« PDFと文字 (38) – Unicode標準形NFCの実装 | メイン | PDFと文字 (40) – Unicode標準形式NFCの問題点 »
2006年02月02日
PDFと文字 (39) – Windowsへ表示とPDF作成の相違
昨日、XSL FormaterV3.4ではWindowsの画面には正規分解を正しく表示できても、PDFでは正規分解を正しく表示できない、ということを示しました。
実は、このあたりがWindowsの大変ややこしいところなのです。
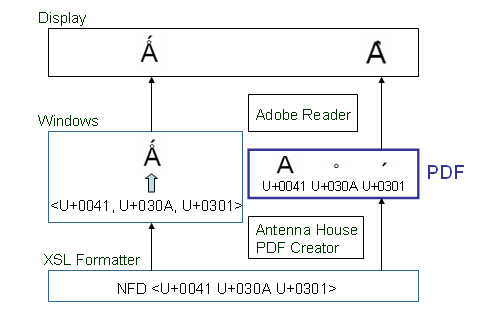
Latin capital letter A with ring above and acute (![]() )という文字をWindowsの画面に表示することを考えて見ます。この合成文字のコードポイントはU+01FAです。もし、入力されたデータの中の文字コードが正規分解
)という文字をWindowsの画面に表示することを考えて見ます。この合成文字のコードポイントはU+01FAです。もし、入力されたデータの中の文字コードが正規分解
そうしますと、Windowsが文字の形を作り出して ![]() という形を画面に表示します。
という形を画面に表示します。
一方、PDFを作成するときは、正規分解
これに対して、V4.0でLatin capital letter A with ring above and acute (![]() )を画面でもPDFでも正しく表示できるのは、Formatterの方で、正規分解
)を画面でもPDFでも正しく表示できるのは、Formatterの方で、正規分解
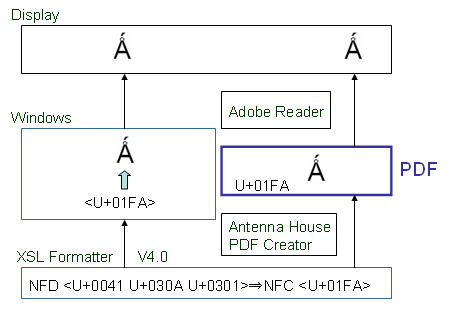
以上により、Unicodeの結合文字列から合成文字にするのは有効なように思います。では、この問題点はないのでしょうか?引き続き検討してみましょう。
投稿者 koba : 2006年02月02日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/145