« 第18回 XSLSchool 開催 | メイン | PDFの解像度とは? »
2007年01月24日
日本語の文字についての用語について(10) — 文字コードと漢字の字形
日本語における漢字の字形と文字コードの関係について、とりあえず、まとめて見ます。
UnicodeやJIS X0213のような、文字コードの規格は、コンピュータで日本語を処理するために漢字を含む文字に符号を与えた、漢字を抽象化した存在であるということです。
それに対して、現在のコンピュータの画面や印刷される漢字は、フォント技術を使って可視化した具体的なものです。Adobe-Japan1のような文字を集めたものは、フォントの開発用のものであって抽象化した文字集合ではないと思います。
漢字は、ラテンアルファベットとは違って、1文字=1単語という意味合いが強いもので、その成り立ちからしても、形が単語の意味に密接に関係しています。しかし、抽象化した文字コードと具体的な字体を同列に論じることはあまり意味がないと思えます。
コンピュータによる日本語処理は、画面・紙への可視化のみでなく、検索やソートなどの対象にもなります。
例えば、日本語の文字についての用語について(7) — Adobe-Japan1の用語で紹介しました、「次」の異形字についても、CIDはそれぞれ、2253、13799、13800と別ですが、Unicodeは3文字ともU+6B21で、Adobe Readerの検索では3文字とも同一の字としてヒットします。

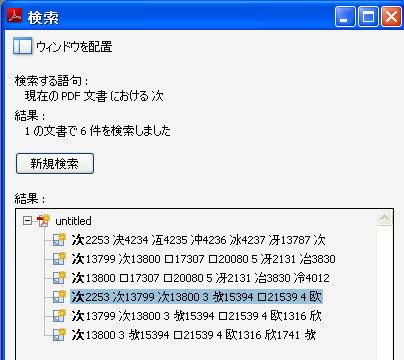
ですので、字の形だけ考えても片手落ちという感は免れません。字の形とその意味の違いまで同時に調べていかないといけませんね。そういう話になってしまいますとなかなか難しいのですが。
投稿者 koba : 2007年01月24日 08:00
トラックバック
このエントリーのトラックバックURL:
http://blog.antenna.co.jp/PDFTool/mt-tbng2.cgi/575