« PDFと文字 (31) – リガチャ | メイン | 中国のOffice文書標準XML形式 UOFの動向 »
2006年01月24日
PDFと文字 (32) – 文字コードと情報交換を考える
日本のJIS規格に関する議論、さらにUnicodeについても議論でも、字の形と文字コードが1対1になることを暗黙に想定した議論が多いように思います。しかし、アラビア文字はその典型的な例ですが、文字コードと画面表示・印刷される字形は1対1になっていません。
この仕組みを次のような簡単な絵で表してみました。
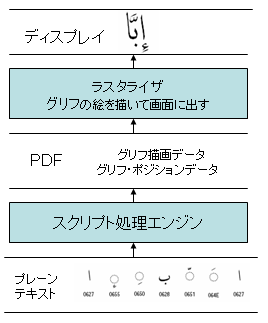
この図の中の言葉の意味は次の通りです。
・プレーンテキストとは、2005年12月15日のPDFと文字(4) – 文字の取り扱いで述べました、飾りのない本文文字にあたります。
・グリフ描画データとは文字の形を描画するためのデータまたはプログラムです。2006年01月13日PDFと文字(22) – グリフとグリフセットあたりをご覧ください。グリフポジションデータとは、そのグリフをどの位置に描画するか、というデータと理解してください。PDFの中には、かなり抽象化して言いますと、テキストを表示・印刷するためのグリフ描画データとグリフポジションデータが収容されているということができます。
さて、コンピュータで電子ドキュメントを情報交換する場合、まず、どのレベルで情報交換をするか、ということを考えなければならないでしょう。上の図で言いますと、プレーンテキストを情報交換するか、それとも、例えば、PDFのレベルで交換するかということになります。両方セットで交換することももちろん可能でしょう。
プレーンテキストレベルで交換した場合、受け手の側に、送り手と同じスクリプト処理エンジンが必要となります。具体的に言いますと、例えばWindowsではUniscribeというスクリプト処理エンジンがあり、これがUnicodeのテキスト文字列を受け取って正しいグリフの列や位置を割り出す処理をしているようです。Linuxなどでこのプレーンテキストを表示しようとしますと、同等の機能をもつエンジンを使わないと正しく表示できないことになります。携帯電話などで読もうとするときも同じです。
このように見ますと、プレーンテキストレベルでの情報交換は必ずしも最適解ではないケースが多いだろうと思います。
これに対して、PDFのレベルであれば、スクリプト処理エンジンの出したデータを交換するわけですから、オリジナルの情報を加工するとき、例えば、WindowsでUniscribeを使ったとしても、受け手には同じ機能は不要です。
このように、文字コードと画面表示・印刷される字形とを分離させて考えることは、漢字の場合にも有効なように思います。
漢字については、2000字も使えれば、一般的のコミュニケーションは可能でしょうし、さらに、5000字を使えれば相当なもの。1万文字を使いこなせる人は日本にも殆どいないでしょう。このような現実に対して、7万を超える文字にひとつづつ情報交換用のコードポイントを与えても情報交換という意味ではあまり意味がないように思います。どうしても文字の形状を交換したいのであればグリフデータを交換することを考えるのも有益だろうと思います。
※参考資料
Uniscribeについてはこちらにも説明があります。
Uniscribe
投稿者 koba : 2006年01月24日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/132