« PDFと文字 (35) – 文字の合成方法 | メイン | PDFと文字 (37) – 結合文字列の正規合成 »
2006年01月29日
PDFと文字 (36) – 文字の合成方法(続き)
さて、昨日の説明をお読みになって、Unicodeでは、コードポイントを与えられていない文字についても、基底文字と結合文字から合成することのできる文字なら、必要に応じて合成できるのか、これは便利だな、とお思いになった方も多いと思います。
実際、Unicodeの仕様書には文字をダイナミックに合成できそうなことがいろいろと説明してあります。仮にラテンアルファベットに限ったとしても、本当にそんな便利なことができるのでしょうか?そのあたりの記述を取り上げて整理してみましょう。
基底文字とダイアクリティカルマークの文字列(pp. 44-45)
・Unicodeでは、基底文字に結合するダイヤクリティカルマークを、基底文字に続けて適用する順番で使用します。
・二つ以上のダイヤクリティカルマークをひとつの基底文字に適用することがあります。規定文字に続く結合文字の数は制限していません。
・ダイヤクリティカルマークは、出現順に内側から外側に向かって配置していきます(これをインサイドアウトルールと言います)。従って、ダイヤクリティカルマークの順序に意味があります(下の図)。
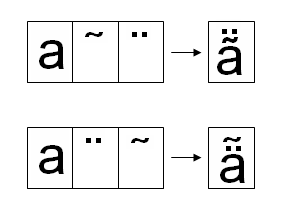
結合文字の適用(pp. 82-83)
・囲み記号は先行する文字の周りを順番に取り囲みます。従って、囲み記号が順番に出現すると後の記号は前の記号の周囲を囲むことになります。
・二つの文字に結合する二重のダイヤクリティカルマークは他の字幅のない記号(non spacing mark)よりもルーズに結合します。従って他の字幅のない記号の外側に配置します。
結合クラス(pp. 97-98)
結合文字の結合クラスは、その文字が基底文字に対してどこの位置に配置されるかを示します。(これは昨日の図で示しました)。
字幅のない記号の可視化(Rendering)(pp.125-127)
・インサイドアウトルールは既定値ですが、タイポグラフィーの規則によっては変更することができます。例えば、ベトナム語では、アキュートまたはグレーブ・アクセントは、サーカムフレックス・アクセントの上ではなく、やや左右に配置されます。コードチャートのU+1EA4以降に、ベトナム語表記用のラテン拡張文字があります。
・文字の並びを合成したものが、可視化可能でないときの救済の方法としては、Unicodeの仕様書のように結合文字を点線の円と共に、基底文字とは別に表示するか、単純に基底文字に重ねます。
・文字間を広げる際の字幅のない文字の取り扱いについては、基底文字と結合文字の組がずれないようになど、結合文字の配置についての記述がいろいろあります。
仕様書7.2 Combining Marksの節にも結合文字の可視化の方法について繰り返して類似のことを説明しています。
このような記述は、いかにも、基底文字と結合文字を使ってその組み合わせの文字を画面に奇麗に表示したり、印刷したり、PDF化ができることを期待しているように思えます。
しかし、実際にそのようなことが自由にできるようには、相当なインテリジェントをもつフォントとそれを使いこなせるアプリケーションが必要でしょう。
例えば、上の図に示しました基底文字aにCombing tilde (U+0303)とCombining Diaeresis (U+0308)をつけた合成文字はUnicode4.0にはコードポイントがありません。では、この合成文字をa, U+0303, U+0308の並びから合成して表示できるかと言いますと、例えば、Microsoft Wordではできません。次図のようになってしまいます。
一番右がMicrosoft Word2003で文字列を表示したところ。(フォントはTimes New Romanを指定)
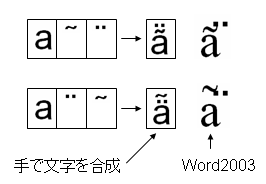
Wordは、tildeの高さの制御を行っています。もしかすると<U+0061,U+0303>という文字列をU+00E3(Latin small letter with tilde)に置換しているのかもしれません。
このように、任意の合成文字を正しく表示するには結合文字の位置を自在にあやつることができないと無理なことがわかります。
投稿者 koba : 2006年01月29日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/139