2008年07月02日
頼みの綱のフォント(Last Resort Font)
UnicodeのWebページに「頼みの綱のフォント」(Last Resort Font)が公開されています。
これは自動組版などで、指定したフォントでは、あるUnicode文字を表すためのグリフ(文字の形状)がないとき、代わりに表示するためのグリフを集めたフォントです。
通常はフォントに文字がないとMissing Glyphになって、どういう文字が表示されるかは分からないことになります。Missing Glyphになったとき、この「頼みの綱のフォント」が使われるようにすると、グリフのない文字コードにどんなフォントを指定すれば良いか分かるようになるでしょう。
Unicodeの「頼みの綱のフォント」は、文字のブロック毎にそれを代表する文字(例えば、基本ラテンではA、CJKは字(図))とその周囲の帯でデザインされたグリフ234種類と、未定義を示すグリフ1、文字ではないコードであることを示すグリフ1の合計236種類からなっています。

もし、頼みの綱のフォントのグリフが使われたとき、そのグリフを見ますと文字の種類が分かりますので、どのようなフォントを指定すると事態が改善されるかが分かるということが狙いです。
なかなか良いアイデアのように見えます。
少しだけためしてみました。
まず、LastResortフォントをインストールします。
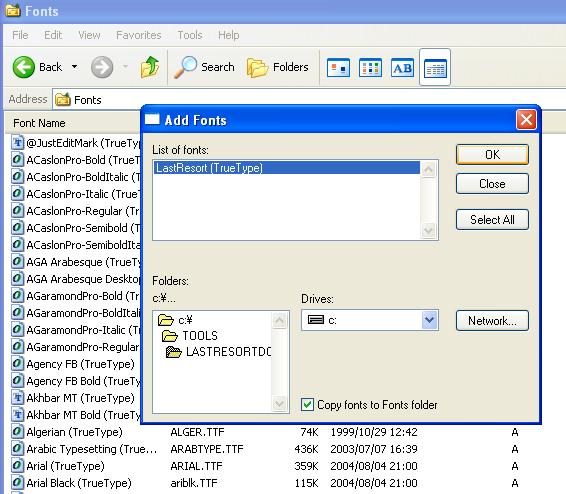
例えば英語、日本語、韓国語を含むFOを作成します。
そして、font-family="Arial, MS ゴシック, Batang, LastResort"を指定したブロック(上)と、font-family="Arial, MS ゴシック, LastResort"を指定したブロック(下)を作ります。
上のブロックは、Batangフォントが韓国語(ハングル)のグリフを持ちます。下のブロックでは、韓国語のグリフをもつフォントを指定していません。
それでFormatterで組版してみました。
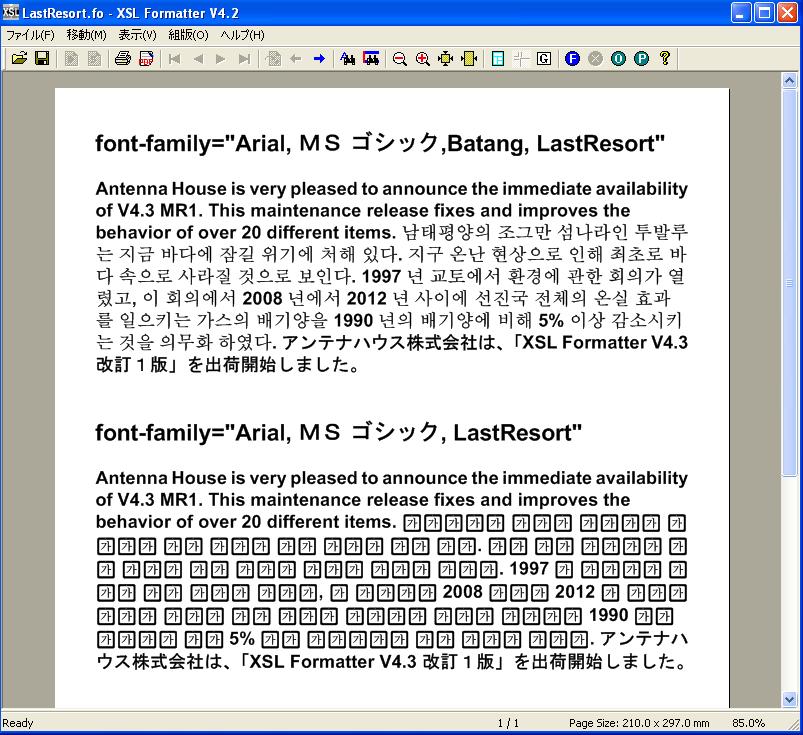
上のように、韓国語(ハングル)のグリフのない部分では、Last Resort フォントが使われます。これにより、ハングルのグリフを持つフォントを指定しなければならないことが分かるようになります。
【ご注意】念のため補足します。XSL Formatterのフォント選択は、文字単位ではなく、スクリプト単位になっています。上の例のように、スクリプトが異なる(ラテン-かな&CJK-ハングル)場合はうまく行きますが、例えば、かな&CJKの中だけで、Missing Glyphに、Last Resort フォントを適用させるのは旨く行かないはずです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年11月01日
外字(表外字)(3)
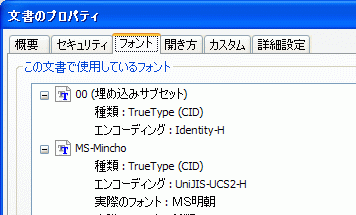
Antenna House PDF Driver で外字を埋め込んだ PDF のフォント情報を Acrobat 8 で確認(※)するとフォント名が「00(埋め込みサブセット)」と表示されますが、Acrobat 8 Pro で出力した PDF では「EUDC(埋め込みサブセット)」と表示されます。なぜこのような違いが生じてしまうのでしょうか。
※ Acrobat 8 の「文書のプロパティ」-「フォント」タブで確認します。
・Antenna House PDF Driver V3.2
・Acrobat Distiller 8.1.0
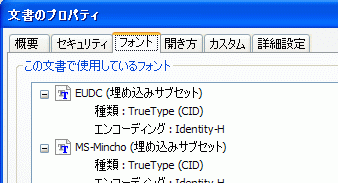
PDF の仕様では、フォント内の name テーブルに PostScript 名が存在すればそれを使用することが推奨されています。EUDC フォントは、フォント内の name テーブルに PostScript 名が「00」と定義されていますので、Antenna House PDF Driver はそれを PDF に使用しています。一方、Acrobat が出力する PDF はこのフォント内に定義されている PostScript 名を使用していないために「00」とならず「EUDC」と表示されているようです。それでは、どこを参照しているでしょうか。EUDC フォントの name テーブルで「EUDC」と定義されているのは、Font Family Name(Name ID = 1)か Full Font Name(Name ID = 4)の2箇所ですので、恐らく Acrobat はこのいずれかを参照していると思われますが、どちらかまではわかりません。
■ これまでの記事
・2007年08月04日 外字(表外字)
・2007年08月09日 外字(表外字)(2)
投稿者 numata : 08:00 | コメント (0) | トラックバック
2007年08月09日
外字(表外字)(2)
外字の話の続きですが、実際に Antenna House PDF Driver がどのように外字を PDF へ出力しているのかを簡単に説明します。
ユーザが各々の環境で作成する EUDC フォントは他の環境に存在することは通常ありませんので、Antenna House PDF Driver は Unicode のコードポイントからそのグリフを外字と判断した場合、自動で PDF にフォントを埋め込みます。EUDC フォントは TrueType 形式のフォントファイルですので、ここからは通常の TrueType フォントを埋め込むのと同じ手順となります。
まず、フォントファイルからグリフのアウトラインデータを取得して PDF 埋め込みますが、PDF の本文内ではグリフ番号だけになり、文字コードによる検索ができませんので、ToUnicode CMap を作成して、フォントに付加します。これで外字を検索することができるようになります。
ToUnicode CMap については、2006/5/18 のブログをご覧ください。
PDFからテキスト抽出のために ToUnicode CMap
投稿者 numata : 08:00 | コメント (0) | トラックバック
2007年08月04日
外字(表外字)
外字を作成することで使用するフォントに定義されていない文字を独自に登録して使うようにすることができます。Windows では Windows 付属の「外字エディタ」で EUDC(エンドユーザ定義文字、End-user-defined characters)としてあらかじめ定められた領域にグリフを定義することができます。
この定められた領域とは、Unicode では PUA(Private User Area:U+E000 - U+F8FF)領域であり、この先頭の一部範囲が Shift-JIS の [F040 - F9FC] に対応します。
さて、「外字エディタ」でグリフを作成した場合、そのグリフは EUDC フォント(EUDC.tte)に格納されます。これは TrueType 形式のフォントファイルです。
「外字エディタ」には作成したフォントの使用方法を指定する、「すべてのフォントにリンクする」「指定したフォントにリンクする」というオプションがあります。前者はデフォルトの EUDC フォントになります。「指定したフォントにリンクする」とは、特定のフォントと EUDC フォントを対応付けて、デフォルトの EUDC フォントに定義されている外字より優先して使用されます。これらの対応は、レジストリの [HKEY_CURRENT_USER\EUDC\932] に定義されます。デフォルトの EUDC フォントは次のように定義されています。
"SystemDefaultEUDCFont"="C:\\WINDOWS\\fonts\\jeudc.tte"
「指定したフォントにリンクする」の場合、たとえば「MS 明朝」に他の EUDC(kakunin.tte)を使用するようにすると次のように定義されます。
"MS 明朝"="C:\\WINDOWS\\Fonts\\kakunin.tte"
このように定義されている場合、「外字エディタ」で U+E000 に なんらかのグリフを作成し、kakunin.tte として、保存してあれば、「MS 明朝」で U+E000 の文字を使用した場合、kakunin.tte に定義した文字が表示されます。
投稿者 numata : 08:00 | コメント (0) | トラックバック
2007年02月12日
日本語の文字についての用語について(11) — 字体と書体 再考
昨日(11日) 第5回もじもじカフェ「正字体の正体とは?!」で、大熊 肇さんの話を聞きました。お話の内容は、全体としても大変興味深いものでしたが、特に、「字体」と「書体」について、大熊さんのお話をお聞きしながら、いままで考えていた定義が偏っていたことに気が付きました。まったく、眼から鱗が落ちる思いとはこのことかと。
2007年01月11日 日本語の文字についての用語について(1)で、「表外漢字字体表」の字体と書体の定義を紹介しました。
この表外漢字字体表の考え方は一言で、字体は抽象的な文字の骨格であり、字体を統一的スタイルでデザインして具体化したものが書体である、というものです。これは、常用漢字表の考え方を踏襲しています。
また、JIS文字規格は字体をまず考え、包摂する異体字を含めて、コードポイントを与えるもの。いわば、字体中心と言えると思います。
つまりこうした考え方は、抽象的な概念である字体がまずある、という考えに基づくもののように思います。少なくとも私は、そう思っていました。
ところがそうじゃない、ということなんですね。漢字の生い立ちから遡って考えるとどうも違うのではないかということなのです。
現代の印刷書体は、明朝体、ゴシック体、教科書体というような書体に分類されます。
これに対して、もじもじカフェで大熊さんは、最初に、正書体、行書体、草書体について次のように説明されました。
・正書体 — 石碑などに彫るかしこまったものにつかう書体。秦の篆書、漢の隷書、唐の楷書を指す。
・行書体 — 日常の筆記体(通行体)
・草書体 — 省略体。草書の字体は、前漢の時代に発生した。
そして、唐の時代に作成された楷書の字体が正字体というものだそうです。
このあたりで、どうも書体についての考え方がかなり違う、ということをなんとなく感じました。
大熊さんは書家ですので、お客さんから、字体を示されて特定の書体で書いてほしいという依頼を受けるそうですが、ところが要望に応えることのできない文字が偶にあるのだそうです。つまり、ある字体を隷書で書いて欲しい、という依頼があっても、その字体を隷書で書くと、まったくおかしなもの、つまり、そのような隷書の文字は存在していなかったもの、あるいはまったく格好悪いものになってしまう、というお話をされました。
その話を聞いていまして、「表外漢字字体表」の書体の定義は、どうもそういう現実から考えると、逆じゃないか?ということに気が付いたわけです。書家的には、あるいは、歴史的には、まず、書体があるのですね。つまり、格好よく文字を書く、あるいは、その時代の政治的な意図で、まず書体ができ上がり、その書体向きの字体が固定化した、という考え方になるのだろうということです。現実的にはこちらの方が妥当なように感じました。
【参考資料】
・TONAN's Web
・字体・字形・書体・字種
投稿者 koba : 08:00 | コメント (3) | トラックバック
2007年01月30日
文字コード — 符号化文字集合と符号化方式
たまたま、フリー百科事典『ウィキペディア(Wikipedia)』の「テキストファイル」の項を見ていたら、文字コードという項がありますが、内容に訂正する方が良いと思われる箇所があります。
「また、英数以外の文字は言語ごとに異なる文字コードが使われているため、英語以外の複数言語を混在させることは。。」
「日本語では次の3種類の文字コードがあり、文字化けなどの問題が多発する原因となっている。」として、ISO-2022-JP、Shift JIS、EUC-JPを挙げています。
次に、「Unicodeは、日本語も含めた世界中のすべての文字を1つの文字コードで表すための規格である。Unicodeが広く普及することで、英数字以外の文字を扱うときの互換性を高め、また多言語が混在する文書が容易に作成できるようになることが期待されている。
しかし、現在のUnicodeは普及途上ということもあり、新しい文字コードがさらに増えたことにより混乱が増している一面もある。」
上の説明の中の問題を挙げます。
1.文字と言語を明確に区別していない
例えば、英語はラテンアルファベットを使って記述しますが、フランス語やドイツ語もラテンアルファベットを使って記述します。
アラビア語はアラビア文字を使って記述しますが、アラビア文字で表す言語には、他にペルシャ語、ウルドゥ語(パキスタン)、現代ウイグル語の表記にも使われます。
このあたりは、以下を参照してください。
2005年12月12日 PDFと文字(1) – 言語と文字
2005年12月13日 PDFと文字(2) – 言語と文字 続き
つまり文字と言語は1対1ではありません。但し、文字コードは20世紀には標準化が国単位で行われたため文字コードと言語が1対1対応になる傾向がありました。
2.符号化文字集合と符号化方式を明確に使い分けていない
・ISO-2022-JP、Shift JIS、EUC-JPは符号化方式の種類です。
・Unicodeは符号化文字集合の名前です。Unicodeの符号化方式としては、UTF-8、UTF-16などがあります。
ですので、ISO-2022-JP、Shift JIS、EUC-JPに対してはUTF-8、UTF-16などを対比させる必要があります。
符号化文字集合と符号化方式については、同じWikipediaの「文字コード」の項を参照してください。
フリー百科事典『ウィキペディア(Wikipedia)』は、便利なもので、皆でさらに充実していきたいものです。この「テキストファイル」の項は、少し書き直す方が良いように思います。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2007年01月24日
日本語の文字についての用語について(10) — 文字コードと漢字の字形
日本語における漢字の字形と文字コードの関係について、とりあえず、まとめて見ます。
UnicodeやJIS X0213のような、文字コードの規格は、コンピュータで日本語を処理するために漢字を含む文字に符号を与えた、漢字を抽象化した存在であるということです。
それに対して、現在のコンピュータの画面や印刷される漢字は、フォント技術を使って可視化した具体的なものです。Adobe-Japan1のような文字を集めたものは、フォントの開発用のものであって抽象化した文字集合ではないと思います。
漢字は、ラテンアルファベットとは違って、1文字=1単語という意味合いが強いもので、その成り立ちからしても、形が単語の意味に密接に関係しています。しかし、抽象化した文字コードと具体的な字体を同列に論じることはあまり意味がないと思えます。
コンピュータによる日本語処理は、画面・紙への可視化のみでなく、検索やソートなどの対象にもなります。
例えば、日本語の文字についての用語について(7) — Adobe-Japan1の用語で紹介しました、「次」の異形字についても、CIDはそれぞれ、2253、13799、13800と別ですが、Unicodeは3文字ともU+6B21で、Adobe Readerの検索では3文字とも同一の字としてヒットします。

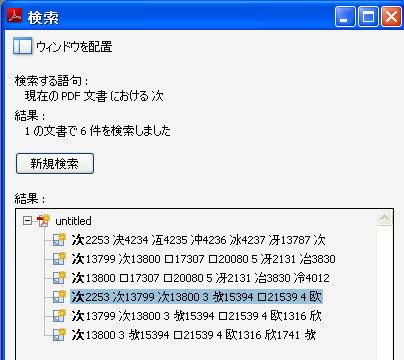
ですので、字の形だけ考えても片手落ちという感は免れません。字の形とその意味の違いまで同時に調べていかないといけませんね。そういう話になってしまいますとなかなか難しいのですが。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月22日
日本語の文字についての用語について(9) — PDFへのフォント埋め込みとは
丁度、良い機会ですので、PDFへのフォントの埋め込みについて説明してみます。
昨日の図の記号で、フォントを埋め込んだPDFとフォントを埋め込まないPDFを比較して示しますと、次のようになります。
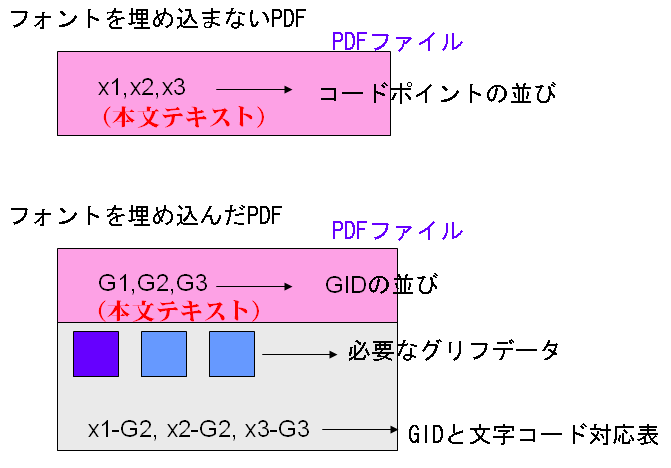
フォントを埋め込まないPDFでは、文字列が文字コードによって表されていますが、フォントを埋め込んだPDFでは、文字列がGIDによって表されています。そして、そのGIDに相当するグリフデータがPDFの中に一緒に埋め込まれているのです。
GIDに相当するグリフデータは、コンピュータのOSが画面に字の形を表示するためのデータです。従って、フォントを埋め込んだPDFを表示するとき、PDFの中のグリフデータをそのまま使って文字を表示すれば、理論的には、文字化けがなくなることになります。
理論的にはと言いましたのは、実際は、プログラムにはバグがつき物だからです。ですので、もし、フォントを埋め込んだPDFで文字が化けるとしますと、PDFを作成する過程で、あるいは、PDFを表示する過程で、関与するプログラムのどこかにバグがあるということになります。
さて、フォントを埋め込んだPDFでは、もう一つ、GIDと文字コードの対応表が必要です。なぜかといいますと、GIDは、文字コードではありませんので、文字コードを必要とする処理はGIDではできないからです。
文字コードを必要とする処理とは、例えば、PDFからテキストを取り出したり、あるいは、PDFの中の文字を検索したりなどの処理です。
GIDと文字コードの対応表は、ToUnicode CMapといいますが、実は、インターネットで流通しているPDFには、ToUnicode CMapがないPDFがかなりの割合で含まれています。これは、PDFを作成するソフトに不可全なPDFを作成するものが多々あるということが原因です。
【1月26日追記】
上の図は、「必ずしも正しくない」、と、弊社のプログラム担当者から指摘されました。PDF Referenceでは、PDFに埋め込むのは、GIDではなくCIDになっている、とのことです。但し、CIDは、Adobe-Japan1のCIDではなくCharacterIDの意味で使用しているようです。同じCIDでも意味が違うことになります。また、埋め込み時に、CIDではなく文字コードになることもあるそうです。
あまり細かいことを書くと、開発ノウハウの流出になりかねないですし、プログラマ以外には関心もないことでしょうから、このくらいにしておきますが。上の図は、大筋正しいですが、細かいところで、誤りがあるようですので、PDFを開発するプログラマの人は鵜呑みにしないでください。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月21日
日本語の文字についての用語について(8) — 文字コードとフォント
次に、OpenTypeなどのフォントを使う場合において、文字コードと実際に表示される文字の形状との関係について考えてみたいと思います。
コンピュータ間で、通常、交換したり処理するデータは文字コードであって、文字の形ではありません。画面に表示したり、印刷する文字の形を表すためのデータは、フォントファイルに含まれています。
例えば、アウトラインフォントで文字を表示する仕組みについては、
2006年04月24日PDFとフォント(15) アウトラインフォント
などでお話しました。
アウトラインフォントで文字の形を現すためのデータは、グリフデータと言いますが、フォントファイルの中には多数の文字のグリフデータが収容されています。そして、各文字を表示するためのグリフデータには、識別番号がついています。OpenTypeフォントでは、これをGIDと言うようです。
フォントファイルの中には、文字コードからGIDへの対応表も含まれていますが、これをcmapと言います。多分、cmapでは、文字コードから代表的なGIDに対応させます。アプリケーションは、該当の文字に、縦書き用の字形、異体字、などがあるときは、フィーチャテーブルを使って他のGIDに置換できるはずです。この仕組みは次の図のように表すことができるでしょう。
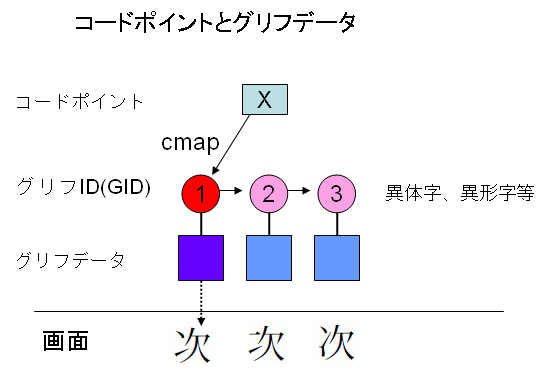
【ご注意】フォントファイルの仕様書ざっと読んで理解した範囲です。自分でプログラムを作ってみれば正しいかどうか検証できますが、検証してないので上の図、多分、このような仕組みになっているはずという話。誤りがあればご指摘いただければうれしいです。
上の図は、文字コードXに対して、GIDは1番が通常対応しますが、アプリケーションは、OpenTypeのフィーチャテーブルを使って、2番、3番に切り替えることもできることを示しています。パソコンのOSは、選択されたGIDに該当するグリフデータを使って、文字を画面上に可視化します。
ここで、Adobe-Japan1のCIDは、上の図で言いますと、1番~3番のGIDに相当します。そして、フォントファイルの中には、CIDを見て、デザインされた文字の字形描画データが入っていることになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月20日
日本語の文字についての用語について(7) — Adobe-Japan1の用語
Adobe-Japan1では、CIDは、文字形状の種別に対して付けられている、と説明されています。しかし、実際には、そうではなく、次のようにまったく同じ字形の文字に対して、別のCIDが割り当てられています。
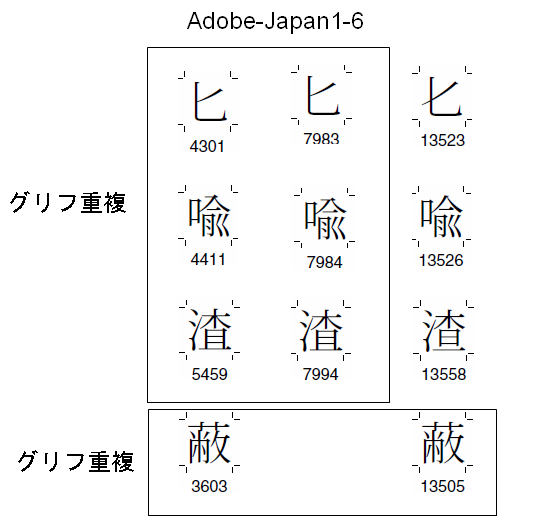
これは、歴史的な要因、およびJIS90規格との互換性を維持するためと説明されています。
また、Adobe-Japan1では、他にも微妙な字形差のグリフが別のCIDで登録されているケースがあります。
例えば、安岡孝一氏が作成した「Adobe-Japan1の漢字(部首画数順)」を見ますと、次の図のようにまったく同じグリフと思われるものが別のCIDになっているものが頻繁に見つかります。

※上図は「Adobe-Japan1の漢字(部首画数順)」より加工
http://coe21.zinbun.kyoto-u.ac.jp/results.html.ja
さらに、半角の文字や括弧類などは、横書き用と縦書き用が別々のCIDに登録されています。
そういう点を考えますと、CID、すなわち、文字形状の種別とは一体何か、意味が大変に分かりにくくなっているように思います。これは、Adobe-Japan1は、標準規格として、きちんとした考証を経て作成されたものではなく、フォントのデザイナの便宜のために字形を収集して適当に番号を付けたもの、なのだからでしょう。従って、このドキュメントでいうグリフという言葉の意味も、また、あまり明瞭でないように思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月19日
日本語の文字についての用語について(6) — Adobe-Japan1の用語
Adobe-Japan1については、丁度1年ほど前にも取り上げました。その概要は、前回の記事をご覧いただきたいと思います。
Adobe-Japan1の資料は英語版ですが、その文書で使われている用語をチェックしてみましょう。
仕様書の中から、用語に関連しそうな部分をピックアップしてみます。
○A character collection contains all gryphs required to make fonts for a particular language.(ひとつの文字の収集には、ある言語のためのフォントを作るのに必要なグリフの全てを含んでいる。)
○Each CID (Character ID) in a character collection is associated with a class of chracter shape. (文字の収集におけるCIDは、文字形状の種別に関連付けられている。)
○The specific shape of a character from a given class is dependent on the typeface style, the language, orientation, writing direction of the font,.. (与えられた種別の文字の特定の形状は、書体、言語、方向、フォントの記述方向に依存する。)
○Character instances (glyphs) for all CIDs are shown in this document, giving a specific example of the correspondence between CID number and its character chape class. (この文書には、全てのCIDについて、文字の例(グリフ)が示されていて、CID番号とその文字形状の種別との対応関係の例を与えている。)
この上の部分で言っていることを、図示しますと次のようになると思います。
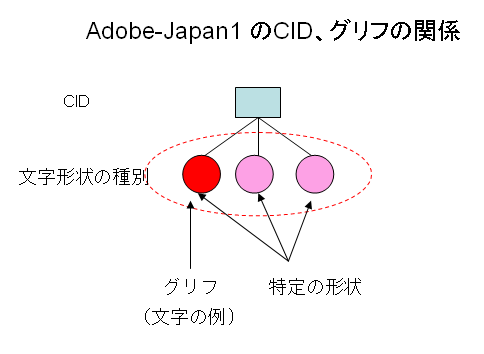
つまり、Adobe-Japan1の文字には、CIDという番号がついていますが、CIDには、一定の種類の文字の形状が対応しており、グリフがその対応関係のひとつの例として示されているということになります。ここで言っているグリフは日本語でいう字体に相当するものなのか、字形に相当するものなのかが、いまひとつ分かりにくいように思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月17日
日本語の文字についての用語について(5) — 3階層モデル
さらに、例示字体と例示字形のどちらが適切なのだろうかと考えていて、コードポイント-字体-字形の3層モデルで考えると分かりやすいのではないかと思いました。
2007年01月09日 Windows Vista と日本語文字コード問題(5)で示しました、次の図をご覧ください。
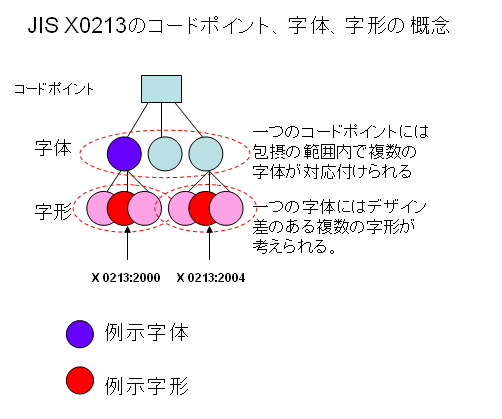
JIS X0213の考え方は、上の図で表すように、コードポイントには包摂の範囲内で複数の字体が割り当てられています。
包摂の基準にはいろいろありますが、たとえば、国語審議会の「表外漢字字体表」で、3部首許容とした「しんにゅう、しめすへん、しょくへん」は、JIS X0213では、包摂される部分字体とされています。次の図をご覧ください。

上の説明をみますと、JIS X0213:2004で変更になったのは字体に相当します。
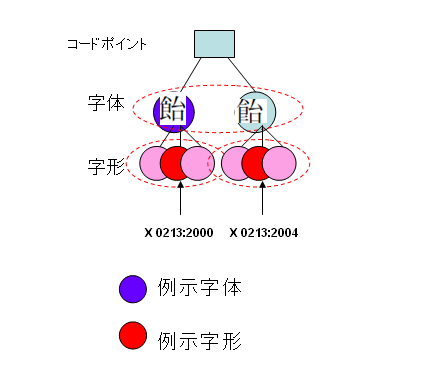
ですので、この場合、例示字形よりも例示字体というほうが正しいのではないか、と思えてきました。
なんとも、難しいものですね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月16日
日本語の文字についての用語について(4) — 例示字体か例示字形か
JIS X0213を読んでいて、いつも気になることがあります。それは、例示字体という言い方と、例示字形という言い方が、両方入り混じっていることです。
JIS X0213:2000の方は、例示字体にほぼ統一されているようです。
そして、付属書には字形例という言葉を別に用いています。
次のように:
付属書4
d)字形例 当該面区点位置で表現される図形文字の字体で、参考となるその他の字形がある場合にその字形を例示したもの。
さらには、康煕字典の字形というような言葉まで飛び出しています。
このような、JIS X0213:2000の言葉の使い方は筋が通っていて気持ちが良いと思います。
ところが、JIS X0213:2004になりますと、とたんに、例示字体と例示字形が入り混じってしまっています。
12.のあたりは、例示字体になっています。
31.になりますと、次のようになります。
付属書6.。。。面区点位置の例示字体の字形を、次に掲げる字形に変更する。
ここで例示字体の字形という表現が出てきます。
そして、解説では、
1.4
a)168文字の例示字形を、。。。。変更した。
となっていて、以下、例示字形という言葉が頻繁に出てきます。
この不統一さは、あまり気持ちが良いものではありません。
一体、例示字体が適切なのでしょうか、それとも、例示字形が適切なのでしょうか?
恐らく、両方とも「字体を例示する字形」を意味しているとは思うのですが。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年01月14日
日本語の文字についての用語について(3) — 朝日文字
朝日新聞の文字を「朝日文字」と呼ぶのだそうですね。既に、ご承知の方も、多いと思いますが、その「朝日文字」も、いよいよ、今日が最後で、明日15日(月曜日)からかなりの文字が新しい字体に変わってしまうとのことです。
9日に朝日新聞に、「常用漢字表にない漢字約900文字の字体を変更する」との社告が掲載されたそうです。
ウィキペディアの「朝日文字」によりますと、朝日新聞社は、1946年に『当用漢字字体表』が制定されたときに、当用漢字以外の漢字も、当用漢字字体表と同じような規則で、字体を簡略化し、その簡略化した漢字によって新聞紙面の印刷を行っていたのだそうです。この朝日新聞独特の漢字を「朝日文字」と呼んでいたのだそうです。
朝日新聞の社告には、例として次のような字体の変更が記載されていました。
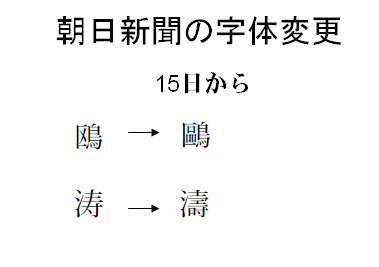
常用漢字の字体は変更しないようですので、紙面に現れる漢字のほとんど大部分は、変わらないのだろうと思います。
朝日新聞の社告に例示されている2つの文字のうち、オウの方は、2つの字体が、それぞれ印刷標準字体と簡易慣用字体として標準とされていますので、必ずしも、字体の変更の必要がないものです。トウの方は「朝日文字」の方は、簡易慣用字体になっていません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月13日
日本語の文字についての用語について(2) — 表外漢字字体表の論理構造
前回、表外漢字字体表の用語を検討しましたので、今日は、それに沿って、この表が字体の標準を定める論理構造を検討してみます。
まず、表外漢字漢字字体表では、印刷標準字体 1,022字を定めています。そして、その1,022字のうちの22字については簡易慣用字体を定めています。
印刷標準字体 — 「明治以来、活字字体として最も普通に用いられてきた、印刷文字字体であって、かつ、現在においても常用漢字の字体に準じた略字体以上に高い頻度で用いられている印刷文字字体」及び「明治以来、活字字体として、康煕字典における正字体と同程度か、それ以上に用いられてきた俗字体や略字体などで、現在も康煕字典の正字体以上に使用頻度が高いと判断される印刷文字字体」
簡易慣用字体 — 「印刷標準字体とされた少数の俗字体・略字体は除いて、現実の文字生活で用いられている俗字体・略字体の中から、印刷標準字体と入れ替えて使用しても基本的には問題ないと判断しうる印刷文字字体」
この関係を一つの字種「997」番で見ますと次のようになります。字種「997」に二つの字体を標準として定めており、簡易慣用字体の方には、デザイン差としてふたつの字形が掲載されています。
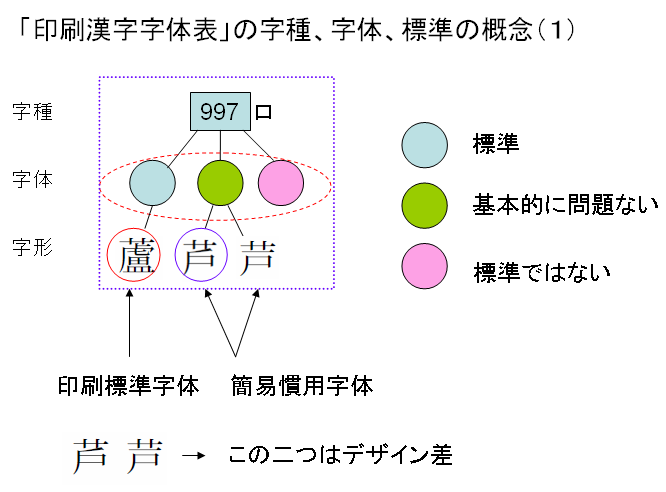
簡易慣用字体が基本的には問題ないとは、一体、なにを意味しているのでしょうか?標準ではないが、問題ないとはどういうことなのか、やや曖昧なように思います。
次に「3部首許容」を見てみます。3部首とは、しんにゅう、しめすへん、しょくへんです。「印刷標準字体としては、![]() の字形を示すが、現に印刷文字として、
の字形を示すが、現に印刷文字として、![]() の字形を用いている場合は、これを印刷標準字体の字形に変更することを求めるものではない。」とされています。
の字形を用いている場合は、これを印刷標準字体の字形に変更することを求めるものではない。」とされています。
例えば次の図のような例があります。
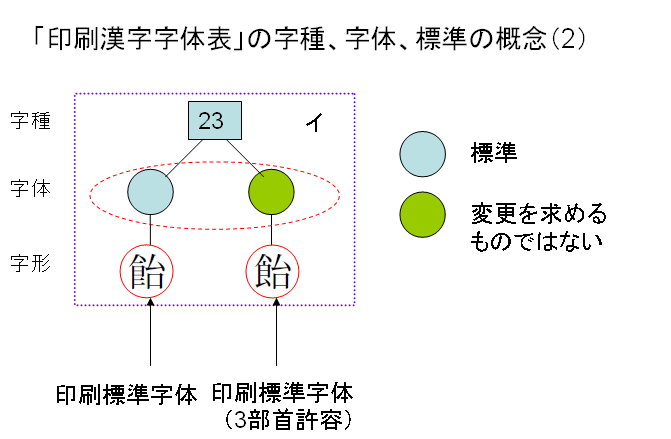
3部首許容とされる上図右の「イ」の字形は、デザイン差でもなく、簡易慣用字体でもありません。では、印刷標準字体なのでしょうか?変更を求めるものではないとは?うーーん。分かりにくいですね。
さて、次のように3部首許容と簡易慣用字体の両方が重なる場合はどうなるのでしょうか?
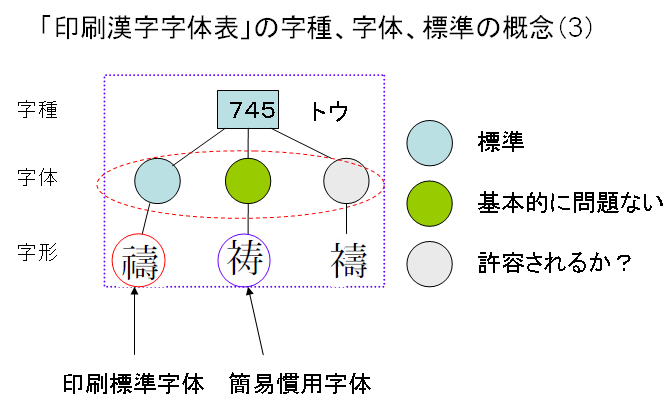
簡易慣用字体と3部首許容を組み合わせた、上図右端のような字体があったとします。そうしますと、この右端の字体は、標準字体になるでしょうか?これは、現に印刷文字として、使用されているかどうか、で判断することになります。これは、極論すれば、表外漢字字体表では、標準字体かどうかを判断するよりどころを放棄していると考えられます。
どうも、国語審議会の表外漢字字体表は、「一般の文字生活の現実を混乱させない」として、ものわかりの良い親父のような答申になってはいますが、戦後の親父の地位低下と同じで、よりどころとしては少々頼りない、という印象ももってしまいますね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月11日
日本語の文字についての用語について(1)
文字コード関係のいろいろな記事やブログ(自分も含めて)を読んでいて、どうも、用語が、それぞれで違っているのが気になります。
以前にも、少し、整理してみたことがありますが、その後、自分でも間違っていたと感じることもあります。そこで、いくつかの資料を読んで、もう一度、文字関連の用語を整理してみたいと思います。
1.「表外漢字字体表」
この数年の話題のネタの発生源が、この国語審議会の「表外漢字字体表」です。この文書は、「印刷文字において標準とすべき字体である」印刷標準字体を定めています。
この文書で定義して使っている単語に字体、書体、字形があり、また、字種、異体字、別字という言葉を使用しています。
字体 — 文字の骨組み。ある文字をある文字たらしめている点画の抽象的な構成のありかた。他の文字との弁別にかかわるものである。文字は抽象的な形態上の概念であるから、これを可視的に示そうとすれば、一定のスタイルをもつ具体的な文字として出現させる必要がある。
書体 — 文字の具体化に際して、視覚的な特徴となって現れる一定のスタイルの体系が書体である。例えば、書体のひとつである、明朝体の場合は、縦画を太くして横画の終端部にウロコという三角形の装飾を付けたスタイルで統一されている。すなわち、現実の文字は、例外なく、骨組みとしての字体を具体的に出現させた書体として存在しているものである。
書体の例としては、明朝体、ゴシック体、正楷書体、教科書体など。
字形 — 印刷文字、手書き文字を問わず、目に見える文字の形そのものを総称していう場合に用いる。
・字体の違いとデザインの違い
この「表外漢字字体表」では、字体の違いとデザインの違いについて次のようになっています。
「デザイン差とは、活字設計上の表現の差」としています。文脈上、デザイン差と対比させる形で字体の違いという言葉を使っていますので、デザイン差の範囲での字形の相違は同じ字体と見なし、デザイン差に収まらないものは別の字体と考えていることになります。
デザイン差について、具体的な分類と例があります。
1 表外漢字における字体の違いとデザインの違い
「デザイン差があてはまっても字種を分ける場合は、デザイン差には該当しない。」という一文もありますので、デザイン差は字種の同じものの範囲で意味をもつとしています。
(1) 「しんにゅう/しめすへん/しょくへん」は、(a)![]() を用いるものと、(b)
を用いるものと、(b)![]() を用いるものがあります。これらは「3部首許容」とされています。印刷字体では標準は(a)だが、(b)を使っても良いということでしょう。特に「3部首許容」と言う表現を使っているのは、これらはデザイン差でなく、別の字体だが、標準として許すといういうことのようです。それにしても、この「3部首許容」という言葉の意図がなかなか分かりにくいですね。
を用いるものがあります。これらは「3部首許容」とされています。印刷字体では標準は(a)だが、(b)を使っても良いということでしょう。特に「3部首許容」と言う表現を使っているのは、これらはデザイン差でなく、別の字体だが、標準として許すといういうことのようです。それにしても、この「3部首許容」という言葉の意図がなかなか分かりにくいですね。
(2)「くさかんむり」については、明朝体では3画を標準としています。しかし、明朝体以外では4画も制限しないということなので、書体によって、デザイン差の許容範囲が違うことになります。
・別字の例が幾つか載っています。異体字で使い分け意識があるものを、特に別字と言っているようです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月10日
Windows Vista と日本語文字コード問題(6)
とりあえず、Microsoftの資料から、MSゴシックとMS明朝のバージョンアップについての概要をまとめてみます。
1.MS明朝、MSゴシックのバージョン
(1) Windows Vista用の標準搭載MS明朝、MSゴシックは、バージョン5.0
(2) 現行 Windows XP用の標準搭載MS明朝、MSゴシックは、バージョン2.3
(3) 次の2つのフォントパッケージが、無償提供される。
a.Windows XP SP2以上、Windows Server2003 SP1以上用のMS明朝、MSゴシックバージョン5.0
b. Windows Vista、Windows Server Longhorn向けMS明朝、MSゴシック、バージョン2.5
2.各フォント・パッケージの概要
(1) MS明朝、MSゴシック バージョン2.3 — 初版は1998年(?)。JIS X0208 6,355文字とJIS X0212の5,801文字 合計12,156文字、その他。
(2) MS明朝、MSゴシック バージョン2.5 — バージョン2.3に、JIS X0213:2004の追加文字とバージョン2.3のバグを修正したもの。字形の変更は行っていない。
(3) MS明朝、MSゴシック バージョン5.0 — JIS X0213:2004の文字セットをサポート。JIS X0208+X0212と重複しない文字を追加。Unicode 4.0の通貨記号を追加。さらに字形変更を行った。この中でJIS X0213:2004の例示字形に準拠するように字形を変更した122字形については、OpenTypeの'jp90'タグで旧字形にアクセス可能とした。(既定値では新字形、'jp90'タグで旧字形を取り出すことが可能)。
字形変更を行ったのは122字のみでなくもっと広範に行っているようです。
昨日指摘しましたように、バージョン5.0で字形を変更した部分が、以前のバージョンとの非互換なバージョンアップであって、印刷・DTP業界で混乱を引き起こす可能性があります。
OpenTypeについて詳しくない方は、OpenTypeの'jp90'タグと言っても理解できないかもしれませんが、OpenTypeは、フォントの様々な組版特性をアプリケーションから使用できるようになっています。これがタグ(正確にはfeature tag)ですが、様々なOpenTypeフォントで共通に付けるべきタグのほか、各フォント独自タグを自由に追加できます。Microsoftは自社開発したフォントに、様々な独自タグを付けていてUniscribeなどから使っています。こうした、フォントに内蔵する組版特性を利用すれば、フォントの特性を使った綺麗な組版ができます。
'jp90'タグは OpenType Layout tag registry に登録されて公開されてます。
http://www.microsoft.com/typography/otspec/features_fj.htm#jp90
これは、Registered by: Adobe でMicrosoft独自タグではないようです。
アプリケーションは'jp90'タグを使えば、MS明朝・ゴシックのバージョン5.0フォントの中から旧字形を取り出すことができるようです。このためには、アプリケーションの改造が必要です。念のために。
投稿者 koba : 07:55 | コメント (0) | トラックバック
2007年01月09日
Windows Vista と日本語文字コード問題(5)
2.MS明朝、MSゴシックについて
MS明朝、MSゴシックについては、「メイリオ」とは事情が違います。例えばWindowsXPに標準搭載されているMS明朝・MSゴシックのバージョンは2.3(V2.3)ですが、Vistaに標準搭載されるもののバージョンは5.0(V5.0)になります
この2つのバージョンは、フォント・ファミリー名が同じになっているため共存できません。
そして、MS明朝・MSゴシックV2.3の字形は、1990年改正のJIS規格の例示字形準拠、V5.0の字形はJIS X0213:2004の例示字形準拠とされています。つまり、V2.3とV5.0では同じコードポイントの文字を表示する字形が大幅に異なるものがある、ということです。
次の図は、「Microsoft® Windows Vista™ における JIS X 0213:2004(JIS2004)対応について」に出ているものです。

※面区点位置について、追記。
これらの文字は、JIS X0213:2004で例示字形が変更された168文字の一部です。JIS X0213の例示字形が変更されたのだから、フォントの字形も変更されるのが自然だろうと思われる方も多いと思いますが、しかし、JISの規格を読むと次のようになっています。
1.JIS X0213の規格は、コードポイントと、そこに対応付けられる抽象的概念としての字体を定めているものです。ひとつのコードポイントには、複数の字体が割り当てられていて、それを包摂(Unification)といいます。
2.X0213:2000 6.6.2 この規格は、字体の図形的実現としての字形については規定しない、とありますように、JISの規格書では字形を定めているわけではありません。
1.2についての概念図は、次のようになるでしょう。
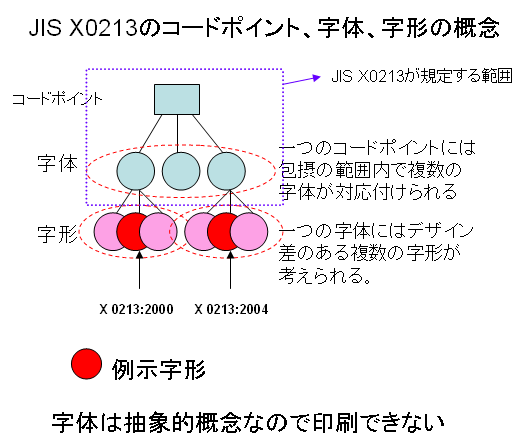
これに対して、字体にデザインを与えて具象化したものが字形です。フォントは字形をコンピュータで表すグリフデータの集合体です。フォントの種類を識別するためにフォントファミリー名を使います。そして、「フォントファミリー名が同じであれば、各文字のデザインは同じ」というのがフォント利用の基本概念と考えています。PDFを作成する場合も、フォントを埋め込まなくてもPDFを表示する環境に同一のフォントがあれば、同じ文字が表示されるということが言われていました。
このように、JIS X0213の規格とフォント技術は抽象度の階層が異なるものです。ですので、JIS X0213の例示字形が変わったからといって、必ずしもフォントの書体デザインを変更しなくても良いのです。また、多くの文字の字形を一斉に変更するのであれば、フォントファミリー名を変更するべきです。
Microsoftの上述の資料を読みますと、JISの規格が変わったから、MS明朝・MSゴシックの字形を変えたというように読めますが、上に説明しましたようにJIS規格とフォントのデザイン変更を1対1対応に解釈するのは少々単純すぎるようにも思います。
そうしたことを考えて見ますと、今回のMS明朝・MSゴシックのバージョンアップは、そのような技術の基本、常識からははずれているように思います。この結果、特に、文字の字形を重視する印刷やDTPの世界では相当な混乱が生まれることが予想されます。
【参考】
2006年03月11日 PDFとフォント(1) 書体、グリフ、フォント
2006年01月11日 PDFと文字(20) – 字体と字形
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月07日
Windows Vista と日本語文字コード問題(4)
昨日までのお話を一言で言いますと、JIS X0213:2004にある文字を全て取り扱うためにはUnicode処理の強化が必要。多くのアプリケーションで、いままでのままでは、正しく処理できない漢字が最低303文字、非漢字が25文字あるのではないだろうか、ということになります。
「Microsoft Windows VistaにおけるJIS X 0213:2004 (JIS2004)対応について」 2006年11月 Version 1.0(Microsoft)によりますと、Windows Vistaは、このために文字入力用のIME、文字列描画用のUniscribeとGDIといった共通のコンポーネントが強化されているそうです。
文字の処理と言っても、文字列の入力・編集・表示・検索・比較など多様です。Windows Vistaでも、IME、Uniscribe、GDIの変更のみではなく、他にもいろいろ変更になっているはずです。また、Windowsの上で動くアプリケーションの場合は、それがWindowsのコンポーネントが提供する機能をどう使っているかによってかなり事情が変わることに注意しなければなりません。結局、ユーザはアプリケーション毎に確認が必要です。
蛇足ですが、LinuxなどのWindows以外の環境で動くアプリケーションは、Windowsが用意した共通機能を享受できません。JIS X0213:2004 をサポートするには、自力で、Windowsが共通機能として提供しているものに相当する機能を強化しなければなりません。
さて、日経BP IT Pro特番ページを見ますと、「文字が化ける」という観点を強調しています。確かに、印刷・PDF化などの観点からは、文字の形がどうなったかは重要です。次にこの問題を検討します。
第二.新しいフォント「メイリオ」の搭載と「MS明朝」、「MSゴシック」のバージョンアップ
1.「メイリオ」について
「メイリオ」は、Window Vistaに標準で搭載される表示用フォントで、他のWindows環境には提供されません。
日経BPの記事では、Windows Vistaで作成した文書を、XPなどのほかのOSで表示したときの文字化け問題を取り上げていますが、そのうち大部分(前述の303+25文字を除くもの)は文字の字形の変更によるものです。
現在のマルチフォントを使う文書作成ではフォントが違えば、文字の字形デザインは違うということが前提だと思います。
Microsoft は「Windowsの次期バージョンWindows Vista(TM)において日本語フォント環境を一新」(2005年7月29日)で、メイリオは「画面上での可読性を大幅に向上させるまったく新しいデザインのフォント(フォント名:メイリオ)」と発表していますし、極論すれば、Windows Vistaで「メイリオ」を指定した文書は、「メイリオ」以外のシステムフォントをもつ環境では、そのまま表字することができないのは、格別の問題にするにあたらないと考えても良いのではないでしょうか。
「メイリオ」を指定した文書を他の環境にもっていって同じ字形で表示したいのなら、フォントを埋め込むしかないでしょう。従って、「Windows Vistaの新文字セットが引き起こすトラブル」でいろいろ述べている「文字化け」議論は雑誌社特有のあおり文書じゃないか?と私は思ってしまうのです。
文字化けだけではなく、「メイリオ」のメトリックスと「MSゴシック」のメトリックスが、同じでないとすると、「メイリオ」を指定した文書を、「メイリオ」のない環境で、表字すると文書のレイアウト自体が変わってしまいます。そういうことからも「メイリオ」は、Windows Vista専用のものであり、他の環境と字形の交換はできないと考える方が妥当と思います。
投稿者 koba : 08:00 | コメント (6) | トラックバック
2007年01月06日
Windows Vista と日本語文字コード問題(3)
JIS X0213の付属書4に、仮名、特殊文字および罫線素片についてのUnicodeとの対応表があります。
これの2004年版を見ますと、JIS X0213では一文字になっているのに、Unicodeでは二つの文字の並びで表すようになっている文字が25文字あります。
これらの文字はUnicodeでは1つのコードポイントが与えられていないため、次の図のように2つのコードポイントの文字(または記号)を合成して表さなければなりません。
図1 文字を結合する仕組み

※以前(下記、参考の日付)にUnicodeの結合文字のお話をしましたので、この仕組みについて詳しくはそちらも参考にしてください。
これらの文字をUnicodeで表すには、基底文字と結合文字のセットで表すしか方法がないということなのです。具体的な文字の一覧を図2に示しました。
図2 JIS X0213 に1文字で定義されているがUnicodeにはコードポイントがない文字

【参考】
Unicodeの結合文字については、こちらを参照してください。
・2006年01月27日 PDFと文字 (34) – Unicodeの結合文字
・2006年01月28日 PDFと文字 (35) – 文字の合成方法
・2006年01月29日 PDFと文字 (36) – 文字の合成方法(続き)
・2006年01月30日 PDFと文字 (37) – 結合文字列の正規合成
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月05日
Windows Vista と日本語文字コード問題(2)
JIS X0213:2004の文字でUnicodeでは4バイトで1文字を表す文字がいくつあるかを調べてみました。
これを調べていて、気が付いたことは、JIS X0213:2000(制定時)は、当初はJIS X0213の文字は全てUnicodeのBMP(基本多言語面:2バイト領域)に割り当てる予定だったらしいことです。
2000年の時点ではUnicode3.0でしたが、そこには、JIS X0213:2000で追加した文字の中に、Unicode3.0にはなかったものがあったのでしょう。JIS X0213:2000の付属書11には、UnicodeとJISの文字コードの対応表がありますが、それらの文字は()付きで示されています。
2003年にUnicode4.0が制定されたのですが、その時点で、恐らく日本側の思惑とは裏腹に、一部の文字が、BMPに割り当てられずに、補助面に割り当てられてしまったんですね。
このため、補助面に割り当てられた文字は1文字を4バイトで処理しなければならなくなったという事情がありそうです。
では、実際に、どんな文字がそれに相当するかは、JIS X0213:2004の付属書6の表で、UCSの番号が2xxxxに対応されているものがそれに相当します。
数えますと、32項に302文字、33項(2004年版で追加した文字)に1文字の合計303文字です。文字の字形の一覧は次のページで確認できます。
Vistaで化ける字,化けない字の図6に示されている26文字
Vistaで化ける字,化けない字(続報)の図9に示されている277文字
これらの文字は、Unicodeを1文字2バイト固定で扱うプログラムでは正しく処理できません。
【参考】Unicode(UCS)の制定時と文字の追加について
2005年12月25日 PDFと文字(11) – UnicodeとISO 10646
2005年12月26日 PDFと文字(12) – Unicode仕様の文字
さて、JIS X0213:2004の文字をすべて完全に扱おうとしますと、Unicode文字列の処理でもう一つの問題があります。これについては明日取り上げたいと思います。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年01月04日
Windows Vista と日本語文字コード問題(1)
Windows Vistaの発売に伴い、日本語文字コードの話題が盛り上がっています。この話題は、文字コードに関心をもつ人の間では、とりたてて新しいものではないのですが、実際の製品が発売されることで、多くの人にとって身近な問題になってきたものです。印刷・DTP関係者には気をもんでいる方も多いことと思います。
日経BP IT Proでは特番ページまで用意しました:Windows Vistaの新文字セットが引き起こすトラブル
マイクロソフトが、Vista用にJIS X0213:2004をサポートする新しいフォント「メイリオ」を標準搭載したこと、および、従来よりWindowsに標準搭載されていたMS明朝が、バージョンアップされX0213:2004対応となるということが、Windows Vistaでの変更点です。
それで、なぜ、印刷・DTP業界が気をもまねばならない問題が起きてしまうかということを、私なりに説明したいと思います。
第一.Uncodeの取り扱いを変更することが必要なケースがあること
JIS X0213:2004では、文字の種類が11,233文字と非常に多くなっています。最近のパソコンのアプリケーションは、内部的にはUnicodeを使うものが多いと思いますが、UnicodeでJIS X0213:2004の全文字を正しく扱うには、一部の文字については1文字4バイトを使って表現することが必須になります。
例えば、アンテナハウスの主なアプリケーションは内部では、文字をUnicodeで取り扱っていますが、現状では、1文字を2バイトで表しています。PDF生成エンジンなども、現在のバージョンは1文字2バイトです。
※Antenna House XML Editorだけは、1文字4バイトのUnicodeで処理しています。
そこで、JIS X0213:2004を完全に取り扱うには、アプリケーションの内部で1文字を4バイトで表現するように改造するか、2バイトと4バイトを混在させることを可能にするように改造するか、どちらかの対策が必要です。
プログラム的には、1文字を4バイトで扱うようにしてしまうのが簡単ですが、そうしますと、ラテン・アルファベットのように、本来1バイトで良いものまでも、4バイトで表すことになってしまうため、あまりメモリ使用効率が良くないと思います。そこで、弊社の場合、原則として、1文字を2バイト表現と4バイト表現を混在させても問題ないようにプログラム内部を修正することを選択しています。
そんなわけで、Vistaの登場に伴ってプログラムの改造が必要になります。これは、Vista対応というよりも、Vistaに標準搭載されるフォント(従って、使用頻度も多くなるであろうもの)で表せる文字を全部正しく扱おうとすると、上の対策が必要になるということで、Vistaは単なるきっかけに過ぎません。長期的に、Unicode対応を完全に進めていく上では、避けられないことだと思います。
他の会社がどのような対応を取るかは、各社それぞれと思いますが、JIS X0213:2004が普及してくれば、どこの会社も同じような対応策をとることが必要になるでしょう。
この対応策が完了するまでは、そのアプリケーションではJIS X0213:2004の一部の文字を、正しく取り扱えないということになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月29日
Unicode Line Breaking Properties (2)その動向
Uncode Line Breaking Properties (UAX #14)は、Unicodeの付録として分類されていますが、Unicode仕様の一部であり重要な仕様です。
1999年8月に第5版の段階でUnicodeのテクニカルレポートとして、初めて正式な仕様になっています。
・1999年8月 第5版 http://www.unicode.org/unicode/reports/tr14-5(Unicode 3.0)
その後、次の時期に改訂版が出ています。正式仕様版の間に、提案書としての版があります。
・1999年11月 第6版 http://www.unicode.org/unicode/reports/tr14/tr14-6.html(Unicode 3.0)
・2000年8月 第7版 http://www.unicode.org/reports/tr14/tr14-7.html(Unicode 3.0.1)
・2000年2月 第10版 http://www.unicode.org/reports/tr14/tr14-10.html(Unicode 3.1.0)
・2002年3月 第12版 http://www.unicode.org/reports/tr14/tr14-12.html(Unicode 3.2.0)
・2003年4月 第14版 http://www.unicode.org/reports/tr14/tr14-14.html(Unicode 4.0.0)
・2004年3月 第15版 http://www.unicode.org/reports/tr14/tr14-15.html(Unicode 4.0.1)
・2005年8月 第17版 http://www.unicode.org/reports/tr14/tr14-17.html(Unicode 4.1.0)
そして昨日お話しました通り今年の8月に最新版として第19版(Unicode5.0.0)が出ています。
日本語では、一つ一つの文字を書く(表示、印刷する)毎に、横書きなら文字の幅、縦書きなら文字の高さ分だけ一文字づつ書き進めていき、一行の最後にきたら改行するのが、原理的な改行規則です。漢字やかななどの間ではどこでも改行できますが、例外として、行の先頭に来てはいけない、または、行の最後に来てはいけない禁則文字があります。
これに対して、英語は、単語の区切り、空白の位置で改行します。ドイツ語やフランス語なども基本は同じです。ただし、昨日述べましたようないくつかの例外があります。
実際に各言語を書いたり、表示したりする処理の際には、アルファベットやかな・漢字だけではなく、記号類、数字、さまざまな空白が混在しますので、ある文字の前後で改行することができるかどうか判断するのはかなり難しい場合があります。
UAX #14は、これを文字の改行特性と、いくつかの規則で統一的に判断しようということですので、多言語組版を行うためには、非常に重要な仕様のひとつです。
一方において、言語に関する知識なしに、UAX #14のような文字に関する規則だけから、その文字の位置で改行できるのかどうか、本当に正しい判断が可能なのだろうか?という疑問もわきますね。
ちなみに、XSL Formatterは、各言語の組版で(原則として)UAX #14に基づいて改行位置を決定しています。古いバージョン(V2の時)のことなのですが、米国の有力パートナーから、「お前のところのソフトは、米国人が絶対受け入れないような位置で改行している。それを直さないなら商談ストップする!」といって、えらく叱られました。
そこで、UAX#14の著者のAsmus Freytag氏に、「UAX#14がおかしいから、お客さんに叱られたので仕様を直して欲しい」とメールでクレームを投稿したことがあります。
他にも文句を言う人がいるためなのでしょうか、UAX#14は比較的頻繁に細かい点が変更になっているようです。UAX#14のような仕様を完璧につくるのは恐ろしく難しいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年10月28日
Unicode Line Breaking Properties と禁則文字
日本語組版に精通している人ならば、日本語の行頭禁則文字や行末禁則文字についての知識はお持ちのことと思います。
行頭禁則文字や行末禁則文字という概念をもう少し広い概念でとらえたものに、「Unicode Line Breaking Properties」という規則があります。
最新版:Line Breaking Properties 19版
最新版は、2006年8月22日に出たもので、Unicode 5.0の一部となっています。
Unicode Line Breaking Propertiesという仕様は、文字の前後で改行できるかどうかという観点から文字をいくつかのグループに分けて改行についての挙動を示しているものです。
たとえば、英語の組版では、原則は、(1)単語間の空白で改行し、(2)必要に応じて単語をハイフネーションすることができるということです。しかし、この単純な原則だけでは必ずしも十分ではありません。たとえば、The Chicago Manual of Styleの15版には、単語の区切りという節があり次のような区切りは良くないとあります。
・7-40 名前の中の番号や、Jr.、Sr.の前できってはいけない。
例) Elizabeth II は改行するなら、Eliz- /abeth II とする。
・7-42 単位の数字と単位の略語の間では区切らない。
例) 345 m のような場合、数字と単位は行末で別れないように。
・7-43 行の中のリスト
行の中に(3)、(c)のような文中の箇条書き番号が出現したら、箇条書き番号と続く文字は同じ行にはいるようにする。
これは、空白があっても空白で改行してはならないケースですが、逆に空白でなくても記号類で改行できることもあります。Unicode Line Breaking Propertiesを見ますと、次のような分類があります。
B2 前後で改行できる 例:emダッシュ
BA 後ろで改行できる 例:空白、ハイフン
BB 前で改行できる 例:辞書の中の句読点
HY ハイフン 数字の中を除き、後ろで改行できる
CB 他の情報次第で改行できる
そして、逆に、改行を禁止する文字の種類として
CL 閉じ括弧 文字の前で改行することを禁止
EX 感嘆符(!) 同上
IN リーダのように対の間で改行できない
NS 非開始文字 例:小さな「かな」文字
OP 開き括弧 文字の後ろで改行することを禁止
QU 曖昧な引用符 開き括弧と閉じ括弧の両方の役割
などがあります。
さて、上の文字の属性のみで単純に判断すると、例えばUTF-16というような単語がUTF-と16で切れてしまったり、example(s)の開き括弧の前で改行が起きてしまいます。
Unicode Line Breaking Propertiesでは、このあたりをもう少し詳しくルールを決めているのですが、それはまた明日。
The Chicago Manual of Styleとは
シカゴ大学の出版部が出している米国の代表的な編集マニュアル。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年05月08日
GB18030の法的拘束力とは?
2006年01月16日 PDFと文字 (24) – Adobe-GB1, Adobe-CNS1, Adobe-Korea1で、Adobe-GB1が、GB18030-2000をカバーしていないと書いて、小川創生@檸檬の家さんに間違っていると指摘されました。(随分前の話ですみません)。
Adobe の GB18030 対応をご参照ください。
確かに、Adobe-GB1には、GB18030をサポートすると書いてありますので、私が間違っていたように思います。
で、ついでなので、この機会に、かねてから疑問に思っていたことを書いておきます。
それは、「GB18030-2000」が法的拘束力をもつとは、どういうことなのか?ということなんですが、この数年間、ずっと疑問のまま。
私の疑問は、次の点です。
1.GB18030-2000って、文字の符号化方式の標準じゃないの?
2.しかし、実際のところ、GB18030-2000サポートという課題を、グリフの認定という課題に、問題をすり替えているんじゃないの?
ということです。もう少し説明しますと、
・GB18030-2000は、文字の符号化方式と理解しています。
-そうなりますと、これを、サポートするとは、OSやアプリケーションの内部コードで使えってこと?それとも、変換テーブルを用意して入出力できれば良いってこと?一体どちらなんだろ?
・GB18030-2000仕様書では、表の一部に、実際の文字の字形が印刷されています。残りの表には、Unicodeのコードポイントが書き込まれているのみです。
- GB18030-2000のコードポイントは160万以上。そのうち字形が印刷されているのは、28,522に過ぎません。(自分で数えたわけじゃないですが)。
- そうすると、符号化方式はどうでも良くて、仕様書で字形が印刷されている文字は、使えるようにせよ、ということ?
・ビットマップフォント標準字形の国家規格というのがあり、GB18030に対応するビットマップフォントというものが売りだされています。
- これは、グリフを規定しているものではないのでしょうか?グリフの国家規格とGB18030の法的拘束力というのは別の問題だよね。
情報機器などでは、内部文字コードにUicodeを使っているものがあります。この様な機器で、GB18030に対応するビットマップフォントを使うには、買ってきたビットマップフォントをUnicode順に並び替えることが必要です。そうすると、並び替えたものはGB18030に対応するビットマップフォントではなくなるのかな?
・今回の話で新たに沸いた疑問として:AdobeのCIDというのは、文字のグリフを集めてきたもの。フォントベンダがCIDに対応するフォントを作るときは、CIDのグリフを参考にして、自分達で新しくデザインしたグリフセットを作成する、という目的で用意されているものと理解していました。
しかし、
---引用ここから---
The typeface used to illustrate each character in this section is STSong™ Light, a product of Changzhou SinoType Technology Co., Ltd. STSong Light is certified by the Press and Publication Administration of the People’s Republic of China, the China State Language Commission, and the National Typeface Committee; and is recommended for use in official and professional publications.
---引用ここまで---
Adobe-GB1-4 Character Collection for CID-Keyed Fonts
(強調は筆者による)
というのは、CIDの趣旨に根本的に背反するのではないでしょうか?
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年02月11日
PDFと文字 (43) – ラテンアルファベットのリガチャ
さて、2006年01月26日 PDFと文字 (33) – ラテンアルファベットで、Unicodeのラテンアルファベット・ブロックを取り上げてから、結合ダイアクリティカルマークの検討に随分とお話の回数をかけてしまいました。
次にラテンアルファベットのリガチャについて検討してみましょう。リガチャについては、アラビア文字の時にも紹介しましたが、2つ以上の文字の組み合わせが出現するとき、文字のデザイン上の配慮から、二つ以上の文字を合成した別の形状のグリフに置き換えるものです。
2006年01月23日 PDFと文字 (31) – リガチャを参照。
ラテンアルファベットのリガチャはUnicodeでは次にコードポイントが与えられています。
・ラテンリガチャ:U+FB00-U+FB06 コードチャート
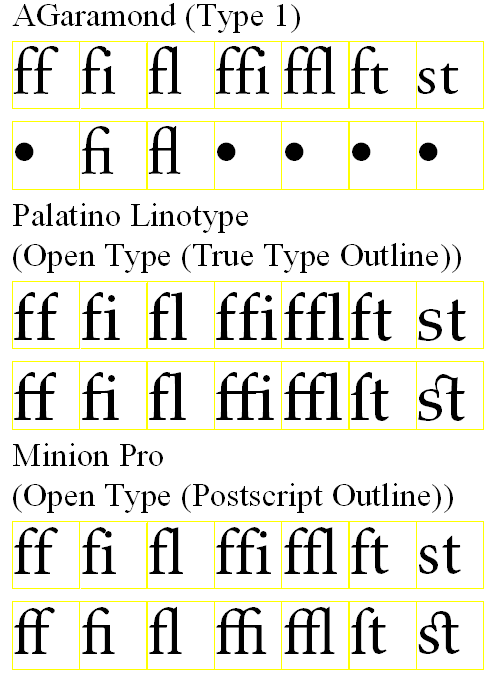
このブロックではラテンアルファベットのリガチャは次の7文字になっています。
U+FB00:ff
U+FB01:fi
U+FB02:fl
U+FB03:ffi
U+FB04:ffl
U+FB05:ft
U+FB06:st
次の図は、AGaramond、Paratino Linotype, Minion Proの3つのフォント・ファミリーについて、リガチャなしの文字の組とU+FB00~U+FB06を対比させたものです。AGaramondのようなType1のフォントは、U+FB01、U+FB02しかグリフがないことが分かります。他のフォントでもU+FB02については、fとlの2文字の配置とわずかな相違しかありません。
Wikipedia(英文)のリガチャの説明を見ますと、もっと他にも挙げています。例えば、次の文字は、Wikipediaではリガチャとされていますし、Unicodeでも文字の名前にリガチャという文字を含んでいます。
U+00C6:Æ Latin capital ligature AE
U+00E6:æ Latin small ligature ae
U+0132:IJ Latin capital ligature IJ
U+0133:ij Latin small ligature ij
U+0152:ΠLatin capital ligature OE
U+0153:œ Latin small ligature oe
次の文字は、文字の起源はリガチャとされていますが、Unicodeの文字名ではリガチャという名前は付いていません。
U+0028:& Ampersand (文字の起源はEtのリガチャ)
U+00DF:ß Latin small letter sharp s (文字の起源は、ſ Latin small letter long s とsのリガチャ)
この他、ラテン拡張Bには、クロアチア文字としてラテンアルファベット2文字を組み合わせて1文字にした文字があります。
U+01C4~U+01CC
この他に、2文字を組み合わせて1文字にしたものが幾つかあります。これらの2文字のセットにコードポイントを与えた文字とリガチャはどのような関係なのでしょうか?両者の境界が曖昧なようにも思います。
リガチャについては、2つの文字が1行に入りきらない時は、必ずしも合成形に置き換えないこともありますので、本質的には文字コードというよりは、特別な表示形と言うべきでしょう。
また、これらのリガチャの形状の中には、Unicodeで互換分解マップが与えられているものがあります。(2006年01月30日 PDFと文字 (37) – 結合文字列の正規合成の分解可能な文字の説明を参照。)
これらの互換分解マップが与えられる文字は、例えば検索では、互換分解した文字列でヒットさせることが望まれるのだろうと思います。この点から見ても、ひとつの文字として扱うものではないということになります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
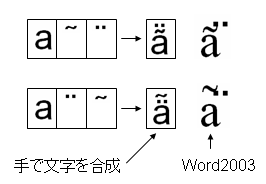
2006年02月09日
PDFと文字 (42) – ハングル音節文字の合成
次に、2006年02月03日PDFと文字 (40) – Unicode標準形式NFCの問題点で挙げましたが、ハングルの字母(Jamo)で表されたテキストをNFCにすることでハングル合成文字(Johab)にすることが可能、という点について調べてみます。
以前に、2006年01月18日PDFと文字(26) – ハングルの扱いで、ハングル音節文字(Johab)は字母からプログラムで合成できると書きましたが、これは具体的には、字母で表された文字列をNFCにするということを指します。
こんどは、実際に試して見ましょう。
(1) まず、ハングルの「こんにちは」は、「アンニョンハセヨ」と言うらしいですが、このハングル表記を調べます。そして、各音節文字を初声、中声、終声に分解します。
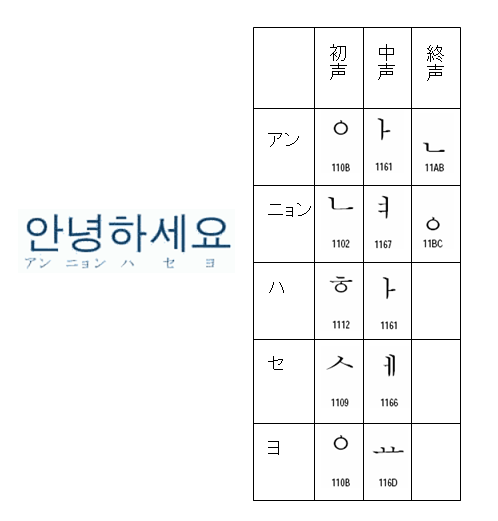
(2) これをUnicodeのJamoの文字列として表します。次のようになります。

(3) この文字列をXSL FormatterV4.0(Alpha)で標準形NFCにして表示します。
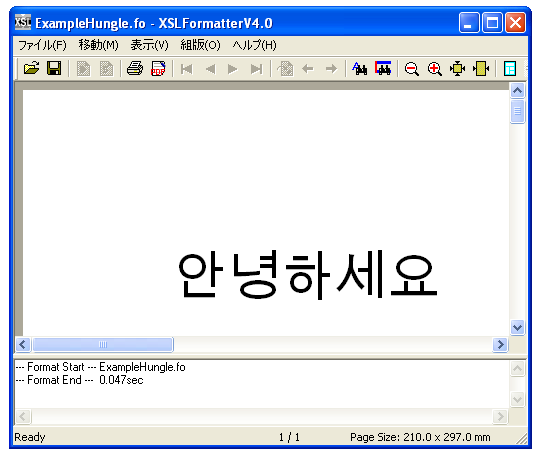
このように、ハングルの字母で表した文字列をNFCにすることで、合成文字Johabにして表示することができることを確かめることができます。
試しに、同じ文字列をMicrosoft Word2003で表示しますと次のようになってしまいます。
![]()
どうやらMicrosoft Word2003は、まだ、ハングルの字母を合成することはできないようですね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月07日
PDFと文字 (41) – Unicode標準形式NFCの問題点(続き)
2006年02月03日にPDFと文字 (40) – Unicode標準形式NFCの問題点で、合成除外文字の中の1種類Singletonについて説明しました。
合成除外文字のリストには、Singletonの他に、次の種類があります。
(a) スクリプト依存
デバナガリ文字、ヘブライ文字の合成文字など67文字。
(b) Unicode3.0以降に追加された合成文字
数学記号1文字、音楽記号13文字
(c) 正規分解が結合文字から始まる合成文字
4文字
これらの文字は、標準形NFCにすると分解されたままになってしまい合成されません。
Singletonの問題を合わせて考えますと、組版ソフトのように文字の形が重要な意味をもつソフトでは、Unicode文字列を安易に標準形NFCにする処理を既定値にするのは危険なので避ける方が良い、という結論になりそうに思います。
次に、2006年02月03日に挙げた2つ目の
(2) Unicodeにコードポイントを持たない文字を指定したときの問題
について検討します。これは、UAX#15の表5にも載っていますが次の図のような例です。
これは、Latin capital letter D with dot aboveとCombining letter dot belowという結合文字列を標準形NFCにすると、Latin capital letter D with dot belowとCombining letter dot aboveに化けてしまうという類の問題です。
NFCにする処理では、最初に、合成済の文字を分解し、そして正規並び替えを行います。(2006年01月30日PDFと文字 (37) – 結合文字列の正規合成を参照してください。)
並び替えで、Combining letter dot belowとCombining letter dot aboveの順序が入れ替わります。この結合文字列を正規合成すると基底文字DにCombining letter dot belowが先に結合してしまいます。上と下の両方にドットの付いたDはUnicodeにはありません。従って、Combining letter dot aboveが独立した文字として残ってしまいます。
正規並び替えでは結合クラスが小さい文字を、結合クラスが大きい文字より先になるよう並び替えるため、この例のような問題が起きるケースは、少なくないと考えられます。
元はといえば、Unicodeの正規分解や正規合成の概念は、分解可能な文字、合成済みの文字を想定して組み立てられています。従って、標準形NFCの適用範囲は、分解可能な文字、合成済みの文字、及びそれらを分解した文字だけからなる文字列に限定されるのではないかと思いますが、どうなのでしょうか?
実際のところ、上の例で、最初の結合文字列と最後の結合文字列が正規等価である、といわれても認めがたいように思います。少なくとも、結合文字列の表示が等価になるかどうかは、フォントとレンダリングするアプリケーション依存となってしまいます。
ちなみに、上の2つの結合文字列をWord2003で表示しますと次のようになります。

正規等価な結合文字列の表示が同じになっていないということがお分かり頂けると思います。
結合文字列をレンダリングするアプリケーションが、結合文字の位置を自在に制御して、基底文字に対して正しい位置に配置できるのであれば、標準形NFCなど考慮しなくても、結合文字列をダイナミックに合成できるわけです。この場合、標準形NFCは無用の概念となります。
このように、文字をレンダリングするという観点から考えますと、標準形NFCというのはやや中途半端な仕様ということになりそうです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月03日
PDFと文字 (40) – Unicode標準形式NFCの問題点
昨日までで、Unicodeの標準形式NFCを使えば結合文字列を合成できそうなことは分かりました。しかし、便利なものには落とし穴もあるもの。NFCにもなにか問題があるに違いありません。
そこで、仕様書を少し詳しく検討してみましたところ、気になる点が出てきました。
(1) 合成除外文字の問題、特に、CJK互換漢字が別の文字に置換されてしまう件。
(2) Unicodeにコードポイントを持たない文字を指定したときの問題。
の二つです。
一方、ハングルの字母(Jamo)で表されたテキストをUnicode標準形NFCにすることで、ハングル合成文字(Johab)に変換できるというメリットもあるようです。
2006年01月18日PDFと文字(26) – ハングルの扱いで、ハングル音節文字(Johab)は字母からプログラムで合成できると書きましたが、Jamoの列を標準形式NFCにすることで、これが実現できてしまうんですね。
順番に検討してみます。
(1) 合成除外文字の問題について
Unicode文字列の標準形NFCの作成では、文字列をまず正規分解し、次に正規合成します。ところが、この処理は完全なラウンドトリップ変換ではありません。つまり出発点に戻らない文字があります。
UAX#15に合成除外文字のリスト(Composition Exclusion Table)が用意されています。これを見ますと、合成除外文字には幾つかの種類がありますが、一番問題になりそうなのが、正規分解でそれ自身とは異なる一文字になってしまう文字です。これはSingletonと言います。
Singletonの例としてUAX#15にはオングストローム記号が出てきます。オングストローム記号は、上リング記号付きラテン大文字Aへの分解マッピングを持っています。さらに、NFDでは<U+0041, U+030A>になります。ところがSingletonは合成除外文字に指定されているため、オングストローム記号のNFCをとっても元に戻りません(次の図を参照)。
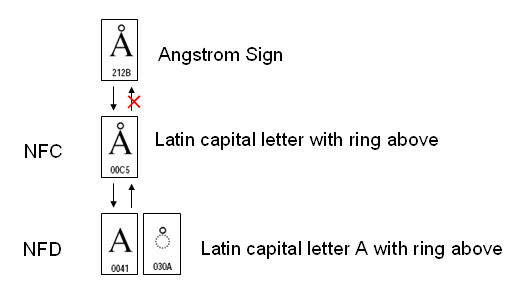
もし、万一、指定したフォントでオングストローム記号と、上リング記号付きラテン大文字Aのグリフが違っていると、NFCを取る場合とNFCを取らない場合で表示される字形が異なってしまうという問題が生じます。オングストローム記号をわざわざU+212Bで表す数奇者はいないと思いますが。それなら、Unicodeは、なぜ、オングストローム記号にコードポイントを与えたのでしょうか?
オングストローム記号程度なら良いのですが、Singletonのリストの中に漢字が997文字もあります。
※Composition Exclusion Tableには、Singletonの合計コードポイントは924となっていますが、漢字だけで997文字もありますから、924は誤りでしょう。
997文字は全部CJK互換漢字のブロックの文字です。
※CJK互換漢字については、2006年01月04日 PDFと文字(15) – CJK統合漢字拡張を参照してください。
CJK互換漢字(U+F900~U+FAFF)のブロックは、12文字(U+FA0E, U+FA0F, U+FA11, U+FA13, U+FA14, U+FA1F,U+FA21, U+FA23, U+FA24, U+FA27, U+FA28, U+FA29)を除く残りがSingletonになっています。また、CJK互換補助漢字(U+2F800~U+2FA1D)はすべてがSingletonになっています。これらの文字は標準形式NFCにするとCJK統合漢字に置き換わってしまいます。
ちなみに、JIS X0213 とのラウンドトリップ用にコードポイントをもつU+FA30~U+FA6Aの59文字もCJK統合漢字への正規分解マッピングを持っていますのでNFCで文字が置換されてしまいます。
実際にどうなるか見てみましょう。
こんどは、Normalization Conformance Testのデータに、フォント・ファミリーをMS明朝を指定してPDF化してみます。最初が標準形NFCにしない場合、次が標準形NFCにした場合です。
図 標準形NFCにしない場合

図 標準形NFCにした場合

これを見ますと、現在の時点では、MS明朝では、U+FA30~U+FA6Aの文字にはグリフがないことがわかります。これをNFCにしますと文字が表示されるようになります。
Windows Vistaでは、MS明朝にJIS X 0213の文字のグリフが追加されるようですので、そうなると、Unicode標準形NFCにすると字形の置換が現実に起きてしまうのではないかと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月02日
PDFと文字 (39) – Windowsへ表示とPDF作成の相違
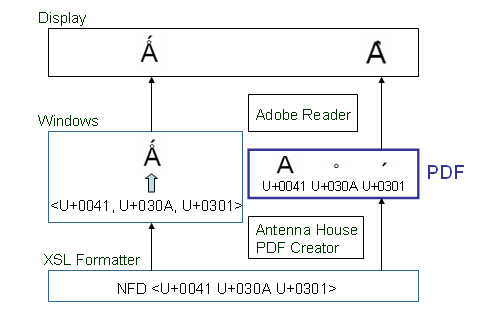
昨日、XSL FormaterV3.4ではWindowsの画面には正規分解を正しく表示できても、PDFでは正規分解を正しく表示できない、ということを示しました。
実は、このあたりがWindowsの大変ややこしいところなのです。
Latin capital letter A with ring above and acute (![]() )という文字をWindowsの画面に表示することを考えて見ます。この合成文字のコードポイントはU+01FAです。もし、入力されたデータの中の文字コードが正規分解
)という文字をWindowsの画面に表示することを考えて見ます。この合成文字のコードポイントはU+01FAです。もし、入力されたデータの中の文字コードが正規分解
そうしますと、Windowsが文字の形を作り出して ![]() という形を画面に表示します。
という形を画面に表示します。
一方、PDFを作成するときは、正規分解
これに対して、V4.0でLatin capital letter A with ring above and acute (![]() )を画面でもPDFでも正しく表示できるのは、Formatterの方で、正規分解
)を画面でもPDFでも正しく表示できるのは、Formatterの方で、正規分解
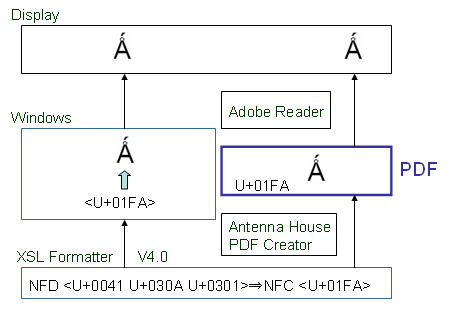
以上により、Unicodeの結合文字列から合成文字にするのは有効なように思います。では、この問題点はないのでしょうか?引き続き検討してみましょう。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年02月01日
PDFと文字 (38) – Unicode標準形NFCの実装
さて、先日までに、Unicode文字列をUnicode標準形NFCに変換する処理を実装することで、結合文字列を合成文字で表示できるようになるはず、ということを考えて、実際にXSL Formatterの次期バージョンV4.0のα版に試しに実装してもらいました。
そこで、まずその成果をざっと見てみましょう。Unicodeの標準形を決めているUAX#15には、Normalization Conformance Testというテストケースが付随しています。
これを、従来のバージョンと新機能を実装したバージョンで組版して比較してみました。そうしましたところ次のことに気がつきました。
(1) XSL FormatterV3.4のGUIでは、Unicodeの結合文字列をNFCを使わないで表示しているにも関わらず、結合文字列がかなりの割合で正しく表示できます。
次の図は、XSL FormatterV3.4のGUIに表示される組版結果中、ラテン拡張-Bブロックの後ろの方の画面のスクリーン・ショットです。
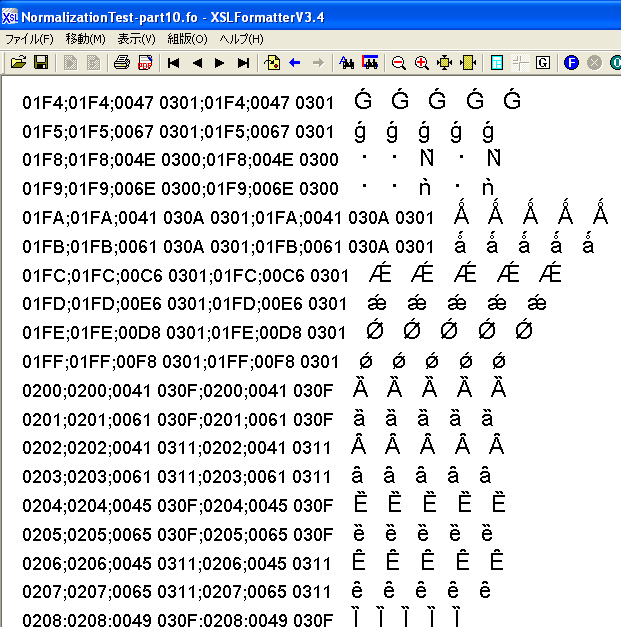
図の中で、左から3列目が左端の文字の正規分解(NFD)です。例えば、U+01FAは、<U+0041, U+030A, U+0301>と正規分解されます。WindowsのGUI経由では正規分解が正しく表示できています。
主なブロックの文字の正規分解が正しく表示できるかどうかを、表に整理しましたが、ラテン文字はほとんど正しく表示できていることが分かります。
| ブロック | コードポイント | Windows XP SP2の表示 | |
|---|---|---|---|
| ラテン文字 | Latin-1追補 | U+00C0~U+00FF | 結合文字列を正しく表示している |
| Latin Extended-A | U+0100~U+017F | 結合文字列を正しく表示している | |
| Latin Extended-B | U+0180~U+024F | U+0218以降の結合文字列が正しくない | |
| Latin Extended Additional | U+1E00~U+1EFF | 結合文字列を正しく表示している | |
| ギリシャ文字 | Greek | U+0370~U+03FF | U+0344, U+0374が不正。一部グリフがない。 |
| Greek Extended | U+1F00~U+1FFF | U+1FBE, U+1FC1, U+1FCD~U+1FCF, U+1FDD~U+1FDF, U+1FED~U+1FEF, U+1FFDが不正。 | |
| キリル文字 | Cyrillic | U+0400~U+4FF | U+0400, U+040D, U+04ECが不正。一部グリフがない。 |
Windows XPは、ラテン文字については結合文字列を画面に表示する際に、結合文字列の中の結合文字の位置を正しく調整していると思われます。あるいは、結合文字列を、それと正規等価な合成済み文字に置き換えているのかもしれません。但し、この処理は、スクリプト依存になっているようです。すなわち、ラテン系はほぼOKですが、キリル文字、ギリシャ文字はNGが幾つかある、というように。
先日(2006年01月29日PDFと文字 (36) – 文字の合成方法(続き))、「Wordは、tildeの高さの制御を行っています。」と書きましたが、これはWordではなく、実際はWindowsが行っているんですね。
(2) 次に、この文書をFormatterV3.4でPDFにして見ました。上の図と同じ場所のPDFの画面が次の画像です。XSL Formatter V3.4のPDFは、結合文字の位置が正しくないものがあります。これは、バグではなく仕様です。
このように、Windowsの画面表示では正しく見えてしまうのに、PDFにすると結合文字の位置が正しくないことがあるというのは注意が必要です。
(3) さらに、XSL Formatter V4.0 (Alpha)で標準形NFC化の機能をONにして、同じ文書を組版し、PDFを作成してみました。そうしますと、こんどは、正規分解で表した結合文字列も正しく表示できています。次の図を参照してください。
これを見ますと、標準形NFCのサポートにより、正規分解を合成文字として正しくPDFにできるようになっていることが分かります。
なお、この画面でもうひとつ気が付くことがあります。それは、U+01F8、U+01F9がグリフがないとされていることです。この試験では、Unicodeのグリフをもっとも沢山もっているとされるArial Unicode MS フォントを指定しています。しかし、Arial Unicode MS フォントにもU+01F8、U+01F9のグリフはないんですね。
また、最初の画面で分かりますが、WindowsのGUIはU+01F8、U+01F9についてはArial Unicode MS フォントにグリフがないので合成文字は表示できませんが、結合文字列はそれぞれを基底文字と結合文字で表示しています。これを見ますと、Windowsでは結合文字列を画面に表示するとき、フォントに合成済みグリフがあるかどうかをチェックして、グリフがあるときは基底文字と結合文字に正規等価な合成文字に置換しているのかもしれません。いづれにせよWindowsのやっていることは不透明です。
※テスト環境OS:Windows XP SP2(英語版)。地域と言語の設定は、地域のオプション:日本語、Location:日本、非Unicodeアプリケーションの言語:日本語としています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
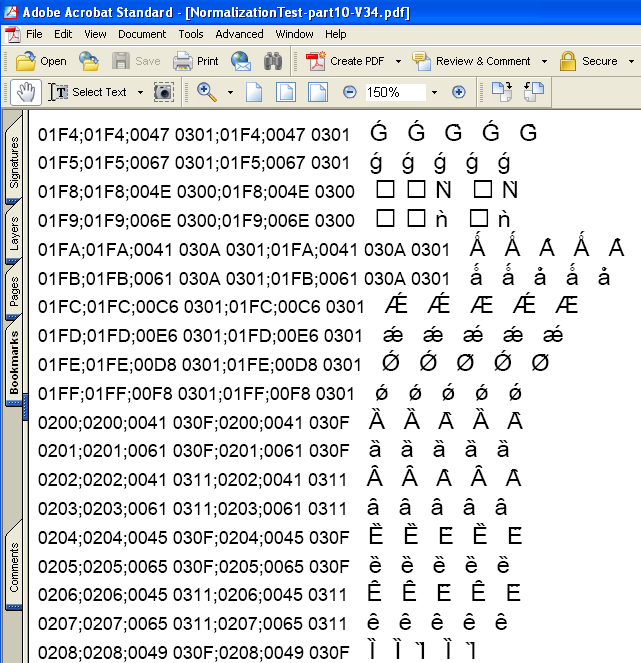
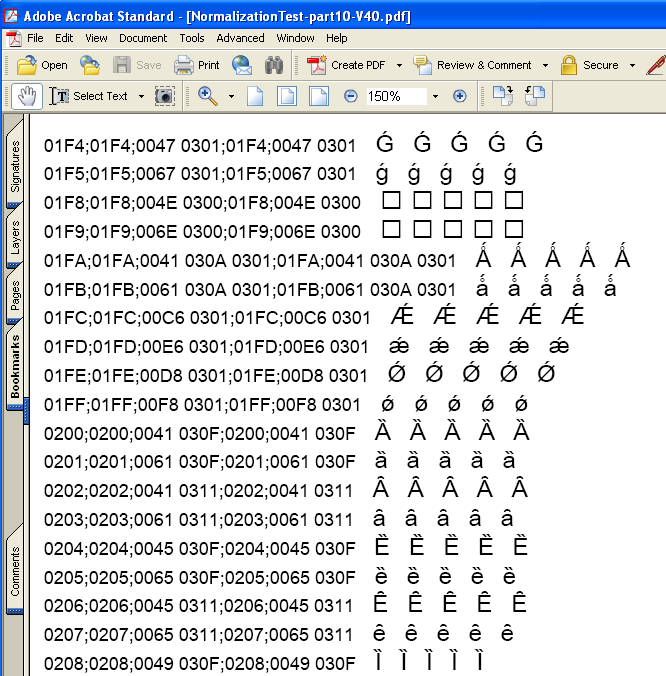
2006年01月30日
PDFと文字 (37) – 結合文字列の正規合成
昨日は、任意の新しい文字を、結合文字を使って合成して表示したり印刷したりするというのは、どうやらまだ夢の中のことらしい、ということをお話しました。
では、Unicodeでは結合文字列を合成して表示することはできないのでしょうか?
調べてみましたところ、正規合成(canonical composition)という方法があり、これを使えば、Unicodeでコードポイントをもつ合成済み文字の範囲ならば、殆どの文字を、結合文字列から合成できるように思います。
但し、Microsoft Word2003、OpenOffice.org2.0で試したところ、どうも両方とも正規合成をサポートしていないようです。
では、実際に、正規合成を使って結合文字列から合成済みの文字を合成して、表示・印刷・PDFにすることができるのでしょうか?このあたりをもう少し検討してみたいと思います。検討にあたり、最初に用語を明確にしておきましょう。
結合文字列 (Combining character sequence) p.70 D17
基底文字とそれに続く一つ以上の結合文字の並び、または、一つ以上の結合文字の並び。合成文字列 (Composit character sequence)とも言います。
分解可能な文字 (Decomposable character) p.71 D18
Unicodeの仕様書で文字の名前を指定している箇所で、名前の後に文字の分解マップが指定されている文字を言います。なお、分解マップには正規分解マップ(≡で示される)と互換分解マップ(≈で示される)があります。次の図はU+1E99の正規分解マップが<U+0079, U+030A>、U+1E9Aの互換分解マップが<U+0061, U+02BE>として与えられていることを示します。

合成済みの文字 (precomposed character)、合成文字(Composit character)とも言います。
分解 (Decomposable character) p.71 D19
分解可能な文字と等価な一つ以上の文字の並び。分解が1文字の場合もあることに注意しましょう。
※なお、以下では互換分解については説明しません。
正規分解 (Canonical decomposition) p.72 D23
分解可能な文字を正規分解マップを使って分解します。分解の中に分解可能な文字が入っているときは分解を繰り返し、完全に分解します。次に、分解の中の幅を持たない文字に対して正規並び変え(Canonical ordering)を適用します。この結果が正規分解です。
正規分解が一文字になることもあります。
正規分解可能な文字 (Canonical decomposable character) p.72 D23a
正規分解が自分自身と異なる文字のこと。
正規合成済みの文字 (Canonical precomposed character)、正規合成文字 (Canonical composit character) とも言います。
正規等価 (Canonical equivalent) p.72 D24
二つの文字列は、その二つの文字列の完全な正規分解が同じになる時に正規等価と言います。
正規並び替え(Canonical ordering) pp. 84-85
結合文字は基底文字または先行する結合文字列に対して特定の結合の仕方をします。結合文字に与えられる結合クラスが、この結合の仕方を決めていることは既に説明しました(2006年01月28日 PDFと文字 (35) – 文字の合成方法)。特に結合クラスが同じ値の場合は、結合文字はインサイドアウトルールで配置されます。このように結合文字の順序には意味があります。
従って、正規並び替えでは、二つの結合文字列が同じかどうかを比較するために、結合文字列を結合文字の順序の意味を変えない範囲で(すなわち、結合クラスが同じ値の結合文字の順番は入れ替えないで)、小さいほうから順に並び替えます。
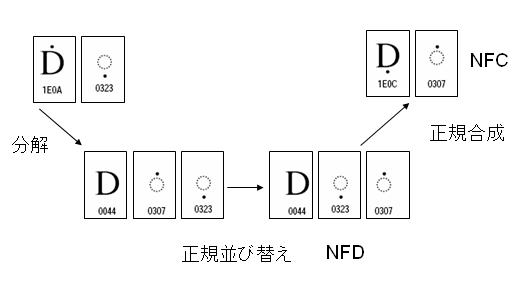
正規合成 (Canonical composition)
分解の中の二つの文字のペアを、そのペアと正規等価なUnicodeの合成済の文字に置き換えていく処理。但し、合成除外文字(Composition Exclusion Tableの文字)は置き換えしません。
※UAX#15 Unicode Normalization Forms を参照。
UAX#15では、Unicode文字の4つの標準形を規定しています。その中で正規分解、正規合成に関係するのは次の二つです。
(1) 標準形式D(NFD):これは上に説明しました正規分解の形式です。
(2) 標準形式C(NFC):文字を正規分解にした後、正規合成した形式です。
次に簡単な絵で説明します。
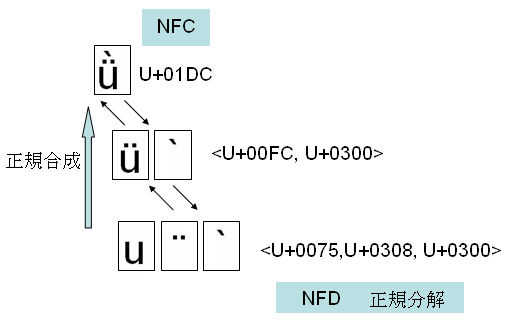
Latin small letter u with diaeresis and grave (U+01DC)は Latin small letter u with diaeresis (U+00FC) と Grave (U+0300)への正規分解マップをもちます。さらに、Latin small letter u with diaeresis は、Latin small letter u (U+0075) と Diaeresis (U+0300)への正規分解マップをもちます。NFDは一番下の形です。NFCは一番上の形です。
Latin small letter u with diaeresis and grave は、NFD形式では、uとGraveとDiaeresisの並びになります。NFD形式を正規合成するとNFCになります。
これを応用すれば、複雑な合成済み文字ラテン文字を基底文字と結合文字でバラバラに記述しておき、表示・印刷・PDF化するときに合成文字にする、ということができそうです。
ということで、この機能をXSL Formatter V4.0のα版に組み込んでもらいました。組み込みは簡単で、数日で、できてきましたので、次に、ちょっと試してみましょう。ほんとにうまくいくのでしょうか?
※XSL Formatter V4.0 α版はまだ一般公開はしていませんが、近いうちに一般公開の予定のものです。
※ご参考
NFD、NFCについては下記にも良い情報があります。
Unicode正規化とは
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月29日
PDFと文字 (36) – 文字の合成方法(続き)
さて、昨日の説明をお読みになって、Unicodeでは、コードポイントを与えられていない文字についても、基底文字と結合文字から合成することのできる文字なら、必要に応じて合成できるのか、これは便利だな、とお思いになった方も多いと思います。
実際、Unicodeの仕様書には文字をダイナミックに合成できそうなことがいろいろと説明してあります。仮にラテンアルファベットに限ったとしても、本当にそんな便利なことができるのでしょうか?そのあたりの記述を取り上げて整理してみましょう。
基底文字とダイアクリティカルマークの文字列(pp. 44-45)
・Unicodeでは、基底文字に結合するダイヤクリティカルマークを、基底文字に続けて適用する順番で使用します。
・二つ以上のダイヤクリティカルマークをひとつの基底文字に適用することがあります。規定文字に続く結合文字の数は制限していません。
・ダイヤクリティカルマークは、出現順に内側から外側に向かって配置していきます(これをインサイドアウトルールと言います)。従って、ダイヤクリティカルマークの順序に意味があります(下の図)。
結合文字の適用(pp. 82-83)
・囲み記号は先行する文字の周りを順番に取り囲みます。従って、囲み記号が順番に出現すると後の記号は前の記号の周囲を囲むことになります。
・二つの文字に結合する二重のダイヤクリティカルマークは他の字幅のない記号(non spacing mark)よりもルーズに結合します。従って他の字幅のない記号の外側に配置します。
結合クラス(pp. 97-98)
結合文字の結合クラスは、その文字が基底文字に対してどこの位置に配置されるかを示します。(これは昨日の図で示しました)。
字幅のない記号の可視化(Rendering)(pp.125-127)
・インサイドアウトルールは既定値ですが、タイポグラフィーの規則によっては変更することができます。例えば、ベトナム語では、アキュートまたはグレーブ・アクセントは、サーカムフレックス・アクセントの上ではなく、やや左右に配置されます。コードチャートのU+1EA4以降に、ベトナム語表記用のラテン拡張文字があります。
・文字の並びを合成したものが、可視化可能でないときの救済の方法としては、Unicodeの仕様書のように結合文字を点線の円と共に、基底文字とは別に表示するか、単純に基底文字に重ねます。
・文字間を広げる際の字幅のない文字の取り扱いについては、基底文字と結合文字の組がずれないようになど、結合文字の配置についての記述がいろいろあります。
仕様書7.2 Combining Marksの節にも結合文字の可視化の方法について繰り返して類似のことを説明しています。
このような記述は、いかにも、基底文字と結合文字を使ってその組み合わせの文字を画面に奇麗に表示したり、印刷したり、PDF化ができることを期待しているように思えます。
しかし、実際にそのようなことが自由にできるようには、相当なインテリジェントをもつフォントとそれを使いこなせるアプリケーションが必要でしょう。
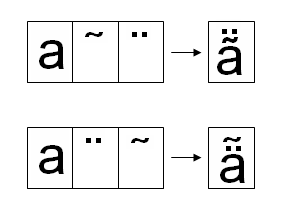
例えば、上の図に示しました基底文字aにCombing tilde (U+0303)とCombining Diaeresis (U+0308)をつけた合成文字はUnicode4.0にはコードポイントがありません。では、この合成文字をa, U+0303, U+0308の並びから合成して表示できるかと言いますと、例えば、Microsoft Wordではできません。次図のようになってしまいます。
一番右がMicrosoft Word2003で文字列を表示したところ。(フォントはTimes New Romanを指定)
Wordは、tildeの高さの制御を行っています。もしかすると<U+0061,U+0303>という文字列をU+00E3(Latin small letter with tilde)に置換しているのかもしれません。
このように、任意の合成文字を正しく表示するには結合文字の位置を自在にあやつることができないと無理なことがわかります。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月28日
PDFと文字 (35) – 文字の合成方法
Unicodeでは基底文字と結合文字があり、基底文字と結合文字を合成することができることを説明しました。次に合成の実際について少し検討してみたいと思います。
まず、基底文字になることができるのはどんな文字で、結合文字になることができるのはどんな文字かを調べてみます。
Unicodeでは各コードポイントの文字に対応する属性のデータベースとしてUnicode Character Databaseを提供しています。
このデータベースではUnicodeでコードポイントが与えられる全ての文字を、アルファベットや漢字など通常の文字(L)、マーク(M)、数字(N)、句読点(P)、数学・通貨記号(S)、空白・改行などの分離子(Z)、その他(C)の7つの大きなカテゴリーに分けています。
結合文字はカテゴリーMに分類されます。カテゴリーMは、さらに、字幅のない記号(Mn)、字幅のある記号(Mc)、囲み記号(Me)に分類されています。囲み記号は今まで出てきませんでしたが、丸付き数字などを合成して作りだすための○記号などになるのでしょう。
さらに各コードポイントには結合クラスという数字が定義されています。基底文字は結合クラスがゼロ(0)の文字とされています。これに対してカテゴリーMの記号には、1から240の数値が与えられます。
数値の意味は次の通りとなっています。
1:上書きまたは文字の内部
2:ヌクタ(Nukta:デバナガリ文字の結合記号)
3:ひらがな・カタカナの濁音・半濁音
4:ヴィラマ(Virama:デバナガリ文字の結合記号)
10から199:固定の位置
200~240:基底文字の上下左右の位置(図)
実際に、これまでに出てきました結合文字の結合クラスを調べてみましょう。
| 文字名 | コードポイント | カテゴリ | 結合クラス |
|---|---|---|---|
| Hamza Below | U+0655 | Mn | 220 |
| Kasra | U+0650 | Mn | 32 |
| Shadda | U+0651 | Mn | 33 |
| Fatha | U+064E | Mn | 30 |
| Combining circumflex accent | U+0302 | Mn | 230 |
| Combining macron below | U+0331 | Mn | 220 |
| Combining macron low line | U+0332 | Mn | 220 |
| Combining grave accent | U+0300 | Mn | 230 |
| Combining tilde | U+0303 | Mn | 230 |
| Combining diaeresis | U+0308 | Mn | 230 |
| Combining macron | U+0304 | Mn | 230 |
| Combining macron over line | U+0305 | Mn | 230 |
| Combining accute accent | U+0301 | Mn | 230 |
| Combining cedilla | U+0327 | Mn | 202 |
| Combining ring above | U+030A | Mn | 230 |
| Devenagari vowel sign aa | U+093E | Mc | 0 |
| Devenagari vowel sign i | U+093F | Mc | 0 |
| Thai char. sara i | U+0E34 | Mn | 0 |
| Thai char. mai tho | U+0E49 | Mn | 107 |
実際のデータではデバナガリ文字や、タイ文字では結合文字の属性をもちながら、結合クラスがゼロになっている文字があります。
基底文字に続く結合文字の並びは、その結合クラスの値を参照して基底文字の上下左右に配置するのだな、ということが想像できますね。そうして、Unicodeの合成規則は、ラテンアルファベットとダイアクリティカルマークを対象に考案されていて、アラビア文字、タイ文字、デバナガリ文字には適用できそうもないこともなんとなく想像されます。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月27日
PDFと文字 (34) – Unicodeの結合文字
ラテンアルファベット、アラビア文字を初めとして、世界の文字にはひとつの文字の上下、あるいは左右に別の文字または記号をつけて発音の変化や声調の変化を表すものが数多くあります。
これらの文字はUnicodeでは結合文字(Combining Character)と言われています。結合文字とはプレーンテキストの文字列を表示・印刷・PDFにするとき、文字列の中で先行する基底文字にくっついて図形的にひとつの塊になる文字ということができるでしょう。
結合文字には次のようなものがあります。
・アラビア文字のHarakat: 2006年01月22日PDFと文字 (30) – アラビア文字Harakatの結合処理
・ラテンアルファベットのダイアクリティカルマーク:2006年01月26日PDFと文字 (33) – ラテンアルファベット
・キリルアルファベットのダイアクリティカルマーク:例えば、ロシア語の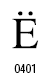 や
や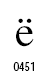 は、基底文字E、eに結合ディアレシス(ウムラウト)
は、基底文字E、eに結合ディアレシス(ウムラウト) を付加したもの。
を付加したもの。
・デバナガリ文字の母音記号:

・タイ文字の母音や声調記号など:
結合文字は、一般に、次のような特徴を持ちます。
(1)原則として単独では使われません。
(2)点線の円の位置には基底文字が置かれることを想定しています。
(3)文字の大きさやスタイルは基底文字と同じになります。
既に見ましたように、ラテンアルファベットでは、基底文字と結合文字を組み合わせて合成した文字についても沢山のコードポイントが与えられています。これらは合成済み文字(pre composed character)と言います。理論的には、任意の基底文字に結合文字を組み合わせる処理ができるはずですので、コードポイントが与えられている合成済み文字は、基底文字と結合文字の組み合わせの一部に過ぎません。合成済み文字は、既存の様々な文字規格に収録されていたものから、既存の文字規格との互換性のために採用されているとも言えるかもしれません。
結合文字の中には、基底文字の表示位置と同じ位置に表示されるものがあります。この属性をもつ結合文字は字幅のない記号(non spacing mark)といわれることもあります。
図 字幅のない結合文字
結合文字には字幅を取るものもあります。これは、字幅のある記号(spacing mark)です。
ところで、現在、多くのパソコンのキーボードには、チルダ、サーカムフレックスなどの結合文字と似た形をもつ文字のキーが幾つかあります。これらの文字は字幅のある文字(spacing character)とされていて、Unicodeの仕様では結合文字として扱わないとされています。対応する結合文字には別のコードポイントが与えられていますので使い分けが必要です。
| 字幅のある文字 | 類似の形の結合文字 | ||
|---|---|---|---|
| Circumflex Accent | U+005E | Combining circumflex accent | U+0302 |
| Low Line | U+005F | Combining macron below | U+0331 |
| Combining macron low line | U+0332 | ||
| Grave Accent | U+0060 | Combining grave accent | U+0300 |
| Tilde | U+007E | Combining tilde | U+0303 |
| Small Tilde | U+02DC | ||
| Diaeresis | U+00A8 | Combining diaeresis | U+0308 |
| Macron | U+00AF | Combining macron | U+0304 |
| Combining macron over line | U+0305 | ||
| Accute Accent | U+00B4 | Combining accute accent | U+0301 |
| Cedilla | U+00B8 | Combining cedilla | U+0327 |
| Degree Sign | U+00B0 | Combining ring above | U+030A |
| Ring Above | U+02DA | ||
参考資料
UnicodeV4.0仕様書 より
・ダイアクリティカルマークの幅をもつクローン (pp.167)
・3.6 結合 (pp.70-71)
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年01月26日
PDFと文字 (33) – ラテンアルファベット
Unicodeのラテンアルファベットについて検討してみます。ラテンアルファベットのベースは、英語のアルファベット26文字の大文字A~Z、小文字a~zです。ご承知のように、英語はアルファベット26文字で表記できますが、他の言語ではこれに様々な発音符(diacritical mark ダイアクリティカルマーク)をつけた文字を追加しています。
Unicodeでは、ラテン文字は次のブロックに規定されています。
・基本ラテン (Basic latin):U+0041~U+007A コードチャート
アルファベット26文字と基本的な記号類
・ラテン-1追補 (Latin-1 Suppliment):U+00C0~U+00FF コードチャート
ヨーロッパの主要言語で使用するダイアクリティカルマーク付きの文字
・ラテン拡張A (Latin Extended-A):U+0100~U+017F コードチャート
さらにその他の欧州言語で使用するラテンアルファベット系の文字
・ラテン拡張B (Latin Extended-B):U+0180~U+024F コードチャート
中欧から東欧にかけての言語で使う特別な文字など
・ラテン拡張追加 (Latin Extended Additional):U+1E00~U+1EFF コードチャート
ダイアクリティカルマーク付きの文字各種、ベトナムの文字など
上で定義されているラテンアルファベットの多くは、基本ラテン文字とダイアクリティカルマークを結合したものに対してコードポイントを与えているものです。
一方でダイアクリティカルマークマークは、単独でもコードポイントを与えられています。
・結合ダイアクリティカルマーク(Combining Diacritical Marks):U+0300~U+036F コードチャート
結合グレーブアクセント(U+0300)、結合アキュートアクセント(U+0301)、結合サーカムフレックス(U+0302)などの一般的なものを初め、他の文字の上に乗せるアルファベットのようなめったに使いそうもないような文字まで107種類のマークが網羅されています。
・結合ダイアクリティカルマーク追補(Combining Diacritical Marks Supplement):U+1DC0 - U+1DFF コードチャート
使用頻度の少ないマークが4種類、Unicode 4.1で追加されています。
ラテン文字の表示・印刷・PDF作成と言う点で注意しなければならないのは、この結合ダイアクリティカルマークおよびリガチャでしょう。
結合ダイアクリティカルマークのブロックに収録されているマークは、一般に、結合文字といわれます。先日、2006年01月22日 PDFと文字 (30) – アラビア文字Harakatでも説明しましたが、結合文字は先行する基底文字と結合されるという属性をもちます。
そうしますと、Unicodeのラテンのブロックで結合済の形でコードポイントを与えられている文字の多くは、基底文字と結合文字の並びで表すこともできそうです。
ひとつの例を示します。
グレイブアクセント付きラテン大文字Aは、ラテン大文字Aと結合グレイブアクセント文字の並びでも表すことができそうに思います。このような場合、結合済の文字とそれを分解した文字は、同等の扱いをするべきなのでしょうか。
もし、同等とするならば同じ文字を2通りの符号化ができるということなのでしょうか?また、同等か同等でないかの判断をどうしたら良いのでしょうか?様々な疑問が沸きますね。これについては明日また続けて検討してみたいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月24日
PDFと文字 (32) – 文字コードと情報交換を考える
日本のJIS規格に関する議論、さらにUnicodeについても議論でも、字の形と文字コードが1対1になることを暗黙に想定した議論が多いように思います。しかし、アラビア文字はその典型的な例ですが、文字コードと画面表示・印刷される字形は1対1になっていません。
この仕組みを次のような簡単な絵で表してみました。
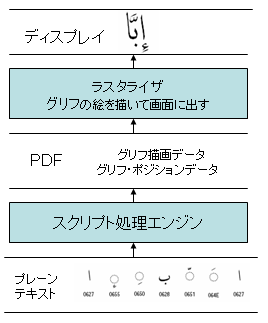
この図の中の言葉の意味は次の通りです。
・プレーンテキストとは、2005年12月15日のPDFと文字(4) – 文字の取り扱いで述べました、飾りのない本文文字にあたります。
・グリフ描画データとは文字の形を描画するためのデータまたはプログラムです。2006年01月13日PDFと文字(22) – グリフとグリフセットあたりをご覧ください。グリフポジションデータとは、そのグリフをどの位置に描画するか、というデータと理解してください。PDFの中には、かなり抽象化して言いますと、テキストを表示・印刷するためのグリフ描画データとグリフポジションデータが収容されているということができます。
さて、コンピュータで電子ドキュメントを情報交換する場合、まず、どのレベルで情報交換をするか、ということを考えなければならないでしょう。上の図で言いますと、プレーンテキストを情報交換するか、それとも、例えば、PDFのレベルで交換するかということになります。両方セットで交換することももちろん可能でしょう。
プレーンテキストレベルで交換した場合、受け手の側に、送り手と同じスクリプト処理エンジンが必要となります。具体的に言いますと、例えばWindowsではUniscribeというスクリプト処理エンジンがあり、これがUnicodeのテキスト文字列を受け取って正しいグリフの列や位置を割り出す処理をしているようです。Linuxなどでこのプレーンテキストを表示しようとしますと、同等の機能をもつエンジンを使わないと正しく表示できないことになります。携帯電話などで読もうとするときも同じです。
このように見ますと、プレーンテキストレベルでの情報交換は必ずしも最適解ではないケースが多いだろうと思います。
これに対して、PDFのレベルであれば、スクリプト処理エンジンの出したデータを交換するわけですから、オリジナルの情報を加工するとき、例えば、WindowsでUniscribeを使ったとしても、受け手には同じ機能は不要です。
このように、文字コードと画面表示・印刷される字形とを分離させて考えることは、漢字の場合にも有効なように思います。
漢字については、2000字も使えれば、一般的のコミュニケーションは可能でしょうし、さらに、5000字を使えれば相当なもの。1万文字を使いこなせる人は日本にも殆どいないでしょう。このような現実に対して、7万を超える文字にひとつづつ情報交換用のコードポイントを与えても情報交換という意味ではあまり意味がないように思います。どうしても文字の形状を交換したいのであればグリフデータを交換することを考えるのも有益だろうと思います。
※参考資料
Uniscribeについてはこちらにも説明があります。
Uniscribe
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月23日
PDFと文字 (31) – リガチャ
アラビア文字のもう一つの特徴はリガチャ(合字)です。結合文字は基底文字を主とすると、その基底文字の上・下に付く従たる文字と言って良いと思います。
これに対して、リガチャは特定の二つ以上の文字が並んだときに、二つの文字のグリフを並べる代わりに別のグリフに置き換えるものです。アラビア文字ではラムとアレフの2文字が連続したときは、リガチャにするのが必須です。
ラテンアルファベットにもリガチャはありますが、アラビア文字のリガチャは文脈依存のグリフとの組み合わせになるため複雑です。
・ラムとアレフのコードポイント
| 名称 | コードポイント |
|---|---|
| ラム | 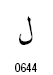
|
| アレフ |  |
ラムは、文脈依存のグリフを4つもちます。これに対して、アレフは常に単独形となります。この二つの文字が連続する場合、リガチャがなければラムの左にアレフが接続したU型のカーブをもつ文字になりそうなものです。(あるいは、ふたつの文字はつながらない?)しかし、リガチャにより別の形になるとされています。
(次の図を参照)。

※フォントは、Arabic Typesettingを指定。実際のところはアレフは次の文字(左)に接続しませんので、ラムとアレフのリガチャは、単独形と右接形(FinalForm)しかもたない、というべきかもしれません。また、上の図でリガチャなしは無理やり作成したもので正しくないものですので、ご注意ください。
PDFと文字 (28) – アラビア文字のプログラム処理の(1)文字の結合(Cursive Joining)の項に出てきましたが、Unicodeにはゼロ幅接合子(Zero Width Joiner:U+200D)、ゼロ幅非接合子(Zero Width Non-Joiner:U+200C)という文字があり、これを使うことで擬似的に接続状態を制御して文脈依存のグリフの切り替えを行うことができます。
例えば、上のリガチャの図では対象文字の接続する側にU+200D、接続しない側にU+200Cを配置しています。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月22日
PDFと文字 (30) – アラビア文字Harakatの結合処理
さて、アラビア文字の検討で、1月20日アラビア文字のプログラム処理でHarakat(母音記号)とリガチャが出てきました。この二つについて、Unicodeによる取り扱いをもう少し検討してみます。
まず、Harakatについて検討します。次の画像をご覧ください。

これは、聖典クルアーンの一部ですが、文字の上と下に記号が付加されています。アラビア語では、原則として子音を文字として筆記する方式です。ビジネス文書や操作説明書などではそれで十分なようですが、クルアーンなどでは読み方を明確にするため、母音記号や子音の発音のバリエーションを示すための記号類を付加することがあります。
このオプションとして使われる記号類を総称してHarakatと言います。上の例では、右から次のような文字を見ることができます。
| 名称 | 役割 | コードポイントと文字 |
|---|---|---|
| Hamza Below | 声門閉鎖音を表す |  |
| Kasra | 短母音iを表す | 
|
| Shadda | 子音の連続(重子音)を表す |  |
| Fatha | 短母音aを表す |  |
上のような文字は、一般に結合文字(Combining Character)と呼ばれています。表示したり、印刷・PDF作成したりするときは先行する基底文字の上または下に配置します。
そうしますと、先頭(右)からUnicodeの文字列として表しますと、次のようになるでしょう。
A. 
最初の2文字を結合した文字は、結合した形のコードポイントも与えられていますので、次のようにあらわすこともできます。
B. 
このように、Unicodeでは基底文字と結合文字の組によっては、結合済の形でコードポイントを与えれられているものもあります。その場合、基底文字と結合文字を分離したものと同等になります。すなわち、上のAとBの文字列は同等として扱わねばなりません。
上の文字列を実際に表示・PDF化しますと次のようになります。
![]()
※Arabic Typesettingフォントを指定
※ご注意
私は、アラビア語はわかりませんので、上の説明の中でアラビア語に関する部分の説明は、必ずしも正確でないかもしれません。ここでは、Unicodeのアラビア文字でどうやってアラビア語を表すかという例としてご理解ください。また、誤りがありましたらご指摘いただければありがたいです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月21日
PDFと文字 (29) – アラビア文字表示形
Unicodeには、アラビア文字表示形のブロックが二つあります。
表示形A(Form-A):U+FB50~U+FDFF
表示形B(Form-B):U+FE70~U+FEFF
なぜ、このような二つのブロックが用意されているのでしょうか?
まず、表示形Bを見ますと、ここにはアラビア文字が140種類あります。
先頭のU+FE70~U+FE7Fには、1文字(U+FE73)を除いて、Harakat(母音記号など)を基底文字と分離した形で表示・印刷する形式、およびHarakatをカシダ(Tatweel:U+0640)の上下に配置した形式の文字があります。
ちなみに、カシダとはアラビア文字の単語を左右に伸ばすときに接合部を引き伸ばすために挿入する横線です。下の例をご覧ください。
・単語にカシダを挿入してない状態

・単語にカシダを挿入した状態

アラビア語の文章を両端揃え(Justification)するときは、単語にカシダを挿入して単語を横に伸ばします。カシダは文字と文字の間に挿入するのですが、どこにいくつのカシダを挿入するべきかは分かっていません。Unicode仕様書にはフォントと可視化ソフトに依存する、とのみ書いてあります。このあたり、まだUnicodeの仕様書を書いている人にもきっと分かっていないのでしょうね。
ご存知の方がいらっしゃいましたら、お教えいただきたいと思います。
次のU+FE76からU+FEF4の区間は、アラビア文字の基本形(U+0621~U+064A)に対して、単独形、左接形、両接形、右接形を全て登録しています。その後ろのU+FEF5からU+FEFCは、ラムとアレフのリガチャのいろいろな形が載っています。すなわち、この部分は、昨日説明しましたプログラムによるCursive接続とリガチャの処理を施したあとのグリフ(以下では、これを文脈依存のグリフと言います)を登録しているわけです。
ここの文字は過去の規格との互換用として用意しているとされています。通常は、適切なグリフをプログラムで選択するべきものです。
一方、表示形A(U+FB50~U+FDFF)の範囲を見てみます。こちらはまさにアラビア文字の符号化の難しさを象徴している部分です。
・ペルシャ語、ウルドゥ語、シンディ語などで拡張された文字に対する文脈依存のグリフ:U+FB50~U+FBB1
・中央アジアの言語で拡張された文字に対する文脈依存のグリフ:U+FBD3~U+FBE9
・2文字のリガチャ:U+FBEA~U+FD3D
ラムとアレフの2文字が連続した場合はリガチャが必須になります。しかし、それ以外の2文字にもオプションのリガチャが使えます。ここではそれらのリガチャのグリフにコードポイントを与えています。
・3文字のリガチャ:U+FD50~U+FDC7
3文字の並びからできるリガチャを文字として扱っているものです。ちなみに、ラテンアルファベットの3文字のリガチャについてはffi(U+FB03)、ffl(U+FB04)の二つにコードポイントが与えられています。
最後の方では、ほとんどロゴマークといってよさそうなリガチャにまでコードポイントを与えています。
Arabic Ligature Jallajalalouhou:U+FDFB 
これは、U+062C, U+0644, U+0020(空白), U+062C, U+0644, U+0627, U+0644, U+0647の、実に8文字の並びからできるリガチャを文字として扱っていることになります。
現在の時点で、このブロックをすべて実装したものはない、とされています。
(Unicode仕様書V4.0 p.204)
※参考資料
リガチャ(合字)については、以下をご参照ください。
日本語:合字(未完成)
英語:Ligature
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月20日
PDFと文字 (28) – アラビア文字のプログラム処理
アラビア文字はアラビア語以外の表記に使われるようになる際、文字が追加されています。Unicodeのアラビア文字ブロックには、アラビア語以外の言語用に追加されたアラビア文字も含まれています。
拡張アラビア文字(Extended Arabic Letters)という見出し付きで、ペルシャ語(イラン)、ウルドゥ語(パキスタン)、パシュトゥー語(アフガニスタンほか)、シンディー語(インド)など各種の言語用に追加された文字が規定されています。
アラビア文字を表示・印刷・PDFに処理するプログラムは、単に文字コードからグリフに対応つけるだけではなく、幾つかの必須処理を行わねばなりません。
次に簡単に紹介しておきます。
(1) 文字の結合(Cursive Joining)
アラビア文字は接合に関して次の6つのクラスになります。
・接合しない文字:ゼロ幅非接合子(Zero Width Non-Joiner U+200C)など
・右接形のみ:印刷の際に右の文字にのみ接合する文字
・両接形:両方の文字に接合する文字
・接合を起こす文字:ゼロ幅接合子(Zero Width Joiner U+200D)など
・接合に対して影響を与えない文字
※左節形しかないものはありません。
プログラムはアラビア文字自身がどのクラスに属するか、及び、左右の文字のクラスを見て、その文字の表示・印刷・PDF作成用のグリフを選択します。
(2) Harakatの処理
アラビア文字にはHarakat(母音記号など)があります。Harakatは基底になる文字の上、または下につけて発音を表します。Unicodeでは、Harakatに基底の文字とは別のコードポイントを与えていますので、表示・印刷・PDF作成では、プログラムで基底文字と結合し、Harakatを基底文字の上あるいは下に配置しなければなりません。
(3) リガチャの処理
アラビア文字を筆記するには、必須とされている2文字のリガチャがあります。必須リガチャについては、単に接合させるだけではなく、2文字を組みにした新しいグリフに入れ替えなけばなりません。
アラビア文字を表示したり、印刷・PDF作成では、文字のコードポイントから単純に該当するグリフを取って来るだけではなく、プログラムで(1)から(3)の処理を行わねばなりません。そのためのロジックは、昔ならば、各アプリケーションのメーカが研究したものでしょう。ロジックをゼロから研究するにはアラビア語を理解して、アラビア文字を独自に研究する必要があります。
Unicodeの仕様書に標準のアルゴリズムが掲載されていることで、これを忠実に実装すれば、アラビア語を全然知らなくても、最低限のアラビア文字処理ができることになったわけです。
アンテナハウスでは、XSL-FOに準拠する組版ソフトXSL Formatterを開発・販売しています。XSL Formatterは、2002年にアラビア文字の組版・PDF化を、この分野の製品としては世界で始めて実装しました。これにより、自動車、OA機器などのアラビア語などのマニュアル作成用途として、メーカやローカリゼーションの関連の多数の会社に採用していただくことができました。XSL Formatterの成功のきっかけは、アラビア語組版を、世界で一番最初に実現したことにあるともいえます。
その後、他のXSL-FO組版エンジンのメーカもアラビア文字組版を実現してきているようです。誰でもできるわけですから、その分、ソフトウエアのグローバルな競争も厳しくなるわけですね。
※参考資料
Unicode 4.1.0 Middle Eastern Scripts
Unicode4.0仕様書pp.199~202
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月19日
PDFと文字 (27) – アラビア文字の扱い
アラビア文字がアラブ文化圏の広がりとともに、様々な国で使われていることについては、12月13日に簡単に触れました。
ここでは、Unicodeでアラビア文字がどのように扱われているかをまとめてみましょう。
アラビア文字が定義されているブロックは、アラビア文字(U+0600~U+06FF)、アラビア文字追補(U+0750~U+076D)、アラビア文字表示形-A (U+FB50~U+FDFF)、アラビア文字表示形-B (U+FE70~U+FEFF)の3ブロックになります。これらについて検討します。
アラビア文字の書法は印刷でもcursive、日本語でいう連綿体(書道で、草書や仮名の各字が次々に連続して書かれている書体)になります。このため多くの文字は、単語の中で出現する位置によって形 (form) が変わり、単独形、左接形、両接形、右接形の4つの形をもつことになります。
次の図の上は、全部、文字を単独形で並べたもの、下は、単語の中の文字を接続させたもの(通常)です。

アラビア文字:U+0600~U+06FF コードチャート
ISO/IEC 8859-6 (Part 6 Latin/Arabic Alphabet) 規格と同じ順序で文字を並べています。但し、Unicode独自で追加した文字もあります。掲載している文字の形は単独形のみです。
アラビア語の表記では、主にフランス語系統の句読点や括弧類を使います。括弧類はラテンアルファベット用のものを鏡に写した像の形になります。形が大きく違っているものは独自のコードポイントが与えられています。アラビア文字ブロックにコードポイントのある句読点は次のものです。これ以外の句読点はラテン文字と共用になります。
| 名称 | コードポイント | 形 |
|---|---|---|
| Arabic Comma | U+060C |  |
| Arabic Date Separator | U+060D | 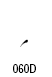 |
| Arabic Semicolon | U+061B | 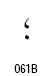 |
| Arabic Question Mark | U+061F | 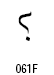 |
| Arabic Percent Sign | U+066A |  |
| Arabic Decimal Separator | U+066B | 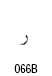 |
| Arabic Thousands Separator | U+066C | 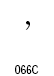 |
| Arabic Five Pointed Star | U+066D |  |
| Arabic Full Stop (ウルドゥ語用) | U+06D4 | 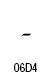 |
アラビア文字の数字は2種類が定義されています。
| 数字の名称 | Arabic Indic | Eastern Arabic-Indic |
|---|---|---|
| コードポイント | U+0660~U+0669 | U+06F0~U+06F9 |
| 0 |  |

|
| 1 |  |

|
| 2 | 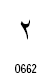 |
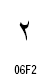
|
| 3 | 
|
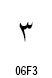 |
| 4 | 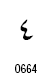
|
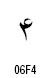 |
| 5 |  |
 |
| 6 | 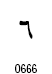
|
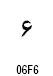 |
| 7 | 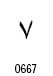
|
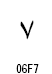
|
| 8 | 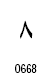
|

|
| 9 |  |
 |
【参考資料】
・"Arabic Typography, a comprehensive sourcebook" (Huda Smitshujizen AbFares, Saqi Books, 2001, ISBN0863563473(pb))
・第10回多言語組版研究会配布資料(PDF)
・多言語組版研究会ホームページ
・アラビア系文字
・「アラビア系文字の基礎知識」
なお、アラビア文字は右から左に書きますが、数字は左から右に書きます。また、ラテン文字用の句読点、あるいは数字を共用します。右から書き表す文字や記号と、左から書き表す文字や記号が混在すると、画面表示や印刷時の、文字の進行方向を決定するのが複雑になります。Microsoft Word のようなWYSIWYGのワープロを使って書くとわけがわからなくなってしまうようです。このような表記の問題については、別途、改めて検討したいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月18日
PDFと文字(26) – ハングルの扱い
漢字の場合は、ひとつの字体にひとつの文字コードを与えるのが原則ですが、そう単純ではないしくみの文字も世界には沢山あります。お隣の韓国・北朝鮮の言語である朝鮮語を書くための文字ハングルもそのひとつです。
ハングルは、李氏朝鮮の世宗大王が15世紀に学者の協力を得て定めた文字とされていて、比較的新しいこともあり、科学的な発想による仕組みをもつ文字と言われています。
ハングルでは、頭子音(初声)、母音(中声)、終子音(終声)を表す3つの字母(Jamo)を組み立てて音節文字を作ります。頭子音は19種類、母音は21種類、終子音は27種類の形があります。但し、頭子音と終子音には同じ形状のものがあります。
音節文字の数は、理論的には次の(1)と(2)の合計11,172種類となります。
(1)頭子音と母音で組み立てる文字:19×21=399種類
(2)頭子音、母音、終子音の3つを組み立てる文字:19×21×27=10773種類
ハングル文字の符号化方法には、字母を符号化する方法と、組み立て済の文字を符号化する方法の2種類があります。韓国の国内文字規格には、この両方の方法に基づくものがあり、それぞれ、かなり頻繁に改訂されたため、大変分かりにくくなっています。
Unicodeにも、2種類の符号化方式を採用したものが盛り込まれていて、それぞれ、コードチャートの次のブロックに定義されています。ハングルを処理するプログラムは両方の符号化方式を正しく処理できないといけないようです。
・ハングル字母(Jamo):U+1100~U+11FF
組み立て前の字母を登録しています。コードチャートを見ますと、頭子音が90種類、母音が68種類、終子音が82種類もありますね。ここの字母は、UnicodeV4.0 仕様書の3.12節に組み立てる方法が説明されています。この範囲のハングル文字コードの並びが表れた時は、それを表示したり、印刷、PDF化するときは、その並びを判断して音節文字に置き換える必要があります。
・ハングルの互換字母(Compatibility Jamo)全角形:U+3130~U+318F
韓国の文字規格 KS X1001:1998 のハングル字母に準拠する全角形94種の文字が定義されています。このブロックの互換字母は組み立てなくても良いようです。
・ハングルの互換字母半角形:U+FFA0~U+FFDF
ここに半角形の互換字母もあります。
・ハングル音節:U+AC00~U+DA73
韓国の文字規格KS C 5601-1992から収録した組み立て済の音節文字が11,172個登録されています。これをJohab文字セットと言います。これらは、ハングル字母の並びから対応つけることができます。対応付けのロジックは、Unicode仕様書3.12節にあります。また、プログラムで字母を組み立てて、音節文字の字形を作ることもできます。
但し、古ハングル文字にはJohab文字セットにないものもあり、その場合は、ハングル字母の並びで表すしかないようです。この場合は、プログラムで音節文字の字形を作り出すことになるのでしょう。
【参考資料】
「文字符号の歴史 アジア編」(三上 喜貴著、共立出版、2002年、ISBN4-320-12040-X )pp.165~174
ハングル フリー百科事典『ウィキペディア(Wikipedia)』
投稿者 koba : 08:00 | コメント (7) | トラックバック
2006年01月17日
PDFと文字 (25) – CMapで文字コードからCIDへ変換
Adobe-Japan1、Adobe-GB1などのグリフセットでは、ひとつひとつのグリフにCIDという番号が付いていることは説明しました。CIDフォント・ファイルには、文字を画面表示したり印刷するためのグリフ・データを収容しています。フォント・ファイルに収容されているグリフ・データにアクセスするときはCID番号を使わなければなりません。
Windows、LinuxやマッキントッシュなどのOSや、OSの上で動くアプリケーションは、Unicode、または機種専用の文字コードを使ってテキストを処理します。一方、CIDフォントにあるグリフを使ってその文字を表示・印刷するには、文字コードからCIDに変換しなければなりません。
この文字コードからCIDへの変換を定義するのがCMapです。
図 CMapで文字コードからCIDへ変換
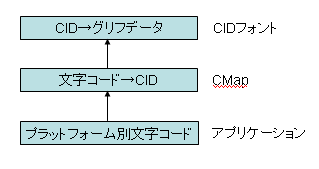
アドビシステムズはAdobe-Japan1、Adobe-GB1などのグリフセット毎に多数のCMapファイルを提供しています。古いCMapにはNECのPC、富士通のPC、Windows3.1、マッキントッシュなど機種依存文字コードからCIDへの変換用が沢山あります。しかし、最近のCMapはUnicodeからCIDへの変換用が中心になっています。
例えばAdobe-Japan1用の比較的新しいCMapには次のようなものがあります。
| CMap名称 | 内容 |
|---|---|
| UniJIS-UTF8-H | Unicode 3.2 (UTF-8) からCID |
| UniJIS-UTF8-V | UniJIS-UTF8-Hの縦書用 |
| UniJIS-UTF16-H | Unicode 3.2 (UTF-16) からCID |
| UniJIS-UTF16-V | UniJIS-UTF16-Hの縦書用 |
| UniJIS-UTF32-H | Unicode 3.2 (UTF-32) からCID |
| UniJIS-UTF32-V | UniJIS-UTF32-Hの縦書用 |
| UniJISX0213-UTF32-H | Unicode 3.2 (UTF-32) からCID Mac OS X Version 10.2互換 |
| UniJISX0213-UTF32-V | UniJISX0213-UTF32-Hの縦書用 |
各CMapファイルには、横書用(-H)と縦書用(-V)の2種類があることに注意してください。これは次のような仕組みです。
(1)文字によっては横書と縦書で表示・印刷用の字形が異なるものがあります。
(2)グリフセットには、これらの文字に相当するグリフには横書用と縦書用の2種類が用意されています。(次の例)
横書用グリフの例: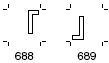
縦書用グリフの例:
※Adobe-Japan1-6 Character Collection for CID-Keyed Fonts p. 12, p. 76
末尾に-Hの付くCMapを使うと、文字コードから横書用グリフのCID番号に変換することになり、同-Vの付くCMapを使うと、縦書用グリフのCID番号に変換することになります。
OSやアプリケーションの文字コードを内部コードと言うと、CID番号の付いたグリフは表示層と言えます。この内部コードと表示層を分離して、CMapで仲立ちをさせていることになります。この仕組みでフォントをプラットフォームの文字コードから独立にした、ということがCIDフォントの意義ということになります。
但し、CMap方式で入力値として指定できるのは単一コードになります。縦書と横書に対してCMapを切り替えることで、単一の入力コードからそれぞれ異なるグリフを得るCIDフォント方式は、漢字やかなのような単純な記法の文字を使う日本語や中国語などしか適用できないでしょう。例えばアラビア文字や南インド文字、あるいはラテン文字の結合やリガチャには対処し難いように思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月16日
PDFと文字 (24) – Adobe-GB1, Adobe-CNS1, Adobe-Korea1
アドビシステムズのテクニカル・ノートでは、Adobe-Japan1の他に、Adobe-GB1, Adobe-CNS1, Adobe-Korea1の3つのグリフセットが公開されています。これらをざっと見ておきます。
Adobe-GB1は、中国の簡体字用のグリフセットで、GB 2312-80、GB 1988-89、GB/T 12345-90、GB 13000.1-93、GB 18030-2000用のグリフ29,063種類を含んでいます。
| 領域 | CID範囲 | Adobe-GB1 | 説明 |
|---|---|---|---|
| 追補0 | 0~7716 (7,717個) | Adobe-GB1-0 | GB 2312-80、GB1988-89文字規格用のグリフ。GB/T 12345-90で規定する縦書グリフを含む |
| 追補1 | 7717~9896 (2,180個) | Adobe-GB1-1 | GB/T 12345-90のグリフ。Adobe-GB1-0に繁体字を追加する。 |
| 追補2 | 9897~22126 (12,230個) | Adobe-GB1-2 | GBKとUnicodeV2.1の20,902漢字をサポートするためのグリフ |
| 追補3 | 22127~22352 (226個) | Adobe-GB1-3 | 半角とプロポーショナルグリフの回転済のもの。 |
| 追補4 | 22353~29063 (6,711個) | Adobe-GB1-4 | 大部分は、UnicodeV3.0のCJK統合漢字拡張A用 |
※Adobe-GB1-4 Character Collection for CID-Keyed Fonts 2000年11月30日
Adobe-CNS1は、台湾の繁体字用のグリフセットで、主にBig-5とCNS 11643-1992規格をサポートするためのものです。一部に香港用の文字を含んでいます。
| 領域 | CID範囲 | Adobe-CN1 | 説明 |
|---|---|---|---|
| 追補0 | 0~14098 (14,099個) | Adobe-CN1-0 | Big-5とCNS 11643-1992の1面、2面、およびBig-5のETen拡張用 |
| 追補1 | 14099~17407 (3,309個) | Adobe-CN1-1 | 香港政庁の漢字文字セット、モノタイプ、ダイナラブ社の文字の一部 |
| 追補2 | 17408~17600 (193個) | Adobe-CN1-2 | 半角とプロポーショナルグリフの回転済のもの。 |
| 追補3 | 17601~18845 (1,245個) | Adobe-CN1-3 | 香港の追加文字セット |
| 追補4 | 18846~18964 (119個) | Adobe-CN1-3 | 香港の追加文字セット(追加) |
※Adobe-CNS1-4 Character Collection for CID-Keyed Fonts 2003年5月27日
Adobe-Korea1は、韓国のKS X 1001:1992 (旧KS C 5601-1992)、KS X 1003:1992 (旧KS C 5636-1993)をサポートするためのグリフセットです。
| 領域 | CID範囲 | Adobe-Korea1 | 説明 |
|---|---|---|---|
| 追補0 | 0~9332 (9,333個) | Adobe-Korea1-0 | KS X 1001:1992、KS X 1003:1993とアップルのマッキントッシュ用の拡張 |
| 追補1 | 9333~18154 (8,822個) | Adobe-Korea1-1 | KS X 1001:1992のJohabとWindows 95の統合ハングルコード拡張 (UHC) |
| 追補2 | 18155~18351 (197個) | Adobe-Korea1-2 | 半角とプロポーショナルグリフの回転済のもの。 |
※Adobe-Korea1-2 Character Collection for CID-Keyed Fonts 2003年5月27日
しかし、これらはどうも古いですね。Adobe-GB1なんて2000年の日付になっています。それに肝心のGB18030がカバーされていません。Adobe-CN1、Adobe-Korea1いづれも2003年5月です。これに対して、Adobe-Japan1は2004年6月なので比較的新しいですが。中国や台湾ではアドビシステムズはあまりまじめにやってないのでしょうか?そんなことはないと思いますが。分かりません。
【2006/5/3 追記】
GB18030をカバーしてないんじゃないの?と書いて、ちょっと物議をかもしてしまったようなので削除しておきます。どうして、カバーしてないと書いたか忘れてしまいましたが、多分、間違いでしょう。Adobe-GB1で規定されている字形の総数(29,063)は、GB18030:2000で字形が記述されている文字数(28,522)よりは多いようです。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2006年01月15日
PDFと文字 (23) – Adobe-Japan1
Adobe-Japan1とは日本語表記に使う文字のグリフを集めて、各グリフを識別するCIDという認識番号を付けたものです。
0から6までの版があり、版数が大きくなるに従い、新しいグリフが追加されます。最新のAdobe-Japan1-6には、合計23,058種類のグリフを集めています。
各版に追加されたグリフの概要は次の表の通りです。
| 領域 | CID範囲 | Adobe-Japan1のセット | 説明 |
|---|---|---|---|
| セクション3 | 0~8283 | Adobe-Japan1-0 | JIS X 0208 1978と1983、JIS X 0201-1997、アップル、富士通、NECの文字セット。 |
| セクション4 | 8284~8358 | セクション3~4でAdobe-Japan1-1になる | マッキントッシュの漢字Talk7.1用文字、JIS X0208-1990、富士通とNECが追加したグリフなど。 |
| セクション5 | 8359-8719 | セクション3~5でAdobe-Japan1-2になる | Windows3.1J用のグリフを追加。 |
| セクション6 | 8720~9353 | セクション3~6でAdobe-Japan1-3になる | 半角とプロポーショナルグリフの回転済のもの。 |
| セクション7 | 9354~15443 | セクション3~7でAdobe-Japan1-4になる | 専門的、商業印刷に使うグリフを追加 |
| セクション8 | 15444~20316 | セクション3~8でAdobe-Japan1-5になる | JIS X 0213:2004標準を完全にサポートするためのグリフを追加 |
| セクション9 | 20317~23057 | セクション3~9でAdobe-Japan1-6になる | JIS X 0212-1990、共同通信のU-PRESS文字集合をサポートするためのグリフを追加 |
※Adobe-Japan1-6 Character Collections for CID Keyed Fonts, Technical Note #5078, 11 June 2004 (PDF)
Adobe-Japan1-6の仕様書の名称は、「Adobe-Japan1-6 Character Collection for CID Keyed Fonts」と言います。名前から想像すると、もともとCIDフォントの開発者向けに用意されたものと思います。しかし、CIDフォントは既に古いものになり、新しいOpenTypeフォントにとって変わられつつあります。従って、現時点でのAdobe-Japan1の役割は、OpenTypeフォント開発者向けのグリフ一覧表ということになります。
なお、Adobe-Japan2というJIS X 0212用グリフセットもありましたが、Adobe-Japan1-6のセクション9に吸収されて廃止されました。
Adobe-Japan1は、例えば、セクション3に90度回転済の半角文字のグリフが収容されていたり、セクション4にも回転済みのグリフが収容されています。これらはOpenTypeフォントにおける縦書用のグリフを提供するものです。
また、セクション7には商業印刷用の漢字と異形字(kanji variants)が2,124個収容されています。
※Adobe-Japan1-6 Character Collection for CID-Keyed Fonts p.96
これらの回転済みのグリフはもちろんのこと、漢字の異形字にはJISやUnicodeで規定されていないものを含んでいますが、これらはOpenTypeフォントでないと使うことができないとされています。
なお、小形克宏の「文字の海、ビットの舟」――文字コードが私たちに問いかけるもの 特別編26では、「まず「文字の形」から集め、次に文字コード規格と対応づける」と述べていますが、Adobe-Japan1は、まさしく文字の形をあつめたものに相当することになります。このようにアドビシステムズは、各種の国内標準規格や、主要なメーカ、ユーザが必要とする文字のグリフを集めてこれにCIDという番号をつけてフォントの開発者向けに提供しているわけです。
投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年01月13日
PDFと文字(22) – グリフとグリフセット
符号化文字集合とは別の観点から文字を集めた集合にグリフセットというものがあります。PDFReferenceには次のようなグリフセットの名前が参照されています。
・Adobe-Japan1
・Adobe-GB1
・Adobe-CNS1
・Adobe-Korea1
※PDFReference(5版 PDF1.6) pp.416-417
グリフセットの仕様書は、アドビシステムズのFont technical notesのページのCJK/CID-Keyedfontsとして公開されています。
グリフセットの検討に入る前に、グリフ(Glyph)とはなにかについて調べてみます。
PDF Referenceには次のような記述があります:
「文字は抽象的な記号なのに対して、グリフは文字を可視化した形状である。...歴史的に、コンピュータによる組版の世界では、この二つは交換可能な用語として使われてきた。しかし、この領域の進歩によりだんだん意味の違いが明確になってきた。」
※PDFReference p.358
文字とグリフについて使い分けるようになったのは比較的最近のことのようです。このため、PDF Referenceの中には混同した名前が使われている箇所がある、と書かれています。
コンピュータで文字を表示したり印刷するときはフォントを使いますが、グリフのデータはフォント・ファイルに収容されています。各文字のグリフは、ビットマップ・フォントで表現されている場合もありますが、アウトライン・フォントではグリフをプログラムまたはそのパラメータとして記述しています。
フォント関連の用語については、フォント情報処理用語も参照してください。
なお、Answers.comでGlyphを引いてみますと、次のような文章が見つかります。
In computing as well as typography, the term character refers to a grapheme or grapheme-like unit of text, as found in natural language writing systems (scripts). A character or grapheme is a unit of text, whereas a glyph is a graphical unit.
For example, the sequence ffi contains three characters, but will be represented by one glyph in TeX, since the three characters will be combined into a single ligature. Conversely, some typewriters require the use of multiple glyphs to depict a single character (for example, two hyphens in place of a dash, or an overstruck apostrophe and period in place of an exclamation mark).
---ここまで---
(訳)
コンピュータ処理では、組版と同じように、文字は、テキストの書記素または書記素のような単位。...文字または書記素はテキストの単位であるのに対し、グリフは図形の単位である。
例えば、ffiは3つの文字を含んでいるが、TeXでは一つのグリフで表されるだろう。...逆に、タイプライターによっては、一つの文字を複数のグリフを用いて表す。
---以上---
用語にこだわるようですが、グリフという用語を調べていてグリフを字体としている文書がいくつか見つかりました。
たとえば、
(1) CHISEプロジェクトの「グリフ・字形情報の統合と合成」ページには、次のような記述があります。
文字データベースに字形やグリフ(字体)に関する情報を収録し、 文字に関する知識とグリフ・字形を統一的に扱うシステムを実現します。
(2) 「文字コード標準体系専門委員会報告書」(情報処理学会の情報規格調査会、2002年3月)のレポートでは、字体と字形を次のように定義しています。
字体 (glyph)
文字の抽象的な形 (骨格) の概念で、文字の骨組みなどともいわれ、具体的に視覚化することは不可能である。(ISO/IEC TR15285、国語審議会資料などから。)
字形 (glyph image)
印字・表示などの手段によってグリフ表現を表示 (presentation) することによって得られる“glyph”の可視化表現で、必然的に何らかの書体によってしか表示できない、一般的な意味で文字出力と言われるもの、あるいは、印字・表示・転写・手書きなどによって可視化された結果の文字。
※同報告書 p.69
どちらが正しいと即断はできませんが、グリフという言葉の意味するところに専門家の間でもかなりの違いがあることは確かに思います。とりあえず、このブログでは、PDF Referenceの使い方を採用します。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月12日
PDFと文字(21) – 大文字セット
漢字の大文字セットを使うことができるものには次のようなものがあります。
1.まず、今昔文字鏡です。
・文字鏡研究会のWebページ:
http://www.mojikyo.gr.jp/
・文字鏡関係製品のWebページ
http://www.mojikyo.com/
諸橋轍次著『大漢和辞典』に収録されている約5万の見出し漢字を含め、日本・中国・台湾・韓国・ベトナムの漢字12万字を収録しています。他に、また、梵字・甲骨文字などまで入っているようです。
文字鏡はなかなかすごいプロジェクトだと思います。日本で漢字についてこのようなデータが作成されていることはすばらしいことです。
2.次は、東京大学多国語処理研究会が作成しているGTフォントです。
http://www.l.u-tokyo.ac.jp/GT/
漢字が約67,000字TrueTypeフォントとして作成されているようです。
GTフォントはWindows上でも使うことができるようです。
また、BTRONをOSに使っている超漢字もGTフォントを使っています。
2005年12月の日経ネットの記事によりますと、TRONプロジェクトを率いる東大の坂村教授は、約12万字からなる世界最多の漢字フォント集を作成した、と発表しています。これは、文字数がGTフォントの2倍近くなっていますが、GTフォントとどんな関係なのでしょうかね?
3.それから島根大学のe-漢字データベースがあります。
http://ekanji.u-shimane.ac.jp/
・大漢和辞典((株)大修館書店発行) 50305字
・康煕字典の49188字
・Unicodeの20902字
・新字源((株)角川書店発行) 約9900字
の漢字コードから字形を検索できます。
それにしても、漢字の話になりますと必ずと言っていいほど、『康煕字典』が登場します。
この辞典はもともとは、清朝の皇帝が作ったものなのだそうです。清朝の国家プロジェクトということです。できたのは18世紀の初頭ですから、比較的新しいものですが、日本では江戸時代1780年ということ。そうしてみますと、漢字の歴史が数千年といっても、現代漢字の典拠ができてから、まだ300年経っていないと言って良いのでしょうか?
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月11日
PDFと文字(20) – 字体と字形
加藤 弘一氏の「ほら貝」には「文字コード問題を考える」というページがあり楽しい読み物が沢山公開されています。
ほら貝:文字コードの「二千年紀の文字コード問題」の2.小文字セットと大文字セットで、加藤氏は次のように述べています。
---加藤氏の文章引用:ここから---
①JISや Unicode側では、字体レベル以上の包摂をおこなっても、フォント名指定で字体を特定すればよいと考えているようである。文字コードは複数の字体をふくむ粗い網の目にとどめておき、個別の字体は文字コート+フォント名であらわすわけだ。この立場を小文字セットと呼ぼう。
②それに対して、個別の字体ごとにコードを割り当てていくという立場もある。字形を分類する網の目が密になり、コードポイントが増えるので、大文字セットと呼ぶことにする。
現在の文字コードをめぐる論点は、結局、小文字セットを選ぶか大文字セットを選ぶかの問題に集約されると考える。
---ここまで---
この文章の後ろの方で、加藤氏は要するに小文字セットを否定して、大文字セットが良いと言っています。また、氏は、漢字の統合、特に国を超えての統合には反対のようです。
小文字セットと大文字セットの対照はなかなか興味深いと思います。そこで、これを少し検討してみましょう。
ところで、ここ1、2週間、漢字を符号化文字集合として、どうやって扱ったら良いかという問題意識で、いろいろと資料に眼を通しています。そこで、まず感じたのは、最初に用語を定義しておかないといけないな、ということです。そうしないと、もともとヤヤコシイ話が、ますます混沌として訳が分からなくなってしまいそうです。少し用語を見ておきましょう。
例えば、上で引用しました加藤氏の文章での「字体」は、JIS規格の定義では、「字形」に相当するのだろうと思います。
JIS X0213の用語定義は次のようになっています:
i) 字体 図形文字の図形表現としての形状についての抽象的概念
h) 字形 字体を、手書き、印字、画面表示などによって実際に図形として表現したもの
※JIS X0213 : 2000 p.3より。
JIS X0213規格(以下、JIS規格と言います)の用語定義、特に、字体は理解しにくいですね。まず、文字を視覚的に表記することを想定し、視覚的表記には文字を表す図形を使うということを想定しています。
Unicodeではコードポイントと言いますが、JIS規格では面区点位置と言います。
JIS規格(漢字部分)は、コードポイントに漢字の字体を一つづつ割り当てます。この時、字体は抽象的なものなので、割り当て表は、具体的な例として例示字体を示し、字書の音訓、用例などを添えて定めている訳です。例示字体で示されている図形はあくまで例です。JIS規格では字形については規定していないと明記されています。
なお、Unicodeの用語では、抽象的形状(abstract shape)という言葉が使われていますが、これがJIS規格の用語では字体に相当すると思います。
フリー百科事典『ウィキペディア(Wikipedia)』で字体の項を見ますと、概ね、JIS規格と同じで、字体とは「図形を一定の文字体系の一字と認識し、その他の字ではないとしうる範囲に対する概念」となっています。
ここには、字形の説明もありますね。このWebページは書きかけの状態とされていますが、概ね、納得できます。そこで、今後は、ある漢字の字体というときは、抽象的形状を意味し、漢字の字形というときは、その漢字が具体的に印刷・表示される形状として使うことにします。
こうしてみますと、加藤氏の文章は、JIS規格と比べて字体と字形の言葉の使い方が逆じゃないでしょうか?
デザイン面に着目すると、字体はデザイン要素を捨て去ったものですが、当然、字形には文字デザインによる相違をも含んでいます。符号化文字集合で文字を区別する際にデザイン要素までを考慮せよ、という意見を述べる人はいないと思います。つまり、字体ではデザイン要素を捨て去って考えることについては合意されているでしょう。では、デザイン要素はどうなるの?ということは後で検討します。
字形と字体の相違はデザイン要素による相違だけではありません。その前に、もっと難しい問題があります。
一番ややこしいのが一般に異体字と言われているものです。先の『ウィキペディア(Wikipedia)』では、次のように説明されています。字体は同じだが異なる字形、ある正字体系の標準的な字形と異なる字形、或は字源は同一でも別の字体と認識される字体のこと。そうして、異体字の例を次の5種類に分けて示しています。
1. 字体の構成要素の位置が異なるもの。
2. 異なる音符を使ったもの。
3. 異なる意符を用いたもの。
4. 一方が形声で作られ、一方が会意で作られたもの。
5. 会意や形声の仕方が異なり、字形上の共通項がないもの。
さらに、ひとつの漢字には、正字・俗字という字形区分もあります。
日本では新字・旧字という字形の区分もあります。
中国では、1950年代に、簡体字を定めたため、ひとつの漢字に旧来の繁体字と簡体字というふたつの図形表現の体系ができてしまいました。
フリー百科事典『ウィキペディア(Wikipedia)』の漢字の項も参照。
このように字体を抽象的な形状というのは簡単ですが、では符号化文字集合を作る際には、特に漢字の場合、実際にどうやってこれを規定するかが難しいわけです。誰が作業しても同じに結果になるであろうような規定を定めない限り、科学的に符号化文字集合を作成することができません。
違う規定を使えば符号化文字集合は別のものになってしまうでしょう。Unicodeの漢字統合のように途中で規定が振れてしまえば、実際上、やむをえず使うにしても、理屈の上では破綻状態です。
投稿者 koba : 08:00 | コメント (1) | トラックバック
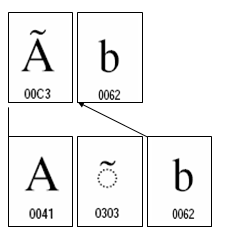
2006年01月10日
PDFと文字(19) – 漢字統合問題再検討
Unicode4.0では、既に漢字を7万字以上も規定しています。さらに統合漢字拡張Cとして新たな漢字の追加を計画しているようです。
しかし、1月5日、1月6日には、①Unicodeの漢字統合の基礎になるはずの3次元モデルが曖昧で間違った解釈がなされていること。②その結果、統合ルールも不整合になっていること。③新しく追加した漢字の中には同じ抽象的字形を別のコードポジションに重複して登録しているものがあるなど、既に大きな問題を抱えていて、Unicodeの漢字統合は破綻していると述べました。
このような状況で新しい漢字を追加することは、新たな混沌をもたらすだけではないでしょうか?
これに対して、どのように考えたら良いのでしょうか?
「日本の苗字七千傑」というWebページのQ&Aを見ますと、
Q4.日本の苗字は何種類の漢字が必要か?
という項があります。
これによりますと、住民基本台帳ネットワークでは、非公開の統一文字コード(約二万一千字)を外字として使用していて、JIS X0213でも漏れている文字があるとのこと。さらに、苗字拾遺を見ますと、Unicode外(とされている)漢字の例も見ることができます。
このようなことからだけでも、標準文字規格に新しい漢字を追加して欲しい、という強い要望があるだろうことは容易に予想されます。では、その要望通り追加したら良いのではないか、と思われますが、事はそう簡単ではありません。標準規格に文字を追加することは、後で検討しますように、社会全体では相当に大きな額のコストがかかるだろうと思います。
しかし、自分の苗字位は正しく書きたいのは人情です。これに応えられなければ、プロの名が泣くというものです。
大口たたいたな。じゃあ、お前、解決策を示してみろ?と問われれば:
私は、現段階では実際のところ直感的にですが、PDFを使うことによって標準規格の漢字字種不足および漢字統合に関する問題を、すべて、比較的簡単に解決できるのではないかと考えています。このことについては、このブログですこしづつ検討したり、説明していきたいと思っていますので、お楽しみに :-)
つまり、私たちの時代は、漢字の標準規格に新しい漢字をそれほど沢山追加しなくても、世の中に出現する漢字を自由自在に取り扱う技術を有していると思うのです。ですので、これから、何万種類もの漢字を標準に追加したり、管理する作業は行わなくても良いのではないか、いや、むしろ社会的コストを考えますと漢字を増やすのはできるだけ止めるほうが良いのではないかと考えています。
そういっても、実際のところどうなの?本当にPDFですべての問題を解決できるの?ということもあると思います。
それに万人を説得できる証拠を提示することも必要でしょうし。そうなりますと、もう少し漢字のことを調べてみなければなりませんね。そんなわけで、漢字から先へ進めなくなってしまいました。そんなつもりじゃなかったんですが :-)
※補足
なお、統合漢字拡張Bには次のような疑問を感じる漢字もありますが、次の漢字は正しいのでしょうか?
・天地が逆ではないでしょうか?それとも逆さまであることに意味があるのかな?
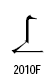
・白抜きの部分はどう解釈すべきでしょうか?


投稿者 koba : 08:00 | コメント (2) | トラックバック
2006年01月09日
PDFと文字(18) –Unicodeの漢字関連ブロック
Unicodeには今までに述べた統合漢字、互換漢字以外に、漢字に関連するブロックが、①漢文、②部首、③漢字を組み立てるためのコードの3つがあります。
これらについて次に簡単にまとめておきます。
①漢文 U+3190~U+319F
中国語の漢字の文章を日本語で読むための記号です。学校の漢文の授業などでならったものです。
②部首 U+2E80~U+2FD5
辞書の索引などで使う部首が規定されています。
・康煕部首(U+2F00~U+2FD5) 214種類の部首用文字
・CJK補助部首(U+2E800~U+2EF3) 115種類の部首の派生形、または簡体字用部首
これらの文字は部首であることを示すため専用で、統合漢字と同等のものとして扱うことはできません。
③漢字を組み立てるためのコード
統合漢字や互換漢字はひとつひとつの漢字を図形文字として識別して番号を与えていくという方式です。これに対して、漢字を別の漢字の部品として使って、新しい漢字を組み立てるという考え方が、1970年代から研究されてきたようです。
この方式には、いくつかの方法がありますが、その一つがIDS(Ideographic Description Sequence)という方法です。このIDSで用いる文字をIDC(Ideographic Description Characters)と言い、U+2FF0~U+2FFBに12文字が規定されています。
IDCは結合文字(他の文字とまとめてひとつの文字にする文字)ではなく、また、通常の図形文字の代替表現を提供するために用いるものではないとされています。Unicode準拠アプリケーションは、IDS方式の文字の並びを表示する際、一つの文字として表さなくてもかまいません。
IDCは、もともと中国の文字規格GBKでGB2312-80にないUnicodeの文字を追加するために盛り込まれたものです。そこで、Unicodeでは、IDSをまだ符号化されていない文字を既存の文字を組み合わせて表現するための方法と位置づけています。
【IDSの応用例】
IDSを、既存の漢字の構造を表すために使っている例もあります。
京都大学の人文科学研究所の守岡氏らは、文字に関する知識データベースの作成とその利用を開発するCHISEプロジェクトを行っています。CHISEプロジェクトの中で、このIDSを用いて漢字を表す構造情報データベースを開発中です。
■参考資料
1.CHISEプロジェクトについて
http://www.kanji.zinbun.kyoto-u.ac.jp/projects/chise/
2.CHISE / 漢字構造情報データベース
http://www.kanji.zinbun.kyoto-u.ac.jp/projects/chise/ids/
投稿者 koba : 08:00 | コメント (0) | トラックバック
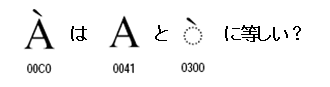
2006年01月07日
漢字統合の3次元モデルについてKen Lundeの誤り
Ken Lunde著「CJKV日中韓越情報処理」という本は、コンピュータによる漢字処理の専門家にとっては必読書とされている重要な書籍です。
この本のUnicodeの漢字統合の説明の箇所でUnicodeの3次元モデルが紹介されています。Unicode仕様書は英文しかありませんし、実際のところKen Lunde本で3次元モデルを見た人の方が多いかもしれません。ところが、今回、Ken Lundeの本に紹介されている3次元モデルの図は間違っていることに気が付きました。
Unicodeの仕様書の図は次のようになっています。
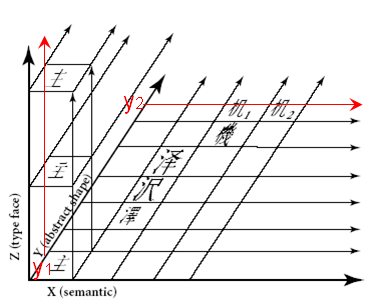
※「The Unicode Standard 4.0」 p.299の図を引用
赤の座標値と矢印は、私が追加。
Y軸の座標値が同じである漢字の例として、抽象的形状が同じでセマンテッィク(Ken Lunde本の訳では字義)が異なるとして、その例として、機械の”機”の略字![]() と”机”
と”机”![]() が出ています。
が出ています。
また、抽象的形状が同じで書体が異なる例が、Z軸方向に配置されています。
これに対して、「CJKV日中韓越情報処理」には図3-1 漢字の字形を比較する3次元モデルとして、次の図が掲載されています。

※「CJKV日中韓越情報処理」の日本語版(2002年12月刊)p.123の図を引用
赤の座標値と矢印は、私が追加。
Ken Lundeの図で、Y軸の座標値が同じである漢字とは、X軸、Z軸と平行な赤色の矢印で示す位置にある漢字となります。この図では、Y軸の定義とされている座標値が同じ文字は抽象的形状が同じが満たされていません。つまりKen Lundeの図は、Unicodeの3次元モデルの正しい説明になっていません。
ところで、この部分、日本語版の説明は次のようになっています。
漢字の字形は、3次元モデルによって比較することができる。X軸(字義)は、漢字を意味によって分け、Y軸(抽象形状)は、X軸上の漢字を抽象化された形状(同定し得る形状)毎に分ける。つまり、ある漢字の正字体と簡略字体は同じY軸の上に置かれる。Z軸(字形/書体)は漢字を字形の違いによって分ける。
(p.122 下から10行目~下から6行目)
このアンダーラインの部分は、座標軸としてのY軸の解釈を間違えていると思います。そこで念のため原文に当たってみたのですが、原文は次のようになっています。
...Traditionnal and simplified forms of a particular Chinese character fall into the same X axis position, but have different position along the Y axis. ..
(CJKV Information Processing, by Ken Lunde, January 1999, First Edition, p.124)
日本語版は訳が誤っていますね。正しくは、次のようになります。
中国の漢字の正字体と簡略字体は、X軸上では同じ位置になる、しかし、Y軸に沿っては異なる位置になる。
原書で図と本文の説明の意味が食い違っているため、図の意味が分からなくて、翻訳者たちも苦労したのでしょうね。「CJKV日中韓越情報処理」は、”バイブル”と言われている本ですので、ぜひ、誤りを修正してほしいものです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月06日
PDFと文字(17) – 統合漢字の理論
そもそも、日本、中国、韓国などの漢字を統合しようというのは誰が考えたのでしょうか?
Unicodeを最初に考えた人たちは、日本、中国などの漢字の文字数があまりにも多く、コードスペースの中に入りきらないという単純な動機から、同じ形の漢字に一つのコードポイントを与えようと考えたのではないかと思います。
しかし、その後の進展で、日本、中国、韓国などの専門家が参加するところとなり、漢字統合の理論を誰かが考えたようです。Unicodeの仕様書では、CJK統合漢字の理論は、3次元概念モデルとして、次のような図を用いて説明されています。この図は、漢字の簡体字が入っていますので、多分、北京の中国人の考案でしょう。
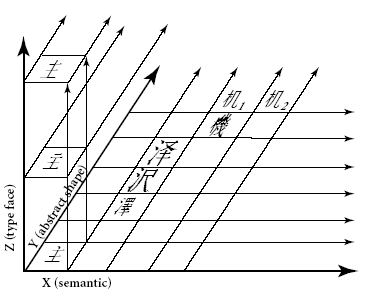
(Unicode仕様書 V4.0 Fig.11-3 p.299 より引用)
ここに、X軸はセマンティック(意味または機能)、Y軸は抽象的形状、Z軸はタイプフェース(書体)とされています。
この概念モデルに基づいて、日本、中国、韓国などの漢字をひとつにまとめたと説明しています。しかし、Unicodeの仕様書を読んでも、どうも統合にあたってのセマンティック軸の扱いが明確になっていません。そこで、この部分を私なりに検討してみました。
■仕様書V2.0では次のように書かれています。
Only characters that have the same abstract shape (that is, occupy a single point on the X and Y axes) are potential candidates for unification. Z axis typeface and semantic differences are generally ignored.
(Unicode V2.0 仕様書 p. 6-108、下から10行目~8行目)
※アンダーラインは私が付けました。以下、同じです。
3次元概念モデルでは、Y軸上で同じ位置の漢字が同じ抽象的な形状となります。抽象的形状が同じものをまとめるということは、Z軸とX軸を無視することになります。ですので上の文章は正しくありません。私の考えでは、正しくは次の文章になるはずです。
Only characters that have the same abstract shape (that is, occupy a single point on the Y axis) are potential candidates for unification. Z axis typeface and X axis semantic differences are generally ignored.
上の図の例で、セマンティックを無視すれば、![]() と
と![]() は統合され、ひとつのコードポイントが与えられます。
は統合され、ひとつのコードポイントが与えられます。
※ちなみに、この二つは字形が同じで意味が違う例として、![]() は”機械”を意味し、
は”機械”を意味し、![]() は、”机”を意味すると説明されています。
は、”机”を意味すると説明されています。
■ところが、V3.0仕様書から以降、この部分が次のように訂正されています。
Only characters that have the same abstract shape (that is, occupy a single point on the X and Y axes) are potential candidates for unification. Z axis typeface and stylistic differences are generally ignored.
(直訳)
同じ抽象的形状をもつ文字(すなわち、XとY軸の上でひとつの点を占める)のみが統合化の潜在的候補となる。Z軸のタイプフェースとスタイルの違いは一般に無視する。
この新しい説明では、セマンティック(semantic)がスタイル(stylistic)に代わってしまいました。そして、無視されるのはZ軸(タイプフェースとスタイル)のみとされています。
セマンティックの扱いは明確に書かれていません。しかし、X及びY軸で同じ位置にあるものが抽象的形状が同じ、と言っているわけですから、セマンティックが抽象的形状の一要因になったということに等しいわけです。言い換えるとセマンティックが違えば抽象的形状が違うとみなす、と暗黙に示したことになります。
このあたり、3次元(立体)で考えるのは難しいので、わかり易くするため、2つの軸、X軸×Y軸を1次元に展開して、図を書き直すと次のようになります。
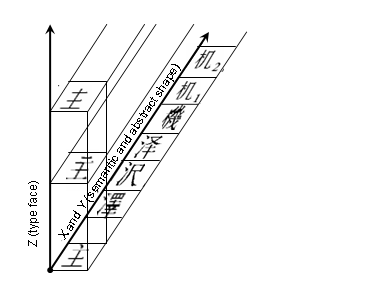
※この2次元の図は私が作りましたが、上の3次元の図と同等なはずです。
V3.0以降の仕様書では、この図でZ軸のみが無視されると言っています。ですので、![]() と
と![]() は別のコードポイントが与えられることになります。
は別のコードポイントが与えられることになります。
言い換えると、V3.0以降では同じ抽象的形状でもセマンティックが異なれば統合の候補にならない。抽象的形状とセマンティックが共に同じ漢字のみが統合の候補になると変更したことになります。
※しかし、仕様書には、統合ルールは、原規格分離規則以外は、変更してないとも書いてあります。従って、仕様書の説明に矛盾を含んでいます。
X軸、すなわちセマンティックについて考えて見ます。同じ字形の漢字でも言語によって意味が変わったり、新しい意味が付加されたりすることが多く、言語の違いがセマンティックに重要な影響を及ぼすのは明らかです。従って、字形が同じでもセマンティックが違えば別のコードポイントを与えるとなると、中国語、日本語、韓国語、ベトナム語という異なる言語の中で出現する漢字を字形で統合するのは至難になります。乱暴に言えば、セマンティックを無視しなければ、CJKVの漢字統合はできないのではないでしょうか。
結局、概念モデルではセマンティックを無視しないと言い、実際の作業はセマンティックを無視して漢字統合したということで、示した理論と実際にやったことが矛盾してしまったように思います。
V1.0でCJK漢字を統合すると言いながら、原規格分離規則によって、これを徹底できずにV3.0では原規格分離規則を廃止したというように、漢字統合ルールも振れています。
昨日、Unicodeの漢字統合は破綻してしまったと言いましたが、その原因を辿っていけば、ルールの基になる概念=3次元概念モデルが曖昧だったためではないでしょうか?
20世紀最大の偉業のはずなんですが。残念。漢字統合は、21世紀にもう一度やり直しが必要なんでしょうね。
[2006/3/15]
芝野先生のご指摘により、一部削除しました。
また、CJK統合理論が生まれた経緯につきましては、芝野先生、安岡先生にコメントをいただいていますので、そのあたりをご参照ください。
※英文にするときは、全体を修正しなければなりませんね。翻訳が遅れていますので、いつのことになりますか?
投稿者 koba : 08:00 | コメント (7) | トラックバック
2006年01月05日
PDFと文字(16) –漢字統合の破綻
Unicodeの漢字統合は、中国、日本、韓国で同じ字形の漢字をひとつのコードポイントにまとめた、と言いました(1月3日)。しかし、UnicodeV3.1の統合漢字拡張Bを調べてみますと、UnicodeのCJK漢字統合は破綻してしまったのではないかという印象をもちます。
ここにいくつかその例を挙げます。
1.一般統合漢字と同じ漢字が定義されている例
○一般統合漢字

○統合漢字拡張B
この2つの漢字は字形が完全に同じものではないでしょうか?なぜ、まったく同じ字形を別のコードポイントに追加したのでしょう?
2.一般統合漢字に統合されるはずの漢字が別に定義されている例
(1) ハネの有無
○一般統合漢字
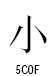
○統合漢字拡張B
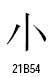
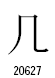
この2組の漢字は、ストローク終端のハネの違いです。ストローク終端のハネの違いは、書体の違いとして統合するという例がUnicodeの仕様書に出ています。しかし、統合漢字拡張Bで分離されて新しいコードポイントを与えてしまいました。
(2) 点の有無
○一般統合漢字


○統合漢字拡張B


この2組については、1月3日に日本語と中国語の字形の例で示しました。一般統合漢字では、点のある器と点のない器、点のある突と点のない突は、ひとつのコードポイントに統合されています。ところが、統合漢字拡張Bで、点のない器と点のない突が、新たに別のコードポイントを与えられてしまいました。
これは、統合漢字拡張Bのコードチャートを1,2時間ざっとみて見つけたものです。コードチャートを詳細にチェックすると他にもこのような例が一杯出てくるのではないかと思います。
Unicodeの仕様書では、一般統合漢字と統合漢字拡張の統合ルールは、原規格分離規則を除いて同一と説明されています。しかし、上の例で示しましたように、実際のコードチャートを見ると、それ以外にも統合ルールが違っていることになります。この統合ルールの変更は仕様書に書いてない、闇ルールということになります。
Unicode仕様書によれば、統合漢字拡張Bには、使用制限がなく、一般統合漢字と混在使用できます。従って、一つの漢字に複数のコードポイントを与えてしまった問題は、理論的に救済不可能と思います。
どうしたら良いんでしょうか?実装の段階で一方を使わないようにするんでしょうか?
それにしても困ったものです。実装者泣かせの仕様書ですね。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月04日
PDFと文字(15) – CJK統合漢字拡張
UnicodeV4仕様書の付録A Han Unification Historyに漢字統合の歴史について書いてありますが、一般統合漢字の作成は中国、日本、韓国の関係者を集めたCJK-JRGという研究グループが行って、UnicodeコンソーシアムとISO 10646に提出したものです。
その後、CJK-JRGはISO/IEC JTC1/SC2/WG2の下の作業グループとなり、名前もIdeographic Rapporteur Group (IRG)と変わりました。UnicodeV3以降で統合漢字が拡張されていますが、この拡張作業はIRGが行ったものです。
また1994年にベトナムの規格を追加しています。
次に、Unicode4の仕様書本文第11章East Asian Scriptsの統合漢字拡張と互換漢字についての説明を要約してみましょう。
統合漢字拡張Aと統合漢字拡張Bは、一般統合漢字と比べてまれにしか使わない文字で、一般統合漢字に統合できない文字を追加したものです。
統合化の規則のなかで原規格分離規則は1992年で廃止されましたので、統合漢字拡張Aと統合漢字拡張Bには適用されていません。それ以外の統合化規則は、一般統合漢字と同じとされています。
統合漢字拡張AはIRGが1993年から1998年にかけて各国の規格と古典から集めて、Unicode3.0でコードスペースBMPに6,582字を規定したものです。
一方、統合漢字拡張Bは、UnicodeV3.0に含まれなかった42,711文字を補助多言語第2面に規定したものです。G(中国)、H(香港)、T(台湾)、J(日本)、K(韓国)、V(ベトナム)の6つの原規格から漢字を集めて整理したもので、ちなみに、日本の原規格として、J3 JIS X 0213:2000の第3水準と同第4水準が入っています。
一般統合漢字、統合漢字拡張A、統合漢字拡張Bの3つのブロックは使用上の制約がありません。
これに対して、互換漢字は、12文字(下記③の文字)を除き、原規格とラウンドトリップする用途のみに使用できる、という制限が付いています。
ラウンドトリップとは、各国別規格に準拠する文字符号化テキストデータをUnicode文字符号化テキストデータに変換し、また、元の文字符号化テキストデータに戻したとき、全ての文字が元のコードに戻るということです。
CJK互換漢字(U+F900~U+FAFF)
361文字が規定されていますが、4種類に分かれます。
①韓国のKS C 5601-1987仕様は一般統合漢字の原規格として使われましたが、その中の268文字は同じ漢字の異なる発音を符号化したものなので、原規格分離規則の例外として一般統合漢字には含めませんでした。そのままではKS C 5601-1987とのラウンドトリップを実現できなくなることから、互換漢字に含め、KS C 5601-1987とのラウンドトリップ専用に使います。
②22文字は他の原規格にあり、統合漢字に含まれる漢字の複製または統合できる派生文字です。原規格とラウンドトリップする目的で含まれているものです。
③12文字(U+FA0E, U+FA0F, U+FA11, U+FA13, U+FA14, U+FA1F,U+FA21, U+FA23, U+FA24, U+FA27, U+FA28, U+FA29)はUnicodeコンソーシアムから出した原典にあります。この12文字は統合漢字の拡張として使うことができます。
④U+FA30~U+FA6Aの59種類の互換漢字はJIS X 0213:2000とのラウンドトリップ専用で他の目的には使えません。JIS X 0213:2000には原規格分離規則が適用されないため、JIS X 0213:2000は統合漢字拡張Aに追加されたにも関わらず、59文字が他の文字と統合化されてしまったための救済措置なのでしょう。
CJK互換補助漢字(U+2F800~U+2FA1D)
CNS 11643-1992の面3, 4, 5, 6, 7,15とのラウンドトリップ専用で他の目的には使えません。これらのCNS文字集合はIRGの統合化規則と大幅に異なる統合化規則を使っていたため、一般統合漢字を決める際に原規格分離の例外として扱われていたのです。しかし、そのままではラウンドトリップができなくなるため救済したのでしょう。
Unicodeの仕様書の漢字の部分を要約しましたのは、Webでいくつか文書を読んでみましたが、どうも、仕様書を読み込まずに、書いているものがあるように見受けられたからです。
このように申し上げている私も、Unicodeの仕様書で統合漢字の部分を精読したのは初めてなんです。お陰でいろいろ分かりました。仕様書を読み込むのは大事ですね。やはり :-)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月03日
PDFと文字(14) – CJK漢字統合問題
漢字に関する大きな問題は12月24日のUnicodeの誕生の記事で出てきましたCJK統合漢字に関するものでしょう。
CJK統合漢字は日本(J)、中国(C)、韓国(K)の3カ国の漢字で字形が似ている文字をひとつのコードポイントにまとめて作られたものです。
JIS X0221-1995(ISO 10646-1:1993に対応するJISの規格で、UnicodeV1.1と対応する)の規格書にはCJK統合漢字の各コードポイントにはC(中国、台湾)、J、Kの各字形が掲載されています。ひとつのコードポイントに最大4つの字形が見本として示されています。
コードポイントに示されている字形によっては、日本の漢字と中国の漢字で字の形が微妙に異なるものがあります。例を次の図に示します。各コードポイントの漢字は、日本の漢字にはMSゴシック、中国の漢字にはSimHeiフォントを指定して表示しましたが、このように期待する字形を表示するには、適切なフォントを指定しなければなりません。
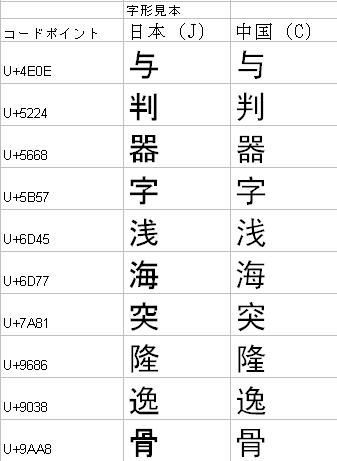
※この表は、「CJKV日中韓越情報処理」(Ken Lunde著、オライリー・ジャパン発行、ISBN4-87311-108-0、、2002年12月24日初版第一刷)のp.128の表3.82ほかの資料より作成。
Unicode4.0の仕様書、あるいは、コードチャートに掲載されている字形は中国の漢字字形になっています。
上のように、コードポイントのデータだけ、つまりUnicodeで符号化したテキストのみでは期待する漢字の形を指定できない場合があることになります。
どうしてこんなことになっているのでしょうか?これを知るために、CJK統合漢字について調べてみましょう。
CJK統合漢字は標準化時期により次の3つに分類されます。
(1)UnicodeV1.0から規定されている20,902文字。これを、このブログでは、便宜上、一般統合漢字と言うことにします。
(2)1992年~1998年に開発作業を行い、UnicodeV3.0で規定された統合漢字拡張A
(3)1998年~2002年に開発作業を行い、UnicodeV3.1で規定された統合漢字拡張B
この他に互換漢字というものがあります。
まず、一般統合漢字ですが、これは次のように作っています。
■原規格
G0 GB2312-80
G1 GB12345-90
G3 GB7589-87
G5 GB7590-87
G7 現代中国で一般的に使用する文字
G8 GB8565-88
T1 CNS 11643-1986/1面
T2 CNS 11643-1986/2面
Te CNS 11643-1986/14面
J0 JIS X 0208-1990
J1 JIS X 0212-1990
K0 KS C5601-1987
K1 KS C5657-1987
※The Unicode Standard V2.0 p.6-105, Table 6-21。V4.0の仕様書p.294, Table 11-1 ではTeが削除されている。
Gxは中華人民共和国、Txは台湾、Jxは日本、Kxは韓国の国内文字規格です。原規格から次のように文字集合を作り上げます。
1.G、T、J、Kの各グループ毎に、重複する文字は捨てて重複しない文字を集める。
2.1.で集めた文字に対して、3.の統合化規則に従って、同じ漢字に同じコードポイントを与える。
まず、概念モデルとして、漢字には①意味、②抽象的形状、③タイプフェース(文字デザイン)の違いがあるとして、②抽象的形状が同じものを統合化の候補とすると述べています。
3.統合化の規則
R1 原規格分離規則:原規格で別のコードポイントが与えられる漢字は別のコードポイントを与える(統合化しない)。
R2 形が似ていても起源が異なるものは統合化しない。
R3 同じ抽象的形状をもっていて、かつ、R1、R2規則で統合化を禁止されない漢字を統合化する。
抽象的形状が同じかどうかを決めるのは難しいと思うのですが、仕様書には次のように書かれています。
①漢字の部品の構造を比較する
②漢字の特徴を比較する
・部品の数
・部品の相対位置
・対応する部品の構造
・原漢字集合での扱い
・部品に含まれる部首
③上の特徴がひとつでも違うと異なる抽象的形状をもつとし、これらの特徴が同じなら抽象的形状が同じとする。
こうやって、CJKの漢字を国を無視して、同じような形状の漢字に同じコードポイントを与えたのです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2006年01月02日
PDFと文字(13) – Unicode文字の検討
Unicodeは、アメリカの企業を中心とする私的コンソーシアムが定めている仕様ですが、文字集合の決定、その符号化方式の仕様はISOという国際標準化団体と一緒に決めていることは、12月25日にUnicodeとISO 10646で説明しました。
(1) ISO 10646の仕様は、各国から代表が集まった委員会で議論・投票をして決定しています。このため、決定内容が各国の思惑の違いに左右されることがあるようです。
(2) そして、Unicodeに収容する文字は、ゼロから独自に集めたわけではなく、各国で決まっている標準規格等から収集しています。ここに各国の標準規格との関係をどうするかという課題が生まれます。
(3) また、当初のUnicodeは、16ビットでの実装用に企画されていたため2の16乗(65,536)個のコードポイントしかありませんでした。これは、実装の制限が仕様に影響を及ぼしたことになります。現在は、2005年12月26日に述べましたように、コードスペースが拡張されていますが、この拡張は極めてトリッキーな(tricky;巧妙な、ずるい)方法によるものです。
このような事情から、Unicodeの仕様には、いろいろと問題が出ている面もあるようです。これについて、以下に少し、まとめてみたいと思います。なお、私は、ISOの委員会にもJISの国内委員会にも参加していませんのであまり詳しいことは知りません。Webなどで調べながら書いていますので、誤りがありましたらぜひ指摘していただきたいと思います。
また、前にも申し上げましたが、私自身Unicodeは20世紀の偉業の一つと考えています。実際のところ、いまなにか製品を実装するとしてベースにする符号化文字集合にはUnicode以外の選択肢はないだろうと思います。
そのようなわけで、製品を実装する、あるいは利用する場合に理解しておくべき事柄として問題を整理してみたものです。このことを予めお断りしておきます。
1.漢字について
まず、最初に漢字について見てみましょう。Unicode4.0では次の表のように71,098文字の漢字が定義されています。(12月26日の表から漢字だけ取り出したもの)。
■Unicode4.0の漢字文字数
| 分類 | コード範囲 | 文字数 | 収容時期 |
|---|---|---|---|
| CJK統合漢字拡張A (CJK Unified Ideographs Extension A) | U+3400~U+4DB5 | 6,582 | V3.0 |
| CJK統合漢字 (CJK Unified Ideographs) | U+4E00~U+9FA5 | 20,902 | V1.0 |
| CJK互換漢字 (CJK Compatibility Ideographs) | U+F900~U+FA6A | 361 | V1.0で302文字 V3.2から361文字に増加 |
| CJK統合漢字拡張B (CJK Unified Ideographs Extension B) | U+20000~ U+2A6D6 | 42,711 | V3.1 |
| CJK互換補助漢字 (CJK Compatibility Ideographs Suppliment) | U+2F800~ U+2FA1D | 542 | V3.1 |
| 合計 | 71,098 |
※注意
1.正しくは、Ideographを表意文字と訳すべきですが、ここでは分かり易く漢字としています。
2.この表は、Unicode4.0仕様書のAppendix A Table D-2, Table D-3を元に構成したものなんですが、Unicode4.0仕様書の11.1 Han (p.293) の下から3行目では漢字は70,207文字とされています。891文字の違いはどこから来るか分かりません。
さらに、
http://www.unicode.org/Public/UNIDATA/DerivedAge.txt
を見ますと、UnicodeV4.1.0で128文字が追加されています。
| 分類 | V4.0 | V4.1で追加 | V4.1総数 |
|---|---|---|---|
| CJK統合漢字拡張A | 6,582 | 0 | 6,582 |
| CJK統合漢字 | 20,902 | 22 | 20,924 |
| CJK互換漢字 | 361 | 106 | 467 |
| CJK統合漢字拡張B | 42711 | 0 | 42,711 |
| CJK互換補助漢字 | 542 | 0 | 542 |
| 合計 | 71,098 | 128 | 71,226 |
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月26日
PDFと文字(12) – Unicode仕様の文字
さて、Unicodeについて、次のような観点から、少し詳しく検討してみたいと思います。
第1は、Unicode仕様で決めている文字の数について
第2は、その文字をどのようにコンピュータ同士で情報交換するかについて
第3に、その文字をアプリケーションでどのように処理するかについて
まず、Unicode仕様で決めている文字の数について、①Unicodeの文字の収容、すなわち、番号付けをどのように行っているかということ、ついで、②その番号位置にどのような文字を割り当てているかということ、を見てみます。
①Unicodeで決めているのは番号付けした文字です。Unicodeではこの番号のことをコードポイント(Code Point)と言い、番号の範囲をコードスペース(CodeSpace)と言います。コードスペースは0から10FFFF(16進表記、以下、コードポイントは全て16進表記します)で、1,114,112個のコードポイントを収容しています。
コードスペースを便宜上64Kずつのサイズの面に分けています。主な面には次のものがあります。
・基本多言語面(BMP、すなわちBasic Multilingual Plane):0000~FFFFまで。ここに大部分の通常使う文字が収容されます。
・第1面、または補助多言語面(Supplementary Multilingual Plane):10000~1FFFFまで。Lenear B(線状文字B)など歴史的な文字、音楽表記用の文字、数学表記用の文字(記号)のような特殊用途の文字用の面。
・第2面、または補助表意文字面(Supplementary Ideographic Plane):20000~2FFFFまで。BMP面に入りきらなかったCJK文字(漢字)を収容します。
②UnicodeのV1からV4までの各バージョンで収容されている文字数は次の通りです。
| 面 | 分類 | V1.0 | V2.0 | V3.0 | V4.0 |
|---|---|---|---|---|---|
| BMP | アルファベット・記号 | 4,748 | 6,509 | 10,236 | 11,649 |
| 漢字 | 20,902 | 20,902 | 20,902 | 20,902 | |
| 漢字拡張A | 6,582 | 6,582 | |||
| 互換漢字 | 302 | 302 | 302 | 361 | |
| ハングル音節 | 2,350 | 11,172 | 11,172 | 11,172 | |
| 図形文字(小計) | 28,302 | 38,885 | 49,194 | 50,666 | |
| 補助面 | アルファベット・記号 | 2,465 | |||
| 漢字拡張B | 42,711 | ||||
| 互換補助漢字 | 542 | ||||
| 図形文字(小計) | 45,718 | ||||
| 合計 | 28,302 | 38,885 | 49,194 | 96,384 | |
(注)仕様書Appendex D p.1356には、96,382文字と書いてありますが、合計は96,384文字になります。2文字の違いがどこから来るか分かりません。
さらに、Unicode 4.1 で、1,273文字追加したとあります。しかし、どこに追加したかはわかりません。
各文字の字形は、The Unicode Character Code Charts By Scriptで見ることができます。
たとえばLenear Bというのは考古学上の有名な文字らしいですが、Unicodeのコードチャート(次のURL)で見ることができるなんて、楽しいですね。
Linear B Syllabary (PDF)
Linear B Ideograms(PDF)
投稿者 koba : 08:00 | コメント (2) | トラックバック
2005年12月25日
PDFと文字(11) – UnicodeとISO 10646
Unicodeの仕様は4.1.0が現時点で最新です。
まず、印刷された出版物の最新版は、次の4.0版の書籍が最新です。
The Unicode Standard, Version 4.0
(The Unicode Consortium. Addison-Wesley, 2003. ISBN 0-321-18578-1),
これより新しい情報はWebサイトにあります。
まず、4.0以降の次の二つの更新情報があります。
Unicode 4.0.1
Unicode 4.1.0
また、5.0のベータ版が、2005年12月12日に公開されています。
BETA Unicode 5.0.0
Unicode4.1.0について、少し詳しく説明してみたいと思いますが、その前に、UnicodeとISO 10646との関係を簡単にまとめておきます。
WebサイトでUnicodeの解説をしているページを見ると、大抵、UnicodeとISO 10646との関係に触れていますので、このふたつはどういう関係なのだろうと疑問をもつ人が多いでしょう。
Unicode4.0の仕様書には、Appendix CにRelationshipt to ISO/IEC 10646(付属C ISO/IEC 10646との関係)という項があります。そこの説明をまとめると次のようになります。
1. ISO/IEC 10646-1: 1993 とUnicode Version 1.1 は、正確に一致する。
2. ISO/IEC 10646-1: 2000 とUnicode Version 3.0 は、正確に一致する。
3. ISO/IEC 10646-2: 2001 で初めて、補助面(Supplimentary Plane)を規定した。
4. Unicode 3.1 は、ISO/IEC 10646-2: 2001と同期を取った。
3. Unicode 4.0 は、ISO/IEC 10646: 2003(予定)と一致する。なお、ISO/IEC 10646: 2003は、10646-1と10646-2を合併したもの。
なお、UnicodeコンソーシアムのWebページには、Unicode and ISO 10646というページもあり、次のようなQ&Aが掲載されています。
Q. じゃあ、この二つは同じものなの?
A. いいえ。
文字コードと符号化方式は同期を取っていますが、Unicodeは実装上の適合性を重視しています。このため、ISO/IEC 10646で規定していない、拡張した機能文字、文字データ、アルゴリスム、背景資料などを提供しています。
ISO 10646を翻訳し、JISの国内規格との関係について解説を追加したものが、JIS X0221です。
投稿者 koba : 00:00 | コメント (0) | トラックバック
2005年12月24日
PDFと文字(10) – Unicodeの誕生
さて、地域別に符号化文字集合が異なるということは、コンピュータ・ソフトウエアの国際化にとっては非常に面倒なことになります。テキスト処理はコンピュータ・ソフトウエアにとっては基本的なものなのですが、そのテキスト処理を地域毎に変更しなければならなくなってしまうからです。
また、インターネットの普及に伴い、地域を超えて情報交換を行う必要性も高まっています。地域別に符号化文字集合が異なると、国境を越えたコミュニケーションの上でも大変不便です。
こうしたことから地球上の全ての文字を網羅するグローバルな符号化文字集合が必要なことは容易に理解できると思います。
この要請に応えて生まれたのがUnicodeです。Unicodeについての情報はUnicodeコンソーシアムのホームページで見ることができます。
Unicodeのアイデアが生まれ、実際に活動が始まったのは、1980年代の終わり頃です。Mark Davisの「Ten Years of Unicode 1988 - 1998」(Unicodeの10年、1988年から1989年)を見ますと、次のようなことが書いてあります。
Unicodeの基本設計は、1987年にゼロックスにいたJoe BeckerとLee CollinsおよびアップルにいたMark Davisが検討した。ゼロックスは、Star(Xeroxの研究所でStarを見たSteve JobsがMacintoshのアイデアを得たのは有名な話)の日本版J-Starを作る過程で、また、AppleはKanji Talk(Macintoshの日本語環境)を作る過程で、日本語化の問題に直面した、こんなことからUnicodeのアイデアについて意見を交換した。
1988年4月に初めてアップルがUnicodeテキストのプロトタイプを出し、TrueTypeでUnicodeをサポートすることを決めた。また、1988年7月にアップルはResearch Libraries Groupから中国語、日本語、韓国語(CJK)の文字データベースを購入し、CJK漢字の統一化(Unification)をはじめた。(これが、日本で悪名高いUnicodeのCJK統合漢字問題の始まりというわけです。)
こうして、Unicode制定への活動が始まり、その後、Sun、IBM、Microsoftなどの米国メーカの賛同を得て、次第に大きな動きになっていきました。
Unicode1.0の仕様書は1991年に出版され、1992年には、仕様書の第2巻が追加されUnicode1.0.1となりました。
1987年から始まったUnicode1.0の歴史は「Chronology of Unicode Version 1.0」(Unicode Version 1.0年代記)にあります。
私は、Unicodeはコンピュータ・ソフト分野における20世紀最大の偉業のひとつと考えていますが、こういう歴史が作られる過程をまざまざと見られるのは大変に興味深いものです。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月23日
PDFと文字(9) – 中国の文字規格
漢字を生み出した国、中国でも独自の文字規格の制定が行われています。中国での文字規格は国家標準の略である「国標」のピンイン表記(Guo Biao)の頭文字をとって、GBxxという番号が付いています。
1バイトの文字集合には、GB11383-89(8ビット)、GB1988-89(7ビット)があります。また、簡体漢字を含む主要な標準規格には、GB2312、GBK、GB18030などがあります。
また、ISO 10646の中国語版であるGB13000-1-93という規格もあります。
GB2312-80は、簡体字6,763文字、記号682文字の合計7,445の文字と記号を定めています。従来、最も良く使われてきた文字集合ですが、近年は、GB18030に置き換えられつつあります。
GBK文字集合は、GB2312の拡張版です。GBという頭文字が付いていますが、標準規格ではなく指導的な規範とされています。MicrosoftのWindows95中国語版の内部コードとして実装されました。しかし、これもGB18030への過渡的な存在となりそうです。
現在、重要な存在になっていますのがGB18030です。これは、GBKに基づいて文字を追加して策定した国家標準で、2001年01月01日から発売する製品は必ず、この標準をサポートしなければならないと発表されています。GB18030には1バイト、2バイト、4バイトの3種類の長さで文字を収容していますが、4バイトの文字コード領域もあるため160万のコードをエンコーディングできるという巨大な収容量があります。ただし、GB18030-2000の仕様書に字形が記載されている文字の数は、28,522文字です。文字を追加する計画もあるようです。
さらに、中国政府は、この標準で定める文字を実装したフォントを開発して中国国内で販売する製品用に売り込んでいます。なかなか商魂たくましいものですね。日本のメーカ向けには、ダイナコムウェア社が販売代理店となって活動しています。
ダイナコムウェア社のページ中国新文字コード規格 GB18030
次の記事は、ダイナコムウェアの営業責任者 松田さんが寄稿したものです。
「漢字の国」にみる、電子機器の文字問題(1)
「漢字の国」にみる、電子機器の文字問題(2)
「漢字の国」にみる、電子機器の文字問題(3)
読み物としては面白いですが、少々、営業的側面?があるような気もしますね。
投稿者 koba : 00:00 | コメント (0) | トラックバック
2005年12月22日
PDFと文字(8) – JIS X0212, X 0213
さて、JIS X0208-1997で決めているのは6,879文字数で、そのうち漢字が6,355文字です。しかし、これでは当然漢字の種類が少なすぎるということで、JIS X0208:1990 と同時に、追加の文字を「補助漢字」として規格化したのがJIS X0212です。しかし、これはなぜか普及していません。
代わって、最近、話題を集めているのがJIS X 0213です。
X0213は2000年に制定され2004年に改正されました。
この規格書(2000年版)の先頭には、JIS X0208の6,879文字と同時に運用する4,344文字を含め、11,223文字を定めた、と書いてあります。もともとX 0212もX0208の補助漢字として定められたわけですから、この文章を読むと、X0212は止めて、X 0213で、X 0208の拡張をやり直したということがわかります。
JIS X 0213では、94×94の大きさの表を2面使って文字の番号表を定義しています。ひとつの面には理論上94×94=8,836文字が収容できますが、第1面には、JIS X 0208で定義されていた文字は、同じ位置にそのま収容し、さらに、JIS X 0208で空きになっていた位置に新しい文字を追加しています。第2面は新しい面で、2,436文字を定義しています。第2面にはだいぶ空きが残っています。
実装水準3の文字が8,787文字で、すべて第1面に割り当てられています。実装水準4では、第2面の2,436文字を含む全文字を実装することになります。
JIS X0213は、2004年2月に改正され10文字を追加しました。現在は、4,354文字をJIS X0213で新たに追加、X0208とあわせて合計11,233文字を定めています。
【参考資料】
JIS漢字コード表の改正について-報道発表-経済産業省
さて、最近話題というのは、マイクロソフトがWindowsVista用に、JIS X0213を実装する新しいフォントを作っているという発表です。
Windowsの次期バージョンWindows Vista(TM)において日本語フォント環境を一新
これによると、JIS X 0213:2004に対応したMSゴシック3書体、MS明朝2書体を新しく作っているということです。フォントはVistaだけでなく、XP向けにも提供されるということですので、期待したいと思います。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月21日
全角文字と半角文字について(蛇足)
JIS X0201で実際に使う文字はすべてX 0208に収容されています。このため、文字の種類だけを考えるのであればだぶりがあることになります。
X 0201の文字は半角文字、X 0208の文字は全角文字などとも呼ばれます。要するに、シフトJISコードでは、ラテンアルファベットや数字記号類、およびカタカナには、同一文字に半角文字と全角文字があるということです。これをどうやって使い分けたら良いでしょうか?
たとえば、IMEで文字を入力するとき、このような選択メニューが表示されます。
このメニューで半角文字を選ぶとX 0201の文字コードが入力され、全角文字を選ぶと、X 0208の文字が入力されることになります。
この使い分けの基準としては次のように考えれば良いと思います。
インターネットのアドレスなどは半角文字で入力することはご存知と思います。さらに海外とのやりとりをする場合、メールの本文、あるいはワープロの文書本文でもASCIIに定義されているラテンアルファベットや数字・記号類は半角文字を使うべきです。そうしないと、もし、海外のパソコンで文書を開いてみる可能性がある場合、全角のラテンアルファベットを使用すると、相手先で文字が化けてしまう可能性が大きくなるからです。ただし、¥マークは全角を使う方が良いでしょう。
一方、特別な事情がある場合を除いて、半角のカタカナは使わずに全角カタカナを使う方が良いと思います。
X 0201でなされた半角カタカナの拡張は、昔、コンピュータで使える資源が少なかった時代の名残で、将来はなくなるべきものだろうと思います。
もともと全角、半角という言葉は、どこから生まれてきたか知りませんが、文字の種類ではなく、キャラクタディスプレイで文字を表示したり、あるいはドットマトリックス・プリンタに文字を印刷するときの幅に由来していると思います。
シフトJISコードは、ある意味では初期のパソコンで和洋折衷をしたための妥協の産物です。今になって考えれば、ソフトウェアの国際化という観点からは、あまり望ましくない解決策ですので、個人的には、シフトJISコードはできるだけ早期に廃止されることを希望しています。
なお、次のページは、日本語中心ですが、文字コードについて、概略をわかり易く説明しています。
文字コード
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月20日
PDFと文字(7) – JISの文字規格
日本では、日本工業規格(JIS: Japanese Industrial Standard)で定めている文字集合についての規格があります。
現在、日本独自の規格として、次の4つの規格があります。
JIS X 0201 7ビット及び8ビットの情報交換用符号化文字集合
JIS X 0208 7ビット及び8ビットの2バイト情報交換用符号化漢字集合
JIS X 0212 情報交換用漢字符号-補助漢字
JIS X 0213 7ビット及び8ビットの2バイト情報交換用符号化拡張漢字集合
それから、ISO 10646という国際規格の日本語版として、JIS X 0221 国際符号化文字集合 (UCS) -第1部:体系及び基本多言語面
があります。
JIS X 0201は、ラテンアルファベットや記号類、およびカタカナ文字を定めています。ラテンアルファベットと記号類についてはISO 646をベースに一部の文字を日本特有にし、さらに独自にカタカナを追加したものです。
実用上、大きな問題は、ISO 646でバックスラッシュを定義していた文字番号を、X 0201では円記号を定義するように代えてしまったことでしょう。このため、X 0201は完全な国内規格であってインターネット時代には不適切です。日本語で円マークを書いたつもりでも、海外の人がみたらバックスラッシュになってしまうからです。
JIS X0208は、漢字類を定める基本的な規格で、
1978年に第一次規格 JIS C 6226-1978
1983年の第二次規格 JIS C 6226-1983(1987年にX 0208に移行)
1990年の第三次規格 JIS X 0208-1990
1997年の第四次規格 JIS X 0208-1997
と改訂されてきました。第二次規格で文字の番号の入れ替え(第一水準、第二水準間)を行い、罫線記号や特殊文字類71文字、漢字4文字の追加を行ったために1980年代後半には、旧JIS、新JISというような言葉が生まれるなど大きな混乱をもたらしました。
1990年の第三次規格でさらに2文字を追加して、合計文字数は6,879文字になりました。第四次規格では文字の番号や追加削除は行わず、規定の明確化に努めたとされています。
JIS X 0201 とJIS X 0208を同時に使うための工夫として、マイクロソフトなどが考案したのが、シフトJISコードです。
JIS X 0208-1997ではじめて、シフトJISコードを、JIS規格(付属書)として定めました。
なお、マイクロソフトのアプリケーションが出力するシフトJISは、丸囲数字などNEC拡張文字やIBM拡張漢字などJIS X 0208にない文字を追加しています。従って、厳密には、JIS規格で定めているシフトJISコードとは異なるものです。マイクロソフトのアプリケーションが出力するシフトJISコードの正式名は、Windows-31Jです。
参考
日本工業標準調査会
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月19日
ブラウザで表示できる文字符号化の例
インターネットのWebで、日本にいながらにして世界中の国のホームページを見ることができます。実際に各国の文字を見る機会は、PDFよりもブラウザを使っての方が多いかもしれませんね。
インターネット用ブラウザは、世界中の文字を表示できるようになっています。その中で、最近話題のMozilla Firefoxをチェックしてみましょう。
Firefoxでは、文字の符号化方式を自動的に判別できるようになっています。(Firefoxに限らず、電子メールソフトなどでも同じです。)しかし、もし正しく判別できなかった場合に備えて、自分でも文字符号化方式を選択できるようになっています。
文字符号化をCharacter Encodingといいますが、Firefoxでは文字エンコードメニューで符号化方式を選択します。自分で文字符号化を指定するメニューでは、次の符号化方式がリストされています。
| 地域 | 符号化方式 | 日本語メニュー |
|---|---|---|
| 西欧 | 
|
西欧ISO-8859-1 |
| 西欧ISO-8859-15 | ||
| 西欧IBM-850 | ||
| 西欧MacRoman | ||
| 西欧Windows-1252 | ||
| ケルト語ISO-8859-14 | ||
| ギリシャ語ISO-8859-7 | ||
| ギリシャ語MacGreek | ||
| ギリシャ語Windows-1253 | ||
| アイスランド語MacIcelandic | ||
| 北欧ISO-8859-10 | ||
| 南欧ISO-8859-3 | ||
| 東欧 |  |
バルト語ISO-8859-4 |
| バルト語ISO-8859-13 | ||
| バルト語Windows-1257 | ||
| 中欧IBM-852 | ||
| 中欧ISO-8859-2 | ||
| 中欧MacCE | ||
| 中欧Windows-1250 | ||
| クロアチア語MacCroatioan | ||
| キリル文字IBM-855 | ||
| キリル文字ISO-8859-5 | ||
| キリル文字ISO-IR-111 | ||
| キリル文字KOI8-R | ||
| キリル文字MacCyrillic | ||
| キリル文字Windows-1251 | ||
| キリル文字/ロシア語CP-866 | ||
| キリル文字/ウクライナ語KOI8-U | ||
| キリル文字/ウクライナ語MacUkrainian | ||
| ルーマニア語ISO-8859-16 | ||
| ルーマニア語MacRomanian | ||
| 東アジア |  |
簡体字中国語GB2312 |
| 簡体字中国語GBK | ||
| 簡体字中国語GB18030 | ||
| 簡体字中国語HZ | ||
| 簡体字中国語ISO-2022-CN | ||
| 繁体字中国語Big5 | ||
| 繁体字中国語Big-HKSCS | ||
| 繁体字中国語EUC-TW | ||
| 日本語EUC-JP | ||
| 日本語ISO-2022-JP | ||
| 日本語Shift_JIS | ||
| 韓国語EUC-KR | ||
| 韓国語UHC | ||
| 韓国語JOHAB | ||
| 韓国語ISO-2022-KR | ||
| 西南・東南アジア |  |
アルメニア語ARMSCII-8 |
| グルジア語GEOSTD8 | ||
| タイ語TIS-620 | ||
| タイ語ISO-8859-11 | ||
| タイ語Windows-874 | ||
| トルコ語IBM-857 | ||
| トルコ語ISO-8859-9 | ||
| トルコ語MacTurkish | ||
| トルコ語Windows-1254 | ||
| ベトナム語TCVN | ||
| ベトナム語VISCII | ||
| ベトナム語VPS | ||
| ベトナム語Windows-1258 | ||
| ヒンディー語MacDevanagari | ||
| グジャラート語MacGujarati | ||
| グルムキー語MacGurmukhi | ||
| 中近東 | 
|
アラビア語ISO-8859-6 |
| アラビア語Windows-1256 | ||
| アラビア語IBM-864 | ||
| アラビア語MacArabic | ||
| ペルシャ語MacFarsi | ||
| ヘブライ語ISO-8859-8-I | ||
| ヘブライ語Windows-1255 | ||
| ヘブライ語ISO-8859-8 | ||
| ヘブライ語IBM-862 | ||
| ヘブライ語MacHebrew |
これを見て気がつくのは、ISOなどの標準規格の他に、IBM、Macintosh、Windowsの名前を冠したメーカ定義の符号化方式もあるということです。このように、メーカが独自に文字符号化を定義しなければならなかったのは、旧来の文字規格では、標準化されている文字の種類がすくなく、各メーカがユーザの要望に応じて独自の文字を追加していたためです。
なお、Firefox(特に、日本語訳)では、言語と文字符号化方式をあまり厳密に使い分けていないようですね。
投稿者 koba : 08:00 | コメント (1) | トラックバック
2005年12月18日
PDFと文字(6) – 地域別文字規格
文字に関する標準規格には、主に各国の機関が定めている国別標準が昔から使われてきました。
一番古くから使われていて、有名なものにASCIIコードがあります。ASCIIコードはアルファベットを含む128種類の文字を定義しています。
ASCIIコードをベースに国際標準化したものが、ISO 646です。これはさらに、主に西欧言語用に文字コードを拡張してISO 8859シリーズとなっています。(下の表では、Latin Alphabet, Latin/ と表記したもの)。
これとは別に日本ではJISの文字コード規格があり、中国、台湾、韓国などでも同様の文字コード規格が定められています。
下の表に世界の言語に使われる地域別文字規格について、簡単にまとめてみました。
| 言語コード | 言語名称 | 言語名称(日本語) | 使用する文字の種類 | 地域別文字規格 |
|---|---|---|---|---|
| ar | Arabic | アラビア語 | Arabic | ASMO 449, Latin/Arabic Alphabet |
| bg | Bulgarian | ブルガリア語 | Cyrillic | Latin/Cyrillic Alphabet |
| zh-CN | Chinese(Simplified) | 北京中国語(標準中国語マンダリン) | 簡体字(漢字) | GB2312, GB18030 |
| zh-TW | Chinese(Traditional) | 中国語 | 繁体字(漢字) | BIG5 |
| hr | Croatian | クロアチア語 | Latin | Latin Alphabet No.2,10 |
| cs | Czech | チェコ語 | Latin | Latin Alphabet No.2 |
| da | Danish | デンマーク語 | Latin | Latin Alphabet No.1,4,5,6,8,9 |
| nl | Dutch | オランダ語 | Latin | Latin Alphabet No.1,5,9 |
| en | English | 英語 | Latin | Latin Alphabet No.1..10 |
| et | Estonian | エストニア語 | Latin | Latin Alphabet No.4,6,7,9 |
| fi | Finnish | フィンランド語 | Latin | Latin Alphabet No.4,6,7,9,10 |
| fr | French | フランス語 | Latin | Latin Alphabet No.9,10 |
| de | German | ドイツ語 | Latin | Latin Alphabet No.1..10(7除く) |
| el | Greek | ギリシャ語 | Greek | Latin/Greek Alphabet |
| he | Hebrew | ヘブライ語 | Hebrew | Latin/Hebrew Alphabet |
| hu | Hungarian | ハンガリー語 | Latin | Latin Alphabet No.2,10 |
| is | Icelandic | アイスランド語 | Latin | Latin Alphabet No.1,6,9 |
| id | Indonesian | インドネシア語 | Latin | Latin Characters |
| it | Italian | イタリア語 | Latin | Latin Alphabet No.1,3,5,8,9,10 |
| ja | Japanese | 日本語 | Latin、漢字、かな、カタカナ | JIS X0201, JIS X0208, JIS X0212 |
| kk | Kazakh | カザフ語 | Cyrillic | Extended Latin/Cyrillic Alphabet (Cyrillic Asean) |
| ko | Korean | 韓国語 | ハングル、漢字 | KS C5601, KS X1001, Johab |
| lv | Latvian | ラトビア語 | Latin | Latin Alphabet No.4,7 |
| lt | Lithuanian | リトアニア語 | Latin | Latin Alphabet No.4,6,7 |
| no | Norwegian | ノルウェー語 | Latin | Latin Alphabet No.1,4..9 |
| fa | Persian(Farsi) | ペルシャ語 | Arabic | Extended Latin/Arabic Alphabet (Arabic Character 28+ Original 4 Characters) |
| pl | Polish | ポーランド語 | Latin | Latin Alphabet No.2,7,10 |
| pt | Portuguese | ポルトガル語 | Latin | Latin Alphabet No.1,3,5,8,9 |
| ro | Romanian | ルーマニア語 | Latin | Latin Alphabet No.10 |
| ru | Russian | ロシア語 | Cyrillic | koi8-r, Latin/Cyrillic Alphabet 32 Chars (not compatible with Ukrainian) |
| sr | Serbian | セルビア語 | Cyrillic | Latin/Cyrillic Alphabet (Serbian) |
| sk | Slovak | スロバキア語 | Latin | Latin Alphabet No.2 |
| sl | Slovenian | スロベニア語 | Latin | Latin Alphabet No.2,4,6,10 |
| es | Spanish | スペイン語 | Latin | Latin Alphabet No.1,5,8,9 |
| sv | Swedish | スウェーデン語 | Latin | Latin Alphabet No.1,4,5,6,8,9 |
| th | Thai | タイ語 | Thai | TIS 620, Latin/Thai Alphabet |
| tr | Turkish | トルコ語 | Latin | Latin Alphabet No.5 |
| uk | Ukrainian | ウクライナ語 | Cyrillic | koi8-u, Latin/Cyrillic Alphabet 33 Chars |
| vi | Vietnamese | ベトナム語 | Latin | Extended Latin Characters |
言語コードは国際標準化機関ISOが、ISO 639規格を定めています。主に2文字コードが使われていますが、現在は、より多くの言語を表すことができるように3文字コードも決まっています。
参考資料
「bit別冊 インターネット時代の文字コード」 (小林 龍生ほか、共立出版、2001年4月号)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月17日
PDFと文字(5) – テキストを構成する文字
一昨日、テキストとは飾りのない本文文字のみで構成されるデータと言いました。では、そのテキストを構成する文字データとはどのようなものでしょうか?
文字については、コンピュータによる情報処理のために、様々な標準化作業が行われています。そういう標準化作業では、文字とは次のようなものであると言っています。
例えば、JIS X 0221 による定義では、文字(Character)とは、「データの構成、制御または表現に用いる要素の集合の構成単位」と言っています。難しい表現をしていますが、注意しなければならないのは、文字には表現用のものだけでなく、コンピュータのデータを制御するためのものも含むということです。具体的には改行するためのものや、ワープロなどで桁揃えするためのタブなども文字に含むということになります。タブを含むのは、タイプライター時代の名残なんでしょうね。
文字を集めたものを文字集合(Character Set)と言います。
そうして、集めた文字にはひとつづつ番号をつけます。なにしろ、コンピュータですから番号をつけないと処理できないんですね。
再び、X 0221を見ますと、番号のついた文字を符号化文字(Coded Character)、文字集合と符号化の規則をあわせて、符号化文字集合(Coded Character Set)と言っています。
難しい表現ですが、平たく言うと沢山の文字を集めてきて、整理して番号をつけて、その文字の集まりと番号のつけ方について標準化しているといって良いと思います。
文字に関する標準規格は、非常に沢山あります。昔から使われてきた国別の標準に加えて、比較的新しい国際標準であるUnicodeがあります。詳しくは、また別途お話したいと思います。
ところで、文字集合というのは英語のCharacter setの訳語のようですので数学的な集合と考えているのでしょうか。特に、X 0221の定義を見ますと、数学的に厳密にやろうと努力している傾向がうかがえますね。
一方、Unicodeの仕様書を読むと、あまり数学的に厳密にやろうとはしないで、実践的に問題を解決しようとしているという印象を受けます。
このように、文字集合が数学的な集合なのか、単に文字を集めた収集(Collection)なのかについては専門家の間でも議論があるようですね。
Dan Connollyは、Character Set Considered Harmfulで、数学的集合として扱うべきと主張していますが、それに対して、Glenn Adamsは、Re: Character Set Terminology, SC2 vs. SC18 vs. Internet Standardsで、そうじゃないと反論しているようです。
このあたりはとても難しい問題です。だんだん進歩して厳密な定義ができるようになるかもしれませんが、Unicodeは数学的厳密さをもっているとは、到底、言えないと思います。
参考資料
「国際符号化文字集合(UCS)—第一部 体系及び基本多言語面
JIS X 0221 1995」
「The Unicode Standard Version 4.0」 (The Unicode Consortium 著, Addison-Wesley, ISBN 0-321-18578-1, August 2003)
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月15日
PDFと文字(4) – 文字の取り扱い
さて、言語の文字による表現には様々な方法がありますが、例えば、次のような観点で分けてPDFでの扱いがどうなるかを概観してみましょう。
(1)プレーンなテキストとしての文字表現
(2)タイプセッティング、日本語では文字組版
(3)カリグラフィー、書道、あるいは超組版
(4)イラストレーション
まず、テキストとしての文字です。コンピュータ関係者はテキストというとバイナリとの対比をすぐに思いつきます。
ちなみに「テキスト バイナリ」をキーワードにしてGoogleで検索してみると:
[9] テキストとバイナリ - インターネットメールの注意点では「文字コードだけを使ったものをテキストといいます。」と言っています。これはちょっと乱暴すぎるのでは?文字コードってなに?
バイナリファイルとはなにか --- テキスト以外のファイルのことであるでは、「テキストとは、バイトの並びをアスキーコード等を使って文字の並びとして解釈したものです。」と言っています。うん、説明に苦労していることがわかります。
ファイルの保存形式についてでは、「テキスト形式ファイルは、画面に表示できる文字と改行やタブなどのいくつかの特殊文字だけで構成されます。」と説明しています。例えば、電子メールが文字化けして表示されることが時々ありますが、このように画面上で文字化けして表示されてもテキストなのかな?
というような具合でテキストという言葉を説明するのはそんなに簡単ではありません。実際のところ、テキストという言葉はうまい日本語がないように思います。明治の初めに活躍した福沢諭吉のような人なら、漢字をつかったうまい日本語を作るのでしょうが、今は、漢字をあてはめて造語するのではなく、英語のカタカナをそのまま日本語にしてしまうからでしょうね。で、日本語の意味を知るのに、英和辞典を引く、という変なことになってしまうのですが、諦めて英和辞典を引いてみると、「本文、原文」などとあります。これもちょっと違うように思います。
そういうわけで、ここでは、勝手な定義としてテキストとは、飾りのない本文文字のみで構成されるデータと言っておきます。さて、そうするとテキストはPDFでは次のような扱いができます。
①ビューアなどで検索対象になる
②ビューアなどで範囲を指定してコピーして、他のアプリケーションに文字列として貼り付ける
③テキスト抽出機能で文字列として取り出す アンテナハウスのTextPorterとかリッチテキストPDFなどを使って :-)
実は、PDFで表示される文字の中には、テキストとして扱うことができるものと、テキストとして扱うことができないものがあります。
AdobeReaderなどのPDFビューアで文字として見えていても上で述べたようなテキストとして扱えるとは限りません。テキストとして扱うためには、PDFファイルの中にそのための設定データがなければならないのです。
では、どういう時にテキストとして扱うことができて、どういう時にできないでしょうか?これにきちんと回答するのは、現時点ではとても難しくて泥沼にはまりそうなので、とりあえず、AdobeReaderの、![]() ツールで範囲を指定してコピーできれば、テキストとして扱えるとしておきます。範囲を指定しようとしてもカーソルが滑ったようになってしまって範囲を指定できなければ文字として見えていてもテキストとしては扱えません。
ツールで範囲を指定してコピーできれば、テキストとして扱えるとしておきます。範囲を指定しようとしてもカーソルが滑ったようになってしまって範囲を指定できなければ文字として見えていてもテキストとしては扱えません。
上の説明は、堂々めぐり、あるいは、ツールの動作で仕様を説明するという、実際、あまり好ましくない説明とは思いますけれど。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月14日
PDFと文字(3) – 言語と文字 その3
簡体字は中華人民共和国の漢字簡単化政策によって作り出されたもの、という話をしましたが、このように文字は政治や経済と密接な関係があります。
その際立った例をいくつか紹介してみましょう。
まず、イスラエルの国語である現代ヘブライ語があります。
ヘブライ語は、もともと古代パレスチナ人が使っていた言葉ですが、2000年以上前に誰も使わなくなってしまったものです。現代ヘブライ語は、いったん誰も使わなくなった言語をイスラエル建国の際に復活したものです。このヘブライ語を書き表すために使う文字がヘブライ文字です。
ヘブライ語
ベトナム語は、現在は、ラテンアルファベットに文字種を追加した文字で記述されています。この文字は19世紀にフランスの宣教師が考案したものらしいです。東南アジアの南方はインド文化の影響を受けているようですが、ベトナムとはもともと「越南」の読みなのだそうで、ベトナム語は漢字の偏旁を独自に組み合わせて作ったチュノムで表記されていたようです。
ベトナム語
ところで「三国志」では蜀の諸葛孔明が何度か南方遠征をしますが、ベトナムまで行ったのでしょうか?
フィリピンの公用語のひとつであるタガログ語も昔はインド起源の文字を用いていたようですが、現在は、ラテンアルファベット表記に変わっています。
タガログ語
政治的理由から比較的短い期間に、文字政策が変わった地域もあります。例えば、新疆ウイグル自治区は、1949年に人民政府に帰順して中華人民共和国の一部になりました。その当時は、ソ連と中国の蜜月時代ということもあり、ウイグル語をキリル文字で表記しようとしたそうです。ところが、中ソ緊張の時代になるとともにキリル文字はあっさり解消、次は、漢字のピンイン法案によりラテン文字表記をしようとしました。その後、1982年になって元のアラビア文字に基づく表記にもどったそうです。
中国・新疆ウイグル自治区における文字と印刷・出版文化の歴史と現状(菅原 純)
いままでお話しましたのは、ごく一部の言語の例です。世界には、数千種類(一説には6000種類)といわれる言語があります。
それぞれの言語は表記方法である文字がなければ記録として残すことができません。ですので表記の手段として文字をもつということは、その言語の文化を伝え、あるいは遠くの人と意思を伝えていくために大変重要なものです。
PDFは紙に表記された情報を電子的化するものですので、PDFでもこのような様々な文字を扱えなければなりません。
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月13日
PDFと文字(2) – 言語と文字 続き
昨日、漢字のお話をしました。漢字は中国で生まれ、中国の文化と共に周辺の国に渡って、その国の言語を表記するのに使われるようになったということはご存知のことと思います。
漢字と同じように、文化圏の広がりと共に周辺地域に普及し、その地域の言語表記に使われるようになった文字にアラビア文字があります。
アラビア文字とアラビア語を英語で表すといづれもArabicとなるため混同し易く、よく間違えますが、この二つは別の概念です。間違えないように使い分けないといけないですね。
アラビア語は聖典クルアーンの言語として、世界各地のイスラム教徒に親しまれています。このイスラム教とアラブ文化圏の広がりに伴い、アラビア文字はペルシャ語(イラン・イスラーム共和国)、ウルドゥ語(パキスタン)、現代ウイグル語(中国新疆ウイグル自治区)などの表記にも使われています。アラビア文字の場合も、ラテンアルファベット同様に、アラビア語以外では、その言語特有の音を表記するための文字・記号類が追加されています。
アラビア系文字
「アラビア系文字の基礎知識」
キリル文字もロシアをはじめスラヴ系の多数の言語の表記に使われています。ソヴィエト連邦の解体にともない、キリル文字で表記していた言語の中でラテン文字表記に変更しているものもあるようです。このように表記する文字を変更することは世代間のコミュニケーションに深刻な問題をもたらす可能性があります。
キリル文字(フリー百科事典『ウィキペディア(Wikipedia)』)
東南アジアのタイ語、ラオス語、カンボジア語は、それぞれ特有の文字( タイ文字、ラオス文字、クメール文字)で表記されます。日本語のひらながとカタカナは50音というくらい、音節と文字が一対一の関係があります。これに対して、タイ語、ラオス語、カンボジア語では、発音の音素と文字字形(グリフ)が一対一に対応せず、並び時も発音順でないという複雑な関係になっています。
タイ語,ラオス語,カンボジア語(クメール語)の文字処理と組版における課題
東南アジア大陸部のインド系文字
インドには850~1700の言語があるようですが、その中でもヒンディー語は人口の約4割で使われているとのこと。ヒンディー語を表記するのに使われているのがデーヴァナーガリー文字です。この文字は、組み合わせによる表示形の変化(リガチャ)の種類が極めて多いため、コンピュータ処理の難関といえます。
インドの言語と文字
デーヴァナーガリー文字
投稿者 koba : 08:00 | コメント (0) | トラックバック
2005年12月12日
PDFと文字(1) – 言語と文字
さて、PDFは紙を電子化したものなので、紙の上に表現できるあらゆる情報を表現することができます。それらの情報の中で、特に、文字がPDFでどのように取り扱われているかを、これからしばらくの間、お話してみたいと思います。
文字とはなんでしょうか?こういう哲学的、大上段に構えた質問をしてしまうと、なかなか答えることが難しいものですね。そこで、少し、具体的に考えて見ましょう。
私たち日本人は、日常会話では日本語を話し、そうして日本語で書かれた新聞、雑誌、書籍、インターネットのページ、ブログページを書いたり読んだりしています。このような日本語の記事は、漢字、ひらがな、かたかな、句読点、括弧類などの記号を使って表記します。
ここから類推して、簡単に言えば、言語を表記するツールが文字であると考えて良いと思います。
長い年月でみれば、特定の言語の表記に使う文字の種類はかなり変遷します。例えば、江戸時代より以前、墨と筆で文字を書いていたときは、恐らく句読点や括弧類はなかったのでしょう。句読点が定着したのは明治三九年、文部大臣官房図書課が『句読法案』を発表してからのことなのだそうです。
句読点研究会
最近の携帯電話には、いろいろな絵文字が登録されています。このような絵文字が市民権を得て、皆が使う日がいづれ到来するのでしょうか?あるいは廃れてしまうのでしょうか?このように文字と認めて良いかどうか、意見が分かれる記号も沢山あります。
英語は、26種類のアルファベットの大文字と小文字、カンマ、ピリオド、感嘆符、引用符などの記号類を使って表記します。
フランス語ではアクセントを多用するため、26種類のアルファベットでは足りず、Accute accent, Grave accent, Circomflex accent, Diacresis, Cedillaの5種類のアクセントをつけた15文字を追加して使います。括弧記号も英語とは違います。
ドイツ語は、26種類のアルファベットに加えて、ドイツ語特有のウムラウト付き文字 (A with diacresis, O with diacresis, U with diacresis) とエスツェット (Sharp S) を追加しています。
お隣の韓国・北朝鮮の言語は朝鮮語ですが、現在は、ハングル文字による表記が主流です。ハングル文字は、1443年に発明された比較的新しい文字で、それ以前は朝鮮語の表記は漢字によっていたようです。
朝鮮語
漢字の本家、中国では、漢字簡易化政策の下に1950年、1960年代に漢字を簡体字にしてしまいました。このため、漢字には、現在、大陸で使われている簡体字と、台湾を中心に使われている繁体字の2種類があります。
「近現代中国における言語政策」 藤井 久美子 2003年2月23日 株式会社三元社発行
コンピュータの世界で、CJK文字といえば漢字のことを言うのですが、現在は、このように日本、中国、韓国の漢字事情は、それぞれ相当に異なっています。