« PDFと文字(16) –漢字統合の破綻 | メイン | 漢字統合の3次元モデルについてKen Lundeの誤り »
2006年01月06日
PDFと文字(17) – 統合漢字の理論
そもそも、日本、中国、韓国などの漢字を統合しようというのは誰が考えたのでしょうか?
Unicodeを最初に考えた人たちは、日本、中国などの漢字の文字数があまりにも多く、コードスペースの中に入りきらないという単純な動機から、同じ形の漢字に一つのコードポイントを与えようと考えたのではないかと思います。
しかし、その後の進展で、日本、中国、韓国などの専門家が参加するところとなり、漢字統合の理論を誰かが考えたようです。Unicodeの仕様書では、CJK統合漢字の理論は、3次元概念モデルとして、次のような図を用いて説明されています。この図は、漢字の簡体字が入っていますので、多分、北京の中国人の考案でしょう。
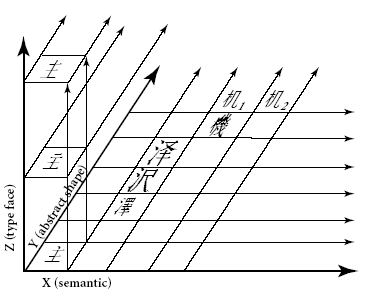
(Unicode仕様書 V4.0 Fig.11-3 p.299 より引用)
ここに、X軸はセマンティック(意味または機能)、Y軸は抽象的形状、Z軸はタイプフェース(書体)とされています。
この概念モデルに基づいて、日本、中国、韓国などの漢字をひとつにまとめたと説明しています。しかし、Unicodeの仕様書を読んでも、どうも統合にあたってのセマンティック軸の扱いが明確になっていません。そこで、この部分を私なりに検討してみました。
■仕様書V2.0では次のように書かれています。
Only characters that have the same abstract shape (that is, occupy a single point on the X and Y axes) are potential candidates for unification. Z axis typeface and semantic differences are generally ignored.
(Unicode V2.0 仕様書 p. 6-108、下から10行目~8行目)
※アンダーラインは私が付けました。以下、同じです。
3次元概念モデルでは、Y軸上で同じ位置の漢字が同じ抽象的な形状となります。抽象的形状が同じものをまとめるということは、Z軸とX軸を無視することになります。ですので上の文章は正しくありません。私の考えでは、正しくは次の文章になるはずです。
Only characters that have the same abstract shape (that is, occupy a single point on the Y axis) are potential candidates for unification. Z axis typeface and X axis semantic differences are generally ignored.
上の図の例で、セマンティックを無視すれば、![]() と
と![]() は統合され、ひとつのコードポイントが与えられます。
は統合され、ひとつのコードポイントが与えられます。
※ちなみに、この二つは字形が同じで意味が違う例として、![]() は”機械”を意味し、
は”機械”を意味し、![]() は、”机”を意味すると説明されています。
は、”机”を意味すると説明されています。
■ところが、V3.0仕様書から以降、この部分が次のように訂正されています。
Only characters that have the same abstract shape (that is, occupy a single point on the X and Y axes) are potential candidates for unification. Z axis typeface and stylistic differences are generally ignored.
(直訳)
同じ抽象的形状をもつ文字(すなわち、XとY軸の上でひとつの点を占める)のみが統合化の潜在的候補となる。Z軸のタイプフェースとスタイルの違いは一般に無視する。
この新しい説明では、セマンティック(semantic)がスタイル(stylistic)に代わってしまいました。そして、無視されるのはZ軸(タイプフェースとスタイル)のみとされています。
セマンティックの扱いは明確に書かれていません。しかし、X及びY軸で同じ位置にあるものが抽象的形状が同じ、と言っているわけですから、セマンティックが抽象的形状の一要因になったということに等しいわけです。言い換えるとセマンティックが違えば抽象的形状が違うとみなす、と暗黙に示したことになります。
このあたり、3次元(立体)で考えるのは難しいので、わかり易くするため、2つの軸、X軸×Y軸を1次元に展開して、図を書き直すと次のようになります。
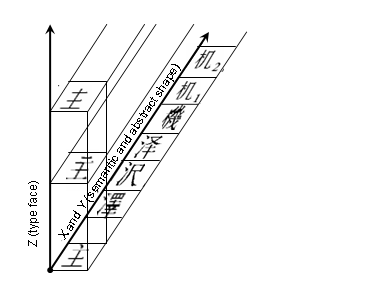
※この2次元の図は私が作りましたが、上の3次元の図と同等なはずです。
V3.0以降の仕様書では、この図でZ軸のみが無視されると言っています。ですので、![]() と
と![]() は別のコードポイントが与えられることになります。
は別のコードポイントが与えられることになります。
言い換えると、V3.0以降では同じ抽象的形状でもセマンティックが異なれば統合の候補にならない。抽象的形状とセマンティックが共に同じ漢字のみが統合の候補になると変更したことになります。
※しかし、仕様書には、統合ルールは、原規格分離規則以外は、変更してないとも書いてあります。従って、仕様書の説明に矛盾を含んでいます。
X軸、すなわちセマンティックについて考えて見ます。同じ字形の漢字でも言語によって意味が変わったり、新しい意味が付加されたりすることが多く、言語の違いがセマンティックに重要な影響を及ぼすのは明らかです。従って、字形が同じでもセマンティックが違えば別のコードポイントを与えるとなると、中国語、日本語、韓国語、ベトナム語という異なる言語の中で出現する漢字を字形で統合するのは至難になります。乱暴に言えば、セマンティックを無視しなければ、CJKVの漢字統合はできないのではないでしょうか。
結局、概念モデルではセマンティックを無視しないと言い、実際の作業はセマンティックを無視して漢字統合したということで、示した理論と実際にやったことが矛盾してしまったように思います。
V1.0でCJK漢字を統合すると言いながら、原規格分離規則によって、これを徹底できずにV3.0では原規格分離規則を廃止したというように、漢字統合ルールも振れています。
昨日、Unicodeの漢字統合は破綻してしまったと言いましたが、その原因を辿っていけば、ルールの基になる概念=3次元概念モデルが曖昧だったためではないでしょうか?
20世紀最大の偉業のはずなんですが。残念。漢字統合は、21世紀にもう一度やり直しが必要なんでしょうね。
[2006/3/15]
芝野先生のご指摘により、一部削除しました。
また、CJK統合理論が生まれた経緯につきましては、芝野先生、安岡先生にコメントをいただいていますので、そのあたりをご参照ください。
※英文にするときは、全体を修正しなければなりませんね。翻訳が遅れていますので、いつのことになりますか?
投稿者 koba : 2006年01月06日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/111
コメント
なるほど。
統合の動機は、コードスペースの制約ではないということなんですね。
考えて見ますと、ラテン文字やアラビア文字など他の文字では、1種類の文字が複数の言語で使われます。従って、言語の範疇を超えて、漢字という文字に着目して文字集合を作るのは自然な発想とも言えます。
雑談的ですが、CJK統合漢字などという名前を付けたので、ナショナリストの無用な反発を招いたのかもしれませんね。
投稿者 koba : 2006年01月12日 08:55
>Unicodeを最初に考えた人たちは、日本、中国などの漢字
>の文字数があまりにも多く、コードスペースの中に入りき
>らないという単純な動機から、同じ形の漢字に一つのコー
>ドポイントを与えようと考えたのではないかと思います。
この件ですが,BTRONの仕様書には諸橋大漢和で5万字だから,2バイトのBTRONコードを作れば,世界のすべての文字を収録することができると書かれています。
最初のJISコードの設計でも,コードスペースを制限しようとした経緯は全くありません。
Unicodeについても,CJK-JRG以前のUnicode Ver.0でもCJKシソーラスをもとに,JIS X 0208,GB 2312,KS 5601など日中韓の基本コードをもとにした水準と補助漢字水準の二つの水準に分けていましたが,統合は行っています。
また,大漢和辞典は「統合漢字」の辞典で日本語の読みだけではなく,中国語の読みも出典も書かれています。
そもそも「漢字」の「漢」は中国を意味しますよね。日本独自の漢字は「国字」と呼びます。
投稿者 芝野耕司 : 2006年01月12日 02:42
安岡様、芝野様
コメントありがとうございました。
数日間北京に行っていまして、コメントの公開が遅くなり申し訳ありませんでした。
また、いろいろ勝手な推測を書いて済みません。誤りを指摘していただいてありがたいです。勉強にもなりますし。
それにしても高名な先生方に読んでいるとは。気楽に書けなくなりそうです :-)
放談と思ってお許しください。
投稿者 koba : 2006年01月11日 17:31
Unicodeの統合漢字のアイデアは,RLG(Research Library Group)のCJKシソーラスから来ています。RLGは,アメリカの大学図書館の連合体で,初期のUnicode開発で大きな役割を果たしています。
しかし,CJKシソーラスのそもそものアイデアは,日本の国会図書館の高橋さんの提案です。
>Unicodeを最初に考えた人たちは、日本、中国などの漢字
>の文字数があまりにも多く、コードスペースの中に入りき
>らないという単純な動機から、同じ形の漢字に一つのコー
>ドポイントを与えようと考えたのではないかと思います。
この記述は完全な誤りです。
投稿者 芝野耕司 : 2006年01月09日 14:39
Unicodeにおける漢字統合のアイデアは、そもそもは高橋徳太郎さんの「A Proposal for a Standardized Common Use Character Set in East Asian Countries」(46th IFLA General Conference, Manila (August 18-23, 1980), Paper 83/INF/JE)に源を発しています。ただし、ISO 10646における漢字統合は、1989年10月のJTC1/SC2/WG2(アンマン)での中国提案に端を発していて、1991年7月のCJK-JRG(北京)で中国が押し切ったというのが現実で、その意味では『3次元概念モデル』ってのは所詮アトヅケに過ぎないような気もします。なお、中国提案の概要は、「Chinese National Position on HCC」(JTC1/SC2/WG2/N512, October 16, 1989)か、あるいはKim-Teng Luaさんの「A Proposal for Multilingual Computing Code Standardization」(Computer Standards & Interfaces, Vol.10, No.2 (Summer 1990), pp.117-124)あたりをごらん下さい。
投稿者 安岡孝一 : 2006年01月09日 14:08
安岡さん
こんにちは。
書籍などでお名前は存じあげています。
コメントありがとうございます。
以前に、中国の先生が、漢字統合の講演をしているのを聞いたこともありまして、中国人の発明などと勝手な推測を書いてしまいましたが。
いづれご指摘の資料にあたってみたいと思います。
投稿者 koba : 2006年01月08日 09:33
私の記憶が確かなら『3次元概念モデル』は、文字フォント開発・普及センターの「異体字に関する調査研究委員会」(平成元年度~平成3年度)が提案したものだったと思います。よければ「異体字に関する調査研究報告書」(文字フォント開発・普及センター, 東京, 1992年)や、田嶋一夫さんの「国際標準化のための活動と経緯」(しにか, Vol.4, No.2 (1993年2月), pp.19-25)をごらん下さい。
投稿者 安岡孝一 : 2006年01月08日 01:04