お正月のある日。
何をするでもない無為な時間を過ごすことは、人生にとって必ずしも無駄なことではない、むしろ贅沢なことだ、などと嘯いているのもそろそろ飽きてきたので、新たな見聞を広めるため、おもむろにPCを引きずり出してネットサーフィン(これも今や死語か)ならぬネット漂流に出掛けてみることとしました。
そんな中で、とある記事に目が留まる。
「視覚障害の方のインターネット利用は91.7%」。総務省が2012年に発表の調査データらしい。
アクセシビリティとユーザビリティの確保は、Webを製作する側も公開する側も配慮すべき優先課題であるのは今では言うまでも無いこと。その規格化は2004年から始まっているとのことだが、利用者側の情報について触れることはほとんどなかったので、利用率の高さに正直なところ驚いた。
夢うつつの漂流が現実に引き戻されつつある中で、こんな記事にぶつかった。
パソコンからインターネットを利用する際に困ることについては、全盲者では「スクリーンリーダーで読み上げられないPDFやフォームなどがある」(94.4%)が最も高い。
また別の調査では、「PDFファイルについては、画像のみでテキストが埋め込まれておらず読み上げないという問題と、読み上げ順序が文脈通りになっておらず、内容を理解しづらい」という問題の指摘が多い。「PDFによる解説は解読不能」との意見も。
最後に、とどめの一撃が。
質問:知りたい情報がPDFファイルで提供されている場合の利用方法。
回答:PDFファイルのみで提供されていた場合は読まない(18.24%)。
フルボッコです。
「これでいいのか、PDF!アクセシビリティはどこへ行った?」
2016年4月1日、障害者差別解消法は施行された。
正月気分も冷めやらぬ中、俄か知識を引っ提げて、アクセシブルなPDFの普及が急務であると、ドヤ顔で語っておりましたところ、ある制作会社さん曰く。
「もう2~3年前から手掛けてますよ、うちは。官庁・自治体のお客様が多いから必須なんですよ。ただ、加工が大変でして、簡単にPDFにタグがつけられるツールとかありませんか。」
己の見識の狭さに赤面しながら、「流石、法定義務を課せられているだけあって官庁は動きが早いですね。努力義務の民間のお客さんはまだまだでして・・・・ははは」としどろもどろの言い訳に、赤っ恥のボディブローがジワリと効いてくる。
「が、頑張っているじゃないかぁ、PDF!」
印刷用の版下に、どうしてアクセスビリティが必要なの?
その疑問ももっともですが、PDFの活用はそのレベルで十分とお考えですか。
昨今は印刷物とHTMLをセットで納品するのが当たり前、PDFをWebにあげなくてもとのご意見もありますが、印刷物のレイアウトを広く共有するためにPDFでなければならない場合も多々あります。
必要とされる以上、対応しないわけにはいかない。
それにしても、できあがったPDFに後からタグを追加する作業の効率の悪さ。
PDF/UAでは、形式的、意味的に厳密なタグ付け(マークアップ)が求められています。
アクセシブルなPDFの普及を妨げる要因が、それらPDF仕様の複雑さとアクセシビリティ要求の高さにあるとすれば、現状の改善は望めないのでは・・・・・。
いえいえ、アンテナハウスにお任せあれ!
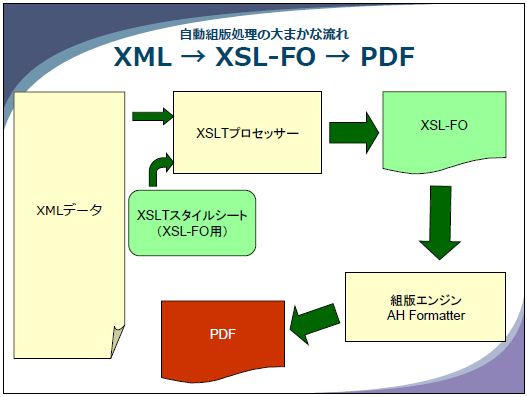
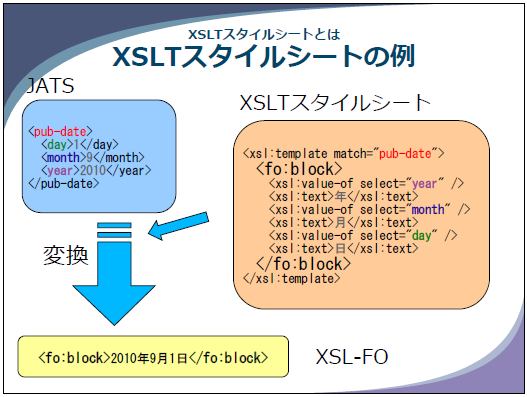
解決法はオリジナル文書の段階で階層化、マークアップしてしまう以外にはありません(断言)。
構造化文書からどうやってアクセシブルなPDFを?
『AH Formatter V6.4』はPDF/UA出力機能を実装しました。
アンテナハウスは、一つのコンテンツから印刷用PDFとアクセシブルなPDFを自動生成すると共にHTMLも作成する、ワンソースマルチユースのもう一つの応用を提案します。
製品紹介・実演をご希望の方は、2月8日から開催のPAGE2017(BT-8)にてお待ちしております。
【参考資料】