« PDFと文字 (30) – アラビア文字Harakatの結合処理 | メイン | PDFと文字 (32) – 文字コードと情報交換を考える »
2006年01月23日
PDFと文字 (31) – リガチャ
アラビア文字のもう一つの特徴はリガチャ(合字)です。結合文字は基底文字を主とすると、その基底文字の上・下に付く従たる文字と言って良いと思います。
これに対して、リガチャは特定の二つ以上の文字が並んだときに、二つの文字のグリフを並べる代わりに別のグリフに置き換えるものです。アラビア文字ではラムとアレフの2文字が連続したときは、リガチャにするのが必須です。
ラテンアルファベットにもリガチャはありますが、アラビア文字のリガチャは文脈依存のグリフとの組み合わせになるため複雑です。
・ラムとアレフのコードポイント
| 名称 | コードポイント |
|---|---|
| ラム | 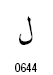
|
| アレフ | 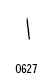 |
ラムは、文脈依存のグリフを4つもちます。これに対して、アレフは常に単独形となります。この二つの文字が連続する場合、リガチャがなければラムの左にアレフが接続したU型のカーブをもつ文字になりそうなものです。(あるいは、ふたつの文字はつながらない?)しかし、リガチャにより別の形になるとされています。
(次の図を参照)。

※フォントは、Arabic Typesettingを指定。実際のところはアレフは次の文字(左)に接続しませんので、ラムとアレフのリガチャは、単独形と右接形(FinalForm)しかもたない、というべきかもしれません。また、上の図でリガチャなしは無理やり作成したもので正しくないものですので、ご注意ください。
PDFと文字 (28) – アラビア文字のプログラム処理の(1)文字の結合(Cursive Joining)の項に出てきましたが、Unicodeにはゼロ幅接合子(Zero Width Joiner:U+200D)、ゼロ幅非接合子(Zero Width Non-Joiner:U+200C)という文字があり、これを使うことで擬似的に接続状態を制御して文脈依存のグリフの切り替えを行うことができます。
例えば、上のリガチャの図では対象文字の接続する側にU+200D、接続しない側にU+200Cを配置しています。
投稿者 koba : 2006年01月23日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/131