« PDFと文字 (36) – 文字の合成方法(続き) | メイン | サーバベース・コンバータ V1.2をリリース »
2006年01月30日
PDFと文字 (37) – 結合文字列の正規合成
昨日は、任意の新しい文字を、結合文字を使って合成して表示したり印刷したりするというのは、どうやらまだ夢の中のことらしい、ということをお話しました。
では、Unicodeでは結合文字列を合成して表示することはできないのでしょうか?
調べてみましたところ、正規合成(canonical composition)という方法があり、これを使えば、Unicodeでコードポイントをもつ合成済み文字の範囲ならば、殆どの文字を、結合文字列から合成できるように思います。
但し、Microsoft Word2003、OpenOffice.org2.0で試したところ、どうも両方とも正規合成をサポートしていないようです。
では、実際に、正規合成を使って結合文字列から合成済みの文字を合成して、表示・印刷・PDFにすることができるのでしょうか?このあたりをもう少し検討してみたいと思います。検討にあたり、最初に用語を明確にしておきましょう。
結合文字列 (Combining character sequence) p.70 D17
基底文字とそれに続く一つ以上の結合文字の並び、または、一つ以上の結合文字の並び。合成文字列 (Composit character sequence)とも言います。
分解可能な文字 (Decomposable character) p.71 D18
Unicodeの仕様書で文字の名前を指定している箇所で、名前の後に文字の分解マップが指定されている文字を言います。なお、分解マップには正規分解マップ(≡で示される)と互換分解マップ(≈で示される)があります。次の図はU+1E99の正規分解マップが<U+0079, U+030A>、U+1E9Aの互換分解マップが<U+0061, U+02BE>として与えられていることを示します。

合成済みの文字 (precomposed character)、合成文字(Composit character)とも言います。
分解 (Decomposable character) p.71 D19
分解可能な文字と等価な一つ以上の文字の並び。分解が1文字の場合もあることに注意しましょう。
※なお、以下では互換分解については説明しません。
正規分解 (Canonical decomposition) p.72 D23
分解可能な文字を正規分解マップを使って分解します。分解の中に分解可能な文字が入っているときは分解を繰り返し、完全に分解します。次に、分解の中の幅を持たない文字に対して正規並び変え(Canonical ordering)を適用します。この結果が正規分解です。
正規分解が一文字になることもあります。
正規分解可能な文字 (Canonical decomposable character) p.72 D23a
正規分解が自分自身と異なる文字のこと。
正規合成済みの文字 (Canonical precomposed character)、正規合成文字 (Canonical composit character) とも言います。
正規等価 (Canonical equivalent) p.72 D24
二つの文字列は、その二つの文字列の完全な正規分解が同じになる時に正規等価と言います。
正規並び替え(Canonical ordering) pp. 84-85
結合文字は基底文字または先行する結合文字列に対して特定の結合の仕方をします。結合文字に与えられる結合クラスが、この結合の仕方を決めていることは既に説明しました(2006年01月28日 PDFと文字 (35) – 文字の合成方法)。特に結合クラスが同じ値の場合は、結合文字はインサイドアウトルールで配置されます。このように結合文字の順序には意味があります。
従って、正規並び替えでは、二つの結合文字列が同じかどうかを比較するために、結合文字列を結合文字の順序の意味を変えない範囲で(すなわち、結合クラスが同じ値の結合文字の順番は入れ替えないで)、小さいほうから順に並び替えます。
正規合成 (Canonical composition)
分解の中の二つの文字のペアを、そのペアと正規等価なUnicodeの合成済の文字に置き換えていく処理。但し、合成除外文字(Composition Exclusion Tableの文字)は置き換えしません。
※UAX#15 Unicode Normalization Forms を参照。
UAX#15では、Unicode文字の4つの標準形を規定しています。その中で正規分解、正規合成に関係するのは次の二つです。
(1) 標準形式D(NFD):これは上に説明しました正規分解の形式です。
(2) 標準形式C(NFC):文字を正規分解にした後、正規合成した形式です。
次に簡単な絵で説明します。
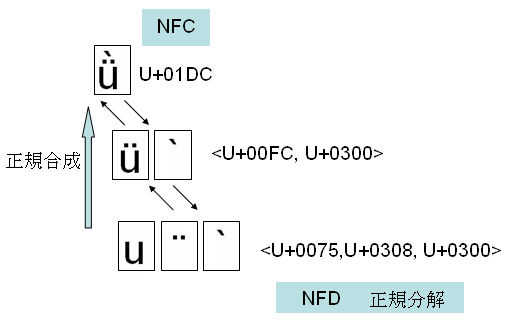
Latin small letter u with diaeresis and grave (U+01DC)は Latin small letter u with diaeresis (U+00FC) と Grave (U+0300)への正規分解マップをもちます。さらに、Latin small letter u with diaeresis は、Latin small letter u (U+0075) と Diaeresis (U+0300)への正規分解マップをもちます。NFDは一番下の形です。NFCは一番上の形です。
Latin small letter u with diaeresis and grave は、NFD形式では、uとGraveとDiaeresisの並びになります。NFD形式を正規合成するとNFCになります。
これを応用すれば、複雑な合成済み文字ラテン文字を基底文字と結合文字でバラバラに記述しておき、表示・印刷・PDF化するときに合成文字にする、ということができそうです。
ということで、この機能をXSL Formatter V4.0のα版に組み込んでもらいました。組み込みは簡単で、数日で、できてきましたので、次に、ちょっと試してみましょう。ほんとにうまくいくのでしょうか?
※XSL Formatter V4.0 α版はまだ一般公開はしていませんが、近いうちに一般公開の予定のものです。
※ご参考
NFD、NFCについては下記にも良い情報があります。
Unicode正規化とは
投稿者 koba : 2006年01月30日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/140