« 2006年01月05日 | メイン | 2006年01月07日 »
2006年01月06日
PDFと文字(17) – 統合漢字の理論
そもそも、日本、中国、韓国などの漢字を統合しようというのは誰が考えたのでしょうか?
Unicodeを最初に考えた人たちは、日本、中国などの漢字の文字数があまりにも多く、コードスペースの中に入りきらないという単純な動機から、同じ形の漢字に一つのコードポイントを与えようと考えたのではないかと思います。
しかし、その後の進展で、日本、中国、韓国などの専門家が参加するところとなり、漢字統合の理論を誰かが考えたようです。Unicodeの仕様書では、CJK統合漢字の理論は、3次元概念モデルとして、次のような図を用いて説明されています。この図は、漢字の簡体字が入っていますので、多分、北京の中国人の考案でしょう。
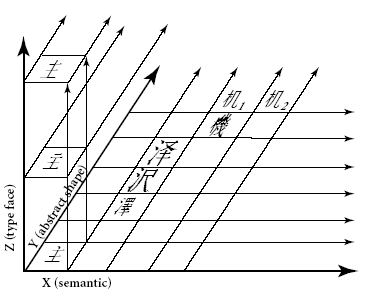
(Unicode仕様書 V4.0 Fig.11-3 p.299 より引用)
ここに、X軸はセマンティック(意味または機能)、Y軸は抽象的形状、Z軸はタイプフェース(書体)とされています。
この概念モデルに基づいて、日本、中国、韓国などの漢字をひとつにまとめたと説明しています。しかし、Unicodeの仕様書を読んでも、どうも統合にあたってのセマンティック軸の扱いが明確になっていません。そこで、この部分を私なりに検討してみました。
■仕様書V2.0では次のように書かれています。
Only characters that have the same abstract shape (that is, occupy a single point on the X and Y axes) are potential candidates for unification. Z axis typeface and semantic differences are generally ignored.
(Unicode V2.0 仕様書 p. 6-108、下から10行目~8行目)
※アンダーラインは私が付けました。以下、同じです。
3次元概念モデルでは、Y軸上で同じ位置の漢字が同じ抽象的な形状となります。抽象的形状が同じものをまとめるということは、Z軸とX軸を無視することになります。ですので上の文章は正しくありません。私の考えでは、正しくは次の文章になるはずです。
Only characters that have the same abstract shape (that is, occupy a single point on the Y axis) are potential candidates for unification. Z axis typeface and X axis semantic differences are generally ignored.
上の図の例で、セマンティックを無視すれば、![]() と
と![]() は統合され、ひとつのコードポイントが与えられます。
は統合され、ひとつのコードポイントが与えられます。
※ちなみに、この二つは字形が同じで意味が違う例として、![]() は”機械”を意味し、
は”機械”を意味し、![]() は、”机”を意味すると説明されています。
は、”机”を意味すると説明されています。
■ところが、V3.0仕様書から以降、この部分が次のように訂正されています。
Only characters that have the same abstract shape (that is, occupy a single point on the X and Y axes) are potential candidates for unification. Z axis typeface and stylistic differences are generally ignored.
(直訳)
同じ抽象的形状をもつ文字(すなわち、XとY軸の上でひとつの点を占める)のみが統合化の潜在的候補となる。Z軸のタイプフェースとスタイルの違いは一般に無視する。
この新しい説明では、セマンティック(semantic)がスタイル(stylistic)に代わってしまいました。そして、無視されるのはZ軸(タイプフェースとスタイル)のみとされています。
セマンティックの扱いは明確に書かれていません。しかし、X及びY軸で同じ位置にあるものが抽象的形状が同じ、と言っているわけですから、セマンティックが抽象的形状の一要因になったということに等しいわけです。言い換えるとセマンティックが違えば抽象的形状が違うとみなす、と暗黙に示したことになります。
このあたり、3次元(立体)で考えるのは難しいので、わかり易くするため、2つの軸、X軸×Y軸を1次元に展開して、図を書き直すと次のようになります。
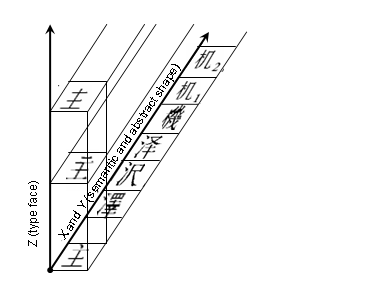
※この2次元の図は私が作りましたが、上の3次元の図と同等なはずです。
V3.0以降の仕様書では、この図でZ軸のみが無視されると言っています。ですので、![]() と
と![]() は別のコードポイントが与えられることになります。
は別のコードポイントが与えられることになります。
言い換えると、V3.0以降では同じ抽象的形状でもセマンティックが異なれば統合の候補にならない。抽象的形状とセマンティックが共に同じ漢字のみが統合の候補になると変更したことになります。
※しかし、仕様書には、統合ルールは、原規格分離規則以外は、変更してないとも書いてあります。従って、仕様書の説明に矛盾を含んでいます。
X軸、すなわちセマンティックについて考えて見ます。同じ字形の漢字でも言語によって意味が変わったり、新しい意味が付加されたりすることが多く、言語の違いがセマンティックに重要な影響を及ぼすのは明らかです。従って、字形が同じでもセマンティックが違えば別のコードポイントを与えるとなると、中国語、日本語、韓国語、ベトナム語という異なる言語の中で出現する漢字を字形で統合するのは至難になります。乱暴に言えば、セマンティックを無視しなければ、CJKVの漢字統合はできないのではないでしょうか。
結局、概念モデルではセマンティックを無視しないと言い、実際の作業はセマンティックを無視して漢字統合したということで、示した理論と実際にやったことが矛盾してしまったように思います。
V1.0でCJK漢字を統合すると言いながら、原規格分離規則によって、これを徹底できずにV3.0では原規格分離規則を廃止したというように、漢字統合ルールも振れています。
昨日、Unicodeの漢字統合は破綻してしまったと言いましたが、その原因を辿っていけば、ルールの基になる概念=3次元概念モデルが曖昧だったためではないでしょうか?
20世紀最大の偉業のはずなんですが。残念。漢字統合は、21世紀にもう一度やり直しが必要なんでしょうね。
[2006/3/15]
芝野先生のご指摘により、一部削除しました。
また、CJK統合理論が生まれた経緯につきましては、芝野先生、安岡先生にコメントをいただいていますので、そのあたりをご参照ください。
※英文にするときは、全体を修正しなければなりませんね。翻訳が遅れていますので、いつのことになりますか?
投票をお願いいたします