップして、ページ順の組み換えや、追加、削除、回転などを行なう事ができるPDF編集ソフトです。
複数のPDFから必要なページを集めて編集し、ひとつのPDFとして完成させることができます。
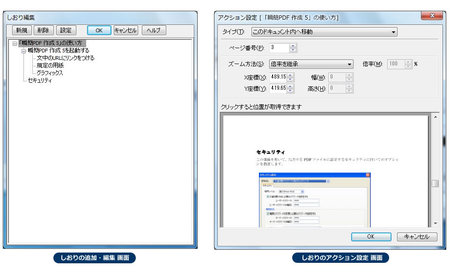
また、専用のツールでしおりの追加・編集を行なったり、編集用のビューアで文字やページ番号、図形、捺印、コメント、その他注釈などを追記することができます。
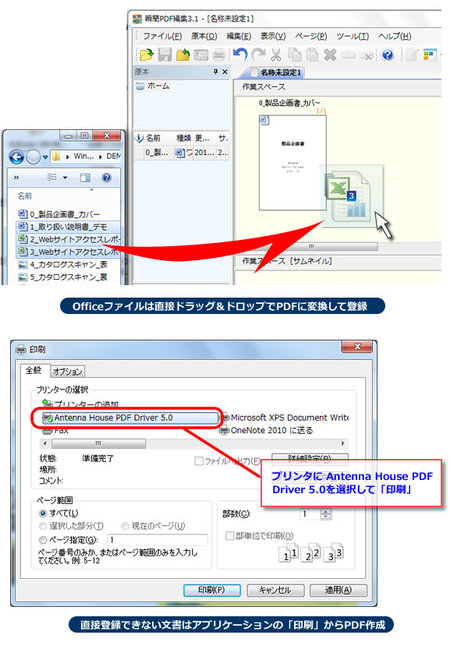
PDF作成仮想プリンタドライバー「Antenna House PDF Driver」が付属しますので、Microsoft OfficeなどPDF以外の文書は、PDFに変換して登録することができます。
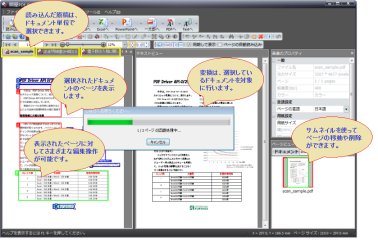
[ドラッグ&ドロップでページ編集]
[専用ツールでしおりの追加・編集]
[編集用ビューアで文字や注釈の追記]
[PDF作成プリンタドライバーでPDFに変換]
その他、詳しくは『瞬簡PDF 編集 3.1』の製品紹介ページをご覧下さい。
デスクトップ製品のサポート期間
デスクトップ製品のサポート窓口には様々なお問い合わせがありますが、その中に製品のサポート期間を知りたいというお問い合わせがあります。
製品の利用ガイドなどにも記載されておりますが、アンテナハウスのデスクトップ製品は、お客様が製品をご購入されてから1年間がサポート期間となっており、お電話、あるいはメールでのお問い合わせにお答えしております。
また、ご購入から1年以上を経過した製品でも、製品の販売終了から1年未満の製品については、なるべくご質問にお答えしております。
販売終了から1年以上経過した製品のお問い合わせにつきましては、場合によってはお断りするケースもございますが、お客様が製品を使うにあたり、少しでもお役に立てるようサポートを行っておりますので、製品をご購入頂いた後、お困りのことがあった際には是非サポートセンターをご利用ください。
なお、デスクトップ製品のサポートについての詳細は「デスクトップ製品のユーザーサポートについて」をご参照ください。