« 2007年01月20日 | メイン | 2007年01月22日 »
2007年01月21日
日本語の文字についての用語について(8) — 文字コードとフォント
次に、OpenTypeなどのフォントを使う場合において、文字コードと実際に表示される文字の形状との関係について考えてみたいと思います。
コンピュータ間で、通常、交換したり処理するデータは文字コードであって、文字の形ではありません。画面に表示したり、印刷する文字の形を表すためのデータは、フォントファイルに含まれています。
例えば、アウトラインフォントで文字を表示する仕組みについては、
2006年04月24日PDFとフォント(15) アウトラインフォント
などでお話しました。
アウトラインフォントで文字の形を現すためのデータは、グリフデータと言いますが、フォントファイルの中には多数の文字のグリフデータが収容されています。そして、各文字を表示するためのグリフデータには、識別番号がついています。OpenTypeフォントでは、これをGIDと言うようです。
フォントファイルの中には、文字コードからGIDへの対応表も含まれていますが、これをcmapと言います。多分、cmapでは、文字コードから代表的なGIDに対応させます。アプリケーションは、該当の文字に、縦書き用の字形、異体字、などがあるときは、フィーチャテーブルを使って他のGIDに置換できるはずです。この仕組みは次の図のように表すことができるでしょう。
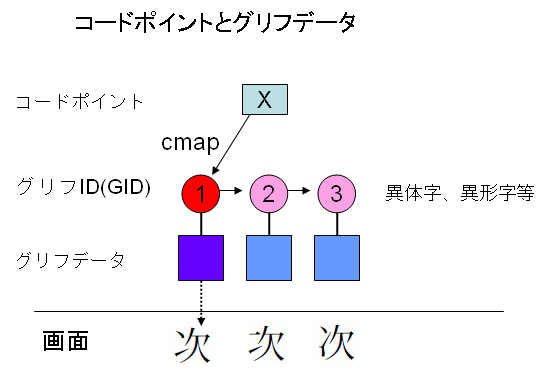
【ご注意】フォントファイルの仕様書ざっと読んで理解した範囲です。自分でプログラムを作ってみれば正しいかどうか検証できますが、検証してないので上の図、多分、このような仕組みになっているはずという話。誤りがあればご指摘いただければうれしいです。
上の図は、文字コードXに対して、GIDは1番が通常対応しますが、アプリケーションは、OpenTypeのフィーチャテーブルを使って、2番、3番に切り替えることもできることを示しています。パソコンのOSは、選択されたGIDに該当するグリフデータを使って、文字を画面上に可視化します。
ここで、Adobe-Japan1のCIDは、上の図で言いますと、1番~3番のGIDに相当します。そして、フォントファイルの中には、CIDを見て、デザインされた文字の字形描画データが入っていることになります。
投票をお願いいたします