« 日本語の文字についての用語について(8) — 文字コードとフォント | メイン | 第18回 XSLSchool 開催 »
2007年01月22日
日本語の文字についての用語について(9) — PDFへのフォント埋め込みとは
丁度、良い機会ですので、PDFへのフォントの埋め込みについて説明してみます。
昨日の図の記号で、フォントを埋め込んだPDFとフォントを埋め込まないPDFを比較して示しますと、次のようになります。
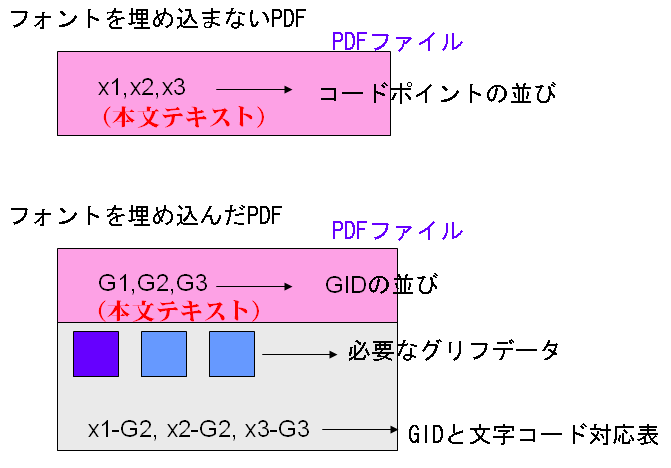
フォントを埋め込まないPDFでは、文字列が文字コードによって表されていますが、フォントを埋め込んだPDFでは、文字列がGIDによって表されています。そして、そのGIDに相当するグリフデータがPDFの中に一緒に埋め込まれているのです。
GIDに相当するグリフデータは、コンピュータのOSが画面に字の形を表示するためのデータです。従って、フォントを埋め込んだPDFを表示するとき、PDFの中のグリフデータをそのまま使って文字を表示すれば、理論的には、文字化けがなくなることになります。
理論的にはと言いましたのは、実際は、プログラムにはバグがつき物だからです。ですので、もし、フォントを埋め込んだPDFで文字が化けるとしますと、PDFを作成する過程で、あるいは、PDFを表示する過程で、関与するプログラムのどこかにバグがあるということになります。
さて、フォントを埋め込んだPDFでは、もう一つ、GIDと文字コードの対応表が必要です。なぜかといいますと、GIDは、文字コードではありませんので、文字コードを必要とする処理はGIDではできないからです。
文字コードを必要とする処理とは、例えば、PDFからテキストを取り出したり、あるいは、PDFの中の文字を検索したりなどの処理です。
GIDと文字コードの対応表は、ToUnicode CMapといいますが、実は、インターネットで流通しているPDFには、ToUnicode CMapがないPDFがかなりの割合で含まれています。これは、PDFを作成するソフトに不可全なPDFを作成するものが多々あるということが原因です。
【1月26日追記】
上の図は、「必ずしも正しくない」、と、弊社のプログラム担当者から指摘されました。PDF Referenceでは、PDFに埋め込むのは、GIDではなくCIDになっている、とのことです。但し、CIDは、Adobe-Japan1のCIDではなくCharacterIDの意味で使用しているようです。同じCIDでも意味が違うことになります。また、埋め込み時に、CIDではなく文字コードになることもあるそうです。
あまり細かいことを書くと、開発ノウハウの流出になりかねないですし、プログラマ以外には関心もないことでしょうから、このくらいにしておきますが。上の図は、大筋正しいですが、細かいところで、誤りがあるようですので、PDFを開発するプログラマの人は鵜呑みにしないでください。
投稿者 koba : 2007年01月22日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/573