2008年07月06日
PDFの将来を考える(5)紙にマルチメディア?
Acrobat 9では、PDFにマルチメディア機能を統合したり、Officeのネイティブ形式を結合したり、あるいは、AcrobatやAdobe Readerを使ってのWebサービスなど、電子の紙の範囲からかなり離れた機能を強化しているというお話をしました。
アドビシステムズやマイクロソフトは、現時点では、圧倒的な市場支配力を持っており、市場の方向性にかなり大きな影響を与えることができると思います。しかし、本当に、PDFにマルチメディアを統合することがユーザにとって良いのでしょうか?
どうも、違うと思えてなりません。なぜかと言いますと、PDF自体、電子機器の画面に表示するのはかなりの無理があります。
一番、分かりやすいのは用紙サイズの概念です。PDFは紙への印刷を暗黙に想定しているため用紙サイズの概念を持つメディアです。これが、良くも悪くもPDFの性質を決定付けています。
ページの概念も用紙の概念も、皆、紙であるところから派生しているもの。
ところが、コンピュータのディスプレイは紙ではなく、用紙サイズの概念はありません。Webブラウザの成功、ハイパーリンクも紙の世界では起こり得なかったことです。
現在、携帯電話がインターネットの端末として、PCを超えた主流になろうとしていますが、そこで一番困るのはPDFの扱いです。ただでさえ、携帯電話の世界では取り扱いしにくいPDFをベースとしてマルチメディアを統合してしまうと、携帯電話などではますます困ることになると思います。
マルチメディアはPDFに統合しないで、直接携帯電話などの画面で表示するようにする方がずっと良いのではないかと思います。
むしろ、PDF自体もっとシンプルにして、携帯電話を含む様々な媒体で簡単に表示できるようにする方がより適切な方向ではないのでしょうか?
投稿者 koba : 08:00 | コメント (2) | トラックバック
2008年06月30日
DITAヨーロッパ・ミュンヘンで開催 など
2005年から2007年まで毎年11月に、欧州で開かれていましたDITAの欧州会議(DITA European Conference)は、今年2008年は11月17日から18日にドイツ・ミュンヘンで開催されるようです。第4回目の開催となります。
主催者からYahooのDITA会議に発表者募集の案内が投稿されました。
2008 DITA Europe Conference Call for Speakers
このほか、DITA関係の予定としては、DITAのOpen Tool Kit V1.5の開発が始まっています。
Plans for future versions of the DITA Open Toolkit
DITAのOpen Tool Kit(OTK)は、現在V1.4で、これは、DITA V1.1に対応します。DITA V1.2仕様の開発がOASISで現在行なわれており、このV1.2仕様の確定に向けてOTK V1.5の開発を並行して行なっていこうと計画しているようです。
このマイルストーンはこちら。
Plans for DITA Open Toolkit version 1.5
なお、アンテナハウスは、デジタルコミュニケーションズと共同で、DITA入門セミナーを来る7月18日(金曜日開催の予定です。
現在、申し込み受付中ですが、予想よりも速いペースでお申し込みをいただいています。日本でもDITAに対する関心が高まっているようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年05月26日
PDFによる情報保存の法的な有効性 (9) — 書面の定義は?
表題について、今日は、商業登記法を調べていました。
商業登記法
商業登記はオンライン申請ができます。この申請の手続き根拠は、商業登記法第17条とされています。
商業登記法第17条では、「登記の申請は、書面でしなければならない」とあります。
あれ?先日、会社法を見ていましたら、書面は紙で、それと、並列して電磁的記録を上げていたように思いました。もし、会社法の用語と解釈が正しいとしますと、商業登記法第17条では、電子申請はできないのではないでしょうか。
と思って調べましたら、「行政手続等における情報通信の技術の利用に関する法律」(オンライン化法)という通則法形式で、書面に代えてオンラインで可能としているようです。
しかし、問題は、この通則法のために、書面という言葉が混乱してしまっていることです。
例えば、会社法の第67条では、創立総会の議決権の行使方法の定め方を決めています。
第68条では、創立総会に出席しない設立時株主が書面または電磁的方法によって議決権を行使することができることを定款に定めた場合は、創立総会の召集通知書は書面でなければならないとしています。そうでないとき、ある条件を満たせば、電磁的方法で通知を発することができるとあります。
このように、会社法をざっと見ますと、書面は紙であり、それと別の手段として電磁的方法という筋を通しているように見えます。つまり、書面と電磁的方法は相反する手段です。
しかし、商業登記関係の規程では、随所に、書面が電磁的記録で作られている場合、という文言が出てきます。
例えば「商業・法人登記の申請書の添付書面を電磁的記録で作成している場合について」
商業登記関係規定では、書面は紙で作ることも電磁的記録で作ることもできるという風に解釈できる文章が随所に出てきます。
会社法にも、商業登記法にも、書面の定義はありません。しかし、会社法と商業登記で、書面の定義が逆さまになってしまうのは、如何なものでしょうか?
例えば、PDFで株主総会議事録を作成しますと、会社法では電磁的記録であって書面ではないことになりそうですが、商業登記法では書面を電磁的記録で作ったという解釈になってしまうようです。変ですね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年05月24日
電磁的記録は改ざんされやすい?
昨日は、印紙税についての小泉首相の答弁をご紹介しましたが、この答弁を読み、つくづくと考えてしまいました。
現在、何らかの書類を作る時、ほとんどの人は、パソコンのソフトウエアを使っていると思います。
もはや、現在の社会人で書類を、手書きで作る人はほとんどいないと言って良いと思います。パソコンで書類を作れば、印刷の際には、プリンタにお世話になっているはずです。ですので、書面の書類といってもその、ほとんどは電磁的に作成されていることになります。
それにも関わらず、「印紙税は、経済取引に伴い作成される文書の背後には経済的利益があると推定されること及び文書を作成することによって取引事実が明確化し法律関係が安定化することに着目して広範な文書に軽度の負担を求める文書課税であるところ、電磁的記録については、一般にその改ざん及びその改ざんの痕跡の消去が文書に比べ容易なことが多いという特性を有しており、現時点においては、電磁的記録が一律に文書と同等程度に法律関係の安定化に寄与し得る状況にあるとは考えていない。」
という認識をしているのですが、この中には、技術に関する認識不足があるように思います。少し分解して考えて見ます。
1.「文書を作成することで、取引事実が明確化し、法律関係が安定するという経済的効果があること」
○これは、衆目の一致するところと思いますし、正しいでしょう。
2.「電磁的記録については、一般にその改ざん及びその改ざんの痕跡の消去が文書に比べ容易なことが多い」
○これは認識不十分です。電磁的記録に電子署名を施すことで、電磁的記録の改ざんは、書面の改ざんよりも困難になります。
3.「電磁的記録が一律に文書と同等程度に法律関係の安定化に寄与し得る状況にあるとは考えていない」
○この認識は2項が真という前提に基づきますが、2項が真でない場合はこの認識は誤っていることになります。
電磁的記録に適切な処理(電子署名)を施すことで、書面よりも改ざんを困難にできる、というのが正しいのですが、しかし、恐らくは、小泉元首相の答弁と同じような既成概念をもっている人は非常に多いと思います。
このあたりの認識を正すために、電子署名についての、もっと分かりやすいアピールが必要です。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年05月11日
WordでDITAをオーサリング
アンテナハウスではWord2007でDITA XMLを編集するシステム開発のご提案を再開します。
もう既に、ブログで何回かDITAのことを取り上げてきましたし、ご存知の方も多いと思いますが、DITAとは、内容をトピックという小さな・再利用可能な単位に分けて記述し、マップを使ってトピックを組み合わせることで、マニュアルなどの文書を表現し、コンテンツ情報を再利用するための仕様です。
以前は、Word2003でご提案していましたが、昨年、Microsoft Office 2007にバージョンアップしたことなどもあり、しばらくWordによるDITAの編集について、見直していました。
XMLのオーサリングは非常に大きく、また、難しい課題ですが、コンテンツを制作するには、どうしてもオーサリングを避けて通ることはできません。
そんなことで、WordによるDITAの編集を、今度は、Office 2007でご提案していきたいと考えています。
DITAのトピックとは、わかりやすく言えば、マニュアルの章や節などにあたります。オーサリングを章や節の小単位レベルで行うことによって分割管理や再利用を可能にします。
分割レベルが大きすぎると編集に負担がかかるとか、再利用が出来なかったりします。
分割レベルが小さすぎると今度はシステム的に複雑になったり内容の統一性(整合性)が失われます。
Wordで編集する単位をどの位の単位で行うのが最も効率がよいかなどをさらに検討していく必要があります。
しかしながら、それらは単体では本という単位にするための情報はどこにもありません。これを定義するのが構成情報(DITAでいうところのmap)です。バラバラのトピックをどのような順でどのような構成で一冊の本に仕上げるかという定義をします。
お問い合わせは、sis@antenna.co.jpまでどうぞ。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年05月04日
DITAの管理をSubversionで行うことについて
DITAの管理をSubversion(SVN:ソースコードを管理するバージョン管理システム)で行うことについての可否(YahooのDITAグループ)
【質問者】
始めたばかりの医療分野のソフトウェア製品開発でドキュメントを作成する。担当者は2人。開発者はWordで文書を出してくる。これまでに500ページだが、直ぐに倍増するだろう。DITAを導入しようとしている。設計者は、文書をSubversionで製品のプログラムと同じように管理し、製品のビルドと同じように毎日ビルドしたいと言っている。昔の文書も含めPDFに出す。
Content Management and DITA docs
【意見1】
・Subversionで管理するのは良い。
・文書を毎日ビルドするのも良い。
・最初にDITAの計画を作り、枠組を作り、文書を出力できるようにし、それから昔の文書を移行すると良い。
Steve
【意見2】
・開発者の文書をDITAに継続的に変換するのは望ましくない。DITAのためにはDITAで書くほうが良い。
・ビルドは簡単。
・プログラマと同じようにDITAの執筆者も定期的に執筆、ビルド、テストをするのが良い。
・毎日というのは不合理とは思わない。執筆者が毎日文書を配布することは薦めないが。
・製品と文書のビルドを統合するのは良い。
Troy Klukewich
【意見3】
・我々はソースをCVS(ソースコードを管理するバージョン管理システム)で管理しており、DITAのソースは別のSVNを使っている。
・SVNの幹を使う方針だ。製品をリリースする毎にタグを付けて、先へ進める。
・製品単位で文書化しているが、機能単位にするように要求を受けている。DITAのソースとプログラムのソースが一緒だと、機能単位の内容をどこに置くか困るのではないだろうか?
Andy Hall
【意見4】
・内容をSVNで管理するのは問題ない。
・プログラムとは別の領域を確保するように。そうしないと、文書のリリースのためにソースのリリースを止める必要が生じると説明したらどうか。
・文書を、一括ではなく、ひとつひとつ変換していくように。
・夜間にバッチを動かしてビルドする。
・承認印なしで、出荷させないように。
Steve
こうしてみますと、DITAのコンテンツ管理にSVNを使っているケースは結構多いように思います。
考えて見ますと、この質問はDITA特有ということではないように思います。製品ドキュメントをXMLで記述し、XML文書をSVNやCVSで管理しておいて、製品のビルドに合わせて、PDF、HTML、ヘルプを作りだすのは簡単にできます。
例えば、弊社の「書けまっせ!!PDF」の場合、製品ドキュメントはXMLで作成しています。XMLからPDFファイルをFormatterで作成し、同時にCHTMLヘルプを生成しています。ドキュメントはCVSで管理していますので、上述とほとんど同じことをやっていることになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月28日
DITA関連のコミュニティと参加者人数など動向
YahooのDITAメーリング・リストに27日投函されたメールにDITA関連のコミュニティと参加者人数の情報が載っていましたのでご紹介しておきます。
1.Yahooメーリング・リスト
dita-users@yahoo.com (参加者数:1900人)
○アーカイブはこちらです。
http://tech.groups.yahoo.com/group/dita-users/messages
ちなみにYahooGroupで見ますと、約1,760人となっています。なお、Yahoo のXSL-FOグループは、約1,500人です。SVG-Developerは約7,900人。
2.OASISの公式コミュニティ DITA.XML.org
<http://dita.xml.org/> (メンバー数:1300人)
3.DITAニュース
the DITA News <http://www.ditanews.com/>/DITA Users<http://www.ditausers.org/>コミュニティ (メンバー数:600人)
4.STC: Society for Technical Communicators
<http://www.stc.org/> (参加者数:13,000人)
5.TECHWR-L
<http://www.techwr-l.com/techwhirl/index.php3> 寄稿者:2,500人
6.Content Wrangler Community
<http://thecontentwrangler.ning.com/>
(参加者 1,600人のソーシャル・ネットワーク)
こうしてみますと、DITAの専門ネットワーク参加者は、まだ2,000人弱ということになりそうです。
2006年、2007年と過去2回DITAに対する関心が高まっていますとお伝えしましたが、2008年3月まで見ましても、まだ、YahooのDITAグループへの発言数が増えています。
■月間発言数の推移
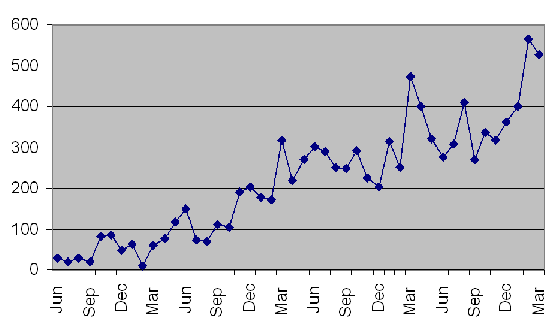
ご参考:
・2007年08月16日 DITA、初のバージョンアップでV1.1となる
・2006年08月24日 DITA への関心が急激に高まっています
DITAは、かなり難しいですから、腰を据えて取り組んでいきたいものです。
なお、2005年から2007年まで毎年11月に、欧州で開かれていましたDITAの欧州会議(DITA European Conference)は、今年2008年はどうも開催されないようです。主催者の話ではドル安で開けないということだそうですが。大変残念です。米国のXML業界の景気は相当悪いのでしょうか?でも欧州のXML業界は景気が良さそうに思いますけど。
○2008年6月26日 DITAヨーロッパがミュンヘンで開催のアナウンスがありましたので上記の情報を訂正します。
PDF千夜一夜の2008年6月30日で紹介しますので、ご参照ください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月23日
オープンソース長期署名ライブラリーのソースが公開されました
弊社の関連会社 ラング・エッジは、以前よりXML長期署名を開発し、ライブラリーを公開していましたが、この程、Le-XAdESライブラリのソースのソースが公開されました。
Le-XAdESライブラリ / XAdES署名ツール XAdEStool
いままで、長いことβ版でしたが、4月にV1.0になったのかな?しかし、知らない間にV1.01になってます。ずっといままで、バイナリの公開だけだったようですが、遂にソースの公開に踏み切ったとは、なかなか大胆な決断です。
長期署名は、まあ、会社がなくなっても検証されねばならないでしょうし、オープン・ソースにする方が良いかもしれませんね。
私的には、オープン・ソースの考え方はあまり好きではありませんけれども。
長期署名は、これから、だんだん重要度が増していくと思います。しかし、実際のところは長期署名の前に、署名対象になる電子ファイルの長期的な利用可能性をどうやって保証するか、ということの方がその前提になる重要な課題だろうと思います。
電子ファイルに署名をつけて、それを遠い将来に検証して、改竄されていないことを確認できたとしても、肝心の電子ファイルを人間が開いてみることができないのであれば、あまり意味がないのは明らかです。
例えば、いまから15年前を考えてみます。15年前といえば、1993年です。ワープロ文書について言えば、ワープロ専用機とWindows3.1の時代です。いま、Windows3.1の電子ファイルはどこまで読むことができるでしょうか?ワープロ専用機の電子ファイルにいたってはほとんど読めないでしょう。
こうしてみますと、なにも考えないで電子化して、15年もたてば電子ファイルのほとんどは開いてみることさえできないだろうと予想されます。いまから、15年後、果たしてWindowsのPCがどれだけ使われているでしょうか?携帯電話に、あるいは、ブラウザ上のアプリケーションにすべてが統合されてしまっている可能性すらあります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月20日
DITAの価値は、コンテンツ再利用、シングル・ソース、標準の3点にあり
米国時間の18日(日本時間では19日)、DITA指数という面白いデータが発表されました。
ボストンのDITAユーザズ・グループで過去2年間にDITAのビジネス的な意味に関連して、よく聞かれた質問から、10項目を取り上げて、質問表とし、その回答をもとに指数化したものです。
4月18日時点のDITA指数表は次のようになっています。
| 項目 | 平均点 |
|---|---|
| コンテンツ管理システムを使用しているか? | 5.1 |
| コンテンツを構造化しているか? | 3.5 |
| コンテンツをどの程度再利用しているか? | 9.5 |
| シングル・ソース(コンテンツをマルチ形式で出版しているか?) | 8.7 |
| コンテンツを翻訳しているか? | 6.4 |
| メタデータはマークアップされているか? | 4.4 |
| コンテンツはモジュール化されているか? | 5.8 |
| 条件処理(コンテンツを聴衆毎に変えているか?) | 5.0 |
| タスク志向とミニマリズムに従っているか? | 4.5 |
| 標準化の重要性(共有されたプラクティスを使いたいか?) | 9.0 |
これを見ますと、DITAの価値として
○コンテンツ再利用
○シングル・ソース
○標準
の3項目を重視している人が多いということが分かります。
・DITA指数表
・DITA指数とは?
・DITA指数のための回答フォーム
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月16日
標準文書作成支援ツールについてのご紹介
社団法人 情報通信技術委員会 (以下TTC)が試作した、「標準文書作成支援ツール」に関する資料がXSL Formatterのケーススタディとして公開されましたので、ここにご紹介します。
ISOや、ITU-T(国際電気通信連合 電気通信標準化部門)などで作成している標準文書の作成には、XMLを使うのが望ましいのは、多くの専門家が同意するところと思います。
しかし、XMLはオーサリングの方法が大きな課題です。XML専門のエディタは色々ありますが、これは多くの人にはなかなか使いこなせません。一方、WordなどWYSIWYGの編集ソフトは、見栄えをたよりに文書を作成しますので、構造化された文書を作るにはあまり向きません。
ということで、XMLにより構造化された文書を簡単に作成するツールは、ずっと大きな課題なのですが、子今回、TTCはブラウザで一般的に用いられているツリー構造のインターフェイスを用いて、標準文書の構造を表現することで、「標準文書の論理的構造を保ったまま文章作成が可能であること」の条件を満たしたシステムを試作されたとのことです。
■ご案内
【第21回 XSLSchool】【第3回 XSL-FO指南塾】4月24日~4月25日開催
☞ XSLSchoolの案内書・参加申込書
☞ XSL-FO指南塾の案内書・参加申込書
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月14日
日本語ワープロやエディタのビジネスは成立するのだろうか?
エルゴソフトのEgwordの事業終了の話が大きくWebででているのに今頃気がつきました。
エルゴソフトegword、egbridgeパッケージソフト事業終了のお知らせ
そういえば、販売終了のお知らせが来ていたな、と思い出しました。エルゴソフトとはビジネス上の接点が無い訳ではなかったのですが、なにしろ先方のOSが、私がとっくに見捨てたMacということであまり注意しないままに時間が経過してしまったのが残念。個人的には1980年代から1990年初頭位まではMacの大ファンでした。Windows95の登場とともに完全にMacを見捨てて、それ以降ほとんど見向きもしていません。
さて、エルゴソフトの事業終了の話ですが。エルゴソフトのEgwordは、日本のMac界では大変に有名な存在ですし、製品としても優れていて、優秀な技術者もいたようです。それにも関わらず、事業を終了しなければならない、という決断に至ったのはなぜでしょうか?
会社の経営という観点から、やはりチェックしておかねばならない課題と思います。
といっても手元には公開された情報以外はほとんどありません。とりあえず、分かるのは、同社の沿革
http://www.ergo.co.jp/company/history.html
・設立 1984年ですが、これはアンテナハウスと同じ年です。EGWordをこの年発表しています。
・1985年日本語入力ツール「EGBridge」Ver.1.0を発表。
・1986年には、日経の年間優秀製品賞受賞を受賞しています。
・1987年EGTalk、EGBookを発売
・1988年EGWorksを発売 CANON Navi用です。
・1989年PC9801用ワープロソフトEGLightを発売
・1990年にEGLightを、J3100、FMR、PS/55用に発売
・1991年にJ3100用EG Calcを発売、DOS/V用EGLightを発売
・1992年3Dグラフィックソフト「Swivel 3D Professional」「Swivel Man」「Model Shop II」、アニメーション3Dソフト「LIFE FORMS」を発売
・1993年定型文書の作成・管理のための「EGForm」を発売。この年光栄が株式を100%取得。
・1994年に本社、東京営業所、東京開発センターを東京都渋谷区に統合。この年は新しいEGwordのバージョンを出していますが、新製品はありません。また、Windows用のEGBridgeを発売しました。
※株主の変更、事業所統合、新製品なし、といった状況から、恐らく、1993年までの事業の見直しが行われたのものと推測されます。
・1995年もEGWord、EGtalk、EGBridgeといった初期からの製品のバージョンアップのみを行っています。Windows用のEGWordを出しています。
・1996年からまた、EGWord、EGBridge以外の新しい製品を出し始めました。2001年位まで新製品を色々と出しています。
・2002年頃からまたEGWord、EGBridgeに回帰しています。
・2008年1月にパッケージソフト事業を終了するまで、新しい製品を出さずに、ほとんどEGWord・EGbridgeに世界に閉じこもっています。
こうして、エルゴソフトの沿革をざっとチェックしますと、(1)最初にワープロソフト、日本語入力ソフトで成功し、(2)表計算、3Dグラフィック等の製品を出して事業拡大を図る、(3)一端縮小し初期のワープロと日本語入力の原点に返り、(4)再度、新しい製品にチャレンジ、(5)また日本語ワープロ・日本語入力ソフトに回帰、という繰り返しを行っているように見えます。
中小企業が成長・発展するには:
・事業の多角化は絶対条件である。
・従って、経営者は多角化に挑戦しなければならない。
・しかし、多角化に成功するのは非常に難しい。
ということが、エルゴソフトの沿革にまるで教科書の通りに描かれていると言ったら言いすぎでしょうか?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月13日
XAML, XPS, WPF, XPSviewer, Silverlight ? その3
Codezineに掲載されたSilverlightの文書形式について読んで見ました。
Silverlight入門(1)-XAMLの文法
参考:MSDN のSilverlightリファレンス
・HTML上のOBJECT要素によってSilverlightをブラウザに表示するか、Silverlight SDK付属のSilverlight.jsを使い、createObject関数を呼び出す。
・SilverlightのコンテンツはXAMLで作成する。その記述方法は、XMLの要素として、XAMLのオブジェクト名、XMLの属性としてオブジェクトのプロパティとその値を指定する。属性を使う代わりに、属性と同等のプロパティ要素を使う方法もある。
・例えば、文字列はTextBlockオブジェクトを使い、線を引くならLineオブジェクトを使うなど。オブジェクトの入れ物としてのCanvasオプジェクトも使える。
続き: Silverlight入門(2)-図形やテキストを扱うオブジェクト(Codezineに登録しないと閲覧できないと思います。)
Silverlightで使えるXAMLのオブジェクトの種類は、まだ非常に機能的に少ない。また、この解説を読んだ範囲では、Silverligh用XAMLはXMLによる仕様書としてはそれだけで独立ではなく、Silverlightプログラム依存になっていると思います。つまり、オブジェクトとプロパティについて完全な仕様として記述されていないので、レンダリングがそのデータを解釈する実装に依存するということで、Microsoft OfficeのOOXMLも同じような性格を持っています。
XAML全体が、実行プログラム依存かと言いますと、そうでもなく、マイクロソフトのXAML の概要を見ますと、XAMLのドキュメントには固定ドキュメントとフロー・ドキュメントの2種類があると説明されています。
固定ドキュメントは、WYSIWYGアプリケーション用とのことです。このあたりは仕様を詳細にチェックしないとはっきりは言えませんが、レンダリングされる結果が常に同一になるように仕様上保証されていれば、アプリケーション独立になることがかなり期待できます。
XPSはXAMLの固定ドキュメントをひとつ以上とその表示に必要なリソースをパックしたものとのこと。
つまり、XPSはXAMLのサブセット+資源のパックということです。
SilverlightでXPSをどこまで表示できるかという問の回答は、Silverlightがサポートしているオブジェクトの種類と、あとは、フォントなどのリソースをサーバからクライアントにどこまで送信できるか、という問題もありそうです。サーバ上にXPSと共に置いたフォント・リソースを解体してクライアントに送信したら、ライセンス違反の危険があるかもしれません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月12日
XAML, XPS, WPF, XPSviewer, Silverlight ? その2
XAMLをつかった、「New York Times」のリーダは、2007年から有償配信サービスをしているようですが、日本では、イーストがXAMLを使った記事配信に熱心に取り組んでいるようです。
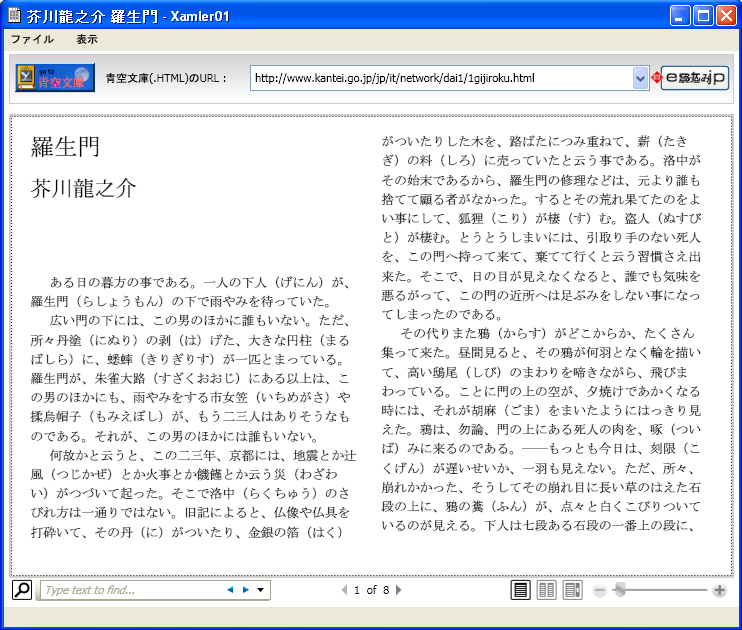
イーストのサイトにXamler01.exe 青空文庫ビューアが公開されていました。早速、ダウンロードしてみました。
○羅生門をXamler01.exeで表示したところ。
○XAMLのビューアは、ウインドウを狭くすると1段に、広げると段数が3段になります。
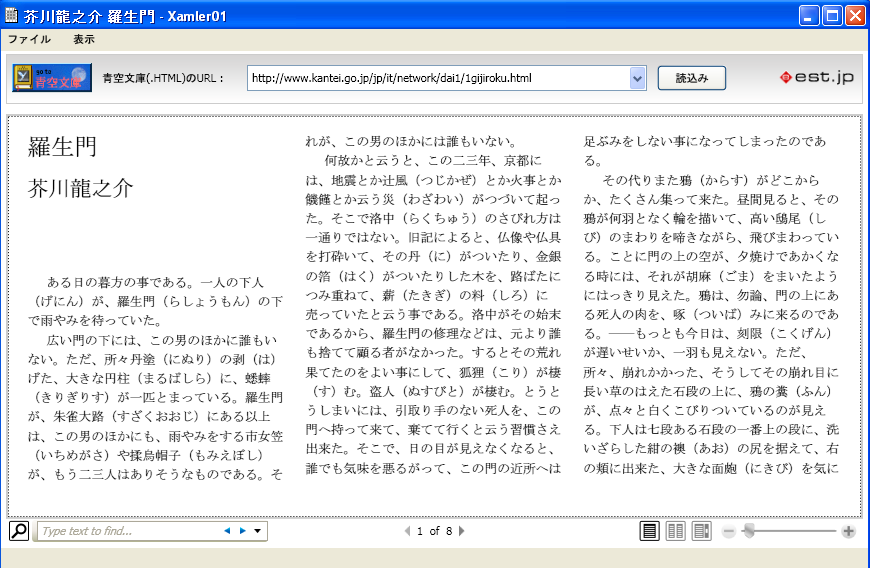
ブラウザと比べると、格段に読みやすいように思います。また、PDFと違って、固定のサイズもつ紙のページを画面に表示するのではない、と言う点で、確かに次世代の電子ファイルビューアの片鱗があります。
しかし、日本語組版はお世辞にも綺麗とは言えませんね。
○拡大したところ
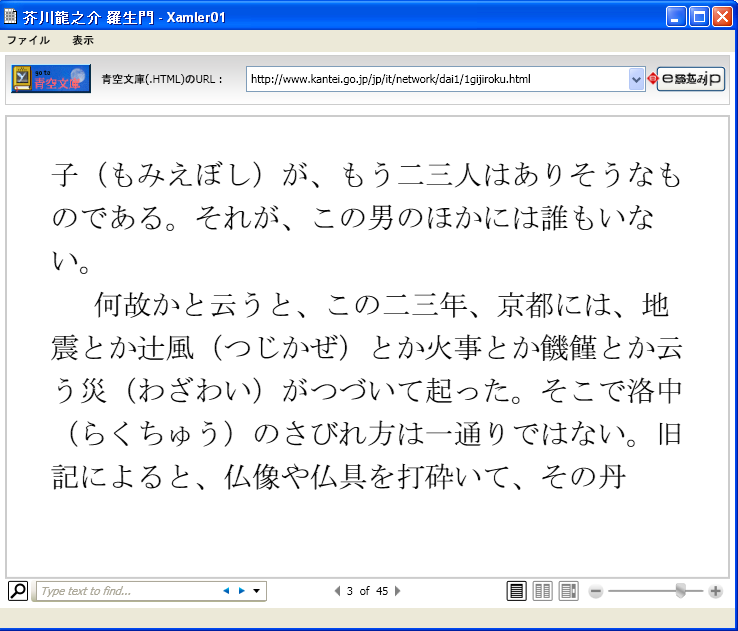
Xamler01では、テキスト中心の表示になっています。少し複雑なHTMLページはうまく表示できません。
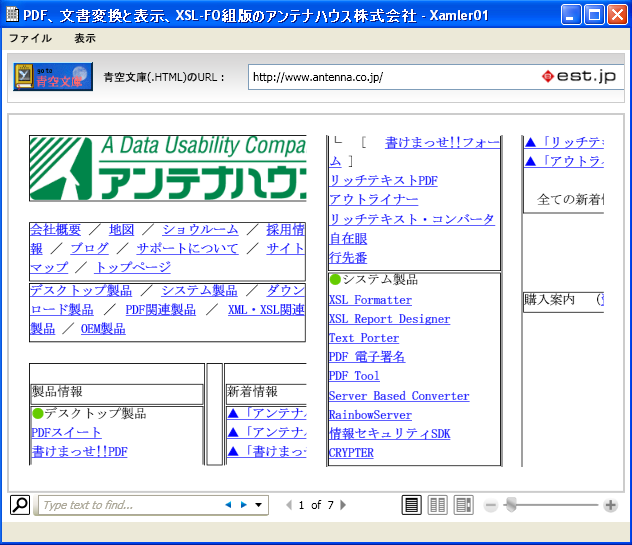
Xamlerには、Silverlight版とかMobile版とかいろいろあるようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月11日
DITA アーキテクチャ仕様書を翻訳しました
1月13日に「今年は、DITAを積極的にやろうかと思案中です。」とお話しました。DITAを勉強するために、OASISのDITAアーキテクチャ仕様書を翻訳していましたが、ほぼ出来上がりました。
こちらでご覧いただくことができます。
OASIS DITA Version 1.1 アーキテクチャ仕様
OASIS標準
2007年8月1日
この仕様書は、『DITAの入門を目的とはしていないし、ユーザ・ガイドでもない。この仕様が意図する聴衆は、DITA標準を実装する人であり、ツール開発者や専門化する者を含む。』と本文にもありますとおり、ユーザ向けのものではなく、かなり難しいと思います。
ちょっと気になっていますのは、Specializationという言葉の日本語訳です。私の訳では「専門化」と言う言葉を使いましたが、IBMのWebでは「特殊化」という訳を充てています。
DITAは、トピック型という一塊の情報単位が基本です。トピックの元祖は一般トピックですが、一般トピックをもとにして、コンセプト、タスク、参照、用語集(V1.1から)という専門化した文書型トピック型を作り出します。
(訂正)トピック型は文書型ではありませんでした。
また、トピックを組み合わせて文書にするマップがあります。マップには、一般のマップの他、本を作るためのブックマップ(V1.1から)という用途を絞った専門的なマップがあります。ブックマップは、一般のマップをSpecializeしたものなのですが、こういうものを特殊化といって良いのかどうか、専門化という方が妥当なのではないか、と。専門化なのか特殊化なのか、どちらでも良いような気もします。
なお、DITAを実際に使用したり普及させるには、もう少しやさしいDITAの入門書が必要ではないかと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年04月10日
XAML, XPS, WPF, XPSviewer, Silverlight ?
Windows Vistaに伴って、いろいろと新しいMSのアーキテクチャが導入されました。もう、先刻ご承知の方が多いと思いますが。
○XAML:Extensible Application Markup Language
XMLベースのプレゼンテーション言語
○WPF:XAMLローダを備えておりXAMLで記述されたデータを実行するらしい。
○XPS:XML Paper Specificationは、XAMLのサブセットで電子ファイルを記述する言語。
○XPSは、XPSViewerで表示することができる。
○Silverlight:以前は、WPF/E(Windows Presentation Foundation/Everywhere)と呼ばれていたらしい。WPFのマルチ・プラットフォーム版。
ということは、SilverlightでもXPSを表示できそうな気がします。調べてみますと、Delayさんという人が、SilverlightでXPSを表示するプロトタイプを作ったようです。
Lighting up the XML Paper Specification [Proof-of-concept XPS reader for Silverlight!]
こんな感じで動きます。

○FireFox+Silverlight2
しかし、まだ、Silverlight自体ではXPS表示をサポートしていない?
を見ますと、この人も私と同じことを考えたようで、SilverlightでXPSを表示できないかと、Googleで検索しても、Delayさんのプロトタイプしか出てこないぞ、と言ってます。
そうしてみますと、XPSをSilverlightで表示するのは、なにか作らないとできないということなんでしょうか。
Windows環境であれば、XPSViewerがあれば、XPSを表示できますので別にSilverlightを必要とはしないと思います。Silverlightが、真にマルチプラット・フォームで動くのなら、XPSをSilverlightで表示するのにも意味がありそうに思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年03月28日
XSL-FO 2.0 の要求項目 第2版 公開
W3CのXSL FO作業グループは、XSL-FO 2.0の要求項目の第2版を26日(日本時間27日)に公開しました。
Extensible Stylesheet Language (XSL) Requirements Version 2.0
W3C Working Draft 26 March 2008
XSL-FO2.0については、現在、どのような機能を拡張すべきかについてのアンケートも行われています。
Information needed to answer XSL 2.0 Requirements Survey (2008年9月30日まで)
なお、日本語組版については、W3Cのタスクフォースとして日本語組版についての要求をまとめる作業が行われています。これもそろそろ、取りまとめられる予定です。
ちなみに、上記の要求項目第2版の
6 Further improved non-Western language support
の部分を見ますと、
---ここから---
Specifically, the Japanese Layout Taskforce is creating a document about requirements for general Japanese layout realized with technologies like CSS, SVG and XSL-FO. The document is currently in draft stage and is being developed further by the Japanese participants in the task force. This document will be an input to the XSL working group as a source of requirements.
---ここまで---
となっていて、日本語組版に関するタスクフォースがまとめた資料は、XSL-FO 2.0 の要求項目への情報源として使用される予定になっています。
XSL-FO 2.0が、日本語組版に関する規定が盛り込まれた形で完成するのは、少なくとも後、数年は掛かることが予想されます。少しずつではありますが、Webで綺麗な日本語組版ができる時代に向かって進んでいることは確かです。
○日本語組版のタスクフォースについて
Japanese Layout Taskforce
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年01月23日
XPS(XML Paper Specification)の将来
XPSが出てからそろそろ1年たちますが、まだあまりXPSを見かけることがありません。XPSって現実に使われているのでしょうか?
このところ、普段見かける、あるいはWebなどから配布されている電子ファイルの流通形式は、ほとんどPDFだけです。
先日、プリンタ向けのXPSのレンダリング・ソフトの会社で話を聞きましたが、まだ、一部のプリンタ・メーカを除くとあまり熱心ではないとのこと。特に米国では、HPがプリンタの市場を主導しているのでHP次第らしいです。
見ますと、いちおう、かなり昔、HPもXPSをサポートするというニュースが流れています。
Photo printing under Windows Vista
しかし、HPにとってXPSをサポートする意味はあまりないのでは?
XPSは、PDFと比べると仕様もすっきりしていますので、アプリケーションを作るにはやり易そうなんですが、ただ、XPSがもっとポピュラーになって、XSP形式で作成されたファイルがもっと出回ってこないと、アプリケーションを作ってもなかなか、身近なものになりそうもありません。
プリンタのメーカにとって、XPSサポートはそれなりの売上に繋がっているのだろうか?余計なことではありますが、少々気になりますね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2008年01月22日
Office OpenXML形式のISO投票でのコメントへの対応完了
Microsoft Office のファイル形式「Office Open XML Formats」のISOへの提案”ISO DIS 29500”は、ISOのFast Trackの投票では、賛成者が足りませんでしたが、2月のISOの「Ballot Resolution Meeting」までに、投票時に集まったコメントを反映して仕様書を改訂し、再検討されることになっています。このことは、昨年12月のXML開発者の日に国際大学の村田さんから詳しく報告がありました。
http://d.hatena.ne.jp/StL/20071221/p1
の「OOXMLの投票結果とballot resolution meetingの予測」を参照。
ECMAは1月14日コメントへの対応を終了して各国のISO関係者にレポートを提供したと発表しました。詳細な資料は公開されていませんが、概要がこちらに報告されています。
Proposed dispositions for National Body comments on DIS 29500 complete – New phase to begin
3500ものコメントが集まったということですから、これをすべて検討するのは大変な作業だったろうと思います。以下に、ざっと纏めました。
1.言語タグ
最初の提案では、言語を識別するのに自然数の組を使っていたが、これは、言語についてはISO 639、書記法についてはISO 15924に従うように変更。
2.日付と関連する計算
a)表形式における日付の保存を、ユニークな数値で保存していたものを、ISO 8601標準で定義する形式に変更。
b)1900年以前の日付
ECMAの案では、1900年以前の日付を計算する法則を規定していなかったが、ISO 8601に規定するように1900年以前の日付も計算できるようにした。
c)閏年の計算
ECMA案では、昔の表計算(Lotus 1-2-3)との互換性を保つために1900年を閏年として扱っていたが、これは、Lotus 1-2-3のバグを継承したものなので、正した。
3.仕様の主部分からの機能
既存文書・過去との互換性を維持するためにある機能を永続的なものにしないための取り扱い。
主なものは、閏年のバグ、VML、”AutoSpaceLikeWord95”のような互換性のための設定は、付録に移し、新しい文書の生成では使わないように推奨することにした。
a)VML
VMLについては、すべて削除せよとか、付録に移すべきという意見があった。ECMAはVMLを、仕様本体から除外することに合意した。VMLが使われていた箇所では、すべてDrawingMLを使用可能とした。VMLは、将来、DrawingMLにすべて取って代わられることになる。
b)互換性設定
古いアプリケーションとの互換性設定に関する記述を詳しく書くと共に、付録に移した。
4.仕様への適合性・構成
開発者が自分達で重要と考える機能だけを実装して、かつ、仕様準拠であることができるように。
a)適合性
WordprocessingML, SpreadsheetML, PresentationML, OPC、拡張性のそれぞれについて仕様適合性を記述した。
b)構成の変更
仕様を、(ア)DIS 29500-1(WordprocessingML, SpreadsheetML, PresentationML, SharedML)、 (イ) DIS 29500-2 (OPC:パッケージ化)、(ウ)DIS 29500-3(拡張性)の3部構成とした。
5.ページ境界
ページ境界として使える、グラフィック・オブジェクトをカスタム化可能とした。
6.文法にISO標準を使用
表計算の計算式、フィールドをISO/IEC 14977:1996を使って記述。
7.オブジェクトのリンク技術
オブジェクト・リンク技術について、KDE デスクトップ、GNOME対応のサンプルを増やした。
8.カラー
W3CのSVGに適用されているカラー定義を使うようにした。
9.パスワードのハッシュ化
ISO/IEC 1011803を使うようにした。
10.国際化
労働日と週末の定義方法をより自由にしたり、多言語対応のため右から左へ書く言語と左から右へ書く言語の表記に関する説明など、多言語対応を追加した。
11.アクセシビリティ
アクセシビリティの専門家にレビューしてもらい、アクセシビリティ・ガイドラインを作成した。
各国のISO担当機関からのフィードバックを反映したレポートは2月25日から29日のBallot Resolution Meetingの6週間前までに作成することになっていたので、それに間に合うように作成したもの。今後は、これに対して電話会議などで議論をしていくことになっている、とのこと。
「Office Open XML Formats」がいつISOの標準になるかは、分かりませんが、早くそうなって欲しいものです。
ちなみに、アンテナハウスでは、現在、「サーバベース・コンバータ(SBC) 2.0」を開発しています。SBC2.0は、Office 2007互換の組版エンジンとなります。長期的には、ISO 29500に準拠した組版エンジンということにしたいと思います。
ご参考:サーバベース・コンバータ
【広告】
書けまっせ!!PDF3 プロフェッショナル
既存のPDFに文字や図形を書き込めるPDF編集ソフトの新バージョン
http://www.vector.co.jp/magazine/softnews/080122/n0801224.html
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年12月24日
第10回XML開発者の日(3)
全体のメモがこちらにあります。よく、ずっとメモしていたものだ。
http://d.hatena.ne.jp/StL/20071221/p1
ジャストの舛形さんの、XML-IMの話を聞いて、アンテナハウスXML Editorで少し試みた、「入力支援」機能を思い出しました。
XML-IMの場合は、IMEで文章を入力していくときに、文字列に対して紐づけたXML要素をIMEで文字を入力するときに選択可能にしようというものです。
アンテナハウスXML Editorでは、DTDを元にして、DTDからその位置で入力可能な要素の候補リストアップしていこうというものでした。途中までやって中途半端なままで、もう、7,8年止まったままになっています。
このように、XMLの要素をどうやって簡単に入力するかというのは、エディタを作る場合のかなり大きな課題です。
人間にとってXMLを簡単に使えるようにするには、タグの入力とかオーサリングが大きな問題ですが、XMLのオーサリング技術って、この10年位あまり進歩してないような気がします。
この10年の進歩といいますと、やはりxfyがでてきたことでしょうか。xfyでかなりいろいろできるようになったのは、大きな進歩と言って良いような気もします。
しかし、xfyでDITAのような高度なXML文書の編集ができるのだろうか?
そういえば、DITAの編集で、いま一番良いエディタは、Syntext Serna、それに近いのがOxygenXML Version 9という話が出ていたのを思い出しました。
Oxygen XML V9 Now Just Works: Here's How
http://tech.groups.yahoo.com/group/dita-users/message/8382
ぜひ、xfyでDITAに挑戦してみてもらいたいものです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年12月23日
第10回 XML 開発者の日(2)
昨日に続き、第10回XML開発者の日で、面白かった内容につきまして。
セッション4で、村田 真さんが、「Atomとその拡張を検証するためのスキーマ」という題で、Atomに要素や属性を追加して拡張した複合文書を検証する方法について報告されました。
XMLでは名前空間を使うことにより、さまざまなスキーマのXMLを自在に組み合わせることができます。
Atomに限らず、ODF(Open Document Format)、OOXML(Office Open XML形式)などで、あるひとつのスキーマのXMLの中に、他のスキーマのXMLを入れて、複合文書を作る例が増えています。
こうした複合文書を検証するための仕様としてNVDLという仕様があるようです。(もう、かなり昔からやているようですが、知りませんでした。)
NVDL:Namespace-based Validation Dispatching Language
http://nvdl.org/
NVDLは、複合文書XMLの大きなツリーを、名前空間毎の個別スキーマの枝毎に切り離して、単一スキーマのXML文書にし、個々に検証しようという仕様のようです(多分)。
それから、IBMの基礎研究所の宮下さんによる、NVDLで切り離してシンプルなXMLファイルにしたものを、もう一度、組み立てるプログラムのデモがありました。
問題としては、Atomにせよ、ODFにせよ、名前空間をきちんとした方針で使い分けているわけではなく、単に要素名の衝突をさけるという便宜上の使い方をしているために、複合文書を分割するとやたらに沢山のファイルができたりしてしまうことだそうです。
また、実際に使うXML文書の要素には、ユニークなID(識別子)が付いていたり、ある要素からあるIDをもつ要素を参照したり、あるいは、文書要素間で相互に参照しあったりする関係をもっています。そうしますと、複合文書を、名前空間毎に切り離した段階で、IDのユニークさ、あるいは相互の参照などの関係が変ってしまうことになります。これらの問題は、どうもNVDLではうまく扱えないようです。
複合文書を、それを構成する部品に分解したり、部品を組み合わせて複合文書を作ることが自由自在にできるようになると、相当に面白い応用ができそうな気がします。それには、予めそういうことを考えて文書構造を設計しておかないといけないということなのでしょう。
こうしたことを考えますと、NVDL問題もそうなのですが、XML技術は面白いですが、実用上に使いこなすのは非常に難しいものだと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年12月22日
第10回 XML開発者の日(1)
21日は第10回XML開発者の日。去年より1ヶ月ほど遅く、暮れの押し迫った季節で忙しかったのですが、1日参加してきました。(来年は、もう少し早めに開催してほしいな)。
プログラム:http://www.asahi-net.or.jp/~eb2m-mrt/kaihatsu10.html
今回は、どうもジャストシステムのプレゼンテーション・デイのようで、半分位xfyとジャストの技術・製品の宣伝だったように思います。
昨年は、宮川さんのPlaggerのプレゼンなどがあって盛り上がりました。今年は、それに比べて、やや目新しさに掛けたようですが、XML技術というのは、それ自体として色々な技術的な挑戦とそれを使った新しい応用があってとても面白いものだと思います。少なくとも文字コードなどよりは面白いでしょう。
で、面白くない方の文字コード関係では、アドビの山本さんによるAdobe-Japan1-6をUnicodeのUTS 37 Ideographic Variation Databaseに登録したという話に、実務的にですが、関心をもちました。
このUTS 37は、もともとは漢字の異体字を登録して使うための仕様として2005年に提案されて、2006年1月に正式な仕様となっていました。要するに、Unicodeにコードポイントのある文字を例えば、U+82A6としますと、その異体字に対してE0100~E01EFまでの240のインデックスを付加することで識別可能とするものです。
今回Adobeが初めて、この仕様をつかって、Adobe-Japan1-6の中の字形を登録したとのことです。
登録された字形とコードはこちらに公開されています。まだ、登録ほやほやで12月14日付けです。
Ideographic Variation Database
例えば、<82A6 E0100> が、Adobe-Japan1-6 のCID+1142に、<82A6 E0101>が同CID+7961に対応します。
ここに登録された文字を使うUnicodeテキストには、E0100~E01EFのコードが含まれます。従って、アプリケーションは、Unicodeテキストのこの部分を解釈して、それなりのグリフに対応つける必要があることになります(最悪、E0100~E01EFを削除する)。このようなコードが普及する前に、Unicodeテキストを処理するアプリケーションの改造が必要になります。
Adobe-Japan1-6の字形が登録されてしまった以上、今後、他のフォントベンダーなり、他のメーカは、各Unicodeのコードポイントに付随するインデックスであるE0100~E01EFに異なる字形を割り当てることができなくなると思います。
このあたりは、PRをしっかりやって、他のフォント・ベンダ等も協調をとっていただきたいものです。そうしないと、Unicodeテキストをグリフにマップする過程で、字形が思わぬものに置き換わる可能性があります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年12月18日
WebFontについて(2) もう少し
昨日、お話しましたWebフォントについて、もう少し。
CSSの提唱者であるHåkon Wium Lieさんのブログに、少し古いですがWebフォントの記事とサンプルがあります。
通常の印刷では、様々なフォントを使うことができるのに、Webのデザイナーは、10種類やそこらの、普遍的に入手可能なフォントを使ってデザインしなければならない。
などとあり、Webフォントを使ったページデザインの例、WebフォントのCSSによる使い方の説明が出ています。
○Webフォントの歴史
Webフォントは、1998年にCSS2で、スタイルシートからフォントをリンクする方法が説明されており、MicrosoftとNetscapeがサポートしたのですが、(1)両方ともTrueTypeをサポートしなかったこと、(2)両者が、それぞれ別々に、EOTとTrueDocというあまり使われず、ツールもないフォーマットをサポートしたために、忘れ去られていたんだそうです。
なるほどー。
いまは、一般的でないフォントを使おうとすると、画像化してからWebページに貼り付けるしかないようです。
Håkonさんのブログで紹介されているCSSZen GardenのWebページも一部の文字は画像化して埋め込まれているものです。
こういう使い方はやはり変態的ですし、確かに、いろんなフォントを自由自在に、簡単に使えるようになればWebページの表現は、もっと楽しいものになりそうです。
しかし、考えて見ますと、PDF(あるいは、電子文書)へのフォント埋め込みを許諾しているフォントは多いですので、PDFへのフォント埋め込みと同じレベルで、HTML+CSSへのフォント埋め込みを可能にできないのでしょうかね。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年12月17日
WebFontについて
HTMLからWebサーバに置いたフォントをアクセスして、端末に表示するWebFontのフォーマットとして、MicrosoftのEOTフォント埋め込み形式がW3CのCSSワーキング・グループに提案されたようです。
※注意 これは、W3CのCSSワーキングで検討中の項目であり未公開です。W3Cとして正式に決定したものではないと思います。
このことが、次のAdobeのTypblography, the Phinney-us Blogに紹介されています。
Web font embedding returns: Survey!
Webフォントが使えるようになると、クライアントにフォントがなくても、サーバ側からフォントをダウンロードして表示可能になりますので、Webページのデザイン上のメリットは大きいと思われます。しかし、一方において、多くの商用フォントではこのようなフォントの使い方は許諾されていません。
従って、WebフォントをCSSとブラウザがサポートすると、商用フォントの不正使用を助長する可能性があるということで、Phinney氏のブログでは、多くのコメントが寄せられています。
また、ブログサイトでのアンケートの結果が公開されました。
Web fonts: user survey results
Q1 Webページ用のフォントの選択について
(1)印刷に使っているのと同じフォントをWebページに使えること:「致命的に重要」と「極めて重要」との回答が65%
(2)既存の視覚的に同等性を保つ部分で、Webでも同じフォントを選択できる:「致命的に重要」と「極めて重要」との回答が81%
Q2 Webフォントの仕組みとしてどういう仕組みが望ましいか?
フォントの使用条件で許諾されたフォント(全体の3-5%)のみを使用可能とする意見よりも、プレビューと印刷を許諾されたビットマップをもつフォント(全体の半分)を使用可能とする方が望ましい、という意見が多い。
Q3 フォントの使用ライセンスに関する意識
かなり多くの回答者は、フォントが合法的に使用可能かどうかをチェックする、と回答しています。
このアンケートを見る限り、Webフォントについての需要はかなり大きいのではないか、という印象をもちます。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年10月31日
Movable Typeの限界に到達?
PDF千夜一夜は、連続1000日更新を目指し、「有言実行」で頑張っています。2年前に開始して、今日でもう745話目です。つまり745日連続更新です。
その種を明かしますと、連続更新は、ずっと、自動設定でやっていたのです。大抵、翌日のブログを前日の夜、帰社する前に書き、翌日の朝8:00にブログの記事が自動的に公開されるように「指定日公開」機能をセットして帰ります。
最初のうち、この機能は順調に働いていましたが、最近は、翌日出社しますと、8時を過ぎても公開されていないトラブルがしばしば発生するようになってきました。
先週は、データベースが大きくなりすぎているのかということで、サーバ管理者にデータを圧縮してもらいました。それで、土曜日と日曜日はなんとか自動公開が動いていたようです。
しかし、今週、月曜日、火曜日は、設定した時刻を過ぎても自動公開されていませんでした。そこで、やむなく手動で公開しています。
そんな具合で、このところ、お読みいただいている方の中で「あれ?今日はお休み?」と思われる方もいらっしゃるかもしれませんね。
しかし、まだ第三コーナーですから、老体に鞭打って、まだまだ頑張りますよ。
でも、コンピュータ・ソフトなんだから、指定時刻に指定の動作をするのは100%完璧であって欲しいものです。さて、今日(明日)は、どうなっていますか??と心配しながら帰る毎日が続いています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年10月10日
「HTML&スタイルシート レイアウトブック」を読んで
最近、CSSでホームページを作る方法をもう少し勉強しようと思い立ち、「HTML&スタイルシート レイアウトブック」外間かおり著 株式会社ソーテック発行 ISBN978-4-88166-568-8 (定価2300円+税)を買ってきました。
外間かおりさんの本って、アマゾンに35冊もリストアップされます。上記の本は、アマゾンで見て、4星半の評価ですが、評価通り、分かりやすくてなかなか良い本だと思います。
この本には、CSSを使ってWebページを2段組、3段組をする例がふんだんに掲載されています。
この本を購入した動機は、表を使わないでCSSで段組をする方法を学びたいという、かなり単純なことなのです。本を読んでそれは理解できましたし、それ自身は、Webページ作成のテクニックとして参考になります。今度、Webページで活用してみましょう。
それは、良いとしまして、気になりましたのは、この本では、2段組、3段組を、absolute-position、もしくは、floatを使って実現しているということです。メインの左右に配置されるサイド・コンテンツに対して、floatなどを指定するのは良いのだろうと思います。
さらに、本文の段組もfloatやabsolute-positionで指定して、見掛け上2段組、3段組にしているのですが、これは、表を使うよりは良いだろうことには同意します。
しかし、やはり真の段組とは言えないのでしょうね。つまり、真の段組であれば、Windowの幅が狭くなれば、自然に改段の位置が変わる、フローするのだろうと思いますが、floatやabsolute-positionで指定するのは、予め、段毎にdiv要素で区切りを入れて置く必要があります。
結局、段毎のブロックをdivで囲むという形で、レイアウトをコンテンツに反映していることになります。極言するとコンテンツとレイアウトが分離していない、とも言えるわけで、CSSの思想に反してしまいます。
結局、CSS2では、まだ、自然な段組はできないのでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年10月01日
W3Cの日本語レイアウトに関するタスク・フォース活動
W3CのCSSワーキング・グループは、今年の5月から、CSS仕様の開発に関するブログを運営していますが、そこに、日本語レイアウトに関するポストがあります。
Resolutions 2007-09 Beijing Part II: Japanese Layout and Vertical Text
http://www.w3.org/blog/CSS/2007/09/24/beijing_part_2
それによりますと、W3Cには、I18n, XSL, SVG, CSSのワーキング・グループ合同による日本語レイアウトに関するタスクフォースがあり、このワーキング・グループの目標は、日本語文書に関するレイアウト要求を文書化し、それぞれの仕様に反映することだそうです。
タスク・フォースは、主に日本で日本語により会議を行っていますが、最終的には、英語でW3Cノートを作成することです。
現在、第一部の英語化が完成していますが、2007年11月のW3C技術総会までに資料を完成し、発表されることになっています。
W3Cの会員向けのメーリング・リストなどでは、既知の情報ですが、このタスクフォースに関する情報が公開されたのは、このブログが初めてでしょう。
ところで、CSSが提案されて、既に10年を経過していますが、昨日、新宿のジュンク堂に行ってCSS関連の書籍の種類が多いことに驚きました。
W3Cの仕様の中で、CSSは最も成功した仕様の一つであると言っても過言ではありません。HTMLは別格としても。しかし、CSS3はなかなか仕様の策定が進んでいませんね。
CSSに関するブログを読んでいましたら、
Why is the CSS Working Group so slow? Wouldn't being more like the WHATWG speed it up?
CSSワーキング・グループは、なぜ、こんなに遅いの?
という記事がありました。きっと、いろんなところから、「遅い!」と突っ込まれるのでしょうね。
。。最終的には、キーボードをたたく(鳴らす)「スキル×時間」が足りないのだそうです。
http://www.w3.org/blog/CSS/2007/07/02/behind_the_scenes
投稿者 koba : 09:00 | コメント (0) | トラックバック
2007年09月14日
CSS3 新しいモジュールGrid Positioning追加
CSS3に新しいGrid Positioningモジュールの仕様案が発表されました。
CSS Grid Positioning Module Level 3
W3C Working Draft 5 September 2007
これは、書籍や新聞で使われているグリッドの仕組みをオンライン文書に適用しようというもの。CSSでは既に、異なるアプローチでAdvanced Layoutというモジュールが提案されていますが、これを補うもののようです。
そうしますと、CSS3ではオブジェクトのレイアウトに二通りの方法が規定されてしまうということなのでしょうか?だとしますと、ただでさえ、遅延しているCSS3の仕様がますます混乱して遅延しそうな気がします。
このドラフトの著者を見ますと、
Alex Mogilevsky, Microsoft
Markus Mielke,Microsoft
で両名ともMicrosoftの人です。Alex Mogilevskyは、Microsoftのソフトウエア・アーキテクト43歳。TechEdでOffice2007のGUIについて、プレゼンテーションしてますね。
http://download.microsoft.com/download/D/F/7/DF7DA0F0-34EA-4A22-8669-13A2B7F6650A/Ses1_mat_CD303_OFC309.ppt
Markus Mielkeは、IEのブログにしばしば登場しています。しかし、IEチームではないらしい。
いづれにせよ、グリッド・ベースのレイアウトシステムがIEあたりに実装されたら面白いですが。しかし、このドラフトは、まだ、かなりラフな状態のようなので、今後どうなるかはあまり予測が付きません。
いや、そもそもCSS3は一体どういう風に収束するかさえも予想しずらい状態。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年08月20日
Microsoft Open XML Formatをサポートするソフト
Microsoft のOffice 2007のXML文書形式であるOpen XML Formatをサポートするソフトウエアのリストが下記にあります。
iWork ‘08 supports the Open XML formats
http://blogs.msdn.com/brian_jones/default.aspx
・iPhone
・iWork
・Officeの旧バージョン
・OpenOffice.org
・WordPerfect
・PalmOS
・NeoOffice
・MindMapping
・OpenXML Writer
など、全部で16製品が掲載されています。
Microsoft Office 2007が発売されてもうかなりの時間が経過していますので、もっと他にもあると思いますけれども。
ちなみに、アンテナハウスでは、TextPorter V4.2は、既に、Open XML formatのテキスト抽出をサポートしています。残念ながら、テキスト抽出のみです。
また、Microsoft Office互換のレンダリング・ソフトServer Based Converterや自在眼は、次のバージョンで、Open XML形式をサポートする予定です。現在、開発中ですので、しばらくお待ちください。
ところで、iWork'08というのはMac用の統合オフィスソフトなんですね。知りませんでした。iWork'08は、8月7日に発売されたばかりです。
・Pages'08:編集ソフト
・Keynote'08:プレゼンテーションソフト
・Numbers'08:表計算
という3種のソフトのパッケージで、US$79.00(日本では9,800円)です。これまでは、編集ソフトとプレゼンテーションソフトのみでしたが、今回('08)から表計算が追加になりました。iWork'08ではPDFの出力も可能です。オフィス・ソフトにはPDF出力が標準になるのでしょう。
Macは、Intel アーキテクチャに移行していますが、インテルMac版のMicrosoft Office 2008のリリースは、2007年後半の予定が、2008年に遅延するとのことです。
Office 2008 Coming January 2008(Office for Macチームのブログ)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年06月01日
PDFと署名(36) — ハッシュ・アルゴリズムについて
さて、昨日の続きですが、「PFU タイムスタンプの使い方」2006年5月版 P.57/60 には、さらに、PFUのタイムスタンプは、「V2.0L10から、PDF文書からのハッシュ生成アルゴリズムを、より強固なものに変更しています」として、SHA-512ハッシュアルゴリズムおよびSHA-512withRSA署名アルゴリズムを使っていること。そして、「これらに対応していないAcrobat署名プラグインでは、正しい検証結果が得られません。」と書いてあります。
ところが、PDF Referenceによりますと/adbe.pkcs7.detachedは、メッセージダイジェストとして以下の5種類をサポートしています。
・SHA1 (PDF 1.3)
・SHA-256 (PDF 1.6)
・SHA-384 (PDF 1.7)
・SHA-512 (PDF 1.7)
・RIPEMD160 (PDF 1.7)
出典:PDF Referefnce 1.7 740 ページの表
とあります。なので、単純にアルゴリズムをサポートする・しないだけの観点で言えば、Adobe Reader内蔵のデフォルトハンドラでもSHA-512はサポートしていると言えます。
じゃあ、なぜAdobe readerのデフォルト署名ハンドラで、PFUのタイムスタンプが検証できないのか、これが以前として疑問です。
そこで、PFUのタイムスタンプ・ハンドラが作成している署名値を、少し調べてみることにしました。
PDFでは、署名値は署名辞書のContentsキーに保存されています。
Contentsキーの内容は、署名対象PDFの署名対象範囲(ByteRange)のダイジェストになります。公開鍵方式で署名する場合は、この値はPKCS#7のバイナリデータをDER符号化したものである、とされています。
PKCS#7とDER'について:
PKCS#7: RFC2315 Cryptographic Message Syntax Version 1.5
DER:Distinguished Encoding Rules
この中を見るのはとても大変そうですが、都合の良いことに、DER符号化したPKCS#7のデータをXMLにするツールがラング・エッジのWebサイトから入手できます。
これで見ますと、PFUのPDFタイムスタンプ・サンプルの署名値は次のようになります。
PFUのタイムスタンプ・サンプルPDFの署名値PKCS#7をXML化したもの
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月19日
PDFと署名(30) — PDFの署名の検証
さて、今週は、水曜日から金曜日3日間ソフトウェア開発環境展ということで、3日間のうち半分ほどは、国際展示場に行っていました。弊社は、このところ、ソフトウエア・コンポーネントの販売が好調で、だんだん、パッケージ会社からソフトウエア・コンポーネント会社に事業の中心がシフトしつつあります。そういう意味では、今年のソフトウェア開発環境展は丁度良い機会でした。
ブースでは、XSL Formatterを初め、PDF製品を出展して説明させていただきましたが、大勢の方に関心をもっていただき、また、説明を聞いていただいた方も多く、本当にありがとうございました。
今回、参考出品した「PDF電子署名モジュール」を目当てにお立ち寄りいただいた方も予想外に多く、商品化に向けて、ますます張り切っていきたいと思います。さて、「PDF電子署名モジュール」関係で幾つか、ご質問をいただきました。その中に、
○PDFの署名にルート証明書が付くかどうか、
という御質問がありました。
これは、Acrobatを初め、PDFの署名にSelfSign方式を使っているため、いわゆる、PKI(公開鍵インフラ)の立場から見て、「PDFの署名の信頼度はどうなんだろう?」という疑問をもたれているのではないか、と推察しました。
この質問に対してお答えするため、まず、「PDF電子署名モジュール」では、どのような「秘密鍵+電子証明書」を使うかについてQ&A形式で整理してみます。
質問:認証局が発行した証明書は使えますか?
回答:使えます。「PDF電子署名モジュール」(参考出品版)では、Windowsの証明書ストアに証明書を登録して、Windows証明書ストア用のAPIを使って署名をします。ですので、Windowsの証明書ストアに入れることのできる電子証明書であれば、任意のものが利用可能です。
質問:自己署名(Self-Sign)証明書は使えますか?
回答:使えます。「PDF電子署名モジュール」(参考出品版)には、自己署名証明書を発行する機能も付いています。また、自己署名証明書は、Windowsの証明書ストアに入れることができます。
質問:Windowsの証明書ストアとは何ですか?
回答:Windows標準の証明書管理領域を、証明書ストアと言います。Internet Explorerの[ツール]-[インターネットオプション]の[コンテンツ]タブから[証明書]ボタンをクリックして証明書ストアに格納されている証明書を確認することができます。Windows環境では、証明書と秘密鍵を証明書ストアに入れて利用する方法が一般的です。

[Windows証明書ストア]
さて、そこで、最初の「PDFの署名にルート証明書が付くかどうか」という御質問ですが、電子署名したPDFには、PDFの指定した範囲のハッシュ値を秘密鍵で暗号化したデータと、その秘密鍵のペアである公開鍵証明書(電子証明書)を埋め込みます。ですので、ルート証明書が署名されたPDFの中に付くわけではありません。
ルート証明書は、PDFに埋め込まれた電子証明書を検証するために使うのですが、その際、署名を検証する環境で、PDFの中の電子証明書からルート証明書までのチェーンができれば、ルート証明書の役割は終わりです。そういう意味では、ルート証明書は署名を検証するPC環境にあるか、あるいはインターネット経由でアクセスできれば良いのであって、「電子署名をしたPDFの中にルート証明書を入れる必要はもともとありません。」ということになります。
上記アンダーラインの部分、PDF Referenceを確認しましたところ、間違っているのかもしれません。
☞ 5月21日へ続く
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年05月14日
PDFと署名(26) — Adobe Readerによる署名されたPDFの検証
Adobe Readerで署名付きのPDFを開きますと、次の例のように署名の状態を確認することができます。
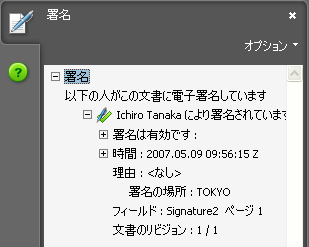
Adobe Readerのヘルプを見ますと、署名の状態を示すアイコンには、次の6種類があるとされ、簡単な説明文がついています。
(1)![]() :未署名の署名フィールド
:未署名の署名フィールド
(2)![]() :PDF が証明済みであること、つまり有効な証明用署名を含んでいる
:PDF が証明済みであること、つまり有効な証明用署名を含んでいる
(3)![]() :署名が有効である
:署名が有効である
(4)![]() :署名が無効である
:署名が無効である
(5)![]() :署名後に文書が変更されている
:署名後に文書が変更されている
(6)![]() :信頼済み証明書の一覧に署名者の証明書がないために署名が検証できなかった
:信頼済み証明書の一覧に署名者の証明書がないために署名が検証できなかった
これらのアイコンと説明はなんとなく分かりそうですが、よく考えると分からないですね。そこで、「Digital Signature User Guide」の説明を見て、もう少し調べてみました。
(1)最初の未署名の署名フィールドについては、既に、ブログでお話しました。
(2)次の、「有効な証明用署名を含んでいる」のアイコンは、証明プロセスを使って証明し、かつ、この署名者が第一番目の署名者であり、かつ、文書が署名後に変更されていないか、許可された範囲で変更されていることを示す。
※この証明プロセスで技術的にどんな処理をしているのか、(2)との違いについては、さらに調べてみる必要があります。
(3)「署名が有効である」というのは、有効な証明書を使って署名されており、また、署名後に不正な変更がないことを示しています。
(4)「署名が無効である」とは、証明書が不正か、それとも、文書に許可されない変更がなされていること。
(5)「署名後に文書が変更されている」は、証明書が検証できず、かつ、文書に予め許可された変更がなされているということを示します。
(6)最後は、証明書を検証することができないか、文書の検証を完了できなかった。
なお、この他に、![]() と
と![]() の不明状態が紹介されています。前者は証明書の信頼性を検証できず、かつ、文書が署名後に変更されていること、後者は、証明書の信頼性を検証できず、かつ、文書は署名後に変更されていない状態を示すようです。
の不明状態が紹介されています。前者は証明書の信頼性を検証できず、かつ、文書が署名後に変更されていること、後者は、証明書の信頼性を検証できず、かつ、文書は署名後に変更されていない状態を示すようです。
このようにPDFの検証では、(a)電子証明書の検証、(b)文書内容の変更の検証があり、さらに文書内容の変更では、予め許可された変更は妥当ですが、許可されていない変更は不正となります。このように状態が多いので複雑です。
参考資料:「Digital Signature User Guide Acrobat and Adobe Reader Version 8」2007年2月27日
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月08日
PDFと署名(21) — 電子証明書ICカードはなぜVistaで使えない?
もういろいろなところで、問題として取り上げられていますが、電子入札・電子申請が軒並みWindows Vistaで使えません。また、電子証明書ICカードもWindows Vistaで使えないようです。
○電子入札コアシステムのクライアントはWindows Vistaは使えません。
コアシステムにおけるWindows Vistaへの対応について
「RC1版では、既存のICカードドライバが動作しないこと、およびJRE1.3.1では正常動作しないことが判明しており、現時点ではWindows Vistaのクライアント端末にてコアシステムを使用することはできません。このため、Windows Vistaにつきましては、2007年1月30日以降もコアシステムのクライアント推奨稼動環境には含まれませんのでご注意ください。」(2007年5月8日現在)
これを受けて、電子入札対応ICカードを発行している認証局でも、Vista非対応という表示をしているところがあります。
当然ですが、コアシステムを採用しているすべての団体の電子入札への応札者のクライアントPCは、Windows Vistaは使うことができません。
○公的個人認証サービス利用者クライアントソフト自体がVistaに対応していません。
公的個人認証サービスの利用に必要となるパソコン等の仕様について
「次のいずれかが必要です。
* Microsoft Windows XP (Service Pack 2適用)。
* Microsoft Windows XP (Service Pack 1適用)。
* Microsoft Windows 2000 (Service Pack 4適用)。
* Microsoft Windows 2000 (Service Pack 3適用)。
* Microsoft Windows 2000 (Service Pack 2適用)。
* Microsoft Windows NT (Service Pack 6a適用)。
* Microsoft Windows Millennium Edition (Me)。
* Microsoft Windows 98 Second Edition (SE)。」
(2007年5月8日現在)
当然(?)、公的個人認証サービスのICカードで、Vistaで動作保証されているものは見当たりません。
この結果、電子政府の窓口もほとんどWindows Vistaに対応していません。電子政府の申請は、かならずしも、電子証明書必須ではないですし、また、電子証明書を使うにしてもICカードとは限らないのですが。
これは一体どこに問題があるのでしょうか?
・ICカードリーダのデバイスドライバの問題?
・WindowsVistaとJAVA(JRE)の問題?
○ICカードリーダのデバイスドライバの問題なら、ICカードリーダをVista対応版にすれば解決できます。しかし、電子証明書用のICカードリーダを販売している会社でVista対応版を用意しているところは見当たりません。ICカードリーダのメーカの方は、上位のアプリケーションがVista対応でないのだから、別に、Vista対応を急ぐ必要はないと思っているようです。
例えば日立のICカードリーダ
「※公的個人認証サービスをご利用の方へ
現在、公的個人認証サービス利用者クライアントソフト自体がVistaに対応しておりません。今後、公的個人認証サービス利用者クライアントソフトのVista対応に合わせて検証試験を行います。 」
(2007年5月8日現在)
また、JDL電子申告システムのWindows Vistaの対応ページには次のように書いてあります。
「JDL電子申告システムは、弊社Windows Vista™対応ハードウェア製品およびソフトウェア製品でご利用いただくことができます。但し、電子署名に必要なICカード(ICカードマネージャ)とICカードリーダライタにつきましては、現在提供元およびメーカーの動作確認が報告されておらず、ご利用いただくことができません。したがって、電子署名のみ、動作確認済みの弊社Windows®XP搭載機種およびWindows®XP対応製品で行ってください。」 (2007年5月8日現在)
これをみると、原因はICカードのリーダライタ側にあるということなんですが。
しかし、ICカードリーダのベンダは沢山あるのだから、どこか1社ぐらいは、Vista対応版を出してもよさそうなものですが。なぜ、どこも出さないのでしょう?
○また、JAVAの実行環境にも問題があるようです。もともと、JAVAを使えば、アプリケーションをOSから独立にできるという触れ込みでしたが、Vistaの登場でそれが嘘であることがばれてしまいました。JAVAそのものが一つのアプリケーション実行環境(JRE)なので、アプリケーションがWindows環境依存からJAVA環境依存に変わっただけだったのです。だから、JREがVistaできちんと動かない限り、JAVAアプリケーションの作者は手も足もでません。Vistaの登場で、そのことがはっきり分かったともいえるんだよね。じゃあ、クライアントのJREを全部入れ替えろ!というのも面倒なことになります。要するにWindowsクライアントのジャバはジャマなんです。
※JAVAはアプリケーション開発の生産性が高いということでJAVAを選んだケースが多かったのかもしれない。しかし、生産性が高いというのは、反面ブラックボックスが増えるということでもあります。そういう意味では、Vista問題はソフトウエア開発環境の選択の事例研究として、専門家が検討すべきでしょうね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月06日
PDFと署名(20) — 電子証明書と個人情報
次に、電子証明書と個人情報保護の関係について考えて見ます。PDFを含めて文書に電子署名すると、文書と署名データと電子証明書を一緒に相手に渡すことになります。このように電子証明書の内容は相手方に開示されるものです。
現在、さまざまな認証局が発行している電子証明書は、公開鍵証明書の標準であるX509のバージョン3を基本としていますが、subjectAltNameを独自拡張して、証明書所有者について詳しい情報を保存しているものが多いようです。
例えば、次のようになっています。
・公的個人認証サービス (東京都)— 氏名, 生年月日, 性別, 住所, 氏名代替文字の使用情報, 住所代替文字の使用情報
・電子認証登記所 — 商号、本店、資格、氏名、会社法人番号、管轄登記所
・AOSignサービス(日本電子認証株式会社) など — C=JP, S=本社住所(都道府県), L=本社住所(群、市町村以下), O=企業名, CN=氏名
・TOiNX電子入札対応認証サービス(東北インフォメーションシステムズ株式会社) — 利用者氏名(かな漢字表記、以下、同じ)、組織名、区市町村名、都道府県名、国名
・日本司法書士会連合会認証サービス — ST=(所属する事務所所在地の都道府県), L=(所属する事務所所在地の市町村以下), O=(日本司法書士会連合会 固定), OU=(所属する司法書士会名称), T=(司法書士:司法書士登録番号), T=(簡裁訴訟代理関係業務認定:認定番号), CN=(利用会員氏名)
一方で、認定認証機関でも、subjectAltNameを独自拡張していないものもあります。このように電子証明書の発行機関によって拡張領域に記録される内容は様々です。
もともと、公開鍵暗号方式は、公開鍵をインターネットなどで一般に公開するという概念からスタートしています。そして、公開鍵の所有者等の情報を記載するとともに、公開鍵自体の情報を改竄から守るために公開鍵証明書の形式で公開します。Webサーバに掲示するサーバ証明書がその典型的な使用例でしょう。
一般に、運転免許証やパスポートなどは身分証明書としても使うことができます。これを身分証明書として使ったり、体面で相手に提示したり、あるいは、パスポートは航空券を申し込む時、コピーして提示したりします。しかし、このような身分証明書をインターネットなどで不特定多数に公開する人はまずいないと思います。これに対して、電子証明書は、公開される身分証明書であると言っても良いと思います。
電子証明書によって署名をした相手が本人であるかどうかを判断するためには、本人を特定する情報は必須です。ところが、電子証明書は署名した文書とくっついてインターネット上で相手にわたりますので、電子証明書が個人情報やプライバシーに関わる情報を含んでいると、これが公開されるのははまずいということになります。
この点に、電子証明書の矛盾があります。このことを考えると、各認証機関がsubjectAltNameを独自に拡張してしまったのは少しまずいのではないかとも思います。X509ではそのために属性証明書が規定されていて、関連する公開鍵証明書に紐付けして使うようになっています。しかし、属性証明書を発行している認証局は少ないようです。
例えば、首相官邸Webから公開されている「2006年度 電子政府評価委員会報告書」には、公的個人認証サービスをもっと普及させるために、電気、ガス、医療などにも使えるようにせよ(p.25)、とあります。しかし、そもそもいままで三文判で済ませていたような申し込み書に、個人情報満載の電子証明書を使う必然性があるのでしょうか?
※電子政府評価委員会のWebページ
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月05日
PDFと署名(19) — 商業登記に基づく電子証明書は使えそう。しかし。
法務省の「商業登記に基づく電子認証制度」(電子認証制度)は、法人の登記情報に基づく、電子証明書を発行しています。この電子証明書は、次の人が対象となります。
「登記所に印鑑を提出している会社の代表者・支配人や商号使用者。また、会社以外の民法法人,独立行政法人,特殊法人,認可法人,協同組合,社会福祉法人,医療法人,宗教法人,学校法人,信用金庫,特定非営利活動法人などについても,登記所に印鑑を提出した代表者。」
電子認証制度の電子証明書には、公開鍵証明書 X.509 V3仕様の独自拡張部分を用いて、法人について、商号、本店、代表者名、代表者の資格、管轄登記所、会社法人番号が記録されています。従って、この電子証明書に対応する秘密鍵で署名した文書については法人を特定できます。
この電子証明書の発行申請は、各法人の管轄登記所ですが、東京法務局が電子認証登記所(CRCA)となります。電子証明書の検証は、署名された文書の受信者がだれでも行うことができますので、一般の企業の取引でも使うことができます。登記内容は商業登記法に基づいており、虚偽の登記は罰則が適用されますし、汎用性が高いものと思います。
しかし、問題が幾つかあります。
(1)手数料は3ヶ月単位で3ヶ月から最長で27ヶ月(2年と3ヶ月)。3ヶ月の場合で2,500円、1年7,900円、27ヶ月で16,900円となります。さらに、取得申請時に登記済みの印鑑証明も必要ですので、印鑑証明1通分の手数料がプラスされます。
(2)秘密鍵・公開鍵ペアを自分で行い、公開鍵をフロッピディスクに入れて提出しなければなりません。いまどきは、フロッピディスク・ドライブ装置を持っていないPCも多いのにね!
(3)フロッピへの記録方式が規定されています。このフロッピ作成等の処理を行うためのアプリケーション・ソフトウエアが必要です。
☞ 電子証明書の方式等に関する件(告示)
(4)この電子認証制度の電子証明書は、多くの電子入札システムで使えます。但し、例えば電子入札コアシステムでは、電子証明書の保存媒体としてはICカードしか使えませんので、コアシステムを採用した電子入札に使おうとすると、受け取った電子証明書を電子入札コアシステム用のICカードに移すことが必要です。
(5)電子認証登記所が発行した証明書を検証するときは、証明書失効リスト(CRL)ではなく、オンライン(OCSP)で状態を問い合わせる必要があります。従って、インターネットに接続していない端末から証明書有効性の検証はできません。
電子認証制度の電子証明書は、法人(代表者)の証明書としては、最も正統的であり、かつ汎用に使えるものです。この点、今後の普及を期待したいところです。しかし、普及させるには、手数料をもっと安くすること、期間を大幅に延長すること、手軽に使えるアプリケーションが増えることなどの諸条件が整うことが必要なように思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月04日
PDFと署名(18) — 公的個人認証サービスの電子証明書の用途は?
2007年04月27日PDFと署名(12) — ルート認証局の種類で、全国の地方自治体が行っている「公的個人認証サービス」を紹介しました。このサービスは、「電子署名に係る地方公共団体の認証業務に関する法律」(公的個人認証法)に基づくもので、公的個人認証サービスの電子証明書は次の特徴があります。
(1)個人が現在住んでいる市町村(住民基本台帳がある住所)を通じて、都道府県の知事に対して、発行を請求します。
(2)市町村長が本人の確認を行い、その確認通知を受けて、都道府県知事が発行します。
(3)電子証明書は、現在のところ、住民基本台帳カードに保存されます。
(4)電子証明書には、住民基本台帳に記録された氏名、住所、生年月日、性別と、利用者が電子署名のために使用する秘密鍵に対応した公開鍵が記載されます。
(5)電子証明書は発行の日から3年間有効です。但し、有効期間中であっても住所の変更や氏名の変更の場合などで記載事項に変更が生じた場合は無効になります。
(6)2007年04月29日PDFと署名(14) — 電子証明書の検証で説明しました通り、電子証明書を使った署名を検証するには、証明書の失効をチェックする必要があります。しかし、公的個人認証サービスの電子証明書の失効者リスト(CRL)を入手できるのは、行政機関などの特別な機関に限ります。従って、一般の個人・法人には公的個人認証サービスの電子証明書による署名を検証することはできないことになります。
以上のこと(特に、(6))からお分かりになりますように、公的個人認証サービスの電子証明書は、行政手続だけに使うことができます。
使用できる行政手続きは、次に一覧があります。
公的個人認証サービスを利用する行政手続き
・国の機関等
・地方公共団体等
使える行政手続きの種類は多いので、社会保険労務士、行政書士、など様々な申請の代理業務を行っている場合には、メリットが大きいかもしれません。
ただし、どこまで使えるかの判断は難しそうです。例えば、特許庁のインターネット出願ソフトの概要(平成17年1月)p19 には、「住基カードの公的個人認証サービス電子証明書については、現時点(H16.12)では、「電子署名に係る地方公共団体の認証業務に関する法律」第19 条第2項により、利用方法が限定されている為、利用できません。」とあります。
注意しなければならないのは、この電子証明書には、氏名、住所、生年月日などの個人情報が入っていることです。このためこの電子証明書を公開すると、まさに、個人情報の公開になってしまいます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月03日
PDFと署名(17) — e-Taxで使う電子証明書
昨日は、電子入札で使う電子証明書が、個人(自然人)の電子証明書になっていることが多いようで疑問を感じる、とお話しました。
もう少し調べてみますと、認定認証局によっては、電子署名法の施行規則で求めている手続き(個人の本人性確認のみ)の他に、所属する企業までを確認して電子入札用の電子証明書を発行するところも多いようです。実際のところ、電子入札などの政府・行政と法人間の取引行為に個人の電子証明書を使うというのは不合理なように思います。これは公私混同でもありますので、正さねばならない問題でしょう。
また、法務省の商業登記認証局では、法人代表者の電子証明書を発行していますので、電子入札では、そういうものを使う方向に進むかもしれませんね。
では、国税庁の電子申告・電子納税(e-Tax)で使う電子証明書はどうでしょうか?
e-Taxの場合、関与する税理士が申告する場合は、税理士の電子証明書でよいのですが、自己申告する場合は電子証明書が必要です。使える電子証明書は、次のものです。
・個人の申告等では、地方公共団体の公的個人認証サービス、 法務省が運営する「商業登記認証局」が発行するもの、認定認証局が発行するもの。
☞ 個人が利用可能な電子証明書には何がありますか。
・法人の申告等でも同じです。
☞ 法人が利用可能な電子証明書には何がありますか。
e-Taxでは、法人税の申告に代表者個人の電子証明書も使える、と明確に書いてあります。
☞ 商業登記認証局の発行する法人代表者の電子証明書は、法人代表者個人の所得税申告にも使用できますか。また、法人代表者個人の公的個人認証サービスなどの電子証明書は、法人税の申告に使用できますか。を参照。
法人税の申告に代表者個人の電子証明書を使うことができる根拠は、「法人税法では申告書に法人代表者の自署・押印」を求めていることだそうです。私の記憶では、紙で法人税関係の申告をする時の押印に使う印鑑は、三文判でも問題ないはずです。つまり、法人税の申告では電子証明書は三文判の延長としての役割を担っているのでしょう。このあたりに、税理士が関与した場合は、本人の電子署名が不要ということになる遠因があるのではないでしょうか。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年05月02日
PDFと署名(16) — 電子証明書の使用者は法人?自然人?
通常の社会活動において、署名者の主体は、自然人または法人となります。例えば、個人的に物品を購入したり、個人で住宅や土地を購入する場合、その主体は自然人です。それに対して、会社として物品を購入したり、会社としてビルの賃貸契約したり、業務の請負契約をする場合は、その主体は法人となります。
従来の印鑑の場合であれば、自然人は地方自治体に実印を登記できます。そして、重要な契約は個人の実印を用いて押印し、その印鑑証明を添えることが求められます。
また、法人の代表者は、民間企業であれば、法務局に代表者印を登記しており、企業を代表して重要な契約をする場合は代表者印を使用して押印し、その印鑑証明を添えることが一般に行われます。
このあたりまでは、電子化されていない印鑑による商取引の常識だろうと思います。
ところが、電子署名法とその施行規則を調べますと、電子署名法に基づく認定認証局が発行する電子証明書の所有者は、どうも自然人に限られるようです。
「電子署名及び認証業務に関する法律」の第六条二では、認証業務を行うものは、利用者(電子証明書の発行相手)の特定方法を、「申請に係る業務における利用者の真偽の確認が主務省令で定める方法により行われるものであること。」と定めています。
そして、その主務省令にあたる「電子署名及び認証業務に関する法律施行規則」では、第5条(利用者の真偽の確認の方法)で、具体的な方法を定めています。この部分は長いですが、端的にいいますと、「住民票の写し、戸籍の謄本など」の提出を求め、そして、「パスポートまたは運転免許証など」で本人を確認する、こととなっています。従って、電子署名法に基づく認定認証局の発行する電子証明書では法人の代表者であることは証明されません。
ところが、官公庁などの電子入札の入札資格者は、ほとんどの場合、自然人ではなく法人のはずです。例えば、国土交通省の電子入札運用規則には次の項目があります。
「電子入札を利用することができるICカードは、競争参加資格認定通知書に記載されている者(以下「代表者」という。)又は代表者から入札・見積権限及び契約権限について年間委任状(様式2)により委任をうけた者(以下「受任者」という。)のICカードに限る。」
このため、法人の代表者と自然人を対応つける必要が発生します。つまり、前述の通り、ICカード(認定認証局の発行する電子証明書)は自然人のものになります。で、その自然人のICカードが、確かに、その法人を代表する人のものであることを証明しないといけないのですが、どうやって、これを電子的に証明するのでしょうか?例えば、A建設工業の代表者山田太郎が、電子証明書記載の山田太郎と同一人物であることを証明するのは、電子証明書のみではできないと思います。また、委任状を用意したとして、委任状の電子署名が代表者のものであることを、どのように証明するのでしょうか?
アナログの世界では、法人の代表者印は法人に紐付け付けられていて、代表者が別の人に交代しても、印鑑の所有者の登記を変更するだけでした。ところが、電子証明書の方は、自然人である代表者の方に紐付けられていることになります。どうも、180度違っているように感じます。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年05月01日
PDFと署名(15) — 電子証明書の用途別種類
次に、電子証明書の種類とその値段について、ざっと調べてみたい思います。電子証明書の用途としては、次のようなものがあるようです。
・サーバ証明用
・コードサイニング証明用
・個人認証用
・社員であることの認証用
・会員であることの認証用
・官職証明用
・電子入札・開札システム用
・電子届出・電子申請用
・電子申告・納税用
・電子契約用
・その他
以下に簡単に説明します。
・サーバ証明書
インターネットのサーバとクライアントの間でSSL暗号通信を行うために、サーバ側に用意する証明書。
・コードサイニング証明書
Windowsなどで、プログラムをインストールする際に、その開発元を証明する用途で用いられる証明書。
・個人認証用
一番多いのは、電子メールなどに電子署名をすることで、電子メールの送信者を証明するもの。それ以外に、ベリサインなどでは、簡単に個人を特定するためのクラス1という証明書を発行している。
・社員であることの認証用
会社の中にプライベートな認証局を構築し、社員に対して証明書を発行するもの。会社のネットワークに入る人を特定するなどの用途で用いることができる。
・会員であることを認証用
会社の社員と同じような趣旨。
・官職証明用
官庁の職責で発行する文書に電子署名するための証明書で、GPKIの認証局が発行する。
・電子入札・開札システム用
認定認証局などが、官公庁・行政機関の入札の書類用に発行する。発行先は企業になる。
・電子届出・電子申請用、電子申告・納税用
認定認証局などが、官公庁・行政機関への電子届出・申請、税金の申告・納税用に企業向けに発行するものと、地方自治体が発行する公的個人認証サービスの電子証明書がある。公的個人認証サービスの電子証明書の対象は個人。
・電子契約用
企業間取引のために用いる電子署名の証明用
・その他
例えば、商業登記に基づく証明用電子証明書があります。これは、商業登記の内容を証明するもののようです。
こうしてみますと、電子証明書の種類は非常に沢山ありそうです。他にも探せばもっとありそうに思います。ひとつの証明書で、全てを賄えれると良いのですが、なかなかそうも行かないです。特に、PDFとの関係では、サーバ証明書やコードサイニング証明書は関係がありません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月29日
PDFと署名(14) — 電子証明書の検証
電子署名を検証するためには、その電子署名に付随する電子証明書が信用できるかどうかを判断する必要があること、そしてそのためには、電子証明書を発行した認証機関が信用できるかどうか判断しなければなりません。そして、認証機関は鎖のように繋がっていて、最終的にはルート認証局が信用の原点であることがわかりました。
一般人には、ルート認証局の信用を独自に調査するのは困難です。しかし、Web Trustなどの基準、あるいは、日本の電子署名法に基づく認定認証機関などであれば、ある程度の信用は確保できると考えられます。
公開鍵証明書のチェーンが信用できるルート証明書にたどり着ければ、第一関門はクリアされます。
電子証明書の検証では、さらに、次のことが必要です。
1.電子証明書が有効期限内かどうか。— これは、X.509公開鍵証明書の標準に準拠したものであれば、電子証明書の中に記述されていますので確認できます。
2.電子証明書が、失効していないかどうか。—電子証明書は、次のような場合に失効します。
・電子証明書に記載された事項について記録誤り等があった場合
・秘密鍵が漏えいまたはき損した場合
・失効の申請をした場合
失効した電子証明書のリストは、証明書失効リスト(CRL)として提供されることになっています。電子証明書がそのリストにないことを確認しなければなりません。なお、CRLを提供しないで、OCSPプロトコルを使ってオンラインで状態を問い合わせると証明書が失効しているか否かを解凍する方式の認証局もあります。
※これは、こう書くのは簡単ですが、実際に、実現するのはかなり大変ではないでしょうか?ちょっと疑問です。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月28日
PDFと署名(13) — その他のルート認証局/証明書
昨日は、日本における公的なルート認証局を見ました。海外では、ルート認証局として認定する審査基準のひとつに、米国公認会計士協会 (AICPA) が用意している「WebTrust for Certification Authorities」 プログラムがあります。
Webページはこちら:
AICPA/CICA WEBTRUST PROGRAM FOR CERTIFICATION AUTHORITIES VERSION 1.0
これは証明書発行機関を審査するプログラムで、このプログラムで認定されると、認証局はWebTrust シールを張ることができると書いてあります。WebTrustの実際の審査は、米国公認会計士協会のライセンスを受けた会計事務所などが行うようです。
Webを通じて、パスワードやカード番号などをセキュリティをたもって通信するには、公開鍵証明書による暗号化が必要です。公開鍵証明書を検証するにはルート証明書が必要ということで、Microsoftの Windows XP、Microsoft Windows Server 2003 および Windows Vista は、Windows Update Web サイトのWebTrust(同等の基準を含む)の審査を通った認証局のルート証明書を自動的にチェックしダウンロードする仕組みが用意されています。
2007年1月現在のMicrosoftルート証明書プログラムの認定メンバーは次にあります。
http://support.microsoft.com/kb/931125
Mozilla(ブラウザ)にもルート証明書が同梱される枠組みがあります。次のところに、MozillaのCA証明書同梱のための方針があります。
Mozilla CA Certificate Policy (Version 1.0)
これを見ますと、Mozillaの方が、Windowsよりも幅広いCA運営基準を認めているようです。
携帯電話は、容量の関係で数が少ないですが、ルート証明書が搭載されています。これらを見ますと、携帯電話のルート証明書も、公開鍵暗号化による通信(SSL通信)を行うことが主な目的で、電子署名はあまり意図していないようです。
[DoCoMoのルート証明書]
http://www.nttdocomo.co.jp/service/imode/make/content/ssl/spec/#p04
[SoftBankのルート証明書]
http://developers.softbankmobile.co.jp/dp/tech_svc/web/ssl.php
[auのルート証明書]
http://www.au.kddi.com/ezfactory/tec/spec/ssl.html
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月27日
PDFと署名(12) — ルート認証局の種類
前回は、電子証明書はルート認証局の自己証明書からスタートしてエンドユーザの電子証明書までの鎖ができているということを説明しました。
結局、ルート証明書を発行した認証局の信用が電子証明書の信用となっているわけです。会社や一部の組織の中で使う電子証明書であればプライベートな鎖で十分ですが、政府・地方公共団体の行政サービス、あるいは企業間取引などでつかうようなパブリックな電子証明書は、それを発行する認証局の鎖が一定の公的な信用が保たれている必要があります。
公的な信用という意味では、官公庁・行政、あるいは、「電子署名及び認証業務に関する法律に基づく特定認証業務の認定に係る指針」で認定された認証局を、その筆頭に挙げることができると思います。その日本におけるその種のPKIの認証局は、大きく分けると、次のように分かれます。
・政府認証基盤(GPKI)の認証局
・商業登記認証局(電子認証登記所(CRCA))
・地方公共団体における組織認証基盤(LGPKI)の認証局
・公的個人認証サービス(JPKI)に係る認証局
・民間認証局
この中で、GPKIの認証局は、次のものがありますが、政府機関のための官職証明書を発行するもので、民間人に証明書を発行する認証局ではないと思います。
・内閣府認証局
・警察庁認証局
・防衛庁認証局
・金融庁認証局
・総務省認証局
・法務省認証局
・外務省認証局
・財務省認証局
・文部科学省認証局
・厚生労働省認証局
・農林水産省認証局
・経済産業省認証局
・国土交通省認証局
・環境省認証局
・最高裁判所認証局
さらに、GKPIには他の認証局と相互接続するブリッジ認証局があります。
※政府認証基盤(GPKI)
それから、法務省が運営する「商業登記認証局(電子認証登記所(CRCA))」があります。これは商業登記関係の証明書を発行します。民間人にも関係ありますね。
また、地方公共団体における組織認証基盤(LGPKI)の認証局として、「LGPKIブリッジ認証局」と、「LGPKIアプリケーションCAの自己証明書」があります。この認証局は、地方公共団体のネットワーク用と思います。
さらに、各種行政サービスのための公的個人認証サービス(JPKI)に係る認証局として、「JPKIブリッジ認証局」と47都道府県の各認証局があります。これは行政サービス用ですので、民間人にも大いに関係があると思います。
※公的個人認証サービス・ポータルサイト
最後に、民間認証局として、次の認定認証局があります。
・日本認証サービス株式会社: AccreditedSignパブリックサービス2に係る認証局
・日本電子認証株式会社: AOSignサービスに係る認証局
・株式会社NTTアプリエ(旧エヌ・ティ・ティ・メディアサプライ株式会社): e-ProbatioPSサービスに係る認証局
・東北インフォメーション・システムズ株式会社: TOiNX電子入札対応認証サービスに係る認証局
・株式会社帝国データバンク: TDB電子認証サービスTypeAに係る認証局
・セコムトラストシステムズ株式会社(旧セコムトラストネット株式会社): セコムパスポートforG-IDに係る認証局
・ジャパンネット株式会社: 電子入札コアシステム用電子認証サービスに係る認証局
・全国社会保険労務士会連合会: 全国社会保険労務士会連合会認証サービスに係る認証局
・日本商工会議所: ビジネス認証サービスタイプ1に係る認証局
・四国電力株式会社: よんでん電子入札対応認証サービスに係る認証局
・株式会社中電シーティーアイ: CTI電子入札・申請届出対応電子認証サービスに係る認証局
・日本税理士会連合会: 税理士証明書発行サービスに係る認証局
・日本司法書士会連合会: 日本司法書士会連合会認証サービスに係る認証局
・株式会社NTTアプリエ: e-ProbatioPS2サービスに係る認証局
・日本土地家屋調査士会連合会: 日本土地家屋調査士会連合会認証サービスに係る認証局
・株式会社ミロク情報サービス: MJS電子証明書サービスに係る認証局
どうも、ざっと調べた範囲では、このあたりまでが、日本のパブリックなサービスに関わるルート認証局と思われます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月19日
PDFと署名(11) — ルート証明書の信用保証
電子証明書の信用を付与する仕組みは、電子証明書の鎖ですが、その鎖をたどっていくと行き着くところは、ルート証明書となります。電子証明書の鎖は次の図のように構成されます。
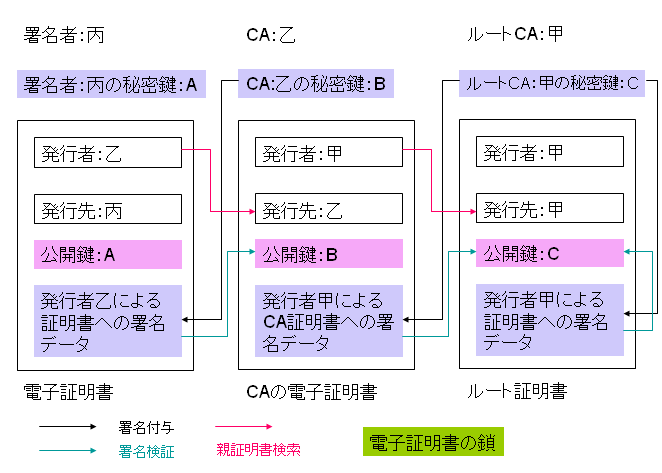
上の図は、署名者:丙の電子証明書、CA:乙の証明書、ルート認証局:甲のルート証明書の3つから電子証明書の鎖が構成されている場合の例です。
署名者:丙の電子証明書が信用できるかどうかは、ルート証明書まで鎖をたどって検証します。しかし、ルート証明書の信用は別の方法で付与する必要があります。なぜかといいますと、ルート証明書は自己署名証明書であり、自己署名証明書は、誰でも簡単に作ることができるからです。
※ルート証明書が改竄されていないかどうかは、ルート証明書の中の公開鍵を使って署名データの暗号を解読することで検証できます。しかし、信用できるかどうかは改竄されていないかどうかとは別問題。あくまで、発行者を信用して良いかどうか、ということです。
ルート証明書が信用できるかどうかが判断できない限り、署名者:丙の電子証明書が信用できるかどうかは判断できません。では、どうするのでしょうか?
例えば、企業内や、仲間内のような比較的狭い集団であれば、ルート証明書の発行者を何らかの方法で特定し、その人が信用できるかどうかでルート証明書が信用できるかどうかを判断できるでしょう。
また、日本政府のPKI(GPKI)の場合は、ルート証明書のフィンガープリントを官報などで公開することで、ルート証明書の信用を判断する仕組みになっています。
参考:
・政府認証基盤(GPKI)
・財務省認証局について
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月18日
PDFと署名(10) — 自己証明書とルート証明書
さて、前回は、電子証明書を発行する機関を認証局(CA)ということ、そして、その発行された電子証明書の信用はCAの電子証明書(CA証明書)の信用に依存していることを説明しました。
CA自身の信用が他のCAに依存しているのですが、その信用の鎖をたどって遡っていきますと、最後には、ルートCAにたどり着きます。ルートCAの証明書(ルート証明書)は、他のCAが署名したものでなく、自分自身で署名したものになります。
公開鍵証明書の標準形式X.509には、発行元(Issuer)と発行先(Subject)の項目があり、そこに、証明書を発行した機関と発行先の機関の名前が書かれています。
発行元と発行先が同じになっている公開鍵証明書のことを、自己署名証明書と言います。

さて、そこで、次のような疑問をもってしまいました。
1.自己署名証明書は、電子署名法第13条でいうところの「電子証明書」に該当するのでしょうか?
※電子署名法第13条について
2007年04月13日PDFと署名(8) — 公開鍵証明書の発行と有効性検証
この文章を読みますと、どうも、自己署名証明書は電子証明書とは、言えないのではないかと思うのですが。今のところ、ちょっと自信がありません。
2.ルート証明書は、必ず自己署名証明書になります。しかし、逆に、自己署名証明書はルート証明書ではないでしょう。これは、自分で公開鍵と秘密鍵を生成して、自分の公開鍵に自分の秘密鍵で署名したX.509形式の公開鍵証明書を作れば、定義上、自己署名証明書になることから考えて明らかです。
まとめますと、電子署名の信用の根拠は、電子証明書にあります。その電子証明書の信用の根拠は、その証明書に署名したCAにあります。そのCAのCA証明書には他のCAが署名していますので、CAの信用の根拠は、そのCA証明書に署名した他のCAにあります。という具合にCAの信用の根拠をずっとたどっていきますと、ルートCAの自己署名証明書であるルート証明書に行き着きます。
そうしますと、どのような条件を満たす自己署名証明書が信用できるルート証明書として認められるのでしょうか?これは、電子署名ではかなり重要なポイントだと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月14日
PDFと署名(9) — 電子証明書の信用を保証する仕組み
昨日は、電子署名法では、電子署名がある電磁的記録は、その電子署名が本人だけが行うことができることとなるものである場合に限り真性なものと看做す、とされていることを見ました。
これを技術的にどういう仕組みで実現しようとしているか?これはなかなか面白いと思います。で調べてみましたら、かなり、分かりやすくて、良い資料がありました。
「PKI 関連技術解説」(独立行政法人 情報処理推進機構 2005年最終更新)
※この資料は私のレベルには良くできています。こんな資料をWebで無料で読めたら、書籍が売れるわけがありません。PKIの新しい本がないのも良く理解できます。
電子証明書の信用を保証するのは、本人登録を受付て、電子証明書を発行する機関です。本人登録を行う機関をRA(Registration Authority)、電子証明書を発行する機関を認証局CA(Certification Authority)と言います。RAは登録を申請した人が本人かどうかを確認する機関ですから、かなり人間的なアナログ組織、CAの方はデジタルな世界です。(RAとCAを分ける必要はないと思いますが。)
で、ともかくCAは電子証明書を発行します。そして、CAは、それが発行する電子証明書に、CA自身の秘密鍵で電子署名をし、CAの電子証明書を添えます。従って、各人の電子証明書はCAの電子証明書に信用の基盤を持つわけです。
では、そのCA自身の信用をどうやって保証するのでしょうか?
「PKI 関連技術解説」では、CAの信頼を保証する「信用モデル」について次のようなモデルがある、としています。
・単独CAモデル—1つの CA が全てのユーザに証明書を発行する方式。企業内などの閉鎖組織で用いる。
・階層型モデル—複数の CA を階層型(ツリー構造)に構成する方式。最上位のルートCAに絶対的(?)信頼を寄せる。下位のCAは上位のCAを信用する。
・Web モデル—Web ブラウザにはあらかじめルート CA の証明書が幾つか埋め込まれている。この証明書を信用する。
・メッシュモデル—複数の CA を接続して、相互に認証しあう方式。
・ブリッジ CA モデル—複数の CA がブリッジ CA を介して接続する。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月13日
PDFと署名(8) — 公開鍵証明書の発行と有効性検証
一般に電子署名を利用する主な目的は、署名した人を特定し、その人により署名された文書が改竄されていないことを検証することにあります。これを支える技術のキーポイントは、公開鍵暗号化方式による電子署名自体であることは無論です。
しかし、公開鍵暗号化方式のみでは、署名者を特定することはできません。署名者を特定できない以上改竄の有無を判定できるはずはありません。署名対象文書を作成した人と別の人が、偽って署名していることがないと言い切れないならば、内容が改竄されていないと言い切れないのは自明です。
ですので、本当に重要なポイントは、署名を検証するための公開鍵を保証する公開鍵証明書のあたりにありそうだ、ということになります。
このあたりどうなっているか、電子署名及び認証業務に関する法律(平成十二年五月三十一日法律第百二号)(電子署名法)を読んでみましょう。
○この法律では、公開鍵証明書のことを「電子証明書等」と言っています。
第十三条で、電子証明書等とは、利用者が電子署名を行ったものであることを確認するために用いられる事項が当該利用者に係るものであることを証明するために作成する電磁的記録その他の認証業務の用に供するものとして主務省令で定めるものをいう、と説明されています。
「等」という部分が、ちょっと曖昧ですが、これを省略して、電子証明書と呼んでも良いのではないでしょうか。そこで、今後は、公開鍵証明書のことを、電子証明書ということにします。
第三条には、「電磁的記録であって情報を表すために作成されたものは、当該電磁的記録に記録された情報について本人による電子署名(これを行うために必要な符号及び物件を適正に管理することにより、本人だけが行うことができることとなるものに限る。)が行われているときは、真正に成立したものと推定する。」
とありますので、電磁的記録に電子署名がなされていたとき、それが真性に成立すると言うためには、その電子署名が「本人だけが行うことができるものに限る」ことを証明しなければなりません。
では、電子証明書で電子署名を検証すれば本人だけが行うことができると言えるのでしょうか?このあたりがどう扱われるか、とても難しそうです。
電子証明書は、署名が本人に関わるものであることは証明できることになります。では、例えば、ある利用者が公開鍵を認証事業者に登記して電子証明書を入手した後に、秘密鍵が漏洩してしまった場合は、どうなるのでしょうか?これは、秘密鍵が適正に管理されていないので、署名を本人だけが行うことができるといえませんので、真正に成立したとは言えません。
これを、電子証明書では、どうやって判定できるのでしょうか?また、そういう判断を行うための技術基盤はどうなっているのでしょうか?これはもっと調べてみないと分かりません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月12日
PDFと署名(7) — RSA、DSA、ECDSA って?
Wikipediaの電子署名の項には、電子署名方式(アルゴリズム)がいろいろ紹介されています。
RSA署名、離散対数問題を利用するElGamal署名、楕円曲線を利用するとか、いろいろ面白そうなのがあります。しかし、言ってみればこれらのアルゴリズム自体は、ハンコで言うとハンコの字形をいろいろ工夫して変えているようなものです。
例えば、個人の「実印」とか、会社の「代表者印」は、彫られた文字の形もさることながら、法務局にその印鑑を登記してあることの方が重要です。いままでの紙の世界では、重要な契約などには、実印をついて印鑑証明書を添えることが求められます。
それに対して、電子署名の場合は、公開鍵を登記して、「公開鍵証明書」をもらうことになります。
いろいろ資料を見てますと、結局のところ、どのような署名アルゴリズムを使うかよりも、「公開鍵証明書」に関連する問題の方がずっといろいろと難しく、また、重要なようです。
で、その話に進もうかと思いましたが、Wikipediaの「電子署名」を見直していて、日本の電子署名法では、RSA、DSA、ECDSA の3方式を指定とありますが、この3方式ってどんな方式なんだろう、所詮、印鑑の字形じゃないか?と無視して良いかどうか?とちょっと気になりました。
この法律を検索しても、RSA、DSA、ECDSA というような言葉は出てきません。大体、法律でアルゴリズムを決めるとは思えないですがね。
調べてみましたところ、これは、総務省、法務省告示第二号、経済産業省「電子署名及び認証業務に関する法律に基づく特定認証業務の認定に係る指針」(平成13年4月27日)にありました。
○RSA方式(オブジェクト識別子 1 2 840 113549 1 1 5)又はRSA-PSS方式(オブジェクト識別子1 2 840 113549 1 1 10)であって、モジュラスとなる合成数が1024ビット以上のもの
○ ECDSA方式(オブジェクト識別子 1 2 840 10045 4 1)であって、楕円曲線の定義体及び位数が160ビット以上のもの
○ DSA方式(オブジェクト識別子 1 2 840 10040 4 3)であって、モジュラスとなる素数が1024ビットのもの
の3つが基準を満たすとあります。
・RSAはよく聞きますが、大きな数の素因数分解が困難であることを利用する方式です。
・ECDSAは楕円曲線暗号(Elliptic Curve Digital Signature Algorithm)の略。
Elliptic Curve DSA
・DSA(Digital Signature Algorithm)は、米国のNISTが定めたもので、ElGamal署名の改良版だそうです。
DSA:Digital Signature Algorithm
やっぱり、これらは印鑑の字形に相当するものと言ってよいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月10日
PDFと署名(6) — 公開鍵証明書
先日(2007年04月06日)は、電子署名による認証の本質的な役割は、電子証明書が担っていること、そして、電子証明書による認証の基盤として、PKIという仕組みができていることをお話しました。
日本では、このような仕組みが作られたのは、2000年頃ではないかと思います。週末に新宿のジュンク堂に行って探してみたのですが、電子署名関係の本は、2000年頃に出版されたものが多いようです。この頃に、日本で電子署名法が施行されましたのが2001年です。2000年頃が電子署名ブームだったのですね。
※参考資料
総務省:電子署名・電子認証ホームページ
電子署名及び認証業務に関する法律(平成12年法律第102号)
その後、もう6,7年経過していますが、その後、あまり新しい書籍も出ていないようです。少なくともジュンク堂には、この2,3年に出版された本は見当たりませんでした。現金なものです。それで、少し古い本ですが、「PKI公開鍵インフラストラクチャの概念、標準、展開」(カーライル・アダムス他、ピアソン・エヂュケーション社発行)と言う本を買ってきて読んでみました。
で、前置きが長くなりましたが、もう少し、電子証明書について調べてみましょう。
1.各人の保有する秘密鍵とそれに対になる公開鍵は、数学的なペアになっていて切り離せません。
2.では、そのペアが、本当に所有者であると主張する人のものであることは、もちろん、数学的には証明できません。登録機関に本人であることの証拠を沿えて登録し、その登録に基づいて、公開鍵に証明書を付けます。
3.公開鍵と証明書のペアが、広く公開されるわけですが、そのペアリングを保証するために証明書の発行元が、その発行元の秘密鍵で署名します。この署名があることで、公開鍵と証明書の対応関係を切り離すことができなくなります。
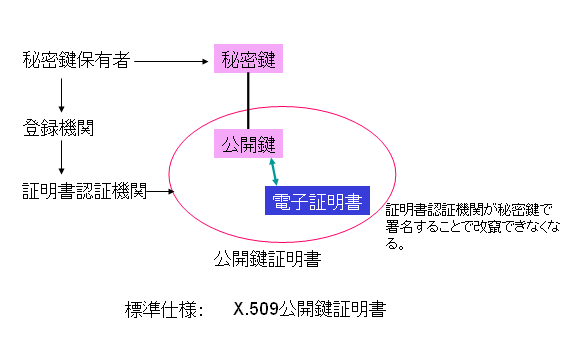
4.公開鍵証明書が広く一般に使われるためには、公開鍵証明書は、標準形式で作成する必要があります。標準形式には幾つかあるようですが、一番普及していそうなのが、X.509公開鍵証明書仕様というものだそうです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月03日
PDFと署名(3) — 公開鍵暗号方式
昨日は、「公開鍵暗号方式」というキーワードが出てきましたが、公開鍵暗号方式とは、どういうものでしょうか?
公開鍵暗号方式は、もう非常にポピュラーな言葉で、Webで検索しますと、簡単な説明は一杯あります。ちなみに、Wikipediaでは、次の説明があります。
これらを要約しますと公開鍵暗号化方式とは次のようなものです。
(1)公開鍵と秘密鍵というペアの鍵を使って暗号化した情報のやり取りを行う方式。
(2)これで機密情報通信を、次のように実現します。
a.機密情報を受信する人は、公開鍵と秘密鍵を生成するツールを使って、自分独自の公開鍵と秘密鍵を作ります。公開鍵は情報源となる相手に渡します。秘密鍵は他者に見せないように保持しておきます。
b.機密情報を送信する人(情報源となる人)は、送信したい相手の公開鍵を使って、送りたい機密情報を暗号化します。そして、暗号化された情報を送りたい相手に送信します。
c.機密情報を受信した人は、その情報を自分の秘密鍵を使って暗号解読します。
おおざっぱな仕組みは、次の図のように表すことができます。
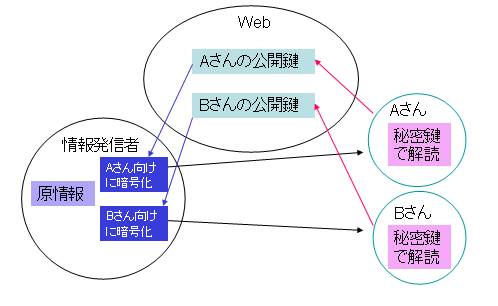
この仕組みで、機密を保持した通信を行うには、次の条件が成り立つ必要があることは簡単に分かります。
(1)公開鍵と秘密鍵のペアは、送りたい相手毎に違っていなければなりません。そして、公開鍵で暗号化した情報は、それと対になる秘密鍵のみで解読ができること。
(2)さらに、公開鍵が情報を送りたい相手のものであることを一意的に保証する仕組みが必要です。送り手とは別の人の公開鍵で間違って暗号化してしまえば、送りたい相手以外に情報が漏れてしまうからです。
このあたりの詳しい説明は、もう少し専門的な解説に任せることにして、上の説明からしますと、公開鍵暗号化方式と電子署名とは、どうも違うもののように思います。
単純に考えて、電子署名では、情報を送信したい人が誰であるかを証明したいわけです。他人の公開鍵を使って署名したところで送信したい人が誰かを証明できるはずがありません。公開鍵は名前どおり、誰でも入手できるものだからです。
ところが、Webの説明をざっと読みますと、電子署名は公開鍵暗号方式を使っているという説明が多いようです。
昨日紹介しました、Wkikpdeiaの電子署名の説明の書き出しも、「電子署名を実現する仕組みとしては、公開鍵暗号方式に基づくデジタル署名が有力である」とあって、一見、公開鍵暗号化方式を使うとそのまま、電子署名ができそうに思えてしまいます。しかし、このような説明はあまりに単純化しすぎではないのかな?という疑問を持ちました。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月02日
PDFと署名(2) — PDFの署名機能と電子署名
現在、PDF Toolに電子署名機能を追加しようとして開発していることは、昨日、申し上げました。開発担当者がやっていることの報告を聞いたり、時間があるときにPDF Referenceを見たりしてますと、PDFの署名機能と、一般の電子署名といわれる機能は、かなり異なっているように思います。
で、かなり異なっているようだということはなんとなく分かりますが、厳密にどこが、どう異なっているかは説明できません。そんな具合で、どうも、隔靴掻痒の感があります。
これからPDF 電子署名機能を出すにあたり、これではちょっと頼りない。ということで、ブログを書くついでに、このあたりを、もう少し明確にするために自分で調べてみることにしました。実際、とこが異なっているかを理解するには、一般の署名機能もPDFの署名機能について少なくとも概略を理解する必要があります。そこで、まず、次のことを整理してみたいと思います。
(1)一般に電子署名とはどういうものか?
(2)PDFの電子署名とはどういうものか?
電子署名とは?
フリー百科事典『ウィキペディア(Wikipedia)』の「電子署名」の項を見てみます。
次のような説明があります。
「電子署名とは、電子的な文書に付与する徴象であり、紙文書での印やサインに相当する機能を意図したものである。」
電子署名は、パソコンなどで扱うデジタルデータに付与するもので、紙文書での押印やサインに相当するものというのは、なんとなく分かります。
「電子署名を実現する仕組みとしては、公開鍵暗号方式に基づくデジタル署名が有力である。日本では電子署名及び認証業務に関する法律(電子署名法)にて、RSA、DSA、ECDSA の3方式を指定している。いずれも公開鍵暗号方式に基づく方式である。」
ということで、この文章からは次のことが分かります。
・電子署名には、「公開鍵暗号方式」に基づくものと、「そうでないもの」がある。
・公開鍵暗号方式が有力。
・公開鍵暗号方式の中では、RSA、DSA、ECDSA の3種類が日本では法的に認められている。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年04月01日
PDFと署名(1) — 「書けまっせ!!」に電子署名は必要?
「書けまっせ!!PDF」は、現在、V2ですが、もちろん、次のV3に向けて準備を進めています。
次のバージョンでは、PDFをもっと便利に使えるいろいろな機能を強化したいと考えています。その機能強化ポイントの一つとして、署名機能が一つの候補です。
日本で、申請書と来たら印鑑はつき物です。ですので、PDFの申請用紙に文字を簡単に記入できるようになったら次は押印機能の実装は自然な流れでしょう。
そこで、ちょっと悩んでいることです。
印影を画像にしてPDFに貼り付けるだけなら、操作性を問わなければ、今の「書けまっせ!!PDF2」でもできます。ただ、印影をPDFに貼り付けるのは簡単ですが、実際のところ、それで良いのでしょうか?
アンテナハウスでは、PDF Tool 用にPDF電子署名機能を開発しています。遠からず、システム部品としてのPDF Toolに、電子署名機能付きのバージョンをリリースできると思います。
企業用のシステムで、本格的な署名・認証まで行うということになりますと、こうした電子署名機能も必要なように思います。しかし、企業内の本格的なシステムならともかく、「書けまっせ!!PDF2」のような簡易なPDF筆記具に、電子署名機能が必要なのでしょうか?
紙の世界での認印というのは、ほとんどデジタルの世界では、画像を貼り付けたものと同等です。そこにいきなり、高度な電子署名の機能が本当に必要なのでしょうか?「書けまっせ!!PDF2」は、紙に文字を書く筆記具のようなソフトを目標にしていますので、認印を実装すれば、それで良いんじゃないか、という気もします。
どんなものでしょうか。
※今日はエイプリルフールです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月31日
Open XML と ODFの比較レポート
少し古い情報ですが、Microsoft Office 2007のXML文書形式である「Open XML」と、OpenOffice.orgの文書形式である「ODF(Open Document Format)」についての、IDCの調査レポートの日本語版が公開されています。
IDC report on Open Document Standards (Japanese version)
ODF陣営を中心に、既に、ODFがISOの標準になっているのに、二つ目の国際標準は要らない、という意見も見られるようです。それに対して、このIDCのレポートでは、オープンな標準が二つあっても別に問題はないという結論を出しているように読み取れます。多分、それが、このレポートが、Open XML のWebサイトで公開されている理由なのでしょう。
IDCのレポートは、ざっと一読してみる価値はあります。
ところで、私は、「Office 2007」の文書形式が、標準になることについては、IDCの言うオープンな標準とは別の観点から、大きな意味があると思っています。
このことは、以前に、XML開発者の日にも、コメントさせていただきましたけれども繰り返しますと、— Microsoftは、Word2003で、WordprocessingMLを出したとき、「これが標準だ」、と言っていたはずなのですが、4年経過してWord2007になった時点で、新しいWordprocessingML(2007)は、Word2003のWordprocessingMLとはかなり変わってしまいました。
弊社では、Word2003のWordprocessingMLをいろいろ調べて、Word2003によるXMLオーサリング・システムを開発したりしたのですが、Word2007でファイル形式が変わってしまったことで、また、(全部ではありませんが)やり直しが必要でしょう。
オーサリングだけではなく、サーバべース・コンバータは、Word2003のWordprocessingMLを組み版することはできるのですが、Word2007のWordprocessingMLは組版できません。また作り直しです。そんなわけで、早いところ、ISOの標準になって、Microsoftの独断でファイル形式を変更できないようになると、ありがたいと思っています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月26日
日本語組版はグリッドベースで行うと言って良いのか?(8)
CSSのページに、W3Cのリチャードイシダ氏が書いた、「Tutorial: CSS3 and International Text」という記事があるのを見つけました。
Tutorial: CSS3 and International Text
この文書は、前書きに「CSSの非ラテン・テキストのサポートに関し、将来どうなるかについて概略を知りたいと考えているXHTML/HTMLとCSSによるコンテンツ作者向け」とされています。このチュートリアルは、CSS3のドラフトを元にした解説を意図していると思われるのですが、この中に、ドキュメント・グリッドという項があります。簡単に紹介してみましょう。
東アジアの言語で書かれる文書では、グリフをページの上に配置するときグリッドのパターンにレイアウトするのが一般的である。これは、漢字、かな、ハングル文字が同じ幅をもつという事実によっても支援される。
CSS3では、グリッドを適用し、グリッドの中でラテンのテキストなどの全角でない文字を管理する方法について幾つかの属性を定義している。これらの属性によって、表意文字以外の文字に対してもCJK文字と同じようにグリッドを当てはめるかどうかを指定する。
次のスライドは、グリッドを当てはめないときの日本語の縦書きを示す。
http://www.w3.org/International/tutorials/css3-text/en/slides/Slide0170.html
l
さらに次のスライドは、前のスライドに対してあるグリッドの属性を当てはめたものを示す。
http://www.w3.org/International/tutorials/css3-text/en/slides/Slide0180.html
このスライドは、2007年02月27日 日本語組版はグリッドベースで行うと言って良いのか?(5)の10.2 line-grid-mode、10.3 line-grid-progressionの説明です。
以前として、この10.2 line-grid-mode、10.3 line-grid-progressionの意味が分かりません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月10日
Open Publish Conference — XML オーサリング
Open Publishは、オーサリングのトラック、コンテンツ・マネジメントのトラックの二つのトラックで開かれていました。この会議は出版業界を対象にしているようです。出版においてどのようにコンテンツを作成・管理して、コンテンツを多重利用するか、という日本でもおなじみのテーマです。
プレゼンテーションを行っている人の大半は、どうもXML関係のコンサルタントのようです。
私は、オーサリング・トラックをずっと聞いていたのですが、人気があるテーマのときは、聴衆が集まりますし、あまり関心がないテーマでは、聴衆が少なくなります。聴衆の数の変化からは、オーサリング・トラックでは、ODF(Open Document Format)とMicrosoft Office 2007のXML形式についての話題に関心がもたれたようです。多分、これは、日本と同じでしょう。
アンテナハウスでも、ある会社のためのMicrosoft WordでXML(マニュアル)を編集・組版するシステムを作っています。そんなこともあり、Mark Jacobsonの「Microsoft WordでXMLをオーサリングする実際の話」には関心がありました。このプレゼンは今日のプレゼンの中では参加者が一番大勢集まりましたので、参加者の間でも関心を集めたようです。
この話の内容は、次のようなものです。
(1)Word97/2000時代には、RTFをXMLに変換するシステムを作った。
(2)Word2003でWordMLで保存できるようになり、RTFの代わりにWordMLを使うことで、XMLからXML変換で済むようになり楽になった。
(3)Word2007では、WordMLが標準のフォーマットとなった。
(4)しかし、Word2003もWord2007もカスタムXMLのサポートは中途半端、ユーザ・インターフェイス(GUI)は、XML編集には向いていないなど、XMLエディタとして使うには向いていない。
(5)Wordのスタイルは平坦なので、ネストした構造をWordのスタイルで表すことができないし、属性の入力、混合内容(Mixed Content)を編集するのは非常に難しい、など。
ざっくり言って、私達も経験で知っているのと同じような内容で、あまり目新しさは感じませんでした。
あとは、立法(legislative)に関するオーサリングと出版についてのプレゼンが二つありましたが、こちらは、両方とも実際の地方自治体でのシステムのデモもあり、なかなか面白いものでした。XSL Formatterは、米国の州政府・カナダ政府の法律出版システムなど、法律の出版物の作成に使われている例がいくつもあります。今日のプレゼンテーションを聞いて、なぜ、法律のシステムにXMLが向いているかが理解できました。
今日は、6つ(6人)のセッションを聞いただけなのですが、その講演者でXSL Formatterのユーザが2人いました。XSL Formatter=XSL-FOの代名詞とまでは行きませんが、これは、なかなかの数字ではないでしょうか。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月09日
CSS3 Text Level3 モジュールの新草稿が公開
W3CのCSS3仕様案の中で、文字組版に関係する部分である「CSS3 Text」の新しい草稿が3月6日に公開されました。
CSS Text Level 3
W3C Working Draft 6 March 2007
新しい草稿では、日本語の約物の詰めの仕様(7.3. Fullwidth Punctuation Kerning: the 'punctuation-trim' property)に関する部分がだいぶ変わっています。
また、ぶら下げ禁則なども盛り込もうとしているようですが、まだ、定義が不十分という状態のようです。
9.2 Hanging Punctuation: the 'hanging-punctuation' property
Textモジュールは、文字組版に関する規定ですが、日本語の組版からしますと、重要な和欧文間の空き量などは入っていません。
狙いとしては、Typographyを実現しようということと理解していますが、多言語のTypographyを一元的に扱うというためには、もっと、世界中の専門家の英知の結集が必要なように思います。
なお、CSS3の仕様進捗状況について、次のページの情報をついでに更新しておきました。
XML資料室:W3CにおけるCSS仕様策定の動向
ご活用ください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月04日
日本語組版はグリッドベースで行うと言って良いのか?(7)
昨日は、Microsoft Wordのページ設定で、「文字数と行数を指定する」、「原稿用紙の設定にする」、という二通りの設定をして、文字を入力した結果を検討してみました。
その結果を見ながら、2007年02月27日日本語組版はグリッドベースで行うと言って良いのか?(5)を振り返って、CSS3の10.2 line-grid-modeの仕様に出ているサンプルの図と照らし合わせてみます。
そうしますと、Microsoft Wordの「文字数と行数を指定する」(標準の字送りOFF)は、すなわち、CSS3のallグリッド・モードと同じであり、「原稿用紙の設定にする」は、ideographグリッド・モードと同じになっていることが分かります。
このことからも、CSS3 Text Module W3C Candidate Recommendation 14 May 2003の10. Document gridの仕様は、Microsoft Wordのページ設定の仕様をベースに作られていると言って間違いない、つまり、CSS3(案)に規定されているグリッドの仕様は、ワードプロセッサの原稿清書用の機能をCSSに持ち込んだものである、といえます。
このMicrosoft Wordの機能は、従来であれば手書きで行っていた、論文集・作文集の原稿執筆などを、原稿用紙と鉛筆の世界からワードプロセッサを使って行うための機能と考えられます。つまり、ワードプロセッサを紙と鉛筆の代わりに使って原稿書きをするためのものです。そのための目的としては重宝されるものと思います。しかし、そこで出来上がった結果は、あくまで、清書されてプリントされた原稿であって、そのまま印刷物にするものではありません。
これに対して、JIS X4051「日本語文書の組版方法」は、表題の組版から自明なように印刷のためのものであり、適用範囲では、主に書籍に適用する、とあります。
XSL-FOの用途は、XMLドキュメントの組版をすることにありますので、適用範囲は、書籍あるいは操作説明書などの書籍に近い印刷物となります。従って、XSL-FOには、原稿清書用の機能は不必要と考えられます。
では、CSSには、原稿清書用の機能が必要なのでしょうか?これは、CSS3の適用される用途にも依存しますので、なんとも言えません。
ただ、CSS3 Text Module W3C Candidate Recommendation 14 May 2003を見ますと、"Giving a fixed advance width to ideograph grapheme clusters only. Other grapheme clusters are spaced normally. This is called "genko" in Japanese typography."(漢字かな類のみを固定ピッチとし、他の文字には通常のスペースを与える、これは、日本のtypographyでは"原稿"と呼ばれる)という文章があります。
ここでTypographyとはなんでしょうか?Wikipediaの説明は以下のようになっています。
Typography英語版
Typography is the art and techniques of type design, modifying type glyphs, and arranging type. Type glyphs (characters) are created and modified using a variety of illustration techniques. The arrangement of type is the selection of typefaces, point size, line length, leading (line spacing) and letter spacing.
Typography is performed by typesetters, compositors, typographers, graphic artists, art directors, and clerical workers. Until the Digital Age typography was a specialized occupation. Digitization opened up typography to new generations of visual designers and lay users.
日本語版
タイポグラフィ (英: Typography) とは、活字(あるいは一定の文字の形状を複製し反復使用して印刷するための媒体)を用い、それを適切に配列することで、印刷物における文字の体裁を整える技芸である。タイポグラフィの領域はその周縁においては、木版を用いて文字を印刷する整版、見出し用途のための木活字の使用、やはり木活字を使用する古活字版、さらにはレタリングやカリグラフィー、東アジアの書芸術と、技術的内容においても審美的様式においても、深く連関する。
この説明を見て、直ぐに分かることは、原稿執筆はTypographyにはあてはまらないということです。もし、CSS3が、原稿とはTypographyの一種であると理解して書かれているならば、まず、この理解の誤りを正す必要があります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年03月03日
日本語組版はグリッドベースで行うと言って良いのか?(6)
さて、CSS3のグリッドの仕様はだれが考えたのかは、私には分かりません。しかし、CSS3 Text Module
W3C Candidate Recommendation 14 May 2003を担当したのがMichel Suignard (Microsoft)となっていますので、恐らく、Microsoft関係者ではないかと思われます。
それで、ベースになっているのは多分Microsoft Wordでしょう。実際、Microsoft Word2003(英文)のページ設定のダイヤログには、次のような機能があります。
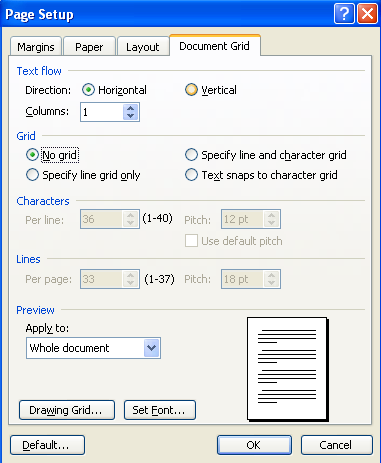
Word2003の日本語版で、このダイヤログに相当するのは次の図です。
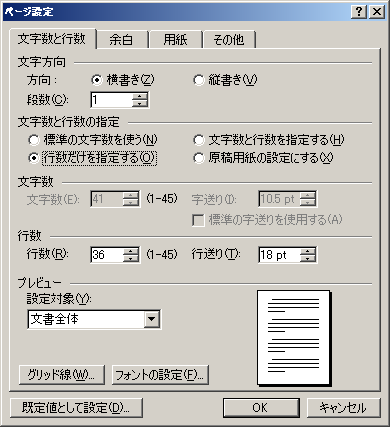
1.文字数と行数の設定
Microsoft Word 2003では、「文字数と行数を指定する」にチェックすると一行の文字数とページ内行数を設定できます。「標準の字送りを使用する」にチェックをいれない状態では、字送り(文字ピッチ)は用紙の幅から左右の余白を引いた残りの本文領域の幅を文字数で割った値になります。行ピッチも同様に、用紙の高さから上下の余白を引いた数字になります。この設定で文字を入力すると次の図のようになります。

このとき、「標準の字送りを使用する」にチェックを入れますと、文字ピッチが文字の大きさになります。この設定で文字を入力すると次の図のようになります。

2.原稿用紙の設定
次に、「原稿用紙の設定にする」(英語版では「Text snaps to character grid」)にします。すると、文字が各グリッドの中央に配置されます。さらに、ラテンアルファベットの文字配置が、単語ベースになります。すなわち、最初の図では、ラテンアルファベットを1バイト=半角で入力したときは、2文字ずつが一つのグリッドに入っていたのですが、「原稿用紙の設定」では、ラテンアルファベットは文字単位ではなく、単語単位で配置されて、次の図のようになります。

投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年02月27日
日本語組版はグリッドベースで行うと言って良いのか?(5)
CSS3 のText Moduleの10. Document gridの部分、初めて、ざっと見てみましたがどうも大きな問題がありそうです。このまま仕様になったら大変なことです。以下に簡単に抄訳しておきます。
10.1 ドキュメント・グリッドとはなにか?
中国語や日本語のグリフは、ページの上に1次元または2次元で指定されたグリッドに従って配置するのが一般的である。文字詰め方向のグリッドは、行の中の文字の進行幅を変更することで得られる。
ルーズ・グリッドモード、原稿モード、固定幅モードのようないくつかのモードがあり、line-grid-mode属性でこの進行幅の変更の許可/不許可を切り替え、line-grid-progression属性でその値を設定する。
10.2 line-grid-mode
値:noneまたはideographまたはall
none
グリッドなしで通常のテキスト配置が適用される。
ideograph
内容をストリップ(細長い小片)とよぶ単位に分割する。各ストリップは、それを含む最小個数のグリッドの中央に配置される。グリッドの幅は、line-grid-progressionで決まる。
全角文字はひとつずつでストリップになる。半角のかなをベースとする文字も一つのストリップになる。イメージのような分割できないオブジェクトもストリップである。その他のものはまとめて一つのストリップである。そして、
・全角文字、半角かなはグリッドの中央に可視化する。
・その他の文字に対応するストリップ(ラテン文字など、つまり英単語などが該当する)は、それを含むのに必要な最小個数のグリッドの中央に配置される。
・一つのグリッドに入りきらない全角文字は、それを含むのに必要な最小個数のグリッドの中央に配置される。(1.5倍角の文字は、2個のグリッドの中央に置くという意味)。
このideographモードでは、特別なテキストの均等割付やグリフの幅の調整は不許可になる。
例

all
この指定は、均一幅のレイアウト用である。ストリップを定義する方法が異なっていて、非結合の基底文字をもつ書記素がストリップになる。結合する基底文字(アラビア文字など)は結合している単位毎にストリップになる。
☆次の例のように、ラテンアルファベットが1文字単位でストリップになるということようです。

10.3 line-grid-progression
これはグリッドの幅を指定する方法です。
このサンプルとして、次の図のような縦書か横書の分からないサンプルが出ています。


このような仕様は、JIS X4051の考えとはかなり異なっています。多分、日本語組版の専門家には受け入れがたいのではないでしょうか?
CSS3は、まだ検討中で、構成もかなり変わっています。最新のドラフトでは、このグリッドの仕様がなくなったかと思いきや、ファイル構成が変わって別のところに、まだ、しっかりそのまま生きているようです(最新ドラフトは、W3Cの会員のみ閲覧用で未公開ですが)。これはちょっと問題ではないでしょうかね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年02月26日
日本語組版はグリッドベースで行うと言って良いのか?(4)
日本語組版では、昨日お話しました、約物の詰め処理、あるいは、和欧文間の文字間隔など基本的な詰め処理や禁則処理などを行います。こうした結果、文字の配置は必ずしも、正方形の枠を並べた状態、すなわちグリッドにうまく入らないことが多くなります。
それにも関わらず、日本語組版はグリッドベースで行われる、と表現してしまうと、次のような問題が起こります。
約物の詰め処理や、禁則処理を説明したとたんに、「そうすると文字がグリッドからずれてしまうがどうするのか?」という疑問を引き起こしてしまいます。
これは、まさに、昨年のXSL-FO 2.0 の会議で経験したことです。
昨年10月18日のXSL-FO 2.0 の会議で、プレゼンテーションが終わったとたんに、グリッドベースと矛盾する、約物の詰め処理や、禁則処理をどうやって定義するのか?と質問の嵐になりました。
それだけではなく、10月19日のミーティングでもそのことをいろいろと説明を求められたわけです。
要するに、グリッドベースということで、縦横に引いた線に合わせて文字を配置する、と言うことを頭に思い浮かべるのに、その後で、詰め処理を説明すると、これは論理的に矛盾していることになりますので、聞いた方が混乱してしまうことになります。
これに類する話は、CSS3の仕様案にも盛り込まれています。CSS3のText Module(このモジュールの最新は、現在、Webには見当たりません。)の古いバージョンには、一見もっともらしい、次のような定義があります。
10. Document grid
10.1. What is document grid?
It is very common for the glyphs in documents written in East Asian languages, such as Chinese or Japanese, to be laid out on the page according to a specified one- or two-dimensional grid. The concept of grid can also be used in other, non-ideographic contexts such as Braille or monospaced layout.
(中国語や日本語のグリフは、ページの上に1次元または2次元で指定されたグリッドに従って配置するのが一般的である。)
原典:CSS3 Text Module W3C Candidate Recommendation 14 May 2003
そして、この文章の後ろの方には、JIS X4051的に見ますと、まったくでたらめな次のような文字配置が規定されています。
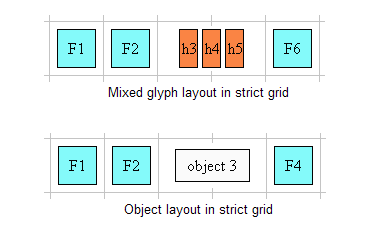
上の図は、厳密なグリッド・モードと言うらしいですが、これはグリッドを優先して和文をグリッドに合わせて配置し、和文と欧文の間隔は、和文文字用グリッド端と欧文の単語の始端・終端の間隔にすることになります。しかし、このような文字配置は、現実の日本語組版では決して行われないでしょう。この仕様は、日本語組版はグリッドベースで行われるという公理(!?)から、論理的に導き出されていると思われます。しかし、これは現実には適合していません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年02月25日
日本語組版はグリッドベースで行うと言って良いのか?(3)
昨日は、XSL-FOやCSSにJIS X4051で定めている、日本語組版における基本的な文字配置を設定できるようする必要があると言いました。そのためは、具体的にどういうことが必要でしょうか?
これは、簡単に言いますと、2007年02月23日 日本語組版はグリッドベースで行うと言って良いのか?(1)の最後の二つの図にある式に出てくる変数を設定できるようにすれば良い、ということになります。
ここで、グリッドという言葉を持ち出す必要はありません。むしろ、グリッドを持ち出すのは有害です。
なぜ、グリッドは有害なのでしょうか?以下にそのことを説明したいと思います。
このため日本語組版特有の詰め処理ということを見てみます。
日本語の組版では、句読点や括弧類を約物と呼び、文字と文字の間の空き量に特別の配慮をします。
(1)約物の詰め処理
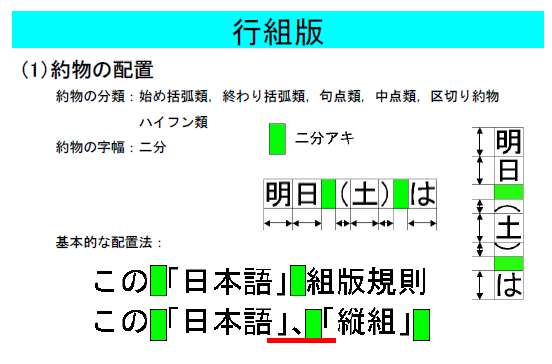
この図の一番下の例は、閉じ括弧と句点が連続したとき、半角(二分)詰めることを意味しています。つまり、行の中で句読点や括弧類が連続したとき、その連続する約物の組合せによって特別の処理をしなければならないことを示しています。この文字の種類の組合と字詰めの規定がJIS X4051の表5に掲載されています。
(2)約物の詰め処理 続き
この図は、行の先頭に始め括弧類が来たとき、その空き量をどうするか、幾つかの方法があることを示しています。
(3)和欧文間の空き
この他、空き量の調整としては、漢字やひらがなのような和文と、ラテンアルファベットのような欧文の間には1/4の空き(四分)を取ることも表5から分かります。
JIS X4051にはこのような日本語の文字を配置していくときの規則が事細かに規定されています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年02月24日
日本語組版はグリッドベースで行うと言って良いのか?(2)
日本語文書の組版方法については、さまざまな出版社毎のルールがあると思いますが、JIS X4051は、専門家が集まって長いこと議論を重ねて標準として定めたものですので、やはりそれに準拠するのが良いと思います。
このJISの「4.1行に配置する文字の基本的な配置位置」は、欧文系の仕様ではあまり標準的な考えではありません。
その前に簡単にここで使う用語を説明します。次の図をご覧ください。
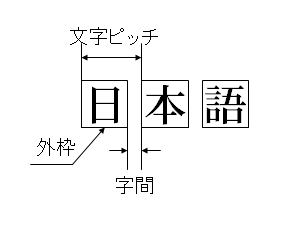
まず、日本語の漢字や一般のひらがななどは、一つ一つが正方形でデザインされています。文字の外枠の大きさ(高さ)が文字サイズとなります。そして、文字と文字の間隔を文字間と言います。JIS X4051では定義されていませんが、ここでは文字を1文字ずつ進める幅を文字ビッチと言います。
さて、「4.1行に配置する文字の基本的な配置位置」では、
a.行送り方向は、それぞれの文字の中心を揃えて文字を配置する。
b.字詰め方向は、行頭、行末および隣接する文字間に表5に規定する空き量を確保して文字を配置する。
とあります。表5を見ますと、普通の漢字やひらがなでは、空き量はゼロ(文字間なし)となります。つまり、日本語の横書きでは文字をその外枠をつけて左から順に並べていくことになります。
そして、昨日の図にありましたように、指定した文字数分並べたら、新しい行に進み、次の行の先頭から文字を並べます。
従って、ワープロでJIS X4051準拠の日本語組版をしようと考えたら、左余白を指定し、それから文字のサイズを指定し、それから文字数を指定する、というページ設定ができなければなりません。
例えばMicrosoft Wordなどでは、特別に注意しないでページ設定をしますと、左余白、右余白を設定し、その結果として本文の入る幅が決まります。一行の文字数は、文字のサイズを決めると結果的に決まることになります。但し、Microsoft Word 2003のページ設定ダイヤログには、(1)左余白を設定し、(2)文字数と行数を設定、(3)標準の字送りを使用することで、右余白が計算して設定される機能があります。これを使いますとJIS X4051に準拠する文字の配置ができると思います。このようにMicrosoft Wordは日本語組版を研究して、その方式で設定可能な機能を用意している点はさすがです。
ところが、現在のXSL-FOやCSSには、そのような指定方法は用意されていません。Microsoft Wordの標準と同じで、左右余白を設定する方式です。そこで、まず、このような設定を簡単にできる機能を用意してもらわなければならないということになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年02月23日
日本語組版はグリッドベースで行うと言って良いのか?(1)
この間の多言語組版研究会で、ちょっと気になったことをもう少し突っ込んでみます。
それは、「日本語組版はグリッドベースで行う」と言う表現についてです。
昨年のXSL-FOV2.0のワークショップで、ジャストシステムの大野氏が、日本語組版からXSL-FOへの要求事項ということでプレゼンテーションを行いました。このことは、既にブログでも触れています。
2006年12月12日 XSL-FO 2.0 Workshop続き先日のPage2007でも、2月9日の「D6XMLと高度な日本語組版の実現」というセッションで、報告がありましたので、お聞きになった方も多いと思います。
そのプレゼンテーションのスライドに次の図があります。

この図は、まさしく、日本語組版はグリッドベースで行うということを言っていると思います。XSL-FO 2.0 Workshopでも、Page2007 でもそのプレゼンテーションを聞きながら、この表現が内包している問題点に気が付かなかったのですが。先日の研究会で初めて気が付きました。
それに対して、多言語組版研究会で、小野澤氏は次の図と式を示されました。
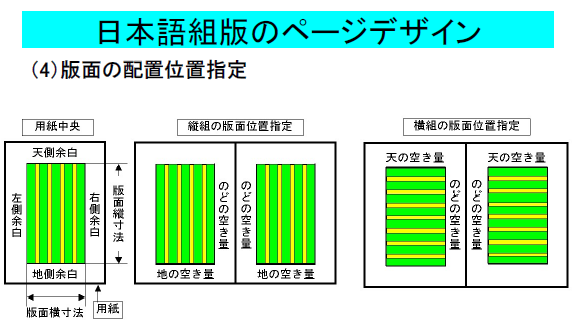
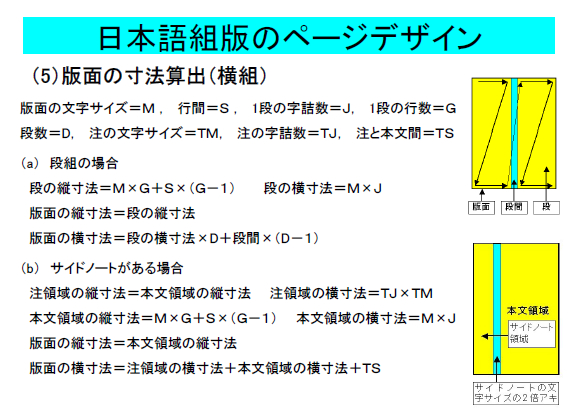
この図と二つの式の一部を説明しますと、
横組みにおいては、のどの空き量を指定し、版面の寸法(幅)は文字数×文字サイズで計算し、小口の空き量は成り行きとなる(結果的に決まる)と言っています。
上の用語は分かりにくいと思いますので、皆さんが普段使っているワープロの用語でワープロで言ってみましょう。
そうしますと、見開きページでは内側の余白を設定し、さらに文字の大きさと文字数を指定します。
その結果、文字の大きさと文字数から本文領域の幅がきまります。そして、外側の余白は、ユーザが明示的に指定するのではなく、紙の幅から、内側の余白と本文領域の幅の和を引いた値となります。
これが、小野澤氏の説明、すなわちJISX4051が定めている、日本語組版における文字を流し込む領域の指定方法です。
つまり、JISX4051が定める日本語組版では、横組みの時は、右ページなら、左余白を指定し、本文領域の左から文字を一つづつ置いていき、文字数分まで達したら、そこで行を折り返すというわけです。
このことは、もし、文字が全部同じ大きさで、括弧類や、句読点が無ければ、結果的に文字がグリッドに入れたようになる、ということになります。すなわち、グリッドはあくまで結果的にできるものであって、最初からグリッドを想定して、決して、各グリッドのセルに文字を入れていくものではない、ということです。
ところが、欧米人に対して、まずグリッドありきという表現をしてしまったために、おかしなことが起きてしまったように思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年02月08日
テキストファイル考(3) — XMLの場合
さて、具体的な例として、XMLを取り上げて見ます。
によると、XML文書の構成は、次のように規定されています。
「XML文書は実体という記憶単位から成り,実体は構文解析されるデータ又は構文解析されないデータから成る。構文解析されるデータは,文字から成り,その一部は文字データを構成し,一部はマーク付けを構成する。」
これを見ますと、XMLの構成単位の中心は、文字のみのデータ(テキスト系データ)であることが分かります。
そして、構文解析されないデータについては、次のように書かれています。
「解析対象外実体は,内容がテキストでもそうでなくともよいリソースとする。」ということで、XML文書にはバイナリ系データを含んで良いということになります。
そして、テキストとは次のように定義されています。
●テキストは、文字の並びであって,マーク付け又は文字データを表してもよい。
●文字 は,テキストの最小単位であって,[ISO/IEC 10646]に規定されている。使用できる文字は,タブ,改行,復帰及び(Unicode及びISO/IEC 10646に規定する)図形文字とする。
XMLの実体は、ファイルなどの形で保存されたり、交換されますが、そのとき、どういう方法で保存されるかが、文字符号化方式です。
「XML文書内の外部解析対象実体は,それぞれ別の文字符号化方式を用いてもよい。すべてのXMLプロセサは,UTF-8で符号化した実体,及びUTF-16で符号化した実体を処理できなければならない。」
例えば、Unicodeでは、文字に固有の番号を割り当てています。この番号は、Unicodeのコードポイントであって、ファイルなどに書くときは、符号化方式という計算式をつかって、別の番号のシーケンスにして交換します。Unicodeには、多数の符号化方式が提唱されていますが、一番ポピュラーなのが、UTF-8またはUTF-16となります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年02月07日
テキストファイル考(2) — データ交換形式としてのテキスト
昨日のお話は、取り扱うデータの種類という観点でのものです。
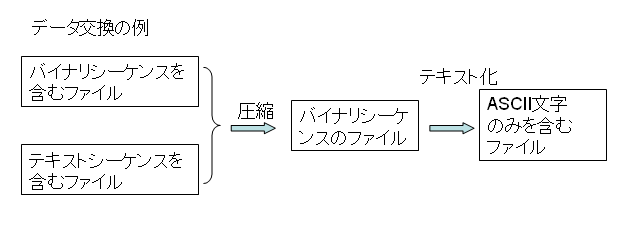
これらデータは、コンピュータ内部では、すべてバイナリ(0-1の組合せ)で取り扱われます。さて、それを、コンピュータの外部に出して交換するときはどうするかということですが、そのときもまた、テキスト系とバイナリ系という分類ができます。一応、これらに、テキストシーケンスとバイナリシーケンスという言葉を当てはめて見ましょう。
次の図のようになります。
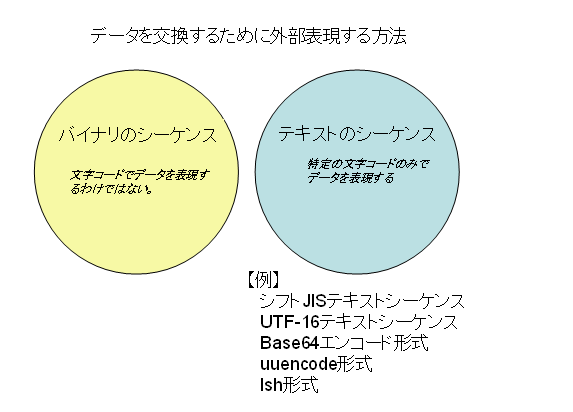
【お詫び】この図誤っていましたので、2月11日に差し替えました。
注意していただきたいのですが、扱うデータがバイナリ系かテキスト系かということと、外部交換形式としてのテキストシーケンスとバイナリシーケンスかということは、1対1対応ではありません。次の図をご覧ください。
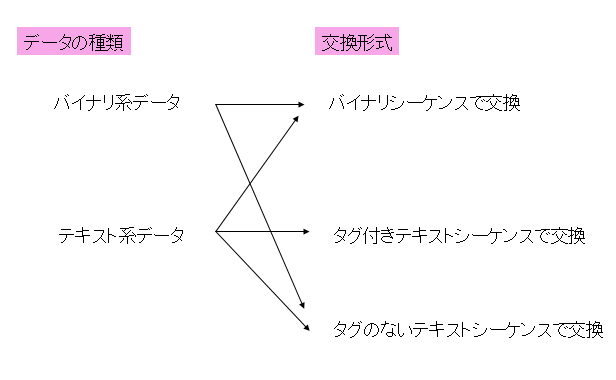
インターネット以前のパソコン通信では、バイナリファイルやテキストファイルを圧縮して、圧縮したファイルをIshでASCII文字のみのテキストに変換してデータを送受信していたものです。これは、通信路やソフトウェアの中に、ASCII文字のみのテキストしかうまく通さないようになっている箇所があったためです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年02月06日
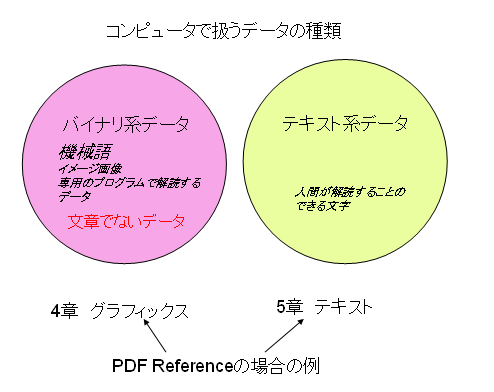
テキストファイル考(1) — テキスト系データとは
Wikipediaを読んでいたら、テキストファイル、プレーンテキスト、バイナリファイル、マルチスタイルテキスト(この言葉は、私は始めて見ました。)というような用語の説明が出てきて、私の考えとは少し違うなと思うところがありますので、自分なりの考えをちょっと整理して見ました。
まず、最初に私の考えを簡単にまとめてみます。
1.コンピュータで扱うデータ
コンピュータで扱うデータを大きく分けると、人間の目でみて理解できる文字列で表すデータとプログラムでしか理解できないデータがあります。これを、一応、テキスト系データとバイナリ系データと分けて見ます。
テキスト系データをさらに分けますと、次のようなものがあるだろうと思います。例えば、数式、ベクトルグラフィックス、さらにはPostscriptやPDFを持ち出し始めますと、実際のところ、テキスト系データとバイナリ系データの区分はかなり曖昧なように思います。
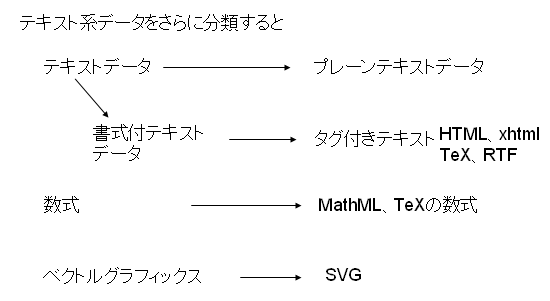
時代の流れとしてテキスト系データ、とりわけ書式付テキストデータの表現方法が非常に豊かになってきたことが挙げられます。20世紀はTeX、RTF、CGMのような制御単語とコンテンツ・テキストが混在していた方式が中心でしたが、21世紀はXMLのような制御単語をメタ言語で表現して、コンテンツ・テキストをマークアップする方式に移行しています。
オフィス文書の表現方法としてOffice Open XMLが出てきたこともその一つです。RTFは21世紀にはWordprocessingMLにとって代わられることになるのでしょう。
また、あえて言えば、数式表現としてのTeXは、だんだんMathMLに、そして文章表現としてのTeXはXSL-FOにとって代わられることになるものと思います。
PDFもどちらかというと20世紀の技術に属すると思います。大胆に予測しますと、いづれは、PDFのXML表現(Mars)、またはXPSの時代が来るのではないかと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年02月03日
第22回多言語組版研究会 — 「縦組の組版方法と組版指定交換形式」について
2月19日に、久しぶりの多言語組版研究会を開催致します。
テーマは、「縦組の組版方法と組版指定交換形式」についてということで、社団法人日本印刷技術協会(JAGAT)の縦組スタイルシート作業部会の「縦組の組版方法と組版指定交換形式」(作業原案)について、原案作成者の小野澤氏に下記の点を中心に原案概要の説明をしていただきます。
・縦組スタイルシート作業部会について
・版面・用紙
・行組版
・改頁・改段・見出し・注の処理
・図・写真等の処理
・表組・漢文の処理
・版面又は段への行の配置と領域調整処理
「縦組の組版方法と組版指定交換形式」は、現在の時点では、まだ原案ということで、これから作業部会での議論などの過程で変更になるものと思われます。
JAGATの縦組スタイルシート作業部会の成果は、将来、W3CのCSSやXSL-FOの作業委員会の方にも提案されるものと思います。
一方、W3CのCSS3の作業委員会では、新しいCSSの仕様の策定が進んでいます。
これから、両方の作業が平行して進むものと思いますが、XSL-FOの方は、現在、XSL-FO 2.0の作業開始へ向けて準備中のようです。
JAGATの作業と、W3Cの二つの仕様の作業が平行して進んでいますので、その間でうまくベクトル・タイミングが合えば良いのですが、会わないとばらばらになってしまうのでそのあたりが気になっています。
まあ、私が気にしてもあまり意味がないのですが。とりあえずは、研究会を開いて皆で勉強しましょう、ということを考えています。関心をお持ちの方はぜひご参加ください。
ご案内の詳細とお申し込みはこちらからどうぞ。
http://www.antenna.co.jp/ml/kaisai.htm
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月10日
XPSをチェックする (2) XPSの構造
さて、折角ダウンロードしてインストールしたのだし、今日、もう一度XPSを調べてみようと思います。ところが今日は、XPSビューアが最初のファイルからいきなりブルースクリーンです。
ブルースクリーンのメッセージには、これが2回目なら、ハードウエアかソフトウエアをアンインストールせよ、とあります。仕方ありません。昨日、うまく表示できたファイルの内部を少し見てみましょう。
昨日のファイルは次の図のような4ページものです。
このファイルは、ZIP圧縮形式ですが、内容はそのままXML形式です。ZIP圧縮ファイルの中には、FixedDocumentSecuence.fdseq、[Content_Types].xmlという二つのファイルのほか、フォルダが三つあります。
これは、Microsoft Office2007のOffice Open XML形式の文書保存形式と良く似ていますね。ファイルのパッケージングの方法は共通なんでしょう。
さて、さらにフォルダの中を見ますと、次のような構造になっています。
すぐに気がつきますのは、4ページのそれぞれが別のファイル(1.page~4.pageの4つのファイル)になっているようだ、ということです。
この1.page~4.pageはそれぞれXMLファイルになっていて、各ページのテキスト・コンテンツが入っています。
ちなみに1ページ目(1.page)を取り出して内容をブラウザで表示してみます。
1ページ目の先頭の行は、昨日の画像でありますように「Cocoa & Chocolate」という見出しなのですが、これは、ファイルの中では、1ページ目の最後の方にあります。
2行目は、「The term “Cocoa,” a corruption of “Cacao,” is」という文字列ですが、上の画像では、この部分が、
Glyphs OriginX="26.6666666666667" OriginY="98.2033333333333" FontRenderingEmSize="16" FontUri="/Resources/a7b9593b-a0f7-4049-a7e6-b8107ad481f9.ODTTF" UnicodeString="The term “Cocoa,” a corruption of “Cacao,” is" Indices=";;;,38;;;;;,38;;;;;;;;;,38;;,38;;;;;;;;;;;,38;;;,38;;;;;;;;;,38" Fill="#FF000000"
となっているのが見えます。
ですので、文字列は(この例では)1行単位に区切られていて、文字列の表示開始座標とともに保存されています。また、ファイルの中では、文字列が表示の順序で現れるとは限らない、ということが分かります。この特徴は、PDFファイルと同じです。
それから、この文書には画像が二つあります。この画像は、Resourcesというフォルダの中に入っていることがわかります。それから、上の図でResourcesフォルダの中にはフォントらしきものも入っていることが分かります。
このあたり、PDFと相当に似通っている、といえると思います。XPSはPDFをざっくりXMLで表現したものといっても大筋では間違っていないでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年11月09日
XPSをチェックする
Microsoft のAndy Simonsのブログを見てましたら、XPS (XML Paper Specification)がいよいよV1.0になった!と喜びの声が上がっています。
XPS V1.0の仕様書の配布も始まりました。
XML Paper Specification Updated: October 24, 2006 Version 1.0
というわけで、まずは、XPSを体験してみようと思いたち、XPSのビューアとXPSのサンプル文書を落としてみました。
Windows XPで、XPSのビューアを動かすためのプログラムは、ここにあります。
XPSを表示してみるためには、
Microsoft XML Paper Specification Essentials Pack Version 1.0
と、MicrosoftのコアXMLサービスをインストールする必要があります。コアXMLサービスというと高尚に聞こえますが、XMLを読むためのおまじないツールと思えば良いと思います。
Microsoft Core XML Services (MSXML) 6.0
ただ、XPSを表示するだけならばMSXMLパーサをインストールすれば良いようです。インストールファイルはmsxml6.msiです。MSXMLかあ、久しぶりだなあと思いながら。
無事インストールが済みました。
次に、サンプル XPS Documentからサンプル・ファイルを落としてと。。
うん。。表示できますね。次の図は、XPSビューアでサンプルを表示したところです。

と思ったのもつかの間!5つくらいファイルを表示したところ、いきなり、Windowsがいなくなって、ブルースクリーンになってしまいました。Windowsが根こそぎ死んでしまったようです。しょうがないので、電源をむりやり落として再起動。まあ、ソフトがハードを壊すことはないでしょうがねえ。
というわけで、今日は、ここまでにします。これからXPSを試すときは、大事なファイルは全部保存してバックアップとっておかないと危ないですね。ご注意。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月12日
Office Open XML File Format(OOX)最終ドラフト公開
Microsoft Office2007のXML形式である、Office Open XML File Formatの最終ドラフトが公開されました。
Ecma Office Open XML File Formats Standard
仕様は5部から構成されています。
第一部:基礎 173ページ
第二部:パッケージ化の約束事 129ページ
第三部:最初に 472ページ
第四部:マークアップ言語のリファレンス 5129ページ
第五部:マークアップの互換性と拡張性 43ページ
下記のEcmaのPRページによれば、
Ecma Office Open XML File Formats Standard - Status Report - 28 September 2006 - Trondheim, Norway
この最終ドラフトは、Ecmaの作業委員会TC45のメンバの間で9月下旬に開催された会議で全員一致の賛成で決定されました。
そして、12月に開かれるEcmaの全体の会議で正式な仕様として採用するかどうかの投票が行われるようです。
それにしても、この仕様書PDF形式で5900ページ超えて、自動車の整備マニュアル並みの厚さです。読むだけで大変。実装することを考えたら冷や汗がでます。
XSL-FOの仕様書なんて500ページ程度。それでもXSL Formatterの開発には7年もかかったのに。
当社としては、サーバベース・コンバータ(SBC)でOOXを組版しなけりゃならないんです。6000ページの仕様書なんて。SBCは完成するまで一体何年かかることやら。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月09日
XSL-FOの勧告提案までの経過
ここで、XSL-FOがV1.0からV1.1までの経過について、振り返ってまとめてみたいと思います。
・2001年10月 XSL-FO V1.0の勧告
・2002年4月頃からXSL-FO V1.0のErrataの作成作業開始。
ユーザ等からのコメントへの対処作業
テストケースの改訂
・2002年10月25日 XSL-FO V1.0についてErrataの発行
Extensible Stylesheet Language (XSL) Version 1.0 Errata
(その後、随時更新)
・2002年秋までに作業グループ内で時期バージョンでは2.0を狙わずに、各社の拡張の標準化を図ることで合意したようだ。
・2002年12月新しい作業委員募集 新しいメンバ数人が参加。
・2003年前半まで XSL-FO拡張についての提案の収集
・2003年秋に電話投票でXSL-FO V1.1での標準化アイテムを決定
この意思決定過程で、私の記憶ではXSL Formatterでかなり沢山のクレームがあった脚注の配置の問題が拡張候補にリストアップされなかった。このため脚注の配置については、V1.1でもベンダ独自仕様のままになっているのは残念。
ちなみに、XSL Formatterは、脚注について次のような拡張をしています。
○axf:footnote-align 脚注の配置を指定します。
○axf:footnote-position 脚注を段ごとに配置するかどうかを指定します。
○axf:footnote-stacking 脚注の配置の方法を指定します。
XSLFormatter V4.0 のXSL独自拡張仕様
アンテナハウスから提案したはずなんだけど、アピールできなかったのは失敗。
・2003年12月最初の作業草稿(Working Draft)を公開
Extensible Stylesheet Language (XSL) Version 1.1 Requirements
W3C Working Draft 17 December 2003 (要求)
Extensible Stylesheet Language (XSL) Version 1.1
W3C Working Draft 17 December 2003 (作業草稿)
・2004年春。作業草稿を出してから様々な意見が出た。次の段階に進むため、再度、仕様に盛り込む項目について作業グループで投票が行われる。
※欧米人は投票が好きなんだ。主張を通すには、投票で点を稼がないとだめってことだね。
・2004年11月 XSL 勧告へのコメントの処理について公開資料更新
Disposition of Comments on XSL Recommendation
・2004年12月第二回目の作業草稿(Working Draft)を公開
Extensible Stylesheet Language (XSL) Version 1.1
W3C Working Draft 16 December 2004 (作業草稿)
・2005年7月ラスト・コール(最終草稿)を公開
Extensible Stylesheet Language (XSL) Version 1.1
W3C Working Draft 28 July 2005
その後は、2006年2月に勧告候補、2006年10月に勧告提案となっています。いや、しかし、振り返ってみますと長い道のりでした。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月08日
XSL-FO V1.1 がProposed Recommendationに
Extensible Stylesheet Language (XS-FO) V1.1が、10月6日にProposed Recommendationとして公開されました。
Extensible Stylesheet Language (XSL) Version 1.1
W3C Proposed Recommendation 06 October 2006
これからW3Cの会員代表者による投票が行われ、投票の結果によりますが、問題なければXSL-FO V1.1 勧告仕様として認められることになります。投票の期限は11月3日です。
V1.1は、2月に勧告候補になった後、半年以上かけて実装報告を集め、その報告に基づいて議論と微調整が行われてきました。9月にはほぼ全ての問題について検討修了してProposed Recommendationになりました。
関係されたワーキング・グループの皆様の真摯な努力に対して、心からお礼を申し上げたいと思います。
V1.1では、V1.0のマイナーなバージョン・アップであり、延べ22項目が追加されています。この仕様が勧告になるための条件は、各項目に対して、2つのベンダのサポートがあることです。
ベンダからの実装報告は、まだ公開されていませんが、アンテナハウスを含め4社からの実装報告が集まっています。(実装報告のサマリは、ベンダ各社の反対がなければ公開される予定になっています)。
4社中で22項目全てを実装済みと報告しているのはアンテナハウスのみ。2番手は13項目フル実装+6項目部分実装+3項目未実装となっています。4社合わせますと20項目が2社以上の実装、2項目がアンテナハウスのみの実装となっています。
問題があるとしますと、アンテナハウスのみ実装の2項目が基準に達していないということですが、この2項目はオプションで、特にそのうちひとつは、日本語と中国語用の縦書きのために追加したものである、とされています。
XSL-FOの概要と、今回のV1.1で追加された機能につきましては、次のページに紹介していますので、ご参照ください。
1ヶ月あまりで結論がでることになります。差し戻しということはないと思いますので、年内には勧告になるものと期待しています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月29日
XSL-FOとCSSの未来 (2) CSS仕様の迷走
Webブラウザは、見方によっては、自動組版エンジンの一種と考えることもできるでしょう。HTML/XHTMLで記述されたコンテンツをパソコンの画面上に組版するエンジンです。
そのとき、CSS(Cascading Style Sheets)を使うことによって、HTMLやXMLのレイアウト指定をコンテンツから分離することができるという点で、CSSを使うことは大きなメリットがあります。CSSについて詳しい人にはいまさら、というほどの基本的なことですが。
そういう重要な仕様でありながら、2006年09月26日 XSL-FOとCSSの未来でも少しお話しましたが、CSSの仕様は混迷した状態にあります。そこで、CSSの仕様が、これまでどんな経緯を辿ってきたか、現在、どんな状態になっているか、これからどうしたら良いかを少し考えてみたいと思います。
1.CSSの歴史
2006年06月12日XSL-FOによるXMLのPDF化 (6) XMLのスタイル指定でも説明しましたが、CSSの最初の仕様(レベル1)は、1996年には策定されています。
その後、CSSレベル2が1998年2月に勧告仕様となっています。
ここまでは順調な歩みに見えます。
2.CSS2.1 仕様の策定の問題
その後、1999年にはレベル3の策定作業が始まっています。ところが、一方で、CSSレベル2.1(レベル2リビジョン1)の仕様がWorking Draftとして公開されています。
Cascading Style Sheets, level 2 revision 1
CSS 2.1 Specification
W3C Working Draft 11 April 2006
問題は、2.1の仕様案の2.0からの変更点の内容です。この変更点は、次の4つに分かれます。
Appendix C. Changes
C.1 Additional property values プロパティ値の追加
C.2 Changes 変更
C.3 Errors 誤り
C.4 Clarifications 明確化
この中で問題なのはC2の変更です。これを見ますと、特に、CSS2で定義されていたものが削除されたり変更になったものが多数あります。具体的なことは別途、例をあげて説明したいと思いますが、これは、仕様を実装する立場からは非常に困ったことになります。
なぜならば、(1)CSS2は、既に変更になるということが意図されているということになりますので、CSS2の完全な実装を意図することが無駄となってしまいます。
(2)ところが、CSS2.1は、いまだ、WorkingDraft(草稿)段階です。それどころか、一度、勧告候補まで進んだにもかかわらず、差し戻しで前に戻ってしまった状態になっています。いつ仕様として策定されるのかわからないという状況です。
そうしますと、CSS2.1の完全実装も目標として掲げ難くなります。なぜかと言いますと、果たして、標準仕様になるのかどうか分からないからです。このようにCSS2が既にCSS2.1によって否定されているにもかかわらず、CSS2.1が宙ぶらりんになっている、というのは、かなりまずい状況といえるとでしょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年09月26日
XSL-FOとCSSの未来
XMLを印刷するための標準仕様としてXSL-FOとCSSがあるということは、既に、ブログで何回か取り上げました。
ブログの記事をまとめたもの
XSL-FOとCSSは兄弟のような関係ではありますが、標準化という点でもかなり異なる状況にありますし、また、互換性という点では、どうもだんだん離れていきそうな雰囲気になっています。
しかし、利用者側の視点ではそれでは困ります。なぜかと言いますと、まず、CSSとXSL-FOでは似たようなレイアウトモデルを採っていますし、レイアウトを指定するためのプロパティもかなり似通っています。
使用しているユーザの数、出回っている書籍の数、Webの情報という点から見ますとCSSの方が、XSL-FOよりはるかに多いのではないかと思います。つまり、XSL-FOに比べて、CSSの方が圧倒的に普及しているということは間違いないだろうと思います。
そうしますと、CSSを使った経験のある人、CSSについての知識を持つ人が、XSL-FOを使ってみようということになることが多いはずです。そういう人にとっては、CSSのプロパティが、そのまま、XSL-FOで使えると有難いでしょう。それができればXSL-FOの普及はもっと進むと思います。
ところが一方で、CSSとXSL-FOは標準化がかなり独立に行われ、さらに悪いことには、標準化に携わっている人の中に、無用なライバル意識があってお互いに譲歩して接近しようという気持ちがないように感じます。
標準化をすすめるワーキング・グループの運営でも、XSL-FOは強力なリーダ・シップで統制をとって、一応、順調に進んでいるのに対して、CSSのワーキング・グループは、どうも統制がなく、仕様策定もいきつ戻りつで、順調に進んでいません。
この状況をなんとか打開しなければならないでしょう。これは、私だけではなく、CSS仕様に関心を持つ人の多くが感じているだと思いますが、どうしたら良いでしょうかねえ。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年06月27日
BDFとは何の略? (メモ)
ビットマップフォントの形式にBDFと呼ばれるものがあります。
私は、以前からBDFとは、アドビの次の仕様書のタイトルにあるGlyph Bitmap Distribution Format の略だと思っていました。
Glyph Distribution Format Specification
ところが、BDFをググッて見ていましたら、BDF (Bitmap Description / Display Format) としている情報源もありました。
こちら
↓
フォント関連の基礎知識 ⇒BDF と PCFの項
ところが、ここにサンプルで出ている「東雲ゴシック 16 ドット」の先頭部分の例は、上記のGlyph Bitmat Distribution Format Specificationの仕様に準拠しています。
つまり、BDF (Bitmap Description / Display Format) とGlyph Bitmat Distribution Formatとは同じものということです。
BDF Bitmat Distribution Formatでググルと61000件がヒット、
BDF Bitmap Description Formatだと、67900件がヒットする。
尤も、Bitmap Description Formatの方でヒットするのは、Bitmat Distribution FormatのBitmapとFormatと、他の文中の Description が多い。
やはり、私としては、BDFはBitmat Distribution Formatの略ではないかと思いますが、どうなんでしょうね。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年05月30日
さまざまなフォントについての概要
「PDF 千夜一夜」で、グリフ、フォントについての説明を「さまざまなフォントについての概要」としてまとめてみました。
こちらからご覧いただくことができます。
さまざまなフォントについての概要
こうしてみますと、ほとんど、アウトライン・フォントのアウトラインの説明に終わってしまっています。
いづれ、もう少し詳しく検討してみたいと思いますが、現在の時点では、私の知識ではこの程度が限界です。もっと詳しく説明するには、さらなるインプットが必要です。
ところで、今回、連休を機にブログで書いた記事を整理してみましたが、記事のリライトというのは、結構、時間がかかるものです。
ワンソース・マルチユースというのは、言うのは簡単、実践はなかなか難しいという経験を積ませてもらいました。
自分では、まとめる際の手間がかからないように、毎日のブログのお話をうまくつなげてきたつもりなのですが。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年05月16日
PDFとフォント(29) エレメント方式フォント
アウトラインフォントのお話は、ほとんど、アドビシステムズが開発したフォントと、Microsoftが開発したフォントで終始してしまいました。
しかし、他にフォントがないのか?と言われるとそのようなことはないでしょう。
他の方式のフォントがないのか、とWebを探していましたら、リコーのエレメント方式フォント((JetFont)というものが見つかりました。
これは、文字を書き表すストロークを、約700種類に分類しておき、そのストロークを組み合わせて文字を表す仕組みです。
詳しくはエレメント方式フォントのWebページをご覧ください。
漢字のように何万種類もの文字があるときは、小さな部品から組み立てていく方式は、有効なように思います。JetFontは漢字だけではなく、ラテン系の文字やハングルなども文字として用意しているようです。
このフォントは、フォントデータとラスタライザ(ソースプログラム)で提供されるようですので、Linuxなどにも載せて使えそうです。
PDFに使うのはどうなんでしょう?PDFの仕様を拡張しなくてもPDFに埋め込んで使えるのかな?フォントのラスタライザが問題ですが、こういう技術をPDFと一緒に使えるようにしていくと、マルチプラット・フォームのPDF配信ができるようになるかもしれません。
大いに期待したいものです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年05月11日
PDFとフォント (28) フォント技術の将来
こうしてみますと、アウトラインフォントの技術については、アドビシステムズとMicrosoftがほとんどを握ってしまっているように思います。
アウトラインフォントを使う場合、困るのはフォントデータとラスタライザがセットでないと役に立たないということがあります。フォントデータの方は、フォントベンダがまだ沢山ありますし、ツールを使えば新しいフォントを作り出すことはできます。
問題はアウトラインフォントのラスタライザです。例えば、OpenTypeを例に取りますと、TrueTypeアウトラインと、CFF/Type2アウトラインの2種類があります。OpenTypeを可視化するには、その2種類のフォントのラスタライザが必要です。
OpenType の仕様書には、
---引用開始---
PostScript data included in OpenType fonts may be directly rasterized or converted to the TrueType outline format for rendering, depending on which rasterizers have been installed in the host operating system.
---引用終了---
OpenType Overview
と書いてあります。つまり、PostScriptアウトラインは、TrueTypeアウトラインに変換してラスタライズできると。これが事実ならTrueTypeのラスタライザのみで良いのですが。しかし、これは、多分近似的にできるということで、完全にはできないでしょう。3次元のベジエ曲線を2次元で表現するのは不可能なはずですから。
Windowsで文字を表示するのであれば、ラスタライザはMicrosoftとアドビが提供しているので問題ないのですが、Windows以外のOS、例えば、Linux、あるいは、もっと離れて、携帯電話などで表示しようとするとラスタライザがないということが大きな問題になると思います。
PDFにフォントを埋め込むと、表示環境にフォントがなくてもPDFを見ることができる、と言われます。しかし、PDFに埋め込まれているのはラスタライズした(可視化した)文字ではなく、フォントのアウトラインデータです。
従って、表示環境にラスタライザがなければ、PDFにフォントが埋め込まれているとしても、その文字を表示することはできません。
OpenTypeが普及した場合、上のことは相当に大きな問題で、Microsoftまたはアドビの協力がなければ、PDFを表示することができないということになりかねません。このあたり、将来、どうなるのか?不安を感じるところです。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年05月09日
PDFとフォント (27) OpenTypeによるグリフのレイアウト
OpneTypeでは、OpenTypeレイアウトというコンセプトを持っています。
OpenTypeレイアウトは、フォントファイル中には特性テーブル(feature table)として用意されます。
これは、グリフを行にそって配置していく際に次のようなことを行うためのものです。
・複数のグリフのリガチャ、文字の位置によるグリフの変化など。
・文字の配置方法に依存するグリフの入れ替え
・2次元平面上でのグリフの配置、グリフの付加
例えば、日本語ですと縦書と横書での句読点、括弧類の形の入れ替えたり、アラビア文字では、単語の中での文字の位置により、グリフの形が変わります。アラビア文字については、
2006年01月19日 PDFと文字 (27) – アラビア文字の扱い
~
2006年01月22日 PDFと文字 (30) – アラビア文字Harakatの結合処理
あたりをご参照ください。
OpenTypeレイアウトには次のような幾つかの共通テーブルがあります。
・BASE ベースラインについてのデータ
・GDEF グリフの定義データ
・GPOS グリフの配置データ
・GSUB グリフの入れ替えデータ
・JSTF グルフの均等配置のためのデータ
文字・言語によってそれぞれのテーブルの中に用意されているデータを使って、グリフに対する操作・配置を行うことができます。
フォントファイルから取り出したグリフの操作や配置は、WindowsではUniscribeというグリフ・レイアウト・エンジンを使って行うことができます。もちろん、アプリケーションが自前のグリフ・レイアウト・エンジンを使用することも可能です。
ちなみに、アンテナハウスのXSL Formatterでは、アラビア文字、ヘブライ文字、タイ文字などについては、自前のグリフレイアウト・エンジンを使ってグリフの配置を行っています。
現在は、クメール文字やデバナガリ文字はWindowsのUniscribeに頼っています。しかし、Windowsに頼っていると、Unix、あるいはLinuxで同じ機能を実現できませんので、将来は、これらの文字も自前で処理したいものです。
このようにOpenTypeのレイアウト・テーブルを使うことで、組版ソフトなどのアプリケーションが高度なタイポグラフィを実現することができます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年05月07日
PDFとフォント (26) フォントファイルとしてのOpenType
次にOpenTypeのフォントファイルとしての主な特徴について整理しておきます。
1.グリフのアウトライン記述形式
OpenTypeのグリフアウトラインは、TrueTypeアウトラインと、PostScriptアウトラインのどちらかを使用できます。PostScriptアウトラインは、CFF/Type2形式です。
なお、アウトライン形式に加えて、ビットマップのグリフを含めることもできます。
OpenTypeフォント・ファイルの拡張子は次のようにつけます。
・TrueTypeアウトラインの場合:.OTF、または、.TTF(過去のシステムでも使用可能にしたいとき)
・TrueTypeコレクションの場合:常に.TTC
・PostScriptアウトラインのみを含む場合:.OTF
2.cmapテーブル
フォントを使用するアプリケーション・OSで使う文字コードからグリフ番号(GID)への対応表をcmapと言います。TrueTypeと同じものと思います(推測)。
cmapは、一つのフォントファイルに複数のテーブル(cmapサブテーブル)を持つことができます。
サブテーブルは、プラットフォームID(Windows:3、Macintosh:1)と、プラットフォーム毎の符号化方式(2バイトのUnicode:1、4バイトのUnicode:10など)の順で並べます。フォントファイルに様々なOS別のサブテーブルを用意することで、一つのOpenTypeフォントをマルチ・プラットフォームで使えることになります。
cmapサブテーブルは7種類(Format:0, 2, 4, 8, 10, 12)あり、各サブテーブルの先頭に該当する種類がセットされます。
Unicodeサポートについて
UnicodeからGIDへのcmapサブテーブルは、次の3種類が使えます。
・Format4:[U+D800 - U+DFFF] (サロゲートペア)以外のUnicode領域をサポートする文字コードからGIDへの対応表(Microsoftの標準)
・Format8:16ビットと32ビット混在。サロゲートペアの文字コードは32ビット。それ以外が16ビット。
・Format12:32ビット固定長(UCS-4)の表。(サロゲートペアをサポートする時のMicrosoftの標準)
なお、サロゲートペアをサポートできるのはWindows2000以降ですが、サロゲートペアをサポートするOpenTypeフォントは、過去のOSでも使えるようにするためFormat4のcmapサブテーブルも用意しておかなければなりません。
【注意】
このように、cmapはUnicodeの全領域をサポートできそうに見えますが、OpenTypeのひとつのファイルに収容できるglyphの数は64k(65,536個)とされています。従って、UnicodeV4で定義されている全文字をひとつでサポートするOpenTypeフォントを作ることはできません。Arial Unicode MSの最新Unicode全文字版はできないということになりますね。
※参考資料
OpenType specification
特に
cmap - Character To Glyph Index Mapping Table
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年05月06日
PDFとフォント (25) OpenType
さて次は、いよいよ真打OpenTypeの登場です。OpenTypeという名前は、既に何回か出てきました。
ここでは、フォントファイル形式としてのOpenTypeとそれがPDFでどのように扱われるかについて検討してみましょう。
いままで延々といろいろなフォントの形式を説明してきましたが、これはすべて、本命であるOpenTypeの説明をするための準備をしてきたようなものです。
【歴史】
OpenTypeは、最初Microsoftによって、TrueType Open として開発されました。その後、1996年にアドビが開発に参加、1997年4月に共同で発表されました。
Adobe Systems and Microsoft Deliver OpenType TM Font Specification
1990年代前半まで、アドビのPostScript Type1フォントと、マイクロソフト/アップルのTrueTypeという2大アウトライン・フォントがしのぎを削るという状況でした。この両陣営が協力してOpenTypeというフォントファイル形式を開発したのは、アウトライン・フォントの歴史上では、非常に大きなできごとと思います。
OpenTypeは、TrueTypeとType1フォント技術の後継として位置付けられています。
また、OpenTypeは、現在、ISOで標準化が進んでおり、新しい標準は、OpenType 1.4で、ISOで名前を変更して"Open Font Format"になるようです。2006年終わりに最初の版が出ると期待されています。
【普及の見通し】
アウトライン・フォントの普及には、フォント制作者が提供するフォントファイルと、それを使うアプリケーション、フォントファイルからアウトラインを取り出してグリフを可視化するラスタライザの3つが大きな要因となります。
OpenTypeはもともとTrueTypeの延長として開発されていますので、TrueTypeフォントの多くについては、大きな変更なく使用できるだろうと思います。これに対してアドビはType1フォントを全てOpenType形式に変換し、OpenTypeフォントに集中しています。
Wikipediaの記事では、2005年の末で、10,000種類のOpneTypeが入手できるそうですが、このうち1/3がアドビのものと推定しています。やはり早く手がけたものが有利ということでしょうか。
いずれにしても、フォントファイルの供給という面からは、今後、OpenTypeが圧倒的に増えるだろうと予想できます。
【参考資料】
Wikipedia OpenType
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年05月05日
PDFとフォント (24) CID-Keyedフォント(PDF)
PDF ReferenceにもCID-Keyedフォントの説明があります。
5.6.1 CID-Keyed Font Overview
PDF Reference V1.6 pp.403 -405
ここを読みますと、昨日、説明しましたPostScriptを想定するCID-KeyedフォントとPDFのそれでは微妙に違いがあることがわかります。
まず、PDF Referenceではフォントをsimpleフォントとcompositeフォントの二つに大別しています。simpleフォントとは1バイトフォント、compositeフォントとは複数バイトのフォントです。
2006年05月03日 PDFとフォント(22) Type0 フォントでも説明しましたが、PDF Referenceでは、compositeフォントのことをType0フォントと言い、具体的にはCID-Keyedフォントのみ使うことができます(OCFはサポートされていない)。
PDFのCID-Keyedフォントは次のものから構成されます。
・CID
・CMap
・CIDFont
(1) CIDは、昨日説明しましたPostScriptと同じものです。
(2) CMapも同じような役割なのですが、PDFでは少し機能を限定しています。
(3) 一番の違いはCIDFontです。PostScriptの時とは違い、PDFではCIDFontにはType0とType2の2種類があります。
・CIDFont Type0は、アドビのType1フォントの形式でグリフを記述したもの
・CIDFont Type2は、TrueTypeフォントの形式でグリフを記述したもの
PDFでは、1バイトのTrueTypeフォントをsimpleフォントの1種類として扱い、CJKなどの複数バイトのTrueTypeフォントは、compositeフォントとして、Type0フォントの仕組みを使って扱っているということになります。
この影響でPDFではCMapによるグリフ選択の仕組みも、PostScriptのCID-Keyedフォントとは少し異なっていて、TrueTypeの取り扱いが追加されます。このあたりは細かい技術的な話ですので省略します。
このことは、1バイトのTrueTypeフォントと2バイトのTrueTypeフォントが、AcrobatのPDFのフォント・プロパティ情報で、表示が違うことからも確かめることができます。

※Acorbat Standard 6 (英語版)による
上の画面の例ではTimesNewRoman(1バイト)のタイプはTrueTypeですが、MS明朝(2バイト)のタイプはTrueType(CID)となっています。
私としては、いままではTrueTypeにCIDなんてないのに「おや?おかしいな。」と思っていたのですが、漸く、わかりました。
※このあたりはアドビの手抜きじゃないかなと思うのですが。ま、こんな細かいことに文句言うのは日本人だけかもしれませんね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年05月04日
PDFとフォント(23) CID-Keyedフォント (PostScript)
CID-Keyed フォントは、PostScript Type1形式の複合フォントとしてOCFの後継として規定されました。
CJK /CID-keyed fonts CID フォントに関する一連の仕様
CIDフォントの構成要素は、次のものです。
・CID文字集合
・CMapファイル
・CIDフォントファイル
(1) CID文字集合
日本語、中国語(繁体字、簡体字)、韓国語についてグリフを集めてCID番号をつけたものです。これについては、既に2006年01月15日 PDFと文字 (23) – Adobe-Japan1、2006年01月16日 PDFと文字 (24) – Adobe-GB1, Adobe-CNS1, Adobe-Korea1で簡単に紹介しました。
(2) CMap
さまざまな符号化文字集合の文字コード番号から、CIDへの対応表です。アドビが用意した標準のCMapは無償配布されています。フォントベンダなどが独自に定義することもできます。
これについても、既に、
2006年01月17日 PDFと文字 (25) – CMapで文字コードからCIDへ変換で説明しました。
(3) CID フォントファイル
これは、フォントのグリフを記述するプログラム(データ)を収録したファイルです。フォントベンダが開発するものです。Type1のグリフアウトライン形式と互換の形式になっていて、Adobe Type ManagerやPostScriptインタープリタで解釈してラスタライズすることができます。
CID-Keyedフォントを表示・印刷する仕組みの一部は2006年01月17日に示しましたが、CMapを使って、文字コードからCIDに変換し、CIDをキーにして、文字のグリフを取り出し、そのグリフをラスタライズするものです。
CID-Keyed Font Technology Overview Technical Note #5092にはCIDフォントの特長として次のようなことを挙げています。
・CMapファイルを使って、複数のCID-Keyedフォント、OCFフォント、Type1、Type3フォントを参照して使える。
・文字を追加して、拡張していくのが簡単。
・Type1よりフォントを取り出してラスタライズするのが速い。
・広範な機器に使える。
・OCFと比べてフォントのファイル数が少なくて済む。コンパクトになる。
など。
基本的にCJK用なので日本のフォントベンダもCIDフォントを多数出しています。
CIDフォントにモリサワの報告があります。OCFからCIDへの移行で細かいことでかなりいろいろな問題を経験しているとのこと。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年05月03日
PDFとフォント(22) Type0 フォント
Type0フォントは、複合(Composit)フォントと言い、もともとはPostScriptの仕様書で定義されている、複数のフォントを束ねて高度なフォントを作る仕組みです。
Type1フォントは1バイトでローマ字用のもののため、CJKの文字を扱えませんでした。そこで、アドビはType0フォントの仕組みを利用して、OCF(Original Composite Font)を開発し、さらに、その後CID-Keyedフォントを開発しました。
このうち、OCFフォントはPostScriptでのみ使えるもので、PDFの仕様ではサポートされていません。
この記事を読みますと、OCFフォントは、日本のDTP分野で一時代に流行(という言葉が適切かどうかわかりまえせんが)したものですが、既に、フォント・メーカはサポートを終了してしまっているようです。Mac OS Xではインストールさえもできないとあります。PDFの仕様書を検索しても、OCFという言葉は一言も出てきません。
CID-Keyedフォントの概要は次に説明があります。
CID-Keyed Font Technology Overview Technical Note #5092
PDFで使えるのは、CID-Keyedフォントのみに制限されています。
PDF Reference V1.6
5.6 Composite Fonts (p.403)を参照。
PDF Referenceでは、composite font = Type0 フォント= CID-Keyedフォントとなっています。しかもcompositの意味が、1バイト以上の並びを解読して、CIDfontからグリフを選択する仕組みという意味になっていてPostScriptとは異なっています。
さて、ややこしいことに、PDF ReferenceのCIDFontには、CIDFontType0とCIDFontType2の2種類があります。
Technical Note #5092のCID-KeyedフォントとPDFの2種類のCID-Keyedフォントとの関係が今ひとつ分かりにくいですね。明日、もう少し調べてみましょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年05月02日
PDFとフォント(21) Type3 フォント
Type3フォントは、PostScriptでグリフを表現するものです。2006年04月26日 PDFとフォント(17) Type1 フォントで説明しましたように1980年代は、Type1フォントのファイル形式は非公開でした。
これに対して、Type3のファイル形式は、最初から公開されていましたので、一般の人がPostScriptベースでアウトライン・フォントを開発しようとするとType3を使うしかなかったわけです。
Type3フォントの仕様については、 PostScript Language Reference Manual, 2nd Edition; Addison-Wesley (ISBN #0-201-18127-4)に記述されています。
青木俊道(あおきとしみち)さんという方のWebページで「Type3フォントについて」実際に作って試した話が載っています。
アドビのサポートページで、Type1とType3についての比較を見ますと次のようなことが書いてあります。
・Type3フォントの文字の字形は、標準のPsostScriptの命令で記述できる。
・従って、作るのは簡単。また複雑な形状の文字を作ることもできる。
・アドビは、Type3フォントの仕様を公開したが、自社でType3フォントを作成したことはなく、配布したこともない。
・Adobe Type Manager などのアプリケーションはType3フォントをサポートしていない。
※参考資料
Distinguishing Type 1 from Type 3 Fonts
要するにType3フォントの仕様はPostScriptでグリフを作れるよ、というサンプルのようなものなんでしょうね。
PDF Reference(1.6版)には、5.5.4項(pp. 389~395)に7ページも費やしてしっかりとType3フォントの説明があります。
この部分、もう削除してしまっても良いと思うのですが。Type3フォントなんてフォントに使っている人がいるのだろうか?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月29日
PDFとフォント(20) マルチプルマスターType1フォント
マルチプルマスター・フォントというのは、Type1フォントの拡張で、ひとつのフォント・プログラムから様々な書体のフォントを作りだすことができるものです。
フォントのウエイト(ライトから極太)、幅(コンデンスからエクスパンド)などのフォントのデザインの次元を使うことで行います。
※参考
マルチプルマスターダイアログ
アドビとアップルはそれぞれ独自の技術を開発したようです。
マルチプルマスターType1フォントはアドビが開発した方法。アップルのはTrueType用ですので別のものです。
アドビの方法では、フォントのウエイト、幅、サイズなどのデザイン軸について、両極端の全てのフォントを用意しておき、その間に入るものを自動的に生成するもののようです。
中間のデザイン特性をもつフォントの生成は、ATMなどのフォントのラスタライザが行います。PDFにマルチプルマスター・フォントを埋め込む場合は、実際にラスタライザが補完して作り出したフォントを埋め込みます。マルチプルマスター・フォントそのものをPDFに埋め込むことはありません。
なお、CFF/Type2では、最初は用意されましたが削除されてしまい、これらの仕様ではマルチプルマスター・フォントは廃止された状態になっています。
PostScript fontsによりますと、アドビは、1999年にマルチプルマスター・フォントの開発を止めるとアナウンスしたようです。今までに制作されたマルチプルマスター・フォントは、約50種類と少ないようということを見ても、マルチプルマスター・フォントはあまり成功したフォント形式とは言えないようです。
2006/5/2 追記
"TrueType, PostScript Type 1, & OpenType: What’s the Difference?"Thomas W. Phinney
の最後の方にも、MMType1について成功していないと書いてあります。成功しなかった理由として、サポートする(MMType1を読んで、ラスタライズ、画面表示できる)アプリケーションが少なかったことを挙げています。
MMtype1を実現するには、各軸にそった極端なグリフセットを作らないといけないのですが、3軸だと8種類になります。それなら、最初から、8家族からなるフォント・ファミリーを制作するほうが手っ取りばやいという訳です。
私は、最初にMMtype1についての説明を読んで、なんてすごいアイデアだと思ったことを覚えています。しかし、どうやら現実の方が厳しかったようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月28日
PDFとフォント(19) CFF/Type2 フォント
CFF(Compact Font Format)は、Type1フォントのグリフアウトラインなどのプログラム容量を小さくするために開発されたものです。
CFFは通常Type2文字記述手続き(charstring)と一緒に使い、Type1フォントは、CFF/Type2セットと完全に(情報のロスなしで)相互変換ができます。Type1フォントからCFF/Type2に変換すると容量が30%~40%少なくなるそうです。
CFF/Type2フォントはAcrobat3.0(PDF1.2)のPDFにType1フォントを埋め込むのに使われており、Type1フォントをPDF1.2に埋め込む時は、CFF/Type2に変換してから埋め込みます。
逆に、PDFに埋め込まれているCFF/Type2のフォントは、PDFから取り出した後、Type1に変換してからリーダで表示したり、プリンタで印刷されます。
参考資料
CFF / Type 2 Q & A
なお、CFF/Type2というフォントの形式は、単独のフォント形式名としては存在しないようです。むしろCFF形式は、OpenTypeの中でType1フォントを保存する形式として使われることで普及しています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月27日
PDFとフォント(18) TrueType
次はTrueTypeです。今は、TrueTypeと言いますと、Microsoft Windowsに標準搭載のフォント技術という印象があります。しかし、TrueTypeフォント技術は、もともとAppleがOSレベルで拡大・縮小可能なフォントを実現しようとして開発を始めたものです。Microsoftは別途TrueImageという技術を開発していました。
TrueImage
これを見ますと、TrueImageは、Cal BauerとBauer Enterprisesが開発して、1989年にMicrosoftが買収した、PostScript互換のインタープリタとされています。
Microsoftとアップルは、TrueImageとTrueTypeをクロスライセンスして、TrueTypeがWindowsで使えるようになったのだそうです。
TrueImageは、PostScript互換のプリンタ用に商品化されましたが、結局あまり成功することなく終わってしまいました。
現在、Webで検索しますと、TrueImageは、他の会社の何の関係もない(?)製品名になってます。こうして見ますと、なんとなくアップルは庇を貸して母屋を取られたのではないかという印象がありますね。
このあたりの経緯は、JAGATの研究会の報告にも見られます。
アドビの最初のつまずき : 1989年
TrueTypeとType1のアウトラインデータの形式の特性、ラスタライザの性能特性などのグリフのデザインとその可視化の技術的な優劣については、いろいろな議論があるようです。この点はまた、別途、機会をみて検討してみたいと思います。
TrueTypeフォントのファイル形式としての特長をまとめますと、次のようなことになると思います。
・Type1フォント形式と違い、アウトライン情報とメトリック情報はひとつのファイルに収容されている。
・アップルのMacintosh System7.0 とWindows3.1以降のOSに、TrueTypeラスタライザが標準で搭載されていてOSレベルでサポートされている。この点で、Type1はPostScriptプリンタという高品位印刷の領域から始まったのと違い、TrueTypeは最初から非常にポピュラーな存在である。
・Microsoft Windowsには、多数のTrueTypeフォントファイルがバンドルされている。このファイルの拡張子は、.TTF、と.TTCがある。.TTCは、True Type Collectionの略でひとつのフォントファイルに複数のフォントを含んでいるもの。CJKフォントにこの形式が見られる。例えば、MS明朝とMS P明朝がひとつのフォントファイルにまとめられていたり、MSゴシックとMS Pゴシックがひとつのフォントファイルまとめられているなど。
※参考資料
A History of TrueType
Microsoft Typography TrueType
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月26日
PDFとフォント(17) Type1 フォント
アウトラインフォントと言いますと、なんといっても、Type1フォントを筆頭に挙げなければならないと思います。
2005年11月24日 消え去るType1フォントを参照してください。そこに、Type1フォントの簡単な歴史を紹介しています。
一部繰り返しになりますが、Type1フォントは、次のようなものです。
・1980年代にアドビシステムズが、PostScript言語用のフォント形式として開発し、1985年アップルのレーザライターに採用されて普及した。
2005年11月03日 PDFの作成方法(2) – PostScriptの登場をご覧ください。
・Type1は、PostScriptでアウトラインフォントを効率的に表現したもの。PostScriptの仕様は公開されて、サードパーティがクローン製品を作ることができた。しかし、Type1フォントの仕様は公開されず、それらのクローン製品でType1フォントをラスタライズすることができなかった。
・Type1フォントは、印刷用に用意されたものでPSプリンタ用に使われた。
・1989年12月に出たATM(Adobe Type Manager:Type1フォントのラスタライザ)によって、初めてType1フォントをパソコンの画面やビットマップ・プリンタで出せるようになった。それに続いて、1990年3月にType1フォントの仕様が初めて公開された。Windows9x/ME、MacOS 8/9で、Type1フォントを表示するにはATMが必要。
・Windows2000以降、アップルのMacOS X以降では、Type1フォントのラスタライザが標準搭載されているのでATMは不要になった。
・Type1フォントは、グリフのアウトラインデータを収録したPFB(Printer Font Binary)ファイルとフォントのメトリック情報を集録したファイルのペアで使う。このためフォントファイルがOS独立でない。
- Windowsの場合は、PFM (Printer Font Metrics)ファイル
- UnixなどではAFM(Adobe Font Metrics)ファイル。
Type1フォントは、このような特徴をもちパソコンのアウトライン・フォントの草分けとして大きな影響を及ぼしました。しかし、アドビシステムは、既にType 1フォントの販売を終了しています。
他のフォント・ベンダもType1フォントの販売を終了しつつあるようです。このようにType1フォントの重要度は、歴史的な存在になりかけているようです。
※参考資料
"TrueType, PostScript Type 1, & OpenType: What’s the Difference?"Thomas W. Phinney
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月25日
PDFとフォント(16) アウトラインフォントのタイプ
昨日は、アウトラインフォントがグリフのアウトラインを数学的な曲線で表わすものであること、そして、曲線で囲まれた領域のドットを塗り潰すことでグリフを可視化することを説明しました。
アウトラインフォントの中核はグリフのアウトラインデータですが、フォントファイルには、グリフの幅や高さを表すメトリック情報、あるいは、文字コードとグリフ番号の対応表、などのデータも含まれます。
アプリケーションがフォントを利用するための様々なデータを含めて、フォントファイルにどのような状態で収容されているかの仕様がフォントファイル形式と言います。
現在、普及しているアウトラインのフォントファイル形式には次のものがあります。
・PostScript Type 1
・TrueType
・OpenType TrueTypeアウトライン
・OpenType CFFアウトライン(PostScriptアウトライン、Type1アウトラインなどということもあります)
実際のところ、私が多少なりとも知識をもっていますのは、上の4つなんです。
ところが、PDF Referenceを読みますと、他にもいろいろ出てきます。
PDF Reference 5.4項に、PDFで定義するフォントの種類一覧(表5.7)がありますが、ここでは、
・Type0
・Type1
・MMtype1
・Type3
・TrueType
・CIDFontType0
・CIDFontType2
が出ています。(表5.7にはOpenTypeという言葉は出てきません)。
この他、
・Type42
フォントという言葉も聞いた覚えがあります。
PDF ReferenceあるいはPDFをAdobe Reader で表示したときのフォントの属性の用語と、一般に使われる用語に少しずれがあるような気もします。
そこで、これから少しフォントの種類について、調べて、整理してみたいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月24日
PDFとフォント(15) アウトラインフォント
昨日は、ビットマップフォントについて説明しました。これは、点滅するドットのパターンを予め用意しておく、という単純な方法でフォントを作成するものです。
2.アウトラインフォント
アウトラインフォントのアウトラインとはグリフの輪郭のことです。アウトラインフォントのファイルには、各グリフのアウトラインを描くためのデータ(パラメータ)が収録されています。
そこで、グリフの可視化は次のステップで行うことになるはずです。
(1)可視化したいグリフのデータを取り出す。
(2)データを元にグリフのアウトラインを描く。
(3)アウトラインで表現したグリフの状態から、塗り潰すべき点を見つける。
(4)塗り潰すべきを塗り潰す。
結局、アウトラインフォントをコンピュータのディスプレイに表示するには、全てのグリフについて、(1)~(4)のステップで点滅するドットのパターンに置き換えていきます。この処理を行うプログラムをフォントのラスタライザと言いWindowsのGDIやPostscriptを印刷するプリンタなど様々な機器にフォントのラスタライザが搭載されています。
アウトラインフォントについての詳しい説明は、次のページをご覧ください。
FontForgeアウトラインフォントエディタ(概要)
この中の「アウトラインフォントとは何か? ビットマップフォントとは何か?」あたりにアウトラインフォントについての詳しい説明が載っています。
グリフのアウトラインを記述する方法の中で、現在、最もポピュラーなのは、PostScript(Type1)フォントで使われている3次ベジエ曲線、およびTrueTypeフォントで使われている2次ベジエ曲線のふたつの方法です。
FontForgeの中に、ベジエ曲線についての分かりやすい説明があります。
Bézier1 スプライン
アウトラインフォントでは、グリフの輪郭を多数の線分に分割し、各線分をベジエ曲線で表します。ベジエ曲線は、二つの端点とそれに加えて曲線の曲がり具合を制御する制御点のデータで表現することができます。従って、アウトラインフォントのグリフデータの中核は、多数の線分の端点と制御点の集合ということになります。
アウトラインフォントの良い点は、グリフをベジエ曲線という数学的な曲線で表していますので、拡大・縮小が自由にできるということです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月23日
PDFとフォント(14) ビットマップフォント
昨日は、グリフを可視化する方式として、(1)点滅するドットのパターン、(2)ペンで線を描く、(3)光学的方式を説明しました。
今日は、その中で、フォントのデータから(1)点滅するドットのパターンをどうやって作り出すか、という観点からどのような方式があるかを整理してみたいと思います。
1.ビットマップフォント
一番単純なものは、フォントのデータ自身の中に、グリフをドットのON/OFFのパターンとして表したデータとして持つ方式です。
※参考
ビットマップフォント
次の例は、縦方向12行、横方向12列(12×12ドット)の塗り潰しパターンで「阿」という文字を表した例です。

※実際のフォントのデータではありません。
ビットマップフォントでは、このようなパターンデータを文字毎に用意するわけです。
ビットマップフォントの最大の問題は、拡大、縮小をすると汚くなってしまうことでしょう。すなわち、12×12ドットで最適な形になるようにデザインされたフォントを、例えば1文字あたり24×24ドットで表示すると奇麗ではなくなります。このため、文字を表示・印刷する装置のドット密度と表示したい文字の大きさ毎に適切なドット数のフォントを選択しなければなりません。
このためフォント供給者は、様々なサイズのフォントを品揃えしています。例えば、リコーのビットマップフォントの案内を見ますと、次の種類があります。
・ゴシック体 10×10、12×12、14×14、16×16、18×18、20×20、24×24、32×32、40×40
・明朝体 12×12、14×14、14×14 (ボールド)、16×16、16×16 (ボールド)、18×18、20×20、24×24、32×32、40×40
リコーのビットマップフォントには、この他にゴシック体を低解像度用に改良したNewゴシック体、丸ゴシック体も紹介されています。
ビットマップフォントは、パソコンの画面表示、携帯機器(PDA)、携帯電話、あるいは様々な電子機器などメッセージ表示用に使われます。実際のところ、ビットマップフォントが今一番使われているのは、携帯機器ではないでしょうか。しかし、家庭用の電子機器、複写機、FAXなども液晶画面でメッセージを表示するようになっていますので、ビットマップフォントの利用範囲は非常に広範囲に渡っていると思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月22日
PDFとフォント(13) 文字(グリフ)の可視化方法
2006年03月11日 PDFとフォント(1) 書体、グリフ、フォントでは、「フォントとは、書体が同じグリフを集めたもの」と定義しました。
ここでは、文字のグリフを可視化する方法という観点から、コンピュータで使用するフォントの種類について、まとめて見ます。
いま、グリフを可視化するという難しい表現を使ってしまいましたが、その方式として、幾つかあります。
1.点滅するドットのパターンでグリフを可視化する方式
一番簡単な例としては、電光掲示板がその典型的な例としてあげられます。
新幹線の車両や、JRの車両などにはニュースを伝える電光掲示板を良く見かけます。また、野球場のスコアボードにも電光掲示板があります。電光掲示板は、ランプの点滅のパターンで文字を表す仕組みです。
コンピュータの画面、携帯電話の画面、またはプリンタでの印刷などにおいて文字を表す仕組みは電光掲示板方式を精密にしたものです。点滅させるドットを小さくしていくことで、精密さを増しています。
2.ストロークでグリフを可視化する方式
点滅するドットのパターンで表す方式と比べますと、使用される頻度は少ないと思いますが、コンピュータを使ってペンや筆に相当するツールを制御して文字を書くという方式もあります。典型的な例が、プロッタ(ペンプロッタ)と呼ばれる出力装置を使うものです。
この方式は、建築や機械などの設計図面を紙に出力するのに使われる方式で、PDFとは親和性が小さいように思います。
※参考
プロッタ 【plotter】とは
3.その他の可視化方法
グリフの可視化の伝統的な方法として活字などがあります。というよりも活字は可視化されたグリフそのものというべきかもしれません。
この活字の発展形として、日本で開発された独自技術に写真植字(写植)があります。これは、文字盤に記載された文字を、写真の技術を使って、拡大・縮小して印画紙に焼き付けていく、という方法です。
※参考
写真植字機(手動写植機)
活字や手動写植は、コンピュータ技術以前のもので、いわばアナログ方式です。現在は使われることが少なくなっています。
この中で光学的方法で可視化する方式をコンピュータで自動化したものとして、デジタルフォント+電算写植機があります。これは、現在でも新聞の印刷などに使われているようです。
※参考
電算写植
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月18日
PDFのメタデータ (4) — XMPメタデータの埋め込み
昨日は、XMPについて、(1)様々なリソースの特性に関するメタデータを記述する仕様を決めていることを説明しました。
XMPの仕様書では、さらに、(2)メタデータをリソースに埋め込むための仕様、および、(3)ファイルのフォーマットについて知らないアプリケーションが、ファイルをスキャンしてメタデータを取得する方法などについて記述しています。
XMPの仕様書でメタデータを埋め込む方法を説明しているリソースの種類は次のものです。
・TIFF
・JPEG
・JPEG 2000
・GIF
・PNG
・HTML
・PDF
・AI (Adobe Illustrator)
・SVG/XML
・PSD (Adobe Photoshop)
・PostScriptとEPS
・DNG(Digital Negative)
これらのリソースにXMPメタデータを埋め込むときは、次のようにXMPメタデータの前後を<?packet ..?>という命令で囲ってパケット化します。
<?xpacket begin="バイト・オーダー・マーク" id="W5M0MpCehiHzreSzNTczkc9d"?>
XMLテキスト化したXMPメタデータ
<?xpacket end="w"?>
上のバイト・オーダー・マークの部分は、U+FEFFをXMPメタデータと同じ符号化方式(UTF-8、UTF-16、UTF-32)で符号化したデータとなります。
パケット化したデータは、各リソース・ファイルの中に埋め込むことが推奨されています。画像ファイルのようなバイナリ・ファイルに埋め込んだ場合、画像ファイルの形式について知らない場合でもファイルのバイナリ・データをスキャンしてXMPパケットを見つけ出すことができなければなりません。
XMP仕様書には、<?packet ..?>命令を見つけてXMPメタデータを認識するための、スキャンの方法についても説明されています。
また必要であれば、XMPメタデータを埋め込まずに、リソースの外部においてリソースと関係つけることもできます。外部に置く場合、XMPメタデータ・ファイルの拡張子は.xmpとし、MIME タイプが必要な場合は、application/rdf+xmlを使うことになっています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年04月17日
PDFのメタデータ (3) — XMP仕様について
PDFのmetadata streamにXMPパケットを埋め込むと言いましたが、このあたりをもう少し詳しく、見ておきます。
まず、XMPの仕様書とツールキットは、アドビシステムズからオープン・ソースライセンスで提供されています。ライセンス文書によりますと、ツールキットについては誰でもソースコートを改良してアプリケーションに組み込んで再頒布できるとされています。
そこで、早速、ダウンロードしたものを再配布することにしました。こちらにあります。
XMPは、次のようなXMLテキストです。
ルート要素はxmpmeta(オプション)でその下位の唯一の要素としてrdf:RDFをもちます。(恐らく、xmpmetaは旧バージョンとの互換性のために残されているもので、最新版では、rdf:RDFがルート要素として取り扱われると思います)。
rdfの名前空間宣言は、xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'です。ここから分かりますが、XMPではW3CのRDF(Resource Description Framework)を利用しています。
rdf:RDFの子供の要素としてrdf:Descriptionを複数記述できます。このrdf:Description毎にひとつのメタデータ・スキーマを利用して、リソースの属性を記述することができます。
現在のXMPの仕様書では、メタデータ・スキーマとして、次のものが定義されています。
“Dublin Core Schema”
“XMP Basic Schema”
“XMP Rights Management Schema”
“XMP Media Management Schema”
“XMP Basic Job Ticket Schema”
“XMP Paged-Text Schema”
“XMP Dynamic Media Schema”
“Adobe PDF Schema”
“Photoshop Schema”
“Camera Raw Schema”
“EXIF Schemas”
これ以外にも、独自の新しいスキーマを定義したり、既存のスキーマを拡張することができます。
XMP仕様書(72ページ)に載っている記述例をひとつ紹介しておきます。
EXIFはデジタルカメラで使用するイメージファイルの標準です。上の例はEXIFで作成されたリソースの特性について、TIFFのスキーマによる属性、EXIFのスキーマによる属性のふたとおりで記述されていることが分かります。
【参考資料】
EXIFについて
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月23日
PDFとフォント(12) CSSのフォント選択仕様
和文フォント”平成角ゴシック Std”は、もともと、W3、W5、W7、W9がフォントファミリーとして設計されています。しかし、現在のWindowsアプリケーションは、Microsoft OfficeでもWebブラウザ(IE6、Firefox)でも、”平成角ゴシック Std”をフォントファミリー名として認識できていないことを示しました。
私の想像ですが、この原因は、次のようなことでしょう。
(1) フォントファミリーは印刷業界などの専門家向けのDTPソフトで使われていたが、Microsoft Officeでは、文字にフォントを指定する際に、フォントファミリーを使うという概念がなかった。
(2) さらに、WindowsのAPI(アプリケーション・プログラム・インターフェイス)もMicrosoft Officeのような一般ビジネス文書用のアプリケーション用途になっているため、OpenTypeの優先フォントファミリー(ID16)の情報をアプリケーションに提供するようになっていない。
この解決策はないのでしょうか?
CSS2では、ブラウザがフォントを選択するための仕組みとしてフォント記述(Font Description)という仕様が定義されています。
例えば、平成角ゴシック Stdというフォントファミリーは@font-faceを使って、次のように記述することができます。
<style type="text/css">
@font-face { src : local("平成角ゴシック Std W3");
font-family : "平成角ゴシック Std" ;
font-weight : 300
}
@font-face { src : local("平成角ゴシック Std W5");
font-family : "平成角ゴシック Std" ;
font-weight : 500
}
@font-face { src : local("平成角ゴシック Std W7");
font-family : "平成角ゴシック Std" ;
font-weight : 700;
}
@font-face { src : local("平成角ゴシック Std W9");
font-family : "平成角ゴシック Std" ;
font-weight : 900
}
</style>
こうすれば、font-weightが300、500、700、900の4つの特性をもつ平成角ゴシック Stdというフォントファミリーを定義できるはずです。しかし、残念ながらIE6も、Firefoxも@font-face指定を認識できません。
・@font-faceはCSS2から導入されました。IE6はCSS2は未対応。
・CSS2の@font-face宣言は、CSS2.1(Working Draft)では削除されています。
Cascading Style Sheets, level 2 revision 1
CSS 2.1 Specification
W3C Working Draft 13 June 2005
・そのためかどうか、Firefoxでも@font-faceによる上の定義は認識できないようです。
ここにサンプルファイルを置きます。お使いのブラウザでお試しになってみてください。
Download file
どこかに、@font-faceを認識するブラウザがあるのでしょうか?また、Internet Explorer7になったらできるようになるのでしょうか?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月22日
PDFとフォント(11) CSSのフォント指定とブラウザの表示
さて、CSSでは、前に言いました(2006年03月12日PDFとフォント(2) フォントファミリー)が、フォントの指定には font-family, font-style, font-variant, font-weight, font-stretchおよびfont-sizeを使います。
では、WebサーバにあるHTML+CSSで指定されたフォントは端末のブラウザでどのように選択されるのでしょうか?
CSSの font-family, font-style, font-weightの指定の仕方をいろいろ変えたとき、Internet Explorer6 (IE6)とFirefoxで、どのように表示されるかを調べてみましょう。
ここでは、今までに調べてきましたArialと平成角ゴシック StdというふたつのOpenTypeフォントファミリーで試しています。次のような結果になりました。
(1) IE6でもFirefoxでも、font-family="Arial"、font-style="italic"、font-weight="bold" の組み合わせで適切なフォントが選択される。欧文フォントはCSSの指定が機能しています。
(2) IE6でもFirefoxでも、font-family="平成角ゴシック Std"はフォミリー名として認識できず、ブラウザのデフォルトのフォントになってしまう。つまりOpenTypeの優先フォントファミリー(ID16)の名前の指定は有効にならないということが言えます。
(3) 和文フォントに対してfont-style="italic"、font-weight="bold"を指定すると、IE6でもFirefoxでも文字を傾けたり、文字を太らせるというフォント合成を行ってそれらしく表示します。
(4) font-family="平成角ゴシック Std W3"~"平成角ゴシック Std W9"というフォントメニュー名(ID1)を指定すると、Firefoxでは、平成角ゴシック Std フォントファミリーから該当するフォントを選択して適用します。
(5) しかし、IE6は、漢字・カタカナがMSP明朝というブラウザのデフォルトフォントになってしまいます。ラテン文字にのみ、平成角ゴシック Std フォントファミリーの該当するフォントを選択して適用されます。
※結局、このテストデータをIE6で表示しますと、漢字カタカナを平成角ゴシックStdのファミリーを選択して表示するケースは皆無になっています。これはIE6のバグじゃないでしょうか?
(7) font-weightに数値(100から900)を指定したとき、Firefoxは;
a."平成角ゴシック Std W3"、"平成角ゴシック Std W5"では600以上をboldとして扱う。
b."平成角ゴシック Std W7"、"平成角ゴシック Std W9"ではもともと全てをboldとして扱っている。
(8) font-weightに数値(100から900)を指定したとき、IE6は;
a.MSP明朝についてはfont-weight="600"以上になると太らせている。
b."平成角ゴシック Std W3"では500以上をboldとして、"平成角ゴシック Std W5"では700以上をboldとして扱う。つまりそれ自身より2段階上の値が指定されると太らせている。
b."平成角ゴシック Std W7"、"平成角ゴシック Std W9"ではもともと全てをboldとして扱っている。
簡単なサンプルを作ってみただけですが、和文フォントについてはfont-familyで指定して指定したフォントが必ずしもうまく選択されないという問題があるのではないかと思います。
■テストデータ
欧文フォント、和文フォントへのfont-family、font-style、font-weight設定例
■上記のサンプルをブラウザ+アンテナハウスPDFドライバV3でPDF化した例
Firefox1.5+アンテナハウスPDFドライバV3でPDF化
InternetExplorer6+アンテナハウスPDFドライバV3でPDF化
【動作環境】
WindowsXP Service Pack2英語版OSを日本語モードで起動。
InternetExplorer Version 6.0.2900.2180
Firefox 1.5.0.1
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月21日
PDFとフォント(10) フォントの合成
実際に、Microsoft Excelでフォント別にスタイルを指定したデータを作ってみます。
次の図は、Arial、Arial Narrow、平成角ゴシックStdについて、Excelで指定可能なスタイルを指定したものです。
※MicrosoftExcelの印刷プレビュー画面
上の図で、フォント名にブルーの背景をつけた行は、フォントファミリーに該当のスタイルのものがありません。しかし、フォントがなくてもそれらしいスタイルの文字が表示されていることがわかります。
Bold、Italicについては、フォントファミリーに該当するフォントがなくても、OS(Windows)がフォントを合成して該当するスタイルを作りだしてくれることがわかります。
もちろん、これをPDFドライバでPDF化した場合、Excelの印刷プレビューと同じようにPDFでも再現されます。
○上記のExcelファイルをもとにAcrobat6で作成したPDF:
Download file
○上記のExcelファイルをもとにAntenna PDF Driver 3.0で作成したPDF:
Download file
ちなみに、
OSで合成したフォントについては、PDFReferenceには次のように書いてあります。
「システムにインストールされていなくてOSが合成したフォントについては、カンマで区切ってスタイル名を付加する。例えば、TrueType フォントNew YorkのBoldを派生させたときは、BaseFont の値に、/NewYork,Bold と書く」
(PDF Reference 1.6 p.388)
しかし、実際には、そのような出力をしているのは、PDFWriterのみです。次の図は、PDFWriterで出力したPDFのプロパティ-Fontの部分ですが、フォント名の後ろにスタイルを付加していることがわかります。
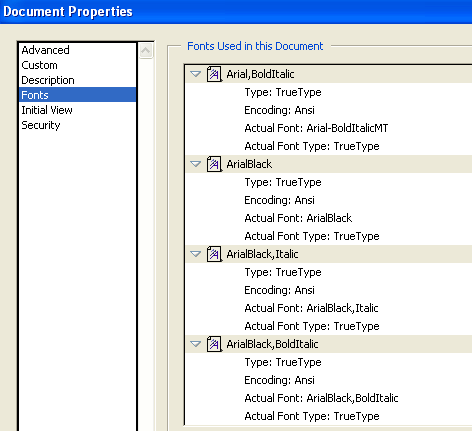
※ちなみに、PDFWriterで作成したPDFは、(ここにはリンクしませんが)平成角ゴシックStd部分が文字化けしてしまっています。
AcrobatPDFもAntenna PDF Driverもそういう出し方はしていなくて、Italicに対して傾ける行列をつけるなどの計算方法を指定しているようです。PDFReferenceの記述は不要ということなんでしょうか?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月20日
PDFとフォント(9) Officeのフォントダイヤログ-スタイル
Microsoft Officeのフォントダイヤログでは、各フォントに対して、スタイルを指定することができます。
フォント名を選択すると、スタイルのリストボックスに、いくつかのスタイルが表示され、その中の一つを選択できます。このリストが実際のフォントファイルにどのように対応付けられているのかを見てみます。
(1) 大部分のフォント名について、スタイルには
・日本語版では標準-斜体-太字-太字 斜体
・英語版ではRegular - Italic - Bold - Bold Italic
の4種類がリストされます。以下、括弧内が英語版。
例えば、ArialやArial Narrowの場合は、4種類のフォントファイルが存在して、ファミリーを作っています。
2006年03月13日 PDFとフォント(3) 欧文フォントのフォントファミリー
このようなフォントファミリーの場合、標準-斜体-太字-太字 斜体(Regular - Italic - Bold - Bold Italic)の4種類のスタイルは、そのファミリーの4つのフォントファイルと1対1対応です。
(2) 欧文フォントのBitstream Vera Sansの場合は、スタイルのリストにはRoman - Oblique - 太字 -太字 Oblique (Roman - Oblique - Bold - Bold Oblique)の4種類が表示されます。標準(Regular)の代わりにRoman、斜体(Italic)の代わりにObliqueになっています。(スタイルの名前が違う)。
(3) Arial Blackの場合は、フォントファイルは一種しかありませんが、スタイルのリストには標準-斜体-太字-太字 斜体 (Regular - Italic - Bold - Bold Italic)の4つが表示されます。つまりフォントファミリーには実際にフォントがないのに、スタイルのリストにはあたかもファイルがあるかのように表示されます。
(4) 平成角ゴシックStdは、W3、W5、W7、W9がそれぞれ単独でフォント名として選択できます。
(a) W3、W5は、標準 - 斜体 - 太字 - 太字 斜体 (Regular - Italic - Bold - Bold Italic)の4種類、
(b) W7は、日本語版Wordでは太字 - 太字 斜体(英語版WordではRegular - Bold Italic)、日本語版Excelでは斜体 - 太字 - 太字 斜体(英語版ExcelではItalic - Bold - Bold Italic)
(c) W9は、日本語版Wordでは標準 - 斜体 - 太字 - 太字 斜体 (英語版WordではRegular - Italic - Bold - Bold Italic)、日本語版Excelでは斜体 - 太字 - 太字 斜体 - 太字 (英語版ExcelではItalic - Bold - Bold Italic - Bold)の4種類のリストが表示されます。
Officeのフォントダイヤログで平成角ゴシックStdW7,W9フォントを選択した時にスタイルのリスト表示は正しくないように思います。特に英語版はWordとExcelで首尾一貫していません。ソフトウエアのとこかにバグがあると思います。
日本語:Windows2000英語版ServicePack4を国際化したOSを日本語モードで起動+Microsoft Office2003日本語版
英語:WindowsXP ServicePack2英語版を日本語モードで起動+MicrosoftOffice2003英語版
上に述べたことをOpenTypeのFont Subfamilyとの関係について表に整理してみました。
※Officeは上に述べたように、OSと日本語版・英語版で首尾一貫してない箇所がありますので、ここでは英語版のExcelのスタイルリストのみとします。
| Font FileのName Table | 英語版Microsoft Excel Font Styleリスト |
|
|---|---|---|
| Font Family(ID1) | Font Subfamily (ID2) | |
| Arial / Arial narrow | Regular | Regular |
| Italic | Italic | |
| Bold | Bold | |
| Bold Italic | Bold Italic | |
| Arial Black | Regular | Regular |
| * | Italic | |
| * | Bold | |
| * | Bold Italic | |
| Bitstream Vera Sans | Roman | Roman |
| Oblique | Oblique | |
| Bold | Bold | |
| Bold Oblique | Bold Oblique | |
| 平成角ゴシックStd W3 | Regular | Regular |
| * | Italic | |
| * | Bold | |
| * | Bold Italic | |
| 平成角ゴシックStd W5 | Regular | Regular |
| * | Italic | |
| * | Bold | |
| * | Bold Italic | |
| 平成角ゴシックStd W7 | Bold | Italic |
| * | Bold | |
| x | Bold Italic | |
| 平成角ゴシックStd W9 | Bold | Italic |
| * | Bold | |
| x | Bold Italic | |
| x | Bold | |
○まとめ
(1) Microsoft Office のフォントダイヤログ-スタイルのリストには、原則として、WindowsにインストールされているフォントファミリーのFont Subfamily (ID2)に設定されている名前が表示される。
(2) 但し、フォントファミリーにはFont Subfamily (ID2)に該当する設定を持つフォントがないのにリストにスタイルが表示されることもある。
上の表で * を示したセルが該当。
(3) Font Subfamily (ID2)になく、かつ、無意味と思われるスタイルが表示されることもある。
上の表で x を示したセル。バグ?。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月18日
PDFとフォント(8) Windows アプリケーションのフォント・メニュー
さて、2006年03月16日のPDFとフォント(6) 和文フォントのファミリーについてに、Ken Lundeさんから、『CJKのOpenTypeフォントの「name」テーブルの内容について、Adobe Tech Note #5149を参照』せよ、というコメントをいただきました。
Adobe Tech Note #5149
OpenType-CID/CFF
CJK Fonts: ‘name’
Table Tutorial
http://partners.adobe.com/public/developer/en/font/5149.OTFname_Tutorial.pdf
早速読んでみましたが、この文書はフォントを作成する人向けの、Name Table設定のための手引書です。
これを見ますと、Microsoft/Unicode Menu Namesに、Font Family (ID1), Font Subfamily (ID2), 優先Font Family (ID16), 優先Font Subfamily (ID17)について、次のようにまとめられています。
・ID1は、優先Font Family (ID16)と優先Font Subfamily (ID17)をスペースを間において結合した文字列とする。
・ID2は、head.MacStyle とOS/2.Selectionのフィールドの情報が、ボールドを示さない時は、Regular固定とする。ボールドを示す時は、Bold固定とする。
平成角ゴシックStdファミリーは、その通りに設定されています。
ところで、Menu Nameという表現は、PostScript Nameとの区分上の表現なのでしょう。そして、この名前はメニューに表示するためのものであることを意味すると予想されます。
そこで、平成角ゴシックStdフォントの名前がWindows上のMicrosoft Wordでどのように表示されるかを見てみました。
1.Windows XP を英語モードで起動した時
2.Windows XP を日本語モードで起動した時
ここから次のことがわかります。
(1) Microsoft Officeでは、Name Table のFont Family (ID1)は、フォントを選択するためのリストボックスに表示するための名前として使われている。
(2) Microsoft Officeのフォント選択ダイヤログには、優先Font Family名 (ID16)は表示されない。
では、一般のWindowsアプリケーションは、優先Font Family (ID16)と優先Font Subfamily (ID17)を使うことができるのでしょうか?
普通のWindowsアプリケーションは、WindowsのAPI(WindowsOSが、アプリケーションに提供するインターフェイス)を使って、Fontファイルの内容を読みます。従って、上の質問に対する回答は、WindowsAPIの機能を調べてみないと分かりません。
で、当社のプログラマの一人に聞きましたら、そんなことは知らないというつれない返事でした。
アンテナハウスのXSL FormatterやPDF関連のライブラリーは、Windowsの他、Linux、Solaris、AIXなどで動きます。これを実現するためWindowsAPIを使わずに、自力で、Fontファイルの内容を読んでいます。ですのでWindowsAPIの機能なんて知らないという答えになってしまうのも仕方ないのです。プログラマも分業制ですしね。
ところで、殆どのソフトハウスは、WindowsAPIを使ってフォントファイルから情報を取り出しているはずです。なぜかと言いますと、例えば日本で販売されているPDF作成ソフトでJAVA版を除くと残りのソフトは、殆どWindows版のみですから。
そうしますと、優先ファミリー (ID16)と優先サブファミリー (ID17)を使うことができるかどうかは、MicrosoftのWindowsAPIにその機能が用意されているかどうか、に依存してしまうということになるのですが。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月17日
PDFとフォント(7) 平成角ゴシック Stdフォントのファミリー名
さて、次に平成角ゴシック Stdフォントの名前が、Macintosh、Windowsの日本語、英語モード用にどのようになっているかを比較してみました。
○まとめ
(1)Macintosh用
・英語では、ファミリー名:Heisei Kaku Gothic Std、サブファミリー名:W3~W9となっています。つまり、フォントウエイトでファミリー化しているということになります。また、優先フォントファミリーの部分は使っていません。
・日本語も同様です。
(2)Windows用
・英語では、ファミリー名:Heisei Kaku Gothic Std W3~同W9、サブファミリー名:RegularまたはBoldとなっています。
この部分を使うと、Heisei Kaku Gothic StdのウエイトW3~W9のフォントはファミリーとして扱われません。
・優先ファミリー名(ID16)を使ってMacintoshと同じようなファミリー化をしています。従って、Windows版では、優先ファミリー名を使わないとファミリーとして扱えません。
・Full font name (ID4)は、ID1とID2を結合したものでなければならない、しかし、そうなっていない、という点で仕様違反です。
・日本語の場合、Full font name (ID4)が空白になっています。日本語WindowsではFull font name を表示するアプリケーションがもしあると困るでしょう。
以下にデータを示します。
次の表は、平成角ゴシック Std W3フォントのName Tableに書かれている4つのプラットフォーム用のフォントファミリー関係のデータを取り出したもの。
表1 平成角ゴシック Std W3フォントのName Tableをttfdump.exeで解析した結果
| Font Family | Font Subfamily | 優先Font Family | 優先Font Subfamily | |
|---|---|---|---|---|
| Mac 英語 | Heisei Kaku Gothic Std | W3 | ||
| Mac 日本語 | 平成角ゴシック Std | W3 | ||
| Window英語 | Heisei Kaku Gothic Std W3 | Regular | Heisei Kaku Gothic Std | W3 |
| Windows日本語 | 平成角ゴシック Std W3 | Regular | 平成角ゴシック Std | W3 |
次の表は平成角ゴシックStdファミリーのName Tableの解析結果です。4つのフォントファイルのフォント名に関する部分を取り出して、4種類のプラットフォーム毎に整理したものです。
表2-1 平成角ゴシックStdファミリー Macintosh用英語
| FileName | Font Family | Font SubFamily | Full Font Name | 優先Font Family | 優先Font Subfamily |
|---|---|---|---|---|---|
| (ID1) | (ID2) | (ID4) | (ID16) | (ID17) | |
| HeiseiKakuGoStd-W3.otf | Heisei Kaku Gothic Std | W3 | Heisei Kaku Gothic Std W3 | ||
| HeiseiKakuGoStd-W5.otf | Heisei Kaku Gothic Std | W5 | Heisei Kaku Gothic Std W5 | ||
| HeiseiKakuGoStd-W7.otf | Heisei Kaku Gothic Std | W7 | Heisei Kaku Gothic Std W7 | ||
| HeiseiKakuGoStd-W9.otf | Heisei Kaku Gothic Std | W9 | Heisei Kaku Gothic Std W9 |
表2-2 平成角ゴシックStdファミリー Macintosh用日本語
| FileName | Font Family | Font SubFamily | Full Font Name | 優先Font Family | 優先Font Subfamily |
|---|---|---|---|---|---|
| (ID1) | (ID2) | (ID4) | (ID16) | (ID17) | |
| HeiseiKakuGoStd-W3.otf | 平成角ゴシック Std | W3 | 平成角ゴシック Std W3 | ||
| HeiseiKakuGoStd-W5.otf | 平成角ゴシック Std | W5 | 平成角ゴシック Std W5 | ||
| HeiseiKakuGoStd-W7.otf | 平成角ゴシック Std | W7 | 平成角ゴシック Std W7 | ||
| HeiseiKakuGoStd-W9.otf | 平成角ゴシック Std | W9 | 平成角ゴシック Std W9 |
表2-3 平成角ゴシックStdファミリー Windows用英語
| FileName | Font Family | Font SubFamily | Full Font Name | 優先Font Family | 優先Font Subfamily |
|---|---|---|---|---|---|
| (ID1) | (ID2) | (ID4) | (ID16) | (ID17) | |
| HeiseiKakuGoStd-W3.otf | Heisei Kaku Gothic Std W3 | Regular | HeiseiKakuGoStd-W3 | Heisei Kaku Gothic Std | W3 |
| HeiseiKakuGoStd-W5.otf | Heisei Kaku Gothic Std W5 | Regular | HeiseiKakuGoStd-W5 | Heisei Kaku Gothic Std | W5 |
| HeiseiKakuGoStd-W7.otf | Heisei Kaku Gothic Std W7 | Bold | HeiseiKakuGoStd-W7 | Heisei Kaku Gothic Std | W7 |
| HeiseiKakuGoStd-W9.otf | Heisei Kaku Gothic Std W9 | Bold | HeiseiKakuGoStd-W9 | Heisei Kaku Gothic Std | W9 |
表2-4 平成角ゴシックStdファミリー Windows用日本語
| FileName | Font Family | Font SubFamily | Full Font Name | 優先Font Family | 優先Font Subfamily |
|---|---|---|---|---|---|
| (ID1) | (ID2) | (ID4) | (ID16) | (ID17) | |
| HeiseiKakuGoStd-W3.otf | 平成角ゴシック Std W3 | Regular | 平成角ゴシック Std | W3 | |
| HeiseiKakuGoStd-W5.otf | 平成角ゴシック Std W5 | Regular | 平成角ゴシック Std | W5 | |
| HeiseiKakuGoStd-W7.otf | 平成角ゴシック Std W7 | Bold | 平成角ゴシック Std | W7 | |
| HeiseiKakuGoStd-W9.otf | 平成角ゴシック Std W9 | Bold | 平成角ゴシック Std | W9 |
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月16日
PDFとフォント(6) 和文フォント、Open Typeの Naming Table
和文フォントのファミリーについて、OpenTypeの仕様と照らし合わせながら少し詳しく調べてみましょう。
OpenTypeのファイルには、そのフォントを利用するアプリケーションのために様々なデータの表が収容されています。フォントの名前などは、Naming Table という表にまとまっています。
ちなみに、ttfdump.exeでHeiseiKakuGoStd-W3.otf(平成角ゴシック Std W3)のNaming Table の内容を見てみました。
Naming Tableには、ひとつのフォントファイルを幾つかのプラットフォーム(OS)で利用するために、名前も一種類ではなく、複数のプラットフォーム用の名前のデータがあります。そして、このフォントでは、次の4つのプラットフォーム用のデータがあることが分かりました。
(1) Macintosh英語用
Platform ID: 1 (Macintosh)
Specific ID: 0 (Roman)
Language ID: 0 (English)
(2) Macintosh日本語用
Platform ID: 1 (Macintosh)
Specific ID: 1 (Japanese)
Language ID: 11 (Japanese)
(3) Windows英語用
Platform ID: 3 (Windows)
Specific ID: 1 (Unicode)
Language ID: 1033 (英語)
(4) Windows日本語用
Platform ID: 3 (Windows)
Specific ID: 1 (Unicode)
Language ID: 1041 (日本語)
平成角ゴシック Stdの場合、MacintoshとWindowsのふたつのOSの、それぞれ英語モード、日本語モードで使えるように、4種類の名前のデータを別の符号化方式で持っているということになります。
逆にいうと、このフォントはLinuxなどの他のOSでは公式には使えないってことなんでしょうか。
さて、Naming Table には幾つかの見出し項目(Name ID)があります。その中で関係しそうなものを拾って見ますと、次のようになります。
| Name ID | 意味 |
|---|---|
| 1 | Font Family。最大4つのフォントが同じFont Family名を共有できる。4つでregular, italic, bold, bold italicというフォントファミリーを形成する。 |
| 2 | Font Subfamily。Font Subfamily名はID 1で同じファミリーに分類されるフォントをさらに細かく区別する。 |
| 4 | Full font name。ID 1とID 2を結合したもの。但し、ID 2でregularの時のみファミリー名のみを使う。 |
| 6 | PostScript name |
| 16 | Preferred(優先)Family。歴史的な理由でフォントファミリーは最大4つのスタイルを含んでいる。優先ファミリーを使うことでデザイナは4種類以上のスタイルをグループ化することができる。ID 1と異なる場合のみ存在する。 |
| 17 | Preferred(優先)Subfamily。ID 2よりも細かい分類をすることができる。ID 2と異なる場合のみ存在する。また、優先サブファミリーの中ではユニークでなければならない。 |
フォントファミリーの基本は、regular, italic, bold, bold italicの4種類がひとつのセットなんですね。そうして、もっと多数のフォントをファミリー化するには、優先ファミリー名と優先サブファミリー名を使うということになっているようです。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年03月15日
PDFとフォント(5) XSL-FOにおけるフォントの扱い
XSL-FOのフォントについての説明はCSS2を元にしていますが、細かく見ますとCSS2とは少し異なっています。
XSL-FO V1.0 仕様書 7.8 Common Font Propertiesでは、フォントについて大まかに、次のように説明しています。
(1) XSLのフォントモデルは、OpenType仕様で示される技術に準拠して説明されている。
※Microsoft, Adobe. OpenType specification v.1.2.
(2) フォントは、グリフと、そのグリフを表示するために必要なフォント・テーブルという情報の集合である。グリフとフォント・テーブルの集合をフォント・データという。
(3) フォント・テーブルには、文字をグリフに対応付けるのに必要な情報と、グリフの領域を決め、グリフの領域の位置を決めるのに必要な情報を含んでいる。各フォント・テーブルはフォントのウエイトやフォントのスタイルのようなフォントの特性から構成される。
ここで、注意すべきことは、フォントとは単なるグリフの集合ではなく、グリフを印刷平面上に配置していくための様々なデータを含んでいるということです。
さて、XSL-FOで使うフォントの属性は、次の6項目でほぼCSS2と同じです。
(1)フォントファミリー font-family <family-name>、または<generic-family>を指定。
(2)フォントサイズ font-size
(3)フォントストレッチ font-stretch
(4)フォントスタイル font-style
(5)フォントの変形 font-variant
(6)フォントのウエイト font-weight
※XSL-FOはCSS2を若干拡張していますが、あまり本質的ではないので省略します。
font-familyはCSS2と同じです。CSS2で出てきました時、説明しませんでしたが、属性に指定する<family-name>は、フォントの提供者がつける固有名となります。これに対して<generic-family>は、キーワードでserif, sans-serif, cursive, fantasy, monospaceの5種類があります。例えば、和文フォントではserifというより明朝という言い方が、sans-serifというよりゴシックという言い方が一般的です。cursive, fantasyは欧文フォントの概念で和文フォントでは一般的ではないように思います。無理にいえば、cursiveは連綿体に相当すると思います。monospaceは、欧文では手動タイプライタのフォントになります。和文フォントはもともと固定ピッチが基本なのでmonospaceというキーワードを和文フォントに適用するのは意味がないと思います。
<generic-family>はフォントの選択メカニズムで重要になります。
さて、CSS2もXSL-FOも上のように、その文字を可視化する際に使いたいフォントのプロパティを(1)から(6)の属性によって細かく指定できるわけですが、既に見ましたように実際に使うことのできるフォントのファミリーには、指定した属性のものが揃っているとは限りません。いや、むしろ揃っていないことの方が多いでしょう。
その時は、どうするのでしょうか?この時に重要になるのがフォントの選択メカニズムです。この辺については別途調べてみたいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月14日
PDFとフォント(4) 和文フォントのフォントファミリー
昨日は、欧文フォントのフォントファミリーはNormal、Italic、Bold、Bold Italicの4種類で構成されているものが多いようだ、と言いました。
それでは、和文フォントはどうでしょうか?Windowsについている最もポピュラーなフォントである、MS明朝やMSゴシックは1種類しかありませんからファミリーにはなっていません。
日本規格協会の文字フォント開発・普及センターが開発した平成明朝体、平成ゴシック体というフォントはいろいろなフォント・ベンダが商品化しています。現在ではかなり普及したフォントになっていると思います。
このフォントは、ウエイトについてファミリー化されています。アドビが商品化した平成明朝体、平成角ゴシック体、平成丸ゴシック体のフォント名とフォントファミリー名を見ますと次の表のようになっています。
いずれも、OpenTypeフォント、PostScriptアウトライン形式。
1.平成明朝体 (アドビ)のフォント名とフォントファミリー名
| ファイル名 | Font Name | Font Family Name |
|---|---|---|
| HeiseiMinStd-W3 | HeiseiMinStd-W3 | 平成明朝 Std W3 |
| HeiseiMinStd-W5 | HeiseiMinStd-W5 | 平成明朝 Std W5 |
| HeiseiMinStd-W7 | HeiseiMinStd-W7 | 平成明朝 Std W7 |
| HeiseiMinStd-W9 | HeiseiMinStd-W9 | 平成明朝 Std W9 |
2.平成角ゴシック体 (アドビ)のフォント名とフォントファミリー名
| ファイル名 | Font Name | Font Family Name |
|---|---|---|
| HeiseiKakuGoStd-W3 | HeiseiKakuGoStd-W3 | 平成角ゴシック Std W3 |
| HeiseiKakuGoStd-W5 | HeiseiKakuGoStd-W5 | 平成角ゴシック Std W5 |
| HeiseiKakuGoStd-W7 | HeiseiKakuGoStd-W7 | 平成角ゴシック Std W7 |
| HeiseiKakuGoStd-W9 | HeiseiKakuGoStd-W9 | 平成角ゴシック Std W9 |
3.平成丸ゴシック体 (アドビ)のフォント名とフォントファミリー名
| ファイル名 | Font Name | Font Family Name |
|---|---|---|
| HeiseiMaruGoStd-W4 | HeiseiMaruGoStd-W4 | 平成丸ゴシック Std W4 |
| HeiseiMaruGoStd-W8 | HeiseiMaruGoStd-W8 | 平成丸ゴシック Std W8 |
この3つの表を見ますと、フォントファミリー名のところにフォントのウエイトの名前が付加されているため全てのフォントがひとつづつ別のフォントファミリー名になってしまっています。つまり意匠上はファミリーであっても、OpenType仕様上でのファミリーになっていません。
このようになっていると、CSS2の font-family、font-weightでプロパティを指定してフォントを選択するというメカニズムを適用することができません。
フォントファミリーということを意匠・書体面の概念としてのみ捉えるのではなく、CSS2などに対応するブラウザで使うための技術仕様であるfont-familyとして捉えるのであれば、OpenType仕様で定めるFont family nameの項目には同一のファミリー名を設定しておかないといけないのではないでしょうか?
[2006/3/15 一部削除]
ザキンコ さんのご指摘により削除しました。詳細は、コメントをご覧ください。
[2006/3/15 追記]
ttfext.exeでFont Family Nameを見ますと、次の画面のようになっています。上の表の通りなのです。しかし、ザキンコ さんのご指摘のように、アドビの平成フォントは、別の箇所に、優先Font Family Nameを持っています。ttfext.exeの表示が不十分ということのようです。この点につきまして調査結果を、3月16日のブログで詳しく説明したいと思います。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年03月13日
PDFとフォント(3) 欧文フォントのフォントファミリー
さて、手元のWindowsマシンに入っている欧文フォントのファミリーがどうなっているか、ちょっと見てみましょう。
OpenTypeのttfext.exeというツールを使うと、各フォントのフォント名とフォントファミリー名を見ることができます。
まず、 Monotype Typography, Inc.のArial 系OpenType (True Type Outline)フォントは、類似の名前のものが10種類入っています。このフォントファミリー名は次のようになっています。
| ファイル名 | Font Name | Font Family Name |
|---|---|---|
| Arial | Arial | Arial |
| Arial Italic | Arial Italic | Arial |
| Arial Bold | Arial Bold | Arial |
| Arial Bold Italic | Arial Bold Italic | Arial |
| Arial Black | Arial Black | Arial Black |
| Arial Narrow | Arial Narrow | Arial Narrow |
| Arial Narrow Italic | Arial Narrow Italic | Arial Narrow |
| Arial Narrow Bold | Arial Narrow Bold | Arial Narrow |
| Arial Narrow Bold Italic | Arial Narrow Bold Italic | Arial Narrow |
| Arial Rounded NT Bold | Arial Rounded NT Bold | Arial Rounded NT Bold |
次にAdobe SystemsのMinionPro系OpenType (PostScript Outline)フォント6種類のフォントファミリー名は次のようになります。
| ファイル名 | Font Name | Font Family Name |
|---|---|---|
| MinionPro-Regular | MinionPro-Regular | Minion Pro |
| MinionPro-It | MinionPro-It | Minion Pro |
| MinionPro-Bold | MinionPro-Bold | Minion Pro |
| MinionPro-BoldIt | MinionPro-BoldIt | Minion Pro |
| MinionPro-Semibold | MinionPro-Semibold | Minion ProSmBd |
| MinionPro-SemiboldIt | MinionPro-SemiboldIt | Minion ProSmBd |
MinionProは、SemiBoldの2書体がMinion ProSmBdというフォントファミリーで、MinionProとは別のファミリーになっています。他のフォントも同じようなものです。大半の欧文フォントはNormal、Italic、Bold、Bold Italicの4種類でフォントファミリーを構成しているようです。Condensedなどのファイル名がついているものもありますが、その場合、フォントファミリー名にCondensedがついているなど、CSS2のプロパティで指定して選択できるようなフォントファミリーを構成するものは、少なくとも手元のパソコンには見当たりません。
ですので、CSS2のフォント・プロパティではウエイト、幅などを指定できますが、フォントファミリーとこれらのプロパティが指定されたとき、既存のフォントファミリーの中から、その組み合わせにぴったりマッチするフォントが見つかる可能性はあまり大きくないと言えます。結局、ブラウザのフォントマッチング手法依存になってしまうのではないでしょうか。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月12日
PDFとフォント(2) フォントファミリー
フォントはいろいろなアプリケーションから使用します。
例えば、Microsoft Officeからフォントを指定して、PDFを作成する場合には、ユーザがフォントについて知識をもっていなくても、それ程、困ることがないでしょう。
InDesignやQuarkXPressなどのDTPソフトを使いこなす上では、フォントについての知識を多く持っている方が都合が良いのではないでしょうか。
これに対して、CSSやXSL-FOなどを使いこなそうとしますと、ユーザがフォントの仕組みについて知識をもっている必要がありそうです。
そこで、CSSの仕様でフォントについての記述を見てみましょう。CSSというのは、WebでHTML/XHTML/XMLの表示方法を指定するための仕様で、現在、W3Cが標準として勧告しているのは、次のCSS2です。
Cascading Style Sheets, level 2
CSS2 Specification
W3C Recommendation 12-May-1998
※なお、CSS2は改訂が進んでおりCSS2.1の最終ドラフトが公開中。CSS3も、現在、策定作業中です。
この15 Fontsを見ますと、フォントの指定方法と、ブラウザなどがフォントを選択する方法について記述されています。
1.フォントの指定方法
CSS2では、フォントについて次の特性を指定できます。
(1) フォントファミリー font-family
欧文フォントは、意匠デザインが同じ系統の幾つかのフォントをシリーズにしてフォントファミリーを構成するように作成しています。フォントファミリーでは、そのファミリーの名前を指定します。つまり、フォントファミリーを指定するということは、複数のフォントを一括して指定するという意味合いになります。
(2) フォントスタイル(font-style)
ファミリー中でnormal(通常)、oblique(斜めに傾けた形状)、italic(手書きに近い形)を指定します。
(3) フォントの変形(font-variant)
normal(通常)、small-capsを指定します。small-capsは小さめの大文字を指定します。ラテン文字のように小さめの大文字という使い方をもつ場合のみ有効です。
(4) フォントのウエイト(font-weight)
normal、bold、bolder、lighter、100~900で文字を構成する線の太さを指定します。
(5) フォントの字幅(font-stretch)
normal、wider、narrower、ultra-condensed~ultra-expandedで文字の幅を指定します。
(6) フォントの大きさ(font-size)
文字の大きさを指定します。
2.CSS2のフォント選択
CSS2ではこのように画面に表示したり印刷する時のフォントを、ファミリー名で指定して、さらにフォントの特性を指定するというやり方をとっています。
このようなやり方がうまく機能するには、フォントファミリーが、CSS2で定義しているような選択法にうまく適合するように作られている必要があります。
また、もし、指定したフォントファミリーの中に、うまく当てはまるフォントがないときに、代わりのフォントをうまく選択するフォントのマッチングという仕組みが必要になります。CSS2の仕様では、ブラウザなどで、ユーザが指定したフォントを選択するための仕組みを定めています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月11日
PDFとフォント(1) 書体、グリフ、フォント
次に、PDFのための必須の技術の中で、フォントについて説明してみたいと思います。私は、フォントについては、少しかじったくらいであまり詳しくありませんので、いろいろ調べながらできるだけまとめてみたいと思っています。間違いがありましたらご指摘いただければ幸いです。
フォントとはなにかということを簡単に整理してみたいと思います。ちょっと古くなりますが、日経バイトの1994年2月号(pp.247~260)のバイト・セミナーに沼尾 禮子・林 隆男氏の連名で「フォント関連用語を正しく理解する」という記事が掲載されました。
その記事では、書体とフォントを区別して次のように定義しています。
(1) 書体は「一連の文字や記号の1セットに対し、印刷や表示のために、美観などのコンセプトに基づいて統一的に施された意匠デザイン」。
(2) フォントは「同一書体を元にして作られた、すべてのファミリ、変形、サイズを含む一連の文字・記号の1セット」。
(3) 書体は抽象的概念で、それを具象化したのがフォントである。
次に、TR X 0003:2000 フォント情報処理用語の関連部分の定義を見てみますと、次のようになっています。
(1) 書体(type face)「表示などに使用するため、統一的なコンセプトに基づいて作成された、一組の文字などの意匠」
(2) フォント(font)「ある書体でデザインされた字形の集合」
(3) グリフ(glyph)「文字の可視化表現またはその構成部分から大きさ及び意匠を正規化した抽象表現(JIS X4161 ISO/IEC 10036)」
JIS X4161-1993 (pp.2-3)では次のようになっています。
(1) グリフ(glyph)「個々のデザインの違いを除去した認知可能な抽象的図記号」
(2) フォント(font)「基本デザインが同一であるグリフ像の集合」
さて、このブログでは、過去にグリフについて、
2006年01月13日 PDFと文字(22) – グリフとグリフセットで検討しました。そこでは、グリフとは、「文字を可視化した形状である」というPDF Referenceの定義に従うことにしました。
グリフとは抽象的なものか、それとも可視化した具象図形かという点に少し違いがありますが、概ね、次のようにまとめることができそうです。
・グリフとは文字を可視化した形状である。但し、リガチャのように複数の文字の連続を別の形状にして可視化する場合、複数の文字がひとつのグリフになり、アラビア文字のようにひとつの文字が複数(4つ)のグリフをもつものもあります。ですので文字とグリフは1対1対応とは限りません。
・書体とは意匠デザイン
・フォントとは、書体が同じグリフを集めたもの。
しかし、この定義は、大雑把過ぎて、実際に使うとなるとあまり役に立たないでしょう。次回、さらに、もう少し詳しく見てみたいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月09日
SVGの行方 キラーアプリケーションは何?
さて、SVGの未来について、アドビが関心ないとか、谷間のゆりとか否定的なことを書いてきましたが、ではSVGには未来はないのでしょうか?
SVGのファイル形式はPDFにかなり似ています。大雑把に言えば、SVGはPDFの代替手段であると言っても良いと思います。しかも、PDFと比べるとかなりシンプルになっています。
PDF仕様はPostScriptをベースにしていることもあり、ものすごく大きな仕様となっていて極めて扱い難いものです。これに対してSVGの取り扱いはPDFより遥かに簡単です。取り扱いし易いというのは、SVGのもつ、PDFにはない大きなメリットです。
ですから、使い方によっては、非常に大きな威力を発揮するように思います。
先日来お話しましたように、SVGが普及していないのは、技術的な問題というよりも政治的な問題が大きいと思います。こう考えますと、キラーアプリケーションを見つけることができればSVGにもチャンスが巡ってくると言えます。
どの辺にSVGのチャンスがあるのでしょうか?
(1) 現在は、SVG-Tinyが携帯電話へのデータ配信・表示に使われているのが最大の用途でしょうか?しかし、PDFやFlashが携帯電話に普及してきますと単なるデータ配信用途では太刀打ちできないような気もします。
(2) 第2は、日本で進んでいる地図の配信用です。これは、goSVG(g-contents over SVG)という、地図情報の配信をSVGで行うプロジェクトがあります。これは結構期待が持てるように思います。
(3) W3Cには、SVGPrintという仕様の草案があります。SVGPrintは、詳しく読んでいませんが、SVGを印刷用のページ記述言語(PDL)の代わりに使おうということのようです。まさしく、PDFの代わりにSVGを使おうということですね。この草稿2003年7月発表ですが、その後進んでいるのでしょうか?
ちなみに、アンテナハウスは、XSL FormatterでXMLをページアップした結果をSVGに出力するオプションを用意しています。また、サーバベース・コンバータでMicrosoft Officeドキュメント、PDFからSVGへの出力もできます。
私としては、将来、Web上でのページアップされた情報配信のメディアとしてPDFだけではなく、その代替手段としてSVGも候補になることを願っています。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年03月08日
SVGの行方は谷間のゆり ?
アンテナハウスの提携先でいつも中国語講座をしていただいている田中先生のすぐ話せて書ける“痛快中国語講座”。
ここに、次のような絵があります。

上の絵は、マイクロソフトのInternetExplorerで表示したものです。ところが、これをFireFoxで表示すると次のようになってしまいます。折角のイラストの部分が脱落してしまった状態で、正しく表示されていません。

この理由は、脱落する部分の画像がVML (Vector Markup language) というMicrosoft独自のベクトル画像(線画)形式で記述されているためです。VMLはFireFoxのようなブラウザでは表示することはできないので壊れた画像の絵がでてしまいます。
画像形式を大別すると、イメージ画像とベクトル画像に分かれます。このうち、ベクトル画像の標準形式としてW3Cが策定したのがSVG (Scalable Vector Graphics) なのです。
インターネットの線画標準の策定過程で、VMLはもともとW3CにWebの標準仕様案として、Microsoft、HP、AutoDesk、Visioの技術者の連名で1998年に提案されました。
Vector Markup Language (VML)
ところが、一方で、アドビシステムズ、IBM、Sun、Netscapeの技術者が、Precision Graphics Markup Language (PGML)という仕様案を提案してます。
このような2つの対立する提案の結果として生まれたのがSVGと言うわけです。このためかどうか、SVGはMicrosoftにはまったく見向きもされていません。MicrosoftはOfficeを初めFrontPageのようなWebページ・デザインソフトでも、依然としてVMLを使っています。しかし、VMLは標準仕様とは言えません。
一方のブラウザで正しく表示できるものが、他方のブラウザで正しく表示できないという問題は、このインターネットの標準を巡る2大陣営の戦いの帰結ということができます。
一方、SVGは、FireFoxでかなり(完全ではない)表示できますが、FireFoxのシェアはわずか5%内外でしょう。また、IEでもアドビのSVGビューアがインストールされていれば表示できます。そういう意味ではかなり普及していると言えるかもしれませんが、圧倒的なシェアをもつMicrosoft系のアプリケーションに無視されているということでは、標準仕様としては弱いでしょう。
そうして、昨日お話しましたように、アドビもあまり関心をもっていないということになりますと、まさに、SVGの将来は谷間のゆりになってしまうかもしれません。
インターネットにおける線画の表現形式の標準が普及していない、というのはユーザにとっては不幸なことではあります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年03月07日
SVGの行方は?
アドビのCEO Bruce Chizenのインタビューを読んでいて気になったことを、もうひとつ挙げます。
それはSVGの行方です。
SVGは、Scalable Vector Graphicsの略で、W3Cが制定しているWebなどで使うためのベクトル・グラフィックスの標準です。2003年にV1.1仕様が勧告となっています。
・SVG V1.1仕様
Scalable Vector Graphics (SVG) 1.1 Specification
W3C Recommendation 14 January 2003
SVGには、フルセットの仕様のほか、携帯などで使うためのSVG Tiny、SVG Basicなどのサブセットの規格もあります。
・SVGモバイル仕様
Mobile SVG Profiles: SVG Tiny and SVG Basic
W3C Recommendation 14 January 2003
SVG Tiny は携帯電話用のビューアとして使われることも多く、スウエーデンのIkivo ABの推定では、SVGビューアを搭載したモバイル機器が世界で950万台出荷されているとしています。
Over 60 Million Ikivo Powered Mobile SVG Handsets Shipped
現時点では、携帯電話用のビューアとしてSVG Tiny がFlashと並ぶ存在と言っても過言ではありません。
SVGの仕様策定にあたってはアドビの技術者の貢献が大きかったと思います。現在もアドビはSVG仕様の編集者を出していますし、SVG仕様はPDFと非常に似通ったところがあります。
現在の時点でもPC用のSVGV1.1ビューアとしては、アドビのSVGビューアが一番ポピュラーでしょう。
しかし、アドビのBruceのインタヴューではSVGは一言も出てきません。
SVG Tinyが携帯用ビューアの有力候補なのですが、アドビはSVG Tinyではなく、FlashLiteとPDFのセットで携帯に取り組むということです。そうすると、SVG Tinyはどうなってしまうんでしょう?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月25日
中国のOffice文書標準XML形式 UOFの動向
CICC(国際情報化協力センター)の主催で、「IT標準化技術交流セミナー」という日中関係者によるセミナが、1/18~1/20 に北京で催されました。そこで、文書フォーマットに関する分科会があり、中国の国家プロジェクトとして策定が進んでいるUOF (Uniform Office Format) のプレゼンテーションがなされたとのことです。
UOFについて以前に聞いていた話から、私は、UOFというのは中国政府が推し進めている国家的標準文書フォーマットと理解していました。しかし、今回の報告では、どうも外部文書形式を定義するだけではなく、UOFでは、文書処理系まで開発し、ユーザインタフェースの統一まで目論んでいるようです。
今回のプレゼンでは、UOFの処理系の開発技術者が出席して、UOFの処理系が動くところを実際に見ることもでき、直接いくらかの質問をすることもできたとのことです。〔興味深深〕
中国でのオフィス文書ソフトウェアのベンダは4社あり、それぞれの文書フォーマットが異なっているため、文書交換に難儀をしていた。そこで中国政府は、統一文書フォーマットを制定すべくUOFプロジェクトを立ち上げたという経緯です。この4社は独自にUOFを扱うソフトウェアを開発中であり、現在ほぼ標準的な機能は実装済みで、それぞれが同じ出力となるように試験中とのこと。Microsoft Office の 98%くらいできていると豪語したそうな。〔おおーー! OpenOffice.orgよりすごいぞ。〕
WindowsとLinuxで稼動しているとのこと、Windows版を見ることができたそうですが、見た目は、Microsoft Office と酷似していたようです。
文書フォーマットとしてはXMLであり、UOF用のスキーマが定義されているということ。UOFの出だしは次のような感じ。
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
<uof:UOF xmlns:uof="http://schemas.uof.org/cn/2003/uof"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:表="http://schemas.uof.org/cn/2003/uof-spreadsheet"
xmlns:演="http://schemas.uof.org/cn/2003/uof-slideshow"
xmlns:字="http://schemas.uof.org/cn/2003/uof-wordproc"
xmlns:图="http://schemas.uof.org/cn/2003/graph"
uof:locID="u0000" uof:version="1.0" uof:language="cn">
<uof:元数据 uof:locID="u0001">
<uof:创建者 uof:locID="u0004">user</uof:创建者>
<uof:作者 uof:locID="u0005">user</uof:作者>
<uof:创建日期 uof:locID="u0008">2006-01-19T17:24:06</uof:创建日期>
<uof:最后作者 uof:locID="u0006">user</uof:最后作者>
<uof:编辑次数 uof:locID="u0009">2</uof:编辑次数>
<uof:编辑时间 uof:locID="u0010">PT2M47S</uof:编辑时间>
<uof:用户自定义元数据集 uof:locID="u0016">
<uof:用户自定义元数据 uof:名称="信息1" uof:locID="u0017" uof:attrList="名称 类型" />
<uof:用户自定义元数据 uof:名称="信息2" uof:locID="u0017" uof:attrList="名称 类型" />
<uof:用户自定义元数据 uof:名称="信息3" uof:locID="u0017" uof:attrList="名称 类型" />
<uof:用户自定义元数据 uof:名称="信息4" uof:locID="u0017" uof:attrList="名称 类型" />
</uof:用户自定义元数据集>
<uof:页数 uof:locID="u0020">1</uof:页数>
<uof:段落数 uof:locID="u0025">1</uof:段落数>
<uof:字数 uof:locID="u0021">1</uof:字数>
<uof:对象数 uof:locID="u0026">0</uof:对象数>
</uof:元数据>
<uof:式样集 uof:locID="u0039">
<uof:字体集 uof:locID="u0040">
<uof:字体声明 uof:locID="u0041" uof:attrList="标识符 名称 字体族" uof:标识符="Tahoma" uof:名称="Tahoma" uof:字体族="Tahoma" />
<uof:字体声明 uof:locID="u0041" uof:attrList="标识符 名称 字体族" uof:标识符="宋体" uof:名称="宋体" uof:字体族="宋体" />
<uof:字体声明 uof:locID="u0041" uof:attrList="标识符 名称 字体族" uof:标识符="Times_New_Roman" uof:名称="'Times New Roman'" uof:字体族="'Times New Roman'" />
</uof:字体集>
<uof:自动编号集 uof:locID="u0042">
<字:自动编号 uof:attrList="标识符 名称 多级编号" uof:locID="t0169" 字:标识符="缺省章节大纲级别式样">
<字:级别 uof:attrList="级别值 编号对齐方式 尾随字符" uof:locID="t0159" 字:级别值="1" 字:尾随字符="none">
<字:编号格式 uof:locID="t0162">decimal</字:编号格式>
<字:编号格式表示 uof:locID="t0163">%1</字:编号格式表示>
<字:缩进 uof:attrList="左缩进绝对值 左缩进相对值 首行缩进绝对值 首行缩进相对值" uof:locID="t0165" 字:左缩进绝对值="0" 字:首行缩进绝对值="0" />
</字:级别>
【某氏コメント】
・世界的な仕様にしようとしているようだが、XMLのタグは中文である。こんなのが世界仕様になるわけがないと思うが、中国人は世界中の人が扱えると考えているのだろうか。
・文書構造とスタイルは分離していない。WordMLと同様に、このXMLはどうレンダリングされるべきかが決まっている。
・ルートタグに uof:language="cn" という属性がある。 languageだから、当然ISO-639の言語コードでしかるべきだが、cn はISO-3166の中国の国名コードだ。ちなみに、中国語の言語コードは zh または zho である。
・すべてのUnicodeを扱えると言っているが、表現できる文書には基本的に中文のことしか考えていない。現在の版でできるのは、中文の他には日本語と韓国語くらいであるが、日本語の禁則処理ができるかは疑問である。英文にしても、ちゃんと組めるとはお世辞にも言えない。
(以下省略)
〔世界的な仕様ですか?なにかの間違いじゃないの?でも、漢字タグが世界標準仕様になったらって、想像するだけでも愉快だよね。〕
※文中〔 〕内は、私の感想。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月15日
PDFと文字(4) – 文字の取り扱い
さて、言語の文字による表現には様々な方法がありますが、例えば、次のような観点で分けてPDFでの扱いがどうなるかを概観してみましょう。
(1)プレーンなテキストとしての文字表現
(2)タイプセッティング、日本語では文字組版
(3)カリグラフィー、書道、あるいは超組版
(4)イラストレーション
まず、テキストとしての文字です。コンピュータ関係者はテキストというとバイナリとの対比をすぐに思いつきます。
ちなみに「テキスト バイナリ」をキーワードにしてGoogleで検索してみると:
[9] テキストとバイナリ - インターネットメールの注意点では「文字コードだけを使ったものをテキストといいます。」と言っています。これはちょっと乱暴すぎるのでは?文字コードってなに?
バイナリファイルとはなにか --- テキスト以外のファイルのことであるでは、「テキストとは、バイトの並びをアスキーコード等を使って文字の並びとして解釈したものです。」と言っています。うん、説明に苦労していることがわかります。
ファイルの保存形式についてでは、「テキスト形式ファイルは、画面に表示できる文字と改行やタブなどのいくつかの特殊文字だけで構成されます。」と説明しています。例えば、電子メールが文字化けして表示されることが時々ありますが、このように画面上で文字化けして表示されてもテキストなのかな?
というような具合でテキストという言葉を説明するのはそんなに簡単ではありません。実際のところ、テキストという言葉はうまい日本語がないように思います。明治の初めに活躍した福沢諭吉のような人なら、漢字をつかったうまい日本語を作るのでしょうが、今は、漢字をあてはめて造語するのではなく、英語のカタカナをそのまま日本語にしてしまうからでしょうね。で、日本語の意味を知るのに、英和辞典を引く、という変なことになってしまうのですが、諦めて英和辞典を引いてみると、「本文、原文」などとあります。これもちょっと違うように思います。
そういうわけで、ここでは、勝手な定義としてテキストとは、飾りのない本文文字のみで構成されるデータと言っておきます。さて、そうするとテキストはPDFでは次のような扱いができます。
①ビューアなどで検索対象になる
②ビューアなどで範囲を指定してコピーして、他のアプリケーションに文字列として貼り付ける
③テキスト抽出機能で文字列として取り出す アンテナハウスのTextPorterとかリッチテキストPDFなどを使って :-)
実は、PDFで表示される文字の中には、テキストとして扱うことができるものと、テキストとして扱うことができないものがあります。
AdobeReaderなどのPDFビューアで文字として見えていても上で述べたようなテキストとして扱えるとは限りません。テキストとして扱うためには、PDFファイルの中にそのための設定データがなければならないのです。
では、どういう時にテキストとして扱うことができて、どういう時にできないでしょうか?これにきちんと回答するのは、現時点ではとても難しくて泥沼にはまりそうなので、とりあえず、AdobeReaderの、![]() ツールで範囲を指定してコピーできれば、テキストとして扱えるとしておきます。範囲を指定しようとしてもカーソルが滑ったようになってしまって範囲を指定できなければ文字として見えていてもテキストとしては扱えません。
ツールで範囲を指定してコピーできれば、テキストとして扱えるとしておきます。範囲を指定しようとしてもカーソルが滑ったようになってしまって範囲を指定できなければ文字として見えていてもテキストとしては扱えません。
上の説明は、堂々めぐり、あるいは、ツールの動作で仕様を説明するという、実際、あまり好ましくない説明とは思いますけれど。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月14日
PDFと文字(3) – 言語と文字 その3
簡体字は中華人民共和国の漢字簡単化政策によって作り出されたもの、という話をしましたが、このように文字は政治や経済と密接な関係があります。
その際立った例をいくつか紹介してみましょう。
まず、イスラエルの国語である現代ヘブライ語があります。
ヘブライ語は、もともと古代パレスチナ人が使っていた言葉ですが、2000年以上前に誰も使わなくなってしまったものです。現代ヘブライ語は、いったん誰も使わなくなった言語をイスラエル建国の際に復活したものです。このヘブライ語を書き表すために使う文字がヘブライ文字です。
ヘブライ語
ベトナム語は、現在は、ラテンアルファベットに文字種を追加した文字で記述されています。この文字は19世紀にフランスの宣教師が考案したものらしいです。東南アジアの南方はインド文化の影響を受けているようですが、ベトナムとはもともと「越南」の読みなのだそうで、ベトナム語は漢字の偏旁を独自に組み合わせて作ったチュノムで表記されていたようです。
ベトナム語
ところで「三国志」では蜀の諸葛孔明が何度か南方遠征をしますが、ベトナムまで行ったのでしょうか?
フィリピンの公用語のひとつであるタガログ語も昔はインド起源の文字を用いていたようですが、現在は、ラテンアルファベット表記に変わっています。
タガログ語
政治的理由から比較的短い期間に、文字政策が変わった地域もあります。例えば、新疆ウイグル自治区は、1949年に人民政府に帰順して中華人民共和国の一部になりました。その当時は、ソ連と中国の蜜月時代ということもあり、ウイグル語をキリル文字で表記しようとしたそうです。ところが、中ソ緊張の時代になるとともにキリル文字はあっさり解消、次は、漢字のピンイン法案によりラテン文字表記をしようとしました。その後、1982年になって元のアラビア文字に基づく表記にもどったそうです。
中国・新疆ウイグル自治区における文字と印刷・出版文化の歴史と現状(菅原 純)
いままでお話しましたのは、ごく一部の言語の例です。世界には、数千種類(一説には6000種類)といわれる言語があります。
それぞれの言語は表記方法である文字がなければ記録として残すことができません。ですので表記の手段として文字をもつということは、その言語の文化を伝え、あるいは遠くの人と意思を伝えていくために大変重要なものです。
PDFは紙に表記された情報を電子的化するものですので、PDFでもこのような様々な文字を扱えなければなりません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月13日
PDFと文字(2) – 言語と文字 続き
昨日、漢字のお話をしました。漢字は中国で生まれ、中国の文化と共に周辺の国に渡って、その国の言語を表記するのに使われるようになったということはご存知のことと思います。
漢字と同じように、文化圏の広がりと共に周辺地域に普及し、その地域の言語表記に使われるようになった文字にアラビア文字があります。
アラビア文字とアラビア語を英語で表すといづれもArabicとなるため混同し易く、よく間違えますが、この二つは別の概念です。間違えないように使い分けないといけないですね。
アラビア語は聖典クルアーンの言語として、世界各地のイスラム教徒に親しまれています。このイスラム教とアラブ文化圏の広がりに伴い、アラビア文字はペルシャ語(イラン・イスラーム共和国)、ウルドゥ語(パキスタン)、現代ウイグル語(中国新疆ウイグル自治区)などの表記にも使われています。アラビア文字の場合も、ラテンアルファベット同様に、アラビア語以外では、その言語特有の音を表記するための文字・記号類が追加されています。
アラビア系文字
「アラビア系文字の基礎知識」
キリル文字もロシアをはじめスラヴ系の多数の言語の表記に使われています。ソヴィエト連邦の解体にともない、キリル文字で表記していた言語の中でラテン文字表記に変更しているものもあるようです。このように表記する文字を変更することは世代間のコミュニケーションに深刻な問題をもたらす可能性があります。
キリル文字(フリー百科事典『ウィキペディア(Wikipedia)』)
東南アジアのタイ語、ラオス語、カンボジア語は、それぞれ特有の文字( タイ文字、ラオス文字、クメール文字)で表記されます。日本語のひらながとカタカナは50音というくらい、音節と文字が一対一の関係があります。これに対して、タイ語、ラオス語、カンボジア語では、発音の音素と文字字形(グリフ)が一対一に対応せず、並び時も発音順でないという複雑な関係になっています。
タイ語,ラオス語,カンボジア語(クメール語)の文字処理と組版における課題
東南アジア大陸部のインド系文字
インドには850~1700の言語があるようですが、その中でもヒンディー語は人口の約4割で使われているとのこと。ヒンディー語を表記するのに使われているのがデーヴァナーガリー文字です。この文字は、組み合わせによる表示形の変化(リガチャ)の種類が極めて多いため、コンピュータ処理の難関といえます。
インドの言語と文字
デーヴァナーガリー文字
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月12日
PDFと文字(1) – 言語と文字
さて、PDFは紙を電子化したものなので、紙の上に表現できるあらゆる情報を表現することができます。それらの情報の中で、特に、文字がPDFでどのように取り扱われているかを、これからしばらくの間、お話してみたいと思います。
文字とはなんでしょうか?こういう哲学的、大上段に構えた質問をしてしまうと、なかなか答えることが難しいものですね。そこで、少し、具体的に考えて見ましょう。
私たち日本人は、日常会話では日本語を話し、そうして日本語で書かれた新聞、雑誌、書籍、インターネットのページ、ブログページを書いたり読んだりしています。このような日本語の記事は、漢字、ひらがな、かたかな、句読点、括弧類などの記号を使って表記します。
ここから類推して、簡単に言えば、言語を表記するツールが文字であると考えて良いと思います。
長い年月でみれば、特定の言語の表記に使う文字の種類はかなり変遷します。例えば、江戸時代より以前、墨と筆で文字を書いていたときは、恐らく句読点や括弧類はなかったのでしょう。句読点が定着したのは明治三九年、文部大臣官房図書課が『句読法案』を発表してからのことなのだそうです。
句読点研究会
最近の携帯電話には、いろいろな絵文字が登録されています。このような絵文字が市民権を得て、皆が使う日がいづれ到来するのでしょうか?あるいは廃れてしまうのでしょうか?このように文字と認めて良いかどうか、意見が分かれる記号も沢山あります。
英語は、26種類のアルファベットの大文字と小文字、カンマ、ピリオド、感嘆符、引用符などの記号類を使って表記します。
フランス語ではアクセントを多用するため、26種類のアルファベットでは足りず、Accute accent, Grave accent, Circomflex accent, Diacresis, Cedillaの5種類のアクセントをつけた15文字を追加して使います。括弧記号も英語とは違います。
ドイツ語は、26種類のアルファベットに加えて、ドイツ語特有のウムラウト付き文字 (A with diacresis, O with diacresis, U with diacresis) とエスツェット (Sharp S) を追加しています。
お隣の韓国・北朝鮮の言語は朝鮮語ですが、現在は、ハングル文字による表記が主流です。ハングル文字は、1443年に発明された比較的新しい文字で、それ以前は朝鮮語の表記は漢字によっていたようです。
朝鮮語
漢字の本家、中国では、漢字簡易化政策の下に1950年、1960年代に漢字を簡体字にしてしまいました。このため、漢字には、現在、大陸で使われている簡体字と、台湾を中心に使われている繁体字の2種類があります。
「近現代中国における言語政策」 藤井 久美子 2003年2月23日 株式会社三元社発行
コンピュータの世界で、CJK文字といえば漢字のことを言うのですが、現在は、このように日本、中国、韓国の漢字事情は、それぞれ相当に異なっています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月04日
Microsoft XPSでPDFに対抗 (4) – XPS仕様(続き)
では、XML Paper Specification(XPS)とは、どのようなものでしょうか?
XPSの仕様書をざっと見てみましょう。まずXPSドキュメントの基本構成要素はFixedPage パーツです。FixedPageの概要は次のようなもので、要するにPDFまたは紙の1ページに相当します。
①FixedPageにはページ上に可視化するすべての視覚的要素、すなわちグラフィックスとテキストを含む。
②各ページは大きさと方向をもち、ページ上のレイアウトは決定済。
FixedPageをいくつかまとめるとFixedDocumentができます。このFixedDocumentに順序をつけて束ねたものがXPSのドキュメント本文パーツ(FixedDocumentSequence Part)となります。要するに紙を束ねた書類がドキュメントの本文パーツということです。
XSPドキュメントのパッケージには、本文パーツ以外に、①サムネイル・パーツ、②プリント・チケット・パーツ、③注釈パーツ、④フォント・パーツ、⑤イメージ・パーツがあります。
たとえば、本文パーツが使用しているフォントは、フォント・パーツにその実体をもちます。そしてXPSドキュメントの中にパッケージ化されます。これにより、XPSドキュメントを配布したとき、相手先のPCでは、生産者が指定したフォントがなくても、XPSドキュメントを指定どおりのフォントを使って印刷できることになります。
イメージを本文とは別のパーツにしているのは、本文で同じイメージを何回も使うとき、別のパーツとしてのイメージを参照することで、イメージの実体を一つだけもてば良いからです。
現在までに、Microsoftと協力してMetroの開発を行ってきた会社の殆どはプリンタ・メーカとプリンタ・メーカ向けにWindows用のプリンタ・ドライバの開発を行っているソフトウエア会社です。これは、Metroが従来のGDIベースの印刷サブシステムがもつ弱点を乗り越える新しい印刷パスとしての位置づけで開発されてきたといういきさつがあるからだろうと思います。
しかし、XPSの仕様書をみると、XPSは単なる印刷システム用のスプールファイル形式ではなく、紙に類似する用紙を定義し、その上にレイアウトされたドキュメントを配布するための機能を持っています。しかも、フォントの埋め込をすることもできますし、サムネイル、リンク、注釈などの機能ももち、限りなくPDFに近くなっています。
少なくとも、XPSはPDFに競合する使い方を意図して設計されているということはできるでしょう。
【参考資料】
XML Paper Specification
XPS と、Windows Vista でのカラー印刷の拡張機能
投稿者 koba : 08:00 | コメント (2) | トラックバック
2005年12月03日
Microsoft XPSでPDFに対抗 (3) – XPS仕様
Metroの仕様書0.7版は、「Open Packaging Conventions 0.75版」(OPC)と「An Open XML Paper Specification 0.75版」(XPS)に分割されました。
0.75版で仕様書を二つに分割した目的は、OPCの適用範囲を、XPSのみではなくMicrosoft Office12のXML文書などにも広げるためでしょう。つまり、XPSというのは印刷形式のファイルですが、それだけではなくOffice12のネイティブなXMLファイルまでOPCを使うことになりそうです。
OPCの仕様書では、情報の生産者と情報の消費者の間で、情報の内容や情報源をどうやってひとまとめに(パッケージ化)して受け渡すかを決めています。パッケージを作り出す生産者は、インターネット上のサーバ、LAN上のサーバ、デスクトップPCなどであり、パッケージを使う消費者は、デスクトップPC上のビューアや、LANやデスクトップPCに接続したプリンタにあたります。
パーツという基本構成要素をまとめてパッケージを作ります。例えば、XMLを使って外部の画像を参照するテキスト文書を作成するとき、テキスト部分がひとつのパーツ、画像がもうひとつのパーツになります。これを一まとめにしたものがパッケージです。
あるパーツからは、パッケージ内部のパーツのみでなく、外部のパーツも参照できます。パッケージには参照関係をまとめて定義する関係部もあります。
パッケージ全体はZIPで圧縮されて受け渡します。
OPC仕様の特徴は次の点です:
①パッケージのパーツや関係部の記述などすべてXML仕様に準拠している。
②消費者がパッケージを開けてみなくても内容がわかるようなサムネイルを付けることができるようになっていること。
③パッケージに対してデジタル署名を付けることができること。パッケージ全体はXMLで記述されますので、デジタル署名にはXML シグネチャを使います。
XMLでドキュメントを作成すると、外部参照している画像ファイルなど多数のファイルに分かれてしまうため受け渡しの際の管理が面倒、という問題があります。このOPCはXMLドキュメントの受け渡しのためのパッケージ化にも使えるかもしれませんね。
ところで今日のお話には、PDFが一回も出てきませんでした。代わりにXMLがいっぱい出てきて閉口した人もいるかもしれません。PDFとXMLというのは相異なる目的で生まれてきたものなのですが、しかし、現在は両方ともデータとドキュメントの表現には欠かせないものとなってきています。いづれ、PDFとXMLの関係について、まとめてお話したいと思いますので、ご勘弁ください。
【参考資料】
Open Packaging Conventions:Specification and License Downloads
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年11月30日
Microsoft Officeの文書形式
Microsoft Officeの文書形式は、Office2003では一部がXML形式となったことは、既にお話しました。
(1)Word文書のXML形式のWordProcessingMLは、完全にWord文書の内容とレイアウトを再現することができます。これは、Microsoft Wordの文書交換用形式として使われてきたRTF形式をXMLで書き直したものということができます。
これに対して、
(2)Excel文書のXML形式であるSpreadsheetMLは、基本的な表形式のデータを表現することができるだけです。Excel文書をSpreadsheetMLで保存しますと、Excel文書に埋め込まれた画像、シェイプといわれる図形、あるいはチャートなどは消えてなくなってしまいます。
また、(3)PowerPoint文書のXML形式は発表されていません。
Microsoftは、Office12ではこれをさらに進めて、Microsoft Office Word、Excel および PowerPointの文書をXML形式にすると発表しています。
6月7日 マイクロソフト、XML を次期 MS Office の既定ファイルフォーマットとして採用することを発表(日本語)
6月1日 Microsoft "Office 12" XML File Formats to Give Customers Improved Data Interoperability and Dramatically Smaller File Sizes(英文:上記日本語の原文)
さらに、11月22日になってMicrosoftは、OfficeのXML形式を情報とエレクトロニクスの技術標準化団体であるEcma Internationalに提出するという発表をしました。
Microsoft Offers Office Document Formats to Ecma International for Open Standardization
Office12のXML文書形式は、Microsoft Office Open XML文書形式という名前になるようですが、まず、Word、Excel、PowerPointの文書形式をEcma標準とし、つぎに、EcmaからISOに提出してもらってISOの標準にするつもりのようです。Microsoftにはアップル、インテル、日立などの関係者が賛同していますので、アンチSun連合を結成して対抗していこうということでしょう。
OfficeのXMLアーキテクチャJean Paoliのインタビューもあります。
Q&A: Microsoft Co-Sponsors Submission of Office Open XML Document Formats to Ecma International for Standardization
これを読むと、次のようなくだりがあります。
Jean Paoliのインタビューの中から引用:
The Office Open XML file formats will provide 100 percent of the functionality of the binary formats, as well as total backward compatibility through all past versions of Office.
つまり、バイナリ形式の機能を100%提供するとともにすべての過去のバージョンへの後方互換性も提供すると。
そうすると、今度はExcel文書をXML形式で保存しても情報が脱落することはなくなり、これまで、できなかったPowerPointも完全にXMLで保存できることになります。一般には文書をPDFファイルとして保存してしまいますと、再利用が困難になりますが、XML形式であれば比較的簡単に再利用できますし、情報の交換という用途では、PDFの新しい強敵が表れるとも言えます。
Office文書の形式をめぐる主導権争いは、PDF、XML形式を含めて、ますます熾烈になっていくようです。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2005年11月29日
OpenOffice文書形式を標準化
OpenOffice.org(以下、OpenOffice)とMicrosoft Officeの文書ファイル形式をめぐるせめぎ合いも熾烈です。OpenOfficeは当初から文書ファイル形式をXMLを使って定義し、情報を公開していました。それにとどまらず、Sunはe-ビジネスの標準化を推進する非営利団体OASISにOpenOfficeの文書形式を標準仕様として提唱しました。
OASISでは
OASIS Open Document Format for Office Applications (OpenDocument) TCというOfficeの文書形式標準化委員会を設定して、審議を行ったうえ、2005年1月に「Open Document V1.0」を標準形式として承認しました。ところで、この委員会の議長も書記もSunのメールアドレスになっています。これをみれば、標準化の推進にはSunの息がかかっていることは一目瞭然でしょう。
続いて、この仕様は国際標準化機関ISO JTC1に提議されています。
仕様書はこちらで入手できます:
OpenDocument v1.0 specification PDF形式
OpenDocument v1.0 specification OpenOffice形式
これに対し、MicrosoftもOffice2003でWord、EXcelのXMLファイル形式をそれぞれ、WordProcessingML(略して:WordML)、SpreadSheetMLとして設定しています。
Office2003のXMLファイル形式に関するWebページ:
Office 2003 XML リファレンス スキーマ
WordMLに関してはこちらの解説もご参照ください:
XMLに関連したWord 2003の機能(第9回多言語組版研究会資料)
ワープロソフトや表計算などのソフトウェア製品は、MicrosoftやSunなど、それを開発した会社が知的所有権を有するものであることは皆が認めるところです。これに対して、ワープロソフトや表計算で作成したデータは、本質的には、ユーザが知的所有権を有するもののはずです。しかし、これまでは、文書ファイル形式がバイナリになっていたこともあり、あまり、そのことに関する意識が高かったとは言えません。
ところが、XMLで文書ファイル形式を定義できるようになったこと、また、文書の作成手段が完全に電子化したことなどにより、特に、文書ファイルをユーザの手に取り戻そうという要求が高まってくるでしょう。この動きは、まず、欧州連合(EU)、あるいはマサチューセッツ州から始まっていますが、徐々に全世界に広がっていくと見られます。
Officeスイートの文書ファイル形式をXMLで定義する動きはOpenOfficeが先鞭をつけたと言えます。OpenOfficeはPDFネイティブ保存でも、Microsoft Officeに先行しています。このようにOfficeスイートの文書形式に関する動きを主導しているのはMicrosoftよりもむしろOpenOfficeであると言えるでしょう。