« 2006年01月02日 | メイン | 2006年01月04日 »
2006年01月03日
PDFと文字(14) – CJK漢字統合問題
漢字に関する大きな問題は12月24日のUnicodeの誕生の記事で出てきましたCJK統合漢字に関するものでしょう。
CJK統合漢字は日本(J)、中国(C)、韓国(K)の3カ国の漢字で字形が似ている文字をひとつのコードポイントにまとめて作られたものです。
JIS X0221-1995(ISO 10646-1:1993に対応するJISの規格で、UnicodeV1.1と対応する)の規格書にはCJK統合漢字の各コードポイントにはC(中国、台湾)、J、Kの各字形が掲載されています。ひとつのコードポイントに最大4つの字形が見本として示されています。
コードポイントに示されている字形によっては、日本の漢字と中国の漢字で字の形が微妙に異なるものがあります。例を次の図に示します。各コードポイントの漢字は、日本の漢字にはMSゴシック、中国の漢字にはSimHeiフォントを指定して表示しましたが、このように期待する字形を表示するには、適切なフォントを指定しなければなりません。
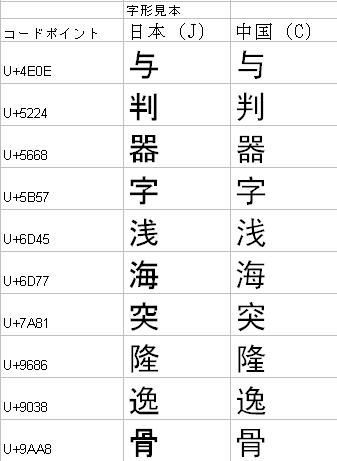
※この表は、「CJKV日中韓越情報処理」(Ken Lunde著、オライリー・ジャパン発行、ISBN4-87311-108-0、、2002年12月24日初版第一刷)のp.128の表3.82ほかの資料より作成。
Unicode4.0の仕様書、あるいは、コードチャートに掲載されている字形は中国の漢字字形になっています。
上のように、コードポイントのデータだけ、つまりUnicodeで符号化したテキストのみでは期待する漢字の形を指定できない場合があることになります。
どうしてこんなことになっているのでしょうか?これを知るために、CJK統合漢字について調べてみましょう。
CJK統合漢字は標準化時期により次の3つに分類されます。
(1)UnicodeV1.0から規定されている20,902文字。これを、このブログでは、便宜上、一般統合漢字と言うことにします。
(2)1992年~1998年に開発作業を行い、UnicodeV3.0で規定された統合漢字拡張A
(3)1998年~2002年に開発作業を行い、UnicodeV3.1で規定された統合漢字拡張B
この他に互換漢字というものがあります。
まず、一般統合漢字ですが、これは次のように作っています。
■原規格
G0 GB2312-80
G1 GB12345-90
G3 GB7589-87
G5 GB7590-87
G7 現代中国で一般的に使用する文字
G8 GB8565-88
T1 CNS 11643-1986/1面
T2 CNS 11643-1986/2面
Te CNS 11643-1986/14面
J0 JIS X 0208-1990
J1 JIS X 0212-1990
K0 KS C5601-1987
K1 KS C5657-1987
※The Unicode Standard V2.0 p.6-105, Table 6-21。V4.0の仕様書p.294, Table 11-1 ではTeが削除されている。
Gxは中華人民共和国、Txは台湾、Jxは日本、Kxは韓国の国内文字規格です。原規格から次のように文字集合を作り上げます。
1.G、T、J、Kの各グループ毎に、重複する文字は捨てて重複しない文字を集める。
2.1.で集めた文字に対して、3.の統合化規則に従って、同じ漢字に同じコードポイントを与える。
まず、概念モデルとして、漢字には①意味、②抽象的形状、③タイプフェース(文字デザイン)の違いがあるとして、②抽象的形状が同じものを統合化の候補とすると述べています。
3.統合化の規則
R1 原規格分離規則:原規格で別のコードポイントが与えられる漢字は別のコードポイントを与える(統合化しない)。
R2 形が似ていても起源が異なるものは統合化しない。
R3 同じ抽象的形状をもっていて、かつ、R1、R2規則で統合化を禁止されない漢字を統合化する。
抽象的形状が同じかどうかを決めるのは難しいと思うのですが、仕様書には次のように書かれています。
①漢字の部品の構造を比較する
②漢字の特徴を比較する
・部品の数
・部品の相対位置
・対応する部品の構造
・原漢字集合での扱い
・部品に含まれる部首
③上の特徴がひとつでも違うと異なる抽象的形状をもつとし、これらの特徴が同じなら抽象的形状が同じとする。
こうやって、CJKの漢字を国を無視して、同じような形状の漢字に同じコードポイントを与えたのです。
投票をお願いいたします