« PDFと文字(17) – 統合漢字の理論 | メイン | 日本語の表記は世界で最も難しい? »
2006年01月07日
漢字統合の3次元モデルについてKen Lundeの誤り
Ken Lunde著「CJKV日中韓越情報処理」という本は、コンピュータによる漢字処理の専門家にとっては必読書とされている重要な書籍です。
この本のUnicodeの漢字統合の説明の箇所でUnicodeの3次元モデルが紹介されています。Unicode仕様書は英文しかありませんし、実際のところKen Lunde本で3次元モデルを見た人の方が多いかもしれません。ところが、今回、Ken Lundeの本に紹介されている3次元モデルの図は間違っていることに気が付きました。
Unicodeの仕様書の図は次のようになっています。
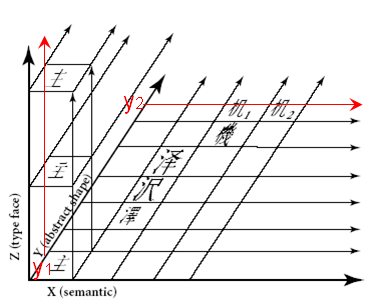
※「The Unicode Standard 4.0」 p.299の図を引用
赤の座標値と矢印は、私が追加。
Y軸の座標値が同じである漢字の例として、抽象的形状が同じでセマンテッィク(Ken Lunde本の訳では字義)が異なるとして、その例として、機械の”機”の略字![]() と”机”
と”机”![]() が出ています。
が出ています。
また、抽象的形状が同じで書体が異なる例が、Z軸方向に配置されています。
これに対して、「CJKV日中韓越情報処理」には図3-1 漢字の字形を比較する3次元モデルとして、次の図が掲載されています。

※「CJKV日中韓越情報処理」の日本語版(2002年12月刊)p.123の図を引用
赤の座標値と矢印は、私が追加。
Ken Lundeの図で、Y軸の座標値が同じである漢字とは、X軸、Z軸と平行な赤色の矢印で示す位置にある漢字となります。この図では、Y軸の定義とされている座標値が同じ文字は抽象的形状が同じが満たされていません。つまりKen Lundeの図は、Unicodeの3次元モデルの正しい説明になっていません。
ところで、この部分、日本語版の説明は次のようになっています。
漢字の字形は、3次元モデルによって比較することができる。X軸(字義)は、漢字を意味によって分け、Y軸(抽象形状)は、X軸上の漢字を抽象化された形状(同定し得る形状)毎に分ける。つまり、ある漢字の正字体と簡略字体は同じY軸の上に置かれる。Z軸(字形/書体)は漢字を字形の違いによって分ける。
(p.122 下から10行目~下から6行目)
このアンダーラインの部分は、座標軸としてのY軸の解釈を間違えていると思います。そこで念のため原文に当たってみたのですが、原文は次のようになっています。
...Traditionnal and simplified forms of a particular Chinese character fall into the same X axis position, but have different position along the Y axis. ..
(CJKV Information Processing, by Ken Lunde, January 1999, First Edition, p.124)
日本語版は訳が誤っていますね。正しくは、次のようになります。
中国の漢字の正字体と簡略字体は、X軸上では同じ位置になる、しかし、Y軸に沿っては異なる位置になる。
原書で図と本文の説明の意味が食い違っているため、図の意味が分からなくて、翻訳者たちも苦労したのでしょうね。「CJKV日中韓越情報処理」は、”バイブル”と言われている本ですので、ぜひ、誤りを修正してほしいものです。
投稿者 koba : 2006年01月07日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/113