2008年06月18日
PDFについての基礎的な技術知識
別の人が作成したPDFを受け取ったとき、そのPDFを表示したり印刷した結果が、最初の作成者がオリジナルのアプリケーションから紙に印刷した結果と同じであるかどうか?
これは、大抵の場合、同じになるのです。が「大抵の場合同じでは困る、常に同じになることを保証せよ。」と言われた時、どうやってこれを保証するか?
なかなか難しい問題です。
PDF/AとかPDF/Xは、(1)表示できない、(2)文字化けが起きない、から始まって、(3)元のアプリケーションの印刷結果とPDFから印刷した結果が全く同じになるようなPDFを作成する方法を規定したもの、とも言えます。
今日は、某所でそんな話になりました。
とりあえず、参考資料をアップしておきます。
だんだん、参考資料が分かりやすくなっていると良いのですが。
PDFファイルをダウンロード
投稿者 koba : 08:00 | コメント (1) | トラックバック
2008年06月14日
PDFの電子署名の第二の役割 「署名者を証明する」
最近、見積書や発注書をPDFで取引先からいただくことがあります。そのPDFには押印がされていることがあります。
しかし、実際のところ、取引先からいただいた見積書や発注書を信用するのは、その押印の印影よりもむしろ、見積書を送付してきた人と面識があるとか、そういった経緯や事情を勘案しての判断になるように思います。ですので、見たことも、会ったこともない相手からPDFで入手した見積書や発注書を直ぐに信用できるかと言いますと、なかなか、そうはいえない場合も多いだろうと思います。
最近のように巧妙なスパム・メールが出回っている状況になってきますと、見知らぬ相手から入手した書類の信憑性(しんぴょうせい)は、ますます、下がると思います。
電子的に作成・送付された書類の信憑性を確保するための、最も確実と思われる手段は、作成者の電子証明書を頼りに判断することです。
PDF電子署名では、署名者の証明書を署名済みPDFの中に埋め込むことにより署名者を証明することができます。これが、PDFの電子署名の第二の役割です。
PDDに埋め込まれている証明書は、アドビ・リーダなどの署名検証用のツールで確認することができます。
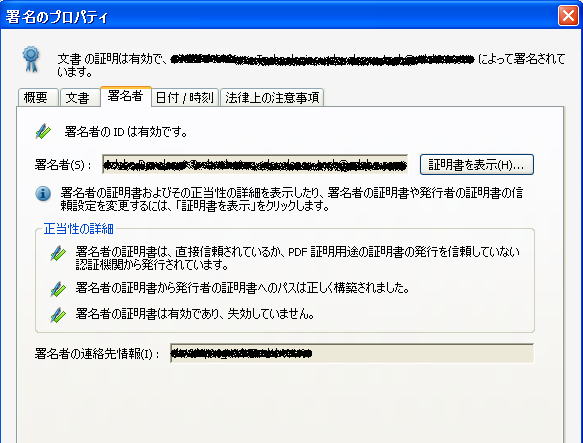
現実の問題として、このメッセージは少しばかり分かりにくいと思います。もう少し分かりやすく出す方が良いでしょうが。
このように、PDF電子署名の第一の用途は改竄の検出ですが、第二の用途として、署名済みのPDFに埋め込まれた署名者の電子証明書を確認することで、署名者の信頼性を確認できるということがあります。
このように考えて見ますと、将来、PDFを紙の代わりに利用するために、PDF電子署名はどうしても欠かせない重要な機能になるはずです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年06月10日
PDFで電子署名による改竄防止とは?ハッシュ値
PDFに電子署名すると改竄防止になるのだろうか?とお考えになる方は、PDFに電子署名するとPDFが暗号化されるのではないかと予想されていると思います。
しかし、昨日もお話しましたように、PDFに電子署名すると、対象のPDFからハッシュ値を計算し、そのハッシュ値を暗号化します。署名対象PDFそのものは元のままです。
署名対象PDFを暗号化しないで、わざわざハッシュ値を作ってそれを暗号化するのは、署名につかう暗号の計算(公開鍵暗号方式といいますが)には処理時間がかかり、PDFのような大きなファイルを処理対象にすると実用的な速度で暗号化できないためです。
そこで、ハッシュ値という元のPDFの代理になる小さなデータを作って、もとのPDFの代わりに代理のハッシュ値を暗号化するのです。
ハッシュ値を計算する方式はハッシュ関数と言います。ハッシュ関数は次のような特性が要求されます。
要求条件:「ふたつのPDFが異なっているなら、それから計算した二つのハッシュ値も異なっている。」
この要求条件が成立すれば、その対偶、「ふたつのハッシュ値が同じであれば、ふたつのもとのPDFは同じ」が成立します。
PDF電子署名では、この原理を使っています。
つまり、署名時点のPDFのハッシュ値と、現在(検証時点)のPDFのハッシュ値をそれぞれ独立に計算し、それが同じかどうかを調べます。
同じであれば、署名時点のPDFと現在(検証時点)のPDFは同じである→改竄されていない、と判定するわけです。
ハッシュ関数には、MD2、MD4、MD5、SHAなどいろいろあります。SHAにはSHA-1、SHA-2(SHA-224、SHA-256、SHA-384、SHA-512)があります。
実際のところ、私の素人的直感では任意のPDFに対して上記の要求条件を完全に満たすハッシュ関数は、たぶん、存在しえないでしょう。どんなハッシュ関数でも、確率的には異なるふたつのPDFから同じハッシュ値がいつかは作られることになってしまうと思います。
でも、実際には、あるPDFとそれを改竄したPDFから計算したふたつのハッシュ値が必ず違っていれば、それで、充分です。それが満たされれば、改竄したPDFを確実に検出できます。
逆に、改竄する前のPDFと意図的に改竄したPDFから同じハッシュ値が計算できるようになってしまったら大変。改竄を発見できなくなるわけですから、そのハッシュ関数は使い物になりません。
こういう状態になることをハッシュ関数の安全性が損なわれた、あるいは、脆弱性というようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年06月09日
PDFで電子署名による改竄防止とは?署名後の変更検出
「PDF電子署名モジュール」を発売以来、
PDF電子署名を使えば、改竄防止ができますか?
というお問い合わせを、何度もいただいています。電子署名は、改竄への抑止効果を期待できるという意味では広い意味では改竄防止のために役立つでしょう。一方、PDFの改竄をできなくするという狭い意味では、改竄防止にはなりません。
一般に、改竄は本来なされるべきでない変更を意味すると思います。このような改竄とは行かなくても、PDFに署名を施した後で、PDFを変更することは自由にできます。例えば、最初の署名後、別の人が署名することなども変更の一例です。(このような適切な更新は、改竄には含めないと思いますが)。
PDFに電子署名することで、署名した時点からPDFが変更・改竄されていないかどうかを検証できるようになります。そして変更・改竄されていればそのことを検出するものです。
このような署名対象の署名後の変更・改竄の検出は、電子署名の効用の一つです。
こうした署名を使った変更・改竄検出処理の内部的な処理は大雑把には次のようなものです。
1.PDF署名ツールは、署名時点のPDFのハッシュ値を計算します。そしてハッシュ値を暗号化してPDF内に保管します。
2.署名検証ツールは、PDF内に保管されているハッシュ値の暗号を解いて署名時のハッシュ値を取り出します。そして、別途独自に現在のPDFのハッシュ値を計算します。
署名時のハッシュ値と、独自に計算した現在のPDFのハッシュ値を比較して、同一か、違っているかを調べます。
二つのハッシュ値が同じであれば、PDFは署名後変更も改竄もされていないとします。
ハッシュ値が違っていれば、そのPDFは署名後変更または改竄されたということになります。
さらに、PDFの場合は、署名済みの範囲を変更しないで、変更箇所を増分更新として記録することで適切な変更を行なえば、不適切な変更である改竄と区別ができます。
以上は、一般的な署名検証ツールの処理です。Adobe Readerには署名検証ハンドラが内蔵されており、署名後の変更・改竄についての検証を行なうことができます。Adobe Readerの内部的な処理は、上の説明より少し詳細なチェックになっているようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年06月03日
XPS vs PDF : XPSの方がPDFより優れている点
Global Graphics社のXPS FAQを読んでみました。これは、XPSについて分かりやすい説明になっています。英文なのが残念ですが。
Global Graphics社はMicrosoftと一緒にXPSを積極的に推進している会社ですので、XPSについての良いことを書いているのだろうと思います。読んでいますと、やはり、そのうちXPSがPDFよりもポピュラーになるかも知れないという気持ちになってきますので不思議です。
この中にXPSがPDFに比べて良い点がいろいろ書かれています。一つ、あまり多くの人が指摘してないですが、という前置きで、PDFでは妥当性の検証ツールがないが、XPSには妥当性検証のツールがいろいろあるという話が出ています。これは、エンドユーザの方々には理解し難いかもしれませんが、PDF関連の開発をしている立場では共感できます。
PDFのツールを開発している会社は沢山ありますが、大抵はPDFが正しくできているかどうかはAdobe Readerで表示できるかどうかで判定しているようです。但し、Adobe Readerで表示できるからといって正しいPDFとは限らず、正しくないPDFは、どこか(例えば、ダイレクトPDF印刷など)で破綻してエラーになることがあるようで、これはプリンタ・メーカ泣かせだそうです。
PDFのシンタックス・エラー、標準非準拠の可能性は大きな問題で、特にPDF/Aについては、準拠性を確認する方法が検討されているということは前にお話しました。
XPSでは最初から妥当性検証のツールが用意されています。XPSはXMLで記述されていますので、XMLの仕組みを使って妥当性検証ができるという有利な面もあるようです。
■XPSの妥当性検証ツール
・Windows Vista DDK のIsXPSツール
・Windows Vista DDKの LooksGood
他に、検証サービスをしている会社もありますね。
あと、PDFでは、フォント埋め込みが必須になっていないため、フォントを埋め込まないPDFが作られて、環境によっては表示が正しくないことがありうるのですが、XPSはフォントの埋め込みが必須とされているのでそういう問題がないというメリットもあるとのこと。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年05月18日
PDF/Aの妥当性検証について
PDF/AのISO仕様について、仕様が決定される前に、ベンダ参加のテストが行われなかったため、仕様ができてから修正が必要になるなどの問題があったということを以前にお話しました。
これについて、ISO(?)でPDF/Aのテスト・スイート(テスト用のデータセット)を作ろうというプランがあるようです。PDF/A-2に備えてのことと思いますが。
現在、ドイツのPDF/A Competence Centerが第一候補のようですが、米国のNISTになる可能性もあるようです。
これに関連して、PDF/A Competence CenterにPDF/A準拠テストに関する簡単な資料が公開されました。
ざっと読んでみました。
・PDF/Aの妥当性検証は、ISO標準だけではなくて、2次仕様への準拠度も対象になる。
・現在のところ、参照にできる実装はない。
・PDF/A準拠は、ベンダ側に大きな努力が必要だ。
・PDFのライフサイクルとの関係
1)作成時。様々なソース形式からPDF/A準拠のPDFを作成する段階
2)修正時。PDF/A準拠になるようにPDFを修正する。
3)処理時。PDF/Aを変更した後でもPDF/A準拠になるように。
4)表示。単純にPDF/Aファイルを表示するだけでは不十分だ。
5)妥当性検証
・現在、妥当性検証をするツール:8種類ほどリストアップ
・PDFの妥当性検証の側面
1)カバー範囲: 標準のすべてをカバーする妥当性検証
2)深さ: フォントの場合なら、TrueType、OpenTypeの仕様との整合性、ICCカラープロファイルとの整合性、XMPなら、その元になっているRDFやさらにはXML、名前空間仕様との整合性検証を行う。
・PDF/A Competence Centerの技術作業委員会(TWG) はテスト・スイートの作成を準備している。
・次の手続き:テスト手続きの形式化、独立したテスト機関によるテスト、テスト・スイートを使って公式に検証ソフトを認定する。
ところで、この文書(英語版)ですが、英語なのに、ドイツ語方式の引用符の使い方をしています。
こんな感じ:![]()
面白いですね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年05月13日
PDF から別文書への内部リンク
Word 文書などで他の Word 文書内のブックマークへ飛ぶリンクを作成した場合、これを PDF にしたときにそのリンクが反映されないでしょうか?という質問をいただくことがあります。この問題については PDF Driver の FAQ にも既に記載してありますが、現状できません。
PDF Driver で外部リンクを持った Word 文書を PDF 化した場合、PDF 内部では、別文書(PDF や Word 文書)へのリンクを PDF で実現するために「リンク注釈」(Link annotation)を使用します。このときに「リンク注釈」は別文書に関連付けされたアプリケーションが開けるように「起動アクション」(Launch Action)を利用します。この「起動アクション」辞書内でリンクしたいファイルを指定するのですが、ここへ内部リンクを指定しても PDF ビューアがそれを解釈できないため、別文書への内部リンクはできません。これらの解釈が可能なビューアであれば、掲題のご要望に対応できるのかも知れません。
別の対応方法として、リンク先の文書も PDF 化した上でその PDF に対して明示的な宛先、或いは名前付き宛先でリンク先を指定するという方法もありますが、PDF Driver 単体で使用することを考えた場合、操作が繁雑になってしまって現実的ではないように思えます。
投稿者 numata : 08:00 | コメント (0) | トラックバック
2008年05月05日
PDFをベースとする各種標準仕様について(アップデート)
PDFをベースとする各種標準仕様についての状況を整理してみました。
特にPDF/Xについて、以前に取り上げて以降、PDF/X-4、PDF/X-5が新たにISOの仕様として出版されています。ISO 32000も、既に委員会ベースでは承認され、現在、出版へ向けて正式承認手続き中ということで、ISOでの仕様策定のスピードが上がっているようです。
従来は、ワープロなどで電子ファイルを作成する目的は紙に印刷することでした。インターネットと電子メールが日常のツールとして普及した現在では、ワープロなどで作成した電子ファイルは、紙ではなくてPDFを使って交換するのが普通となっています。
こういう、電子ファイルの利用形態の変化を考えますと、PDFは、今後の電子社会においては非常に重要な存在になると思います。
国際標準仕様は、そのPDFのバックボーンとも言えるものですので、速やかに仕様が決まることが望ましいと思います。
それを実際に使えるものにするために、ソフトウエアの実装者の役割もますます重要になるでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月30日
電子書籍システム
先日、松下電器の読書端末「ワーズギア」の生産終了の話をご紹介しました。
他にはどんなのがあるのだろう、また電子書籍の業界は、最近、どうなっているのだろうと気になりましたので、引き続いて少し調べてみました。
電子書籍の専用端末では、ソニーの「LIBRIe(リブリエ)」が有名なようです。
◎LIBRIe ソニー
・Webページ
EBR-1000EP
しかし、このリブリエもWebでは生産完了となっています。紛らわしい表現ですが生産終了のことのようです。
◎Flib
Googleで電子書籍で検索しますと Flibという電子図書館が上位にきます。これはシンガポールの E-Book SystemsPte Ltd.社が開発しているFlipBook技術を使っているようで、技術を売るために、電子図書館を作っているようです。やや本末転倒な気がします。
・イーブック・システムズ株式会社
が推進しています。ハードウェアはパソコンです。
◎パピレス
ここは、ハードウェアとしてはパソコンと携帯電話となっています。
ファイル形式と必要なビューア(パソコン)
・KeyringPDF形式 →(特別なDRM付きPDF)
・XMDF形式 →ブンコビューア(無料)
・.book形式 →T-Time(無料)
・Adobe eBook形式 →Adobe Reader
・蔵形式 →蔵衛門8デジブック
あと携帯に対応です。
◎eBookJapan
ここはコミック(漫画)中心です。
・ファイル形式は分かりませんが、専用リーダebi.BookReaderをインストールして使うようです。
パソコン(Windows)のみで携帯電話は未対応のようです。
ざっと見てみただけですが、こうしてみますと、電子書籍がだめというわけではなくて、どうも電子書籍用の専用端末がだめってことのようです。
いまは、携帯小説が好調という話を聞いていますが、このあたり、1980年代に登場したワープロ専用機がパソコンのワープロに押されて、2000年代に入って短い期間で絶滅したのをなんとなく連想してしまいます。専用のハードウェア+ソフトウェアは、汎用のハードウェアとソフトウェアに勝てないという一般化に、かなりの妥当性がありそうです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月29日
PDFに、印刷するときの用紙の横置き、縦置きを指定する方法はある?
次のような質問を受けました。
「PDFをプリンタで印刷するとして、プリンタに用紙を縦置き(ポートレイト)するか、横置き(ランドスケープ)で使うかを、PDFファイル上で指定する方法はあるのでしょうか?」
どうも、PDFの仕様書を見ても、そういう方法はなさそうです。
PDFでは、独自の座標系をもっており、左下、右上の概念はありますが、用紙という概念はありません。そして、PDFのページに設定できるのは、境界ボックスと90度単位の回転角度のみです。
これをプリンタが用紙の上にどうやって対応つけるかは、印刷する方の側の問題ということになります。
※PDFの境界ボックスについてはこちらをご参照ください。
2007年11月30日 PDFのページ境界とXSL-FOの設定方法
ところで、それに関連して、AdobeのPDF Driverを見ていましたら、LayoutタブにOrientation(方向)という設定があります。
・Portlait
・Landscape
・Rotated Landscape
という3つのメニューがあります。
これは一体何をするものなのでしょうか?良くわかりません。どうも、用紙の設定ではなくて、ページの内容の表示領域だけを変更してしまうようです。
(1)Wordで用紙を縦置きとして、Adobe PDF DriverでPortlaitを指定。
・Wordの設定

・Adobe PDFの設定

そうしますと、PDFは正しく出ます。
・
(2)Wordで用紙を縦置き(Wordの設定は(1)と同じ)として、Adobe PDF DriverでLandscapeを指定。
・Adobe PDFの設定
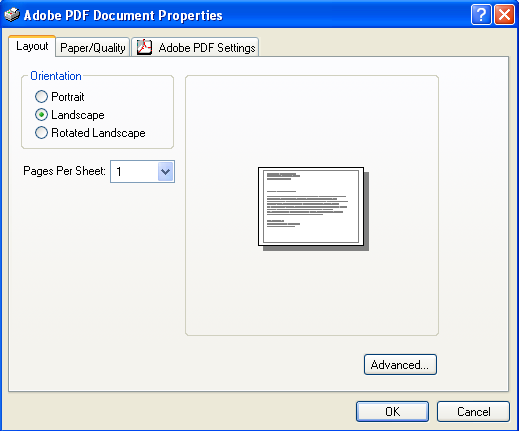
そうしますと、用紙は縦に使いますが、内容が横長になるようです。

Adobe PDF Driverのこのメニューは一体何のため?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月25日
PDF 1.7 仕様に用意されている注釈
昨日、リンク注釈について触れましたが、PDF の仕様には他にどのような注釈があるのか「PDF Reference, version 1.7」で確認したところ、Annotation Types として定義されているのは実に 25種類になります。では、それらすべてが Acrobat 8 Pro で使用できるのでしょうか?ちょっと調べてみました。
以下、左側が「PDF Reference, version 1.7」に記載されている注釈、右側が Acrobat 8 Pro の GUI で用意されているツールの名称です。ツールはメニューバー、ツールバーの両方に用意されていますが、ツールの名称としては主にツールバーにあるものを採用しました。
| PDF Reference | Acrobat 8 Pro |
|---|---|
| Text annotation | ノート注釈 |
| Link annotation | リンクツールまたはテキスト注釈で文字列を選択後「リンクの作成」 |
| Free text annotation | 引き出し線ツール、テキストボックスツール |
| Line annotation | 矢印ツール、線ツール |
| Square annotation | 長方形ツール |
| Circle annotation | 楕円形ツール |
| Polygon annotation | 雲形ツール |
| Polyline annotation | - |
| Highlight annotation | テキスト注釈で文字列を選択後「テキストをハイライト表示」、または「テキストにノートを追加」、またはハイライトツール |
| Underline annotation | テキスト注釈で文字列を選択後「テキストに下線を引く」 |
| Squiggly-underline annotation | - |
| Strikeout annotation | テキスト注釈で文字列を選択後「テキストに取り消し線を引く」、または「選択したテキストを置換」 |
| Rubber stamp annotation | スタンプ注釈 |
| Caret annotation | テキスト注釈で文字列を選択後「選択したテキストを置換」、またはテキスト注釈で位置を指定後「カーソルの位置にテキストを挿入」 |
| Ink annotation | 鉛筆ツール |
| Pop-up annotation | ※1 |
| File attachment annotation | メニューバーの注釈から「注釈ツール」-「ファイルを注釈として添付」 |
| Sound annotation | - |
| Movie annotation | - |
| Widget annotation | 署名、フォーム |
| Screen annotation | ムービーツール、サウンドツール |
| Printer's mark annotation | - |
| Trap network annotation | - |
| Watermark annotation | ※2 |
| 3D annotation | 3Dツール |
※1、Pop-up 注釈は、今回 Acrobat 8 Pro での対応を確認した注釈の内、「Text、Line、Polygon、Highlight、Underline、Strikeout、Caret、Ink」注釈の出力時に同時に作成されます。
※2、Acrobat 8 Pro には、透かしを追加する機能がありますが、Watermark 注釈は使用されないようです。
私の確認した限りこのようになりましたが、今回見つからなかった注釈の中には Acrobat 8 Pro が対応しているものもあるかも知れません。
投稿者 numata : 08:00 | コメント (0) | トラックバック
2008年04月24日
リンク注釈について
PDF の仕様にある「リンク注釈」とは具体的にどのような注釈なのかという質問がありました。
PDF の仕様(PDF Reference, version 1.7)では、リンク注釈は次のように定義されています。
A link annotation represents either a hypertext link to a destination elsewhere in the document (see Section 8.2.1, “Destinations”) or an action to be performed (Section 8.5, “Actions”).
つまり、リンク注釈とは PDF 文書内の「宛先」へのハイパーテキストリンク、または「アクション」を指定する注釈です。
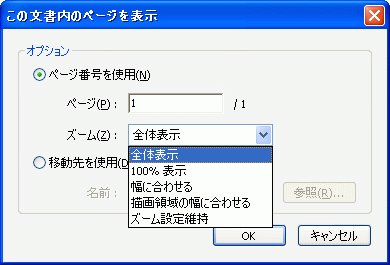
この宛先にはページ番号とその表示方法の指定ができ、表示方法としては仕様では 8種類が用意されています。例えば Acrobat 8 Pro の「リンクツール」を使用してリンク注釈の表示方法を編集すると、ダイアログでは「ズーム」として 5種類の表示方法(「全体表示」、「100%表示」、「幅に合わせる」、「描画領域の幅に合わせる」、「ズーム設定維持」)が用意されています。
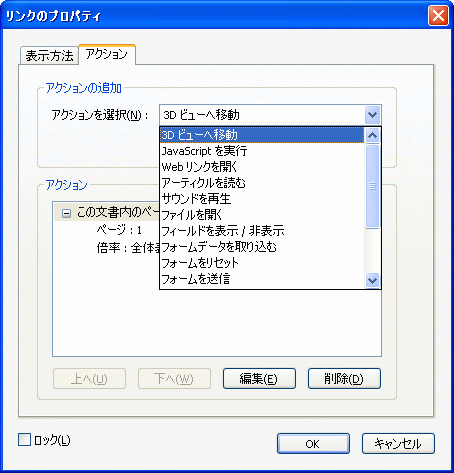
アクションでは、宛先と同じこともできますが、他文書内への宛先や URI 指定、Sound、Movie 再生といった PDF の仕様に用意されている様々なアクションを指定することができます。以下のキャプチャは、Acrobat 8 Pro の「リンクツール」に用意されているアクション項目です。
投稿者 numata : 08:00 | コメント (0) | トラックバック
2008年04月19日
PDF/A に電子署名をするとPDF/Aになるだろうか?続き
PDF/A Competance CenterのFAQページには、次のような一文があります。
「PDF/A ファイルは電子署名を含むことができますか?
はい。PDF/Aファイルに電子的に署名することは許可されています。市場ではPDF/Aファイルに電子的に署名するための様々なツール、方策、ソフトウェア・ソリューションが手に入ります。Acrobat ProfessionalもPDF/Aに電子署名するために使うことができます。
出典:FAQページ
ということなので、試してみました。
○PDF/A-1aファイルにAcrobat 8.1で電子署名して、適合度をチェックします。
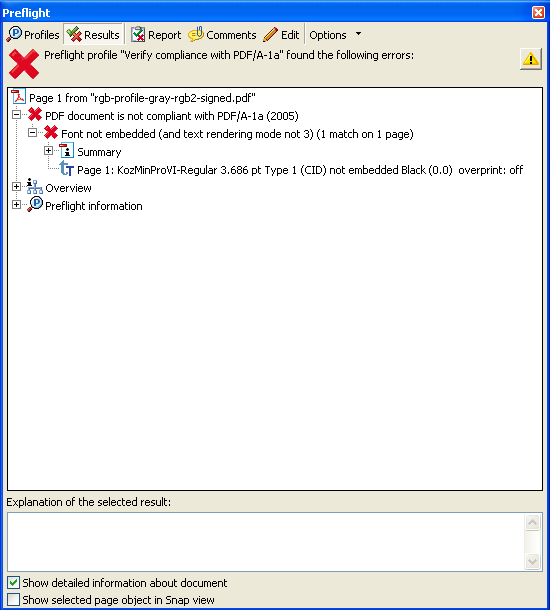
※PDFファイルは下記の(A)です。
あれ?
「PDF document is not compliant with PDF/A-1a(2005)」 となります。Actobat8.1で署名してもPDF/Aにならないようです。おかしいなあ。
使用したのはAcrobat 8.1Professionalです。
○電子署名するまえのPDF/A適合ファイル:
ファイルをダウンロード
(このファイルの検証結果は、昨日のブログのこちらにあります。)
○上のファイルにAcrobat8.1で電子署名して別名保存したPDFファイル(A):
ファイルをダウンロード
もう少しチェックしてみないといけないかもしれませんが、PDF/Aを使いこなすのは、慣れるまでいろいろ調べないといけないことが多そうです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月18日
PDF/A に電子署名をするとPDF/Aになるだろうか?
PDF/Aについては、既に何回かお話しています通り、日本ではまだあまり関心がないようですが、欧米(特に欧州)ではかなり関心があるようです。
アンテナハウスのXSL Formatterでは、組版した結果をPDF/Aに出力できます。FormatterでPDF/Aに電子署名する機能をサポートする計画があるか?という問い合わせが来ていました。
質問: Are there any plans to support digital signatures on PDF/A? If so, in what version can this be expected? If not, can XSL Formatter be used with signature modules that do support signatures on PDF/A?
PDF/Aファイルに署名すると、PDF/Aになるのではないかと、簡単に考えて、少し試してみました。
まず、FormatterでPDF/Aのファイルを作ります。Acrobat8.1でPDF/Aかどうか検証しますと、問題ありません。
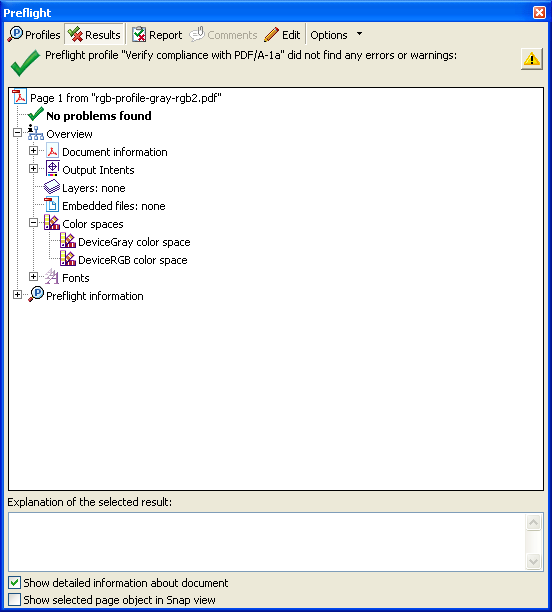
※Formatterで作成した署名前のPDF/A-1aファイルをAcrobat8で検証した画面
これに、PDF電子署名モジュールで不可視署名をつけます。そうして、Acrobat8.1で検証しました。
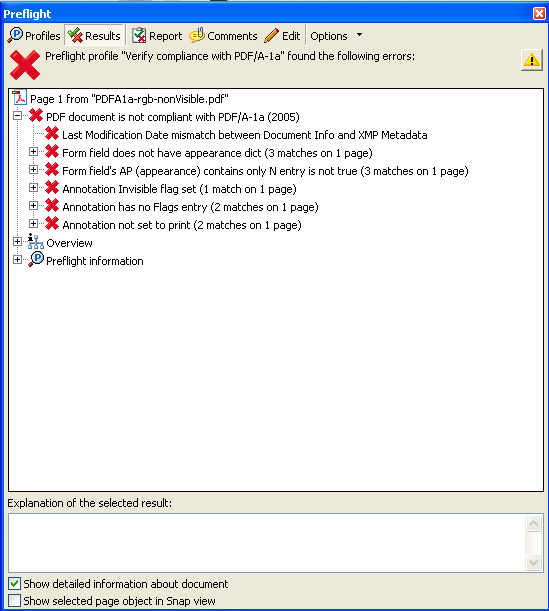
※PDF/A-1aファイルに不可視署名をつけた結果のPDFをAcrobat8で検証した画面
残念ながら、PDF/Aにはならないようです。
では、可視署名をつけたらどうなるでしょうか?
これを試してみるために、PDF電子署名モジュールで可視署名をつけて、Acrobat8.1で検証しました。
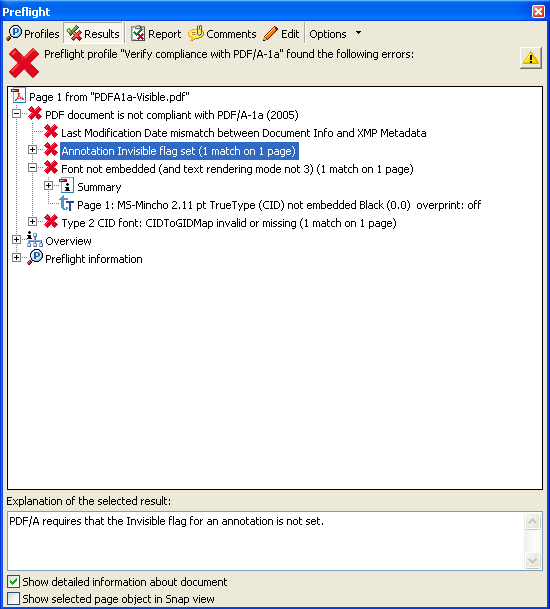
※PDF/A-1aファイルに可視署名をつけた結果のPDFをAcrobat8で検証した画面
こちらも残念ながら、PDF/Aにはならないようです。
ということで、署名する前のPDFがPDF/A準拠になっていても、なにも考えずに署名するとPDF/A準拠ではなくなってしまいます。どうやら、電子署名の付け方もPDF/A対応にする必要がある、ということのようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月02日
OpenOffice.orgでIPAフォント設定時の縦書き用グリフ問題(問題発見!)
さて、「IPAフォントに不具合がある」ということなので、色々と調べてみたのですが、最後に漸く、それらしき問題を発見しました。
昨日、サーバベース・コンバータでフォントを埋め込んで作成したPDFを、今度は、「PDFViewer SDK」を使って表示してみます。
PDF Viewer SDKは、PDF表示機能をアプリケーションに組み込むための開発キットなのですが、Windows画面に文字を表示する方法を切り替えることができます。
PDFにフォントを埋め込んだ場合、各文字のグリフがPDFの中に埋め込まれます。PDFには同時に文字コードへの対応表も定義されます。
(1)PDFにフォントが埋め込まれている場合、通常は、そのグリフを使って表示します。
(2)しかし、グリフを使わずに、文字コードをWindowsに渡して文字を表示させることもできます。この場合、Windowsが、フォントファイルから縦書きか横書きかで適切なグリフを探して表示するはずです。
また、WindowsGDIには、GDIとGDIPlusと2種類があります。GDIPlusの方が新しく、高度な表示機能があります。PDF Viewer SDKでは、GDIを使う表示とGDIPlusを使う表示を切り替えることができます。
この組み合わせは4通りになりますが、4通りそれぞれの表示を試して見ました。
1.埋め込みフォントのグリフを使ってGDIPlusで表示した画面

2.埋め込みフォントのグリフを使ってGDIで表示した画面
3.文字コードを使ってGDIPlusで表示した画面
4.文字コードを使ってGDIで表示した画面
びっくり!
文字コードを使ってGDIPlusで表示したときだけ、縦書きの句読点のグリフが横書き用グリフになってしまっています。
どうやら、WindowsはGDIPlusの時だけ、「IPA明朝」の縦書き用のグリフを正しく取り出せないようです。推測しますに、Microsoft WordやOpenOffice.orgで、「IPA明朝」を指定した縦書き文書の句読点が正しく表示できたのは、文字コードでGDIを使って表示していたからかもしれません。
結局、「IPA明朝」にはどうも問題があるらしいことまでは分かりました。しかし、実際のところ、これがIPAフォントの不具合なのか、それともGDIPlusの不具合なのかは、これだけでは必ずしも断言できないと思います。最後は、「IPAフォント」の中を覗いて見るしかない?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年03月25日
透明の扱いについて(メモ)
先日、「萩さん日記」という、とても興味深いブログを見つけました。
http://hagi-san.blog.ocn.ne.jp/hagisan/
XPSにかなり期待しているようです。
どこの方かは存知上げませんが、プロフィールを拝見しますと、「プリンタ、ページ記述言語 (PDL)、電子ドキュメント関連製品の開発や RIP コア技術の開発を 30 年以上」とありますので、中々、すごいキャリアです。尊敬します。もう、1年以上前から書かれていたようで、もっと早く知っていれば良かったのですが。
最新の記事は、「透過レイヤーを含む PDF 生成における問題」という内容です。
概ね、ここに書かれている通りと思いますが、アプリケーションを開発している立場からちょっとコメントさせていただきます。
透過は、GDIプリント・パスではサポートできないというのは正しいと思いますが、じゃあ、「WPF対応のアプリケーションを開発し、透過をサポートするXPSを生成。。。XPSをPDFに変換」とは、たぶん思わないのじゃないでしょうか。
GDIには、透明を表示するAPIがありますので、画面上に透過を表示することができます。また、GDIPlusは透過をサポートするPNGも表示できます。ですので、透明をWindowsGDI画面に表示するのは比較的簡単にできます。
そうしますと、あとは、PDF出力なのですが、PDFを直接生成すれば、透過をサポートするのはそんなに大変ではありません。
例えば、「書けまっせ!!PDF」では、透明度を設定したPNGを画面に表示することもできますし、PDFに出すこともできます。(でも、GDIプリンタにはちゃんと出せないようです。これは、プリンタ・メーカの責任?)
◎透明を設定したPNGと透明を設定しないPNGを画面に表示した例(「書けまっせ!!PDF3」)
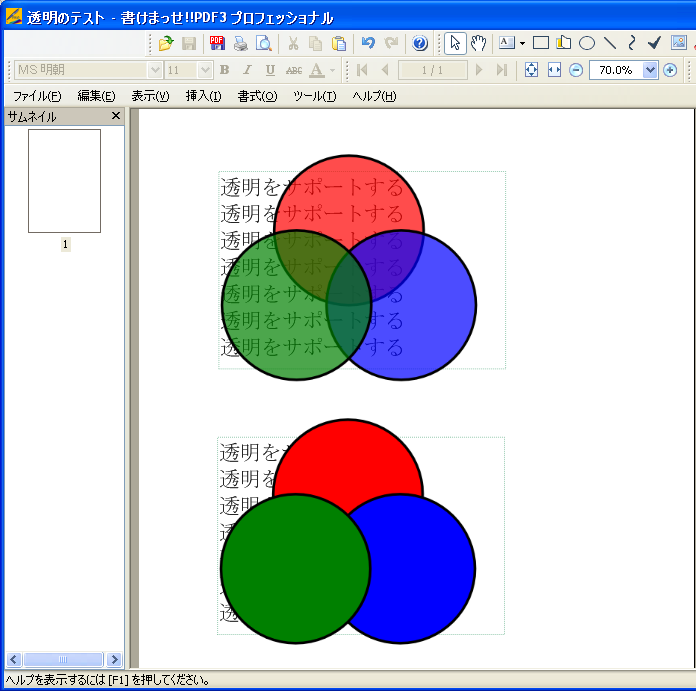
◎上のファイルをPDFに出して、Adobe Readerで表示
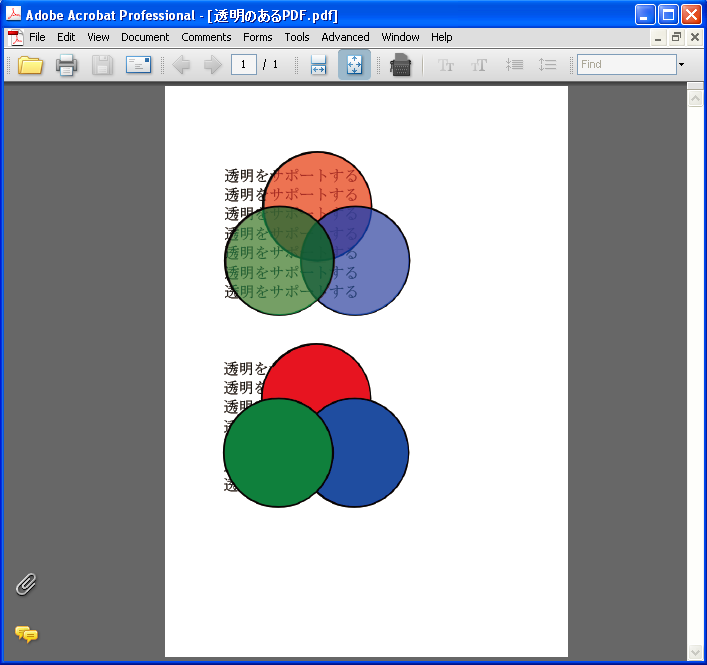
※PDFファイルをダウンロード
私などは、むしろ、WPFをサポートするアプリケーションを開発する方が大変じゃないかと思います。それに、WPFをサポートすることで、GDIのみのWindowsでは動かないというのは困りますので、GDIとWPFを両方サポートしなければならなくなって、2重の開発投資が必要になります。新しいアーキテクチャに直ぐには乗り換えることができない、ということなのですが。
こんなことを言っていますと、自分が年を取っているなと感じるのではありますが。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年03月03日
電子文書と紙文書 — PDF電子署名の場合
昨日お話しましたことを整理しますと、電子署名の用途のうち、「署名者である人間が承認したという意思を確認するための署名では、署名対象文書の内容が正しく画面なり紙に可視化されていること、そして、それを署名者が認識したという事実が保証されないといけないこと」、となります。
電子文書のうち、PDF以外では、これを技術的に保証するのはなかなか難しいと思います。
PDFでは、どうでしょうか?PDFは、紙に印刷する状態を電子ファイル化したものですし、そのファイル内の命令の仕様が公開されていますので、他の電子文書よりは、保証しやすいと思います。
しかし、PDFでも次のような例外があります。
・PDFではJavaScriptを埋め込んで、可視化状態をプログラムで、条件により変更してしまうことができます。
・可視化するビューアやツールによって表示内容が変わってしまうリスクがあります。これに類似する分かりやすい例は、PDFで画面上に墨を塗って文字を消したように見せても、実はその文字がファイルの中に存在していて、他のツールで見えてしまうということがあります。
■参考
2006年08月13日 PDFで隠したはずの個人情報丸見え — について
PDFで隠したはずの個人情報が丸見えになるということは、「PDFでも可視化される状態が、状況によって変わってしまうことがありうる」、ということを示しています。
このためPDFの署名では、「法的内容証明」という機能(オプションです)があります。
■参考
PDF Reference 1.7
8.7.4 Legal Content Attestations
pp.742~pp.743
このあたりは難しいのですが、PDFの電子署名では、上に述べましたような、可視化の方法によっては、相手をミスリードする可能性があることを踏まえて、署名時に、ミスリードしそうな内容をチェックする機能が定義されているということです。この機能はオプションで、アンテナハウスPDF電子署名モジュールは、残念ながら、未対応です。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年02月02日
PDFの限界
最近、いや、昔からかもしれませんが、PDFで配布した情報を、意図しない相手に勝手に流用されたくない、ということで、セキュリティを付けたいというご相談をよく受けます。
例えば、(1)PDFの有効期限を設定しておき、その有効期限を過ぎたら内容を見えなくしたい、とか、(2)PDFをAdobe Reader表示しても保存させないようにしたいなどはその代表的なものです。
このようなセキュリティ設定は、PDFの標準のセキュリティ・ハンドラではできません。
しかし、無論、現在のインターネット環境とソフトウエアの技術をもってすれば、実現できることです。例えば、DRM(Digital Rights Management)を使えば、かなりコントロールができます。そこまでいかなくても、Javascriptを使えばある程度擬似的に実現はできます。完璧ではないですが。
市販の商品やサービスでもこういうことを実現しているものがあります。
しかし、問題なのはPDFの表示には、ほとんどの人がAdobe Readerを使っていることです。従って、実際のところ、セキュリティの実現はAdobe Readerの機能に依存する部分が多いということになります。
このことは、いま実現できていることでも、Adobe Readerに依存している以上、将来、Adobe Readerの機能が変わってしまえば、どうなるか保障できなくなるということを意味します。
そんなことから、どうも、PDFは情報を配布したり、情報を交換するために必要な、セキュリティという部分にかなり大きな限界がある、と感じています。やはり、PDFの標準仕様として、セキュリティ関連機能をもっと強化する必要があるのでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年01月17日
PDFの相互運用性問題 (1) — 相互運用性問題とは?
PDFの規格のISO化が進んでいることは、既に何回もお話しましたので、ご存知の方も多いと思います。これは、私どもPDFのサードパーティにとりましても、大変喜ばしいことです。
PDFのISO規格が制定されれば、日本でもアドビ以外のPDFベンダには追い風になり、サードパーティ製品のシェアがますます高くなることと思われます。
但し、その時の懸念事項として「PDFの相互運用性」があります。
例えば、PDF編集ソフト間の相互運用性を考えて見ます。
多くの場合、PDFはデータの公開出版、つまり、一方通行に使っていると思います。また、以前は、高価なAcrobatでないとPDFを編集できないということで、PDFを編集する機会は比較的少なかったものと思います。しかし、最近は、「いきなりPDF Edit」のような廉価なPDF編集ソフトが発売されていますし、3月には「JUST PDF作成・高度編集」というようなPDF編集ソフトが発売されます。
そうしますと、A社のソフトで作成したPDFを取引先に渡して、B社のソフトで編集したり、その逆のことが行われるようになる頻度が増えてくると思います。
このように、さまざまなメーカのPDF編集ソフトが使われるようになったとき、異なる会社のソフトで作成したPDFをうまく編集できるか、ということが編集ソフトの相互運用性です。
これは、PDF編集だけではありません。以前に、
2007年11月20日PDFと署名(48) — PDFの電子署名とタイムスタンプの相互運用性
でも、お話しましたが、A社の製品で電子署名したものを、B社の製品で検証するという頻度が増えてくることになります。
PDFは、誕生の当初から作成ソフトと閲覧ソフトが別、PDFの印刷利用などでも作成したのとは別のソフトで印刷のための処理をする、という具合に、PDFというファイルを媒介にして、様々なソフトがそれを共有するという性格の強いものでした。つまり最初から相互運用を前提としているものです。
このあたりは、PDFとMicrosoft Officeファイルとで、かなり異なる点です。
しかし、従来は、日本のPDF市場はアドビが支配する市場でしたので、実態としては、様々な会社のPDF関係ソフトの間の相互運用性で問題が顕在化することが比較的少なかったわけです。しかし、今後は、相互運用性問題がかなり大きな問題になってくると思われます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年12月30日
PDFの世界標準ISO 32000がISO標準になったら?(4)
昨日は、PDFの仕様ISO DIS 32000が、ISOの標準規格になったら、ますますPDFソフトの種類が増えるだろうもお話しました。
2007年12月29日 PDFの世界標準ISO 32000がISO標準になったら?(3)
では、そのようなPDFソフトはすべてISO規格準拠と主張できるのでしょうか?もし、そうだとしますと、自称ISO準拠のPDFソフトが雨後の筍のように登場することになります。
そうなりますと、何からの基準をもって、PDFソフトがISO規格準拠かどうかを認定することが必要となるでしょう。そうしないと、自称ISO準拠のPDFソフトで作成したPDFを相互運用できないことになります。そうなればISO規格の権威は地に堕ちてしまいます。
ISOの規格で最も成功したのは、組織の品質管理に関する規格ISO9000ファミリーだそうです。
ISO9000では、審査登録機関があって、そこで認定を受ける仕組みがあり、世界で80万箇所の事業所が認定を受けているのだそうです。ISO規格をベースとするコンサルティングが大きなビジネスになっているようです。
将来的には、PDFも、恐らくこのような認定が行われるようになるのではないかと思います。PDFの場合は、供給者が何十万箇所にのぼることは考えられませんので、認定ビジネスを成立させるのは、かなり難しい課題かもしれません。
しかし、PDFは将来的には紙の代わりに世界中に流通するメディアになるでしょうから、相互運用を保証するための認定の仕組みが必要ではないかと思います。必要性があればビジネスが生まれるのは自然。きっとどこかで誰かがそのようなサービスを始めることでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年12月29日
PDFの世界標準ISO 32000がISO標準になったら?(3)
これまで何回か指摘していますが、紙は2000年以上の歴史をもち、現代でも情報媒体として、プリント媒体は非常に有力なのは間違いありません。日本での紙の生産量は、電子化・ペーパーレスが叫ばれる今でも純増になっているそうです。
一方、情報を出版したり、交換したり、蓄積する媒体として考えますと、紙はあまり効率が良くありません。特に、遠隔地に送付したり、膨大な量の情報を蓄積したり、あるいは、検索などを考えますと効率が悪いのは明らかです。紙ベースで業務を進めるようなシステムでは、数人の企業であればともかく、中堅以上の企業では、電子的なシステムに効率面でまったく対抗できないでしょう。
一方、情報を可視化し、閲読するための媒体として紙は非常に有力です。そうしますと、電子化・デジタル化された情報を紙媒体を前提として可視化するという方法は、電子化された・デジタルの世界と人間の可視世界とをつなぐ非常に重要な手段となります。
このデジタル情報を紙媒体に可視化する、という点で、現時点でもっとも有力な媒体はPDFです。しばらくの間、恐らく10年やそこらの期間、その地位が揺るぐことはなさそうです。
私は、日本ではPDFについて、あまり好意的・前向きに評価していない人が多いような印象を受けています。日本では、欧米に比べて、ややPDFの採用が遅れているように思います。
しかし、PDFが世界標準になることで、官公庁や行政をはじめ、日本でもPDFの利用にますます拍車がかかることは間違いありません。
需要が膨らめば、供給が増えるのが経済の原則でしょう。そうしますと、PDFの供給元が増えて、PDFの種類がますます増えてきます。
情報交換の媒体にPDFを使うということを円滑に実現するには相互運用性が重要です。アドビ製品だけで話が済んでいた時代には、相互運用性はあまり問題にならないでしょうが、供給元が増えて、さまざまなPDFが出てきますと、相互運用性をどう維持するかが、最も重要な課題となるように思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年12月25日
PDFの世界標準ISO 32000がISO標準になったら?(2)
前回の「PDFの世界標準ISO 32000がISO標準になったら?(1)」に続いて、もう少し考えて見ます。それは、2008年のPDFの行方を占うことでもあります。
PDFのISO規格の成立までの過程について、いまひとつ、まだ良く分かっていませんが。
先日、XML開発者の日に、OOXML(Office Open XML形式)のBallot Resolution Meeting(BRM)について村田さんの説明がありました。
その日の説明では、確か、「OOXMLはISOのFast Trackの投票は通過しなかったのですが、投票に際して寄せられたコメントに対して提案者であるECMAが対応する回答を準備中。BRMにおいて、その回答に基づいてOOXML規格書の変更について審議、BRM終了後1ヶ月以内にECMAは最終規格案を作成する。それに基づいて各国は、賛成、反対、棄権の投票を変更できる。最終的に、2/3の賛成があれば、規格案はISO規格として採用される」、ということだったと思います。
一方、PDFのISO規格であるDIS 32000は、ISOのFast Trackの投票を通過しました。
2007年12月06日 PDF仕様 ISO投票を通過
で、この後の予定について、AIIMのブログ
には次のようにあります。
・投票を通じて、多数のコメントを受け取った。その大部分は文章に関わるものであるが、それを規格書の改訂案に盛り込む必要がある。
・反対の投票をした人は、コメントの扱いについて満足した場合、態度を賛成に変更することができる。
・もし、反対投票者が、コメントによって賛成に変更しなかった場合、修正された規格書を対象に2ヶ月の投票期間で再投票する。
・反対投票者が、コメントで賛成に変ったらコメントによる修正をISOの規格書に盛り込み、即、出版となる。
Fast Trackの投票で、賛成多数で通過したPDFの規格案と、賛成表が足りなかったOOXMLの規格案で、その後の規格書出版までの手続きがどのように違うのか、あまり良く分かりませんが、「OOXMLはBRMでは決着しないで必ず再投票になるが、PDFは再投票なしにBRMで決着する可能性がある」ということなのでしょうか?
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年12月21日
PDFの世界標準ISO 32000がISO標準になったら?(1)
PDF1.7をベースとした、ISO標準(ISO 32000)が来年(2008年)には、標準として認められることはほぼ間違いないと思います。そうなったとき、どんな変化が起きるのでしょうか?置きうるシナリオを考えて見ました。
1.PDF仕様の利用に関する正当性
ユーザは今まではPDFの仕様はアドビのものであり、従ってアドビ以外のPDFを使うことは、ある意味では、アドビの権利を侵害するかもしれないということを心配していたかもしれません。多くのユーザは、そこまで心配をしなくても、アドビのPDFが正統なものであり、多少価格が高くてもアドビの製品を買おうという決定を正当化するものだったと思います。
しかし、PDFの仕様がISO の標準として出版されれば、PDF仕様の利用に関してはこうした心配がなくなります。
このことは、ユーザがPDF製品を、心理的には、自由に選択することができるようになります。一方において、ユーザが自分自身の責任でPDF製品を評価して選択しなければならないことになるでしょう。
普通のユーザにとっては、自分の手で、PDF製品を評価して選択することなどは、あまりやりたくないことでしょうから、第三者の評価、推薦、場合によってはランク付けのようなものに需要が生まれるのではないかと思います。
2.PDF製品のメーカにとっての動機付け
PDF製品のメーカにとっては、いままでは、クローン製品のメーカという立場でしたが、今後は標準仕様をサポートするメーカということになり、PDF製品の供給に、大義名分が与えられますので、大きな動機付けになるでしょう。このことは、PDFをサポートするソフトウエア・メーカが、ますます増えることになり、メーカ間の競争もますます激しくなることは確かでしょう。
3.PDFが正しいかどうかの評価
現在、PDFが正しいものかどうかを評価する基準は、恐らくAdobe Readerで表示できるかどうか、どいうことが第一になっているだろうと思います。
これは、言ってみれば、Webページが正しいかどうかを、ブラウザで表示できるかどうかで評価しているようなものです。
しかし、Webページをブラウザで表示できるかどうかでその正しさを判定するのは、技術的には誤りです。本当は、Webページを記述するためのHTMLやXTHMLの定める文法に合致しているかどうかで評価しなければならないのです。
Webページの場合は、そういう妥当性を検証するツールやサービスはいくつかあります。
・W3CのHTM:/XHTML 検証サービス
・Another HTML-lint
PDFについても同じように妥当性を検証するツールが必要なのですが、現在は、そういうものはないように思います。ISO標準になれば、当然に、そういうものが揃わなければならないと思います。誰がそろえるか?それが課題でしょうけれども。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年12月12日
PDF のアクセス権限
PDF は権限パスワード(オーナーパスワード)を設定する際に閲覧者に与える操作の許可を設定することが可能です。PDF の仕様では、このパスワードによる操作の許可が、以下のフラグセット(「User access permissions」)により決められています。
| BIT POSITION | MEANING |
|---|---|
| 1-2 | Reserved; must be 0. |
| 3 | (Revision 2) Print the document. (Revision 3 or greater) Print the document (possibly not at the highest quality level, depending on whether bit 12 is also set). |
| 4 | Modify the contents of the document by operations other than those controlled by bits 6, 9, and 11. |
| 5 | (Revision 2) Copy or otherwise extract text and graphics from the document, including extracting text and graphics (in support of accessibility to users with disabilities or for other purposes). (Revision 3 or greater) Copy or otherwise extract text and graphics from the document by operations other than that controlled by bit 10. |
| 6 | Add or modify text annotations, fill in interactive form fields, and, if bit 4 is also set, create or modify interactive form fields (including signature fields). |
| 7-8 | Reserved; must be 1. |
| 9 | (Revision 3 or greater) Fill in existing interactive form fields (including signature fields), even if bit 6 is clear. |
| 10 | (Revision 3 or greater) Extract text and graphics (in support of accessibility to users with disabilities or for other purposes). |
| 11 | (Revision 3 or greater) Assemble the document (insert, rotate, or delete pages and create bookmarks or thumbnail images), even if bit 4 is clear. |
| 12 | (Revision 3 or greater) Print the document to a representation from which a faithful digital copy of the PDF content could be generated. When this bit is clear (and bit 3 is set), printing is limited to a low-level representation of the appearance, possibly of degraded quality. (See implementation note 25 in Appendix H.) |
| 13-32 | (Revision 3 or greater) Reserved; must be 1. |
さて、Acrobat 8 Pro で「Acrobat 5.0 およびそれ以降」のセキュリティ設定を行った場合にどのフラグがセットされるのかを実際に調べてみました。
※ 現在、「Acrobat 5.0 およびそれ以降」でセキュリティ設定を行うと、8bit の設定が可能な「Revision 3」が使用可能となります。
| Acrobat 8 Pro の GUI で表示される項目 | BIT POSITION | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 変更を許可 | 印刷を許可 | テキスト、画像、およびその他の内容のコピーを有効にする | スクリーンリーダーデバイスのテキストアクセスを有効にする | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| 許可しない | 許可しない | - | - | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 許可しない | 低解像度(150 dpi) | - | - | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| 許可しない | 高解像度 | - | - | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 |
| ページの挿入、削除、回転 | 許可しない | - | - | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| フォームフィールドの入力と既存の署名フィールドに署名 | 許可しない | - | - | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 注釈の作成、フォームフィールドの入力と既存の署名フィールドに署名 | 許可しない | - | - | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
| ページの抽出を除くすべての操作 | 許可しない | - | - | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 |
| 許可しない | 許可しない | ON | (自動的に ON) | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 許可しない | 許可しない | - | ON | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
Antenna House PDF Driver のセキュリティ設定には、「変更を許可」に「すべての操作を許可」という項目があります。これは「印刷」の許可設定のみを行いたい場合に用意したものですが、Acrobat にはそれに対応する項目が用意されていません。そのためか、Acrobat でその設定がされた PDF を開くと「変更を許可」が「ページの抽出を除くすべての操作」となってしまいます。
投稿者 numata : 08:00 | コメント (0) | トラックバック
2007年12月10日
PDF vs Mars
昨日は、PDFとXPSの比較をご紹介しましたが、序に(といってはなんですが)、Marsの動向をチェックしておきましょう。
Marsについて公開されたのは、XML2006だったと思います。それから約1年経過した訳ですが、2007年11月にMars Reference 0.8が公開されています。このバージョン番号から言ってもまだ未完成です。
前回、2006年12月08日PDFのXMLフォーマットが登場!?でMarsを紹介しました。この時の仕様書は、0.7版でした。そうしますと、1年間で仕様書のバージョンが、0.1進んだことになります。
Marsは、XPSと同じくXMLベースです。アドビのMarsについてのフォーラムを読んでいますと、MarsはPDFと完全互換とし、PDFとMars間のラウンドトリップができることを目標にしているようです。
XPSは、例えばフォントについて言えば、昨日もありましたがType1フォントはサポートしていませんし、TrueTypeフォントさえもサポートしておらず、OpenTypeサポートに絞っているようです。
それに対して、PDFとMars間は、実用的に100%互換にするつもりなのでしょう。そうしますと、PDFとMarsの2つの仕様を保守していく意味があるのか?ということが当然ながら疑問になります。フォーラムでもその点質問がありますが、どうもこれに対しては、Marsは、XMLベースのワークフローへの統合というメリットを訴えています。
XMLベースになることで、データを取り出したり、新しい名前空間を使って独自のXML構造を埋め込んだりというような使い方が可能になるというのは確かにメリットを感じます。PDFにも、タグ付きPDFとか、XMPでメタデータを付けるなどの構造をいれる方法はありますけれども、やはりネイティブXMLの方がその辺は楽になると思います。
Marsの本体は、SVG1.1を独自拡張したものなので、SVGが進化していくとMarsとの関係がどうなるか、多少の疑問を感じますが、そのあたりSVG仕様の進化も遅いですから。
Dr. Macroのブログには、Marsが普及するまでに5年以上かかるとありました。
Adobe MARS: Looks Interesting (2006年12月)
もう1年経過した訳ですが、XMLベースになっているというメリットだけだと、現在のPDFを置き換えるだけのメリットとは言えません。仕様書が1年で漸く0.1バージョン・アップしたのみと言い、このペースだと、普及するのに5年じゃなく10年以上掛かる?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年12月08日
ISOにてDIS 32000(PDF1.7)投票で残念なこと
一昨日、ISOでのPDF仕様の投票結果は、賛成多数で通過ということをお話しました。
これで一つ残念なことがありました。
それは、コメント付きの賛成投票国として、英国、米国、ドイツ、スイスが、それぞれ、コメントを、13、125、11、19件付けていたということです。フランスは37件のコメント付きで反対です。
ところが日本は、コメントなしの賛成になっていました。
米国、英国などのコメントは、仕様書に対する、誤りや意見を述べたものと思います。ISO DIS 32000の仕様書は、PDF Reference1.7を元にして、大急ぎで作成されたもので、私もざっと見ましたが、多少疑問点や直す方が良いと感じるところがありました。決して、完成された仕様とは言えない状態なんですね。
米国では、大勢の参加者で、この仕様に対してコメントをつけています。
一部はここに公開もされています。
http://pdf.editme.com/PDFREF
要するにコメントの数は、(フランスはどうか分かりませんが)、関係者のPDFに対する熱の高さ、温度の高さを示していると言えます。
この数字から判断しますと、PDFに熱心な順から、米国>スイス>英国>ドイツ ということでしょうか。
フランスも反対意見も多いにせよ、熱心といえます。
それに対して、日本は、先進国のなかで一番PDFに冷淡?
そんなことを考えますと、日本からももっとコメントを出すべきでした。私なども気が付いたことがあったにも関わらず、なにもコメントを出せなかったのが残念です。いまさら言っても仕方ありませんが。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年12月06日
PDF仕様 ISO投票を通過
PDF 1.7をベースとするISO標準仕様案 DIS 32000に対する投票は、13対1で無事通過したようです。
○コメントなしの賛成国:オーストラリア、ブルガリア、中国、日本、ポーランド、南アフリカ、スペイン、スウェーデン、ウクライナの9カ国。
○コメント付きの賛成国:英国、米国、ドイツ、スイス
○反対国:フランス
○保留:ロシア
総投票数14国のうち、13国(93%)がポジティブ、1国がネガティブ。
コメント総数は205件あり、2008年の1月21日から23日の会議にコメントへの対応が報告されます。
全員が満足すれば、その時点で、PDF標準はISO仕様となります。もし、事態が紛糾すれば、2ヶ月のFDIS投票となるようです。
いずれにせよ、PDFの仕様が、ISOの標準として出版される時期が確実に近づいてきています。
我々サードパーティにとっても、来年には、私達の製品は、もはやクローンではなく、ISO標準を実装した製品と主張することができるようになり、大変に喜ばしいことです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年12月04日
PDFと長期署名(17) — PDF独自の長期署名仕様をどうするか?
「PDF千夜一夜」では、過去16回にわたって、PDFと長期署名について考えてきました。
現在、長期署名については、ECOMで実証実験が進んでおり、2007年度も多数の企業が参加して相互運用実験を行っています。
アンテナハウスは参加していませんが、関連会社のラング・エッジがXAdESに積極的に取り組んでおり、実証実験にも参加してます。この実証実験は、なかなか大変なようですが、有意義なものだと思います。
さて、PDFに長期署名を施すことはできますが、その結果は、PDFファイルにはできません。現在の時点で長期署名を施した結果をPDFとして保存できる仕様はないからです。
この仕様について、日本独自のPDF長期署名仕様を長期署名JISの中に盛り込むという動きがあり、この案が当初のECOMの長期仕様に関するJISへの提案に盛り込まれていました。しかし、その後、これについては大きな問題があるということが分かりました。現在、下記に掲載されている10月17日付けの最新案からは削除されたようです。
http://www.ecom.jp/LongTermStorage/esprofile.html
さて、そうなりますと、PDFの長期署名仕様をどうするか、ということが改めて大きな検討課題となります。
これについて、私は、現在の時点では、次のように考えています。
まず、日本独自のPDF仕様を考えるのは、止めるほうが良いと思います。一番大きな理由は、いまのソフトウエア業界では、日本独自の仕様というものは、全く通用しなくなっているのではないかということです。日本独自に関わらず、独自仕様というものが難しくなっているとも思います。
結論を急ぎ過ぎかもしれませんが、独自仕様は、結局、コスト的に非常に大きなものになります。米国や中国のような大きな市場であれば、なんとかなるかも知れませんが、日本のような中途半端な規模の市場で、独自仕様を考えたら、海外勢にコスト的に全く太刀打ちできなくなってしまいます。短期的には成功しそうにみえても、長期的には必ず駆逐されてしまうのではないでしょうか。
そうなりますと、もし、仕様を作るなら相当に大きな視野でものを考えて、世界をリードできなければならないと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年11月30日
PDFのページ境界とXSL-FOの設定方法
今日の会議で、営業担当の報告を聞いていましたら、お客さんから「XSL FormatterでPDFを出力する際に、トンボの外側に情報を出すことができるかどうか。」という質問を受けて戸惑っていたようです。
そこで、ちょっと調べて整理してみました。
○PDF ReferenceではPDFのページ境界について、次のような項目が設定できることになっています。
※PDF Reference 1.7 pp.962-966
(1)メディアボックス:ページを印刷する用紙の物理的領域
(2)クロップボックス:ページの内容の範囲領域、通常はメディアボックスと同じ
(3)ブリードボックス:書籍・雑誌などの出版物を仕上げるときの絶ち落とし分を含む領域
(4)トリムボックス:書籍・雑誌などの出版物の仕上げページ領域
これを図示しますと、次のようになります。
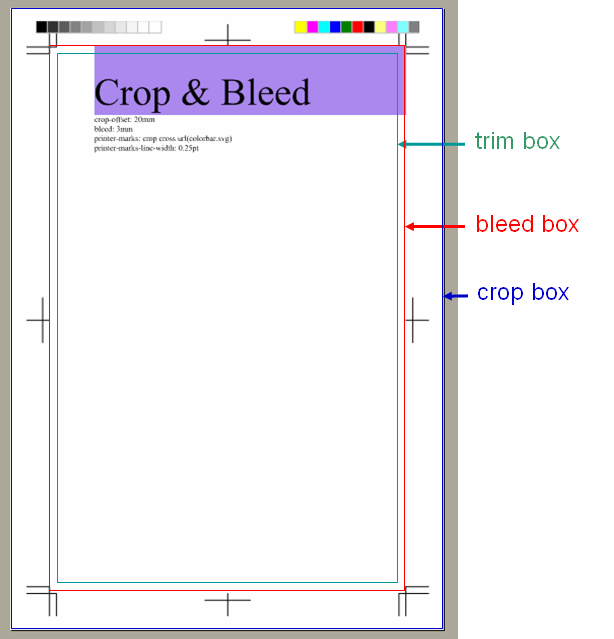
XSL-FOではページをfo:simple-page-masterで指定します。ページのサイズはそのpage-width属性で幅を、page-height属性の値で高さを指定します。fo:simple-page-masterは、PDF上ではトリムボックスの大きさとして指定することになります。XSL-FOの仕様では、クロップボックス、ブリードボックスに相当する領域の設定方法はありません。
アンテナハウスのXSL Formatterでは、独自拡張により、PDFのクロップボックス、ブリードボックスを指定することができます。いずれも、fo:simple-page-masterの属性として次のように指定します。
クロップボックス:axf:crop-offset, axf:crop-offset-top, axf:crop-offset-bottom, axf:crop-offset-left, axf:crop-offset-right属性の値で、トリムボックスの外側へのはみ出し距離を指定します。
ブリードボックス:axf:bleed, axf:bleed-top, axf:bleed-bottom, axf:bleed-left, axf:bleed-right属性の値で、トリムボックスの外側へのはみ出し距離を指定します。
また、トンボを指定することができます。
トリムボックスの外側には、グラフィックスをSVGで指定できます。SVG形式であれば、テキストや、任意の画像を指定することもできます。SVGでカラーチャートを出すこともできます。
次に、サンプルのFOとPDFがありますので、ご参照ください。
・ファイルをダウンロード(FOファイル)
・ファイルをダウンロード(PDF)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年11月15日
CSS仕様の熟成度合い
W3CのCSSブログにCSS仕様の熟成度合いに応じてレベル分けした説明が出ていました。
http://www.w3.org/blog/CSS/2007/11/01/css_recommendation_track
1.探索段階
まだ、未完成で、大幅に変わる可能性あり。
* CSS Grid Layout
* CSS Advanced Layout
* CSS Generated Content
* CSS Tables Level 3
2.書き直し
仕様の大きな部分を書き直し。
* CSS Text Level 3
* CSS Text Layout Level 3
* CSS Fonts Level 3
3.洗練させる段階
仕様の範囲や機能がほぼ完成した段階。しかし、また出版、査読などのサイクルが必要。
* CSS Backgrounds and Borders Level 3
* CSS Multi-column Layout Level 3 この段階の終わりに近い
* CSS Values and Units is almost at this stage
* CSS Box Module Level 3
4.安定化段階
勧告候補の準備が出来ている。
* CSS Ruby
* Media Queries
* CSS Paged Media Level 3
* Selectors Level 3
* CSS Namespaces
5.実装を呼びかけ
* CSS Color Level 3 sections 3.3, 3.4, 3.5, 4.5.2
6.勧告
* CSS2.1
* CSS Color Level 3 (3.3, 3.4, 3.5, 4.5.2を除外)
* Selectors Level 3
7.完成
なし
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年11月12日
WikipediaにPDF/Aを追加
今日は、たまたま、ちょっと時間があったので、ちょっとばかりWebページの整理にとり組み、ついでに、WikipediaにPDF/Aの項を追加しました。
PDF/A(Wikipedia)
Wikipedia英語にはPDF/Aの説明がありますが、私の書いたのは翻訳ではなく、まったくのオリジナルです。
だれか、英語の情報も元にリライトしていただければ幸いです。
ところで、先日、Wikipedia について、3~4ヶ月で閉鎖?という記事が2月に出ていたことを目にしました。
Wikipediaを閉鎖させないために必要な金額はいくらなのか?
この記事にある情報が正しいなら、既に、閉鎖されていなければならないはずですが、どうなっているんでしょうね。未だに、閉鎖されずに続いているのを見て、一瞬、昔一世を風靡したローマクラブの「成長の限界」の予測を思い出しました。
Wikipediaのような販売収入のない=ビジネスモデル的には存在し得ない事業(ビジネスではないと言っても良いと思います)が、一体今後どこまで継続できるものなのか、将来どうなるか、寄付だけで賄うことができるものなのか、これもなかなか予測がつきにくいことです。但し、Wikipediaのコストは、人件費と、サーバのコストと、通信コストなどで、いわゆる製造コストがないと思われますので、そんなに巨額にはならないでしょうから、寄付で賄うのは不可能ではないと思います。
これで、連想するのがワシントンDCのスミソニアン博物館です。あの大きな博物館群も入場無料ですが、開設・運営コストは寄付で賄われたと聞きました(記憶があまり確かじゃありませんが)。アメリカのお金持ちは半端じゃないですし、誰かお金持ちがスポンサーになりさえすれば、Wikipediaの財政難は、簡単に解消できるレベルでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年11月08日
PDFのパスワード・セキュリティについて
PDFのパスワードによるセキュリティには、(1)PDFファイルを開くパスワードと(2)PDFの利用制限を設定するパスワードがあることは良く知られていると思います。
(1)PDFファイルを開くパスワードはユーザーパスワード、(2)PDFの利用制限を設定するパスワードはオーナーパスワードまたはマスターパスワードということもあります。
このPDFには、(1)PDFファイルを開くパスワードとして”OpenPWD”、(2)PDFの利用制限を設定するパスワードとして”PermitPWD”が設定されています。
このファイルをダウンロードして、アドビ・リーダなどで表示する際には、パスワードの入力が要求されます。そこで、OpenPWDを入力すれば開いて内容を見ることができます。
では、ファイルを開くパスワードのダイヤログで、誤って、PermitPWDと入力したらどうなるのでしょうか?
これを試してみますと、PDFを開いてみることができることが分かります。
つまり、PDFの利用制限を設定するパスワードは、オールマイティのパスワードなのです。
では、もうひとつ、(1)PDFファイルを開くパスワードと(2)PDFの利用制限を設定するパスワードに同じ値を設定することはできるのでしょうか?
実際に試して見ますと、Acrobat8.1では、この2つに「同じパスワードを設定することはできません」、として拒絶されてしまいます。役割が違うものに同じ値を設定できないのは当然といえば当然ですけどね。
■ご参考
PDFの標準セキュリィティ機能
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年10月18日
PDF関連仕様:PDF/UA アクセシビリティ
PDF/UA仕様の目的は、アクセシブルなPDFの仕様を作成することにあります。仕様作成の作業は、2004年の暮れ頃から始まっているようです。
仕様書のドラフトを見ますと、導入部分にISOの仕様書の雛形を使っていますので、ISOに提案して標準仕様にすることを意図していると見られますが、現時点では、ISOでの策定作業の段階にはなっていないようです。
仕様作成は米国のDuff Johnson氏が中心になって進めており、PDF/UA Wiki(2006年から)と電話会議によって進行しています。
■PDF/UA Wiki
http://pdf.editme.com/PDFUA
■仕様書のドラフト
PDF/UA 1.0 DRAFT
仕様書は、PDF 1.7をベースとして、それに対する制約事項を記述するプロファイルとして作成しているようです。
ドラフトは31節に分かれており、各節の進捗度合いが表に記入されていますが、これを単純平均しますと、47%になります。
表に記載された進捗の数字(%)が実態を正しく表しているとしますと、完成度50%というところです。Wikiを見ていますと、Duff Johnson氏は熱心に更新していますが、まだまだ先が長いように思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年10月17日
PDF関連仕様:PDF/E Engineering
PDF/E は、エンジニアリング・ワークフローにPDFを適用するための仕様とされており、ISOの委員会が設定されています。
■目標
・知的権利の安全な配布
・信頼できる交換、変更管理
・工学的な図面の正確な印刷
・注釈やコメント・データを交換したり・管理すること支援する。
・3次元、オブジェクト・レベルのデータなど複雑なデータをPDFに組み込む。
■スケジュール (2007年3月時点)
・2004年3月1日開発意図が公開され、2004年3月10日に最初の委員会(USのAIIM)
・2005年6月 ISOで委員会の設置。
・最初のドラフトが、2006年5月に批准された。
・ISOのドラフトのファースト・トラックを利用して投票。2007年3月完了。
・ISO標準は、2007年央に完了。
この日程からしますと、そろそろ、なんらかのアナウンスがあるはずですね。
ISOのWebページを見ますと次のようになっています。
ISO/PRF 24517-1
Document management -- Engineering document format using PDF -- Part 1: Use of PDF 1.6 (PDF/E-1)
9月3日現在のステータスは、FDIS registered for formal approvalとなっていて、承認段階です。
発行予定時期:Target publication date: 2008-06-30
来年の6月となっています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年10月16日
PDF/A-2についての情報源
アンテナハウスがWebで公開している次の資料の最終頁でPDF/A-2に関して説明しています。これについて、ISOで策定中の規格について公開するものとして問題視する向きがあるようです。
また聞きですので、発言した人の意図を明確に理解しているかどうかわかりません。多分、誤解なのでしょうが、とりあえず、降りかかった火の粉を払う(?!)ために、これらの情報がISOから秘密裏に入手したものではなく、公開された情報に基づいて作成したものであることをまとめてみました。
上記の資料で、PDF/A-2について次のことを述べています。
1.PDF/A-2は、当初、PDF 1.6をベースに策定作業が進んでいたこと。
2.PDF/A-2は、現在、PDF 1.7をベースとして策定されようとしている。
3.PDF/A-2は、ISO 32000をベースに策定されるであろう。
4.ISO 32000は、PDF 1.7の部分集合であること。
以上の4点についての根拠を次に示します。
1.PDF/A-2は、当初、PDF 1.6をベースに策定作業が進んでいたこと。
例えば、USのAIIMのPDF/Aに関するWebページには、米国のPDF/Aに関する会合の記録があります。その記録の2006年の議事録には、「 Work on ISO 19005-2, Part 2 – Application of PDF 1.6」というアイテムが頻繁に現れます。これは、2006年時点では、ISO19005-2(これが、PDF/A-2をさす事は、ISO19005-1を読めば自明です)を、PDF 1.6に基づいて作成する作業を行っていることを意味しています。これは1回だけではありません。なお、PDF 1.7は2006年秋に公開されました。
さらに、PDF標準に関するWikiのPDF/Aのページhttp://pdf.editme.com/PDFAには次のような項目があります。
The ISO committee consists of representatives from ISO TC 171 SC2, Document Management Applications, Application Issues; TC 130, Graphics Technology; TC 46, SC11 ; and TC42, Photography. The committee is currently working on ISO 19005-2 which will be based upon Adobe PDF Reference 1.6 as well as ISO 19005-3 which will address dyanmic electronic documents.
この文章を読むとISO19005-2が、PDF 1.6に基づいて作成されるとあります。このWikiを運営しているのはAIIM、AdobeなどのPDF標準関係者であり、信頼にたる情報と考えられます。
2.PDF/A-2は、現在、PDF 1.7をベースとして策定されようとしている。
AIIMが運営している下記のブログに次の記事がでています。
http://aiimstandardswatch.typepad.com/
August 21, 2007
PDF/Archive to meet in Berlin
Nine members of the US committee for PDF/Archive are on their way to an international working group meeting with colleagues from Japan, Germany, Switzerland, United Kingdom and others. The committee will be discussing the next version of PDF/Archive which brings this important standard current to the PDF Reference 1.7 adding many capabilities to the archive file.
このブログは、AIIMのBetsy Fanning(the director of Standards and Content for AIIM)が書いたものです。AIIMというのは米国で、PDFの標準を進める団体で、彼女の肩書きを見れば、ガセネタでないことは明白でしょう。
3.PDF/A-2は、ISO 32000をベースに策定されるであろう。
これは私の推測であり、推測であると明記しています。私は、ISOから推測に基づく発言を禁止される立場にはありません。私の推測を信じるか否かは、資料を閲覧した人の自由です。
4.ISO 32000は、PDF 1.7の部分集合であること。
ISO DIS 32000の作成については、次の資料が公開されています。
ISO Draft of the PDF 1.7 Reference
ここに、PDF 1.7とISO DIS 32000との相違点が記述されています。これと同じものはAdobeのWebページにも公開されています。
実際に、ISO DIS 32000とPDF1.7を比較しますと、例えば、電子署名関連では次のような箇所が削除されています。これらのことから、ISO 32000はPDF 1.7のサブセットであることが証明できます。この部分、Obsoleteだから削除したとされていますので、証明としてはやや弱いかもしれませんが。
■PDF Ref 1.7 TABLE 8.103 Entries in a signature reference dictionary
DigestValue
DigestLocation
上記の2つのキーは、ISO DIS 32000で削除されています。
■PDF Ref 1.7 8.7.1Transform Methods
Appendix I, “Computation of Object Digests,” describes in detail the algorithm for computing object digests.
Note: All transform methods exclude the signature dictionary from the object digest.
上記の2つの文章はISO DIS 32000で削除されています。
■PDF Ref 1.7 Validating MDP signatures
PDF 1.5 required the calculated value of the object digest at the time of signing to be stored in the DigestValue entry in the signature reference dictionary (see Table 8.103). Therefore, an application can compare this entry to its calculated object digest when validating. If the values are different, the signature is invalid.
上の段落はISO DIS 32000で削除されています。
■Ref 1.7 Appendix I Computation of Object Digests
付録Iを削除。PDF1.7で廃止となったため。
これらの削除理由はISO DIS 32000ではObject Digestを廃止、DigestValue を計算する仕様であるPDF Ref 1.7のAppendix Iが廃止されたためと見られます。PDF 1.7でObsolete(廃止)された仕様は、ISO 32000から削除されると説明されています。実際のところは、アドビの製品では、過去との互換性を維持するためにPDF1.7でObsoleteな機能もサポートされているようですので、アドビのPDF 1.7準拠製品とISO 32000準拠製品は、理論上、完全互換ではないということになります。但し、実際上は、問題視する必要はないと思います。
いづれにしましても、PDF/A-2は現在策定中であり、最終的にどうなるかは、予断を許さないということに注意しなければなりません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年10月14日
PDF関連仕様: PDF/H PDF for Health care
PDF に関連する仕様のひとつにPDF/H(PDFヘルスケア)があります。副題に「ベスト・プラクティス」が付いています。仕様というよりも実践ガイドというもののようです。
ヘルスケア分野でPDFを使って情報共有するためのPDFに対する制限などを記載したプロファイルです。
目標:
診断メモ、研究レポート、電子フォーム、スキャンした画像、写真、デジタルX線、ECGなどの医療分野での情報を蓄積・交換するための安全な、電子的コンテナを、PDFの特徴や機能を利用して開発する。
PDFの有利性
・長期に渡る成功
・多様なデータタイプのための安全で汎用のコンテナ機能を提供
・プラットフォーム独立
・相互運用性、双方向のデータ交換が可能
・印刷が直ぐにできる
PDF/Aのような仕様との相違点は、使用例を作成すること、実装ガイドを作っていこうとしているようだ。
ASTMのCCR(ケア記録の連続性)、ヘルス・レベル7のCDA(診断文書アーキテクチャ)のような既存のヘルスケア分野の標準や、他の新しく開発されつつある標準との相互運用を可能にする情報を提供する。
ASTM CCRの利用例 2007年初頭
HL7 CDAの利用例 2007年央
HL7/ASTM CCD利用例 作成予定
などとなっています。
AIIMとASTM共同で開発が行われています。
■CCR
CCR,(Continuity of Care Record)は、ASTM International, Massachusetts Medical Society (MMS), Health Information Management and Systems Society (HIMSS)とAmerican Academy of Family Physicians (AAFP)が共同で開発しているXMLベースの標準仕様。医師、看護婦、医療補助者などが記入し、交換すること医療事故を減らすのが目的のようです。
■ASTMインターナショナル
www.astm.org
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年10月13日
PDFと署名(47) — PDF/Aで、電子署名を使えるか
最近、何回か、「PDF/Aで電子署名を使えるのでしょうか?」という質問を頂きました。どうも、PDF/Aでは電子署名を使えないと考えている人が多いようです。
PDF/A-1の仕様上は、電子署名を使うことは問題ないと考えられます。
それは、次のような理由からです。
(1)PDF/A-1は、PDF 1.4をベースにして、PDF 1.4の仕様の中で、必須事項、禁止事項、制限事項、無視事項を決めています。
(2)PDF電子署名は、PDF 1.3で導入されており、PDF 1.4の仕様でもPDF電子署名機能は定義されています。そして、PDF/A-1では、PDF電子署名に関わる事項を、禁止も制限もしていません。
以上、(1)、(2)からPDF/A-1ではPDF電子署名を使えるといえるでしょう。但し、若干の注意事項があります。
まず、最新のPDF1.7では、PDF電子署名には、普通署名(Document Signature)、MDP(Modify Detection and Prevention)署名、UR(Usage Right)署名の3種類が定義されています。この中で、MDP署名とUR署名は、PDF1.5で導入されました。
従って、PDF/A-1で使用できるのは、普通署名のみとなります。
■PDFバージョンと署名の機能について
| 署名フィールド | 署名の外観 | 署名辞書 | 署名アプリケーション情報 (Prop_Build) |
||
|---|---|---|---|---|---|
| 普通署名 | MDP署名 | ||||
| PDF 1.3 | ○ | △ | ○ | ||
| PDF 1.4 | ○ | △ | ○ | ||
| PDF 1.5 | ○ | ○ | ○ | ○ | ○ |
| PDF 1.6 | ○ | ○ | ○ | ○ | ○ |
| PDF 1.7 | ○ | ○ | ○ | ○ | ○ |
○署名の外観:
Digital Signature Appearances Adobe Acrobat 6.0 May 2003によればAcrobat5(PDF 1.4)までとAcrobat 6(PDF1.5)以降では互換性がない実装となっています。
投稿者 koba : 09:10 | コメント (0) | トラックバック
2007年10月09日
PDFと長期署名(16)—PDF電子署名としての長期署名とは?
前回、ECOM提案のPDF長期署名は、採用できないということをお話しました。
2007年08月22日 PDFと長期署名(15) — ECOM JIS原案「PDF/Aへの長期署名の適用方法」は採用できない
ここにそのことを整理しています。
http://www.antenna.co.jp/PDF/reference/PDF-DS-Long.htm
このままですと、PDFでは長期署名に対応できないと受け止められかねません。
それに対するひとつの解決策は、PDFを含む任意の電子ファイルに対する長期署名フォーマットを使うということでしょう。この場合、長期署名フォーマットの中に、PDFを単純なバイナリとして埋め込んでしまう、ということになります。これが現時点で考えられる正しい解決策と思われます。
それに対して、PDF電子署名の特徴は、PDFの内部に自分自身に対する署名を取り込んでおり、PDFに電子署名を施した結果もPDF形式であるということです。電子署名を施した結果もPDFであるからには、PDFの仕様であるPDF Reference で定めるところに準拠する必要があります。
では、PDF電子署名としての長期署名は考えられるのでしょうか?
その前に、長期署名の対象とする期間を考えてみましょう。
それは、10年、20年、30年、50年のいづれでしょうか?
とりあえず、30年を想定して、30年後のコンピューティング環境がどうなるか、を考えて見ますと、この長期間は、一つの企業の存続期間を超える可能性があります。ましてや、一つの製品の寿命は遥かに超えてしまいます。
過去を振り返ってみますと、現在の主流であるパーソナル・コンピュータが生まれて、まだ、30年経過していません。約30弱前に8ビットCPUをもって生まれたパーソナル・コンピュータは、16ビットCPU、32ビットCPUと強化され、現在、64ビットCPU時代へ突入しつつあります。
Windowsにしても、まだ開発開始後20年を超えたところです。Windows95が出てから、10数年ですが、この間にWindowsのアーキテクチャは、95系、NT/2000系、Vista系へと3回も大きな変化を遂げています。Vista後は、どうなるのでしょうか?
こうしてみますと、今の時点で30年後のコンピュータ環境がどうなるか、まったく想像できない、というのが正直なところです。ですので、30年後のコンピュータ環境で、現在使用できるアプリケーションがそのまま使える可能性は、ほとんどゼロ%に近いだろうと思います。
従って、PDF長期署名を、30年後に検証するとしますと、全く異なったコンピュータ環境において、署名を付加したアプリケーションとは、全く別のアプリケーションで検証することになるであろうことを前提としなければならないでしょう。
このことを想定すれば、一私企業、一アプリケーションを想定して、長期署名を考えてはならないことがわかります。
そして、長期署名は、まず仕様が完全に記述されていること、まず仕様が完全に公開されていること、製品間の相互運用性は完全に確保されていること、これらを満たすことが最低条件である、といえるでしょう。しかし、現在、上記の条件を満たすPDFの長期署名の仕様も実装も存在しません。
こうしてみますと、現在、PDF長期署名対応をアピールする製品がいかに危ういものであるか想像がつくというものです。その危うさのまま、30年という時の流れに対抗できるものなのでしょうか?
まず、そのことを謙虚に考えてみなければなりません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年10月05日
フォントサイズゼロのフォントの扱い
今日、たまたま、XSL Formatter のサポートに面白い問合せが来ていました。PDFでフォントサイズゼロを設定したらどうなるか?というものです。
この問合せされた方の目的は、見えない位置にジャンプするしおりを作りたいことのようです。それで、見えない文字を配置してそこにジャンプするしおりを作ったらどうかとお考えのようです。この目的自体は、XSL-FO V1.1のしおりの標準仕様の範囲内で実現できます。
で、どうもフォントをサイズゼロにしますと、Acrobat8で正しくサイズを認識しないようだ、ということになり、興味半分で試して見ました。
このPDFは、ラテン文字にフォントサイズを0ポイントから1ポイントまで指定して作成したものです。
ファイルをダウンロード

PDFをAcrobat8.1で表示した画像
Acrobat8.1で、テキストのタッチアップ機能を使って文字を選択して、プロパティを見ますと、0.1ポイントまでは、プロパティに正しいフォントサイズが表示されます。次の図をご覧ください。

0.1ポイントの文字列を選択してプロパティを表示
しかし、0ポイントの文字のありそうな箇所を選択してフォントのプロパティを表示しますと、フォントサイズが1ポイントと表示されます。

以前、PDFの線にLine Widthゼロが指定されているとき、1ピクセルの幅になるということをお話しました。こちらをご参照ください。
2006年02月18日 線の太さについてのPDFの仕様
それと同じような話なのかもしれませんね。
ところで、これをPDF/A-1aで出力してみました。

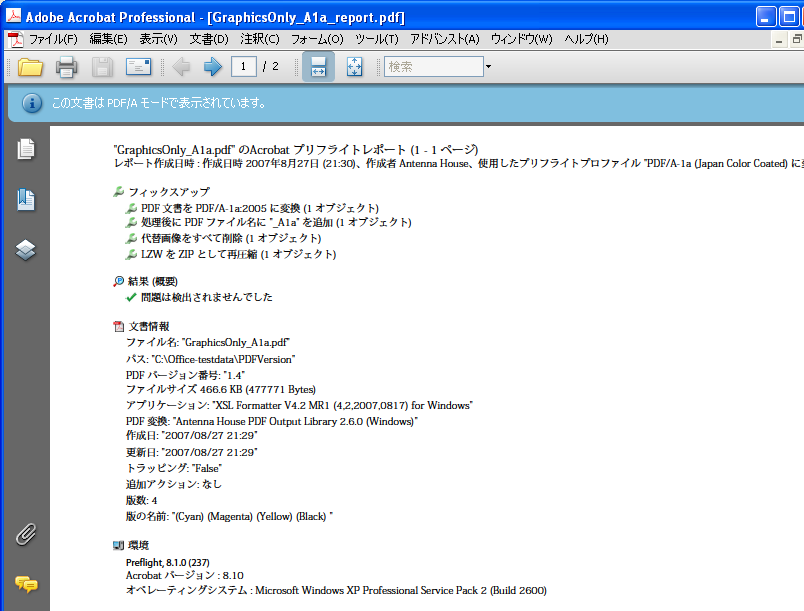
Acrobatのプリフライト機能でPDF/A-1aとして適合しているかどうかチェックしますと、適合となります。

PDF/A-1では、透明は禁止で、透明テキスト付きPDFは作成できない、と思っていました。しかし、サイズゼロを指定した見えないフォントは問題ない、ということなのでしょうか。だとしますと、透明テキスト付きPDFの透明テキストの部分をフォントサイズゼロで指定することで、PDF/A-1適合の透明テキスト付きPDFという裏技が使えてしまいそうです。
投稿者 koba : 00:00 | コメント (0) | トラックバック
2007年10月04日
PDF/Aの準拠性に関する問題点
PDF/Aに関するベルリンでの会議(ISO TC 171 SC2 WG5 Berlin )の結果、PDF/Aへの準拠性に関するアドホックな委員会ができたようです。
以下、http://pdf.editme.com/PDFA-Conformanceより。
問題点1
PDF/Aのパート1は、PDF/A-1のリーダ、ライタ、検証ソフトでテストする前に出版された。出版された後、この標準を使った結果、誤りが見つかり、訂正版を出さざるを得なくなった。そこで、今後の標準の出版にあたって、最終的に認める前に、テストが必要かどうかを見極めて、そのようなテストを行う方法を勧告する。
問題点2
現在、PDF/A-1リーダ、ライタ、検証ツールが、PDF/A-1に準拠しているかどうかを認証する独立の団体がない。そのような、認証団体が存在しなければ、ソフトウエア・ツールがPDF/A準拠であるといってもそれを保証する方法がない。委員会ではそのような状況のリスクを分析し、対策を検討する。
問題点3
PDF/A標準に直接関わっているソフトウエア・ベンダは、標準に関する問題を認識している。しかし、それらの問題が標準で訂正されるのを待つ代わりに、PDF/A-1ファイルを生成するPDF/A-1ライターを開発し、販売している。そのようなPDF/A-1ファイルは、標準に厳密に準拠していないかもしれない。これらのベンダ自身が、それらの厳密にはPDF/A-1標準に準拠していないかもしれないPDFファイルを、検証してPDF/A-1に準拠していると報告するようなソフトウエア・ツールを開発し、販売している。委員会では、ソフトウエア・ベンダが標準に先行するリスクを分析し、問題に対処する方法を勧告する。
以上、やや雑ですが翻訳してみました。
うーーん。我々ソフトハウスには、耳の痛い、話です。
ただし、W3Cなどと比べると、ISOの標準化プロセスって、閉鎖的過ぎるんじゃないでしょうかねえ。
W3CのXSL-FOメーリング・リストなどでは、関連ツールの準拠度なども時々議論されてます。ツールベンダも巻き込んだ、率直な議論の場が必要だと思いますね。PDFは、いままで、アドビの支配下にありましたが、今後は、ISOで標準となるのであれば、仕様策定もオープンなプロセスが望まれます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年09月24日
PDF/Aについてのプレゼン資料を公開
PDF/Aについてのプレゼンテーション資料をPDFで公開しました。
こちらでどうぞ。
同時に、PDF/Aに関する簡単な説明文の方も更新しました。
◎PDF/Aとはなにか?
実際のところPDF/Aは、こういうドキュメントを見ただけではなかなか理解できないと思われます。では、実際のアプリケーションを動かして見たらどうかと言いますと、それでもなかなか分からないのではないだろうかと思います。
PDFに限らず、ソフトは手で触って、あるいは、分解してみることができませんので、いろいろ新しい仕様がでてきても、なかなか簡単に理解していただけないのではないかと思います。このあたりPDFの新しいブランドができても、かななか普及するのが難しい原因かも知れません。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2007年09月19日
フォント埋め込みで、気になったこと
Webを読んでいましたら、
http://www.incunabula.co.jp/dtp-s/cotu/Acrobat/index_a01.html
---ここから引用開始---
PDFで出力する場合、テキストをアウトライン化してしまいたいことがありますね。たとえば、Windowsで作成したPDFをMacintoshで修正したいとしますね。そのとき、フォントが埋め込んであるときは、Macintoshで開いてもフォントが再現できません。Windowsのフォントですから、当然ながら認識できないわけです。
しかし、テキストをアウトライン化してしまうと、MacintoshのIllustratorで開いて編集することができます。テキストの編集も Windowsで利用したオリジナルフォントにこだわらなければ、テキストを修正することができます。フォントはアウトライン化してしまうと、完全にOS に依存しなくなるわけです。
---ここまで引用---
上のような文章がありました。上の文章の前半には少し疑問があります。
私は最近Macを使っていないので、Windowsで、フォントを埋め込んだPDFを作成して、Macintoshで開いたことがないのですが、Windowsでフォントを埋め込んだものがMacintoshで再現できないというのは、文字を正しく表示(可視化)できない、ということであれば誤りではないかと思います。
もし、WindowsでPDFにフォントを埋め込んで作成したPDFをMacintoshで文字を正しく表示できないとすると、PDFのフォント埋め込みが本質的に無意味になってしまうように思います。
そもそもフォントにWindowsのフォントというような言い方があてはまるとは思えません。フォントの形式には、TrueTypeフォント、Type1フォント、OpenType(CFF)というようなタイプがあるのですが、Windowsのフォントとはフォント形式にはないと思うのですが。
なにか、文章の説明不足のように思いますが、どうなんでしょうか。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年09月11日
実践PDF/A (5)
昨日は、XSL FormatterでPDF/A-1a、PDF/A-1bを指定して出力したファイルは、3-Heights™ PDF Validator APIで、検証するとそれぞれ、PDF/A-1a、PDF/A-1bとしてOKとなることを示しました。これについては、Acrobat 8でも同じ結果となります。
ところが、別のファイルを試して見ますと、Acrobat 8ではPDF/A-1aとして問題がないのに、3-Heights™ PDF Validator APIでは、エラーになってしまいます。
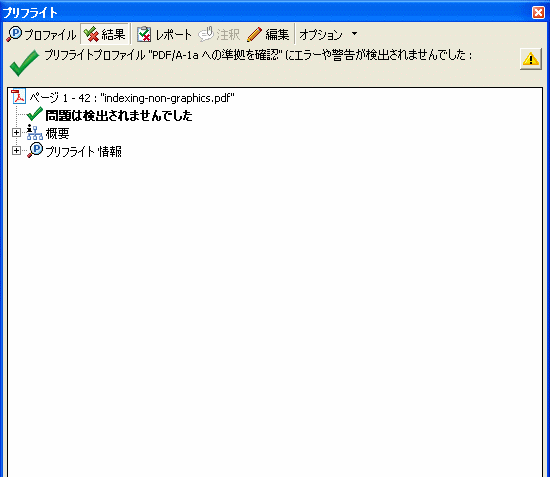
試したのは、このファイルです:ファイルをダウンロード
このファイルは、XSL FormatterV4.2でPDF/A-1aを指定して出力したものですが、Acrobat 8.1のプリフライト検証しますと、PDF/A-1aとして「問題は検出されませんでした」となります(次の図)。
ところが、3-Heights™ PDF Validator APIで検証しますと次のようになります。
>pdfvalidator -cl pdfa-1a -rd indexing-non-graphics.pdf
0, 0x80410605, "The value of the key PageLabels must be an indirect object.", 1
42, 0x83410612, "The document does not conform to the requested standard.", 1
ということで、どうもPageLabelキーの値が正しくないといっているようです。しかし、特にPageLabelキーの出し方は間違っていないようなのですが。
いづれにしても、このファイルの場合、Acrobat8での検証結果とpdfvalidatorが一致していません。今回の場合は、恐らく3-Heights™の方の問題ではないかと思います。で質問をメールで送りましたが、今のところ回答は届いていません(下記参照)。
PDF/Aは、かなり細かい要求事項が多々あり、その「妥当性の検証ツール」の妥当性自体も判定の難しいところがあるように思います。
※9月11日夕方追記
3-Heights™ より回答がきました。
それによりますと、やはり、「"The value of the key PageLabels must be an indirect object."」は正しくないので、次のバージョンで修正する、とのことです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年09月10日
実践PDF/A (4)
PDF/Aを作ることについて、過去3回試してみました。これまで分かったことをまとめてみます。
1.比較的簡単な画像と文字から構成されるパワーポイントから作成したPDFを、Acrobat8でPDF/Aに変換しようとしても多様なエラーが出てしまい、PDF/Aに変換できない。
2.文字を削除して画像(RGB画像)だけのPDFでもPDF/A-1aには変換できない。
以上: 2007年08月27日 実践PDF/A
3.RGB画像だけを含むPDFであれば、出力インテントsRGBを指定すればPDF/A-1bに変換できる。
4.CMYK画像だけを含むPDFであれば、出力インテントとして適当なICCカラープロファイルを選べばPDF/A-1bに変換できる。
5.PDF/A-1aに変換できるためには、タグ付きPDFでなければならない。つまりPDF/A-1aを作ろうとすればタグ付きPDF生成機能が必須である。
以上: 2007年08月28日 実践PDF/A(2)
※以上の変換機能は、Acrobat8.1Professionalを前提としています。
6.XSL Formatterは、タグ付きPDF作成機能があるので、グラフィックス用に適切なカラープロフィールをPDFに埋め込むなどでPDF/A-1aを直接生成できる。
以上: 2007年08月29日 実践PDF/A(3)
ドイツのソフトウエア・メーカはPDF/Aに熱心なようで、PDF/A Conformance Centerという団体を結成しています。その中で、PDF/Aのバリデータ(検証ツール)を作っている会社がありましたので、評価版をダウンロードしてみました。
このバリデータでXSL Formatterで作ったPDF/Aをチェックしてみます。
まず、簡単なところで、次の3種類のPDFを作ってみます。
a. 日本語と英語の混じった文章をPDF 1.4(フォント埋め込みしない) ファイルをダウンロード
b. 日本語と英語の混じった文章をPDF 1.4(基本14フォント以外のフォントを埋め込む) ファイルをダウンロード
c. 日本語と英語の混じった文章をPDF 1.4(すべてのフォントを埋め込む) ファイルをダウンロード
d. 日本語と英語の混じった文章をPDF 1.4(すべてのフォントを埋め込む)+タグ付きPDF:ON ファイルをダウンロード
e. 日本語と英語の混じった文章をPDF/A-1bで出力(タグ付きPDF:OFF) ファイルをダウンロード
f.. 日本語と英語の混じった文章をPDF/A-1aで出力 ファイルをダウンロード
最初はPDF/A-1bに準拠しているかどうか検証してみます。
>pdfvalidator -cl pdfa-1b -rd xxx.pdf (xxx 検証対象ファイル)
エラーメッセージの意味:
ページ番号, エラーコード, エラーの説明, 出現回数
a.の結果
0, 0x80410604, "The key Metadata is required but missing.", 1
1, 0x80410703, "The CMAP UniJIS-UCS2-H must be embedded.", 1
1, 0x80410604, "The key CIDToGIDMap is required but missing.", 1
1, 0x00418704, "The font MS-Gothic must be embedded.", 1
1, 0x00418704, "The font ArialMT must be embedded.", 1
1, 0x83410612, "The document does not conform to the requested standard.", 1
b.の結果
0, 0x80410604, "The key Metadata is required but missing.", 1
1, 0x80410604, "The key CIDToGIDMap is required but missing.", 2
1, 0x83410612, "The document does not conform to the requested standard.", 1
c.の結果
0, 0x80410604, "The key Metadata is required but missing.", 1
1, 0x80410604, "The key CIDToGIDMap is required but missing.", 2
1, 0x83410612, "The document does not conform to the requested standard.", 1
d.の結果
0, 0x80410604, "The key Metadata is required but missing.", 1
1, 0x80410604, "The key CIDToGIDMap is required but missing.", 2
1, 0x83410612, "The document does not conform to the requested standard.", 1
e.の結果
OK
f.の結果
OK
次にPDF/A-1aに準拠しているかどうか検証してみます。
>pdfvalidator -cl pdfa-1a -rd xxx.pdf (xxx 検証対象ファイル)
a.の結果
0, 0x80410604, "The key Metadata is required but missing.", 1
0, 0x80410604, "The key MarkInfo is required but missing.", 1
1, 0x80410703, "The CMAP UniJIS-UCS2-H must be embedded.", 1
1, 0x80410604, "The key ToUnicode is required but missing.", 1
1, 0x80410604, "The key CIDToGIDMap is required but missing.", 1
1, 0x00418704, "The font MS-Gothic must be embedded.", 1
1, 0x00418704, "The font ArialMT must be embedded.", 1
1, 0x83410612, "The document does not conform to the requested standard.", 1
b.の結果
0, 0x80410604, "The key Metadata is required but missing.", 1
0, 0x80410604, "The key MarkInfo is required but missing.", 1
1, 0x80410604, "The key CIDToGIDMap is required but missing.", 2
1, 0x83410612, "The document does not conform to the requested standard.", 1
c.の結果
0, 0x80410604, "The key Metadata is required but missing.", 1
0, 0x80410604, "The key MarkInfo is required but missing.", 1
1, 0x80410604, "The key CIDToGIDMap is required but missing.", 2
1, 0x83410612, "The document does not conform to the requested standard.", 1
d.の結果
0, 0x80410604, "The key Metadata is required but missing.", 1
1, 0x80410604, "The key CIDToGIDMap is required but missing.", 2
1, 0x83410612, "The document does not conform to the requested standard.", 1
e.の結果
0, 0x80410604, "The key MarkInfo is required but missing.", 1
1, 0x83410612, "The document does not conform to the requested standard.", 1
f.の結果
OK
この結果を見ますと、とりあえず、このような簡単なPDFでは、XSL FormatterのPDF出力設定とバリデータのチェック結果は、整合性が取れていることがわかります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年09月09日
PDF処理ツールにおけるPDF電子署名との整合性確保問題(メモ)
PDFの電子署名が普及してきますと、各種のPDF製品で電子署名との整合性を維持する必要性が生じます。
なぜならば、電子署名が付加されたPDFを、署名を認識しないソフトウエアで加工すると電子署名部分が壊れてしまうからです。署名を認識しないPDF処理ソフトで、署名対象範囲のデータを無意識のうちに書き換えてしまいますと、そのPDFの署名は無効になり、結果としてPDF自体が無効と判断されることになります。
そうなりますと、書き換えたこと自体が無意味ということに帰結してしまいます。
現在、配布されている無償のPDFソフトを始め、廉価版のPDF加工ソフトでは、電子署名を認識しないものが多いと思います。
実際のところ、アンテナハウス製のソフト(PDF Toolや、その他の製品を含め)も、「PDF電子署名モジュール」以外は、PDFの電子署名を認識していません。
このため、それらのソフトで電子署名のついたPDFを加工すると電子署名の付いた部分が改竄された状態になり、電子署名の検証が失敗になります。
電子署名は、改竄されたことを検出するためにありますので、PDF電子署名を認識しないソフトによるPDFの変更を署名検証失敗という形で検出できれば、電子署名自体は、それで、存在意義がありますが。
このように、電子署名のついたPDFを無意識のうちに改竄してしまうことを防ぐには、最低限、電子署名を認識して、「この操作は電子署名を無効にします」というようなメッセージを出すようにするのが望ましいでしょう。結局、このあたりは、PDFベンダが協力して、PDF生態系の向上として策を練っていくべき分野のように思います。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2007年08月29日
実践PDF/A (3)
今日は、昨日作成したPDF/A-1aを、XSL Formatterで直接作成してみます。XSL Formatterでは、タグ付きPDFやPDF/Aの出力機能があります。
タグ付きPDFのタグの方は、Formatterの組版結果からPDFを出力する際に、XSL-FOの構造をもとにしてPDFにタグを自動的に埋め込みます。FOの要素とタグの対応関係については、
http://www.antenna.co.jp/XSL-FO/V4/pdf.htm
の「タグ付きPDF」の項をご覧ください。
さて、昨日使用したグラフィックス・ファイルはCMYKカラーで表現されています。PDF/Aでは、CMYKカラーを使う場合、OutputIntent辞書に、Sキーの値としてGTS_PDFA1、DestOutputProfileキーの値としてICCプロフィールのストリームをもつ必要があります。
このためまずICCプロフィールのデータを用意しなければなりません。AdobeのWebページで基本的なICCプロフィールのデータ・セットが配布されています。
http://www.adobe.com/support/downloads/detail.jsp?ftpID=3145
とりあえずデータ・セットをダウンロードします。このカラープロフィールのセットには、CMYKとRGBのカラープロフィールが幾つか入っていますが、その中から、昨日使ったのと同じ、JapanColor2001Coated.iccを選択してインストールします。(ファイル名の上で右クリックして、インストールを実行します。)
そうしますと、このカラープロフィールが、Windowのシステムフォルダにインストールされます。私のWindowsXPの場合は、ここにインストールされます。
C:\WINDOWS\system32\spool\drivers\color
XSL-FOでは、カラープロフィール関係の情報をfo:declarationsの子供として指定します。
次のようになります。
<fo:declarations>
<fo:color-profile
src="url(file:///C:/WINDOWS/system32/spool/drivers/color/JapanColor2001Coated.icc)"
color-profile-name="#CMYK"
/>
</fo:declarations>
※全体のXSL-FOはここにアップしました。
ファイルをダウンロード
Formatterで上記のFOを組版し、PDF出力設定でPDF/A-1aを指定します。

PDFを出力します。
出力したPDF:ファイルをダウンロード
これをAcrobatでPDF/A-1aに適合しているかどうかチェックしますと、次のようなそっけないメッセージですが、OKです。

PDF/Aでは、このようにPDF内に出力インテントとしてカラープロフィールデータを埋め込む必要があります。
ここでは、多少厄介ですが、XSL-FOでカラープロフィールデータのありかを指定し、それをXSL Formatter4.2を使ってPDFにすることで、PDF/Aを正しく作成できることを示しました。
なお、Adobeが配布している上記カラープロフィールのデータセットのライセンス文書には次のように書いてあります。
Adobe also grants you the rights to distribute the Software only (a) as embedded within digital image files and (b) on a standalone basis (Software とはICCカラープロフィールデータ)
ということで、このカラープロフィールをPDFの中に埋め込んで配布することは問題ないと思われます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年08月28日
実践PDF/A (2)
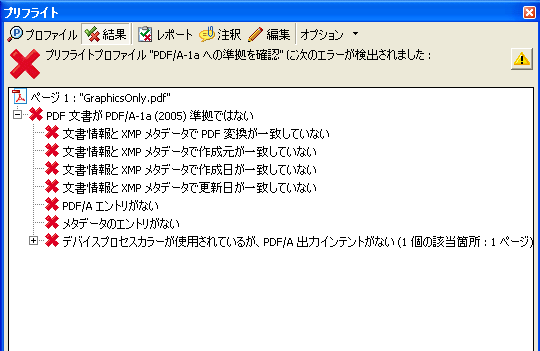
昨日は、簡単な画像の入ったPDFでさえも、PDF/Aに変換できませんでしたが、その原因を調べてみましょう。
昨日は2つのファイルを変換しようとしましたが、まず、簡単なものから。
2つ目のファイル(PDFStamp.pdf)をPDF/A-1aに変換しようとして失敗しました。その時、報告されたエラーは次の2つです。
(1) DeviceRGBを使用
(2) MarkInfoがない
このうち、(2)のMarkInfoはMarkInformation辞書を示すようです。
MarkInformation辞書というのは、タグ付きPDFであることを示す辞書です。PDFのドキュメント・カタログ辞書(最上位の辞書)にタグ付きPDFかどうかを示すオプションのキーMarkinfo(辞書)があり、その内容でタグ付きPDFを示すものです。
PDF/A-1aに準拠するためには、タグ付きPDFでなければなりません。タグ付きPDFでは、Markinfo辞書があり、その唯一のエントリMarkedは、trueでなければならないとされています。MarkInfoがないというレポートはタグ付きPDFなければならないという要求に違反しているエラーです。
次の、 DeviceRGBを使用というエラーは、PDF/Aに変換するとき、出力インテントとして「Japan Color Coated」を選択したのがどうもまずかったようです。Japan Color Coatedは、印刷用なのでCMYKカラースペースなのですが、もとの画像がRGBのため、PDF/Aでは、DeviceRGBとDeviceCMYKを両方使うことができない、というエラーに引っかかってしまったのでしょう。
そこで、今度は、PDF/A-1b形式で、出力インテントとしてsRGBを選択して変換してみました。そうしましたら無事変換が成功しました。
次のレポートをご覧ください。

さて、次にXSL FormatterでCMYKカラーのグラフィックスをもつタグ付きPDFを作ってみました。
ファイルをダウンロード
文書のプロパティを見ますと、次の図のようにタグ付きPDFになっています。

このPDFファイルは、PDF/Aではありませんので、AcrobatでPDF/A-1aかどうかをチェックすると次のようにエラーになります。
このPDFファイルは、Japan Color Coatedの出力インテントをもつPDF/A-1aに変換することができます。
PDFファイル:ファイルをダウンロード
このことからも次のことを確かめることができます。
(1) 通常のPDFをPDF/A-1aに変換するには、そのPDFがタグ付きPDFでなければならない。
タグ付きPDFでないならば、PDF/A-1bにしか変換できない。
つまりAcrobatでタグを自動的に付けることができない。
(2) RGBカラーのグラフィックスを含むPDFはsRGB、CMYKカラーを含むPDFは、Japan Color CoatedのようなCMYK系の出力インテントをもつPDF/Aに変換できる。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年08月27日
実践PDF/A
PDF/Aについて、以前に、仕様の面から解説しました。
2007年07月23日 PDFと長期署名(3) — PDF/A 仕様 ~2007年07月31日 PDFと長期署名(10) — PDF/A 仕様 8 タグ付きPDF
そこで、今回は、実践的に、つまり少し実際にPDF/Aを作ることを通じて試してみたいと思います。
Acrobat7Professionalでは、PDF/Aのドラフト(仕様案)を使えましたが、最新のAcrobat8.1Professionalでは、PDF/A仕様をサポートしており、PDF/Aを実際に体験できます。弊社のXSL Formatter 4.2でもPDF/Aを作成することができます。
そこで、主にこの二つの製品を使ってPDF/Aを体験してみることにします。他にも、PDF/Aをサポートする製品が増えてきているようですので、随時、試してみましょう。
1.PDF/Aを作る
・PDF/Aを作るには、XSL FormatterV4.2のようなツールでPDF/Aをゼロから生成する方法があります。類似の方法としては、PDFLibも7.0からPDF/Aの作成をサポートしています。PDF/Aが生成できるようになったのは比較的最近ということができます。
2.PDFをPDF/Aに変換する
任意のPDFをPDF/Aに自動変換できるなら簡単な話です。そこで、まず、これを試してみました。
Webでも公開していますが、「PDF活用のための基礎知識」をAcrobat 8.1 ProfessionalでPDF-1aに変換してみます。
(1)テストデータ1
オリジナル・ファイル:PDF活用のための基礎知識 (PDFファイル)
http://www.antenna.co.jp/PDF/reference/Seminar-20070702.pdf
このPDFには、フォントを埋め込んで作成してあり、かなり簡単な内容です。
これをPDF-1aに変換して、そのレポートをPDF化したのがこちらです。

このレポートを見ますと、代替画像を削除したり、禁止されているLZW圧縮をZIPに再圧縮したりと言った、自動的にできることはやっているようですが、DeviceRBGを使用、MarkInfoがない、Type2CIDフォントに無効なCIDtoGIDMapがある、などの多数のエラーが出てしまい結局変換は成功していません。
(2)画像だけのPDF
もう少し簡単な画像だけのPDFファイルではどうでしょうか?
オリジナルPDF:
ファイルをダウンロード
これをPDF/A-1aに変換してみました。やはり、うまくいきません。

レポートPDF:
ファイルをダウンロード
このPDFファイルは、文字がありませんので、フォントのエラーは出ませんが、画像がエラーになってしまいます。また、MarkInfoがない、というエラーになります。
これを見ただけでも、PDF/Aを作るのは結構面倒そうなことが分かります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年08月26日
ECOM JIS原案「PDF/Aへの長期署名の適用方法」まとめ
ECOM JIS原案「PDF/Aへの長期署名の適用方法」批判について、過去3回の記述を整理しました。
以下のリンクを辿っていただくことでご覧頂くことができます。
http://www.antenna.co.jp/PDF/reference/PDF-DS-Long.htm
最後の方にも書きましたが、現時点でPDFの長期署名仕様はまだ標準化の段階になっておらず、採用は時期的に早すぎると考えられます。
商売の上では、早いものがちとも言えますが、すくなくとも、「PDF/Aへの長期署名の適用方法」はあまりにも拙劣です。この仕様を実装すれば、実装したツールでしか、検証できず、相互運用できないものになります。
また、仮にECOMに賛同する数社が実装したとしても、PDF標準と非互換なPDF署名ができてしまうことになるため、採用したユーザにも迷惑をかける可能性があります。
JIS原案「PDF/Aへの長期署名の適用方法」にわざわざ参考資料として掲載した意図は、恐らく他者を出し抜いて、商売の利得を得ようということだろうと思いますが、それにしてももう少し勉強するべきです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年08月25日
PDF/A の次期バージョンについて
PDF/Aの次のバージョンに関する国際会議は8月28日から29日にベルリン(独)で開催されます。米国、日本、スイス、英国などの代表者が参加しての会議が予定されています。
PDF/Aの次期バージョンは、当初、PDF 1.6をベースに作成されることになっていましたが、PDF 1.7をべースにしたものになり、新しい機能がいろいろ追加されることになっています。
PDF/Aの次のバージョンは、USの代表によれば、次の3つのパートにしたいようです。
パート1、パート2は、コンテンツの内容が変化しない静的なもの。そして、パート3は、ドロップ・ダウン情報をもつフォームのようなダイナミックな文書の保管を可能にする。
今回の国際会議での目標は、全メンバー国の合意を得るための委員会の投票を行うことを参加者に合意を取ることにあります(以上は、米国発の情報)。
出展:August 21, 2007 PDF/Archive to meet in Berlin
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年08月22日
PDFと長期署名(15) — ECOM JIS原案「PDF/Aへの長期署名の適用方法」は採用できない
PDFへの長期署名の仕様として、ECOMのJIS原案に参考資料として「PDF/Aへの長期署名の適用方法」という仕様案が出ています。それについて2回に渡り批判しました。
・2007年08月01日 PDFと長期署名(11) — ECOM提案のPDF/A長期署名
・2007年08月06日 PDFと長期署名(12) — ECOM提案のPDF/A長期署名を再び批判する
仮に参考資料としても、このような根本的に間違った仕様がJISの規格書に盛り込まれると、将来、大変困ることになると思います。
アンテナハウスPDFは、PDF Reference、さらに将来のISO標準PDFを可能な限り正しく実装しようと心がけています。もし、独自拡張するとしても、その場合の方針は、仕様としてあるものはそれを忠実に実装し、ないものだけを拡張するということになります。
ところが、ECOMのJIS原案のPDF長期署名仕様はPDF ReferenceとPDF/Aで決まっている項目について、それが、意図的か、あるいは、理解不足かはともかくとして、それを無視・違反した上で、自分達の都合の良い独自拡張をしています。この考え方では、標準である部分についても、互換性がなく、相互運用できないPDFが出来上がってしまうことになります。
なぜ、こんな発想が出てくるのか疑問に思い、ECOMの前年度の報告書を見ましたところ、彼らの誤れる発想の原点が少し見えました。
前年度の「長期署名フォーマット相互運用実験報告書」(平成18年3月)次世代電子商取引推進協議会発行資料のPP.45~49まで、PDF/A文書に対する長期署名の標準化という項があり、そこで予備的な検討が行われています。その中に次のような部分があります。
PDF/AのベースになっているPDF Reference1.4では電子署名についての仕様は簡単な記述になっています。
ちなみに、その時点では、PDFの電子署名は別文書「PDF Public-Key Digital Signature and Encryption Specification Version 3.2(Jim Pravetz 著)」で記述されていました。その後、この別文書の内容がPDF Reference本体に吸収されたようです。
※上記の文書は、どうも既にWebからなくなってしまっているようで、内容は私には確認できていませんので推測です。
その結果、ECOM的PDF長期署名にとっては都合の悪い記述がPDF Reference1.6に盛り込まれてしまいました。
すなわち、PDF 1.4では、署名辞書の署名ハンドラの名前(Filterキーの値)、署名の符号化方法を示す名前(SubFilterキーの値)、署名値(Contentsキーの値)について、簡単な記述しかなかったので、長期署名の形式をPDFの署名辞書に定義可能でした。
ところが、PDF 1.6でこれらの記述が詳しくなりました。具体的には、
(1) SubFilterキーの値の部分に次のパラグラフが追加されました。
Defined values for public-key cryptographic signatures are adbe.x509.rsa_sha1, adbe.pkcs7.detached, and adbe.pkcs7.sha1 (see Section 8.7.2, “Signature Interoperability”).
(2) Contentsキーの値の部分に次のパラグラフが追加されました。
For public-key signatures, Contents is commonly either a DER-encoded PKCS#1 binary data object or a DER-encoded PKCS#7 binary data object.
このふたつのパラグラフが追加されたために、長期署名の形式を表すキーの値を定義できなくなってしまったのです。「長期署名フォーマット相互運用実験報告書」の筆者は、この対策として、このインターフェイスの阻害要因である、上の二つの段落を削除する、ということを提案しています。
Adobeが作った標準仕様であるPDF Referenceを利用しておきながら、自分達に都合の悪い段落を削除し、都合の良い項目を追加する、という発想方法は、標準を認めない、ということに繋がります。その結果できるものは標準とは名ばかりで、実態は非互換の独自PDFです。
ところで、PDF 1.7で、SubFilterの項にはさらに次の一文が追加になりました。
Other values can be defined by third party developers, subject to the restriction that all names beginning with the adbe. prefix be reserved for future versions of PDF. All third party names must be registered with Adobe Systems.
これで、サードパーティが他の値を定義しても良くなり、独自拡張可能になりましたので、削除しなくても問題なくなりました。PDF 1.7のように記述を追加して拡張可能にする、というのが正当な方法でしょう。
さて、3回にわたり、ECOMのJIS原案に掲載されている「PDF/Aへの長期署名の適用方法」について検討しましたが、その目的のひとつは、アンテナハウスPDFでこれを採用するかどうかを判断することがあります。結論は、既に明らかなように、アンテナハウスPDFにはこの仕様案は採用できないです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年08月17日
PDFと長期署名(14) — 長期署名は記録保存モデル
前回は、電子証明書が失効したり有効期間を過ぎてしまうような長期にわたって電子署名の有効性をたもつことが必要になることがあり、そのような事情には署名時点での信頼性を保全するA型、と現時点での信頼性の確認を必要とするB型の2つの立場があるとお話しました。
2007年08月14日 PDFと長期署名(13) — 長期署名はどうあるべきか
このように分けますと、現在の長期署名の多くは、A型の要求に基づくものになっているようです。これは、長期署名が必要とされる動機として、裁判などの証拠性を高める、あるいは、行政からの要求による証拠の保全などに基づくものだからでしょう。
ECOMの「電子署名長期保存に関するガイドライン」(平成14年3月)には、次のような定義があります。
「本ガイドラインでは、長期に渡り、デジタル署名の有効性を再確認することを可能とすることにより、デジタル署名の有効性を保証するモデルを検討し、デジタル署名の有効性を維持することを、以下のような事象が発生しても過去に有効性を検証したデジタル署名の再検証を行うことにより、デジタル署名の有効性を確認可能としておくことと定義する。
・公開鍵証明書の有効期限を過ぎた
・公開鍵証明書が失効された
・暗号アルゴリズムが脆弱化した」
(pp.10~11)
ECOM推奨長期署名形式であるCAdES/XAdESも、記録文書に署名を付与し、その署名の検証に成功したら、そのときの情報をカプセルに封印して保全する技術といえると思います。
一方において、B型の例として、有価証券類への署名を考えますと、このような証拠の保全としての長期署名では、その要求を満たすことができないのではないかと思います。有価証券類への署名は、それを評価・検証する時点において信頼できるものと判断できなければ、その有価証券類の取引は成立しないと考えられるからです。有価証券類に限らず、その時点の価値に基づいて取引されるような証書に署名をつけるとすると、その署名の信頼性は、検証する時点の実在環境で確立させる必要があると思われます。このような有価証券型の長期署名モデルも、検討の価値があると思われます。しかし、この論点は少ないようです。
なぜ、このような話を持ち出したかと言いますと、私には、PDFの電子署名の基本的な考え方は、カプセルに封印して保全する型の長期署名とはかなり異なっているように思われるからです。PDFの電子署名モデルは、文書を変化するものとして捉えています。PDFの電子署名は、いわば、変化する文書のスナップショット・モデルです。
前回、最初にPDFの長期署名がどうあるべきかを考えるのは難しいと申し上げましたが、これは、ECOMなどで議論しているA型長期署名形式であるCAdES/XAdESと、PDFの電子署名仕様は、どうも基本の考え方が違うという印象があるからです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年08月14日
PDFと長期署名(13) — 長期署名はどうあるべきか
さて、次にPDFへの長期署名をどのようにすべきか、ということを考えてみたいと思います。しかし、これは非常に難しい問題です。
電子署名は技術ではなく、社会のシステムであること
なぜかと言いますと、電子署名は技術ではなく、社会的なプロセスだからです。技術という点で言いますと、例えば、RSAの公開鍵暗号アルゴリズムは、既に、特許も失効しているほどの古い技術です。そのアルゴリズムを使う限りでは新しいソフトウエア開発などは必要ありません。電子署名をつけたり、検証するプログラムを開発するには、無論、ノウハウは必要ですが、取り立てて新しいものを研究開発するというものではありません。
難しいのは、電子証明書という”証明書”の存在であり、その証明書を信頼するかどうか、という問題です。これは、社会システム的な、もっと具体的に言えば、例えば、電子帳簿保存法という法律、あるいは、その法律に基づいて業務を執行する国税庁の判断、あるいは、電子署名の証拠性という観点でいえば、裁判所がどのように判断するか、という問題です。
すなわち、電子署名の難しさは、技術面にあるのではなく、社会面にあるのです。電子署名について本当に議論するとするなら、特にメーカの技術者や研究者ではなく、もっと利用者、あるいは、経営者や政治家が議論するのが本筋のように思います。
技術的な観点のみの、すなわち仕様のみの議論ではなかなか良いものは作れないでしょう。もともと曖昧なものを、技術で押さえこもうとしますと、どうしても高度で複雑な要求仕様を出すことになりがちです。しかし、実際に裁判になる可能性が少ないのに、最悪の場合の証拠を用意するために多額のお金をかけてシステムを作るのは無駄でしょう。コスト面から考えますと、必要最小限の仕組みを考えなければなりません。しかし、裁判になったときのことを考えると、技術者の立場から、必要最小限を提案するのは、どうしても難しくなります。
電子署名のしくみであるPKIが導入されたのは、2000年~2001年頃と思いますが、現時点で、一部を除いて、まったく普及していないのは、現在のPKIが技術者と役人が考えた社会システムであって、現実の要求に応えていないということがその理由でしょう。注意しないと長期署名でも同じことを繰り返しそうです。
電子署名の検証者の立場を考える
さて、電子署名では、文書に署名する処理と、その文書の署名を検証する処理が対になっているわけです。署名者が署名したものを、受領者が受け取って直ちに検証して、そこで処理が完了するものであれば、あまり大きな問題はないのですが、署名から検証までの時間が長くなりますと、署名と検証の間に時間が経過して、次のような状況になることがあります。
電子署名を付与したときは、電子証明書の信頼性を確認できた。しかし、検証時には、既に、電子証明書が有効ではなくなっている、または有効性を確認できないことがある。
さらに、それ以外に、アルゴリズムが脆弱化してしまう可能性もあります。
二つの異なる要因を同時に考えるのは、話が複雑になりますので、とりあえずは、証明書問題だけを考えて見ましょう。
電子証明書が、署名時は信頼できると判断できたのですが、検証時に、信頼できない、または、信頼性を判断できないというのは、次のケースがあります。
1.証明書の有効期限が過ぎてしまった。
2.証明書が有効期限が来る前に、失効してしまっている。
3.証明書を発行した機関が信頼できない状態になった、あるいは機関がなくなってしまった。
他に、電子証明書は、本来は有効なのだが、システム上の要因で判断できないことがあるかもしれません。例えば、システムがネットワークに繋がっていないなど。こうした要因を別にして、上の1~3のようなときは、検証者はどう判断すれば良いのでしょうか?
これは、明らかに、文書の内容と検証者の立場によって変わります。
A. 過去に署名された書類のその時点での信憑性を確認するのが目的であれば、署名時点に遡って、署名と証明書の信頼性を確認できれば良いことになります。
B. それに対して、例えば、有価証券、土地や家屋の権利書のような証書であれば、検証する時点で有効でないと意味がないことになります。そうなりますと、長期にわたって、常に現時点で署名が検証できる状態を保たねばなりません。
このAとBでは立場が相当に異なるのではないかと思います。AとBのどちらを目的にするかによって、同じ長期署名でも、要求仕様、さらには、実現する社会システムはまったく別のものとなるでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年08月11日
PDFと署名(45) — PDFに署名をするとどういう効果があるか?(1)
さて、先日の「アンテナハウス PDF 電子署名モジュール V1.0 」の新製品発表会でのスライドを使って、PDFに電子署名をつけるとどんな効果が得られるかをお話してみます。

PDFに電子署名をつけるメリットは、上の5項目に集約できると思います。
1項は、署名の対象になるコンテンツに関する保証で、PDFに限らず電子署名一般にあてはまります。
2項は、電子署名に付随する電子証明書がもたらす効用と言えます。これもPDFに限りません。
3項は、PDF独自のものです。
4項も、PDF独自のものです。
5項は、タイムスタンプの機能であり、PDFに限らず一般的にあてはまります。
このように、PDFへの電子署名はいろいろな要素がもたらす複合的な効果があります。それだけに仕組みを完全に理解しようとするとなかなか難しいことになります。
一般の人は仕組みを知らなくても、簡単に利用できれがそれで良いと思います。
しかし、このブログは、ある程度専門的なことを仕組みまでお話するのが趣旨ですので、もう少し立ち入ってみたいと思います。

これは電子署名の大きな意味そのものです。
PDFと署名(4) — 公開鍵暗号方式を署名に使うあたりでお話しています。

PDFの電子署名では、署名したPDFには署名者の電子証明書が埋め込まれることになっていますので、その電子証明書を手がかりにして、署名者の信頼性を確認できます。
AdobeのAcrobatもそうですが、アンテナハウスのPDF電子署名モジュールも、自己署名証明書を発行することができます。自己署名証明書は、個人が自分で秘密鍵と公開鍵を作成し、公開鍵証明書(電子証明書)を作るものです。PKIの専門家には、あまり評判が良くない(?)自己署名証明書ですが、企業内のようなクローズドな集団内のように電子証明書を確実な信頼性をもって配布する手段があれば、そうやって入手した電子証明書とPDFに埋め込まれている電子証明書を比較してみるなどの方法でPDFに署名した人の信頼性を確認することができます。ですので、自己署名証明書でも十分な意義があります。
電子署名の検証で、難しい問題はこの電子証明書の検証問題です。PDFコンテンツが改竄されているかどうかは、ハッシュ・アルゴリズムと暗号アルゴリズムというコンピュータによる単なる計算の問題に過ぎません。ところが、電子証明書の検証には、有効期限、失効情報、証明書の認証機関、ルート証明書への認証パス構築など、やたらに難しい問題がいろいろあります。難しい問題の大半は、電子証明書に起因するといっても過言ではありません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年08月06日
PDFと長期署名(12) — ECOM提案のPDF/A長期署名を再び批判する
前回、PDFと長期署名(11) — ECOM提案のPDF/A長期署名で、ECOMのJIS原案を批判しました。
このJIS原案少し改訂になったようで、現在は、
附属書E
(参考)
PDF/Aへの長期署名の適用方法
となっています。
この付属書Eを書いた人は、PDF/Aの仕様をまったく理解していないと言いましたが、それだけではないようです。PDF Reference の電子署名に関する規定も理解していないようです。
PDF Referenceには、1.4以降1.7まで、一貫して次の一文があります。
Once a document has been signed (see Section 2.2.6, “Security”), all changes made to the document must be saved using incremental updates, since altering any existing bytes in the file will invalidate existing signatures.
(PDF Reference 1.4 p.69)
つまり、PDFに電子署名を施すと、その後、PDFは常に増分更新をしなければならなくなります。
電子署名を施したPDFに添付文書をつけると、その添付文書は、署名後のPDFファイルへの増分更新となります。
ECOMのJIS原案には、次のような一文があります。
E.3 時刻付き署名データ及び長期保存署名データの格納方法
e)長期署名の延長(アーカイブタイムスタンプの再取得)は,添付ファイルに格納された長期保存署名データに対して行い,添付ファイルを差し替える。
しかし、増分更新である以上、添付ファイルの差し替えはできません。
ちなみに、Acrobat 8で、署名したPDFに添付ファイルをつけます。これは、PDF/Aとしては許されませんが、PDFとしては許可されます。
その添付ファイルを削除しようとしますと、次のような警告がでます。
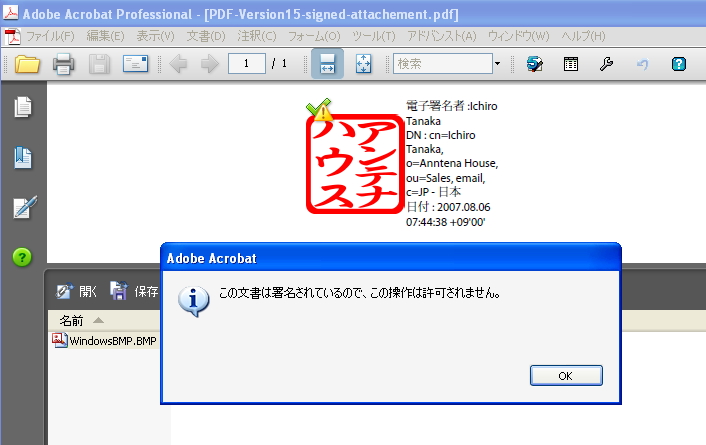
つまり、PDFに電子署名を施したあと、添付ファイルをつけると、その添付ファイルを削除することは、PDF Reference1.4以降の仕様上許されません。追加はできますが、差し替えはできないのです。仮に、差し替えするようなツールを作ったとしますと、そのソフトはPDFの標準を無視したソフトということになります。
前回は、PDF/Aでは、添付ファイルが許されないと言いましたが、仮に、PDF/AをPDFに変更したとしても、この附属書E(参考)PDF/Aへの長期署名の適用方法はPDF Referenceに不適合となってしまいます。
この付属書は全面撤回する方が良いのではないでしょうか。
ところで、ここまで書いて、もしや、と思い、ISO DIS 32000を見ますと次のようになっています。
Once a document has been signed (see 12.8, "Digital Signatures"), all changes made to the document may be saved using incremental updates, since altering any existing bytes in the file invalidates existing signatures.
must beがmay be に入れ替わっています!PDF Reference 1.7とISO DIS 32000は技術的に同等なはずなんですが。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年08月03日
PDFの標準
・PDF 1.7に基づくISO 32000の標準化作業が始まりましたが、他にPDF関係の標準化は次のものがあります。
・PDF/X
1998-99に標準化作業開始、2001年にISO 15930として発行。
・PDF/A
2002年10月標準化作業開始、2005年にISO 19005-1として発行。
現在、PDF/A-2の作業中
・PDF/E(Engineering)
2004年6月作業開始、2007年秋にISO 24517-1として発行予定。
・PDF/Universal Access
2005年1月より作業開始。2008年に投票予定。
・PDF/H(Healthcare)
2006年6月作業開始。2007年秋にベスト・プラクティス・ガイドと実装ガイドを発行予定。
PDFに関する標準化のためのWiki
PDF Standards
http://pdf.editme.com/Home
早速、登録しましたが、どうやらこれは、USの標準化委員会が開設したものようです。USの標準化委員会は、USに住所を持つ人でないと参加できませんので、入れてもらえるかどうかは分かりません。
投稿者 koba : 08:03 | コメント (0) | トラックバック
2007年08月01日
PDFと長期署名(11) — ECOM提案のPDF/A長期署名
日本では長期署名については、ECOMで熱心に取り組んでいることは、一番最初にお話しました。
ECOMでは、長期署名について、調査を行い、また相互運用実験を行い、さらに、JIS規格化に向けて提案を行っています。この活動自体は高く評価されるべきと思います。
ところが、このJIS規格案の付属書Bに次のような参考資料があります。
附属書B
(参考)
PDF/A への長期署名の適用方法
冒頭に「ISO / DIS 19005-1 において規定された、長期保存のための電子文書フォーマットであるPDF/A は、。。」とあって驚きます。まず、ISO 19005-1は、DIS(仕様草案)ではなくIS(仕様)じゃないでしょうか。それを知らないはずはないにも関わらず、DISと言っているのは、PDF/A-2を狙っているのでしょうか。意味深です。
さて、それはともかく、本文はかなり問題があるように思います。
B.1-d)この附属書では,PDF/A への長期署名適用のために,次の名前を定義する。
とあり、
「B.3 時刻付き署名データ及び長期保存署名データの格納方法」
時刻付き署名データをPDF コンテンツの署名タグ内に格納し,可変長の長期保存署名データは添付ファイルとして格納する(図B.1 参照)。
とあります。このような文脈から、この参考資料では、PDF/Aで添付ファイルを使おうと意図していることが明確です。
しかし、このブログをお読みいただいた方は、既にお分かりと思いますが、PDF/A-1では添付ファイルは許されていません。
従いまして、この案は、ISO 19005-1(PDF/A-1)に対して不適合です。いくら参考資料とはいえ、なぜ、わざわざPDF/A-1に不適合な仕様を提案しているのでしょうか?
そこで、ECOMに問い合わせましたところ、次のような回答をいただきました;「電子署名に関し,昨年始めからISO/TC171国内委員会と連携してISO/TC171/SC2/WG5(PDF/Aの標準化WG)に対して,問題提起を行なってきました。この結果,今年1月の会議で各国の賛同を得て,電子署名部分がPDF/Aから切り離され別の仕様になることが決まりました。JISの附属書はこの経緯を踏まえたものとなっています。」
なんだそうです。しかし。。。将来、PDF/A-2で添付書類が許される可能性があるのでしょうか?
私の理解したところでは、 ISO 19005-1を書いた人たちの頭では、PDFの長期保存性を実現するために、PDF/AはPDFファイルの外部環境に一切依存しないで自己完結型のPDFとする、という基本方針に基づいて仕様が作成されているように思います。それに対して、PDFの添付ファイルは、PDFとは異質の別形式のファイルを、PDFの後ろに取り外し可能なアタッチメントのように取り付けたものです。
このように考えますと、PDF/Aの設計思想と、添付ファイルは本質的に相容れないのではないかと思います。従って、将来、PDF/A-2になったとき、(すくなくとも無制限には)添付ファイルを許可する可能性はないように思います。
2番目の大きな問題:長期署名対象のPDFをPDF/Aに限定する必要があるのでしょうか?
このブログをお読みになったかたは、理解されると思いますが、PDF/Aファイルを作るのはかなり大変です。つまり、通常のPDFに比べて、PDF/Aというのは、PDFに対してものすごく大きな制約をかけているものです。ですので、世の中にPDFが100個あったとして、PDF/Aにできるのは、恐らく1個未満じゃないかと思います。
Acrobat8 Professionalをお持ちのかたは、プリフライト機能で、あるPDFがPDF/Aに適合しているかどうかをチェックしてみたら良いと思います。現在、流通しているPDFの99%以上は、PDF/A不適合になるでしょう。いや、もしかすると、WebにあるようなPDFは、ほぼすべて(100%に限りなく近く)がPDF/A不適合となるかもしれません。
PDF/A仕様に適合するPDFを作ろうとしますと、オリジナルのコンテンツからそのことを配慮して作らねばなりませんし、世の中に広く流通しているプリンタ・ドライバ形式のPDF生成ソフトでPDF/Aを作るのは困難、もしくは不適切だろうと思います。
なぜ、そういう性格をもつPDF/Aを前提に長期署名を考えるのでしょうか?普通のPDFに長期署名をつけるのではだめなのでしょうか?
この二つの問題点から、ECOMのJIS案の附属書Bを書いた人達は、PDF/Aについて正しい知識を持っていない、あるいは、全く勉強しておらず、ご都合主義でPDF/Aという単語をつかっているにすぎないと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月31日
PDFと長期署名(10) — PDF/A 仕様 8 タグ付きPDF
PDF/Aの最後の要求項目はPDF内に文書を構造化するタグをつけることです。但し、これは、PDF/A-1aのみの要求項目であり、PDF/A-1bでは要求されません。
タグ付きPDFの機能は、普通は、アクセシビリティの要求項目と考えられています。つまり、PDFを画面に表示して、スクリーンリーダなどで読み上げるとき、その読み上げ順序を正しいものにするためです。PDFの音声読み上げで困るのは、PDFの中に入っている読み上げ対象の文字列が、読み上げたい順序で入っていないことがあることです。それから画像などは読み上げ出来ませんので、代替文字列を入れておき、それを読み上げることになります。
アンテナハウスのXSL FormatterV4.0以降はこのタグ付きPDFを出力することができます。Formatterの製品説明のWebページにタグ付きPDFの機能についての詳しい説明があります。
http://www.antenna.co.jp/XSL-FO/V4/pdf.htm
のタグ付きPDFの項を参照してください。
XSL Formatterの場合、オリジナル組版対象データはXMLであり、それをXSL-FOというスタイル指定されたXMLに変換していますので、元の文書に構造があり、比較的容易にタグ付きPDFの要求する構造化タグをPDFに埋め込むことができます。
また、画像ファイルへの代替文字列、テキスト言語の指定などの要求もオリジナルデータがそのように作ってあれば問題なく対応できます。
しかし、通常のオフィス・アプリケーションで作成した文書をタグ付きPDFに出力するのは、もともとオリジナルに構造がないだけに難しいものがあります。「Wordでタグ付きPDFをうまく作る方法」なんてセミナーがあるくらいです。
そういった難しさがあるために要求水準の高いPDF/A-1aに分類されているのでしょう。
PDF/Aの仕様書によりますと、タグ付きPDFの要求の部分には次のようなことが書いてあります。
6.8 論理構造
・タグ付きPDFの要求の意図は、適合するPDFのファイルのテキストの意味を回復するとき、言語の自然な読み順に定義されるような語句の並びになることを保証すること。
・さらに、文書の論理構造に関して、高度なレベルの意味的な情報を回復できること。
そして、さらに次の注意があります。
・PDF/A-1aを作成するソフトは、オリジナルの文書に明示的または暗黙に存在しない構造または意味的な情報を、PDF/A-1aに適合させる、という目的のみで付加してはならない。
・適切な検証をしないまま、自動的なプロセスで、構造的または意味的な情報を生成するのは薦めることができない。
つまり、タグ付きPDFを自動的に生成して、それがPDF/A-1aに準拠すると主張するためには、元の文書自体に構造がなければならない、ということを言っています。
もとの文書の構造がないときは、手作業などでPDFにタグを埋めて行く必要がありそうです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月29日
PDFと長期署名(9) — PDF/A 仕様 7 XMPメタデータの例
PDF/A-1の仕様書では、XMPメタデータに独自のスキーマで拡張していますが、これは何に使うのかよくわかりません。
そこで実際のPDFを調べてみました。
まず、PDF1.4で簡単なPDFを出力します。Microsoft Wordで簡単な文書を作成してAcrobat 8.1(ドライバ)で出力しました。
このPDFをAcrobat 8.1のProfessionalのプリフライト機能でPDF/A-1b準拠かどうかを調べてみます。
結果は次の図のようになります。
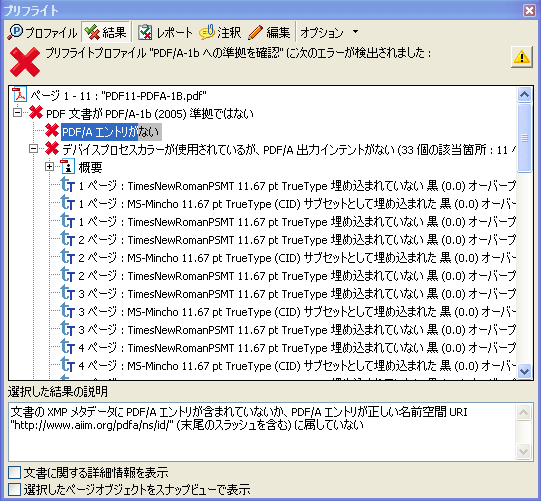
様々な問題があってPDF/A-1b準拠ではないとされています。一番多いのはフォントの埋め込みとカラー出力が違反しているようですが、この際、それは無視して、
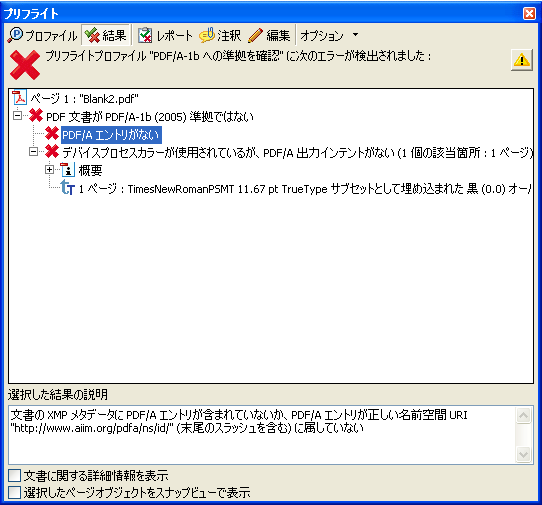
・PDF/Aエントリがない
「文書の XMP メタデータに PDF/A エントリが含まれていないか、PDF/A エントリが正しい名前空間 URI "http://www.aiim.org/pdfa/ns/id/" (末尾のスラッシュを含む) に属していない」
というメッセージに着目してみます。
このメッセージは、どうも、昨日の「PDF/A識別スキーマ 名前空間接頭辞はpdfaid (名前空間http://www.aiim.org/pdfa/ns/id)」に対応するエントリがない、と言っているようです。
仕様書を見ますと、これは次のように説明されています。
-------------------------------
PDF/Aのバージョンと適合性レベルについては、ここで規定するPDF/Aの識別拡張スキーマで指定しなければならない。
pdfaid:part PDF/Aバージョン識別子
pdfaid:amd オプションのPDF/A補足識別子
pdfaid:conformance PDF/A適合レベル:AまたはB
-------------------------------
ということで、やはり、PDF/Aでは独自のスキーマも使っているようです。
これが具体的に、PDFの中でのXMPスキーマにどのように影響を与えるのでしょうか?
PDF/A-1b準拠でないPDFをPDF/A-1b準拠になるように変換して、XMPメタデータがどう変わるかを見てみました。
■元のPDF
※PDF/A-1b準拠ではない。
■変換後のPDF
※PDF/A-1b準拠
◎メタデータの比較
■元のPDFに埋め込まれているXMPメタデータ
<x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="Adobe XMP Core 4.0-c316 44.253921, Sun Oct 01 2006 17:14:39">
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about=""
xmlns:xap="http://ns.adobe.com/xap/1.0/">
<xap:CreatorTool>PScript5.dll Version 5.2</xap:CreatorTool>
<xap:ModifyDate>2007-07-28T18:14:13+09:00</xap:ModifyDate>
<xap:CreateDate>2007-07-28T18:14:13+09:00</xap:CreateDate>
</rdf:Description>
<rdf:Description rdf:about=""
xmlns:dc="http://purl.org/dc/elements/1.1/">
<dc:format>application/pdf</dc:format>
<dc:title>
<rdf:Alt>
<rdf:li xml:lang="x-default">Microsoft Word - Document2</rdf:li>
</rdf:Alt>
</dc:title>
<dc:creator>
<rdf:Seq>
<rdf:li>Antenna House</rdf:li>
</rdf:Seq>
</dc:creator>
</rdf:Description>
<rdf:Description rdf:about=""
xmlns:pdf="http://ns.adobe.com/pdf/1.3/">
<pdf:Producer>Acrobat Distiller 8.1.0 (Windows)</pdf:Producer>
</rdf:Description>
<rdf:Description rdf:about=""
xmlns:xapMM="http://ns.adobe.com/xap/1.0/mm/">
<xapMM:DocumentID>uuid:cec7a163-5d4f-4715-9f5f-5a7e98b4b17e</xapMM:DocumentID>
<xapMM:InstanceID>uuid:7b511bc7-cdc6-4476-af84-787a7a31e672</xapMM:InstanceID>
</rdf:Description>
</rdf:RDF>
</x:xmpmeta>
■変換後のPDFに埋め込まれているXMPメタデータ
<x:xmpmeta xmlns:x="adobe:ns:meta/" x:xmptk="Adobe XMP Core 4.0-c316 44.253921, Sun Oct 01 2006 17:14:39">
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about=""
xmlns:xap="http://ns.adobe.com/xap/1.0/">
<xap:CreatorTool>PScript5.dll Version 5.2</xap:CreatorTool>
<xap:ModifyDate>2007-07-28T18:15:52+09:00</xap:ModifyDate>
<xap:CreateDate>2007-07-28T18:14:13+09:00</xap:CreateDate>
<xap:MetadataDate>2007-07-28T18:15:52+09:00</xap:MetadataDate>
</rdf:Description>
<rdf:Description rdf:about=""
xmlns:dc="http://purl.org/dc/elements/1.1/">
<dc:format>application/pdf</dc:format>
<dc:title>
<rdf:Alt>
<rdf:li xml:lang="x-default">Microsoft Word - Document2</rdf:li>
</rdf:Alt>
</dc:title>
<dc:creator>
<rdf:Seq>
<rdf:li>Antenna House</rdf:li>
</rdf:Seq>
</dc:creator>
</rdf:Description>
<rdf:Description rdf:about=""
xmlns:pdf="http://ns.adobe.com/pdf/1.3/">
<pdf:Producer>Acrobat Distiller 8.1.0 (Windows)</pdf:Producer>
</rdf:Description>
<rdf:Description rdf:about=""
xmlns:xapMM="http://ns.adobe.com/xap/1.0/mm/">
<xapMM:DocumentID>uuid:cec7a163-5d4f-4715-9f5f-5a7e98b4b17e</xapMM:DocumentID>
<xapMM:InstanceID>uuid:a5955ee8-71ba-45bf-9673-e79858058a3a</xapMM:InstanceID>
</rdf:Description>
<rdf:Description rdf:about=""
xmlns:pdfaid="http://www.aiim.org/pdfa/ns/id/">
<pdfaid:part>1</pdfaid:part>
<pdfaid:conformance>B</pdfaid:conformance>
</rdf:Description>
</rdf:RDF>
</x:xmpmeta>
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月28日
PDFと長期署名(8) — PDF/A 仕様 6 XMPメタデータ
PDF/A-1準拠のPDFには、XMPメタデータを埋め込む必要があります。XMPメタデータは、Adobeが開発したものですが、誰でも再配布可能なオープン・ソースライセンスで公開しているものです。
以前(2006年4月16日~4月18日)にブログでも取り上げました。そのときのお話を整理したものがこちらです。
XMP™ (Extensible Metadata Platform)仕様についてのメモ
前回、メタデータを取り上げました時は、PDF Reference(1.7では10.2節)のことを中心にしていました。PDF Reference 10.2項で定義しているメタデータ・ストリームは、文書カタログまたはコンポーネント単位にXMPメタデータ・ストリームを置いて、文書全体または、部品単位にXMPでメタデータをつけ、再利用可能にすることを目的にしていると思います。
XMPメタデータの仕様はこちらです。
XMP仕様書 (PDF) 2005年6月
発行年月は2005年となっていますが、AdobeのWebページにあるものも変更されてないようです。
PDF/A-1では、このXMPメタデータの定義をかなり拡張しています。
標準のXMPメタデータ仕様に準拠する、と言いながら、PDF/A独自の名前空間をいろいろ定義しています。
・PDF/A拡張スキーマ記述スキーマ 名前空間接頭辞はpdfaSchema (名前空間http://www.aiim.org/pdfa/ns/schema)
・PDF/A プロパティタイプ・スキーマ 名前空間接頭辞はpdfaProperty (名前空間http://www.aiim.org/pdfa/ns/property)
・PDF/A 値型スキーマ 名前空間接頭辞はpdfaType (名前空間http://www.aiim.org/pdfa/ns/type)
・PDF/Aフィールド・スキーマ 名前空間接頭辞はpdfaField (名前空間http://www.aiim.org/pdfa/ns/field)
・PDF/A識別スキーマ 名前空間接頭辞はpdfaid (名前空間http://www.aiim.org/pdfa/ns/id)
XMPをこうやって拡張してなにをしようとしているかと言いますと、スキーマを定義しただけで使い方をあまり書いてないように思いますが。明日、もう少し読んでみましょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月27日
PDFと長期署名(7) — PDF/A 仕様 5
次は、PDF/Aで注釈とアクションがどのようになっているかを説明します。
注釈
PDFの注釈(Annotaion)は、PDF Reference1.4では次のものが定義されています。
テキスト注釈、リンク注釈、フリーテキスト注釈、線、矩形、円、ハイライト、アンダーライン、雲形、取り消し線、スタンプ、インク、ポップアップ、ファイル添付、音声、動画、ウイジット、プリンター・マーク(トンボ)、トラップネット。
PDF/Aを表示するリーダでは、注釈辞書のContentsキーの値を表示しなければなりません。例えば、リンク注釈では、Contentsキーには、リンク情報の代替文字列を表示する仕組みが必要とされています。Contentsキーがあるかどうかは注釈の種類によります。但し、ほとんどの注釈で必須です。
注釈の種類は、PDFのバージョンが上がるにつれて追加されていますが、PDF/A-1では、PDF 1.4にない注釈を使用するのは禁止です。さらに、ファイル添付、音声、動画を注釈として使用することが禁止となっています。
* 注釈のCAキーの値は1.0以外であってはなりません。注釈辞書はFキーを含む必要があり。FキーのPrintフラグビットは1にセットします。 Hidden、Invisible, NoViewフラグビットは0にセットします。テキスト注釈は、FキーのNoZoom、NoRotateフラグを1にセットします。
* 注釈辞書は、PDF/A-1OutputIntent辞書のDestOutputProfileのカラー空間がRGBでないときは、C配列、IC配列を含むことができません。
* 注釈辞書が、APキーを含むならば、それが定義する概観辞書は、その値が、注釈の外観を定義するストリームであるNキーのみを含むこと。
アクション
* Launch, Sound, Movie, ResetForm, ImportData, JavaScriptアクションは禁止されています。set-state、no-opアクションは禁止。NextPage, PrevPage, FirstPage, LastPage以外の名前付きアクションは禁止。対話フォームはアクションを実行禁止。
* Widget注釈辞書、フィールド辞書はAAエントリを含んではなりません。文書カタログ辞書はAAエントリを含んではなりません。これらのAAエントリは、外部に依存するJavaScriptアクションのためのものなのでこれを禁止していることになります。
* 対話的なリーダはハイパーリンクを動作不能にすることができます。しかし、GoToRアクション辞書のFとDキー、URIアクション辞書のURIキー、SubmitFormアクション辞書のFキーを表示するメカニズムを提供しなければなりません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月26日
PDFと長期署名(6) — PDF/A 仕様 4
PDF/A-1 の仕様について、続きです。次はフォントです。これもなかなか細かいです。
4.フォント
PDF/Aでは、PDFの中のテキスト情報を、長い将来に渡り、可視化した時に、グリフ単位で最初に作成したときのファイルの見かけに一致し、文字の意味特性を再現できることを意図しています。そのためにフォント関連の要求が規定されています。
* フォントはPDF Reference 5.5に規定するフォント仕様に準拠していること。なお、マルチプルマスター・フォントはType1フォントの特殊なケースと考えます。
コンポジットフォント
* コンポジットフォント(Type 0フォント)では、CIDSysteminfo辞書のRegistryとOrdering文字列は、CMap辞書のUserCMapキーの値がIdentity-HまたはIdentity-Vの時を除き、一致しなければなりません。
* Type 2 CIDFontは、CIDFont辞書にCIDからグリフインデックスへの変換表であるCIDtoGIDMapを含むか、Identityでなければなりません。
* CMap は、Identity-HとIdentity-Vを除いて、PDF Referenve 5.6.4に記述されているようにファイルに埋め込まれる必要があります。埋め込まれたCMapについて、CMap辞書のWModeエントリの整数値は、埋め込まれたCMapストリームのWMode値と同一であること。
フォントの埋め込み
* フォントがテキストレンダリング・モード3のみに使われる場合を除いて、PDFファイルの中で使用されているすべてのフォントが埋め込まれていなければなりません。Type1の標準14フォントも例外ではなく、埋め込み対象です。
* リーダは、環境にあるフォント、代替フォントあるいはシミュレートされたフォントではなく埋め込みフォントを使用します。
* Type 0 CIDFont、Type 1、TrueTypeフォントのサブセット埋め込みでは、ファイル中のすべてのグリフを定義しなければなりません。Type1フォントのサブセットは、フォント記述辞書に、フォントのサブセットの中で定義される文字の名前を一覧化したCharSet文字列を含まねばなりません。CIDFontのサブセットは、埋め込まれたCIDFontファイルの中に、どのCIDが存在するかを識別するCIDSetストリームを含まねばなりません。
フォントメトリックス
* 埋め込まれたフォントの、フォント辞書のWidthエントリに蓄積されたグリフの幅の情報と埋め込まれたフォントの中の情報は一致しなければなりません。
文字符号化対応表
* シンボリックでないTrueTypeフォントは、フォント辞書のEncodingエントリの値として、MacRomanEncodingか WinAnsiEncodingを指定しなければなりません。シンボリックなTrueTypeフォントは、フォント辞書にEncodingエントリを指定してはならず、フォントプログラムのcmapテーブルは一つの符号化のみを含まねばなりません。
* (PDF/A-1レベルAのみの要求)フォント辞書は、一部の例外を除いて、その値が文字コードをUnicode値にマップするCMapストリームオブジェクトであるToUnicodeエントリを含むこと。これによって、Unicodeを使って文字列の検索が可能になります。
5.透明
PDF/A-1に適合するファイルでは透明を使うことができません。具体的には、ExtGState, XObjectのSMaskキーの値はNoneでなければならず、フォームXObjectのGroupオブジェクトにはSキーにTransparency(透明)の値をもつことができない、などです。透明と同じ効果を他の方法で実現することは許されます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月25日
PDFと長期署名(5) — PDF/A 仕様 3
ISO 19005-1(PDF/A-1)の規定を引き続きチェックしてみます。
3.グラフィックス
PDF/A-1ではグラフィックスについてかなり大きな制約を課しています。
出力インテント辞書のSキーに GTS_PDFA1を定義
PDF1.4から文書カタログ辞書にOutputIntentsというキーが定義されました。OutputIntentsキーには、出力インテント辞書の配列によって、文書を可視化するデバイスのカラー特性を記述することができます。PDF/A-1ではOutputIntentsキーに出力インテント辞書を定義することができます。そしてPDF/A-1出力インテント辞書を、出力辞書のSキー(タイプ)にGTS_PDFA1を設定し、そのDestOutputProfileキーの値として妥当なICCプロフィール・ストリームを設定したもの、と規定しています。
もし、出力インテント辞書が複数あるときは、DestOutputProfileキーの値は全て同じICCプロフィール・ストリームでなければなりません。
カラー空間をデバイス独立にすること。
PDF/A-1ではカラーを測色定義などにより、仮定や外部に依存しない、デバイス独立にしていくことが求められています。このために、カラーは、デバイス独立のカラー空間を使うか、それとも、OutputIntentsキーを使って指定しなければなりません。
ICCBasedのカラー空間は、ICCプロフィール・ストリームとして埋め込むこと。
すべてのICCBasedカラー空間は、ICCプロフィール・ストリームとして埋め込み、また、リーダは、ICCBasedカラー空間をICC仕様に指定されているように可視化し、Alternateカラーを使用してはいけません。
DeviceRGBまたはDeviceCMYKのどちらかを使用できますが、両方を使うことはできません。
DeviceGrayをOutputIntentがRGBプロフィールであるファイルの中で可視化するときは、リーダはDeviceGrayカラー指定をPDF Referenceに記述されている方法でRGBに変換しなければなりません。DeviceGrayを、OutputIntentがCMYKプロフィールであるファイルの中で可視化するときは、リーダはDeviceGrayカラー指定をPDF Referenceに記述されている方法でDeviceCMYKに変換しなければなりません。
DeviceNまたはSeparationカラー空間に基づくカラー空間の可視化する規則は次の通り。
o 名前のついたカラー素が、すべて、Cyan、Magenta、Yellow、Blackから来ていて、ファイルがCMYKプロフィールである OutputIntentを持つとき、カラー素はPDF/A-1出力インテント辞書で指定されるカラー空間の要素であるとして扱い、代替カラーを使用してはならない。
o 出力デバイスがSeparationカラー空間またはDeviceNカラーをサポートしないときは、代替カラー空間を使う。
イメージ辞書
代替カラーを示すAlternatesキーやOPIキーを含んではなりませんので、PDF中のイメージを他のイメージで置き換えて表示することができません。もし、イメージ辞書にInterpolateキーを含む場合、その値はfalseでなければなりません。このため、PDFに含まれているイメージの解像度が出力デバイスよりも低いときにも、低いままで出力します。
XObject
フォームXObject
繰り返し使うようなグラフィックス命令のセットをフォームXObjectとして定義できます。フォームXObject 辞書にOPIキーを使えません。PostScriptコードは、PostScript XObjectとして定義する方法の他に、フォームXObject辞書にSubType2キーの値PSでも定義できますが、PDF/A-1では、このようなPostScriptコードを使えません。
※PostScriptについては、PDF Reference 1.4には書いてありませんが、次のerrataに記述があります。
http://partners.adobe.com/public/developer/en/pdf/PDF14errata.txt
Reference XObject
Reference XObjectは、PDFの内容を他からインポートすることができる機能ですが、これは禁止されています。
PostScript XObject
PostScriptプログラムの一部のコードをそのまま取り込むことは禁止されています。
その他
* ExtGState辞書にはTRキーを含んではいけません。TR2キーを含むときは値はDefaultでなければなりません。リーダはHTキーを全て無視します。
* イメージなどはデバイス独立で指定しますが、それでも微妙な調整を可視化インテントで指定できます。この値はRelativeColorimetric, AbsoluteColorimetric, Perceptual, Saturationのどれかにしなければなりません。
* コンテント・ストリームはPDF Reference1.4に定義されていないオペレータを含んではいけません。
※カラー空間の話は、実際のところ、私にはあまり良く理解できていません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月24日
PDFと長期署名(4) — PDF/A 仕様 2
PDF/A-1の仕様書は、表紙を含めて36ページと薄いものです。
アンテナハウスでは、XSL Formatter V4.2でPDF/A-1の出力機能を追加する予定でだいぶ前から実装していました。日本のお客様からはそれほどでもないのですが、やはり海外のお客様からの要望があるようです。
いままでは、担当者から報告を聞いていた程度でしたが、今回、初めて仕様書を読んで見ました。内容はかなり細かな規定があり結構大変です。仕様書を少しづつ読んでみましょう。
2.ファイル構造
ファイル構造の項での制限は細かく記述されていますが、主なものは次の通りです。
・ファイルトレーラ辞書にIDキーワードを含むこと、また、Encryptキーワードを使用してはならない。
ファイルトレーラは、PDFファイルの最後に存在して、アプリケーションは最初にここを読んで、クロス参照表(xref)の場所を探したり、特別なオブジェクトを探します。IDはファイルの識別用に使うものです。通常はオプションですが、PDF/A-1では必須となります。また、Encryptキーワードは、PDFにセキュリティ設定をしたときは必須になるもので、Encryptキーワードを禁止する、ということは、セキュリティ設定を禁止することになります。
・文書情報辞書はXMPメタデータ特性と一致すること。
PDFの文書情報辞書でメタデータを記録します。
PDFの文書情報辞書は、Title、Author、Subject、Keywords、Creator、Producer、CreationDate、ModDate、Trappedがあります。名前で大よその推測がつくと思います。これらの項目の内容は、XMPメタデータの、dc:title, dc:creator, dc:subject, pdf:Keywords, xmp:CreatorTool, pdf:Producer, xmp:CreateDate, xmp:ModifyDateと一致させる必要があります。
・streamオブジェクト辞書にはF、FFilter、FDecodeParamsキーを含んではならない。
これらのキーは、PDFの外部のデータをポイントするためにつかわれるものです。これによりPDFファイルの外部のコンテンツに依存することができなくなります。
・LZWDecodeフィルタは許可されない。
LZW圧縮は特許問題(既に特許は有効期限切れで失効しました)で使用禁止です。
・ファイル仕様辞書(PDF Ref. 3.10.2)には、EFキーを含んではならない。ファイル名辞書(PDF 3.6.3)はEmbeddedFilesキーを含んではならない。
PDFには、PDF以外のファイルを埋め込むことができます。Acrobat8では、「文書」メニューの「ファイルを添付」とすると添付ファイルを使うことができます。
添付ファイルは次のようにPDF本体と別のウインドウで開いてみることができます。
この添付ファイルは、ファイル仕様辞書のEFキーとファイル名辞書EmbeddedFilesキーで指定します。これを使えないことはPDF/A-1では添付ファイル使用禁止を意味します。
・ドキュメント・カタログ辞書には、OCPropertiesを含んではならない。
これにより文書の代替レンダリングを許すオプション内容を含むことができません。要するに、文書の可視化の代替処理を許さないということです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月23日
PDFと長期署名(3) — PDF/A 仕様
PDFは、その名前Portable Document Formatの意味するとことからも明確なように、アプリケーションから独立した電子ファイルの形式として設計されています。Mac OS XのようにOSレベルでPDFをサポートしている場合もあります。ですので、PDFファイルはハードウエアやOSを超えて可視化されることができる点で、Microsoft OfficeやOpenOffice.orgで作成した文書などと比べて非常に有利です。
しかし、一方において、PDFはものすごく豊富な機能をもっています。その中には、電子ドキュメントを長期にわたって保管するという点からは、使用しないほうが良い機能も多数あります。例えば、暗号化によるセキュリティ設定などはその典型的な例でしょう。PDFファイルを暗号化しますと、暗号のための鍵の管理が重大な課題になります。5年、10年、20年経過したときに、もし、暗号の鍵の所在が分からなくなってしまえば、そのPDFの内容を可視化することは極めて難しくなるでしょう。
また、PDFは仕様が公開されており、誰がPDFソフトを作っても良いとされていることから、非常に多くの開発者がPDFのソフトを作っています。
Adobe(ヨーロッパ)の標準ビジネス部門長 Marc Straat氏が2006年12月に行ったプレゼンの資料をみましたら、「Community of nearly 2000 PDF tool developers」とありました。PDFツールの開発者は2000人もいるのだそうです。こうした様々な開発者が作成したPDFが、それぞれ、独自の挙動を示してしまう、という問題も指摘されています。
参考資料
• PDF/A — Format — Status and Practical Experiences
こうした観点から、PDFを長期に保管するためにPDF1.4仕様をもとに、そこにある機能について、必ず設定しなければならないものと、使ってはいけない、あるいは制限付きで使うべきことをまとめたものがPDF/Aです。
PDF/Aについては、「PDF千夜一夜」の中で、既に概要は紹介しています。しかし、今回は、もう少し詳しく、ISOの仕様書を読みながら解説してみたいと思います。
1.PDF/A仕様の意図
PDF/A仕様の意図として、ISO 15009-1の仕様書は次のように述べています。
「PDFは重要な情報を表現するために使われますが、これらの情報には相当な長期にわたって維持されるもの、一部には永久に保存されるものがあります。これらのPDFファイルは多数の技術的世代を跨って、利用可能でなければなりません。」
PDF/Aの目標として、3点を掲げています。
* 作成・蓄積・可視化ツールから独立で、時間がたってもビジュアルな見かけを維持できること。
* 電子文書の文脈と履歴をメタデータの中に残すことができること。
* 電子文書の論理的な構造と意味に関する情報を残すこと。
ところで長期的とはどの程度なんでしょうか?ISOの仕様書には「長期的」という言葉を次のように定義しています。
"period of time long enough for there to be concern about the impacts of changing technologies..略 .. and of a changing user community, on the information being held in a repository, which may extend into the indefinite future"
つまり、技術の変化、ユーザコミュニティの変化が、保管されている情報に対して与える影響について懸念されるほど、の長い期間ということです。先日の国会図書館のケースを見ましても、PDF/Aがターゲットとする長期は、かなり長いということがいえると思います。
投稿者 koba : 00:00 | コメント (0) | トラックバック
2007年07月21日
PDFと長期署名(2) — 電子データを長期に保管するとは?
国立国会図書館の平成16年度の報告書には、同図書館が平成11年度までに受け入れた電子資料の利用可能性の調査結果として次の表が載っています。
出典:電子情報の長期的保存とアクセス手段の確保のための調査報告書 p.5
これをみますと、調査時点から10年前の平成6年の電子資料で15%位しか利用できないという、驚くべき数字になっています。その理由は次のとおりです。
・OS 等、PC の基本ソフトウェアとアプリケーション・ソフトウェアの不適合(69 点)
・アプリケーション・ソフトウェア入手不可(41 点)
・記録媒体の技術的旧式化および劣化(17 点)
・その他(11 点)
昨日もお話しましたが、電子データを可視化(表示、印刷)したり、利用するためには、一般に、そのデータを処理するアプリケーションソフトが必要であり、アプリケーション・ソフトが使えなくなれば、そのデータを完全に元の状態のままで可視化することはできません。
アプリケーションソフトは、ソフトウエアですので、ハードウエアと違って磨耗したり・消耗したり・劣化することはありません。その寿命は無限です。しかし、アプリケーションソフトは、ハードウエア、OSの上で稼動するものですから、ハードウエアが消耗してしまえば使えなくなりますし、OSが変われば動かすことができなくなります。従って、現実として、アプリケーションソフトが利用できる期間は、ハードウエアとOSの入手可能性によって制約を受けることになります。このことが先の調査結果にも明確に現れています。
そこで、電子データを長期的に保存しようとすれば、まずアプリケーションから独立な形式にすることが最も望ましいことになります。他の手段としては、アプリケーションをオープンソース化し、供給元から独立化させて、様々なハードウエア、OSに移植可能にしていくことで、アプリケーションそのものの延命を図るといった方法も考えられるでしょう。しかし、移植作業は大きな工数がかかるのが普通ですから、かりにソースがあっても実現性は低いと思います。
国会図書館で考えているような文化・歴史というレベルの時間単位で考えるのであれば、電子データをアプリケーションから完全に独立にして、それを標準仕様とし、電子データを取り扱いすることのできるアプリケーションを誰でも簡単に作成可能にしていくことが重要であるということになります。
この観点から見ますと、紙に印刷する形式の電子ドキュメントの形式としてはPDFが最も普及していますし、PDFは上に述べたアプリケーションからの独立性という観点からも最も適切な候補となります。こうした時代の要請を受けて策定された仕様がPDF/Archive(PDF/A)です。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月20日
PDFと長期署名(1) — 電子ドキュメントの長期保存とは
さて、次に最近、一部で話題になっている、PDFの長期署名について検討してみたいと思います。
長期署名については、ECOM(次世代電子商取引推進協議会)が熱心に取り組んでいます。
「長期署名フォーマットプロファイルの標準化に向けた活動を開始」
- ETSI/ESIと協調しJIS原案作成に着手 -
このニュースの通り、ECOMは長期署名フォーマットのJISの原案の作成を目指して活動を行ってきました。そして、その成果として、今年度にJIS原案が提出されました。
この原案の付録には、参考資料としてPDF/Aへの長期署名の適用方法に関する仕様も掲載されています。(これは参考資料であって、規格の一部ではないとされています。)
さて、PDFへの長期署名を考える前に、電子ドキュメントの長期保管について少し考えて見ます。
電子ドキュメントの長期保存については、国立国会図書館が平成12年から研究しており、その報告が公開されています。
電子情報の長期的な保存と利用
国会図書館は、国の出版物を収集して、文化遺産として残していく役割を担っていますが、平成12年からCD・DVDやアプリケーションプログラムなどのパッケージ系電子出版物が新たに納本の対象となっています。
国会図書館で収集したこれらのデジタルデータをどうやって長期的に保存するかということは、現在、非常に大きな研究課題です。
デジタル・ドキュメントだけに限ってみても、過去20年の技術の推移たるや、ものすごい変化を遂げています。例えば、日本では、1980年代半ばから、文書はワープロ専用機で作成されてきましたが、1990年代後半からは、文書の編集手段はパソコンのワープロソフトが主流になっています。ワープロソフトのデータは、アプリケーションが違えば互換性はありませんから、アプリケーションを使う環境がなくなってしまえば、もうそのデジタルデータを完全に可視化(表示、印刷)することはできません。
1980年代半ばから1990年代にかけて作成されたワープロ専用機のデータは、仮に、保管されていたとしても、既に、その大半はそのままでは可視化することはできません。アンテナハウスのリッチテキスト・コンバータを使えば、文書データをMicrosoft Wordなどに移して再活用はできますが、元のままの形で可視化することは、現実的なコストでは不可能に近いでしょう。
こうした状況のもとでは、電子署名など考えることすら無意味となります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月17日
PDFがISO標準になることの意義を再び考える!
1月末に、2007年01月31日 Adobe PDFをISO標準として提出へとして、PDFがISO標準になることについてお話しました。あれから約半年で、いよいよISO 32000のドラフトが公開されるという運びになりました。
アドビがPDF 1.7をISO標準として提出するきっかけには、恐らく、MicrosoftのXPS(XML Paper Specifications)の脅威があるのではないかと思います。
Microsoftは過去様々な分野で遅れをとって出発しながらも、時間をかけてもでも先発を追い越してきたという実績があります。AppleのMacintoshに対するWindowの例、Internetブラウザ戦争、そしてJAVA対.NETの対立も、最近の動きを見ていますと、どうやら開発環境はJAVAから.NETへと主導権が移りつつあるという印象を受けます。
そんな、Microsoftの巨大な影響力を知っていれば、アドビがXPSに脅威を感じないはずはありません。無論、XPSに対抗するひとつの方法としてISO標準化という手段を考えたのだろうというのはあくまで推測ではあります。
PDFがISO標準になることは、私達3rdパーティのベンダにとっては大きな意義があります。なにしろ、いままでは、いくらPDF Referenceが公開されているといっても、あくまでAcrobatのクローン製品ということでしたが、ISO標準になればクローン製品ではなく、「ISO標準を実装した製品」ということになります。つまり、大義名分にお墨付きが与えられるということ。これはモチベーション上大きいと思います。
無論、そうなりますと、PDF製品のベンダーもますます増えて、競争はますます激しくなることが予想されます。オープン・ソースも増えて、無償でPDFを作るという動きに拍車がかかる可能性があります。
PDF戦国時代をどうやって勝ち抜くか!
「PDF千夜一夜」も既に、638話になりました。残るは362日ということで既に残り1年を切ってしまいましたが、「燃える闘魂」で、勝ち残りに向けて頑張りたいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年07月16日
ISOにてPDF1.7のドラフト仕様の投票開始
PDF Reference 1.7をベースにしたISOの標準仕様ISO 32000(ドラフト)が公開されています。
こちらからダウンロードできます。
PDF Standard
http://www.aiim.org/standards.asp?ID=33223
この仕様書は既にISOに提案され、7月2日からのファースト・トラック手続きでの投票が始まっています。投票期限は12月2日までです。
この投票を通過することができれば、出版の段階に進みますので、早ければ来年春には、PDF 1.7ベースのISO 32000が国際標準になるものと予想できます。
なお、ISO 32000の仕様書は、全文で748ページです。PDF Reference 1.7は、1,310ページありますので厚さにして6割位に圧縮されたことになります。
どのような形でリライトされたのかがこちらに公開されています。
Change Sheet - ISO Draft of PDF 1.7 Reference
概略は次の通りです。
・ISOの草稿の形式になるように雛形を使って、PDF Referenceを書き直した。
・技術的な内容はそのまま維持して、表現を変更した。
・ベンダー中立になるように、Adobeの製品についての情報への参照を削除した。
最初の2章はAdobeの製品に関連するものなので削除した。
付録C、付録Hの大部分はAcrobatの実装に関するものなので削除した。
・廃止した内容を削除した。
主にAdobeの製品の歴史的な理由から維持されている廃止した仕様を削除した。
・ISOの用語規定に従って、誤解を招くことが少なくなるように記述を変更した。
shall、should、may、canの使い方など。
・アメリカ英語から国際英語に変更。
・ノルマ(規定)的と情報的な内容の分離。
このような修正を注意深く行い、PDF Reference、市場にあるPDF、それを作成したり処理する実装などを忠実に表すPDF 1.7標準として作成した。
以上の結果、ISOドラフトはPDF 1.7のベンダー中立にして、より精密で、より曖昧さを減らす仕様となっている。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年06月30日
PDFについてのQ&A — PDFのフォント埋め込みと著作権(続き)
昨日は、PDFへのフォント埋め込みは権利者の許可なく行うとフォントの著作権侵害となりますが、フォントベンダーによっては埋め込みを許可しているということをご説明しました。
アドビの場合は、埋め込みについては許可しているものが多いようです。
具体的には、こちらにライセンス契約書があります。
http://www.adobe.com/type/browser/legal/index.html
欧文フォント、和文フォントともフォント埋め込みに関する契約条項の文章は同じです。次のようになっています。
「お客様は、お客様の電子文書を印刷および閲覧するため、フォント・ソフトウェアのコピーをその文書に埋め込むことができます。埋め込むフォント・ソフトウェアがAdobeのウェブサイトhttp://www.adobe.com/type/browser/legal/embeddingeula.html で「編集可能な埋め込みのためのライセンス供与済」と指定されている場合は、さらに電子文書の編集の他の目的のためにもそのフォント・ソフトウェアのコピーを埋め込むことができます。」
フォント埋め込みの許可には次の段階があります。
(1)埋め込みを許可しない — アドビのフォントには埋め込みを許可しないフォントはありませんが、フォント・ベンダによっては許可していない場合もあります。
(2)表示と印刷 — フォントをPDFに埋め込んで配布し、表示したり印刷に使うことができますが、PDFを編集するのに用いたり、他のPDFを作成したりするのに用いることができません。アドビのフォントはこの分類が多いようです。
(3)編集可能 — 表示と印刷のほか、PDFの受け手がそのPDFの文書や構造を編集するに用いることができます。
(4)インストール可能 — 受け手がPDFに埋め込まれたフォントをPCにインストールして、新しいPDFを作成するのに用いることができます。これはPDFの受け手はフォントに関してオリジナルと同じ権利をもつことを意味しています。商業フォントではこの分類に属するフォントは少ないと思います。
さて、このようにフォントの埋め込みを許可したり、禁止したりするのは、フォントの権利者(ベンダ)の許諾事項となります。しかし、エンドユーザがフォントの使用許諾契約をチェックしたり、あるいは、権利者にいちいち確認するのは手間が掛かります。
これを自動的に行うために、TrueTypeやOpenTypeといった新しいフォントでは、フォントファイルのフォーマットの中に「埋め込み許可」に関する上記の(1)~(4)の分類情報がセットされるようになっています。
PDFを作成するソフトウエアは、この「埋め込み許可」の情報をチェックして、埋め込みするかどうかを判断することができます。
次の画面は、Antenna House PDF Driver V3.2の設定ダイヤログ「フォント」タブですが、Windowsにインストールされているフォントの一覧を表示するとき、埋め込みが禁止されているかどうかをチェックして鍵のマークで表示するようにしています。
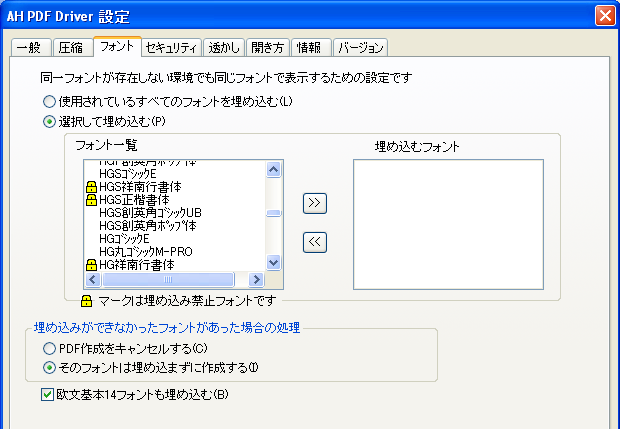
比較的新しいフォントであれば、このようにプログラムで埋め込み許可状態をチェックできます。しかし、Type1のような古いフォントでは、こうしたフラグはありませんので、権利者が許可しているかどうかを個別に確認する必要があります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年06月28日
PDFについてのQ&A —PDFのセキュリティはどの位強固か?
PDFのセキュリティ機能は、どの位強固か、という質問をいただきましたが、その質問にお答えするには、まず、PDFのセキュリティ機能にどのようなものがあるか知る必要があります。PDFで使えるセキュリティ機能には次のようなものがあります。
(1)文書を開くパスワード — PDFファイルを開くときにパスワードの入力を要求し、正しいパスワードが入力されないと文書を開けないようにする。
(2)権限パスワード — PDFファイルは誰でも開くことができるが文書の内容をコピーしたり、高精度印刷したり、編集したりする権限のパスワードを設定する。
(3)文書を開くパスワードの代わりに、PDFを渡したい人の電子証明書を使ってPDFのコンテンツを暗号化し、PDFを閲覧しようとする相手が、対応する秘密鍵がないと開けないようにする。
(4)権限パスワードの代わりに、PDFを渡したい人の電子証明書を使ってPDFのコンテンツを暗号化し、PDFを閲覧しようとする相手が、対応する秘密鍵がないと開けないようにする。
(1)~(4)にあげた標準的なPDFのセキュリティではコンテンツを暗号化しますが、その暗号化プログラム(暗号アルゴリズム)は、RC4-40ビット、RC4-128ビット、AES暗号が一般に使われます。これらの暗号処理機能は標準セキュリティ・ハンドラとしてAdobe Readerに機能があります。
従って、PDFを作成するソフトが、PDFを作成するとき、(1)~(4)の方式で、RC4-40ビット、RC4-128ビット、AES暗号でPDFにセキュリティを設定すれば、Adobe Readerで処理することができることになります。
詳しくはこちらをご覧ください。
PDFの標準セキュリィティ機能
以上で述べたことは標準的な方法です。
しかしPDFでは、独自のセキュリティ・ハンドラ(セキュリティ処理プログラム)を定義することができますので、そうなりますと、そのセキュリティ・ハンドラでできるセキュリティ設定がなんでも可能になります。独自のセキュリティ・ハンドラを使えば、それ以外の暗号アルゴリズムを使うこともできます。従いまして、これについては、「強固」さの度合いはセキュリティ・ハンドラ依存となってしまいます。
さて、暗号アルゴリズムを使ってかけた暗号の強度につきましては、私は暗号の専門家ではありませんのが、一般には、RC4-40ビット⇒RC4-128ビット⇒AES暗号の順で強固になると言われています。
しかし、むしろ、セキュリティが強固かどうかは実際のところは運用に依存すると思います。すなわち、パスワードを使ってPDFにセキュリティ設定した場合、そのパスワードが漏洩してしまえば、パスワードを入手した人には、なんでも出来てしまいます。
日本が開発した「紫暗号」も米国に解読されていたと言う話を読みますと、紫暗号が解読されたきっかけは同じ通信文を、別のもっと脆弱な暗号と紫暗号とで二重に送ったためだそうです。また、ドイツのエニグマ暗号の解読の話を見ましても、毎日同じような暗号文を繰り返した送ったためなどとあります。
ですので、まず、パスワード方式の場合は、パスワードが漏洩しないようにするためにどうするか、最大の課題と思います。
そういう意味では、パスワード方式よりは、電子証明書を使ってセキュリティ設定する方が強固になるはずです。パスワード付きPDFの場合、パスワードを安全に配布するのが大きな問題ですが、電子証明書による暗号化では、パスワード配布の問題が存在しませんので、その分、安全になります。
電子証明書によるセキュリティ設定をサポートしているPDF作成製品は少ないようですが、当社で現在開発しています「PDF電子署名モジュール」では、この電子証明書によるセキュリティ設定も可能となります。
それから、権限パスワードの方は、実際にPDFが相手のPCの上で表示されていることになりますので、情報がまったく漏洩しないというのは常識的に見て考えられないことです。こちらの方は、あくまで、利用を制限する意図を示しているとお考えいただくほうが良いと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年06月20日
PDFと署名(44) — MDP署名の場合
PDFの仕様では、普通の署名とMDP署名という、2種類の電子署名があることは前にお話しました。
2007年05月16日 PDFと署名(28) — PDFの2種類の署名
MDP署名とは、PDF Referenceで、modification detection and prevention(修正検出・防止)と言われているものの頭文字です。日本語版Acrobat 8では、MDP署名は「証明済み署名」(certified signature)と表記されています。
PDFにMDP署名をすると、署名後に変更可能な内容を次の3段階のどれか制限できます。
・変更を許可しない
・フォームフィールドの入力と署名フィールドに署名
・注釈の作成、フォームフィールドの入力と署名フィールドに署名
![]()
「変更を許可しない」を選択してMDP署名をしますと、PDFに対して変更ができなくなりますので、通常署名でできた二つ目の署名を初め、ページの編集、タッチアップ機能によるテキストの変更など一切の変更ができなくなります。従って、増分更新というような機能も無関係です。
「フォームフィールドの入力と署名フィールドに署名」または「注釈の作成、フォームフィールドの入力と署名フィールドに署名」を選択して、MDP署名をしますと、署名時に許可した変更だけができるようになります。署名後の変更内容は、通常署名と同じように、増分更新として保存されます。
PDFの電子署名は、(1)署名フィールドを作成して、(2)そこに署名するという二つのステップの処理を行うことになりますが、MDP署名後に新しい署名フィールドを作成することができません。
MDP署名したPDFファイルに、署名者と別の人に電子署名を求める場合は、予め署名フィールドを作成しておく必要があります。
(1)予め署名フィールドを作成する
![]()
(2)MDP署名をする

(3)通常署名をする

このようにMDP署名と通常の署名では若干ワークフローが違います。しかし、電子署名をした後の変更内容が、PDFファイル上で増分更新として扱われることについての違いはありません。
ちなみにMDP署名をした後、通常署名をしたPDFの署名検証結果(例)は次のようになります。

投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年06月18日
PDFと署名(42) — 署名と増分更新
先日は、PDFの内容を変更した場合、増分更新という保存方法があることをお話しました。
・2007年06月11日PDFと署名(39) — PDFの増分更新
・2007年06月12日 PDFと署名(40) — PDFの増分更新(続き)
増分更新の特徴については、次のように整理できます。
(1) PDFファイルの最後は%%EOFですが、PDFを増分更新すると更新する前のPDFファイルの%%EOFの後ろに更新情報が追加されます。
(2)更新前のPDFに対して、追加した内容だけではなく、更新前のPDFから削除・変更した内容も追加情報として扱われます。
(3)更新部分は、旧版PDFの終わりの%%EOFから更新後のPDFの終わりの%%EOFまでの間に保存され、%%EOFの数はPDFの改訂された版数に対応します。
(4)そこで、増分更新だけを使って更新したPDFであれば、当該の版に対応する%%EOFまでの情報を取り出すことで、改訂前の版のPDFに遡ることができることになります。
通常のPDFでは変更して保存した場合に増分更新しなければならないと決まっている訳ではありません。むしろ、増分更新では、削除した情報を抱えることになる結果、PDFが冗長になりますし、リニアライズ(Web最適化)という面からは望ましくないとも言えます。
例えば、Acrobat8では、「名前をつけて保存」では増分更新となりません。「上書き保存」とすると増分更新となりますが、しかし、PDFの途中のページを丸ごと削除してしまうと、「上書き保存」しても増分更新になりません。
ところが、「PDFに一旦署名をすると、PDFへのあらゆる変更は増分更新としなければなりません。」(PDF Reference 1.7 p.99。 この記述はPDF 1.4から追加された。)
そこで、電子署名に対応するPDFアプリケーションは、電子署名されたPDFを変更する場合は増分更新しなければなりません。この結果、電子署名したPDFについては、旧版のPDFを取り出すことができることになります。
なお、Acrobatでは電子署名PDFに名前をつけて保存するときの機能がバージョンによって少し違うようです。「Digital Signatures in the PDF Language」に次のような一文があります。
---ここから---
最初のAcrobat は、Save As コマンドを使用するとPDF ファイルの中でもはや使われてい
ないオブジェクトを削除し、その結果すべてのファイルを、増分更新セクションのない単純な
PDF ファイルとして保存した。この結果、既存の電子署名を無効にしてしまう。そこで、よ
り最近のAcrobat は、もし電子署名がファイルの中に存在すると増分更新セクションを最適化し
ないようになった。そこで、Acrobat 5 を使っているならば、Save コマンドだけを
使い、Save As コマンドを使ってはならない。または、Acrobat 6 以上を使うこと。
---ここまで---
これを見ますと、Acrobat 6で電子署名PDFのSaveAs機能を変更したと理解できます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年06月13日
PDFと署名(41) —PDFの複数署名
PDFでは、文書に複数の署名をすることができますが、この複数署名は増分更新の機能を使って実現しています。
まず、PDFを作成して、それに普通の電子署名をします。ついで、さらに二つ目の電子署名をします。次のようになります。
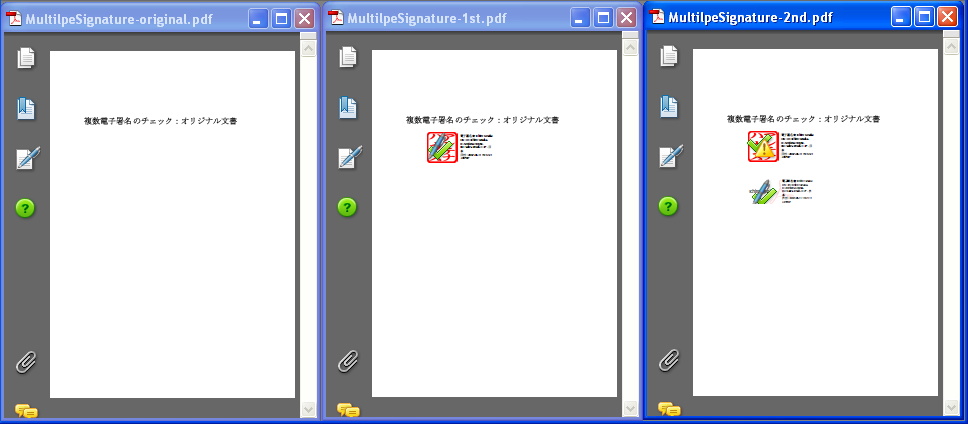
ここで注意して欲しいのは、最初に署名をした段階での署名の検証状態は次のようになっています。
○最初の署名をした段階での電子署名の検証状態
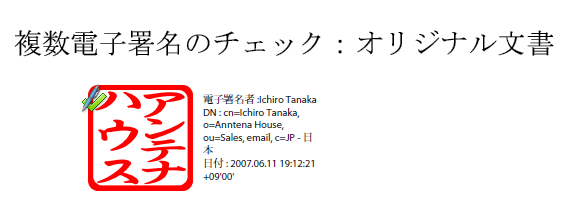
・プロパティ

○二つ目の署名をした段階での電子署名の検証状態
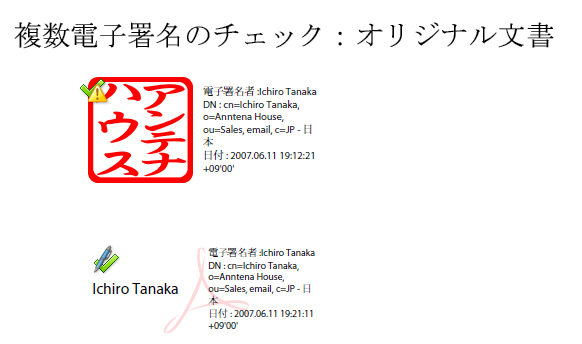
・一つ目の署名のプロパティ

・二つ目の署名のプロパティ

二つ目の署名をした段階で、一つ目の署名は署名が適用された後に変更されたというステータスに変わってしまいます。
PDFファイルの内部は次のようになっています。
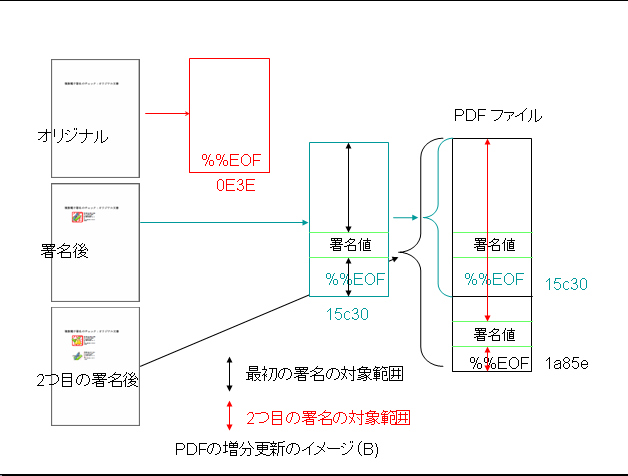
最初の署名をした段階で、オリジナル(署名前)のPDFに対して署名辞書が作成されて、その中に署名データが作られます。署名の対象範囲は、署名データ以外のPDF全体です。
次の署名は最初の署名を含める範囲を署名対象範囲としています。二つ目の署名データは増分更新として作成されます。
また、前回と同じように、増分更新部分(最初の%%EOFより後ろ)を削除してみます。
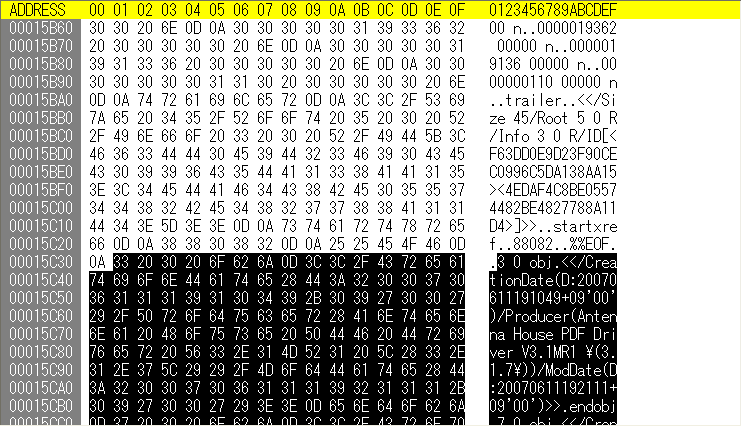
そうして、PDFファイルに保存しますと、最初の署名がなされた状態に完全に元に戻ります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年06月12日
PDFと署名(40) —PDFの増分更新(続き)
PDF Referenceではincremental updateという言葉を使っていましたので、増分更新という言葉を訳語として当てはめてみました。日本語で増分更新と言いますと、いかにも、後ろに追記していくような印象を受けます。
しかし、実は、追記ではなく、文字列を削除したり、書き換え(更新)する場合でも、PDFファイル上は、増分更新の形式となります。その例を示してみます。
(1)文字列をタッチアップツールで変更した例
オリジナルのPDFの文字列を修正して上書き保存、さらに、修正して上書き保存しました。
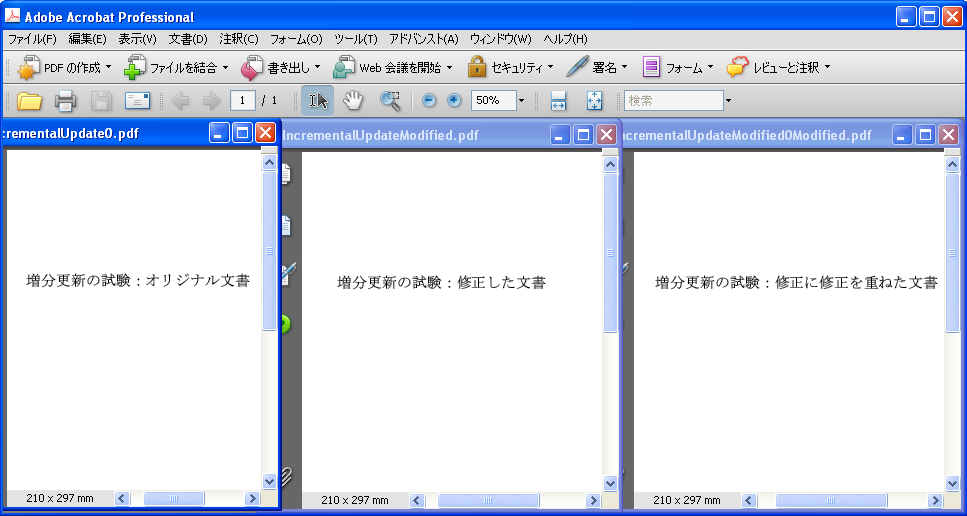
・オリジナルPDFファイルをダウンロード
・修正したPDFファイルをダウンロード
・修正に修正を重ねたPDFファイルをダウンロード
昨日と同じように、この3つのPDFファイルの%%EOFの位置をチェックしますと次のようになります。

第3番目「修正に修正を重ねたPDF」ファイルでは、3つの%%EOFがあります。バイナリのエディタで、PDFファイルを開いて、2つめ&&EOFから後ろを全部削除してみます。
a. 削除する範囲を選択

b.削除後

こうして削除したファイルを保存し、削除前のPDFと削除後のPDFを比較してみます。
このように、増分更新した場合、削除されたはずの情報もそのまま残っていますので、更新された部分のデータをPDFから削除すると、削除されるまえのPDFに戻ります。
(2)ページの追加削除は増分更新になるときとならない時がある
Acrobat 8 の増分更新は、文字列のみではなく、PDFのページ追加、ページ挿入、ページ削除なども、後ろのページについてであれば有効です。但し、PDFの途中のページを削除しますと、上書き保存しても増分更新にはならないようです。
(3)増分更新ではリニアライズは無効になる
なお、増分更新しますと、リニアライズ(Web表示用に最適化)は、仮に設定されていても無効となります。リニアライズでは、ファイルの先頭にランダムアクセスのための情報が必要ですが、増分更新は、ファイルの後ろへの追加になりますので、リニアライズと矛盾するからです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年06月11日
PDFと署名(39) — PDFの増分更新
PDF文書の変更と署名の関係について、調べてみました。これについてお話する前に、PDF文書を作成したあと変更した場合、PDFファイルがどのようになるかを見てみたいと思います。
PDFファイルは、適当なツールを使えば内容を編集(削除、追加、変更)したり、しおりをつけたりといった、様々な変更を施すことができます。そのような変更を行った結果をPDFファイルに保存するときの方法に「増分更新」という保存方法があります。
増分更新とは、変更前のPDFファイルの内容をそのままに維持して、変更前のファイルの最後に変更した内容を追加し、新しいPDFファイルを作る方法です。
Acrobat 8では、PDFを編集して「上書き保存」すると増分更新となります。「名前をつけて保存」すると増分更新ではなく、新しい内容(編集前のPDFの内容が維持されない)になるようです。
次の図は、Wordと「Antenna House PDF Driver」でオリジナルPDFを作成し、Acrobat 8でオリジナルのPDF(左)に、1行追加して上書き保存(中央)し、さらに一行追加して上書き保存(右)したものです。
・オリジナルPDFファイルをダウンロード
・1行追加して、上書き保存したPDFファイルをダウンロード
・さらに1行追加して、上書き保存したPDFファイルをダウンロード
一般にPDFファイルは、%%EOFが区切りになっています。そしてファイルの最後には必ず%%EOFが入ります。そこで、この3つのPDFファイルで%%EOFが入っている位置に注目して図に示しますと次のようになります。
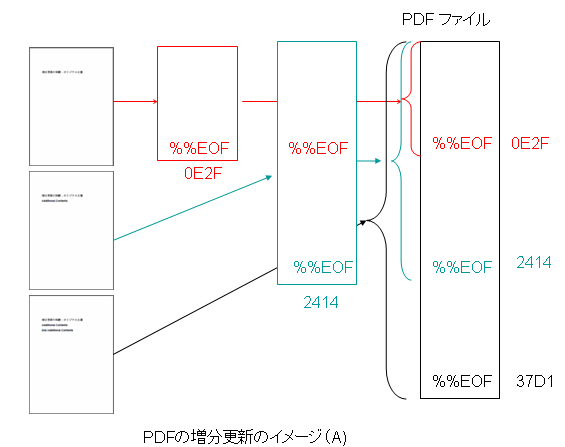
(注)正確には%%EOF位置の後ろの改行コード(0D0A)の0Aの位置を示しています。
増分更新では、編集前の古い世代のPDFがそのまま保持され、%%EOFの後ろに、変更した内容が追加されます。Acrobatのマニュアルには「ファイル」-「復帰」メニューで増分更新したPDFを前の世代に戻せると書いてありますが、なぜか、このPDFではメニューがグレーになってしまっています。
そこで、バイナリエディタで、%%EOFを区切りにして、追加された部分を削除してみました。次のPDFは、「さらに1行追加して、上書き保存したPDFファイル」をバイナリエディタで開いて、0e30以降を削除したものです。
・さらに1行追加して、上書き保存したPDFファイルから0e30以降を削除したPDFファイルをダウンロード
これをご覧いただきますと、増分更新された部分を強制的に削除すると、オリジナルPDFに戻っていることが分かります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年06月07日
PDFと署名(38) — ChallengePKIプロジェクトについて
今日は、日本ネットワークセキィリティ協会(JNSA)の2007年度定時総会が開催されるということで、オブザーバとして見学させてもらいました。
いままで、JNSAについては、まったく知りませんでしたが、このところPKIについて調べていて、このような団体があることを知りました。PDFの電子署名は果たして、セキュリティと言えるのかどうか、疑問がないでもありませんが、公開鍵暗号化方式という根っこのところでは、セキュリティ技術に関係があることは確かです。
と言うわけで、「Challenge PKI」という活動に関心をもちました。
Challenge PKIのプロジェクトでは、PKIの相互運用性に関するテストスイートを作っています。
(1)最新版のテストスイート:
Challenge PKI Test Suite (CPKI-TS) 2.0 2004年7月版
a. GPKIテストスイート:1台のパソコン上に、ブリッジ、府省及び民間の認証局(CA)を擬似的に構築でき、GPKIの環境をシミュレートできる。
b. タイムスタンプ局を相互運用できるシミュレート機能もあります。
当社でも、ちょうど、PDF電子署名のテストを行う必要がありますのでこういうテストスイートがあると大変助かります。
(2) UTF8String問題
電子証明書などにつかう文字コードの符号化方式として、PrintableString、IA5String、T61Stringなどが古くから使われていました。ところが、最近は、UTF8stringが定義され、
RFC3280:Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL)
によりますと、December 31, 2003 から、一部ですが、UTF8Stringを使用しなければならないとなっています。
ChallengePKIプロジェクト・ページの情報では、これに対してUTF8Stringは、まだ実装しているアプリケーションが少なくて急いで、UTF8Stringを使った電子証明書を出す必要はない、としています。
UTF8String問題についての注意喚起が公開されました。(2003/12)
UTF-8問題と移行のシナリオ 島岡 政基
このあたり、実態は、一体どうなってるのでしょうか?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年06月04日
PDFと署名(37) — ハッシュ・アルゴリズムの進化
前回、ハッシュ・アルゴリズムについて、少し取り上げました、ここで、ハッシュ・アルゴリズムの種類と脆弱性について調べてみます。
以前に、公開鍵暗号方式の説明をしたときは、詳しい仕組みやアルゴリズムまで踏み込むのはあまり関係ないのかな、と考えて、ハッシュ・アルゴリズムについては説明を省略してしまいました。
2007年04月05日PDFと署名(4) — 公開鍵暗号方式を署名に使う
ハッシュ・アルゴリズム(ハッシュ関数)については、こちらをご覧ください。
ハッシュ関数
文書をハッシュ・アルゴリズムに入力し、出力されたデータをハッシュ値と言います。または、ダイジェスト値と呼ぶこともありますし、電子政府のWebページでは、フィンガー・プリントと呼んでいます。
電子署名では文書を丸ごと秘密鍵で暗号化するのではなく、文書のハッシュ値を計算し、そのハッシュ値を秘密鍵で暗号化します。そして、(1)オリジナル文書、(2)ハッシュ値を暗号化したデータ、そして(3)公開鍵を相手に渡します。受け取った相手は、暗号化されたデータの暗号を解いて求めた(オリジナル文書の)ハッシュ値と、受け取った文書から改めて計算したハッシュ値を比較して、その両者が一致すれば、受けとった文書が改竄されていないこと、そして、公開鍵とペアになる秘密鍵の所有者が暗号化したことを認めることになります。
4月5日の図を、上の説明に合わせて書き直しますと、次のようになります。

ハッシュ・アルゴリズムの真髄は、(1)ハッシュ値はオリジナルに比べて非常に小さいこと、(2)入力されたデータが少しでも違っていればハッシュ値が異なること、(3)異なるオリジナルデータからは同じハッシュ値にならない(衝突が起きない)ということになります。
但し、この(1)~(3)を全部達成するのは不可能なことは明らかです。仮に元の文書が、1万文字(2バイト/文字)とすると2万バイトになります。2万バイトの情報の改竄パターンは、意味のある情報になるかどうかを別にすると、最大で2の8万乗-1だけあります。ハッシュ値を128バイトとしますと、ハッシュ値で表現できるパターンは2の(128×8)乗です。ですので1ハッシュ値あたり大体2の78乗回の衝突が起きるはずです。しかし、衝突が起きる確率は極めて小さい(2の78乗÷2の8万乗)のです。
このようにハッシュ・アルゴリズムで計算したハッシュ値は衝突が不可避なわけです。しかし、ハッシュ値が同じになる(衝突が起きる)ような改竄方法を短時間で計算できてしまうと問題になります。
これに関連して、最近は、暗号の専門家の会議で、ハッシュ・アルゴリズムの脆弱性がいろいろと報告されています。
MD5を含む各種ハッシュアルゴリズムに欠陥か
暗号アルゴリズムに重大な欠陥発見の報告相次ぐ
SSLやPGPで使われているSHA-1アルゴリズムにセキュリティ欠陥――専門家が指摘
これに対しては、「 CRYPTREC暗号技術監視委員会事務局 」から、次のような公告も出ています。
ハッシュ関数SHA-1及びRIPEMD-160の安全性について
現在のところ、電子署名ではSHA-1を使っていることが多いのでSHA-256 以上に移行するのは難しいのですが、タイムスタンプのような新しい技術では、新しい技術を採用するのが比較的簡単、ということで日本の商用タイムスタンプ局は、ハッシュ・アルゴリスムとしてSHA-512を採用しているようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月31日
PDFと署名(35) — PFUのタイムスタンプ検証プラグインへの疑問
先日、PFUのタイムスタンプ検証プラグインについて、疑問を感じている旨をお話しました。
PDFと署名(33) — PDF署名の検証の互換性にはまる!
その後、なかなか調べる時間がとれず、と言いますか、分からないことを勉強する時間が取れないというのが、本当のところなんですが、調査は遅遅として進んでいませんが、とりあえず、ひとつ気になることがあります。
ダウンロードした検証プログラムに添付のマニュアルを読んでいましたら、このマニュアルには、PFUタイムスタンプはAcrobatのデフォルトハンドラで検証できない、と書いてあります。引用しますと、
「PFU タイムスタンプの使い方」2006年5月版 P.57/60 より
「9.2 他のAcrobat 署名プラグインによる検証について
本製品を使用して取得したタイムスタンプ付き署名を、以下に挙げるようなAcrobat署名プラグインで検証すると、正しい検証結果を得られません。本製品とは異なる検証結果が得られますが、本製品による検証結果が正しい結果です。」
として、Acrobat 8のデフォルトハンドラが、検証できないハンドラのリストに含まれています。
しかし、このようになるのは、PDF Reference違反ではないでしょうか?
前回、PFUのサンプルPDFの署名辞書には、次のエントリがあります。
/SubFilter/adbe.pkcs7.sha1
このSubFilterエントリは、オプションですので、必須ではありません。そして、この説明に、
(Optional) A name that describes the encoding of the signature value and key information in the signature dictionary. An application may use any handler that supports this format to validate the signature.
とあります。これを見ますと、アプリケーションは、SubFilterで説明したフォーマットサポートする任意のハンドラを、署名を検証するのに使って良いと書いてあります。
ですので、PFUのサンプルPDFは、adbe.pkcs7.sha1をサポートするハンドラで署名を検証することを許していることになります。もし、PFUのハンドラで作った署名をAcrobatのデフォルトハンドラで検証できないのであれば、/SubFilter/adbe.pkcs7.sha1というエントリを作成してはならないのではないでしょうか?
これは、Acrobat SDKの方の問題なのかもしれません。いずれにしても、電子署名の検証を許されるハンドラが、正反対の検証結果を出してしまうのはちょっと解せません。正反対の結果をだすようなハンドラには検証を許さないようにさせないといけないのではないでしょうか。そのためには、SubFilterエントリを作らないようにすれば良いと思います。(まだ、確認したわけではないです。)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月29日
Window Vistaで文字化けするPDF
今日、お客さんからAntenna House PDF Viewerで文字化けするPDFがあるので、調べて欲しい、という要請がありました。早速、調べてみましたところ、このPDFは、確かにAdobe ReaderでWindowsXPでは正しく表示されます。しかし、Window Vistaで表示しますと文字化けしてしまいます。次の図をご覧ください。
■問題のPDFをWindows XP上でAdobe Readerで表示したところ。
■問題のPDFをWindows Vista上でAdobe Readerで表示したところ。
このように同じPDFの表示が、Windows XPとWindows Vistaでまったく異なってしまいます。
なぜ、こんなことが起きるのでしょうか?
このPDFの特徴は、
(1) フォントが埋め込まれていない。
(2) 文字コードも使われていなくて、文字コードの代わりにCID(グリフID)が使われています。
(3) CIDを使った場合、CIDを文字コードに変換するために、 ToUnicode CMAPという変換テーブルを用意しないといけないのですが、そのテーブルが用意されていません。
ですので、例えば、このPDFをWindowsXPのAdobe Readerで表示して、テキストを選択、コピーして、他のアプリケーションにペーストしますと、文字が化けてしまいます。
では、Adobe Readerで正しく表示できるのはなぜかと言いますと、このPDFのフォントはMS明朝・MSゴシックですが、フォントの Encoding が Identity-H で任意の2バイトコードになっています。そこで、推測ですが、Adobe Readerは、PDFの中のグリフIDを受け取って、指定されたフォントのグリフIDでWindowsの画面に表示しているものと思われます。
注意すべきことは、グリフIDは、フォント固有になっているのでフォント間で互換性がありません。このケースでは、たまたまPDFを作った環境とPDFを表示する環境のフォントがまったく同じなので一見正しく表示できているのでしょう。要するに偶然うまく表示できていると思います。
Windows XPのMS明朝・MSゴシックは、V2.31です。
ところが、Windows VistaではMS明朝・MSゴシックはV5で、恐らくグリフIDが変わっているため、Vistaで表示すると文字が化けてしまうものと思います。
この、PDFを正しく表示できるようにするには、
(1)フォントを埋め込むか
(2)CIDではなく、文字コードを使うか
(3)ToUnicodeCMAPを用意する
のどれかの対処が必要です。
ちなみに、このPDFは、SVF for JAVA Printで作られたものです。

そういえば、SVF for JAVA Printって、国税庁のWebでも使っていたな、と思って、確定申告のPDFを作ってみました。しかし、こちらはWindowsVistaでも文字化けしないようです。
このPDFのProducer情報
この違いは何でしょうか?
■文字化けする方のPDFは、フォントのエンコーディングがIdentity-Hになっています。
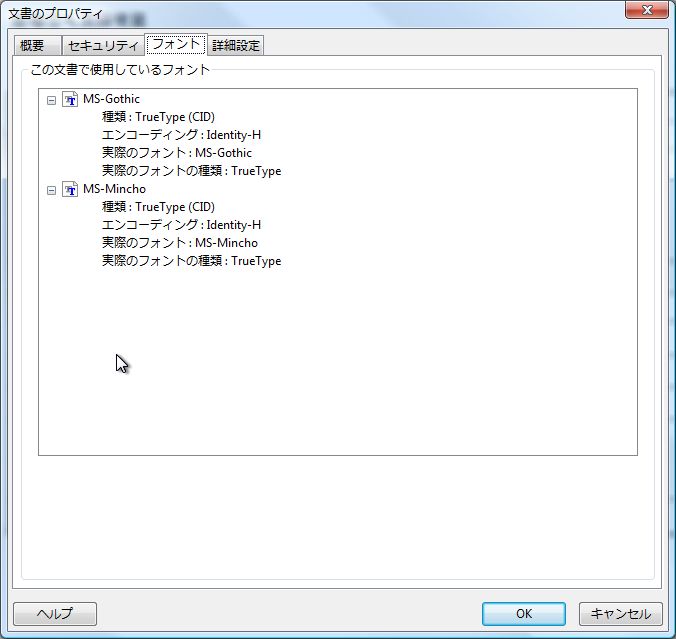
■文字化けしない方のPDFは、フォントのエンコーディングが違います。
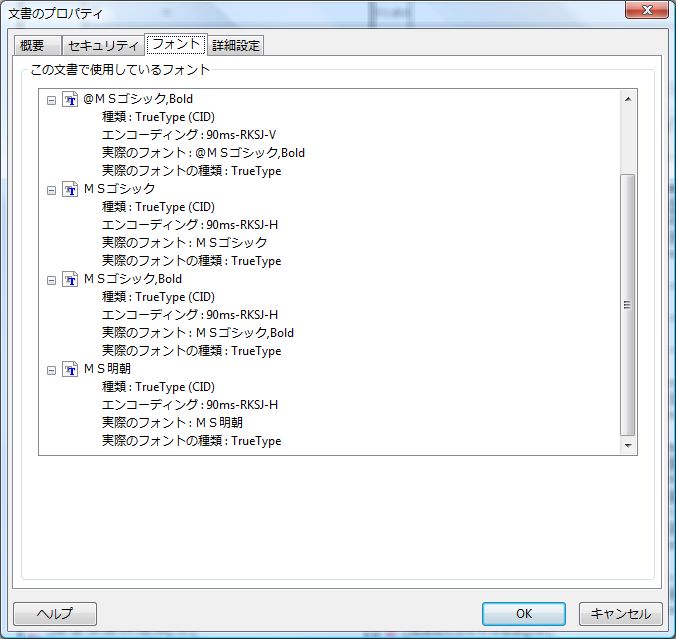
なので、SVF for JAVA Printの設定によって変わるようです。それともバージョンによって違うのでしょうか?これは、ウイングアークに聞いてみないと分かりません。でも、Vistaが普及したらSVFで作ったPDFは、文字化け問題が頻発する懸念があります。会社によっては、10年後に、昔作った帳票PDFを見ようとしたら全部文字化けで大騒ぎ、なんてことになりかねません。
あなたの会社は、大丈夫ですか?
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年05月28日
PDFと署名(34) — PDFへのタイムスタンプ付与
昨日は、少し回り道をしてしまいましたが、次は、PDFとタイムスタンプについて調べてみます。
今までに、PDFに電子証明書を使って署名することで、PDFの内容が作成後に変更または改竄された場合にはこれを検知することができるようになること、さらには、電子証明書が何らかの形で認証されているものであるならば作者本人が作成したものであることも、つまり否認防止などもできることになります。
さらに、タイムスタンプをつけることで、PDFが「いつ作成されたか」を特定できることになります。実際のビジネスでは、いつ、ということが非常に重要になるケースが多いとでしょうから、電子書類にタイムスタンプをつけるというサービスは、PDFかどうかに関わらず重要なビジネスと思われます。
タイムスタンプ・プロトコルに関する技術調査によりますと、欧米では1990年代の中ごろからタイムスタンプサービスが立ち上がっているようです。
2000年前後にタイムスタンプの標準化が図られました。2001年に電子署名に基づくタイムスタンプの標準であるRFC3161ができています。
RFC3161: Internet X.509 Public Key Infrastructure Time-Stamp Protocol (TSP)
電子文書にタイムスタンプをつける技術はさまざまで、特許も多数ありますが、その中で、電子署名に基づくタイムスタンプ技術は、米国では、裁判で公知の技術として特許には抵触しないという認識になっているようです。
RFC3161のタイムスタンプ方式を簡単にまとめますと次のようになります。
(1)タイムスタンプを付けたい文書のハッシュ値を計算する。
(2)ハッシュ値を、信頼できるTSA(タイムスタンプ・オーソリティ)に送信する。
(3)TSAは、ハッシュ値に、TSAの秘密鍵で電子署名をして、電子署名した署名データを、要求元に送り返す。
以上で、文書のタイムスタンプデータが出来上がります。これを文書と関係つけて保存すれば、それで、タイプスタンプ付き文書となります。
ここで分かりますように、タイムススタンプを施すことで、時間のみでなく、文書の原本性(改竄されたり、変更されてない)までもが分かるようになります。
「PDF 1.6から、署名辞書の署名データ(Contentsキーの値)に含めるPKCS#7のオブジェクトに、タイムスタンプを非署名の属性として含めることができるようになりました。PDFにおけるタイムスタンプは、RFC3161準拠であり、かつ、RFC3161の付録Aに記述されているように計算され、埋め込まれなければならない」、とされています。
(PDF Reference 1.7 P.739より)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月27日
PDFと署名(33) — PDF署名の検証の互換性にはまる!
今日は、PDFとタイムスタンプの関係を調べようと思って、PFUのWebページを見てました。
このページはなかなか分かりやすく、タイムスタンプのことを説明してあります。それで、少し試してみようと思い、サンプルPDFを見つけました。
サンプルPDFは、次のページにあります。
PFUタイムスタンプ for Adobe® Acrobat®(検証用)
さっそくダウンロードして、Adobe Reader8で表示しました。ところがこの署名を検証すると次のようになってしまいます。
Acrobat Reader8が英語版のため、英語のメニューなんですが、「この文書は無効(INVALID)である。署名してから、文書が変更されたか、それとも壊れている。」となってしまいます。
ちなみに、これは、Acrobat Reader8のデフォルトハンドラで検証している状態です。
次に、PFU のWebページから、検証用のプラグインをダウンロードしてインストールしてみました。
そうして、署名を検証しますと、今度は次のように、「署名が有効である」となります。
同じ署名が、検証につかうハンドラによって、「有効」と「無効」というまったく異なる結果になってしまうのですが、こういうことがあって良いのでしょうか?
なぜかなあと思って、調べ始めたら、はまってしまいました。
結論から言いますと、このPDFでは署名辞書が次のようになっています。
/SubFilter/adbe.pkcs7.sha1
/Filter/PFUP.TimeStamp
/PFUP.DigestMethod/SHA512
/Prop_Build<</Filter<</Name/PFUP.TimeStamp/
などとなっていますので、PDFのタイムスタンプ用のハンドラ(Acrobatのアドイン)で署名をしているようです。
ハッシュのダイジェスト計算にSHA512という新しいアルゴリスムを使っています。
しかし、adbe.pkcs7.sha1は、SHA1をサポートするハンドラで検証することを意味すると思います。このためにAcrobat Readerのデフォルトハンドラで検証すると、ハッシュ値の計算結果がPFUのハンドラの計算結果(署名辞書に埋め込まれている値)と違ってしまい、署名の検証結果が「無効」になるのでしょう。
原因はともかく、このような場合、Adobe Readerのデフォルトハンドラで、「無効」という相反する結果がでるのはまずいでしょう。デフォルトハンドラでは、最悪でも「不明」あるいは「検証できない」というメッセージを出すようにするべきだと思います。
このPDFは、PFUの署名・タイムスタンプ設定用プラグインで作成されているわけですが、作成時のSubFilterキーの値の設定を変更するほうが良いように思いますが、如何でしょうか?
※追記:このPFUのサンプルのPDF署名辞書の署名データ(PKCS#7形式)を調べてみたのですが、どうも、電子署名部分はSHA1になっているように見えます。つまり、タイムスタンプはSHA512で、電子署名はSHA1。しかし、これ以上はいま調べている能力も時間もありません。また、そのうち。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月24日
PDFと署名(32) — PDF署名の検証について、再び
PDF署名の検証については、既に何回かお話しました。しかし、どうも、断片的でしたので、もう一度、Adobeの「Digital Signature User Guide」に沿って、簡単にまとめてみたいと思います。以下は、Adobe Readerによる署名の検証の概要です。
○署名が有効(妥当)であるとは?
・署名に使った証明書が有効で信頼できること。すなわち、署名者の証明書から信頼できる認証元までのチェーンを作ることができて、また、署名者の証明書が失効していないこと。
・文書が署名されてから変更されていないか、もしくは許可された変更のみがなされていること。
○署名の有効性検証の結果
・有効、不明、有効でないの3つの状態になる。
・有効とは、署名が有効で信頼できる証明書に関連づけられており、かつ、文書は著者が禁止した方法では変更されていない状態
・不明とは、署名が有効性を検証できない証明書に関連づけられているか、文書に不明な変更があるか、それとも未検証の状態
・有効でないとは、署名が有効でない証明書に関連づけられているか、それとも文書は著者に禁止された変更がなされている
※PDFの署名の有効性の検証は、証明書の状態と文書の状態を完全に分離していません。本来、証明書の状態と文書の状態は完全に独立なので、検証結果を明確に分離しても良いように思うのですが。このため、Adobe ReaderのPDF署名の検証状態の表示はとても分かりにくいように感じます。
PDF署名では、署名につかったハンドラが様々になります。署名につかったハンドラと署名を検証するハンドラは同じものであることが望ましいのですが、これは代替ハンドラを使うこともできます。このことは、既にお話しました。
☞ 2007年05月10日 PDFと署名(23) — 署名ハンドラ
証明書が失効していないかどうかの検証は、証明書失効リスト(CRL)と照合するか、それとも、オンライン証明書状態プロトコル(OCSP)でチェックするかのいづれかの方法になります。そして、PDFには、通常署名とMDP署名という2種類の署名がありますが、Adobe Readerは通常署名では必ずしも証明書失効チェックは行われません。MDP署名では必ず証明書失効チェックをするようです。
☞ 2007年05月16日 PDFと署名(28) — PDFの2種類の署名
Windows証明書ストアを信頼するかどうか?
証明書の有効性を検証するには、証明書のチェインを作ることになりますが、証明書のチェインはルート証明書に行き着きます。「Windows証明書ストアには、メーカからの出荷時に、様々なルート証明書が入っていますし、なんらかの拍子に、ルート証明書がWindows証明書ストアに入ってしまうことがあります。そこで、個人ユーザは、Windows証明書ストアを信頼しない方が良い。企業ユーザは、管理者が遠隔操作でWindows証明書ストアを管理できるので、信頼しても良い。」(「Digital Signature User Guide」P.88 6.2.3 Using Root Certificates in the Windows Certificate Storeより)。」
証明書を直接入手した場合、その証明書を信頼する証明書のリストに追加できます。
こうしてみますと、Adobe Readerによる署名の検証結果については、それを左右する様々な要因があり、署名検証の運用管理は注意深く要因を管理しなければならないでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月21日
PDFと署名(31) — PDFの署名値について
先日、PDFに署名するときルート証明書の情報は不要ではないかと言いましたが、もしかすると誤りかもしれません。これについて、PDF Reference 1.7の関連する箇所を調べてみました。
2007年05月19日 PDFと署名(30) — PDFの署名の検証
PDFの署名辞書について、まず、表8.98を見ますと、次のようになっています。
Contentsキー
(必須)署名値。ByteRangeキーが存在するとき、バイトレンジ・ダイジェストの値を表す16進の文字列。ByteRangeキーが存在しないとき、Contentsエントリを除く、署名辞書のオブジェクト・ダイジェストの値。公開鍵署名では、Contentsは一般的にDER符号化のPKCS#1バイナリ・データオブジェクト、または、DER符号化のPKCS#7バイナリ・データ・オブジェクトである。
Certキー
(SubFilterキーがadobe.x509.rsa_sha1のとき必須。それ以外では使わない)(中略)
SubFilterがadbe.pkcs7.detachedまたはadbe.pkcs7.sha1の時、このエントリは使わない。そして証明書のチェーンをContentsキーのPKCS#7封筒に入れなければならない。(2007/5/22 注)
ということは、証明書のチェーンを作成して、署名値の中に入れなければならないようです。
さらに、8.7.2署名の互換性という項を見ますと、PKCS#7署名については、最低限、署名者のX.509署名用証明書を含まねばならない、となっています。ここと、下の部分の記述からしますと、ルート証明書は必須ではないようにも見えます。果たしてルート証明書をPDFの署名辞書に埋め込まねばならないのかどうか、説明があまり明確ではないように思います。どうなんでしょうね?
ところで、PKCS#7オブジェクトは、オプションとして次の属性をもつことができます。
・RFC3161に準拠するタイムスタンプ (PDF1.6~)
・署名された属性として、証明書検証情報 (PDF1.6~)
・署名者の信頼チェインから、一つ以上の発行者証明書 (PDF1.6~)
・署名者の証明書に関連するRFC3281属性証明書、一つ以上 (PDF1.7~)
このあたりの説明は、PDF Reference1.5とPDF Reference1.6の間でかなり変更になりました。また、PDF Reference 1.7でも少し変更になっており、PDFの電子署名機能は、最近になって変更され固まってきたと言えそうです。
注)2007年5月22日追記
この部分ですが、「もしSubFilterがadbe.pkcs7.detachedかadbe.pkcs7.sha1の場合に証明書チェーンを埋め込む場合は、PKCS#7のデータ中に埋め込む必要がある。」
と解釈すべきではないか、というコメントがありました。確かにそういう風に解釈できるようにも思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月18日
PDFと署名(29) — MDP署名のダイジェストの計算
先日、PDFの署名には、(1)普通の署名と(2)MDP署名(有効な証明用署名)の2種類があることを説明しました。
2007年05月16日 PDFと署名(28) — PDFの2種類の署名
普通の電子署名では、署名を付けたい文書のハッシュ値を計算します。そして、そのハッシュ値を秘密鍵で暗号化することになります。PDFの場合、(1)普通の署名では、PDF文書の中の指定した範囲(バイトレンジで指定。通常は、署名辞書の署名の値以外の部分)のハッシュ値を計算します。
MDP署名では、ハッシュ値の計算の過程で、「オブジェクト・ダイジェスト」という特別な方法が使われることがあります。
簡単に言いますと、コンピュータのメモリ中のPDFオブジェクトのツリーの中で指定したオブジェクトを辿ってダイジェストを計算する対象となるデータストリームを生成する方式です。オブジェクト・ダイジェストの方法については、PDF Reference1.7では付録I Computation of Object Digestsに説明されています。
この計算方法は、単純な文書のダイジェスト計算と比べてかなり面倒なようです。電子署名では、ソフトウエアAで作成したPDFの電子署名をソフトウエアBで検証する場合もありますので、互換性が重要なのですが、あまり複雑だと完全な互換性が実現できるのだろうかと、少し心配になったりします。
そのためかどうか分かりませんが、MDP署名の検証方法は、PDF 1.5とPDF 1.6以降でかなり変わっています。
MDP署名の検証(PDF Reference 1.7 pp.732-733)
「PDF 1.5は、署名の時点でのオブジェクト・ダイジェストの計算値が、署名参照辞書(表8-103)のDigestValueエントリに保存されることを要求する。従って、アプリケーションはこのエントリを、検証の時点で計算されたオブジェクト・ダイジェストと比較することができる。もし、値が違っているならば、署名は妥当でないものである。
PDF 1.6では、DigestValueエントリは要求されない。バイトレンジ・ダイジェストを検証したならば、署名辞書(表8-102)のバイトレンジ・エントリで指定される文書の部分が署名の時点での文書の状態に対応するものと知られる。従って、アプリケーションは署名されたものと現行の文書バージョンを比較することができ、それによって変換パラメータで許可されない任意のオブジェクトに対して修正があったかどうかを知ることができる。付録Hの実装メモを参照。」
これを読む限り、PDF 1.6~では、MDP署名において、著者が変更を許可していない部分についてはオブジェクト・ダイジェストを計算するのは止めてしまったように見えます。ともかく、PDF 1.5と1.6~では、MDP署名の検証方法が根本的に変わっていることになります。恐らくは実装上の都合と思いますが、PDFの仕様がこのように変わっているのは注意が必要です。
※米国の専門家のPDFの仕様についての意見を読んでいても、PDFの仕様はPDF Referenceではなく、Adobe製品(つまり実装が仕様)であるということが問題である、と書かれていました。ISO標準になれば、Adobe 製品の実装が標準である、という態度は許されなくなります。早くISO標準になって変わって欲しいところです。
なお、MDP署名で著者が、フォーム・フィールドや注釈などに変更を許す時は、その部分は、フィールドMDP変換という方法で署名参照辞書が作られて、検証されます。フィールドMDPは、フォーム・フィールドのリストに対してオブジェクト・ダイジェストを計算する方法です。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月16日
PDFと署名(28) — PDFの2種類の署名
2007年05月14日 PDFと署名(26) — Adobe Readerによる署名されたPDFの検証で、署名されたPDFの検証で「有効な証明用署名を含んでいる」という状態と、「署名が有効である」という2つの有効な状態があることをお話しました。
この二つの状態は、Acrobat8では次の二つのメニューに対応しています。
○署名が有効である:アドバンスト->電子署名->この文書に署名
○有効な証明用署名:アドバンスト->電子署名->可視署名を使用して署名、または、可視署名を使用しないで署名
この二つがどう違うかをもう少し見てみますと、
(1)「有効な証明用署名」の方は、文書の作者または1人しか署名できません。そして、これは、PDF Reference1.7では、MDP(修正検出・防止(modification detection and preventionの頭文字))署名として説明されているものに相当します。MDP署名は、PDF文書に最大でも1個しか存在できません。
(2)一方の、「文書が有効である」の署名の方は、document:文書(ordinary:普通)署名とされています。これは複数存在することができます。
さらに、MDP署名をすると、署名者が文書を修正することについての許可(Permission)を与えることができます。この許可は、「変更を許可しない」、「フォームフィールドの入力と署名フィールドに署名を許可」、「注釈の作成、フォームフィールドの入力と署名フィールドに署名を許可」の3段階となり、PDFの中では、電子署名用の許可辞書(8.7.3Permissions)に記録されます。
パスワードによるセキュリティハンドラでも同じようなユーザへの許可を与えることができます。
※パスワードによる許可制御についてはこちらをご覧ください。
2006年11月13日 PDFのセキュリティ機能(3)—PDFの利用許可制御
電子署名の許可辞書の設定はパスワード・セキュリティによるユーザの許可設定とは別物です。パスワードによる許可辞書と違って文書を暗号化するわけではありません。署名を検証する側にとってもMDP署名をサポートするには、利用許可設定の内容に沿った修正かどうかを検出しなければならないことになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月15日
PDFと署名(27) — SODEC で、PDF電子署名モジュールを参考出品
いよいよ、明日から年に1度のSODEC開催!アンテナハウスも[ブース番号:東11-8(プロジェクト管理ゾーン内)]にてシステム製品を中心に主要製品を出展します。
ブログでずっとPDFと電子署名について書いてきましたので、もう公然の秘密ですが、弊社では、ずっとPDFの電子署名ツールの開発を行ってまいりました。その第一弾として、サーバサイドのシステムに組み込んで使うための「PDF電子署名モジュール」を近い将来リリースする予定です。
そこで、SODECでは、じゃーーん!開発中のPDF電子署名モジュールをXSL Formatterと連携するデモをご覧いただきたいと思います。
○ポスター
(画像をクリックしますとPDFが表示されます)。
PDF電子署名モジュールは、予め設定した電子署名関連の情報をPDFに設定するものです。
電子署名関連の情報とは、
・PDFに電子署名を付与
・PDFの署名辞書に書き込む情報(署名理由、署名場所、署名者連絡先)
・タイムスタンプ(タイムスタンプ・サーバより取得)
・電子署名の外観(印影など)
などです。
Windowsの証明書ストアに登録されている証明書を使うことができます。PDF電子署名モジュールは、Windowsの証明書ストアと連携して、秘密鍵で署名したデータと電子証明書をPDFに埋め込むことになります。タイムスタンプは予め指定したタイムスタンプ・サーバから取得します。
XSL Formatterとの連携では、XSL Formatterで電子署名の外観を付加したい領域を指定しておくことで、指定位置に電子署名の印影をつけることができます。
ダイナミックに変化するコンテンツをFormatterで組版した結果によってできあがるページ数が変化する場合、印影をつける位置(ページ番号とそのページ内の座標)が変わる可能性があります。そのように印影をつける位置が、コンテンツ依存で変更になっても対応できます。このあたりは、単純な固定フォーマットの帳票ソフトでは、実現が難しいところと思いますが、XSL Formatterのようなドキュメント組版ソフトでは簡単に実現できます。
また、電子署名とリニアライズ、電子署名とパスワードによるセキュリティ設定などを組み合わせることもできます。
今後、お客様のご意見を伺って、製品の詳細な仕様を詰めて行きたいと考えていますので、関心をお持ちの方は、ぜひ、SODECでデモをご覧頂き、忌憚のないご意見をいただければと思います。なにとぞ、よろしくお願いします。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月13日
PDFと署名(25) — 署名の外観
PDFでは電子署名に印影やサインなどの外観をつけることができます。
例えば、次の図のように署名者の印影を付与するために外観を使います。

一般に、PDFのフィールドには、外観をwidget注釈で設定できるのですが、署名はフィールドの一種として扱われますので、署名の外観をwidget注釈で設定できるわけです。この概観は、本来の目的である電子署名されたPDFを検証するために必要なものではなく、外観のない署名[不可視署名]も許されます。
書名付きのPDFをAdobe Reader8で表示しますと、次のようにアイコンとツールチップが表示されます。
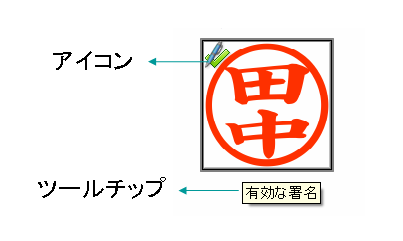
このアイコンとツールチップは、Adobe Reader(プログラム)で表示しているもので、PDFの中に埋め込まれているものではありません。
この署名の外観のために、widget注釈の外観辞書(AP辞書)をどのように設定するかは、原則として、注釈のAP辞書の仕様に基づいていれば問題はないはずです。しかし、各署名ハンドラが勝手にすると、ユーザが混乱を招くということで、「Digital Signature Appearances (Acrobat 6)」にガイドラインがあります。
参考資料:Digital Signature Appearances (Acrobat 6)
これを読みますと、Adobe自体が、Acrobat 6でかなり大幅に署名の外観の取り扱いを変更したことがわかります。すなわち、Acrobat 4/5では、署名の外観を、署名の検証状態と対応して、未検証だと「?」を表示、検証結果が不可では「×」を表示するように変化させるため、AP辞書にそのためのデータを埋め込んでいました。
ところが、Acrobat 6からは、現在のように、アイコンとツールチップを表示する方法に変わっています。
現在のAcrobat は、Acrobat 4/5で作成した電子署名の外観を同じように取り扱える下方互換機能をもっていますので、Acrobat 4/5の古い電子署名とAcrobat 6以降の新しい電子署名で外観の表示が変わるはずです。
このように、Acrobatでは、署名の外観の取り扱いも、Acrobat 4/5と6~で変わっている、ということに注意しなければなりません。なお、ガイドラインではサードパーティはAcrobat 6~と同じように外観を作ることが推奨されています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月12日
PDFと署名(24) — PDFの署名が複雑な事情
PDFの署名は、次の二つの点で非常に込み入っています。
○その第一はPDF Referenceで決める署名の付け方が込み入っていることです。
署名は対話フォーム(AcroForm)の一種である「署名フィールド」として定義されており、まず署名フィールドを作って、署名すると、そこに署名辞書ができます。
またPDF署名には外観をつけることができ、署名の外観は注釈の一種として定義されます。この署名に外観をつけるというのは、PDF特有の機能になります。
そこで、署名辞書のない(未署名の)署名フィールド、署名済みの署名フィールド、外観のある署名、外観のない署名などのパターンができてしまいます。このようにPDF署名は、署名する・しないという単純な状態ではなく、複雑な状態をもつため、ユーザが理解するのがとても難しくなってしまいます。
○その第二は、PDFの署名は、PDF Reference 1.3(Acrobat4)で初めて導入された比較的新しい機能ですが、その後、PDF Reference 1.5(Acrobat6)で大幅に変更になっています。つまりPDFのバージョンによって大幅に変更になっている点がある、ということです。
これを示すために、署名に関連する各種の辞書のキーがPDF1.3からPDF1.5でどのように変わったかを表にしてみました。次の表を見ますと、PDF 1.5で署名関連の辞書が大幅に変更になっていることが一目瞭然です。また、PDF1.6、PDF1.7で細かい仕様拡張が行われています。
○フィールド辞書のキー
| Field Dictionary | |||||
|---|---|---|---|---|---|
| PDF 1.3 | PDF 1.4 | PDF 1.5 | PDF 1.6 | PDF 1.7 | |
| FT | FT | FT | FT | FT | |
| FT | Parent | Parent | Parent | Parent | |
| Parent | Kids | Kids | Kids | Kids | |
| Kids | T | T | T | T | |
| T | TU | TU | TU | TU | |
| TU | TM | TM | TM | TM | |
| TM | Ff | Ff | Ff | Ff | |
| V | V | V | V | V | |
| DV | DV | DV | DV | DV | |
| AA | AA | AA | AA | AA | |
| /FT /Sig固有 | Lock | Lock | Lock | ||
| SV | SV | SV | |||
○Lock辞書
| Lock | ||||
|---|---|---|---|---|
| PDF 1.3 | PDF 1.4 | PDF 1.5 | PDF 1.6 | PDF 1.7 |
| Type | Type | Type | ||
| Action | Action | Action | ||
| Fields | Fields | Fields | ||
○SV辞書
| SV | ||||
|---|---|---|---|---|
| PDF 1.3 | PDF 1.4 | PDF 1.5 | PDF 1.6 | PDF 1.7 |
| Type | Type | Type | ||
| Filter | Filter | Filter | ||
| SubFilter | SubFilter | SubFilter | ||
| DigestMethod | ||||
| V | V | V | ||
| Cert | Cert | Cert | ||
| Reasons | Reasons | Reasons | ||
| MDP | MDP | |||
| TimeStamp | TimeStamp | |||
| LegalAttestation | LegalAttestation | |||
| AddRevinfo | ||||
| Ff | Ff | Ff | ||
○SVのCert辞書
| Cert | ||||
|---|---|---|---|---|
| PDF 1.3 | PDF 1.4 | PDF 1.5 | PDF 1.6 | PDF 1.7 |
| Type | Type | Type | ||
| Subject | Subject | Subject | ||
| SubjectDN | ||||
| KeyUsage | ||||
| Issuer | Issuer | Issuer | ||
| OID | OID | OID | ||
| URL | URL | URL | ||
| URLType | ||||
| Ff | Ff | Ff | ||
○署名辞書のキー
| 署名辞書 | ||||
|---|---|---|---|---|
| PDF 1.3 | PDF 1.4 | PDF 1.5 | PDF 1.6 | PDF 1.7 |
| Type | Type | Type | Type | Type |
| Filter | Filter | Filter | Filter | Filter |
| SubFilter | SubFilter | SubFilter | SubFilter | SubFilter |
| Contents | Contents | Contents | Contents | Contents |
| Cert | Cert | Cert | ||
| ByteRange | ByteRange | ByteRange | ByteRange | ByteRange |
| Reference | Reference | Reference | ||
| Changes | Changes | Changes | ||
| Name | Name | Name | Name | Name |
| M | M | M | M | M |
| Location | Location | Location | Location | Location |
| Reason | Reason | Reason | Reason | Reason |
| ContactInfo | ContactInfo | ContactInfo | ||
| R | R | R | ||
| V | V | V : 署名辞書形式のバージョン | ||
| Prop_Build | Prop_Build | Prop_Build | ||
| Prop_AuthTime | Prop_AuthTime | Prop_AuthTime | ||
| PropAuthType | PropAuthType | PropAuthType | ||
○reference 辞書
| reference | ||||
|---|---|---|---|---|
| PDF 1.3 | PDF 1.4 | PDF 1.5 | PDF 1.6 | PDF 1.7 |
| Type | Type | Type | ||
| TransformMethod | TransformMethod | TransformMethod : DocMDP, UR, FiledMDP, Identity | ||
| TransformParams | TransformParams | TransformParams | ||
| Data | Data | Data | ||
| DigestMethod | DigestMethod | DigestMethod | ||
| DigestValue | DigestValue | DigestValue | ||
| DigestLocation | DigestLocation | DigestLocation | ||
○DocMDP TransformParam 辞書
| DocMDP TransformParam | ||||
|---|---|---|---|---|
| PDF 1.3 | PDF 1.4 | PDF 1.5 | PDF 1.6 | PDF 1.7 |
| Type | Type | Type | ||
| P | P | P | ||
| V | V | V | ||
○UR TransformParam 辞書
| UR TransformParam | ||||
|---|---|---|---|---|
| PDF 1.3 | PDF 1.4 | PDF 1.5 | PDF 1.6 | PDF 1.7 |
| Type | Type | Type | ||
| Document | Document | Document | ||
| Msg | Msg | Msg | ||
| V | V | V | ||
| Annots | Annots | Annots | ||
| Form | Form | Form | ||
| FormEx | FormEx | |||
| Signature | Signature | Signature | ||
| EF | EF | |||
| P | P | |||
○FieldMDP 辞書
| FieldMDP | ||||
|---|---|---|---|---|
| PDF 1.3 | PDF 1.4 | PDF 1.5 | PDF 1.6 | PDF 1.7 |
| Type | Type | Type | ||
| Action | Action | Action | ||
| Fields | Fields | Fields | ||
| V | V | V | ||
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月10日
PDFと署名(23) — 署名ハンドラ
PDF署名では、様々な署名処理プログラムを使うことができます。これを署名ハンドラと言います。署名に使ったハンドラの名前と、それを検証するための望ましい署名ハンドラの名前が、作成されたPDFの中の署名辞書に保存されています。
独自の署名ハンドラを使って署名をつけた場合、署名のついたPDFをAdobe Readerで開いて、その署名を検証しようとしたとき、署名に使ったハンドラがパソコンにないと、次の図のようなメッセージが出ることがあります。
【例】PDF内の辞書に記録された署名ハンドラが、検証するPCにないとき
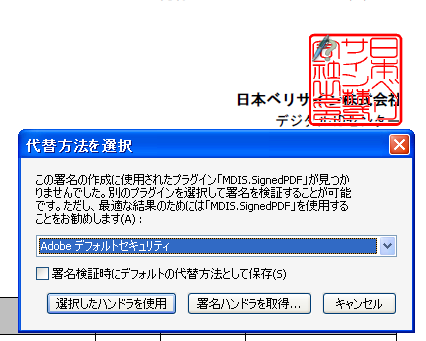
署名に使ったハンドラがないとまったく検証できない、ということでは不便ですので、互換な署名ハンドラでも検証できるようになっています。
署名辞書では、検証のために使うのが望ましい署名ハンドラがFilterに登録されています。さらに、SubFilterには、どのような署名のアルゴリズムを使ったかを表すキーワードを記録することになっています。そこで、SubFilterの内容をチェックして、そのキーワードに示した形式をサポートする任意の互換ハンドラで検証することができます。
SubFilterの定義済みのキーワードは、adbe.pkcs7.detached, adbe.pkcs7.sha1, adbe.x509.rsa_sha1の3つです。
先ほどのPDFを見ますと、署名辞書(一部)には、
/Type /Sig
/Filter /MDIS.SignedPDF
/SubFilter /adbe.pkcs7.detached
となっていて、MDIS.SignedPDFという三菱電機インフォーメーションシステムズ社の署名ハンドラで署名を検証するのが良いということを示しています。
SubFilterは、adbe.pkcs7.detachedとなっています。adbe.pkcs7.detachedは、次のアルゴリズムをサポートしています。
○メッセージのダイジェスト
SHA1 (PDF 1.3)
SHA256 (PDF 1.6)
SHA384 (PDF 1.7)
SHA512 (PDF 1.7)
RIPEMD160 (PDF 1.7)
○RSA公開鍵暗号化アルゴリズム
1024-bit まで(PDF 1.3)
2048-bit まで (PDF 1.5)
4096-bit まで(PDF 1.5)
○DSA アルゴリズムのサポート
4096-bitsまで (PDF 1.6)
そこで、adbe.pkcs7.detachedの形式をサポートする署名ハンドラを使っても良いということです。上の例では、AdobeReaderについている標準の署名ハンドラ(多分、PPKLiteプラグインの中にある)を、MDIS.SignedPDFの代わりに使って検証ができるようです。(但し、完全ではないと思います)。
このあたりの署名ハンドラの互換性は、もっと明瞭・厳密な仕様が必要なように思います。早くISO標準になって欲しいですね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月09日
PDFと署名(22) — PDFと公開鍵暗号
PDFと公開鍵暗号の関係について、PDF Referenceから整理してみます。
まず、PDFでは、公開鍵暗号を(1)暗号化と(2)署名の二通りの方法で利用できます。
(1)暗号化は、PDFを渡したい相手の公開鍵を使ってPDFを暗号化する機能です。PDFのセキュリティで一般的なのはパスワードによる暗号化です。これは相手によらずPDFを一定のパスワードで暗号化します。それに対して公開鍵による暗号化では、PDFを渡したい相手の公開鍵を使って暗号化しますので、相手毎に異なる条件でセキュリィを設定することができます。
この公開鍵暗号化によるPDFのセキュリティについては、既に、2006年11月19日 PDFのセキュリティ機能(7)—公開鍵セキュリティ・ハンドラで概略を紹介しています。
(2)署名は、PDF文書への電子署名です。一般文書への電子署名と同じように、PDF署名では、署名した人が誰かを確認したり、あるいは、文書の署名者に否認防止(知らないよと言わせない)、改竄の有無の検出を行うことができます。さらに、PDF署名は様々な高度な署名の利用ができることになっています。
PDF Referenceで規定しているPDF電子署名の仕様概要は以下の通りです。
注意しなければならないのは、仕様として規定されていても、それを正しく実装したアプリケーションがないと利用できないことです。さらに、正しく実装するだけではなく、それが簡単に使いこなせないと活用できません。また、身近に使いこなすには、安価なツールも必要になります。そういうツールがないと絵に描いた餅になってしまいます。とりあえずは、絵に描いた餅だと思って読んでみてください。
1.PDFでは、署名は署名ハンドラが取り扱います。この署名ハンドラは、プラグインとして実現でき、独自の様々な機能も実現できます。つまり、自分でハンドラを書いて特殊なこともできるというわけです。
2.署名の情報は、PDFの中の署名辞書に登録されます。署名ハンドラは、署名辞書に独自のエントリを定義することもできます。
3.署名は、データまたはデータの一部のダイジェストを計算し、それをPDFの中の保存することで作成します。署名の検証では、ダイジェストを再計算し、PDFの中に保存されていた値と比較します。もし、一致すれば、文書は変更されていないことになりますが、不一致になりますと文書が署名されてから変更されたことになります。
4.PDFではダイジェストを計算する方法に二つの方法があります。第一は文書の中の全体または特定領域の範囲を指定して計算する方法。第二はメモリの中の特定のオブジェクトを辿ってダイジェストを計算する方法です。この第二の方法はPDF独自ではないでしょうか。これによって、かなり複雑なPDF独自の署名機能を実現できると思います。
5.PDFには幾つかの標準タイプの署名を含むことができます。
(1)1つ以上の通常の署名
(2)最大1個の変更検出・変更防止署名
(3)最大2個のユーザ権利の使用権を指定する署名
ここまで読んだだけで、PDFでは、どうもかなりいろんな種類の署名ができそうだと思われますね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月06日
PDFと署名(5) — 電子証明書
昨日は、公開鍵暗号方式を電子署名に使えることを説明しました。キーポイントは、秘密鍵と公開鍵があって、秘密鍵で署名対象データに署名し、公開鍵で署名から署名対象データを復元することにあります(次の図)。
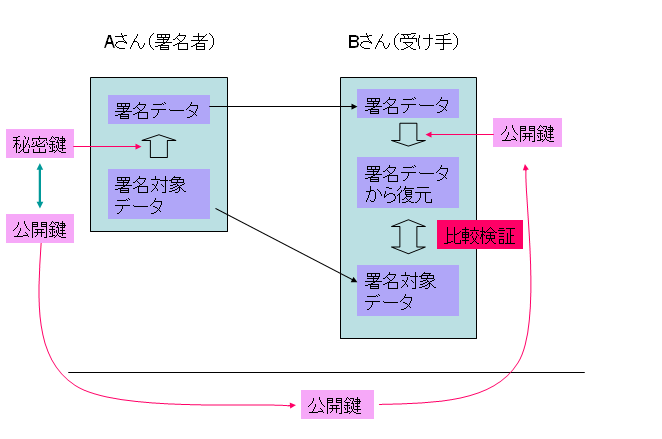
オリジナル文書が大きい場合は、署名・復元の計算時間が膨大になるためオリジナル文書そのものではなく、署名したい文書データから計算したハッシュ値というものを署名対象データとして用います。ここではその部分の説明を省略します。
さて、受け手であるBさんの手元には、署名対象データ、署名データ、公開鍵があります。署名データを復元して、入手した署名対象データと一致したからと言って、署名者がAさんであるとは言い切れません。別のCさんがAさんの名を騙って署名して、Cさんの公開鍵をAさんのものであると偽ってBさんに渡す、という事態が生じる可能性があるからです。
このために、公開鍵には電子証明書をつけます。上に述べましたように、秘密鍵-公開鍵のペアだけでは、署名者を本当に特定することはできません。ですので、電子署名による認証の本質的な役割は、電子証明書が担っているという方が適切なように思います。
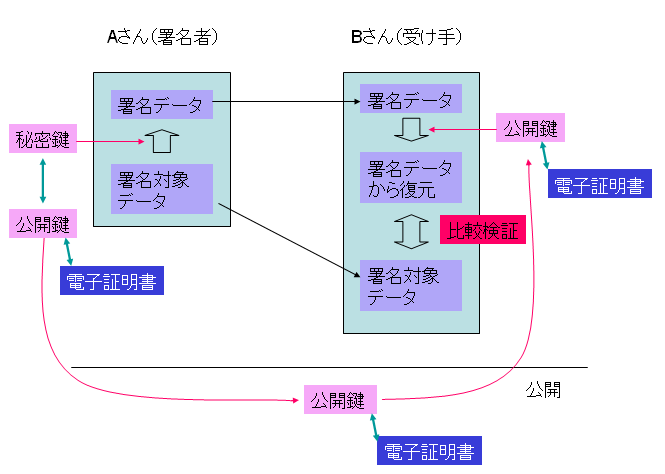
電子証明書の仕組みは幾つかあるようですが、現在、公開鍵暗号基盤(PKI:Public Key Infrastructure)という仕組みが整いつつあります。これは要するに電子証明書を発行して、公開鍵の所有者を特定する社会的な仕組みです。
例えば、e-TaxのWebページには、電子証明書を入手できる機関の一覧が掲載されています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月05日
PDFと署名(4) — 公開鍵暗号方式を署名に使う
前回は、公開鍵暗号方式は、各通信相手毎に異なる「公開鍵」で、相手に渡したい機密データを暗号化し、受け取った相手は、「秘密鍵」でその暗号を解いて、元のデータに戻すという仕組みになっていること。このままでは、署名には使えないのではないかという疑問があることをお話しました。
もう少し調べてみましたところ、署名は、同じ暗号方式の順序を変えて、「秘密鍵」で署名をして、「公開鍵」で逆に署名されたデータを元に戻すのだそうです。
つまり、公開鍵暗号方式は暗号化の鍵を次の図の順序で使います。
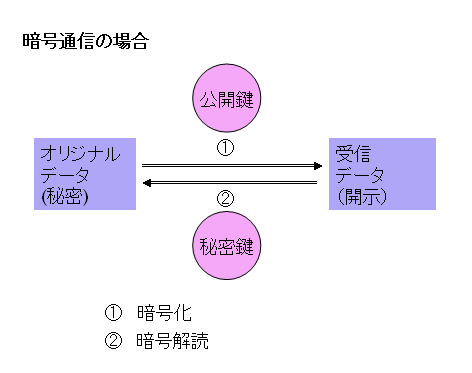
これに対して、署名では暗号化の鍵を次の図の順序で使います。
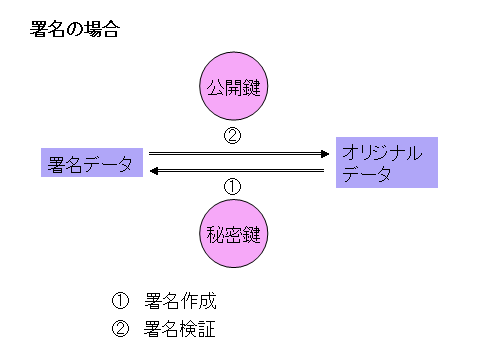
「秘密鍵」は、その署名した人だけが持っているはずの鍵です。オリジナルデータを、その署名者固有の「秘密鍵」で暗号化したデータ(署名データ)は、署名者のみにしか作成することができません。
署名データを受け取った受信者が、その「秘密鍵」と対になる「公開鍵」で署名データの暗号を解いて、オリジナルデータに戻すことができることは、すなわち、その署名データは、「秘密鍵」の所有者によって作られたことを証明できるということになります。
また、署名データとオリジナルデータを受信した人が、署名データから暗号を解いて作り出したオリジナルデータのコピーと、受信した生のオリジナルデータを比較して、一致していれば受信したオリジナルデータが改竄されていないことも証明できます。
こうして、本来は情報の秘密を守るための暗号化方式を、送信者を認識する署名とデータの改竄有無の検証にも使うことができるということになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月28日
PDFの解像度とは?(3) GDI 型PDF Driverの解像度
前回は、PDFの仕様上はグラフィックスがデバイス独立の座標系で表される、そこで、PDFのファイルをダイレクト生成する場合は、解像度の設定は無関係、ということをお話しました。
では、なぜ、様々なPDF Driverに、解像度設定があるのでしょうか?
これについては、もう以前にお話していますが、PDF Driverは、Windowsがプリンタに印刷する仕組みをつかってPDFを作成するからです。
簡単に整理しますと、Windowsからプリンタに印刷するとき、アプリケーションはGDIという仮想的なデバイスにデータを可視化します。そして、GDIに可視化されたデータがプリンタに送りだされることになります。
GDIでは画像が1ピクセル単位で表されますので、ピクセル密度の設定が解像度設定にあたります(次の図をご参照ください)。
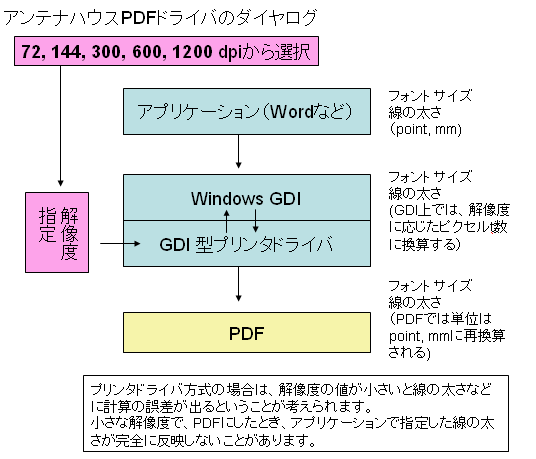
※2006年02月14日PDFの作成方法(21) – PDFドライバの解像度(続き)
結局、「GDI型のプリンタドライバ」は、WindowsのGDIを経由して、プリンタで紙に印刷する仕組みをそのまま使ってPDFを作成するため、プリンタのドット密度に相当する解像度の設定によって、PDFでグラフィックスを表す精度が影響を受けてしまうことになります。
これについて、実際に実験で示したデータについては、2006年02月13日 PDFの作成方法(20) – PDFドライバの解像度をご覧ください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月26日
PDFの解像度とは?(2)
昨日、PDFには、そもそも解像度というものがない、と言いましたが、それをもう少し分解して説明してみます。
PDFにはページの内容を表現するための様々なオブジェクトが定義されています。それらのオブジェクトの中で主なものは、次の図のような、テキスト(文字)、線画、イメージとなります。
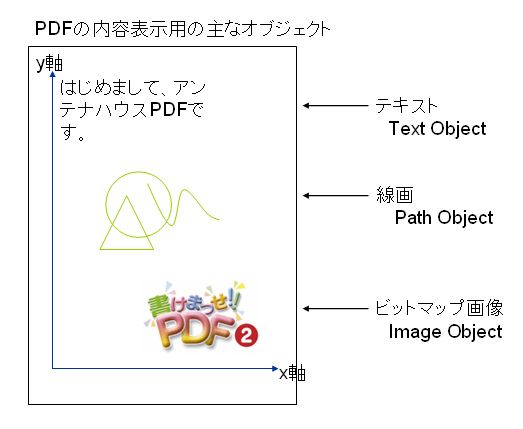
この中で、テキストは文字コードまたはGIDの形で、PDFファイルの中に含まれていることは先日お話しました。
2007年01月22日 日本語の文字についての用語について(9) — PDFへのフォント埋め込みとは
PDFのテキストを表示・印刷する時は、PDFを表示・印刷するコンピュータの上で、フォントのグリフデータを使って、アウトラインの状態からビットマップの状態に変換して可視化されます。その段階で、初めて解像度が問題になります。PDFの状態では解像度という概念はあてはまりません。
※アウトラインフォントの場合です。
PDFファイルの状態では、線画オブジェクトは2次元座標系の上に数学的な直線・曲線(パス)として表現されることができます。そうしたパスに線幅指定、色指定したり、パスで囲む領域を塗り潰したりすることで、図形が表現されます。これらの図形は、物理的な機器とは無縁の、数学的な曲線、曲線の状態を変えるパラメータで表現されていることになります。従いまして、PDFファイルの状態では解像度という概念はあてはまらないことになります。
最後のイメージ・オブジェクトは、ビットマップイメージですので解像度が関係しますが、これは、PDFに埋め込む前にビットマップとして作られていた状態のものを持ち込むことになります。ですのでPDFの解像度というよりは、画像自体の解像度ということになります。
このようにPDFファイルは、基本的にデバイスとは独立の状態でデータを保持することができますので、解像度という概念は該当しないのです。
アプリケーションが、アンテナハウスの「PDF生成ライブラリー」のようなプログラムを使って、オブジェクトを直接PDF内に記述して作成すれば、解像度設定は関係なくなる、あるいは、純粋に数学的に(デバイス独立の)PDFを作ることができます。
今日、ある会社の社長さんがお見えになって、「当社の製品は、CADファイルからPDFファイルへ、ダイレクト変換していますので、高精細です。例えば、円はいくら拡大しても円のまま」というお話をされていましたが、これはそのことをおっしゃっていたのですね。確かに、CADをPDF化するとき、線の太さなどを正確にPDF設定するには、ダイレクト変換が必要なように思います。
アンテナハウスの製品では、サーバベース・コンバータ、XSL Formatterは、それぞれ、ダイレクトPDF作成を行っています。ですので、この2製品には解像度設定はありません。できないのではなく、解像度という言葉が、そもそも該当しないのです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月25日
PDFの解像度とは?
お客様と弊社の担当者の日ごろのやり取りの中で、どうも、PDFの解像度ということが、なかなか理解が難しいようです。
これは、端的に言いましてPDFには解像度という概念はないにも関わらず、Acrobatを初めとする様々なPDF Driver に解像度を設定する機能が備わっている、ということが原因になっていると思います。
以前に、数回にわたり、PDFの解像度関係の話を取り上げたことがありますが、今回は、もう少し別の角度からおさらいして整理してみましょう。
解像度とは?
例えば、Wikipediaの解像度の説明をみますと、「解像度とはビットマップ画像における画素の密度を示す数値である。 すなわち、画像を表現する格子の細かさを解像度と呼び、一般に1インチをいくつに分けるかによって数字で表す。その単位はドット・パー・インチ(dpi)である。」とあります。
これを見ますと、まず、解像度はビットマップ画像について使用する言葉である、ということが分かります。
PDFには解像度はない?
PDFの1ページの表現方法は、原則として用紙の上下・左右の座標系を想定し、その座標の位置に線を引くか、というような、ベクトル表現でデータを表します。しかも座標系の単位は自由に設定できます。
ですので、スキャナーで作成したようなPDFの解像度(これはPDFの解像度というよりもスキャナーの解像度です)や、PDFに埋め込まれているビットマップ画像などを除いて、PDFには解像度という概念はあてはまりません。
そう言い切ってしまいますと、それで話は終わりなんです。ところが、実際は、
次の図のように、PDFを作成するDriverソフトでは、解像度を設定できるようになっています。
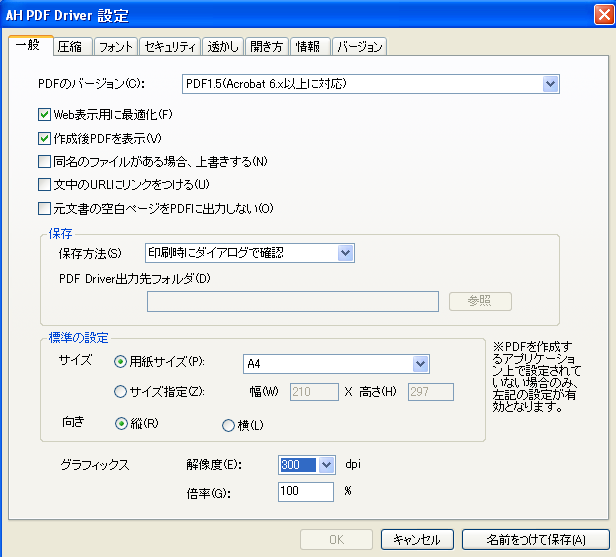
※Antenna House PDF Driver V3.1 の設定画面
これは、なぜなんでしょうか?解像度という言葉ががあてはまらないはずのPDFを出力するドライバに、なぜ、解像度設定が出てくるのでしょうか?
以前に、そのあたりのお話をしましたが、どうも今読み返して見ますと、やけに難しく書いてありますね。自分で読んでも良く分かりません。(汗)
これじゃ、わかんないや、といわれそうです。明日から、もう少し噛み砕いてお話するように試みてみましょう。
【参考】 以前の解像度に関するお話
2006年02月13日 PDFの作成方法(20) – PDFドライバの解像度
2006年02月14日 PDFの作成方法(21) – PDFドライバの解像度(続き)
2006年02月16日 PDFの作成方法(22) – Acrobatの解像度設定
2006年02月17日 PDFの作成方法(23) – GDIをバイパスして高精細なPDFを作成
2006年02月18日 線の太さについてのPDFの仕様
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月03日
Web表示用に最適化PDFの意味、用途、効果
過去何回かわたり、PDFのWeb表示用に最適化(リニアライズドPDF)について、お話しましたが、それを整理してみました。
こちらをご覧ください。
Web表示用に最適化という機能は、いまひとつ理解が進んでいないようです。しかし、これからは、携帯電話やモバイル機器などでのPDF表示が使われる機会も増えるでしょうから、重要度が増すのではないでしょうか。
投稿者 koba : 08:10 | コメント (0) | トラックバック
2007年01月02日
Web最適化について 再度
WikipediaのPDFの項を見ていましたら、「また、ユーザビリティに十分配慮して作成されたHTMLドキュメントと比べると、PDFは扱いにくい面がある。 PDFのドキュメントは、ドキュメントの一部分だけを参照したい場合でも、最初から最後まですべてのデータを閲覧端末に読み込む必要がある。」(2006年12月31日時点の文章)という説明がありました。
これは、技術的に見て、少し説明が足りないと思います。そこで、蛇足ながら、また、Web最適化についてお話したいと思います。
確かに、Web最適化していないPDFでは、この説明の通りです。しかし、既に、このブログでは何度かお話しましたが、PDFにはWeb最適化(リニアライズ)という仕様があります。リニアライズしたPDFの場合、PDF Readerは、ドキュメントの特定ページを直接参照することができます。
PDF Reference 1.7では、Linearized PDFについてpp. 1021 - 1055まで35ページにわたって説明があります。
それによりますと、Linearized PDFは、PDF仕様1.2から追加された機能で、次のような目的をもつとあります。
1.PDFを開くとき、最初のページを可能な限りすばやく開く。最初のページとしては、先頭ページでなくて任意のページを指定できる。
2.ユーザが開いたページから別のページを要求したとき、可能な限りすばやくそのページを開く。
3.文書を遅い通信回線を使って配布するとき、ページを少しづつ順に表示できるようにする。
4.リンクを辿るときに、全てのページを受信して表示しなくても良いようにする。
リニアライズしたPDFでは、PDFを最後まで読まなくても表示することができます。これは、実際にPDFを作成して試してみると分かります。ご参考のために実証データを作成してみました。
Web最適化PDFの実証データ
「XSL Formatter V4.1のマニュアル (PDF)」をWeb最適化したものとしていないものを用意しました。ファイルサイズは、それぞれ約3MBです。
antenna.co.jp
Web最適化していないPDF
Web最適化したPDF
Web最適化していないPDFの150ページを直接取得
Web最適化したPDFの150ページを直接取得
antennahouse.com
こちらのWebサイトの方が、アクセスが遅いので、違いが良く分かると思います。
Web最適化していないPDF
Web最適化したPDF
Web最適化していないPDFの150ページを直接取得
Web最適化したPDFの150ページを直接取得
【ご注意】
IE6、IE7や、FireFoxで上記の設定の違いは有効です。しかし、FireFoxに「PDF Download」(http://www.pdfdownload.org/)を追加してしまうと、上の設定の違いがなくなってしまうようです。
Adobe のAcrobatでは、PDFを印刷機能から作成するとき、リニアライズする設定になっていますので、ユーザの皆さんが意識することが少ないと思いますが、リニアライズするかしないかの指定もできます。そして、あるPDFがリニアライズされているかどうかは、Adobe Readerであれば、文書のプロパティで確認できます。
次の図をご参照ください。
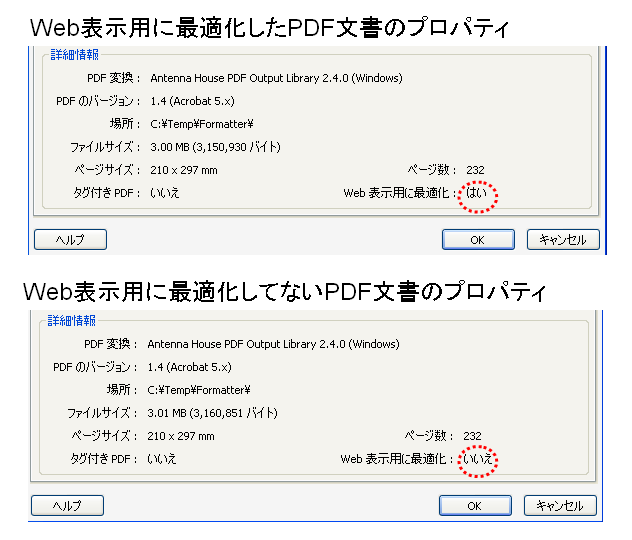
実際には、リニアライズドPDFは、PDFを一旦作成した後に、PDF内部のオブジェクトの順番を並び替えて、表示用に最適化します。
また、PDFは、一旦作成した後で、様々に情報を追加したり、更新できるようになっています。少しでも情報を追加すると、リニアライズドではなくなりますので、再度、リニアライズ処理を施す必要があります。
なお、アンテナハウスの主な製品は、PDFのリニアライズ(Web最適化)機能を持っています。PDF Driver は、V3.1からこの機能を追加しました。
【ご参考】
2006年07月03日リニアライズドPDFとは
2006年07月04日リニアライズドPDFの利用方法 バイトサービング
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年12月08日
PDFのXMLフォーマットが登場!?
Adobeでは、PDFのXMLフォーマットMarsを開発しているようです。
Adobe Labs:Mars
http://labs.adobe.com/wiki/index.php/Mars
PDF Referenceを読み込むにつれて、また、PDFの製品をいろいろ作るにつれて、PDFのレガシーさが嫌になってきて、これは、PDFをXML形式で書き直さないといけないな、と思い始めていたのです。しかし、どうやらAdobeがやっているようなので残念。正直、これはAdobeにやって欲しくないな、と思っていました。なぜかというと、PDFは、もう20年前の技術をベースにしていますので、過去を捨て去って書き直しするべきところが多いように思うのです。Adobeがやると好むと好まざるとにかかわらず、過去との連続性を考えるでしょうからね。
もっとも過去を切り捨てたらPDFじゃなくなるかもしれません。過去を捨ててしまったらXPSとどう違うんだ、といわれてしまいそう。
そんなことを思いながら、ちょっと見てみました。
仕様書(V0.7)はこちらにあります。
Mars Reference
200ページ位です。残念ながらいま忙しくて読んでる時間がありません。
サンプルがあります。
中身を見てびっくり。
まず、全体のファイル構造ですが、次のようなツリーになっています。ひとつのファイルはXMLで書かれた本文や画像などのリソースからなるいくつかのパーツから構成されています。それをZIPで圧縮して固めているのは、MicrosoftのXPSと似ています。
全体に、XPSと印象が良く似ていますが、Marsの場合は、1ページずつ別のフォルダに入っています。
ちょっと驚きましたのは、ページの本文ファイルは拡張子SVGです。どうやらSVGになっているようです。
で、XSL Formatterで見てみました。(XSL Formatter は、SVGビューアとしても使えます)。
これは完全にSVGですね。それにしても、AdobeはSVGを止めたと思ったのに、こんなところで、しっかりSVGをやっているようです。どうなってるんでしょう。
【参考】
2006年10月23日
アドビSVG Viewer、2008年1月でサポート終了
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年11月29日
PDF Reference 1.7の変更点の検討(3)
次に、本文の項レベルでの変化をチェックしてみます。
2章 概要は、2.1節、2.2節とも項レベルの変更はありません。
3章 シンタックスは、3.1節~3.10節までありますが、3.8.1項が変更になっています。
PDF Ref 1.6では、3.8.1 TextStringでした。
PDF Ref 1.7では、3.8.1 String Typesに変更になり、下位に、Text String Type, PDFDocEncoded String, Byte String Type という見出しが新しくできています。
4章 グラフィックスは、変更ありません。
5章 テキストは、変更ありません。
6章 レンダリングは、変更ありません。
7章 透明も変更ありません。
8章 対話機能
8.2.4 コレクションが追加になっています。これは昨日の、PDF1.7の特徴のドキュメントのナビゲーション機能の追加に相当します。
8.7.1 の署名の互換性のPKCS#7にRevocation Informationの見出しが追加。
それから、以前にも言いましたが、8.9節が新設されています。
9章 マルチメディアは、9.5の3次元作品の項がだいぶ強化されています。
10章 ドキュメント交換では
10.7節タグ付きPDFの
10.7.4標準構造属性の下に、印刷フィールド属性という見出しが新設されました。
こうしてみますと、大体、1.2節にPDF 1.7での新機能の説明の内容と同じになっています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月28日
PDF Reference 1.7の変更点の検討(2)
昨日に続いて、PDF Referernce 1.7 での新機能の紹介です。
1.2.4 ドキュメントのナビゲーション機能
複数の添付ファイルをひとつのウインドウで表示するポータブル・コレクションと呼ぶ機能を追加。これは、電子メールのアーカイブや写真のコレクションなどを提示するのに使えます。
1.2.5 セキュリティ関連機能
電子署名関係の機能を強化しました。
また、後方互換性を実現するため、PDFの消費(利用)アプリケーションが備えているべき項目を要求できるようにしました。
1.2.6 一般機能
様々なプラットフォームの使用を推進するため、指定する文字の符号化を説明するための文字型をより明確に。ファイルのパスの文字列に、プラットフォームの標準のほか、Unicode文字列を使用できるようにしました。
1.4 知的所有権
ここは大幅に書き換わっています。簡潔になりましたが、著作権や特許をアドビが保有していることがはっきりと書いてあります。ただし、特許については、
Adobe desires to encourage implementation of the PDF computer file format on a wide variety of devices and platforms, and for this reason offers certain royalty-free patent licenses to PDF implementors worldwide.
とありますので、世界中のPDFの実装者には無償の特許使用権を提供するとあります。certain (ある一定の)の詳細はこちらです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月27日
PDF Reference 1.7の変更点の検討
次に、PDF Reference 1.7 の変更点について、順次チェックしてみます。
最初に、前書きですが、面白いことに、PDF Referenceには、「A significant number of third-party developers and systems integrators offer customized enhancements and extensions to Adobe’s core family of products. Adobe publishes the PDF specification in order to encourage the development of such third-party applications.」という段落がありましたが、これが、ごっそり削除されています。
つまり、アドビがPDF Referenceを公開する目的として、サードパーディがアドビのコア製品ファミリに対して、機能強化・拡張するのを奨励する、ということが以前は謳われていましたが、その項目が削除されたということです。もう、アドビAcrobatのサードパーティはお役ご免らしいですね。
でも、こういう変更して、日付が2004年11月のままとは?過去に遡って方針変更するてことかな?
この本についての節(1.1About This Book)の、次の段落は、もちろん、残っています。
This book provides a description of the PDF file format and is intended primarily for developers of PDF producer applications that create PDF files directly. It also contains enough information to allow developers to write PDF consumer applications that read existing PDF files and interpret or modify their contents.
この段落が削られたら、その時は、PDF ReferenceがPDF開発者の聖書ではなくなる時です。Microsoftもそうですが、米国のソフトハウスは、基本的な方針転換を平気でやるので、注意しなければならない、と思っています。
1.2節にPDF 1.7での新機能が紹介されています。
1.2.1 3次元の作品の表示機能
オリジナルの3次元作品やJavaScriptを使わずに表示制御ができます。3次元の作品を後で適切に見せるための3次元の見栄えについてのマークアップ注釈ができます。アニメーションの制御ができます。
1.2.2 対話機能について
テクニカル・コミュニケーション(TC)とレビュー向け、リーガル設定向けのマークアップ注釈を強化しました。
具体的には、TC用としては、多角形、折れ線についてのマークアップ注釈で、次元、単位、拡大縮小などを意図する機能を追加、など。
リーガル向けでは、用紙選択、印刷処理、ページ範囲などの印刷特性のためのビューア設定の注釈を追加。
1.2.3 アクセシビリティ
TaggedPDFの次のような強化でページ内容の種類の役割を認識できます。
・フォームフィールドの役割
・表の要約の提供
・ページ全体の背景色などの背景の識別
・ウオーターマークやヘッダ、フッタの識別
(つづく)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月26日
PDF Reference 1.7 で追加された内容
さて、昨日、PDF Referernceは、1.6から1.7にかけて、64ページ増えただけということを紹介しました。
実際、Planet PDFには、編集者への手紙というタイトルで、「Acrobat 8は近年のもっとも弱いバージョンアップ」という意見が紹介されています。
それについては、2006年09月30日 Acrobat 8とPDFのファイル形式でも、アドビの担当者のブログで紹介しています。
具体的に、PDF Referenceの1.6から1.7で実際にどのあたりが変わったのか、チェックしてみましょう。
まず、章立てですが、これはまったく変わっていません。
節が増えたのは、本文では、8章 Interactive Featuresの8.9 Document Requirements (pp. 751~753)のみです。この節では、PDF 1.7では、PDF作成アプリケーションはPDF作成時に、そのPDFを利用するアプリケーションが、PDFを正しく処理するために持っていなければならない機能を規定できる、ということを書いてあります。
付録では、D.2 PDFDocEncoding Character Set ( pp. 1001~ 1009)
G.7 Structured Elements That Describe Hierarchical Lists (pp. 1082~ 1090)
のみです。
D2は、 PDFDocEncodingという独自の符号化文字集合です。PDFDocEncodingは、PDF の最初のころからあったと記憶していましたので、おかしいな、と思いましたが、新しく追加されたのは、PDFDocEncodingとUnicodeの対応表ですね。
(ついでに、この表見ていて、先頭のほうの文字が正しく表示されていないことに気がつきました。
PDF ReferenceはFrame Makerで作っているのですが、FrameMakerじゃ無理なんじゃないのかな。)
G.7は、階層リストを表現する構造要素についてのサンプルです。
ですので、新しく追加された節は、実質的に8.9のみでしょう。
なお、ページ数でみますと、9.5 3D Artwork 789が、29ページほど増えていますので、ここが一番分量的には増えているようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月25日
PDF Reference 1.7が出ています
アドビのホームページにPDF Reference の第6版(PDF 1.7)がアップされています。
PDF Reference, Sixth Edition, version 1.7
今回の版は、総ページ数1310ページ。前版PDF 1.6が1236ページですので64ページの増加となります。
ところがファイルサイズが、PDF 1.6が8.86MB なのに、PDF 1.7は、30.93MBと約3.5倍になっています。
これは、なぜなのかと思い、チェックしてみましたところ、PDF 1.7は、タグ付きPDFになっています。PDF 1.6はタグが付いていません。ですので、このファイルサイズの違いは、ほとんどタグ付きPDFに変更したためと思います。
※タグ付きPDFとは、PDF内部に文書の構造情報を持たせるための情報を付け加えたもの。スクリーン・リーダでPDFの文章を読み上げる順序を正しくすることができますので、PDFのアクセシビリティを実現するための技術として使われます。
PDF Referenceもタグ付きPDFに変更とは、いよいよ、米国ではタグ付きPDFが標準になるということなんでしょう。
アンテナハウスのXSL Formatterも、海外のお客さんから、タグ付きPDF出力機能の要求が頻繁になり、漸く今年の4月のV4.0からタグ付きPDF出力機能をつけたばかりです。このときも、タグ付きPDFを作るとファイルサイズが大きくなるので気になっていたのですが。
ちなみに、XSL Formatterのサンプルページの「XMLからXSL-FOに変換するためのXSLTスタイルシートの作成方法」という71ページの文書で比較してみますと、次のようになります。
・タグ付きPDFで作成すると: 1,742KB
・タグ付きでないPDFでは : 871KB
この場合は、大体2倍になっています。ファイルサイズがむやみに大きくなると、ただでさえ、重いPDFがますます重くなって不評になると思うのですが、それを犠牲にしてでもタグ付きにしなければならない時代になるのでしょうね。
タグ付きPDFには、PDF文書が構造情報を含んでいるので、PDFからWordに変換する際、再現性が良くなるだろうというメリットもあります。日本でもタグ付きPDFが普及するまでに、PDFからOfficeへのコンバータもタグを使って変換できる機能を強化しなければならなくなりそうです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月24日
PDFのセキュリティ機能(8)—まとめ
PDFの標準セキュリティ機能について、11月1日から11月19日にかけてお話しました内容をまとめてみました。
仕様書を読みながら、いろいろ書いていくうちに、ブログの連載の最初の方でお話しました内容が少し間違っていることに気が付きましたので、そのあたりも訂正してあります。
もし、皆様のお時間が許すようでしたら、まとめの方をお読みになっていただければと思います。
お恥ずかしいですが、時間もありませんので、ブログの方は訂正していません。書き直すと限りもないことですし。
ところで、本日、24日は、「リッチテキストPDF2 D&D」パッケージ版が、全国一斉発売の日です。こんな感じのパッケージです。どうぞ、よろしくお願いします。

投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月19日
PDFのセキュリティ機能(7)—公開鍵セキュリティ・ハンドラ
PDF Referenceの3.5 暗号化の項には、これまでにお話ししました、パスワード・ベースの標準セキュリティ・ハンドラの他に、3.5.3 公開鍵セキィリティ・ハンドラという、もうひとつのセキュリティハンドラが規定されています。
公開鍵セキィリティ・ハンドラは、公開鍵暗号化技術を使ってPDFにセキュリティをかける方式です。
公開鍵暗号化技術については、いろいろなところで解説されていますが、ざっとまとめて見ますと次のようになると思います。
例えば、AとBの2者間で、公開鍵暗号化方式を使って暗号化通信を行おうというときの順序は、
1.Bは、公開鍵と秘密鍵のペアを用意します。このふたつの鍵は、まったく異なる鍵ですが、一方で暗号化したものは他方の鍵でしか、暗号解除することができないものです。
2.Bは、公開鍵の方をインターネットやメールなどを通じて、公開(Aに渡)します。秘密鍵は、外部に漏れないように保持します。
3.Aは、Bの公開鍵を使って文書を暗号化し、暗号化した文書をBに送信します。
4.Bは、Aから受け取った(暗号化された)文書を、秘密鍵を使って暗号を解除します。
5.うまく暗号が解除できれば、受け取った文書はBの公開鍵で暗号化されたものであることになります。
この通信方式は、電子署名(デジタル署名)とは鍵の使い方が逆になっていることに注意してください。ちなみに、電子署名は、秘密鍵で暗号化したものを相手に渡し、相手は、公開鍵で暗号を解除するものです。
さて、PDFの公開鍵セキィリティ・ハンドラは次のようなことを行うとされています。
(PDF Reference 1.6 pp.104 - 106)
1.PDFの文書コンテンツを暗号化するときに使用する暗号キーの元と、PDFを送信する相手(複数人)のPDFの利用権限(相手によって変えることができます)設定データを用意します。
2.PDFを送信する相手の公開鍵を入手します。複数のときは、公開鍵は相手毎に異なったものになります。
3.1で用意したキーと相手の利用権限設定データを、相手毎に、各人の公開鍵を使って暗号化します。それらの暗号化されたデータをまとめて、受信者データ表として作成します。
4.PDFの暗号化辞書に3で作成した受信者データ表を記録します。
こうして作成した暗号化済PDFを、相手に配信します。
PDFを受け取った相手は、各人の秘密鍵を用いて、受信者データ表の中から暗号キーの元と自分用の利用権限データとを取り出します。この暗号キーの元を使って、PDFの暗号を解いてPDFを閲覧します。この時、自分用の利用権限データが有効になりますので、PDFの配信元が設定した利用権限の範囲内でしかPDFを利用できないことになります。
パスワード方式の標準セキィリティ・ハンドラでは、PDFの受け手によって利用権限を変更することはできないのですが、公開鍵セキィリティ・ハンドラを使うと相手によって利用権限を変えることができます。
なお、PDFの利用権限の設定は、
2006年11月13日
PDFのセキュリティ機能(3)—PDFの利用許可制御で説明しましたものと同じです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月16日
PDFのセキュリティ機能(6)—AES暗号アルゴリズムの使用
昨日は、PDF 1.6から仕様上、AES(Advanced Encryption Standard)を指定可能になったとお話しました。
AES暗号は、米国が2001年に標準として定めた新しい暗号アルゴリズムです。
AES暗号などによりますと、米国でそれまで使っていた標準暗号方式が、技術進歩により脆弱になったため、世界中から公募した15種類の暗号方式から選択されたもので、最終的にベルギーの研究者が考案したものが採用された、とあります。
従来、PDFで使われていた暗号アルゴリズムRC4は、私企業のプライペートな暗号アルゴリズムであったのに対して、AESは、政府が標準として定めた暗号アルゴリズムであり、仕様書が一般に公開されているのが大きな特徴です。
PDFでも、今後は、AESをサポートするPDF生成ソフト、PDF消費ソフトが増えてくることを期待したいと思います。
Acrobat7のPDFドライバでは、AESが使えませんが、Acrobat7(GUI)では、暗号アルゴリズムとしてAESを設定することができます。
次の図のようにAcrobatでPDFを読んで、セキュリティを設定する際に、互換性のある形式として「Acrobat 7.0およびそれ以降」というカテゴリを選択しますと、AES暗号アルゴリズムを設定することになります。
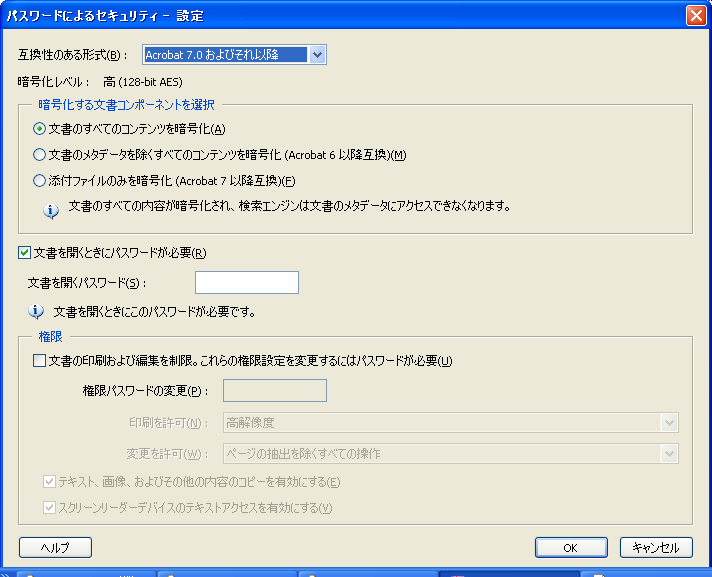
ただし、注意しなければならないのは、セキュリティ設定時にAESで暗号をかけてしまうと、PDF のリーダソフトの標準セキュリティ・ハンドラがAESに対応していないとファイルを開けなくなることです。
例えば、Adobe Readerの場合、Adobe Reader7では、AES暗号を設定したPDFを開くことができます。
■AES暗号でセキィリティを設定したPDFを、Adobe Reader7で開き、セキュリティ・タブで「詳細情報」を表示
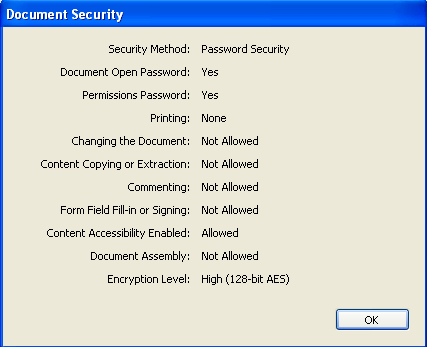
しかし、Adobe Reader6の標準セキュリティ・ハンドラはAES暗号アルゴリズムを内蔵していないため、PDFに正しくない暗号が掛かっている、と誤認してしまいます。
■AES暗号でセキィリティを設定したPDF(上と同じ)を、Adobe Reader6で開こうとするとエラーになってしまいます。
Adobeの製品以外でもPDFを処理する様々な製品があります。現時点では、AES暗号を不用意に使いますと、受け手がPDFの内容を表示することができなくなります。多くのソフトでAES暗号が使えるようになるまでには、少し時間がかかるものと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月15日
PDFのセキュリティ機能(5)—リビジョン4の標準セキュリティ・ハンドラ
次に、標準セキュリティ・ハンドラのリビジョン4について整理してみます。
リビジョン4の標準セキュリティ・ハンドラは、PDF 1.5(Acrobat6)以降で使えます。この標準セキュリティ・ハンドラで追加になっている機能は次の点です。
(1) PDF 1.5の仕様で追加された、暗号フィルター辞書(CryptFilter)機能 — 後述 — を使用できます。
(2) 暗号辞書の中で、PDFの中のストリング、ストリーム、添付ファイルに対して使用する暗号フィルターを個別に指定できます。なお、添付ファイルについてはPDF1.6からとなります。
(3) 暗号辞書の中で、メタデータを暗号化するかどうかを指定できます。なにも指定しないと、メタデータも暗号化しますが、「メタデータは暗号化しない」ようにすることも指定できます。
レビジョン4で追加されたのは、PDFに関するパスワードによるアクセス管理ではなく、むしろPDFコンテンツへの暗号のかけ方をより細かく設定可能にする機能、と言えます。
暗号フィルター辞書とは
暗号フィルター辞書は、PDF 1.5から追加された仕様で、暗号フィルターを定義するものです。その役割は、主に使用する暗号アルゴリスムの指定、暗号フィルターを適用するタイミングを指定などです。
PDFの暗号化では、これまでRC4暗号アルゴリズムを使っていましたが、PDF 1.6から新しい暗号アルゴリズムAES(Advanced Encryption Standard)も使えるようになりました。暗号フィルターで、使用するアルゴリズムをRC4にするかAESにするか指定できます。また、暗号化しないでスルーする暗号フィルターを定義することもできます。
さて、PDF Referenceの仕様上は、上のような機能が追加されていますが、Acrobat7 のPDFドライバで、使用できるようになっているのは、「メタデータを暗号化しない」という機能のみのようです。AES暗号アルゴリズムはもとより、ストリームとストリングで暗号フィルターを切り替えるというような機能も指定できません。
次の図は、Acrobat 7のPDF ドライバのセキュリティ設定のダイヤログですが、「文書メタデータを暗号化しない」のチェック・ボックスが追加されています。
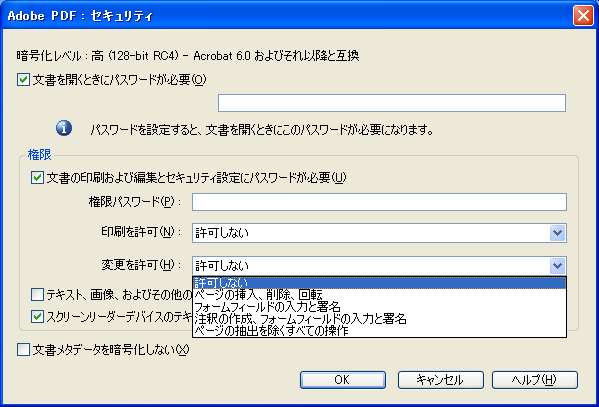
折角追加された、AES暗号アルゴリズムはAdobeのプリンタ・ドライバからは指定することができません。このあたりは、Acrobat 8で変更になるかもしれませんが。
ちなみに、近くリリース予定のAntenn House PDF Driver V3.1では、AES暗号アルゴリズムを指定できるようになっています。もしかすると、PDF Driverに世界で初めてAES暗号アルゴリズムを採用しました!と宣伝できるかもしれないと思いました。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月14日
PDFのセキュリティ機能(4)—Acrobatの実装をチェックする
さて、PDF Referenceでの標準セキュリティ・ハンドラについて記述されている仕様を紹介しましたが、次に実際のプログラムの画面で、どうなっているかをチェックしてみたいと思います。
まず、Adobe Acrobat(プリンタ・ドライバ)でセキュリティ設定をするためのダイヤログを見ます。(このダイヤログは、PDF 1.4レベルで、標準セキュリティ・ハンドラのリビジョン3を選んでいる状態に相当します)。
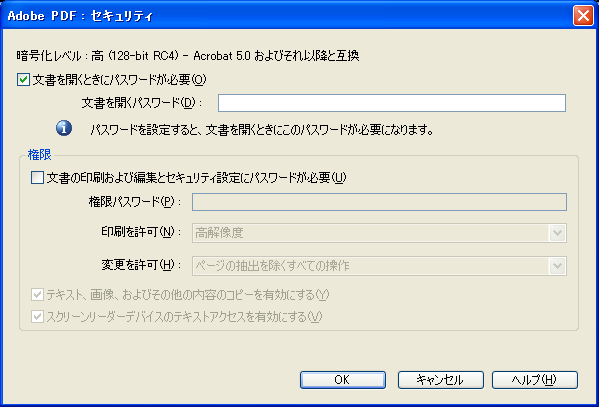
・「文書を開くときにパスワードが必要」にチェックしますと、ユーザパスワードを設定することになります。そうしますと、PDFを利用する人がパスワードを入れないと文書を開くことができなくなります。
・「文書の印刷および編集とセキュリティ設定にパスワードが必要」は、少々、分かりにくい日本語のようにも思いますが、ここにチェックしますと、昨日、説明しましたオーナーパスワードを設定できることになります。
さて、オーナーパスワード設定の状態では、次の二つのダイヤログに示すように、PDF に次のセキュリティを設定できるようになります。
・印刷許可(次のいづれか) — 許可しない、低解像度、高解像度
・変更を許可(次のいづれか) — ページの挿入、削除、回転
フォームフィールドの入力と署名
注釈の作成、フォームフィールドの入力と署名
ページの抽出を除く全ての操作
・テキスト、画像、およびその他の内容のコピーを有効にする
・スクリーンリーダデバイスのテキストアクセスを有効にする
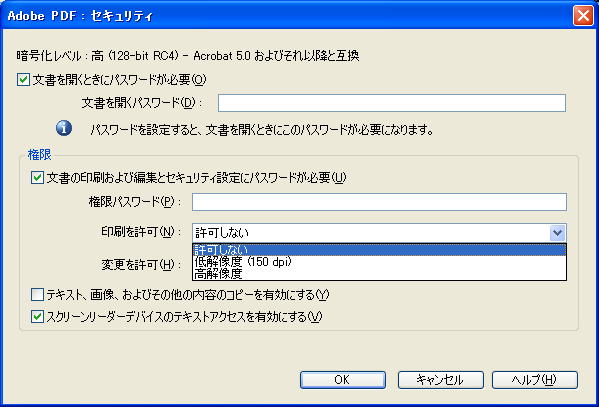
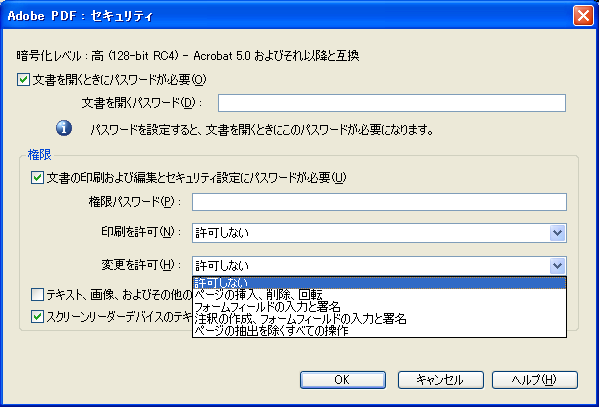
セキュリティ設定のダイヤログを見ますと、Adobe Acrobatのプリンタ・ドライバでは、PDF Referenceに記載されているすべてのセキュリティ設定パターンは指定できないことが分かります。例えば、PDF Referenceの仕様では、「ページの挿入、削除、回転」と「フォームフィールドの入力と署名」は独立に設定 — 両方NO、どちらか一方のみYes、両方Yesの4通りの設定 —できるはずなのに、このダイヤログのメニューでは、両方Yesの設定は不可能です。
さて、PDFに設定されているセキュリティの状態を確認するには、Adobe ReaderでPDFを開いて、文書のプロパティ「セキュリティ」タブを選択します。そこでセキュリティ設定の詳細を確認することができます。
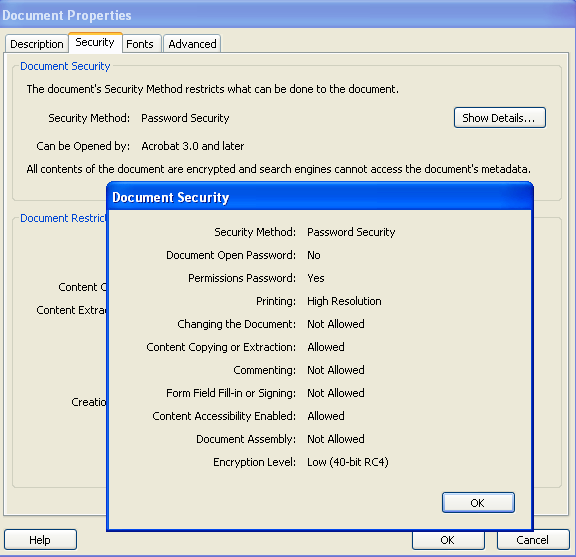
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月13日
PDFのセキュリティ機能(3)—PDFの利用許可制御
さて、今日は、オーナーパスワード(編集パスワード)により設定できるPDFの利用許可制御について、PDF Referenceに記載されている内容を説明します。
PDF作成者は、PDFにオーナーパスワードを設定するとき、PDFを受け取ったユーザがPDFに対して何ができるかを許可できます。PDF利用許可の内容は、PDFに保存される暗号辞書中のフラグのある桁をONにすることで設定します。
標準のセキュリティ・ハンドラには、リビジョン番号2,3,4の3種類があります。PDF Reference 1.6の表3-20 (pp.99-100)に基づいてリビジョン2で設定できる項目を表1、リビジョン3と4で設定できる項目を表2に整理します。
表1.リビジョン2の標準セキュリティ・ハンドラで許可できること
| ビット位置 | ONの時許可 |
|---|---|
| 3 | 印刷を許可する |
| 4 | 内容の変更を許可する |
| 5 | テキストや画像の抽出を許可する |
| 6 | テキスト注釈の追加・変更と対話式フォームフィールドを埋めることを許可する。ビット4がONならば、新しい対話式フォームフィールドを作成したり、変更することも許可する |
表2.リビジョン3、4の標準セキュリティ・ハンドラで制限できること(*は、リビジョン3・4で、リビジョン2に追加されたこと)
| ビット位置 | ONの時許可 |
|---|---|
| 3 | 印刷許可する—さらにビット12がONなら高精度印刷を許可、OFFなら低解像度印刷を許可(*) |
| 4 | 内容の修正を許可する |
| 5 | アクセシビリティ以外の目的でテキストや画像の抽出を許可する(*) |
| 6 | テキスト注釈の追加・変更と対話式フォームフィールドを埋めることを許可する。ビット4がONならば、新しい対話式フォームフィールドを作成したり、変更することも許可する |
| 7 | ビット6が不許可でも、署名を含め対話式フォームフィールドを埋めることを許可する(*) |
| 10 | アクセシビリティの目的(スクリーン・リーダなど)でテキストや画像の抽出を許可する(*) |
| 11 | ビット4(内容の修正)が不許可の時でも、文書の合成を許可する—ページ挿入・ページ回転・ページの削除・しおりの作成・サムネイルの作成(*) |
| 12 | 高精度印刷を許可する |
ちなみに、リビジョン2の標準セキュリティハンドラは40ビットの暗号方式、リビジョン3の標準セキュリティ・ハンドラは、PDFのバージョン1.4から使用可能になった128ビットの暗号方式です。また、バージョン1.5からはリビジョン4の標準セキュリティ・ハンドラが使用可能です。(これらについては、後日、もう少し詳しく説明します)。
ここで分かりますように、リビジョン3・4の標準セキュリティ・ハンドラの方が、リビジョン2よりも詳細な許可設定ができるようになっています。
【注意】上の説明は、あくまで仕様書で規定されている内容であることに注意してください。つまり、皆さんが日ごろご覧になっている実際のプログラムの動きとは違うかもしれない、ということです。すべてのプログラムが、仕様を上の通りに実装しているとは限らないからです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月12日
PDFのセキュリティ機能(2)—暗号辞書とセキュリティ・ハンドラ
さてPDFのセキュリティの方式について、もう少し調べてみます。
1.暗号辞書
PDFに暗号が掛かっているときは、PDFファイルのトレイラに暗号辞書が登録されます。昨日もお話しましたように、PDFを利用するときは、作成ソフトと消費ソフトが異なりますので、お互いに暗号の方式についての情報を交換する必要があり、この交換すべき情報を暗号辞書の内容に設定するようになっています。PDFにこの暗号辞書がないならば、暗号化されていないということを意味します。
2.セキュリティ・ハンドラ
暗号辞書には、セキュリティを処理する方法(セキュリティ・ハンドラ)についての情報を登録できるようになっています。セキュリティ・ハンドラとは、文字通りPDFに対するセキュリティを取り扱うプログラム・モジュールです。
PDF仕様に記載されているセキュリティ・ハンドラには、標準セキュリティ・ハンドラ(3.5.2)と公開鍵セキュリティ・ハンドラ(3.5.3)が規定されています。また、それ以外の独自セキュリティ・ハンドラを使うこともできます。
昨日、パスワード方式と署名方式が使えると言いましたが、それぞれを取り扱うのが標準セキュリティ・ハンドラと、公開鍵セキュリティ・ハンドラに相当します。
3.標準セキュリティ・ハンドラ
パスワード方式で、PDFへのアクセス許可を設定可能とし、それを処理するものです。PDFの仕様では次の2種類のパスワードを設定することができるようになっています。
(1)オーナーパスワード—編集パスワードとも言い、PDFの内容を修正したり、データを取り出したりなどの制限事項を設定します。
(2)ユーザーパスワード—閲覧パスワードとも言い、PDFを表示して読むことができるための閲覧許可を与えます。
PDFを作成する人が、PDF作成時にパスワードを設定します。
もし、ユーザーパスワードが設定されていると、PDFを利用する人が正しいパスワードを入れないと、PDFを表示することができなくなります。
オーナーパスワードが設定されている場合は、パスワードを入力しなくても、制限事項に設定されている範囲でPDFを利用することができますが、それ以外の目的に利用するためには、正しいオーナーパスワードを入力することが求められます。
この制限事項は、セキュリティ・ハンドラのリビジョンによって、具体的に設定できることが違ってきますのでややこしいです。作成するPDFのバージョンによって、設定できる標準セキュリティ・ハンドラのリビジョンが決まってきます。そして、そのPDFを正しく閲覧・処理できるかは、Adobe ReaderなりPDFビューアが内蔵している標準セキュリティ・ハンドラのリビジョンで決まってくるわけです。
標準セキュリティ・ハンドラがなにをなすべきかはPDF Referenceに書いてありますが、あるソフトウエア製品がPDF1.6のパスワード方式セキュリティを正しく処理できるとは、PDF1.6仕様で規定する標準セキュリティ・ハンドラのリビジョン(の機能)を、その製品に実装していることを意味していることになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月11日
PDFのセキュリティ機能(1)—概観
さて、話題を変えて、今日から、PDFのセキュリティ機能について整理してみたいと思います。実は、私はセキュリティはあまり詳しくありません。また、PDF Referenceを読みましても、PDFのバージョンが上がるにつれて、セキュリティ機能が追加されたり、既に廃止されたという記述があったり、さらに、カスタムのセキュリティ方式を組み込む機能が説明されているなど、PDF標準のセキュリティの詳細はかなり複雑に入り組んでいます。
このため、開発担当者にいろいろ聞いてもなかなか理解できないのですが、PDF Referenceを参考にしながら、できるだけまとめてみたいと思います。
そんなわけで、もしかすると間違いが含まれているかも知れませんので、間違いにお気づき方のは、お教えいただけるとありがたいです。
まず、PDFの標準では、どのようなセキュリティ方式が使えるか、ということですが、大きく分けると次のようになります。
(1)パスワード方式—これは共通鍵暗号方式と言い、PDFを作成する人と、PDFを利用する人の間で取り決めた共通のパスワードを使って、PDFの内容へのアクセスを制御する方式です。
(2)署名方式—公開鍵暗号方式による電子署名がその代表的なものです。
次に、PDFに標準で用意されている方式ではないと思いますが、サーバを使って、個々のPDFへのアクセスをきめ細かく制御する方式も様々に提供されています。
まず、最初にPDFでは、セキュリティを(1)どうやって実現しているかということと、(2)何ができるのか、ということについて整理してみましょう。
PDFのファイルには、さまざまなテキスト文字列、イメージ、線画などのコンテンツ情報が入っています。そのコンテンツを整理して、ランダムにアクセスするための構造情報があります。
PDFにセキュリティをかける場合は、一定の暗号化アルゴリズムを使ってPDFを暗号化することになりますが、PDFのファイル全体に暗号をかける訳ではありません。通常は、コンテンツになるデータのみに暗号をかけ、構造情報は暗号化しません。こうすることで、暗号が掛かっているPDFファイルを認識して、暗号を解くことができるようになっています。
PDFファイルは、アプリケーションとは独立に流通していますし、PDFを作成する側がいろいろな暗号化方式を使うことができます。PDFファイル全体に暗号をかけてしまうと、PDFビューアが表示したくても、どんな暗号化方式が使われているかということさえも認識できなくなってしまいますので、これは当然なことです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月05日
「しおり」のすすめ (5) Word からPDFの「しおり」を作る
Microsoft Wordで作成したドキュメントをPDFにするとき、「しおり」を作るには、次の二つの手続きが必要です。
(1) Word文書を作成する際に、スタイル機能を使って適切な「見出し」を設定する必要があります。
(2) 「見出し」を設定したWord文書をPDFに変換する際に、Microsoft Wordの「印刷」メニューではなく、PDF変換ツールのアドインボタンを使います。
・Antenna House PDF Driverの場合、下の図の左のアドインボタン
・Acrobatの場合はPDF Maker(下の図の右)
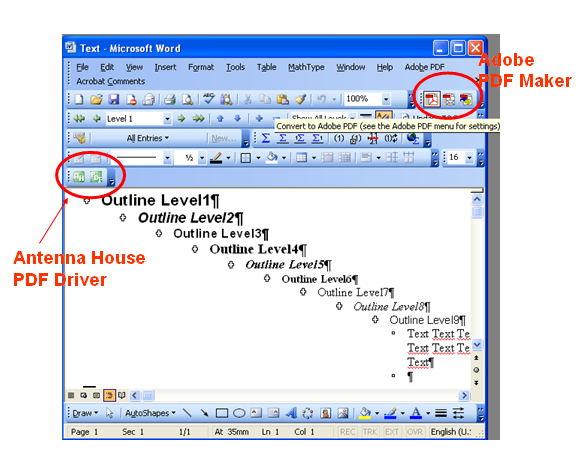
そうしますと、出来上がったPDFには次の図のように「しおり」が付きます。
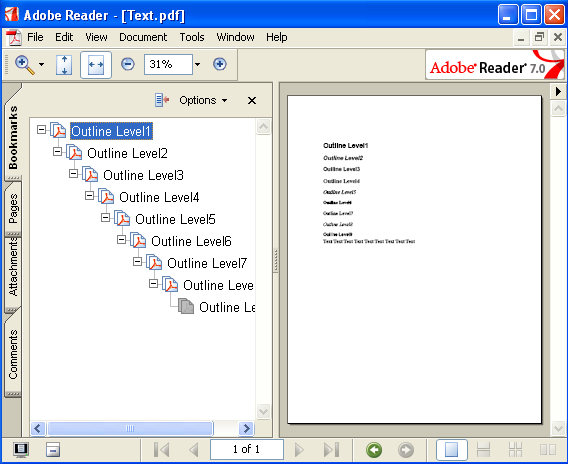
Wordでは、9段階の見出しを付けることができますので、PDFの「しおり」も最大9階層のツリーを作ることができます。
しかし、実際のところ、Wordのスタイルをきちんと使って文書を作る人は少ないでしょうし、アドインボタンを使わねばならないということになりますとやや面倒です。
また、無償で配布されているPDFドライバなどには、アドインボタンのような付属ツールがありません。
このあたりに、一般にWebで配布されているPDFに「しおり」が付いていない原因がありそうです。
ただし、Word2007では、PDFをSaveAsで作成するオプションが用意されるようです(この話、結局どうなったんだろう?)。SaveAsでPDFを作成する際には、「見出し」を「しおり」に変換できます。そうなりますと、来年あたりからPDFの「しおり」普及度がぐっとあがることが期待できそうです。
【注】Wordの「見出し」と「アウトラインレベル」は通常は1対1に対応していますので、本文中では区別しないで使っています。ただし、独立に設定もできるようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月04日
「しおり」のすすめ (4) XSL-FO における「しおり」
ちなみに、XSL-FOの仕様でも、V1.0では「しおり」がありませんでした。このため、XSL-FOの組版ソフトを開発している人たちが、それぞれ、独自にXSL-FOの仕様を拡張して「しおり」機能を独自に実装してしまいました。このためXSL-FO V1.0 ではPDFの「しおり」作成機能は、XSL-FOプロセサ毎の非互換拡張となっています。
今から考えますと、XSL-FOの仕様を作った時にはPDF出力よりも、紙への出力という意図の方が強かったのではないでしょうか。このため恐らく「しおり」ためのFOを忘れてしまったのではないかと思います。
XSL-FO V1.1では、いろいろなXSL-FO組版ソフトの機能を調査したうえで、「しおり」作成のためのFOが標準仕様として盛り込まれました。V1.1対応のXSL-FOプロセサでは、「しおり」作成機能は標準準拠となるわけです。
XSL-FO V1.1では「しおり」を次のように表します。
FOの例:Download file
このFOを組版してPDFにした結果は次のようになります。
このようにXSL-FOでの「しおり」の仕様は簡単です。
(1) PDFに現れる「しおり」ツリーと同じツリーをfo:bookmark-tree以下に作ります。
(2) 「しおり」の一項目をfo:bookmarkで表します。
(3) 「しおり」の見出しの文字列ををfo:bookmark-titleの内容テキストで表し、
(4) 「しおり」をクリックした時に表示する(ジャンプ先)本文をfo:bookmarkのプロパティとしてinternal-destination(外部リンクは、external-destination)で表します。
ですので、fo:bookmark-tree以下のツリー構造は、PDFの「しおり」のツリーそのものとなります。

このようなFOを作るスタイルシートを予め用意しておけば、XSL-FO組版ソフトを使うことで、PDF出力時に自動的に「しおり」が作られることになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月03日
「しおり」のすすめ (3) 「しおり」を付けるタイミングは?
「しおり」は、PDFファイルの中では、次の図のようにドキュメント・アウトラインという情報として管理されています。
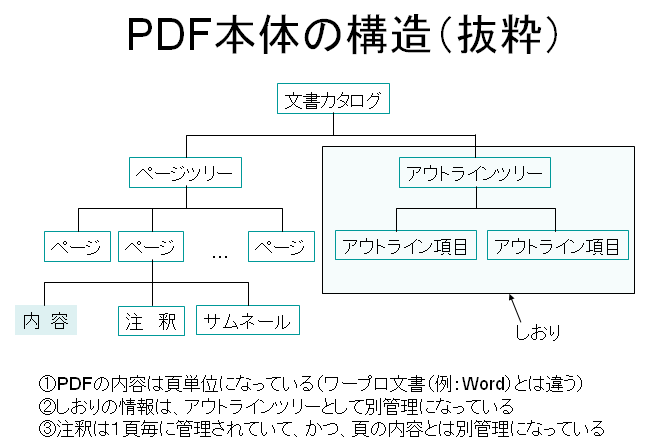
ここで重要なことは、ドキュメント・アウトラインのデータは、PDFの本文ページのデータなど他の情報とは別に管理されていること。PDFに「しおり」を、後から追加したり、また、削除したりしてもPDFの本文ページの表示には何の影響もありません。
ですので、PDFを作成した後で、Webなどで公開するときに「しおり」を付けてナビゲーションし易いようにする、ということも問題なくできます。
しかし、多分、自分で意図的にPDFに「しおり」を付けたことのある人はほとんどいまないと思います。実は、私も、「しおり」の付いたPDFを作ったことは、何度もありますけれども、自分でPDFを編集して「しおり」を付けたことは、製品デモのときぐらいしかありません。
「しおり」をPDFに付ける作業をしたことがある人は、制作会社などで職業的にPDFのコンテンツを作成する人位ではないかと思います。そういう人は、お客さんから受注したPDF作成仕様に「しおり」を付けることという要求項目があって作業しているのでしょう。
多くの場合、PDFに「しおり」を付けるかどうかは、PDFを作成するツール依存になっているものと思います。そして、Microsoft Officeなどの「印刷」メニューからPDFを作成すると、できたPDFには「しおり」が付かないのです。
これが、PDFの「しおり」が便利な機能なのにも係わらず、普及していない理由なのでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月02日
「しおり」のすすめ (2) 米国では?
日本の有価証券の開示資料に「しおり」が付いてないという話をしましたが、これは、日本だけのこと?それとも米国も同じでしょうか?
そこで、NASDAQに開示されている年次資料(Annual Report)でどうなっているか調べてみました。
そうしますと、面白いことに?NASDAQの上場会社25社の開示資料中、「しおり」が付いているのは、3社だけです。この比率はほとんど日本と同じです。どうも、日米を問わず、決算報告書を作る人は、「しおり」に無関心?
米国の場合、面白いのは、PDF作成ツールがかなり分散していることです。Adobeの製品を使って作られたPDFは、25件中6件しかありません。シェアで言いますと3割弱です。
「AFPL Ghostscript 8.5」+「PDFProcessor V1.0」で作っているケースが約半分の12件あります。これは一体なんでしょう?分かりません。
次はQuarkXPressが3件、10-K Wizard Technology, LLCが2件です。10-K Wizard Technologyで作成したPDFは2件とも「しおり」がついています。
ここから考えられることは、決算報告書のPDFを作成する人は「しおり」なんてあまり気にしていなくて、実際のところは、決算報告書を作るのに使っているツール依存になっている、ということですね。
■参考資料
NASDAQのComputers, Technology & Internet業種25社のAnnual Report(Form-10K) ページ数、しおり有無とPDFを作成したアプリケーション
| 社名 | ページ数 | しおり有無 | PDF生成エンジン | アプリケーション |
|---|---|---|---|---|
| ACD SYSTEMS INTERNATIONAL INC. | 28 | N | Acrobat Distiller 7.0 (Windows) | PScript5.dll Version 5.2.2 |
| ATMI | 40 | N | QuarkXPress 6.5 | QuarkXPress 6.5 |
| ACCELR8 TECHNOLOGY CORP | 92 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| ADVANCED MICRO DEVICES INC | 152 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| AFFILIATED COMPUTER SERVICES INC | 132 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| ALLIANCE DATA SYSTEMS CORP | 513 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| APC | 93 | N | Acrobat Distiller 7.0 (Windows) | PScript5.dll Version 5.2.2 |
| ANALOGIC CORP | 85 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| ANSOFT CORP | 51 | Y | PDF Prep Tool (www.blance.ch) | NA |
| APPLIED MATERIALS INC /DE | 119 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| APPLIED MICRO CIRCUITS CORP | 109 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| APPLIX INC /MA/-APLX | 86 | Y | 10-K Wizard Technology, LLC | 10-K Wizard Technology, LLC |
| ARIBA INC | 137 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| AUTODESK | 144 | N | Acrobat Distiller 6.0.1 (Windows) | NA |
| AUTOMATIC DATA PROCESSING INC | 72 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| AVENEX CORP - AVNX | 112 | Y | 10-K Wizard Technology, LLC | 10-K Wizard Technology, LLC |
| Avid Technology, Inc. | 100 | N | QuarkXPress 6.5 | QuarkXPress 6.5 |
| Aixa | 44 | N | Adobe PDF Library 7.0 | Adobe InDesign CS2(4.0) |
| Axon | 64 | N | QuarkXPress 6.5 | QuarkXPress 6.5 |
| BESI | 143 | N | ApogeeX 2.5 Normalizer | Adobe InDesign: pictwpstops filter1.0 |
| Cysco | 74 | N | Adobe PDF Library 7.0 | Adobe InDesign CS2(4.0) |
| Clearspeed Technology | 24 | N | Acrobat Distiller 4.0 for Macintosh | NA |
| COMPUTER TASK GROUP INC | 74 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| CONEXANT SYSTEMS INC | 115 | N | AFPL Ghostscript 8.50 | PDFProcessor V1.0 |
| CORNING INC /NY | 186 | N | AFPL Ghostscript 8.53 | PDFProcessor V1.0 |
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月01日
「しおり」のすすめ (1) しおりとは?
昨日も見ましたように、現在、Webで配布されているPDFには、「しおり」が付いているものが非常に少ないようです。では、「しおり」は無くても問題がないものなのでしょうか?まず、具体的な例を見てみましょう。
次の図は、しおりが付いている「財務諸表PDF」の例です。
これを次のような「しおり」がない「財務諸表PDF」の例と比較しますと、「しおり」があるほうが、遥かに全体像を理解しやすく、また、画面上で内容を閲覧しやすいだろうと思います。
画面の上で、数十ページのボリュームのPDFを読んで内容を把握しようとしますと、「しおり」があれば全体の大筋を瞬時に把握できます。
しかし、もし、「しおり」がないと、最初から最後まで、PDFリーダでずるずるとスクロール、または、ページをめくりながら見ていく必要があります。こういうPDFは、とても内容を把握しずらく、あまり親切とはいえないと思います。
このように「しおり」の重要性は多くの人が認めるものだろうと思います。
それでは、なぜ、現在配布されているPDFには「しおり」が付いているものが少ないのでしょうか?その理由として、次のようなことが考えられます。
1.PDFを作成する人が「しおり」について、まったく、知識を持っていない。
2.「しおり」については知られているが、あまり便利なものとは認識されていない。
3.「しおり」については知っているが、PDFに「しおり」を付けるにはどうしたら良いか知らない。
4.PDFを作成するのに使っているツールに「しおり」作成機能がない。
5.「しおり」を簡単につけるツールが普及していないため、「しおり」を付けたいが、手間が掛かることから敬遠されている。
次回は、もう少し、「しおり」が普及していない理由について考えてみたいと思います。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年10月26日
PDFを画像や音声のコンテナとして使う!?
今日の日経産業新聞にアドビのCEOブルース・チゼン(Bruce Chizen)氏のインタビューが掲載されています。この後ろの方に、次のような発言があります。
記者「文書画像関連ソフトだけでは成長に限界があるのでは。」
BC「...画像や音声など、様々な情報を包み込むコンテナのような役割を未来のPDFとフラッシュは果たすだろう」
アドビは、マクロメディアを買収して以来、フラッシュとPDFの統合を図っています。このことは、何回かこのブログでも触れています。
・Macromedia吸収後のアドビ、次のステップ
・PDFとFlashの統合?
この統合がどういう形になるか、最終的な形は見ていませんが、もし、PDFのフレームの中に音声や動画を埋め込むということであれば、それはかなり無理があるように感じます。
もう少し補足しますと;
PDFはページの概念をもつ紙を電子化したものです。もともと紙であった情報、または紙への印刷を目的としたものをPDF化するというのは適切なように思いますが、紙を前提としない情報をPDFに入れるのは不自然だと思います。
Acrobat Readerを使ってPDFをPCのWindowに表示して画面上で読む行為、Windowに入りきらない部分をスクロールしたり、ズームアップ・ズームダウンしながら読む行為は、どうも不自然ではないか、無理なところがあるのではないかと感じます。
それはなぜかと考えますと、PCのディスプレイは横長の大きさをもつのが普通ですが、紙は通常は縦長の大きさをもちます、紙に比例する領域の大きさをもつPDFを横長のディスプレイに表示する行為には無理、無駄があります。
最近のPDFにはタグ付きPDF、リフロー機能などの機能が追加されていて、Windowのサイズに合わせて表示することもできるようですが、しかし、PDFはもともと紙への印刷を前提として開発された技術の延長上にできたものです。従って、コンピュータのディスプレイや、その上のWindowにフィットさせることを目的とするとき、PDFファイルの内の情報の持ち方は不向きです。
一足飛びに結論を言いますと、まず、PDFとブラウザを融合した新しい情報の表示手段の必要性があるということ。そして、音声や動画などは、基本的にコンピュータ技術を前提としますので、紙よりもコンピュータのディスプレイに親和性が高いはずです。親和性の低い紙=PDFに音声や動画を統合する、というのは技術として筋が悪いのではないか、と思うのです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月11日
フォントを埋め込まないPDFの表示(6)
さて、昨日は、CJKコンポーネント(「alf_jpn.exe」)をインストールすることで日本語フォントを埋め込まないPDFも、表示できるようになることを説明しました。
では、どのような仕組みでこれが可能になっているのでしょうか?
そこで、CJKコンポーネントをインストールすると、追加されるものと調べてみますと、次の3つのようです。
・Program Files\Adobe\Acrobat 7.0\Readerフォルダの
agldt28l_cjk.dllファイル (約1MB)
・Program Files\Adobe\Acrobat 7.0\ResourceフォルダにCIDFontというフォルダができ、中に次のフォントがインストールされます。
KozGoPro-Medium.otf (約3MB)
KozMinProVI-Regular.otf (約6MB)
・Program Files\Adobe\Acrobat 7.0\Resource\CMapフォルダは、インストール前は、Identity-HとIdentity-Vだけでしたが、CJKフォントをインストールしますと、Adobe-Japan1-H-CID以下、94個のCMapテーブルが追加になります。
この中で、agldt28l_cjk.dllファイルの役割は分かりません(このファイルを削除しても、日本語フォントは表示できます)。
また、日本語フォントファイルとして、MS明朝や、平成丸ゴシックが追加されるわけではありませんので、CJKコンポーネントをインストールすることによって表示されるフォントはWindowsのシステムに、あらかじめ存在していたものなのでしょう。
恐らく、日本語フォントを指定した文字がフォントを埋め込まないと表示できない理由のひとつは、CMapテーブルがなかったためだろうと思います。ですがそれだけではありません。CMapテーブルを残しておいて、KozGoPro-Medium.otf、KozMinProVI-Regular.otfを削除してしまうと、再び、フォントを埋め込んでない日本語の文字が表示できなくなってしまいます。
なぜ、KozGoPro-Medium.otf、KozMinProVI-Regular.otfを削除してしまうと、MS明朝や平成丸ゴシックが表示できなくなるのでしょうか?関係なさそうに思えるのですが、これは謎ですね。
それから、英語について、フォントを埋め込まないとArabicTypesettingが正しく表示できないというのは、CJKコンポーネントをインストールしても変化ありません。次の図をご覧ください。上はWordでArabicTypesettingを指定したラテンアルファベット文字、下はフォントを埋め込まずに作成したPDFをAdobe Readerで表示したもの。
フォントを埋め込まないで作成したPDFについて、Adobe Readerの表示方法にはいろいろと謎がありますが、少なくともWindowsのシステムにあるフォントを素直に使っていないのは確かなようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月10日
フォントを埋め込まないPDFの表示(5)
Adobe Reader英語版では、フォントを埋め込んでいない日本語・中国語の文字を正しく表示できないことについては、2006年09月14日
フォントを埋め込まないPDFの表示(3)、2006年09月25日フォントを埋め込まないPDFの表示(4)で説明しました。
これについて、もう少し続けて検討してみたいと思います。
まず、日本語について、いままでMS明朝とMSゴシックだけで検討してきましたので、他のフォントでも同じことが起きるかを確認してみます。そのひとつの例として、「平成丸ゴシック」で試してみました。
上の図は、「平成丸ゴシック」を指定した日本語文字を含む文書をPDFにして、Adobe Reader英語版で表示したものです。上がフォントを埋め込まない場合、下がフォントを埋め込んだ場合です。「平成丸ゴシック」も「MS明朝」「MSゴシック」と同じ結果になっていることが分かります。
Windowsにはこのフォント(平成丸ゴシック)がインストールされていますので、Windowsのシステムフォントを使うと、フォントが埋め込まれていなくても文字を表示できます。ちなみに、アンテナハウスのPDF Viewer SDKではフォントが埋め込まれていなくても「平成丸ゴシック」を指定した文字が表示されます。
さて、アドビのホームページのサポートデータベースには、日中韓フォントが埋め込まれていない PDF の表示方法(文書番号223007)という文書があり、Adobe Reader 6.0/7.0 で、日中韓フォントが埋め込まれていない PDF ファイルを正常に表示するには必要なコンポーネントをダウンロードするようにという説明があります。
このコンポーネントは、「alf_jpn.exe」というプログラムです。これをダウンロードしてインストールしますと、確かに、「平成丸ゴシック」フォントを埋め込んでいないPDFも正しく表示できます。次の図のように確かに、平成丸ゴシックStd-W8フォントで表示しています。
これで、一件落着か?と言いますと、実はそうじゃなく、ますます疑問が深まってしまうのです。次のような疑問です。
・今まで、「平成丸ゴシック」フォントを指定した文字が表示できなかったのに、alf_jpn.exeをインストールすると、なぜ、表示できるようになったのか?
・AdobeReaderが表示に使っている「平成丸ゴシック」フォントは、Windowsのシステムのフォントなのか?それとも、追加でインストールしたalf_jpn.exeに入っていたのだろうか?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月25日
フォントを埋め込まないPDFの表示(4)
10日程前、「フォントを埋め込まないPDFの表示」というテーマで、一般のWindowsアプリケーションからMS明朝、MSゴシックが使える状態になっているにも関わらず、PDFの中のMS明朝、MSゴシックを指定した文字がAdobe Readerで表示できないのは、常識的に判断して不具合である、と言いましたが、どうも気になります。Adobe Readerのフォント選択について、もう少し、調べてみましょう。
まず、PDF Reference ではどのように書いているでしょうか?探してみました。
5.4 Introduction to Font Data Structuresでは、「A font is represented in PDF as a dictionary specifying the type of font, its PostScript name, its encoding, and information that can be used to provide a substitute when the font program is not available.」(PDFにおいて、フォントは、PostScript名、符号化方式、フォント・プログラムが利用できないとき代わりを供給するために使われる情報を指定した辞書として表現される)となっています。
次に、
5.7 Font Descriptorsでは、「A font descriptor specifies metrics and other attributes of a simple font or aCIDFont as a whole, as distinct from the metrics of individual glyphs. These font metrics provide information that enables a consumer application to synthesize a substitute font or select a similar font when the font program is unavailable. (...略 これらのフォント・メトリクス情報は、コンシューマ・アプリケーションが、フォント・プログラムを入手できないとき、代わりのフォントを合成したり、類似のフォントを選択するための情報を提供する)とあります。
この2箇所から、コンシューマ・アプリケーションは、システムにフォントが存在するときにはシステムのフォントを使い、存在しないときに、フォント・メトリクス情報を使って代わりのフォントを選択するものと考えることができるように思います。
Adobe Reader(英語版)は、MS明朝を指定した日本語文字については、Windowsシステムにフォントがあっても表示できないことは、既に確認しています。では、日本語以外はどうなるか、を少し調べてみました。
1.中国語
中国語簡体字にSimSunフォントを指定して、フォントを埋め込まずにPDFを作成してみました。右がWordのオリジナル画面、左が、フォントを埋め込まずに作成したPDFのAdobe Reader英語版で表示したもの。これを見ますと、中国語も同じように表示することができないことがわかります。
2.アラビア語
アラビア語(アラビア文字)の場合はどうなるでしょうか?試してみましたが、アラビア文字は、PDFを作成するときAcrobatにフォントを埋め込まないを指定してもフォントを強制的に埋め込んでしまいます。これは、アラビア文字は、フォントを埋め込まないPDFには意味がない(正確には、アラビア文字は、PDFのテキスト表示の仕様では、フォントを埋め込まない限り正しく表示できないため)と考えられますので、やむを得ないことだろうと思います。
■フォント・プロパティ
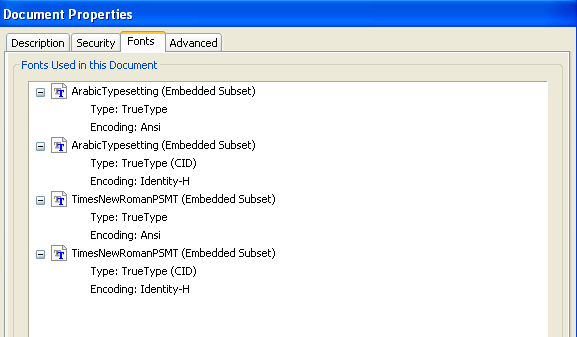
3.ラテン文字
前の例では、フォントを埋め込まないと指定しても、アラビア文字が入っていると、ラテン文字についてもフォントが埋め込まれてしまっています。そこで、ラテン文字だけならどうなるかを調べてみました。
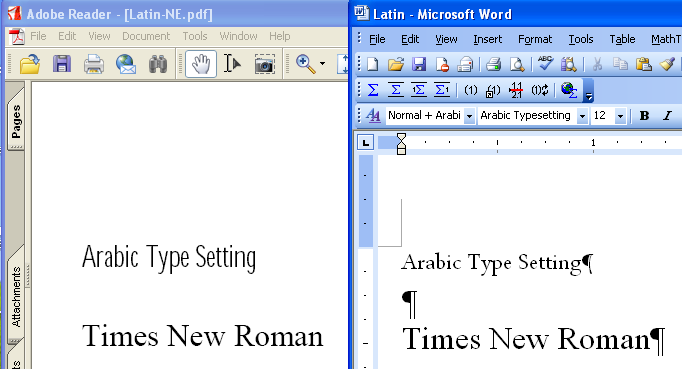
■フォント・プロパティ
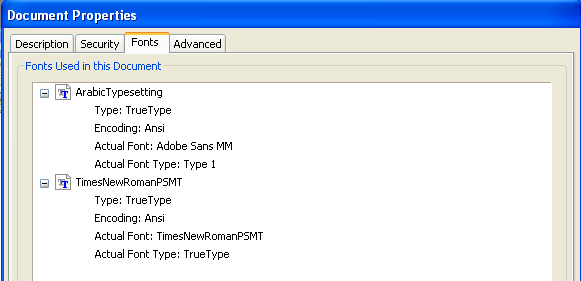
ラテン文字だけだと、フォントが埋め込まれない。Arabic Type Settingを指定した部分がAdobe Sans MM フォントに置換されて表示されていることがわかります。
このような結果を見ますと、Adobe Readerのフォントの選択では、Windows環境にどのようなフォントがあるかをチェックして適切なフォントを選択することを行っていないようです。
また、フォントを埋め込まずにPDFを作成すると、Arabic Type Settingのような特殊なメトリックスをもつフォントが、まったく異なるメトリックスのフォントに置き換えられています。
Adobe Readerのフォント選択の実装はPDF Referenceの仕様の指定するところから少しずれていると言えそうです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月14日
フォントを埋め込まないPDFの表示(3)
さて、「フォントを埋め込まないPDFの表示」についていろいろ実験をしているあいだに、気が付いた問題点がありますので、次にまとめて見ます。
日本語のMS明朝、MSゴシックを使った文書をPDFにする時、フォントを埋め込む指定をしないと、Adobe Readerの英語版(初期状態)ではまったく表示できません。(WindowsにMS明朝、MSゴシックがインストールされていても、不可。)
これは、Adobe Acrobatで作成したPDFでも起きますし(下の図)、Antenna House PDF Driverでも同じようになりますので、PDF作成ソフトの側の問題ではなくAdobe Reader英語版の問題なのだろうと思います。
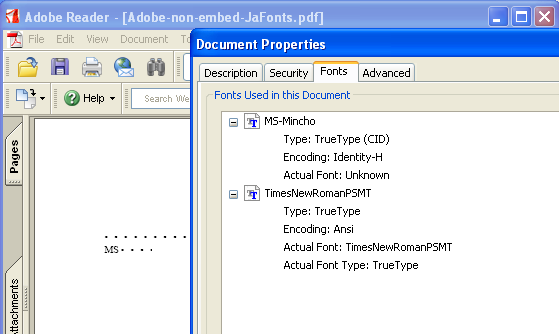
※WindowsXPを英語モードで起動中
この文書の元のWordファイルを、Wordで開きますと、次のようになります。
※WindowsXPを英語モードで起動中。Word2003英語版。
つまりWindowsアプリケーションでは正しく表示できるのに、Adobe Readerでは表示できないのです。
ちなみに、Antenna House PDF Viewerでもちゃんと表示できます。
※WindowsXPを英語モードで起動中。
Antenna House PDF Viewer SDK V1.2 で、Adobe Readerと同じPDFを表示。
一方、Wordでラテンアルファベットだけ(TimesNewRomanフォントを指定)の文書を作成し、フォントを埋め込まないでPDF化したものは、Adobe Readerで問題なく表示できます。
以上のことをまとめて考えて見ますと、一般のWindowsアプリケーションからMS明朝、MSゴシックが使える状態になっているにも関わらず、PDFの中のMS明朝、MSゴシックを指定した文字がAdobe Readerで表示できないのは、常識的に判断して不具合である、と言っても良いだろうと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月12日
フォントを埋め込まないPDFの表示について (2)
MS明朝とMSゴシックを指定し、フォントを埋め込まないPDFを表示しようとすると、Acrobat Readerをインストールしたフォルダの下のリソースに、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルがないと、日本語の文字が「・・・」になってしまうという問題に嵌っています。
昨日、英語版のAdobe Reader をアンインストールし、その後、日本語版のAdobe Readerをインストールしてみました。さらに、日本語版のAdobe Readerをアンインストールし、もう一度、最初に戻って英語版のAdobe Readerをイントールしました。
そうして、問題のJALのPDFを表示しようとしたところ、今度は、次の図のように真っ白になって文字がまったく見えない状態になってしまいました。
Adobe Reader をインストールしたフォルダの下のResourceフォルダの内容をチェックしてみますと、次の図のようになっています。KozMinProVI-Regular、KozGoPro-MediumはCIDfontというフォルダの中に保存されているのですが、CIDfontフォルダそのものがなくなっています。
英語版のAdobe Readerをインストールした直後の状態では、フォントを埋め込んでない日本語文字の入ったPDFはまったく表示できません。(フォントを埋め込んだPDFは、日本語も問題なく表示できます)。
ここでひとつ気になりますのは、WindowsXPのロケールが英語の状態では、このままの状態から改善されないようだということです。
そこで、WindowsXPのロケールを日本語に切り替え、同じJALのPDFを表示しますと、今度は次のように、Adobe Readerをアップデートします。
先ほどのResourceフォルダをチェックしますと、CIDfontというフォルダができていることが分かります。
このCIDfontフォルダには、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルが収容されています。そうして今度は、フォントを埋め込んでないPDFも無事表示できます。
Adobe Reader がこの文書(日本語の文字)の表示に使用しているフォントはMSゴシックです。
つまり、Adobe ReaderのインストールフォルダのResourceの下のCIDfontフォルダとその内容がないと、フォントを埋め込んでない日本語が入ったPDFはまったく表示できないが、CIDfontフォルダができてKozMinProVI-Regular、KozGoPro-Mediumがあると日本語が入ったPDFが表示できるようになるということです。この時、表示用フォントはMSゴシックを使っているようです。MSゴシックとKozGoPro-Mediumとは一体どんな関係なのでしょう。不思議ですね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月11日
フォントを埋め込まないPDFの表示について
1昨日と昨日、MS明朝とMSゴシックを指定し、フォントを埋め込まないPDFを表示しようとすると、Acrobat Readerをインストールしたフォルダの下のリソースに、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルがないと、日本語の文字が「・・・」になってしまうということを説明しました。
この記事を読んで、次のような疑問をもたれた方もいると思います。
「PDFって、フォントを埋め込まなくても、表示するシステムに同じフォントがあれば、システムのフォントで表示するんじゃない?」
その通りですね。ここで紹介しました二つのファイルは、いずれも日本語はMS明朝またはMSゴシックを指定しています。そこで、表示したいWindowsにMS明朝とMSゴシックがあれば、KozMinProVI-Regular、KozGoPro-Mediumの有無に関わらず問題なく表示できるはずだろうと思います。
私が実験につかったPCには、無論、MS明朝とMSゴシックがインストールされていますので、PDFにフォントが埋め込まれていなくても、当該の二つのPDFは正しく表示できないとおかしいと思います。
なぜ、KozMinProVI-Regular、KozGoPro-Mediumがないと正しく表示できないのでしょう?
この原因として、考えられることは、次のようなことがあります。
(1) 英語版のAdobe Readerだから。
(2) 英語版のWindowsを日本語のロケールで使っているため?
(3) PDFファイルのフォント指定の方法が不正ではないのだろうか?
(1)を試してみるために、まず、英語版のAdobe Readerをアンインストールして、日本語版のAdobe Reader7.0.8をインストールし、JALのPDFファイルを表示してみました。それでも現象はかわりません。
ひとつだけ違い気が付きました。日本語版のAdobe Readerのままで、Windowsのロケールを英語に変更したときです。日本語版のAdobe Readerは、メニューが英語に切り替わり、英語版OS上でも使えます。この時、JALのPDFの場合、日本語をMSゴシックで表示しています。次の図を参照。

ちなみに、英語版のAdobe Readerは、同じPDFの日本語をKozGoPro-Mediumで表示するようです。

このふたつの画像は、文字の形は良く似ていますが、「こ」「は」という二つの文字に注目しますと、違いが分かります。
次に(2)について見るため、日本語WindowsXPに日本語版のAdobe Reader7.0.8をインストールし、JALのPDFファイルを表示してみました。それでも現象はかわりません。Adobe Reader のインストールフォルダの下のリソースのKozMinProVI-Regular、KozGoPro-Mediumを削除すると、フォントを埋め込んでないPDFは、システムにMSゴシックがあっても表示できません。
もしや、符号化方式の問題かと考えて、Unicode文書をPDF化してみても同じです。
次に(3)を確認するため、Microsoft Wordを使って、日本語にMS明朝、MSゴシックを指定した文書をつくり、AdobeのAcrobat、Antenna House PDF Driver で、フォント埋め込みをしないPDFを作成しました。それでも同じで、Adobe Reader のインストールフォルダの下のリソースのKozMinProVI-Regular、KozGoPro-Mediumを削除すると、フォントを埋め込んでないPDFは、システムにMSゴシックがあっても表示できません。
結局、この現象はAdobe Readerのバグじゃないかという判断に傾いているのですが。どうでしょうか。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月10日
PDFのフォント埋め込み
昨日、Webから購入した航空券のJALの「e-チケットお客様控え」(PDF)に、フォントが埋め込まれていないので、閲覧時にAdobeReaderが別のフォントに置き換えて表示しているというお話をしました。
そういえば、半年ほど前に、確定申告を下記のWebページから入力して作成しました。
確定申告書等作成コーナー
ここで、数字を入力し終えると、PDFにして返送してくれます。もう自分で電卓たたいて確定申告を作成する必要がありません。大変便利なのですが、このWebでサーバから返送してきたPDFにもフォントが埋め込まれていませんでした。
確定申告PDFをAdobe Reader(7英語版)で表示してPDFのプロパティ-フォントをチェックしますと、MS明朝とMSゴシックを使っているように見えています。しかし、Adobe Readerのインストール・フォルダの下のリソースにある、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルを削除すると、下の図のように文字が・・になってしまいます。
Adobe Readerの下にインストールされているKozMinProVI-Regular、KozGoPro-Mediumがないと、文字が正しく表示できません。Adobe Readerは、MS明朝とMSゴシックをKozMinProVI-Regular、KozGoPro-Mediumをつかって表示している?
これは、もしかすると英語のAdobe Readerだからかもしれません??
環境によってフォントが置換されて表示されてしまう可能性があるのは危険と思います。イントラネットならともかく、WebでPDFを配布するときはフォントを埋め込むべきではないでしょうか。
これに関連して、最近のQ&Aをご紹介しておきます。
<質問>
PDFへの出力におきまして「帳票の印字をMS明朝の太字で統一したい」という要求がありますが、私の認識では「対応するためには、市販のフォントを購入し、PDFの表示を行なうPC上にインストールする必要がある」と考えていますが、何か対応策は、あるのでしょうか?
<回答>
PDF作成時にフォントを埋め込むことで、PDFを表示する環境にフォントは不要となります。
但し、前提条件があります。
(1)PDF作成ソフトが、フォント埋め込み機能を実装していること。
(2)PDF表示ソフトが、埋め込んだフォントを使って表示する機能を実装していること。
<質問>
フォント埋め込みをおこなった場合は、対象フォント全体がPDFファイルに埋め込まれることになり、ファイルサイズがかなり大きくなりますか?そのPDFで使用しているフォントだけが埋め込まれるということでは無いですね?
<回答>
フォント埋め込みは、ソフトによって実装方法は違うと思いますが、アンテナハウス製品の場合は、欧文フォントは文書の中で使用しているフォントの全文字を埋め込みます。
和文フォントの場合は、文書中で使用しているフォントの中で、さらに使用している文字のグリフアウトラインデータのみをPDFに埋め込みます。(サブセット埋め込み)
従いまして、PDFファイルは、それほど大きくはなりません。なお、他社の製品でフォントをどのように埋め込んでいるかは、その会社にご確認いただく必要があります。
情報システムで作成したPDFが流通するようになるにつれ、IT技術者がPDFについて学習する必要が出てきたということなのでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月09日
Adobe Readerのフォント置換への疑問
最近、新しいPDFを見かけるたびに、プロパティをチェックするのが癖になってしまってます。
今日、JALで航空券を予約してクレジットで支払いましたところ、電子領収書がPDFで送られてきました。早速、開いてプロパティをチェックしたところ、PDFにフォントが埋め込まれていません。
○PDFファイルを表示したところ View image
○このPDFのフォント・プロパティ View image
このプロパティを見ますと、日本語はMSゴシックで表示している、とされています。
この状態は、WindowsXP英語版で地域と言語のオプション(ロケール)が日本語になっています。じゃあ、地域と言語のオプションを英語にしたらどうなるか、と思って試してみました。
WindowsXP英語版のロケールを英語にして同じPDFを表示すると次のようになります。
○PDFファイルを表示したところ View image
○このPDFのフォント・プロパティ View image
これでわかることは、Windowsのロケールを英語にするとKozGoPro-Mediumで表示しているということです。
そこで、今度は、Adobe Readerのインストール・フォルダの下のリソースにある、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルを削除しました。そうすると次のようになります。
まず、Windowsのロケールを日本語にしたとき:
○PDFファイルを表示したところ View image
○このPDFのフォント・プロパティ View image
なぜか、Adobe Readerは、このシステムではKozMinProVI-Regular、KozGoPro-Mediumフォントがないと日本語を表示できないようです。
次に、Windowsのロケールを英語にした状態で、Adobe Readerのインストール・フォルダの下のリソースにある、KozMinProVI-Regular、KozGoPro-Mediumという二つのフォント・ファイルを削除しました。そうすると次のようになります。
○PDFファイルを表示したところ View image
○このPDFのフォント・プロパティ View image
結論として次のことが言えそうです。
日本語にMSゴシックを指定して、フォントを埋め込まずに作成したPDFを表示する際、Windowsのロケールが日本語の時は、MSゴシックで表示するが、Windowsのロケールが英語の時は、KozGoPro-Mediumフォントで表示する。
しかし、なぜかAdobe Readerは、Windowsのロケールが日本語にせよ、英語にせよ、自分のインストール・フォルダにKozGoPro-Mediumフォントがないと表示できない。
ここで使用したのは、Adobe Reader 7.0.8 英語版です。どうも奇妙な動作です。
いづれにせよ、WebでPDFを配布するときは、フォントを埋め込むべきではないでしょうか。そうしないと、PDFを表示する環境によって文字がどう表示されるか、予測が付かないケースが出てくると思います。
※9月9日の記事に、事実誤認がありましたので、9月11日に本文を修正しました。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年08月29日
PDFで使う圧縮方法
今日、営業で訪問した先で、PDFで使える圧縮についての話題がありました。以前に、一度、PDF/Xの時にもまとめましたが、もう一度、営業のQ&Aも兼ねて、整理しておきます。
PDF Reference 1.6版 2.2 Compression
PDFで使える圧縮には次のものがあります。
(1)カラー、グレースケール・イメージ
・JPEG
・JPEG2000 (PDF 1.5~)
(2)モノクロ・イメージ
・CCITT G3,G4
・ランレングス
・JBIG2 (PDF 1.4~)
(3) テキスト、グラフィックス、イメージ
・LZW
・Flate (PDF 1.2~)
以上が標準で使えるデータ圧縮方法です。
もうひとつ注意するべきこととして、圧縮の対象とする単位のことがあります。
PDFで圧縮対象となるのは、PDFを構成する細かいコンポーネント(オブジェクトなど)の中のデータ部分(ストリーム)です。PDFはオブジェクト毎のストリーム単位で圧縮されているのであって、PDFファイルを一括して大きな単位で圧縮しているわけではないのです。
ところが、PDF1.5から複数のオブジェクトをまとめて、ひとつのオブジェクトとし、複数のストリームをまとめてから圧縮することができるようになりました。Object Stream, Cross Reference Streamというものです。これによって、圧縮の効率が高まりました。
従って、圧縮に対応するかどうかは、各圧縮アルゴリズム用のフィルターをもつかどうか、ということと、Object Stream, Cross Reference Streamに対応するかどうかの2つの観点で考えなければなりません。
ちなみに、Antenna House PDF Driver V3.0 の圧縮機能は次の図のようになっています。
・テキストとラインアートの圧縮はFlate(ZIP)圧縮です。LZWは使っていません。これは過去にUNISYS特許問題という歴史的な問題があったため。
・画像についてはJBIG2以外の圧縮をすべて使用しています。使用可能なものから画像のタイプにより選択します。
・Object Stream, Cross Reference Streamについては、PDF1.5以上の時に表示される「オブジェクトレベルの圧縮を行う」をONにすると使用します。
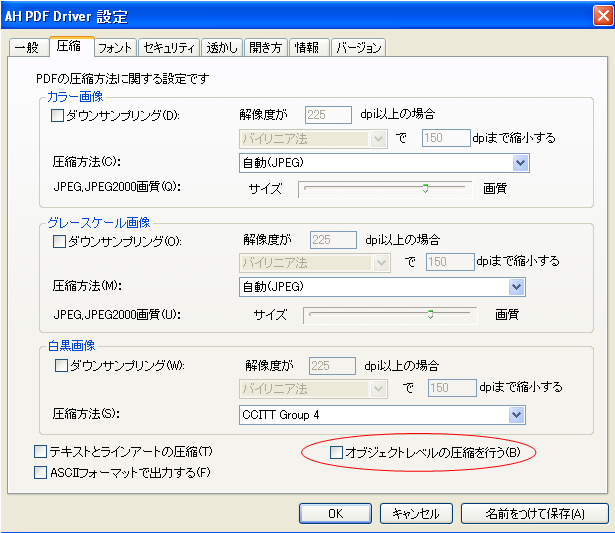
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月21日
PDF/X シリーズまとめ
ISO 15930 (PDF/X) ファミリーの仕様書は、現在6冊あります。その概要をこれまで順次紹介してきました。
最後に簡単にまとめてみます。仕様の準拠レベルを大きく分けると、次の図のようになります。
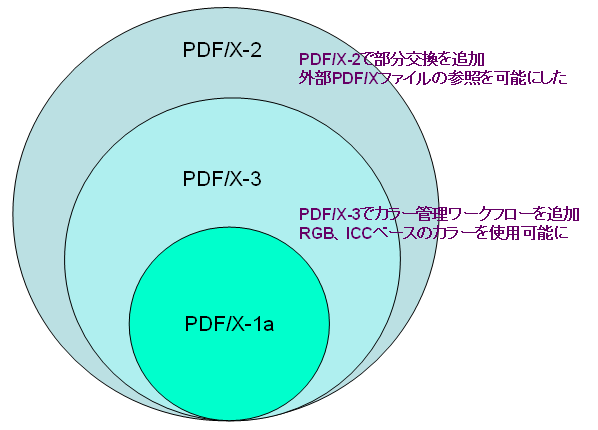
PDF/X-1aが基本で、これはPDFで使える機能に対して、主に次のような制限をつけたものです。
・すべての印刷用の複合実体をPDFファイル中に含むこと。
・カラーはCMYK、グレースケール、セパレーションカラー(特色)とそれをベースとするインデックスカラーなどに制限する
・出力インテントを使ってカラー印刷特性を設定する
・フォントは埋め込むこと
・データ圧縮はLZW、JBIG2を禁止
・ハーフトーンの制限
・PostScriptのプログラム埋め込み禁止
・暗号化禁止
・透明(PDF1.4)の使用禁止
これに対して、PDF/X-3では、RGB、ICCベースカラーの使用を可能にし、カラー管理ワークフローを実現できるようにしています。
さらに、PDF/X-2では外部のPDF/Xファイルを参照することができ、何回かに分けてPDF/Xファイル交換する部分交換が可能となります。
PDF/Xファイルを作成するソフトは、このような制限を満たすPDFを作りだせれば、PDF/X仕様準拠となりますが、PDF/Xファイルを読んで処理するプログラムは、すべての機能を正しく処理できなければなりません。従って、PDF/X-2準拠のリーダを作るのが最も大変ということになります。
※詳しくはこちらをご覧ください。
PDF/Xについて (1) PDF/X-1a
PDF/Xについて (2) PDF/X-3
PDF/Xについて (3) PDF/X-2
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月19日
PDF/X-2について(5)
5.ファイル指定
前項で述べたReference XObject以外の方法により、PDF Reference 3.10項に定めるファイル指定機能を使うことは禁止です。
6.トラッピング
ファイルを交換するにあたり、info辞書のTrappedキーを使わなければなりません。Trappedキーでは、PDF/X-2ファイルそれ自身のトラッピング状態を示しますが、参照されるファイルや、PDF/X-2ファイルと参照されるファイル間の組合せにの間でのトラッピング状態を示すことはありません。
もし、PDF/X-2ファイルの中のすべての印刷要素についてトラッピングされているなら、Trappedキーの値はTrueになります。それ以外のケースでは、キーの値はfalseです。部分的にトラッピングされたファイルは許可されません。PDF/X-2ではTrappedキーの値にunknownは許されません。
Trappnet注釈を含むなら、Trappedキーの値はTrueでなければなりません。
FontFauxingキーの値についての条件は、PDF/X-1aと同じです。また、PCMキーの値の条件は、PDF/X-3と同じです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月18日
PDF/X-2について(4)
外部PDFを参照する元になる側のForm XObject(Reference XObjectのためのRefキーをもつもの)にも同じようにMetadataキーをもつ必要があります。
このMetadataキーの値となるメタデータ・ストリームには、XMPのxapMM:RenditionOf属性を含む必要があり、その値は、ResourceRef要素となります。また、xapMM:DocumentID、xapMM:VersionID、xapMM:RenditionClass属性を含まねばなリません。
xapMM:DocumentIDは、UUIDのような128ビット数のIDとし、ユニークになるように生成するべきです。
難しいですが、参照元のPDFのFormXObjectと、ターゲットのPDFをXMPのメタデータを使って対応関係を付けて、ターゲットを識別するということでしょう。
(3)ターゲットPDFの選択
PDF/X-2の仕様では、PDF/X-2のリーダが候補となるターゲットPDFを探す方法の機構までは定めていません。
但し、PDF/X-2のファイルは、OSや言語に依存しないように作るべきであり、PDF Referenceの仕様で言われている過搬性を満たすように注意するべき、とされています。
一旦、ターゲット候補となるPDFを認識できたならば、PDFの内部のオブジェクトのIDと、参照元とターゲットのメタデータを比較して、ターゲットを識別することができます。
(4)外部文書の描画
PDF/X-2のすべての内容は、同じ印刷特性設定になるように準備されねばなりません。
また、すべてのターゲット文書にある外部データを使って描画する必要があり、ターゲット文書が欠落した状態で描画してはなりません。
また、ひとつのPDFを描画する時は、そのPDFに埋め込まれたフォントを使用しなければならず、他のPDFに埋め込まれたフォントを使用してはなりません。
ターゲット文書を含むPDFとそれに含まれるPDF間のオーバ・プリンティングは、PDF Referenceの定義に従って行います。
Form XObject のBBエントリの座標は、ターゲットPDFのメディアボックスの左下隅に対して相対とします。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月17日
PDF/X-2について(3)
4.外部参照要素
(1) 仕組み
PDF/X-2のファイルでは、印刷要素を省略することができます。この場合、省略した印刷要素については、Form XObjectの機能を使って代理データを含めておく必要があります。代理データはプレビュー画像などでも問題ありません。
代理データは、Reference XObjectの機構を使って、要素を置換するための対象データを指し示さねばなりません。この参照辞書にはIDを含めなければなりません。
PDF ReferenceのXObjectというのは、一塊の完結したグラフィックス・オブジェクトのことを言います。これは、Image XObject、Form XObject、PostScript XObjectの3種類が代表的なものでしたが、PDF 1.4からReference XObject、Group XObjectが追加されています。
このReference XObjectの機構を使うとあるPDFファイルの中に、別のPDFの内容を持ち込むことができます。PDF/X-2ではこの機構を使って別のPDFファイル(ターゲットPDF)を参照することで、部分交換を可能とします。
Reference XObjectのターゲットPDFは、PDF/X-1a:2001、PDF/X-1a;2003、PDF/X-3:2002、PDF/X-3:2003またはPDF/X-2:2003のいづれかでなければなりません。
Form XObject、Image XObjectのOPIキーを使うことはできません。
(2) ターゲット文書の識別
ターゲットPDFのCatalog辞書にはMetadataキーがなければなりません。メタデータを構成するデータは、XMP準拠になっていることが必要で、xapMM:DocumentID, xapMM:VersionID, xapMMRenditionClassプロパティを含まねばなりません。多くの場合、 xapMMRenditionClassの値は、defaultとなります。
※XMPについては、こちらを参照してください。
XMP™ (Extensible Metadata Platform)仕様についてのメモ
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月16日
PDF/X-2について(2)
1.PDF/X-3との関係
PDF/X-2の仕様は、PDF/X-3:2003の仕様のほぼすべての制約を満たさねばなりません。
PDF/X-3:2003については、次を参照してください。
PDF/Xについて (2) PDF/X-3
上のWebページで説明しているPDF/X-3:2003についての制約の中で、PDF/X-2に適用されないのは、次の4項目です。
1.PDF/X-3 ファイル構造
4.ファイル指定
6. トラッピング
7. PDF/X-3ファイルの識別
PDF/X-3が完全交換を目的としていて、一回のPDFファイル交換ですべての情報を交換しなければならないのに対し、PDF/X-2は部分交換を目的とするため、複数回に分けて情報交換を行うことを認めていることから、制約条件が変わっていることになります。
次にPDF/X-3と異なる箇所のみ説明します。
2.PDF/X-2ファイル構造
PDF/X-2では、複合実体のすべての要素がひとつのPDF/X-2ファイルに含まれているか、それとも、後述の外部参照要素の規定に準拠して識別できなければなりません。
※この下線を引いた部分が、PDF/X-3と異なる部分です。
3.PDF/X-2のファイル識別
Info辞書のGTS_PDFXVersionキーの値を(PDF/X-2:2003)とします。
Info辞書のその他のキーの使い方はPDF/X-3と同様です。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月15日
PDF/X-2について
さて、しばらく間が空いてしまいましたが、PDF/Xシリーズの最後に、PDF/X-2について調べてみたいと思います。
PDF/X-2は、PDF 1.4を用いた印刷データの部分交換という副題がついていて、次の仕様書で規定されています。
ISO 15930-5:2003
Part 5: Partial exchange of printing data using PDF 1.4 (PDF/X-2)
準拠ファイルとツール
PDF/X-2に準拠しているかどうかの判断は、PDFファイルのバージョン番号でするのではなく、PDFファイルに含まれている印刷用の複合実体の交換に必要な特徴がISO 15930-5:2003の仕様書に沿っているかどうかで判断しなければなりません。なお、印刷用複合実体の再現には関係ない情報が含まれていても差し支えありません。
PDF/X-2準拠のライター(作成ソフト)は、PDF/X-2のファイルを生成することができれば良いのですが、PDF/X-2準拠のリーダ(読むソフト)はPDF/X-2だけではなく、PDF/X-1a:2001、PDF/X-1a:2003、PDF/X-3:2002、PDF/X-3:2003のすべてを適切に処理できなければなりません。
従って、PDF/X-2が、PDF/Xシリーズの最上位規格ということができると思います。
部分交換
PDF/X-2は部分交換という副題がついています。部分交換とは、一部の印刷要素、または要素の資源を、交換から意図的に除外しておき、別途入手可能とする方式です。データ交換で除外された要素をユニークに識別するための情報を提供することができるようになっています。
PDF/X-2の仕様は、部分交換を可能にすることで、他の仕様を補完するものとされています。
※用語については
2006年07月10日 PDF/X-1, PDF/X-1a (ISO 15930-1:2001)をご覧ください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月07日
PDF/X-3 まとめ
これまで見てきましたように、PDF/X-3は、PDF/X-1aの上位拡張仕様です。具体的には、カラー空間の使用可能範囲を広げて、「カラー管理ワークフロー」を可能にしたものです。
2006年07月28日 PDF:RGBワークフローとデジタルカメラで述べましたように、最近ではデジタルカメラなどで撮影したカラーイメージ画像が印刷に使われることも増えていますので、PDF/X-1aよりもむしろPDF/X-3が重要になりそうです。
PDF/X-3についての今までのブログの記事を整理して下記にまとめてみました。
PDF/Xについて (2) PDF/X-3
参考にしていただければ幸いです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月06日
PDF/X-3 (5)
9.境界ボックス
PDF/X-3の境界ボックスに対する条件は、PDF/X-1aとまったく同じです。
PDF/Xについて (1) PDF/X-1a 7.境界ボックスを参照してください。
10. 拡張グラフィックス状態
PDF/X-3の拡張グラフィックス状態に関する制約もPDF/X-1aとまったく同じです。
PDF/Xについて (1) PDF/X-1a 8.拡張グラフィックス状態を参照してください。
11. PostScript XObject
PDF/X-3ではPostScript XObjectを使うことはできません。この制約もPDF/X-1aとまったく同じです。
12.暗号化辞書
PDF/X-3では、暗号化辞書を使うことはできません。PDF/X-1aと同じです。
13.代替イメージ
PDF/X-3の代替イメージに関する制約もPDF/X-1aとまったく同じです。
PDF/Xについて (1) PDF/X-1a 11.代替イメージを参照してください。
14.注釈
PDF/X-3のトラッピング以外の注釈は、完全にBleedBox(もし、BleedBoxが無い時は、TrimBoxまたはArtBox)の外側になければなりません。PDF/X-1aと同じです。
15.アクション、JAVAScript
PDF/X-3では、アクションやJAVAScriptを使うことができません。PDF/X-1aと同じです。
16.BX/EXオペレータの使用
BX/EXオペレータの使用に関する制約は、PDF/X-1aと同じです。
PDF/Xについて (1) PDF/X-1a 14.BX/EXオペレータの使用を参照してください。
17.デジタル署名
PDF/X-3は、デジタル署名を含むことができます。PDF/X-3のリーダはデジタル署名を無視してもかまいません。
18.透明
PDF 1.4から追加された透明は、PDF/X-3:2003で使用条件に制約が課されています。この制約は、PDF/X-1a:2003と同じです。PDF/Xについて (1) PDF/X-1a 15.透明を参照してください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月05日
PDF/X-3 (4)
4. フォント
PDF/X-3では、フォントのグリフ、メトリックス、符号化方法は、使用されているすべての文字について埋め込まれていなければなりません。
フォントは埋め込みを許可されたもののみを埋め込みできますので、埋め込みが許可されていないフォントをPDF/X-3で使うことはできません。
5.ファイル指定
PDFでは、ファイル指定機能によって、他のファイルの内容を参照することができます。PDF/X-3ではファイル指定機能を使うことは禁止事項です。
参考 PDF Reference Fifth Edition 3.1 File Specifications pp. 151 - 162
6.データ圧縮
PDF/X-3:2002では、LZW以外のPDF1.3で使える圧縮を使用できます。
PDF/X-3:2003では、LZWとJBIG2以外のPDF1.4で使える圧縮を使用できます。
7.トラッピング
PDF/X-3のトラッピングについての仕様は、PDF/X-1aとカラー空間を示すPCMの規定を除いてまったく同じです。
PDF/Xについて (1) PDF/X-1a 5.トラッピングを参照してください。
すなわち、PDF/X-1aでは、PCMキーの値は、DeviceCMYKのみが許されていましたが、PDF/X-3では、PCMキーの値は、PDF/Xの出力インテントで指定した印刷条件に一致していなければならないというように拡張されています。
8.PDFファイルの識別
PDF/X-3のファイルは、Info辞書のGTS_PDF/XVersionキーで識別します。
PDF/X-3:2002ではキーの値が、(PDF/X-3:2002)となります。
PDF/X-3:2003ではキーの値が、(PDF/X-3:2003)となります。
PDF/X-1a の文書情報辞書の一般項目の設定は、PDF/X-1aと同じです。
PDF/Xについて (1) PDF/X-1a 6.PDFファイルの識別を参照してください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月04日
PDF/X-3 (3)
3.2 デバイス依存カラー
DeviceCMYKは、印刷条件がDeviceCMYKで指定されている時は、PDF/Xの出力インテントで識別される印刷条件で解釈しなければなりません。
これに対して、PDF/X-3のファイルにDeviceCMYKで定義されるカラーが含まれているにも関わらず、指定印刷条件がCMYKでないならば、Resource辞書のColorSpace下位辞書にDefaultCMYKカラー空間を含めなければなりません。そして、それは測色計によるカラー定義を提供しなければなりません。
DeviceGrayは、印刷条件がCMYKで指定されている場合、その黒色成分とみなします。印刷条件がグレーで指定されるときは、PDF/Xの出力インテントで識別される印刷条件で解釈しなければなりません。
DeviceGrayで定義されるカラーデータを含んでいるにも関わらず、指定印刷条件がCYMKでもグレーでもない場合は、Resource辞書のColorSpace下位辞書にDefaultGrayカラー空間を含めなければなりません。そして、それは測色計によるカラー定義を提供しなければなりません。
DeviceRGBも、DeviceCMYK、DeviceGrayと同様です。
3.3 ICCBasedカラー空間
ICCBasedカラー空間やその他の既定値のStream辞書では、Alternate(代替)カラー空間を含むことができません。
3.4 Separation, DeviceNカラー空間
CMYKカラー、スポットカラーにはSearationまたはDeviceNカラー空間を使うことができます。
PDF/X-3におけるSeparation, DeviceNカラー空間の仕様は、PDF/X-1aにおける同様の仕様を3.2項の記述に沿って拡張したものとなっています。
すなわち、送り手と受け手が、別の約束をしていない限り、名前をつけた色素は、意図した出力デバイスで使える独立した色素でなければなりません。
SeparationまたはDeviceNカラー空間で指定したスポットカラーをプロセスカラー色素を使って印刷するときは、SeparationまたはDeviceNカラー空間の代替カラー空間と色調変換式を使います。
代替カラー空間が、PDF/Xの出力インテントと同じデバイス依存カラーの場合、PDF/X-3準拠のリーダは、代替カラー空間をその印刷条件を参照するものとして扱います。また、代替カラー空間がDeviceGrayの場合は、PDF/X出力インテントで識別されるCMYKの黒と同等に処理します。代替カラー空間が、印刷条件と対応しないデバイス依存カラー空間を使っている場合は、3.2項を適用します。
3.5 Indexed、Patternカラー空間
Indexed、Patternカラー空間の基底となるカラー空間についても、上記の3.2項を適用します。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年08月02日
PDF/X-3 (2)
3. カラー空間
PDF/X-3:2002、PDF/X-3:2003では、出力デバイスのコード値でカラーを交換したり、測色計で定義したデータでカラーを交換できます。
いづれにせよ、印刷条件を事前に、名前付きの条件またはICC出力プロファイルの形で用意しておかねばなりません。
測色計で定義したデータを記述するには、PDFのICCBasedカラー空間のICCプロファイルを使うか、または、CalGray、CalRBG、Labカラー空間の同等の仕組みを使います。
出力デバイスのコード値は、PDFでは、DeviceRGB、DeviceCMYK、DeviceGray、Separation、DeviceN、Indexed、Patternカラー空間を、これから述べるような制約の元で使用できます。
3.1 出力インテント
出力インテントについては、PDF/X-1aと次の点を除いてまったく同じです。
印刷要素にデバイス独立のカラー空間を使用しているとき、DestOutputProfileキーが存在しなければならない。
PDF/X-1aについては、PDF/Xについて (1) PDF/X-1aの 2.1 OutputIntentによるカラー印刷特性の識別の記事を参照してください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月31日
PDF/X-3
さて、次は、PDF/X-3を調べてみたいと思います。
PDF/X-3は、カラー管理ワークフロー用に適した完全交換という副題が付いています。
2002年版と2003年版があり、それぞれ次の仕様書で規定されます。
ISO 15930-3 PDF/X-3:2002 PDF Reference 1.3 ベース
ISO 15930-6 PDF/X-3:2003 PDF Reference 1.4 ベース
1.準拠ファイルとツール
PDF/X-3の仕様に準拠するファイルとは、PDFファイルであってISOの各仕様書に準拠するものです。準拠するファイルには、印刷に関係ないPDFの他の機能を含むことが許されます。
PDF/X-3に準拠する書き手(ライター)はISOの各仕様に準拠するファイルを書くことができなければなりません。一方、読み手は、各仕様に準拠するすべてのPDF/X-3ファイルを読むことができなければなりません。さらに、PDF/X-1a:2001、PDF/X-1a:2003も処理できなけれなりません。
PDF/X-1aは、PDF/X-3の下位規定になりますので、PDF/X-3のリーダは、PDF/X-1aも読めないといけないわけです。
2.完全交換
PDF/X-3は、PDF/X-1aと同様完全交換の規定です。従って、複合実体のすべての部品がPDF/X-3のファイルに含まれていなければなりません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月27日
PDF/X-1aについてのまとめ
7月8日から7月26日にかけて連載しましたPDF/X-1aについて一区切りとして、まとめてみました。
こちらにアップしましたので、ご参考にしていただければ幸いです。
なにか、ご質問あるいは、誤りがありましたらご指摘いただければ幸いです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月25日
PDF/X-1a:2001、PDF/X-1a:2003 (10)
13.アクションとJavaScript
PDFでは、例えばしおりをクリックした時に、ビューアが新しいアプリケーションを起動したり、音を鳴らしたり、注釈の外見を変更する、JavaScriptを実行するなど、様々なアクションを設定できます。
PDF/X-1aに準拠するPDFファイルは、アクション、JavaScriptを含むことができません。
14.BX/EXオペレータの使用
PDFでは互換オペレータBX/EXが定義されています。このオペレータで囲まれた部分は、PDFの表示ソフトが理解できない場合、エラーにしないで無視するものです。
PDF/X-1aでは、Contentsストリームの中に、PDF Referenceにないオペレータを、仮にBX/EXで囲ったとしても含むことができません。
また、PDF/X-1aのリーダは、BX/EXで囲まれた部分についてもPDF Referenceに従って解釈しなければなりません。
PDFF/X-1aのライターは、BX/EXを使わないことが推奨されています。
15.透明
PDF1.4から透明が定義されました。そこで、PDF/X-1a:2003では、透明を使用しないように仕様が追加になっています。
具体的には、ExtGStateオブジェクトまたはImage XObjectに、SMaskキーを使うときは、値をNoneにしなければならない。
ExtGStateオブジェクトのBMキーはNormalまたはCompatible、CAキーとcaキーの値は1.0でなければなりません。
GroupオブジェクトのSキーにTransparencyの値をもつならば、それをform XObjectに含めてはならない。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月24日
PDF/X-1a:2001、PDF/X-1a:2003 (9)
9.PostScript XObject
PostScript XObjectは、PostScriptのプログラムをPDFの中に埋め込むものですが、PDF/X-1aでは使用禁止です。またPSオペレータ
なお、PDF Reference Fifth Editionでも、既に過去のものとして、使用しないことになっています。
PDF/X-1a:2003では、form XObjectsに、Subtype2キーの値PSを使用してはならないことが追記されています。これは、PostScript XObjectを、subtypeキーをformとし、Subtype2キーをPSとしても定義できますので、それを禁止したものです。
10. 暗号化辞書
PDF/X-1aでは暗号化辞書は使用禁止で、PDFのセキュリティ設定は利用できません。
11. 代替イメージ
image XObjectを指定するイメージ辞書には、ベースイメージに加えて複数の代替イメージを登録することができます。これはAlternatesキーにimage XObjectの配列として指定します。これらのすべての代替イメージは同じベースイメージの同じエリアのものでなければなりません。
さらに、各代替イメージには、その特性を指定しますが、DefaultForPrintingキーの値がTrueになるものは禁止されています。
12.注釈
PDF/X-1a:2001では、TrapNet以外の注釈は、完全にBleedBoxの外になければなりません。(BleedBoxがないときは、TrimBoxまたはArtBoxの外)。
PDF1.4で、注釈にPrinterMarkが追加されました。そこで、PDF/X-1a:2003では次のように変更されています。
TrapNetとPrinterMark以外の注釈は、完全にBleedBoxの外になければなりません。(BleedBoxがないときは、TrimBoxまたはArtBoxの外)。
PrinterMark注釈は、TrimBoxかArtBoxの外側になければなりません。
いずれにせよ、PDF/X-1aを画面に表示したり、印刷するとき、注釈が実際のページの内容に重なってはならないことを規定しています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月23日
PDF/X-1a:2001、PDF/X-1a:2003 (8)
8.拡張グラフィックス状態
PDF/X-1a準拠ファイルは、拡張グラフィック状態を現すExtGStateリソース辞書の中に、伝達関数(transfer function)キーTR,TR2、あるいはハーフトーンフェーズキーHTPを含んではなりません。
※HTPキーはPDF Reference Fifth Edition には記載がありません。ISO 15930-1, 4の両方に記載があって、PDF Reference に記載がないキーワードです。
また、準拠のリーダは、ハーフトーンキーHTを無視してもかまいません。
ハーフトーンキーHTは、印刷条件特性と一致するように使わなければなりません。また、ハーフトーン辞書のTransferFunctionキーはPDF Reference に指定される通りの方法でのみ使わねばなりません。
PDF/X-1a準拠のファイルでは、HalftoneTypeキーの値は1または5の値をもつことができます。
HalftoneNameキーを含むことはできません。
※ハーフトーンの使用には制限があるとされていますが、仕様書の記載とPDF Referenceの記載を併せて見てもどうも良く理解できません。画像処理の専門家による検討が必要なように思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月22日
PDF/X-1a:2001、PDF/X-1a:2003 (7)
7.境界ボックス
PDFは、紙と同じようにページの概念をもつ媒体です。PDFでのページは、ツリー構造で管理され、ツリーの葉に相当する部分が1つのページです。これをページオブジェクトと言います。
ページオブジェクトには様々な属性を設定できます。これを設定したデータをページオブジェクト辞書と言います。オブジェクト辞書の設定キーの中でPDFのページ境界に関するキーを次に示します。PDF/X-1aではこれらのページの境界の設定について制限を課しています。
表 ページオブジェクト辞書のページ境界関連項目
| キー | PDF/X1-a | |
| MediaBox | 必須 | 継承可 |
| CropBox | オプション | CropBoxがあるとき、BleedBox、ArtBox、TrimBoxのいづれもCripBoxの境界を越えないこと |
| BleedBox | オプション | BleedBoxがあるときは、ArtBox、TrimBoxはBleedBoxの境界を越えないこと |
| TrimBox | オプション | TrimBoxかArtBoxのどちらか、一方のみ、が設定されていなければならない。ArtBoxよりもTrimBoxの方が望ましい。 |
| ArtBox | オプション |
参考 ページ境界の意味
通常の書類をPDF化した場合のように、PDFを印刷した物が最終印刷物になる場合、MediaBox、CropBox、TrimBox、BleedBoxは一致します。しかし、PDFを印刷用のフィルムに出力する場合は、MediaBoxがフィルムの境界に相当し、TrimBoxが印刷して周囲を切り落としたページのサイズになります。
BleedBoxは、TrimBoxの外側に裁断や仕上げのために必要な幅を確保した領域です。
CropBoxは、ページの内容をクリップするための領域とされていて、他の境界線との関連性はありません。
ArtBoxはDTPソフトなどのアプリケーションが出力するもので、TrimBoxの内部でページの意味のある内容を囲む領域とされています。
※PDF Referenca Fifth Edition 10.10.1 Page Boundaries pp. 890 - 893
DTPなどの出力したEPSグラフィックスをPDFに変換したときなどに使うと、ArtBoxで切り取って他のPDFに埋め込むなどの用途で便利と思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月21日
PDF/X-1a:2001、PDF/X-1a:2003 (6)
6. PDFファイルの識別
PDF/X-1aのファイルは次のように識別します。
PDFのInfo辞書にGTS_PDFXVersionキーを作成します。
PDF/X-1a:2003ではキーの値が、(PDF/X-1a:2003)となります。
PDF/X-1a:2001ではキーの値が、(PDF/X-1:2001)となります。
PDF/X-1a:2001ではさらに、Info辞書にGTS_PDFXConformanceキーを作成し、このキーの値を、(PDF/X-1a:2001)とします。
このほか、PDF/X-1aの場合は、Info辞書に通常のPDFではオプションのキーを設定しなければならないものがあります。
次に比較表を挙げます。
表 PDF/X-1a の文書情報辞書の一般項目の設定
| キー | 通常のPDF | PDF/X-1a |
| Title | オプション | 必須 |
| Author | オプション | |
| Subject | オプション | |
| Keywords | オプション | |
| Creator | オプション | 勧告 |
| Producer | オプション | 勧告 |
| CreationDate | オプション | 必須 |
| ModDate | オプション | 必須 |
| Trapped | オプション | 必須(True, False) |
必須の時、キーワードをゼロバイトにするのは許されません。
TrailerのIDキーは、通常はオプションですが、PDF/X-1aでは存在しなければなりません。なお、PDF生成ソフトはIDキーがユニークになるように作るべき(勧告)とされています。
次の仕様は、PDF/X-1a:2001には記述がありませんが、PDF/X-1a:2003で追加になっています。
PDFファイルを更新したときは、ModDateを更新しなければならず、Catalog辞書のMetadataストリームも更新すべき(勧告)。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月20日
PDF/X-1a:2001、PDF/X-1a:2003 (5)
5.トラッピング
多カラーの印刷工程では、色別の版の位置ずれが原因で、印刷対象の周囲にギャップができたり帯ができたりする可能性があります。隣同士の色を重ねること、トラップという、により版が多少ずれても問題が起こりにくくすることができます。
トラッピングは、PDFを作成するソフトで行ったり、中間的なアプリケーションでPDFにトラップを追加したり、あるいは、最終段階のRIP(ラスター・イメージ・プロセサ)で追加することもあります。PostScriptにはトラッピングを設定することができます。しかし、PDFファイルにはトラッピングは直接指定しないで、PDFに付随もしくは埋め込まれるジョブチケットで指定します。
トラッピングを最終工程よりも前に行ったときは、トラップは、トラップ・ネットワーク注釈としてPDFに保存します。
PDF/X-1a:2001、2003ともこの部分は同じです。
まず、PDFの文書情報であるInfo辞書のTrappedキーにトラッピングされたものかどうかを記述します。
Trappedキーは、通常のPDFではオプションですが、PDF/X-1aでは必須です。そしてその値は、次のようにTrueまたはFalseでなければなりません。
・PDFファイル全体がトラッピングされているならば、キーの値はTrue
・PDFファイル全体がトラッピングされていないならば、キーの値はFalse
・一部分だけトラッピングされているものは許可されません。またキーの値がUnknown(PDFの規定値)は許可されません。
PDFファイルにトラップ・ネットワーク注釈を含んでいるなら、Trappedキーの値は、Trueでなければなりません。トラップ・ネットワーク注釈を作成した後で頁を修正したら、トラップ・ネットワーク注釈は無効です。
トラップ・ネットワーク注釈の中で、トラップ・ネットワークの生成の際に代替フォントで置換されたフォントを示す、FontFauxingキーは存在しないか、存在しても空でなければなりません。トラップ・ネットワークを生成する際に想定するカラー空間を示すPCMキーの値は、DeviceCMYKでなければなりません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月18日
PDF/X-1a:2001、PDF/X-1a:2003 (4)
4. データ圧縮
PDF/X-1a:2003では、LZWとJBIG2圧縮を除いて使用可能となっています。これに対して、PDF/X-1a:2001は、ImageXObject以外を圧縮するなら、FlateとRunLengh圧縮のみを許可。ImageXObjectを圧縮するならJPEG、Flate、RunLengh、白黒イメージであればCCITT Fax圧縮を許可しています。
2つのレベルの仕様書で書き方が違うため、PDFで扱えるすべての圧縮方式を調べてみないと、この二つが同等かどうか分かりません。
そこで、念のために表を作ってみました。
| 種類 | PDFで使える圧縮方法 | PDF/X-1aで禁止 |
|---|---|---|
| カラーとグレースケール | JPEG、JPEG2000(PDF1.5~) | JPEG2000は禁止でしょうね。 |
| 白黒イメージ | CCITT (G3, G4), RunLength, JBIG2 | JBIG2 |
| テキスト、線画、イメージ | LZW, Flate (ZLIB) | LZW |
一見、PDF/X-1a:2001、PDF/X-1a:2003で同等のように見えますが、問題はPDF/X-1a:2001では、Image XObjectとそうでないものに分けていることです。PDFでは、Image XObjectというのは画像ファイルを埋め込んだものに相当しますが、それ以外にインライン・イメージがあります。インライン・イメージについては、次の圧縮方式が使えます。
LZW, Flate (ZLIB), RunLengh, CCITT, JPEG
※PDF Reference Fifth Edition 4.8.6 Inline Images pp 322- 325
結局、PDF/X-1a:2001ではインライン・イメージの圧縮にCCITT, JPEGは使えませんが、PDF/X-1a:2003では、CCITT, JPEGも使えることになります。表現方法を変えたために仕様が変わっているということです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月17日
PDF/X-1a:2001、PDF/X-1a:2003の続き
2.2 DeviceCMYK、Device Grayカラー空間
カラー空間がDeviceCMYKまたはDeviceGrayで指定されているPDFの印刷要素は、出力インテント・オブジェクトにある印刷条件の通りに解釈します。
2.3 Separation、DeviceNカラー空間
CMYKカラーとスポットカラーに対して、SeparationかDeviceNカラー空間を使うこともできます。
PDFのSeparationカラー空間とは、対象となる出力デバイスの一種類の色素に対して名前をつけて指定する方式、DeviceNカラー空間とは、対象となる出力デバイスの多種類の色素に対して名前をつけて指定する方式です。指定した色素がない他の出力デバイスのために代替カラー空間と、そのカラー空間で、指定の色素を合成するための色調変換式を添えて出力します。
PDF/X-1aでは、すべてのSeparationとDeviceNカラー空間のリソースは、代替カラー空間としては、DeviceCMYKかDeviceGrayを使わなければなりません。
送り手と受け手が、別の約束をしていない限り、名前をつけた色素は、意図した出力デバイスで使える独立した色素でなければなりません。
SeparationまたはDeviceNカラー空間で指定したスポットカラーをプロセスカラー色素を使って印刷するときは、SeparationまたはDeviceNカラー空間の代替カラー空間と色調変換式を使います。
代替カラー空間がDeviceCMYKの場合は、PDF/X-1a準拠のリーダは、PDF/X出力インテントで識別されるCMYKを使います。また、DeviceGrayの場合は、PDF/X出力インテントで識別されるCMYKの黒と同等に処理します。
2.4 Index、Patternカラー空間
PDFのIndexとPatternカラー空間は、ベースとなるカラー空間の上にカラーのテーブルを作ってインデックスでカラーを指定するものです。この場合は、ベースとなるカラー空間に対して、上に述べた制約を適用します。
3. フォント
PDF/X-1aでは、使われているすべての文字に対して、グリフ、メトリックス情報、フォントの符号が埋め込まれていなければなりません。
受け手は、システムにインストールされているフォントではなく、PDFファイルに埋め込まれているフォントを使って、描画したり表示したりしなければなりません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月16日
PDF/X-1a:2001、PDF/X-1a:2003のカラーの続き
2006年07月14日 PDF/X-1a:2001、PDF/X-1a:2003の2.カラーの続きです。
2.1 OutputIntentによるカラー印刷特性の識別
PDF/X-1aではOutput Intentを使ってカラー印刷特性を識別します。次にOutputIntentに設定する内容について簡単に整理してみます。
OutputConditionIdentifierには、PDFのテキスト文字列が入ります。これは、RegistryNameとの組み合わせで使います。
(1) RegistryNameは意図する印刷特性を特性データ登録を使って定義するときに限り使用できます。これを使うときは、OutputConditionIdentifierの値は、その登録における参照名(Reference name)に一致しなければなりません。
代表的なものはICC特性データ登録(ICC Characterization Data Registry) です。
ICC Characterization Data Registry
この時、RegistryNameキーの値は、(http://www.color.org)となります。
例えば、Japan Color 2001 Coatedは、ICC Characterization Data Registryの参照名が、JC200103となっています。するとOutput intent辞書の内容は次のようになるでしょう。
<< /Type /OutputIntent % Output intent dictionary
/S /GTS_PDFX
/OutputCondition (JC200103 (Japan Color 2001 Coated ))
/OutputConditionIdentifier (JC200103)
/RegistryName (http://www.color.org)
>>
(2) RegistryName キーがない時、OutputConditionIdentifierには特別な意味を持たせることはできません。
(3) RegistryName キーが存在して、値が (http://www.color.org)ではないときは、その値は、その登録について詳しい情報を入手可能なURLでなければなりません。
また、上の(2)または(3)の場合は、DestOutputProfileが存在しなければなりません。
OutputConditionキーは常に存在するべきで、その値は、印刷特性を、人間のオペレータに分かりやすい形式で、コンパクトに伝える情報にします。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月15日
PDF/XとOutput Intent
PDF/Xの仕様の策定に伴い、ドキュメントを印刷する環境や出力デバイスカラー特性とPDF文書のカラー特性をマッチさせるためにPDFのドキュメント・カタログにOutput Intent辞書が追加されました。
Output Intentは、PDF1.3では、PDFの仕様ではなく、アドビのテクニカルノート#5413として定義されました。PDF1.4からPDFの正式な仕様となっています。
まず、PDF ReferenceのOutput Intentの項目を見てみます。なお、PDF Reference の説明とPDF/Xの各パートでの制約には不一致の部分があり、その場合は、PDF/Xの仕様書を優先することになっていますので注意してください。
表 10.50 PDF/X用の出力インテント辞書
| キー | 必須かどうか | 値 |
|---|---|---|
| Type | オプション | OutputIntent |
| S | 必須 | GTS_PDFX |
| OutputCondition | オプション | 意図する出力環境を人間に分かるようにコンパクトに記述する |
| OutputConditionIdentifier | 必須 | 意図する出力環境を人間に分かるか、機械可読な形式で記述する。一般にはICC Characterization Data Registryのような業界標準を使用する。業界標準でない場合、Customとするか、それともアプリケーション独自でも良い。 |
| RegistryName | オプション | OutputConditionIdentifierで定義される条件のURI |
| Info | OutputConditionIdentifierが標準の生産環境を指定していないときのみ必須 | 意図する環境を指定するための情報を人間に可読な形で記述 |
| DestOutputProfile | 同上 | PDFの文書を出力デバイスに変換するためのICCプロファイルのストリーム |
Output Intentは、現在、PDF/Xのみが規定されていますが、将来は、他の用途にも拡張されるとしています。PDF/X以外では、参考情報としての意味しかもちません。しかし、PDF/Xでは重要な役割になります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月14日
PDF/X-1a:2001、PDF/X-1a:2003
次にPDF/X-1a:2001とPDF/X-1a:2003について、主な仕様を見てみます。
1.PDF/X-1aファイル構造
・PDF/X-1aの構造は、まずPDF Referenceに従っていることが前提となり、さらに、PDF/X-1aの仕様で書かれた制限に従わねばなりません。
・事前に各ページを色分割して、一色毎に別々のページオブジェクトにしたようなPDFは、ブラインド交換にならないので許されません。
・PDF/X-1aファイルには、最終的に印刷される要素(印刷要素:print element)と印刷向けでない要素(non-print element)を含むことができます。
・すべての複合実体(compound entity)は、ひとつのPDF/X-1aファイルに完全に含まれなければなりません。つまり、すべてのPDFのリソースや印刷要素を交換ファイルに含むこと。
2.カラー
カラーの規定は、印刷要素のみに適用されます。非印刷要素はどのようなカラーを用いても問題ありません。
印刷要素は、CMYKデータ、グレースケールデータ、またはセパレーション・カラーデータとして交換されなければなりません。
PDF/X-1aファイルの中の印刷要素は、DeviceCMYK、DeviceGray、Separation、DeviceN、Index、Patternカラー空間を、この仕様で規定する制限に沿って使うことができます。
これらのカラー空間は、PDF Referenceに説明されるPDF専門用語です。そこで、PDF Referenceの関連部分から補足して考えてみます。
PDFでは次の種類のカラー空間を使うことができます。
(1)デバイス・カラー空間
DeviceCMYK、DeviceRGB、DeviceGray
(2)CIEベース・カラー空間
CalGray、CalRGB、Lab、ICCBased
(3)特色空間
Pattern、Indexed、Separation、DeviceN
※参考
PDF Reference Fifth Edition 4.5.2 Color Space Families
デバイス・カラー空間とは、出力デバイスが出力する色や陰を直接指定するものです。PDF/X-1aではDeviceRGBを使うことができません。
※参考
PDF Reference Fifth Edition 4.5.3 Device Color Space
CIEベース・カラー空間とは、Commission Internationale de l’Éclairageという国際機関が決めた色の標準で指定する方式です。PDF/X-1aではこれらは使えません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月11日
PDF/X-1, PDF/X-1a その2
第1部の規格は、コンフォーマンスレベル(準拠度)としては次の3つがあります。
(1) PDF/X-1:1999 PDF1.2に準拠して作られた、ANSI CGATS.12/1-1999
(2) PDF/X-1:2001 PDF1.3に準拠し、ISO 15930-1:2001 規格で定める
(3) PDF/X-1a:2001 PDF/X-1:2001と比べて次の3点の違いがあります。
埋め込みファイルへのOPI参照を禁止
PDFのEncrypt辞書(プロテクト)を使用禁止
PDFのInfoオブジェクトにGTS_PDFXConformanceキーの値としてPDF/X-1a:2001をセットする。
さらに、第4部として次の規格が制定されています。
(4)PDF/X-1a:2003 PDF1.4 に準拠し、ISO 15930-4:2003規格で定める。
第4部は、第1部を拡大し、さらに洗練したものとしたもので、第1部との違いは、次の通りです。
・PDFのバージョンが1.3から1.4にあがった。
・OPIを使用しないようにした
・ただひとつの準拠度すなわちPDF/X-1a:2003のみ規定
・PDF1.4の追加機能である、JBIG2、透明、参照されたPDF(Referenced PDF)を不許可とする
PDF/X-1a:2003もCMYKを主とする完全交換を目的とする規格です。
PDF/X-1は、廃止規格とされているという資料もありますが、ISO 15930-4:2003には、PDF/X-1を明示的に廃止したとは書いていないように思います。PDF/X-1を使えば、TIFF、EPSなどをプロキシとしてプレビュー・イメージを埋め込んだ上で、OPIを使って印刷用のファイルを埋め込むような交換方式も可能です。有用な規格ですので、廃止する必要はないように思うのですが。廃止したのかどうかはいまのところ分かりません。
※参考
JBIG2
ISO のJoint Bi-Level Image Experts Groupが開発したモノクロイメージの圧縮方式
JBIGホームページ
{kind=link}
Referenced PDF
意味不明です。明日もう少し詳しく仕様書を読んでみましょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月10日
PDF/X-1, PDF/X-1a (ISO 15930-1:2001)
まず、ISO 15930-1:2001を見てみます。冒頭にPDF/Xは、3つの部分に分かれるとあり、ISO 15930-1:2001は、その第1部にあたります。
第1部 PDF/X-1、PDF/X-1a これはCMYKを中心とする完全交換
第2部 PDF/X-2 印刷データの部分交換
第3部 PDF/X-3 カラー管理されたワークフローに適した完全交換
完全交換と部分交換という言葉をもう少し細かく見てみます。
完全交換と部分交換
印刷された文書は、様々な場所で、様々な組織が作成した部分的なページを集合したものとなります。最終印刷物を作るために用意されたテキスト、グラフィックス、イメージなどを伴う作業単位を複合実体(compound entity)と言います。複合実体は、1ページであったり、ページの一部であったり、あるいは複数のページになります。
完全交換とは、1回の交換の中に複合実体のすべての要素があり、かつ、複合実体を処理するための情報が複合実体の中に含まれるか、もしくは外部の標準で規定されているものです。これに対する概念は、部分交換で、これは複合実体の一部の要素を意図的に除外して交換し、別途入手するものです。
もうひとつ類似の概念として、ブラインド交換 (blind exchange) という言葉があります。
ブラインド交換とは、受け手が、送り手から受け取ったページを、送り手の意図通りにレンダリングするために、事前に技術的な情報の交換を必要としないものです。ISO 15930では、完全交換であれば、ブラインド交換になると考えているようです。
第1部はPDFを使った完全交換を規定します。
このために、交換するPDFファイルには次のものを含まねばなりません。
・フォント、フォントメトリックス、フォントの符号化、カラー空間リソースなどを含むすべてのPDFのリソース
・OPIで外部参照されるファイルはストリームとしてPDF/X-1ファイルに含む
・すべての印刷用の要素が、意図されたひとつの印刷設定のために適切に準備されている
OPI:Open Prepress Interface
もともとAldusが規定したもの。印刷用の高解像度の画像は非常に大きなサイズになるので、印刷用のDTPファイルとは別に保存し、DTPファイルの中には、そのファイルが入る場所を確保し、プロキシとして代わりの低解像度の画像を保存する方式。印刷時にOPIサーバと呼ぶフィルターを通して、高解像度画像と入れ替えます。
PDFでも同じ仕組みがあります。PDFでは、プロキシは画像またはXObjectとして、OPI辞書を伴って保存されます。
※PDF Reference 10.10.6 Open Prepress Interface (OPI) pp. 907~911
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月09日
PDF/X 規格策定の原則・ガイドライン
PDF/Xには、なぜ、沢山の種類があるのでしょうか?
ISO 15929 では、PDF/Xの規格策定の原則について説明しています。以下に説明を要約してみます。
A1 Introduction
「PDF/Xの策定にあたり、ISO/TC 130/WG2のメンバーは、印刷・出版産業のニーズは、地域と、新聞・出版・カタログ・商業印刷など応用領域によって変化することを認識した。
このような広範なニーズに答えるために、複数の部分から構成されるISO標準を作るアプローチを選んだ。
また、アドビのPDFが進化しているので、PDF/X標準が、異なるPDFのバージョンを参照しても良いものとした。」
このようなさまざまな異なる条件をカバーするということです。
では、ニーズの違いとは具体的にどんなことでしょうか?
A.3 一般的要請
「次のようなニーズの違いに対応することを考える。
・送り手と受け手の間で技術的なコミュニケーションが最小ですむようなブラインド交換と、事前に技術的な合意をした上で行う交換
・一回の交換で必要な要素を入手するか、それとも、一部の要素は受け手のサイトに存在したり、あるいは、別途交換するか(完全な交換、または、部分交換)
・CMYKデータの交換、または、他のカラー空間による符号化
・送り手が期待する印刷の見栄えを指定するか、それとも、送り手が完全な全域データを提供し、受け手が実際の印刷の条件設定に責任をもつか
・オブジェクトに対して外部の参照ファイルを使うか、すべてのオブジェクトがPDFファイルに中に符号化されるか」
上のようなさまざまなニーズを考えて、複数の仕様が作成されたということです。
各仕様では、PDFの中で使用してよいオブジェクト、あるいはオブジェクトの使用に関して制約を追加しています。
A.4 コンフォーマンスの原則
「幾つかのコンフォーマンスレベルが定義されます。
PDF/Xを活用するソフトウエアには、リーダ、ライタ、ビューア、などを含みます。
PDF/Xを生成するアプリケーションは、各コンフォーマンスレベルにおいて、一部の機能のみをサポートすることが許されます。
一方、PDF/Xを読むアプリケーション(ビューア、あるいは検証ソフト)は、当該のコンフォーマンスレベルの全機能を読んで、正しく処理しなければならない、とされています。」
これを見ますと、どうやら、PDF/Xのリーダを作る方が大変なようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月08日
PDF/X
PDF/X規格は、ISO 15930 で規定されている印刷用のデータ交換を目的としたPDFのサブセットです。
基本的には、印刷するためのすべての情報がPDFファイル内に含まれていて、つまり、PDF/Xに適合したファイルを印刷業者に渡せば、作成者の意図通りに印刷されるということらしいのですが。
次に規格書の名称をあげておきます。ISO 15930規格自体にはいろいろファミリーがあってとても分かりにくいという印象があります。私はもちろん(?)全部読んだことはありません。
# ISO 15929 Graphic technology - Prepress digital data exchange - Guidelines and principles for the development of PDF/X standards
図形技術-製版デジタルデータ交換-PDF/X規格の開発の指針及び原則
# ISO 15930-1 Graphic technology- Prepress digital data exhange-Use of PDF- Part1:Complete exchange using CMYK data(PDF/X-1 and PDF/X-1a)
図形技術-プリプレスデジタルデータ交換-PDFの使用-第1部:CMYKデータ(PDF/X-1及びPDF/X-1a)を使用する完全交換
# ISO 15930-3 Graphic technology- Prepress digital data exhange-Use of PDF- Part3:Complete exchange suitable for colour managed workflows(PDF/X-3)
図形技術-プリプレスデジタルデータ交換-PDFの使用-第3部:色彩管理ワークフロー(PDF/X-3)に適した完全交換
# ISO 15930-4 Graphic technology -- Prepress digital data exchange using PDF -- Part 4: Complete exchange of CMYK and spot colour printing data using PDF 1.4 (PDF/X-1a)
図形技術-PDFを使用するプリプレスデジタルデータ交換-第4部:PDF 1.4 (PDF/X-1a)を使用するCMYKの完全交換及びスポットカラー印刷データ
# ISO 15930-5:2003 Graphic technology -- Prepress digital data exchange using PDF -- Part 5: Partial exchange of printing data using PDF 1.4 (PDF/X-2)
図形技術-PDFを使用するプリプレスデジタルデータ交換-第5部:PDF 1.4 (PDF/X-2)を使用する印刷データの部分交換
# ISO 15930-6:2003 Graphic technology -- Prepress digital data exchange using PDF -- Part 6: Complete exchange of printing data suitable for colour-managed workflows using PDF 1.4 (PDF/X-3)
図形技術-PDFを使用するプリプレスデジタルデータ交換-第5部:PDF 1.4 (PDF/X-3)を使用するカラー管理ワークフローに適した印刷データの完全交換
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月04日
リニアライズドPDFの利用方法 バイトサービング
昨日説明しました、リニアライズPDFは、Web最適化とも言われます。
PDFがリニアライズ(Web最適化)されていると、クライアントからWeb上のPDFの指定ページを高速に表示することもできます。
例えば、Webブラウザで昨日のXSL Formatterのリニアライズ版PDFの100ページをいきなり表示したいならば、ブラウザのURLに次のように指定します。
http://www.antennahouse.com/XSLsample/help/V40/LinearizedPDF/XSLFormatterV40en_V40R1.pdf#page=100
つまり、ページ番号を追加で指定することで、PDFの指定ページを指定します。
もっとも、このページ指定は非リニアライズPDFでも有効です。非リニアライズPDFで、ページ番号を指定する場合は、PDFファイル全体をダウンロードしてからAdobeリーダが100ページ目にジャンプして表示します。この場合、結局、100ページ目を表示するまでの待ち時間の相違ということになります。ネットワークが高速ならあまり差がないね、と言われてしまいそうです。
しかし、通信回線が遅く、また、端末のメモリ容量が小さいときなどは、このリニアライズしたPDFを、ページ単位で端末に送信するバイトサービングを使うと有効でしょう。
《参考》
バイトサービング
バイトサービングを使うにはサーバ側でPDFを1ページずつ送り出してくれる機能が必要ですが、新しいWebサーバはPDFのバイトサービングには対応していると思います。
特に、最近は、NTTドコモのFOMAには、PDFビューア(Acrobat LE)が搭載されているものがあります。FOMAなどで大きなPDFを表示しようとすると、リニアライズとバイトサービングを組み合わせてページ単位にダウンロードするようなことが必須になると思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年07月03日
リニアライズドPDFとは
Webページで配布されているPDFをブラウザで開いてみるとき、PDFのページが表示されるまでに時間がかかると感じた場合、リニアライズドPDF(Linearized PDF)かどうかを確認してみると良いと思います。
普通のPDFをAdobeリーダなどのビューアがファイルの内容を表示する際は、PDFファイルの最後まで読まないと表示開始できません。このため、ファイルの容量が大きい(ページ数の多い)PDFをWeb経由で表示しようとすると、全部ダウンロードするまで、画面には、内容がまったく表示されません。
この対策として、Web経由でPDFをできるだけ早く表示するために作られたのが、リニアライズドPDFという仕様です。
リニアライズドPDFは、PDF1.2から導入されています。PDF Reference 1.6 では、付録F(Appendix F)Linearized PDFという章に36ページの説明があります。
付録になっていることからも分かりますが、あくまでオプション仕様ですので、WebにアップするPDFを作る時はこれを意識して作成しなければなりません。
PDFをリニアライズするプログラムは、出来上がったPDFファイルの内容を並び替え処理を行います。このためPDFの作成とリニアライズは2ステップの処理になります。つまり、リニアライズするとその分追加の処理時間がかかるということです。
また、リニアライズ処理済のPDFを暗号化したり、PDFの内容を書き換えたりしますと、リニアライズドでなくなってしまいますので、再び、リニアライズし直しが必要です。
XSL FormatterV4.0には、リニアライズドPDFを出力する機能がありますので、これを使って試しに、2種類のPDFを作成してみました。
データ1:
リニアライズされたPDF(XSL Formatter V4のマニュアル)
作成方法:XSL Formatter V4 R1で作成したLinearized PDF
サイズ:2,673,164 バイト
データ2:
リニアライズされていないPDF(XSL Formatter V4のマニュアル)
作成方法:XSL Formatter V4 R1で作成した非Linearized PDF
サイズ:2,671,214 バイト
この二つのPDFをWebブラウザから表示してみましょう。リニアライズドPDFの方が表示開始までの時間が遥かに短いことを確認していただけると思います。
ちなみに、PDF Tool でも、既存のPDFをリニアライズすることができます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年05月18日
PDFからテキスト抽出のために ToUnicode CMap
PDFにおけるフォントの取り扱いに関連して、ToUnicode CMapというものがあります。今日はこれについて説明します。
アウトライン・フォントについての説明でお分かりいただけたかと思いますが、PDFにアウトライン・フォントを使って記録された文字を表示する仕組みは、フォントの中にあるグリフのアウトラインをラスタライザで可視化することになります。
これに対して、もう一つのPDFの利用方法として、PDFを読み上げたり、あるいは、検索エンジンで検索したり、あるいはテキスト情報を取り出して他のアプリケーションで使用する、などが考えられます。
通常、上で述べたような処理にはテキストが必要です。テキストについては、2005年12月15日 PDFと文字(4) – 文字の取り扱いで説明しましたので、初めての方は12月15日の話をお読みになってみてください。
PDFの中では、文字を可視化するための情報が入っているのですが、可視化するための情報からテキストを取り出す方法には幾つかあります。
ToUnicode CMap(オプション)は、このための手段の一つとして用意されているものです。
CMapについては、2006年01月17日 PDFと文字 (25) – CMapで文字コードからCIDへ変換で説明しましたが、通常は、文字コードからアドビが定義した、CIDに変換する用途で使います。
ToUnicodeCMapは、CIDへの変換ではなく、PDFの中に入っている表示用の文字列情報をUnicodeに変換するためのテーブルです。CMapの仕様に準拠して作成されています。
PDFの中の情報をUnicodeに変換する方法は他にも幾つかありますが、ToUnicodeCMapは最優先で使われます。また、CJKのTrueTypeを埋め込んでいる場合、ToUnicodeCMapがないとUnicodeテキストを利用できないと思います。これを用意するのは、PDFを作成する生成ソフトの責任です。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年04月16日
PDFのメタデータ (2) — メタデータストリーム
メタデータはPDFの属性(プロパティ)に示されるような、著者、主題、作成日、などファイル内容に関して把握するための情報です。
PDFでは、昨日説明しましたように、ドキュメント情報辞書を使ってファイルにメタデータを付与できます。さらに、もう一つ別の方法で、PDF文書全体、または、PDF文書の中の部品にメタデータを付加することができます。それが、今日説明しますmetadata streamです。
PDFのコンテンツの種類の一つにストリーム・オブジェクトというものがあります。ストリームオブジェクトは、簡単に言いますと一塊のデータに相当します。metadata streamはストリーム・オブジェクトの中の一種類です。
metadata streamについてはPDF Reference 10.2.2 Metadata Streamを参照してください。
metadata streamの内容には、その対象となるメタデータをXMLで記述します。XML形式の仕様は、Extensible Metadata Platform (XMP)として、別途、定義されています。
PDFドキュメント全体を管理する部分にmetadata streamを付けることもできますし、PDFドキュメントを構成する部品単位でもメタデータを付与することができます。
metadata streamをどのように作成するかは、XMP仕様書の中の、XMPパケットをPDFに埋め込むという項を参照してください。
XMP仕様書
原則として、実際の情報を含むような、あらゆるPDFのストリームにはメタデータを付与することができるとされます。このため、却って、どのストリームにメタデータを付与するべきかが曖昧になってしまいますので、データを実際に持っているオブジェクトにできるだけ近い位置にメタデータをつけるべきとされています。
PDF Referenceでは、メタデータをつけるのに適切と思われるコンポーネントには、Metadataのエントリが示されていますが、PDF Referenceに示されていないコンポーネントにメタデータを付与することも可能です。
さらに、コンテントのデータ中のmarked content(タグ付)というコンテンツにメタデータを関連付けることもできます。
このようにmetadata streamをPDF中のコンポーネント・データ毎に付与して、大きな文書の中に埋め込む部品単位メタデータを持たせることができるのは、PDFワークフローを構築する際に部品の管理などに使うことを意図しているようです。
これは、アドビの提唱するメタデータ仕様XMPが、PNG、JPEG、GIFなどのグラフィックスファイルに付与できるものとなっていることとも関係します。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月15日
PDFのメタデータ (1) — ドキュメント情報辞書
PDFのメタデータは、二通りの持ち方になります。
ひとつは、ドキュメント情報辞書としてもつもの。他のひとつは、メタデータ・ストリームとしてもつものです。
ドキュメント情報辞書には次の情報を設定できます。
・Title(タイトル)
・Author(著者)
・Subject(主題)
・Keywords(キーワード)
・Creator(オリジナルのドキュメントを作成したアプリケーション)
・Producer(PDFを作成したアプリケーション)
・CreationDate(作成日)
・ModDate(修正した日)
・Trapped(トラップ処理が行われたかどうか)
このドキュメント情報の多くは、Adobe ReaderでPDFを表示したとき、文書の属性として確認することができます。
この中で、トラップ処理が行われたかどうかちょっと異色です。これは印刷のワークフローで使うものなので、一般向けではなく、Adobe Readerでは確認できないようです。
分かったつもりの印刷用語:Trappingによりますと、Trapとはオフセット印刷で、インキを重ねて刷っていくときに、印刷時の紙の伸縮や位置ずれで、白い間隔ができたりしないようにする処理のことのようです。
新しいPDFにプリプレスはどのように対応するか?--PRNCOM '99から
は、少し古いですが、GATF(Graphic Art Technical Foundation)の調査を紹介しています。これによりますと、DTPデータの問題の中で、トラップミスが12%で第二位なんですね。
2001年に、ハイデルベルグのPDFトラップ・エディタ「Prinect Trap Editor」がGATFの技術賞を受賞しています。
PDFの仕様では、10.10 Prepress Supportの中に、10.10.5 Trapping Supportという項があり、トラップ・ネットワーク注釈という注釈の一種類としてトラップの内容を記述していくようです。なかなか奥が深そうなところです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月14日
PDF/A とはなにか?
PDF/Aは電子文書を長期に保管することを目的して作成されるPDFが満たすべき仕様です。PDF/A-1とPDF/A-2のふたつの仕様があります。
PDF/A-1は、PDF 1.4仕様に基づいています。この中でふたつの準拠レベルを定義しています。
・PDF/A-1a レベルAは、ISO 19005-1完全準拠
・PDF/A-1b レベルBは、ISO 19005-1の一部準拠
PDF/A-1bは、PDFを表示できることが保証されれば良い。これに対して、PDF/A-1aではテキスト抽出ができることが求められます。この時のテキストはドキュメントの論理的な順序どおりになっている必要があります。これはTaggedPDFとも呼ばれます。
■経過等
米国のAIIM他の団体が中心になって、2002年から策定作業を開始、2005年9月にPDF/A-1がISO標準になりました。
なお、PDF/Aには、ISO 19005-2(PDF/A-2)という新しいパートも策定作業中ですが、PDF/A-2は、PDF1.6仕様にもとづくものでデジタル署名などを含んでいます。
■PDF/Aの目的
・デバイス独立
・表示に必要な全ての情報を含む
・自分自身の記述を含む
・基本的なツールで直接解析できる
・技術的に保護しない(パスワード、暗号化なし)
・仕様の公開
・広く普及
■PDF/Aツールの現状
・現在の時点で公式にサポートしたツールはない(と思われます)。
■PDF/A-1とPDF1.4の関係
PDF1.4をベースとして、全体、グラフィックス、フォント、アクション、注釈、メタデータ、論理構造(PDF/A-1aのみ)、対話フォームについて要求項目、勧告項目、制限項目、禁止項目を設定しています。
・やるべきこととしては、大雑把には、フォントの埋め込み、デバイス独立カラー、XMP準拠のメタデータ、タグ付け(PDF/A-1aのみ)があります。
・禁止事項として、大雑把には、暗号化、LZW圧縮、外部コンテンツの参照、透明、マルチメディア、JavScriptがあります。
■メモ
なお、PDF/Aは、電子文書保管のひとつの部品にすぎず、すべてを解決するわけではなく、ソリューションにすることが必要です。
■参考資料
・ISO 19005-1 仕様書(2005年9月出版)
Document Management - Electronic document file format for long term preservation - Part 1: Use of PDF 1.4 (PDF/A-1)
・PDF/Archive Secures ISO Approval
・PDF/Archive
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年03月03日
PDF/A とコンシューマ・デバイス
PDF/A仕様はISOの標準になったことを以前に読んで頭の片隅にありました。
例えば、PDF/Archive Secures ISO Approval
これは、PDFを長期に保管するための仕様で、どうせ電子図書館用の仕様だろうからあまり重要じゃないだろうと思ってました。
しかし、アドビシステムズのBill McCoyのブログMore on PDF/Aを読むとどうやらそうではないようです。
PDF/Aは、アドビが、NTTドコモ、アクセス、ノキアの携帯電話などのPDFビューアや、ソニーの電子ブックビューアSony Reader PRS-500に提供しているPDFビューアは、PDF/Aをベースとして拡張したPDF/A+というべき仕様に基づいていると言っています。
これらのコンシューマ・デバイスでは、パソコンとは違って、CPU、メモリなどのコンピュータ資源が乏しいため、PDF1.6をフルに実装したビューアを動かすのは無理があります。
Bill McCoyによると、そういうコンシューマ・デバイス用に制限したPDF仕様としてPDF/Aが重要とのことです。
この他、PDF/Aが重要なポイントとして、次のことをあげています。
(1)AppleのQuartzのような異なるイメージング・モデルなどで動く代替ビューアを可能にし、クロス・プラットフォームでビューア開発ができる。
(2)新しい機能を使ったPDFが、古いあるいかサブセットのビューアで見えにくくなるという問題に焦点をあてている。
(3)PDFの中のスクリプトなどのプログラムを使えなくすることで、PDF表示のコンピュータへの依存性、セキュリティ上の危険性を減らす。
こうしてみますと、PDF/Aに対する認識を改める必要がありそうです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月18日
線の太さについてのPDFの仕様
昨日までは、PDFを作成する際の解像度設定、特に線の太さ、について検討してきました。これをまとめてみます。
PDFの仕様 (PDF Reference)では、線の太さはLine Widthというパラメータで指定することになっています。
Line Width に設定する値は0以上の数値です。このときの座標の単位はPDFを書くプログラムが自由に設定できます。なお、Line Width 0はデバイスで表示できる最小の幅という特別な意味があり、表示するときは常に1ドットの幅となります。
※PDF Reference Ver. 1.6 p.185 Line Widthを参照
1.PDFを作成する際のLine Width値の設定
(1) WindowsのGDIを経由する場合は、線の幅はGDIで設定するデバイス(ディスプレイ、プリンタ)の解像度から計算されるドット幅の倍数になります。WindowsのGDIもPDFと同様に幅が0の線は1ピクセル幅になります。従って、PDFでLine Widthが0になることはないはずです。
(2)直接PDFの命令を出力する、あるいは、PostScriptを経由する場合は、論理的な寸法を指定できます。この時、次のような場合に、PDFで線のLine Widthが0に設定されることが起こり得ます。
a. 幅をもたない線を引くことができるアプリケーションが、意図的にPDFにLine Widthを0に設定したとき。
b. 外部から入力された線の幅が、PDFを作成するアプリケーションが扱える最小の論理幅より小さいため丸めた結果0になってしまう事態などが起きる、など。これらの場合には、意図しない結果としてPDFの中の線のLine Widthが0になります。
2.PDFを表示・印刷する際のLine Widthの取り扱い
(1) PDFの中の線にLine Widthに0が設定されている場合は、デバイスで表示できる最小の幅、すなわち1ドット幅の線になります。この線は、例えばAdobe ReaderでPDFを表示してズーミングしていっても太さは変わらず、常にディスプレイ上では1ドット幅になります。解像度の小さいプリンタでは太い線になり、解像度の大きいプリンタでは極細い線になります。
このように線幅0の線の太さはデバイス依存となりますのであまり良くないとされています。
(2) 次に、PDFに0以外のLine Width が設定されている場合、PDFに設定されているLine Width は表示、印刷されるときどのように処理されるかを調べてみます。
PDFを作成したツールと表示・印刷するツールは別のものになることが多いと思います。そうなりますと、PDF作成時の解像度と、PDFを表示・印刷する時の解像度は異なることが多いでしょうし、完全に一致したとしても線の位置がデバイスのドットの並びと一致しないこともあるでしょう。
次の図に、このような例を幾つか挙げてみました。
図1 Line Widthはドットの幅の整数倍で位置がずれている例 (左)
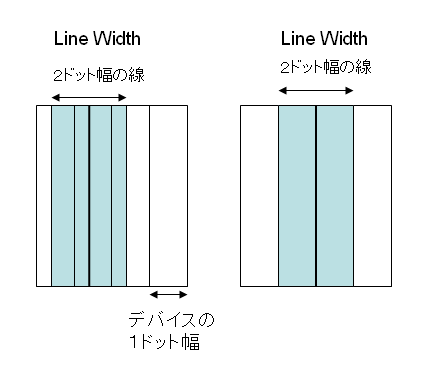
図2 Line Widthがドットの幅よりも狭い例
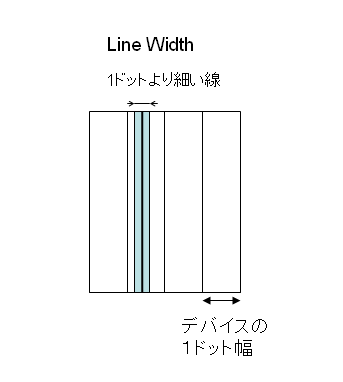
スキャン・コンバージョン
図のような論理的な太さ(幅)を持つ線を、表示・印刷デバイスはドット単位の塗り潰しに変換します。この処理をスキャン・コンバージョン(Scan Conversion)と言います。スキャン・コンバージョンのアルゴリズムは、PDFの仕様の一部として定義されているのではなく、各製品あるいはデバイス毎に最適な実装をすることになっています。
※PDF Reference Ver. 1.6 6.5 Scan Conversion Details (pp. 478~482)を参照
PDF ReferenceにはAcrobat製品のスキャン・コンバージョンについて記述されています。これはPostScript製品にも共通です。以下の説明は、PDFの仕様ではなく、Acrobatの実装のついての説明となります。
スキャン・コンバージョンの方法は、線、イメージ図形、フォントでは異なります。今回のような線の場合は、まず、PDFの中の論理的な座標系を、デバイスのドット単位の座標形にマップします。次に、論理的な座標系における線と少しでも重なるところがあるドットを塗り潰すという方法をとっています。こうすると、スキャン・コンバージョンの結果、線が消えてしまうことがなくなります。
つまり、上の図で示したような線は、デバイスの上では次のようなドット幅の倍数の太さの線になります。
図3 Line Widthはドットの幅の整数倍で位置がずれている例 (左)
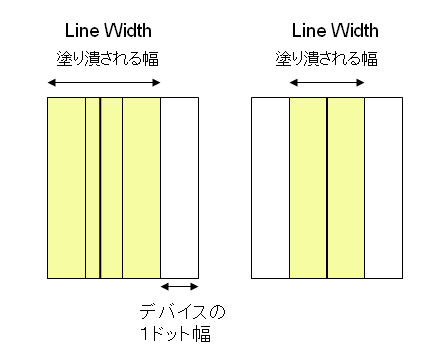
図4 Line Widthがドットの幅よりも狭い例
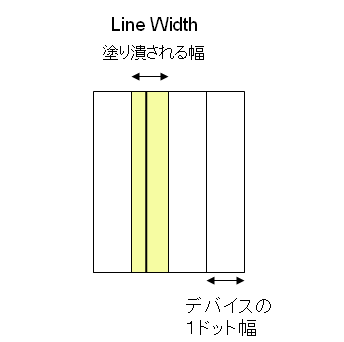
この方法では、図3のように、PDFでは同じ太さの線が、画面やプリンタに出力すると太さが変わってしまうことがあります。特に、解像度が低いデバイスに出力する時は、線の太さのばらつきが目立ってしまう可能性があります。そこで、PDF 1.2以降で、自動ストローク調整機能を用意しています。これがONの時は、線の太さを可能な限り均一になるように調整します。
※Acrobat6.0は、自動ストローク調整機能がPDFの中でON/OFFのどちらに設定されていても、常にONとして処理します。(PDF Reference V1.6 実装ノート 70 (p.1018))