« 2006年12月 | メイン | 2007年02月 »
2007年01月31日
Adobe PDFをISO標準として提出へ
米国Adobeは、29日(現地時間)に、PDF Reference 1.7をISOの標準とすべくAIIMに提供すると、発表しました。今後は、AIIM経由で、PDFのISO標準へ向けて作業が進むことになる見込みです。
Adobe to Release PDF for Industry Standardization
PDFをベースとする標準としては、PDF/X、PDF/Aが有名です。AIIMは、米国の企業向けコンテンツ管理の団体で、これまでもPDF/Aの策定に深く関わっています。
また、AIIMは、現在作業が進んでいるPDF/E(エンジニアリング)の策定作業にも参加するなど、PDF関連のISO標準化の実績があります。
PDFのISO標準化の進展については、次のブログが参考になります。
History of PDF Openness
PDF関係のISO標準化が進むと、その次のステップとしてPDF本体の仕様そのものを国際標準にする、というのは、自然な流れといえます。
今後、PDFの仕様の決定が、私企業の手から標準化団体へ移ることによって、仕様の革新のスピードが落ちることが問題と言う意見もあるようですが、しかし、PDFのような重要な仕様が、ベンダー中立な国際標準になることは歓迎すべきことには違いありません。
アンテナハウスは、XSL-FOという国際標準の実装と販売の経験を通じて、標準仕様というものが、特に、海外の市場において極めて重要なインパクトをもつことを肌身にしみて感じています。
特に、PDFは、今後のインターネットを通じての情報の交換には、無くてはならないものです。
日本市場は、海外と比べてPDFの利用について、やや立ち遅れの感があります。日本のビジネスは、まだまだ紙が重要な地位を占めていますが、いづれは、紙を減らしていくことがさらに厳しく求められるようになることは間違いありません。
私は、これでますますPDF開発投資を積極化しようという意欲が沸いてきました。Adobeの経営者の決断に感謝したいと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月30日
文字コード — 符号化文字集合と符号化方式
たまたま、フリー百科事典『ウィキペディア(Wikipedia)』の「テキストファイル」の項を見ていたら、文字コードという項がありますが、内容に訂正する方が良いと思われる箇所があります。
「また、英数以外の文字は言語ごとに異なる文字コードが使われているため、英語以外の複数言語を混在させることは。。」
「日本語では次の3種類の文字コードがあり、文字化けなどの問題が多発する原因となっている。」として、ISO-2022-JP、Shift JIS、EUC-JPを挙げています。
次に、「Unicodeは、日本語も含めた世界中のすべての文字を1つの文字コードで表すための規格である。Unicodeが広く普及することで、英数字以外の文字を扱うときの互換性を高め、また多言語が混在する文書が容易に作成できるようになることが期待されている。
しかし、現在のUnicodeは普及途上ということもあり、新しい文字コードがさらに増えたことにより混乱が増している一面もある。」
上の説明の中の問題を挙げます。
1.文字と言語を明確に区別していない
例えば、英語はラテンアルファベットを使って記述しますが、フランス語やドイツ語もラテンアルファベットを使って記述します。
アラビア語はアラビア文字を使って記述しますが、アラビア文字で表す言語には、他にペルシャ語、ウルドゥ語(パキスタン)、現代ウイグル語の表記にも使われます。
このあたりは、以下を参照してください。
2005年12月12日 PDFと文字(1) – 言語と文字
2005年12月13日 PDFと文字(2) – 言語と文字 続き
つまり文字と言語は1対1ではありません。但し、文字コードは20世紀には標準化が国単位で行われたため文字コードと言語が1対1対応になる傾向がありました。
2.符号化文字集合と符号化方式を明確に使い分けていない
・ISO-2022-JP、Shift JIS、EUC-JPは符号化方式の種類です。
・Unicodeは符号化文字集合の名前です。Unicodeの符号化方式としては、UTF-8、UTF-16などがあります。
ですので、ISO-2022-JP、Shift JIS、EUC-JPに対してはUTF-8、UTF-16などを対比させる必要があります。
符号化文字集合と符号化方式については、同じWikipediaの「文字コード」の項を参照してください。
フリー百科事典『ウィキペディア(Wikipedia)』は、便利なもので、皆でさらに充実していきたいものです。この「テキストファイル」の項は、少し書き直す方が良いように思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (2) | トラックバック
2007年01月29日
最近知ったブログなど
■言語工学研究所 国分社長の社長ブログ
http://blog.ruigo.jp/kokublog/
内容:日本語処理のシステムに取り組んでいて思いついたこと
2006年11月開始
国分さんは、もう知る人も少ないかも知れませんが、管理工学研究所で初代の「松」を開発された方です。6x歳でなお現役プログラマ。2x年前、プログラマ35歳定年説というのがあったようですが、そんな説はまったく正しくなかったことを証明する人。もう20年以上、日本語処理システムに取り組んでおられるようですが、最近は特に構文解析の開発が中心のようです。試行錯誤するときや、細かなことは人に頼むのよりは、やはり自分でプログラムを書く方が早いのだそうです。
■長村 玄氏のブログ 「明朝体・考」
http://nagamura.jp/moji/minchou/
内容:日本語の基軸書体である「明朝体」について考える
2006年08月開始
字体・字形について事象に現れる表面的なことでなく、根源から考えようとしているとことが伺えます。いま、社会現象としての文字の連載を連載中です。早く、続きを読みたいものです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月28日
PDFの解像度とは?(3) GDI 型PDF Driverの解像度
前回は、PDFの仕様上はグラフィックスがデバイス独立の座標系で表される、そこで、PDFのファイルをダイレクト生成する場合は、解像度の設定は無関係、ということをお話しました。
では、なぜ、様々なPDF Driverに、解像度設定があるのでしょうか?
これについては、もう以前にお話していますが、PDF Driverは、Windowsがプリンタに印刷する仕組みをつかってPDFを作成するからです。
簡単に整理しますと、Windowsからプリンタに印刷するとき、アプリケーションはGDIという仮想的なデバイスにデータを可視化します。そして、GDIに可視化されたデータがプリンタに送りだされることになります。
GDIでは画像が1ピクセル単位で表されますので、ピクセル密度の設定が解像度設定にあたります(次の図をご参照ください)。
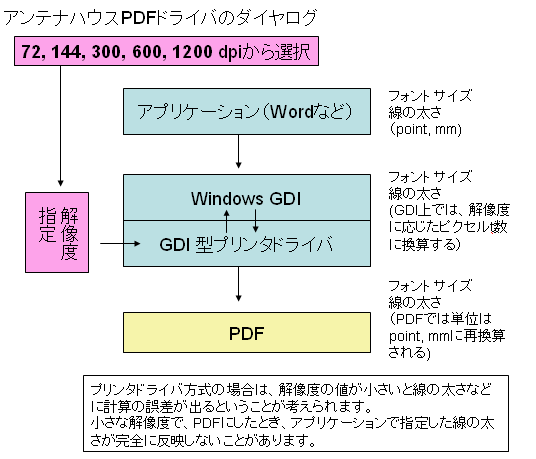
※2006年02月14日PDFの作成方法(21) – PDFドライバの解像度(続き)
結局、「GDI型のプリンタドライバ」は、WindowsのGDIを経由して、プリンタで紙に印刷する仕組みをそのまま使ってPDFを作成するため、プリンタのドット密度に相当する解像度の設定によって、PDFでグラフィックスを表す精度が影響を受けてしまうことになります。
これについて、実際に実験で示したデータについては、2006年02月13日 PDFの作成方法(20) – PDFドライバの解像度をご覧ください。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月27日
「書けまっせ!!PDF2」 ベクターよりダウンロード販売を開始
アンテナハウスでは、「書けまっせ!!PDF2」を、1月26日から株式会社ベクターを通じて、ダウンロード販売開始しました。
ベクターのダウンロード・ページはこちらです。
![]()
(イメージをクリック)
ダウンロード版はパッケージがありませんが、GUIの機能はパッケージ版と同等です。但し、サイトライセンスはありません。
定価は、税込み5,250円で、パッケージ版よりも、少し、お安く設定しています。
ところで、26日にベクターの「プロレジ大賞」の発表がありました。今期のプロレジ大賞は、相栄電器のデフラグソフト「Diskeeper」でしたね。
弊社の「リッチテキストPDF2 D&D」は、残念ながら、プロレジ大賞を取ることができませんでした。次のバージョンでは、もっと変換精度を改良して、再度挑戦したいと思います。こんどこそ、「プロレジ大賞」とるぞぉ!
ところで、デフラグソフトというと、アンテナハウスでも、15年位前、MS-DOSの時代に、デフラグソフトを開発して販売していたことがあります。名前は「DiskPlus」というのですが、あまり売れなかったので止めてしまいましたが。15年ばかり早かったのかもしれません。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月26日
PDFの解像度とは?(2)
昨日、PDFには、そもそも解像度というものがない、と言いましたが、それをもう少し分解して説明してみます。
PDFにはページの内容を表現するための様々なオブジェクトが定義されています。それらのオブジェクトの中で主なものは、次の図のような、テキスト(文字)、線画、イメージとなります。
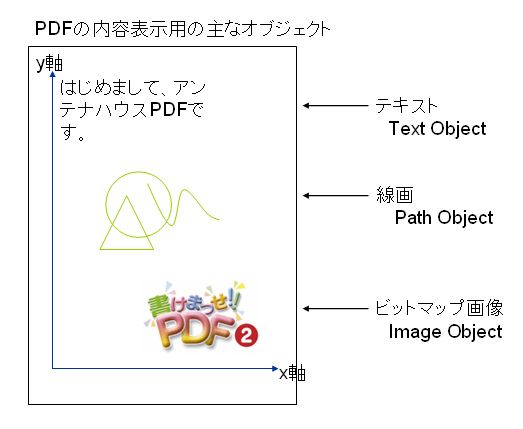
この中で、テキストは文字コードまたはGIDの形で、PDFファイルの中に含まれていることは先日お話しました。
2007年01月22日 日本語の文字についての用語について(9) — PDFへのフォント埋め込みとは
PDFのテキストを表示・印刷する時は、PDFを表示・印刷するコンピュータの上で、フォントのグリフデータを使って、アウトラインの状態からビットマップの状態に変換して可視化されます。その段階で、初めて解像度が問題になります。PDFの状態では解像度という概念はあてはまりません。
※アウトラインフォントの場合です。
PDFファイルの状態では、線画オブジェクトは2次元座標系の上に数学的な直線・曲線(パス)として表現されることができます。そうしたパスに線幅指定、色指定したり、パスで囲む領域を塗り潰したりすることで、図形が表現されます。これらの図形は、物理的な機器とは無縁の、数学的な曲線、曲線の状態を変えるパラメータで表現されていることになります。従いまして、PDFファイルの状態では解像度という概念はあてはまらないことになります。
最後のイメージ・オブジェクトは、ビットマップイメージですので解像度が関係しますが、これは、PDFに埋め込む前にビットマップとして作られていた状態のものを持ち込むことになります。ですのでPDFの解像度というよりは、画像自体の解像度ということになります。
このようにPDFファイルは、基本的にデバイスとは独立の状態でデータを保持することができますので、解像度という概念は該当しないのです。
アプリケーションが、アンテナハウスの「PDF生成ライブラリー」のようなプログラムを使って、オブジェクトを直接PDF内に記述して作成すれば、解像度設定は関係なくなる、あるいは、純粋に数学的に(デバイス独立の)PDFを作ることができます。
今日、ある会社の社長さんがお見えになって、「当社の製品は、CADファイルからPDFファイルへ、ダイレクト変換していますので、高精細です。例えば、円はいくら拡大しても円のまま」というお話をされていましたが、これはそのことをおっしゃっていたのですね。確かに、CADをPDF化するとき、線の太さなどを正確にPDF設定するには、ダイレクト変換が必要なように思います。
アンテナハウスの製品では、サーバベース・コンバータ、XSL Formatterは、それぞれ、ダイレクトPDF作成を行っています。ですので、この2製品には解像度設定はありません。できないのではなく、解像度という言葉が、そもそも該当しないのです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月25日
PDFの解像度とは?
お客様と弊社の担当者の日ごろのやり取りの中で、どうも、PDFの解像度ということが、なかなか理解が難しいようです。
これは、端的に言いましてPDFには解像度という概念はないにも関わらず、Acrobatを初めとする様々なPDF Driver に解像度を設定する機能が備わっている、ということが原因になっていると思います。
以前に、数回にわたり、PDFの解像度関係の話を取り上げたことがありますが、今回は、もう少し別の角度からおさらいして整理してみましょう。
解像度とは?
例えば、Wikipediaの解像度の説明をみますと、「解像度とはビットマップ画像における画素の密度を示す数値である。 すなわち、画像を表現する格子の細かさを解像度と呼び、一般に1インチをいくつに分けるかによって数字で表す。その単位はドット・パー・インチ(dpi)である。」とあります。
これを見ますと、まず、解像度はビットマップ画像について使用する言葉である、ということが分かります。
PDFには解像度はない?
PDFの1ページの表現方法は、原則として用紙の上下・左右の座標系を想定し、その座標の位置に線を引くか、というような、ベクトル表現でデータを表します。しかも座標系の単位は自由に設定できます。
ですので、スキャナーで作成したようなPDFの解像度(これはPDFの解像度というよりもスキャナーの解像度です)や、PDFに埋め込まれているビットマップ画像などを除いて、PDFには解像度という概念はあてはまりません。
そう言い切ってしまいますと、それで話は終わりなんです。ところが、実際は、
次の図のように、PDFを作成するDriverソフトでは、解像度を設定できるようになっています。
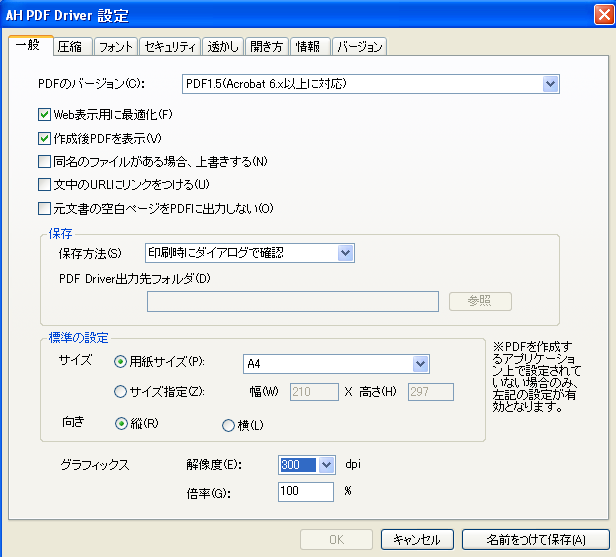
※Antenna House PDF Driver V3.1 の設定画面
これは、なぜなんでしょうか?解像度という言葉ががあてはまらないはずのPDFを出力するドライバに、なぜ、解像度設定が出てくるのでしょうか?
以前に、そのあたりのお話をしましたが、どうも今読み返して見ますと、やけに難しく書いてありますね。自分で読んでも良く分かりません。(汗)
これじゃ、わかんないや、といわれそうです。明日から、もう少し噛み砕いてお話するように試みてみましょう。
【参考】 以前の解像度に関するお話
2006年02月13日 PDFの作成方法(20) – PDFドライバの解像度
2006年02月14日 PDFの作成方法(21) – PDFドライバの解像度(続き)
2006年02月16日 PDFの作成方法(22) – Acrobatの解像度設定
2006年02月17日 PDFの作成方法(23) – GDIをバイパスして高精細なPDFを作成
2006年02月18日 線の太さについてのPDFの仕様
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月24日
日本語の文字についての用語について(10) — 文字コードと漢字の字形
日本語における漢字の字形と文字コードの関係について、とりあえず、まとめて見ます。
UnicodeやJIS X0213のような、文字コードの規格は、コンピュータで日本語を処理するために漢字を含む文字に符号を与えた、漢字を抽象化した存在であるということです。
それに対して、現在のコンピュータの画面や印刷される漢字は、フォント技術を使って可視化した具体的なものです。Adobe-Japan1のような文字を集めたものは、フォントの開発用のものであって抽象化した文字集合ではないと思います。
漢字は、ラテンアルファベットとは違って、1文字=1単語という意味合いが強いもので、その成り立ちからしても、形が単語の意味に密接に関係しています。しかし、抽象化した文字コードと具体的な字体を同列に論じることはあまり意味がないと思えます。
コンピュータによる日本語処理は、画面・紙への可視化のみでなく、検索やソートなどの対象にもなります。
例えば、日本語の文字についての用語について(7) — Adobe-Japan1の用語で紹介しました、「次」の異形字についても、CIDはそれぞれ、2253、13799、13800と別ですが、Unicodeは3文字ともU+6B21で、Adobe Readerの検索では3文字とも同一の字としてヒットします。

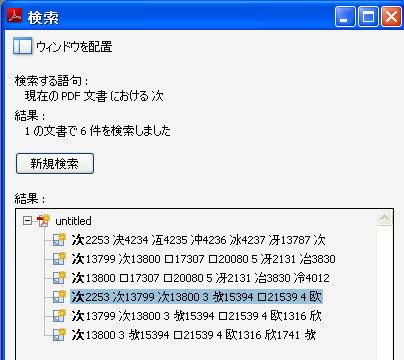
ですので、字の形だけ考えても片手落ちという感は免れません。字の形とその意味の違いまで同時に調べていかないといけませんね。そういう話になってしまいますとなかなか難しいのですが。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月23日
第18回 XSLSchool 開催
2007年2月23日(金) 、第18回XSL Schoolを開催します。
XSL Schoolは、XSL-FOによる組版を実際に体験していただく、「実習形式」のセミナーです。XSL-FOの説明に加えて、普段お使いのパソコンを持ち込んでいただき、実際にスタイルシートを打ち込んでいただきます。
このセミナーは少人数で、1日かけて、XSL-FOの基礎を講義と実践で体験していただくユニークなものです。
第一部では、XMLデータを印刷する為の基本を解説後、スタイルシートを要素ごとに一つずつ作成し、XSLFormater で組版結果を確認しながら解説を行います。
実際にスタイルシートを作っていくことで「XSLT」と「XSL」を理解し、スタイルシート作成の基本的な技術を身につけることができます。
第二部では、第一部で解説したXSL-FOの仕様について、より詳しく解説します。
XSL-FOを詳細まで解説する数少ないセミナーであるだけでなく、テキストは数少ない日本語のXSL-FO仕様解説書となっています。
XSL-FOの仕様は、V1.1が2006年12月5日にW3Cの勧告になり、XSL FormatterもXSL-FO V1.1対応版となりました。
今回は、XSL-FO V1.1による初めてのXSL Schoolとなります。この機会に、ぜひ、XSL-FOを体験して、そのすばらしさを味わってみていただきたいと思います。
詳細のご案内とお申し込みは下記のWebページからどうぞ。
XSL-FOの仕様を解説するとともに、XML文書をXSL-FOに変換するためのXSLTスタイルシートの開発技法を学ぶ
![]()
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月22日
日本語の文字についての用語について(9) — PDFへのフォント埋め込みとは
丁度、良い機会ですので、PDFへのフォントの埋め込みについて説明してみます。
昨日の図の記号で、フォントを埋め込んだPDFとフォントを埋め込まないPDFを比較して示しますと、次のようになります。
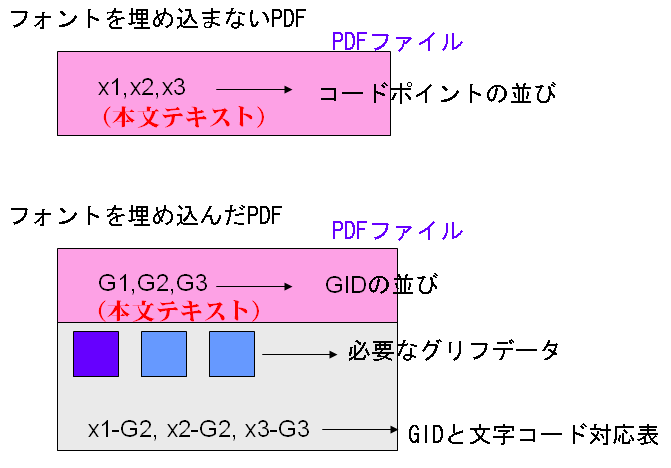
フォントを埋め込まないPDFでは、文字列が文字コードによって表されていますが、フォントを埋め込んだPDFでは、文字列がGIDによって表されています。そして、そのGIDに相当するグリフデータがPDFの中に一緒に埋め込まれているのです。
GIDに相当するグリフデータは、コンピュータのOSが画面に字の形を表示するためのデータです。従って、フォントを埋め込んだPDFを表示するとき、PDFの中のグリフデータをそのまま使って文字を表示すれば、理論的には、文字化けがなくなることになります。
理論的にはと言いましたのは、実際は、プログラムにはバグがつき物だからです。ですので、もし、フォントを埋め込んだPDFで文字が化けるとしますと、PDFを作成する過程で、あるいは、PDFを表示する過程で、関与するプログラムのどこかにバグがあるということになります。
さて、フォントを埋め込んだPDFでは、もう一つ、GIDと文字コードの対応表が必要です。なぜかといいますと、GIDは、文字コードではありませんので、文字コードを必要とする処理はGIDではできないからです。
文字コードを必要とする処理とは、例えば、PDFからテキストを取り出したり、あるいは、PDFの中の文字を検索したりなどの処理です。
GIDと文字コードの対応表は、ToUnicode CMapといいますが、実は、インターネットで流通しているPDFには、ToUnicode CMapがないPDFがかなりの割合で含まれています。これは、PDFを作成するソフトに不可全なPDFを作成するものが多々あるということが原因です。
【1月26日追記】
上の図は、「必ずしも正しくない」、と、弊社のプログラム担当者から指摘されました。PDF Referenceでは、PDFに埋め込むのは、GIDではなくCIDになっている、とのことです。但し、CIDは、Adobe-Japan1のCIDではなくCharacterIDの意味で使用しているようです。同じCIDでも意味が違うことになります。また、埋め込み時に、CIDではなく文字コードになることもあるそうです。
あまり細かいことを書くと、開発ノウハウの流出になりかねないですし、プログラマ以外には関心もないことでしょうから、このくらいにしておきますが。上の図は、大筋正しいですが、細かいところで、誤りがあるようですので、PDFを開発するプログラマの人は鵜呑みにしないでください。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月21日
日本語の文字についての用語について(8) — 文字コードとフォント
次に、OpenTypeなどのフォントを使う場合において、文字コードと実際に表示される文字の形状との関係について考えてみたいと思います。
コンピュータ間で、通常、交換したり処理するデータは文字コードであって、文字の形ではありません。画面に表示したり、印刷する文字の形を表すためのデータは、フォントファイルに含まれています。
例えば、アウトラインフォントで文字を表示する仕組みについては、
2006年04月24日PDFとフォント(15) アウトラインフォント
などでお話しました。
アウトラインフォントで文字の形を現すためのデータは、グリフデータと言いますが、フォントファイルの中には多数の文字のグリフデータが収容されています。そして、各文字を表示するためのグリフデータには、識別番号がついています。OpenTypeフォントでは、これをGIDと言うようです。
フォントファイルの中には、文字コードからGIDへの対応表も含まれていますが、これをcmapと言います。多分、cmapでは、文字コードから代表的なGIDに対応させます。アプリケーションは、該当の文字に、縦書き用の字形、異体字、などがあるときは、フィーチャテーブルを使って他のGIDに置換できるはずです。この仕組みは次の図のように表すことができるでしょう。
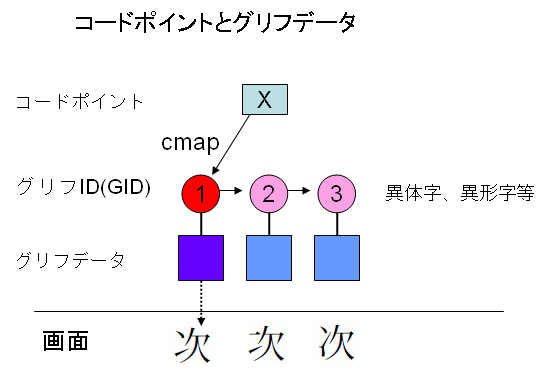
【ご注意】フォントファイルの仕様書ざっと読んで理解した範囲です。自分でプログラムを作ってみれば正しいかどうか検証できますが、検証してないので上の図、多分、このような仕組みになっているはずという話。誤りがあればご指摘いただければうれしいです。
上の図は、文字コードXに対して、GIDは1番が通常対応しますが、アプリケーションは、OpenTypeのフィーチャテーブルを使って、2番、3番に切り替えることもできることを示しています。パソコンのOSは、選択されたGIDに該当するグリフデータを使って、文字を画面上に可視化します。
ここで、Adobe-Japan1のCIDは、上の図で言いますと、1番~3番のGIDに相当します。そして、フォントファイルの中には、CIDを見て、デザインされた文字の字形描画データが入っていることになります。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月20日
日本語の文字についての用語について(7) — Adobe-Japan1の用語
Adobe-Japan1では、CIDは、文字形状の種別に対して付けられている、と説明されています。しかし、実際には、そうではなく、次のようにまったく同じ字形の文字に対して、別のCIDが割り当てられています。
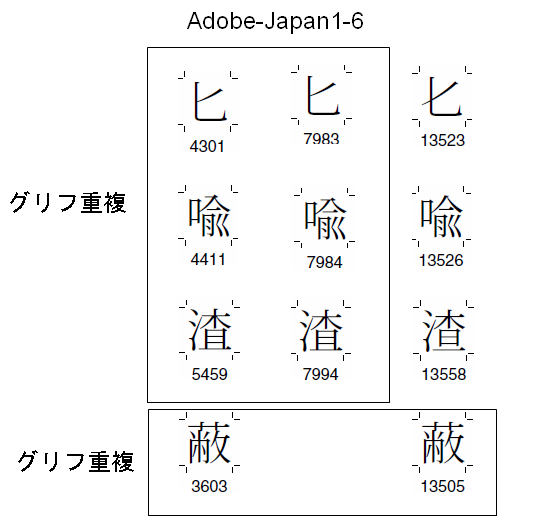
これは、歴史的な要因、およびJIS90規格との互換性を維持するためと説明されています。
また、Adobe-Japan1では、他にも微妙な字形差のグリフが別のCIDで登録されているケースがあります。
例えば、安岡孝一氏が作成した「Adobe-Japan1の漢字(部首画数順)」を見ますと、次の図のようにまったく同じグリフと思われるものが別のCIDになっているものが頻繁に見つかります。

※上図は「Adobe-Japan1の漢字(部首画数順)」より加工
http://coe21.zinbun.kyoto-u.ac.jp/results.html.ja
さらに、半角の文字や括弧類などは、横書き用と縦書き用が別々のCIDに登録されています。
そういう点を考えますと、CID、すなわち、文字形状の種別とは一体何か、意味が大変に分かりにくくなっているように思います。これは、Adobe-Japan1は、標準規格として、きちんとした考証を経て作成されたものではなく、フォントのデザイナの便宜のために字形を収集して適当に番号を付けたもの、なのだからでしょう。従って、このドキュメントでいうグリフという言葉の意味も、また、あまり明瞭でないように思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月19日
日本語の文字についての用語について(6) — Adobe-Japan1の用語
Adobe-Japan1については、丁度1年ほど前にも取り上げました。その概要は、前回の記事をご覧いただきたいと思います。
Adobe-Japan1の資料は英語版ですが、その文書で使われている用語をチェックしてみましょう。
仕様書の中から、用語に関連しそうな部分をピックアップしてみます。
○A character collection contains all gryphs required to make fonts for a particular language.(ひとつの文字の収集には、ある言語のためのフォントを作るのに必要なグリフの全てを含んでいる。)
○Each CID (Character ID) in a character collection is associated with a class of chracter shape. (文字の収集におけるCIDは、文字形状の種別に関連付けられている。)
○The specific shape of a character from a given class is dependent on the typeface style, the language, orientation, writing direction of the font,.. (与えられた種別の文字の特定の形状は、書体、言語、方向、フォントの記述方向に依存する。)
○Character instances (glyphs) for all CIDs are shown in this document, giving a specific example of the correspondence between CID number and its character chape class. (この文書には、全てのCIDについて、文字の例(グリフ)が示されていて、CID番号とその文字形状の種別との対応関係の例を与えている。)
この上の部分で言っていることを、図示しますと次のようになると思います。
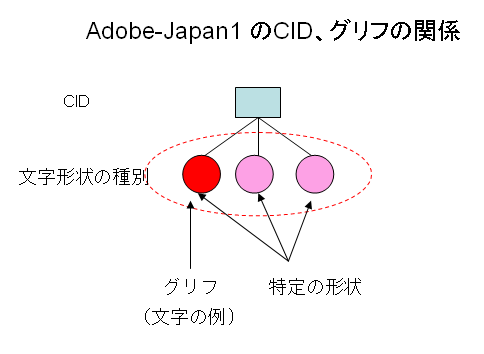
つまり、Adobe-Japan1の文字には、CIDという番号がついていますが、CIDには、一定の種類の文字の形状が対応しており、グリフがその対応関係のひとつの例として示されているということになります。ここで言っているグリフは日本語でいう字体に相当するものなのか、字形に相当するものなのかが、いまひとつ分かりにくいように思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月18日
アンテナハウスのPage 2007 出展等情報
アンテナハウスは、Page2007に次のような形で出展・参加します。ブース、プレゼンにお立ち寄りくださいますようご案内申し上げます。
1.Page 2007 開催概要
・会期 2007年2月7日(水)~2月9日(金)・3日間
・会場 サンシャインシティコンベンションセンターTOKYO
展示ホールB(文化会館4階)
展示ホールC(文化会館3階)
展示ホールD(文化会館2階)
・PageのWebサイト http://www.jagat.or.jp/PAGE/2007/
2.アンテナハウスの展示等の情報
(1)Page 2007 ブース展示
文化会館 2F ブース番号D-32にて、アンテナハウス(株)/(株)エクスイズムと共同出展
●Page展示会場におけるセミナー
2月7日(水曜日) 15:30~15:50
2月9日(金曜日) 14:30~14:50
※2月8日(木曜日) 11:30~11:50 エクスイズムによるセミナー
(2) PDF/X-PlusJ 推進協議会ブース(D-25)にて、協議会メンバのプレゼンテーションの一環として
・2月7日 14:30-14:45
・2月8日 12:00-12:15
・2月9日 14:00-14:15
各15分 「PDF/X、タグ付PDFをサポートするXSL Formatter V4.1」についてのプレゼンを行います。
(3)「コンファレンス」
2月9日(金曜日) サンシャインシティTOKYO ワールドインポートマート8階
グラフィックストラック 16:00-18:00 D6
「XMLパブリッシングと高度な日本語組版の実現」のセッション内にて、アンテナハウス 石野恵一郎が、30分程度のプレゼンテーションを行う予定です。内容は、XSL Formatterによる日本語組版になるだろうと思います。
展示会の招待券をご希望の方はお送りしますので、sis@antenna.co.jpまでメールでお申し付けください。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月17日
日本語の文字についての用語について(5) — 3階層モデル
さらに、例示字体と例示字形のどちらが適切なのだろうかと考えていて、コードポイント-字体-字形の3層モデルで考えると分かりやすいのではないかと思いました。
2007年01月09日 Windows Vista と日本語文字コード問題(5)で示しました、次の図をご覧ください。
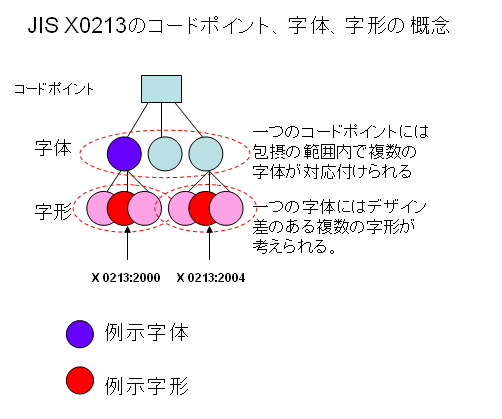
JIS X0213の考え方は、上の図で表すように、コードポイントには包摂の範囲内で複数の字体が割り当てられています。
包摂の基準にはいろいろありますが、たとえば、国語審議会の「表外漢字字体表」で、3部首許容とした「しんにゅう、しめすへん、しょくへん」は、JIS X0213では、包摂される部分字体とされています。次の図をご覧ください。

上の説明をみますと、JIS X0213:2004で変更になったのは字体に相当します。
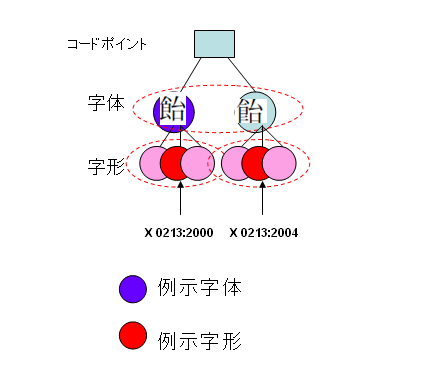
ですので、この場合、例示字形よりも例示字体というほうが正しいのではないか、と思えてきました。
なんとも、難しいものですね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月16日
日本語の文字についての用語について(4) — 例示字体か例示字形か
JIS X0213を読んでいて、いつも気になることがあります。それは、例示字体という言い方と、例示字形という言い方が、両方入り混じっていることです。
JIS X0213:2000の方は、例示字体にほぼ統一されているようです。
そして、付属書には字形例という言葉を別に用いています。
次のように:
付属書4
d)字形例 当該面区点位置で表現される図形文字の字体で、参考となるその他の字形がある場合にその字形を例示したもの。
さらには、康煕字典の字形というような言葉まで飛び出しています。
このような、JIS X0213:2000の言葉の使い方は筋が通っていて気持ちが良いと思います。
ところが、JIS X0213:2004になりますと、とたんに、例示字体と例示字形が入り混じってしまっています。
12.のあたりは、例示字体になっています。
31.になりますと、次のようになります。
付属書6.。。。面区点位置の例示字体の字形を、次に掲げる字形に変更する。
ここで例示字体の字形という表現が出てきます。
そして、解説では、
1.4
a)168文字の例示字形を、。。。。変更した。
となっていて、以下、例示字形という言葉が頻繁に出てきます。
この不統一さは、あまり気持ちが良いものではありません。
一体、例示字体が適切なのでしょうか、それとも、例示字形が適切なのでしょうか?
恐らく、両方とも「字体を例示する字形」を意味しているとは思うのですが。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年01月15日
もじもじカフェのこと、拡張新字体
字体の話をいろいろ調べてましたら、次のようなイベントが開催されるようです。
・もじもじカフェ 第5回「正字体の正体とは!?」
Webページ: http://www.moji.gr.jp/cafe/themes/005/
2月10日(土曜日)開催だそうです。
ところで、このカフェの第2回「日本生まれの漢字たち」でお話された、笹原宏之さんの著書に『現代日本の異体字』があります。この本の紹介のWebページだけでも結構面白いことが書いてあります。
国立国語研究所プロジェクト選書 「現代日本の異体字-漢字環境学序説-」
笹原宏之、横山詔一、エリク=ロング 編
2,730(2,600)円 A5 320頁 4-385-36112-6
紹介ページ http://www.sanseido-publ.co.jp/publ/itaiji.html
昨日、「朝日文字」と言いましたが、ここでは、「拡張新字体」という言葉を使っています。なお、「朝日文字」と「拡張新字体」は、イコールではなく、次の図のような関係になるのだそうです。

拡張新字体とは、常用漢字で採用された字体の簡略化法則を、常用漢字以外の漢字についても、偏と旁に当てはめたもののようです。それに対して朝日文字は、旁が左に来たら略さないのだそうです。もっともこのような議論も今日からあてはまらなくなるかもしれません。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月14日
日本語の文字についての用語について(3) — 朝日文字
朝日新聞の文字を「朝日文字」と呼ぶのだそうですね。既に、ご承知の方も、多いと思いますが、その「朝日文字」も、いよいよ、今日が最後で、明日15日(月曜日)からかなりの文字が新しい字体に変わってしまうとのことです。
9日に朝日新聞に、「常用漢字表にない漢字約900文字の字体を変更する」との社告が掲載されたそうです。
ウィキペディアの「朝日文字」によりますと、朝日新聞社は、1946年に『当用漢字字体表』が制定されたときに、当用漢字以外の漢字も、当用漢字字体表と同じような規則で、字体を簡略化し、その簡略化した漢字によって新聞紙面の印刷を行っていたのだそうです。この朝日新聞独特の漢字を「朝日文字」と呼んでいたのだそうです。
朝日新聞の社告には、例として次のような字体の変更が記載されていました。
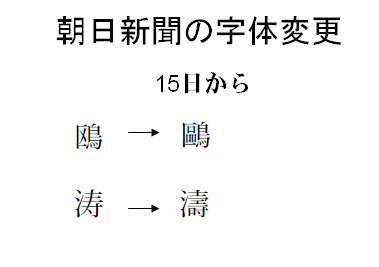
常用漢字の字体は変更しないようですので、紙面に現れる漢字のほとんど大部分は、変わらないのだろうと思います。
朝日新聞の社告に例示されている2つの文字のうち、オウの方は、2つの字体が、それぞれ印刷標準字体と簡易慣用字体として標準とされていますので、必ずしも、字体の変更の必要がないものです。トウの方は「朝日文字」の方は、簡易慣用字体になっていません。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月13日
日本語の文字についての用語について(2) — 表外漢字字体表の論理構造
前回、表外漢字字体表の用語を検討しましたので、今日は、それに沿って、この表が字体の標準を定める論理構造を検討してみます。
まず、表外漢字漢字字体表では、印刷標準字体 1,022字を定めています。そして、その1,022字のうちの22字については簡易慣用字体を定めています。
印刷標準字体 — 「明治以来、活字字体として最も普通に用いられてきた、印刷文字字体であって、かつ、現在においても常用漢字の字体に準じた略字体以上に高い頻度で用いられている印刷文字字体」及び「明治以来、活字字体として、康煕字典における正字体と同程度か、それ以上に用いられてきた俗字体や略字体などで、現在も康煕字典の正字体以上に使用頻度が高いと判断される印刷文字字体」
簡易慣用字体 — 「印刷標準字体とされた少数の俗字体・略字体は除いて、現実の文字生活で用いられている俗字体・略字体の中から、印刷標準字体と入れ替えて使用しても基本的には問題ないと判断しうる印刷文字字体」
この関係を一つの字種「997」番で見ますと次のようになります。字種「997」に二つの字体を標準として定めており、簡易慣用字体の方には、デザイン差としてふたつの字形が掲載されています。
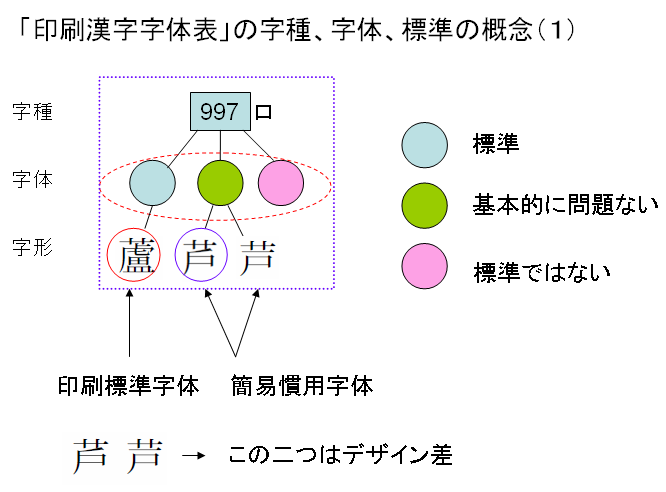
簡易慣用字体が基本的には問題ないとは、一体、なにを意味しているのでしょうか?標準ではないが、問題ないとはどういうことなのか、やや曖昧なように思います。
次に「3部首許容」を見てみます。3部首とは、しんにゅう、しめすへん、しょくへんです。「印刷標準字体としては、![]() の字形を示すが、現に印刷文字として、
の字形を示すが、現に印刷文字として、![]() の字形を用いている場合は、これを印刷標準字体の字形に変更することを求めるものではない。」とされています。
の字形を用いている場合は、これを印刷標準字体の字形に変更することを求めるものではない。」とされています。
例えば次の図のような例があります。
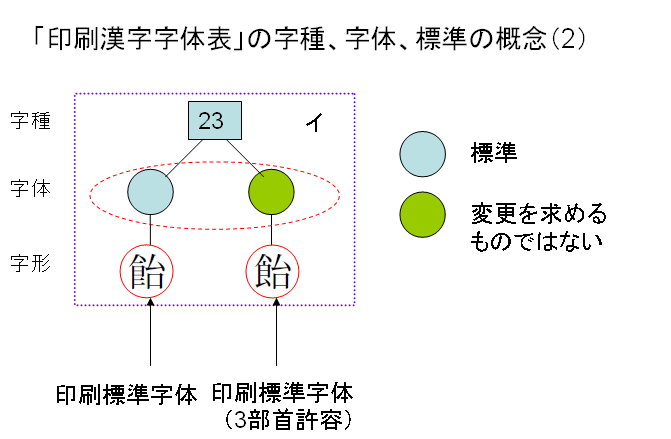
3部首許容とされる上図右の「イ」の字形は、デザイン差でもなく、簡易慣用字体でもありません。では、印刷標準字体なのでしょうか?変更を求めるものではないとは?うーーん。分かりにくいですね。
さて、次のように3部首許容と簡易慣用字体の両方が重なる場合はどうなるのでしょうか?
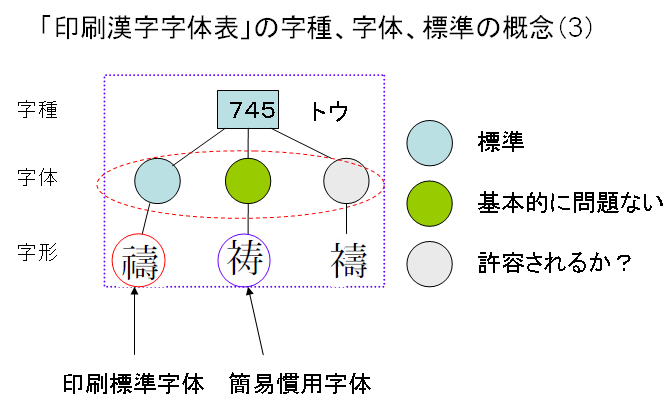
簡易慣用字体と3部首許容を組み合わせた、上図右端のような字体があったとします。そうしますと、この右端の字体は、標準字体になるでしょうか?これは、現に印刷文字として、使用されているかどうか、で判断することになります。これは、極論すれば、表外漢字字体表では、標準字体かどうかを判断するよりどころを放棄していると考えられます。
どうも、国語審議会の表外漢字字体表は、「一般の文字生活の現実を混乱させない」として、ものわかりの良い親父のような答申になってはいますが、戦後の親父の地位低下と同じで、よりどころとしては少々頼りない、という印象ももってしまいますね。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月12日
全文検索向けサムネイル作成 デモサイトを公開
アンテナハウスでは、このほど、「全文検索向けサムネイル作成」のデモサイトを、作成・公開いたしました。
「全文検索向けサムネイル作成」では、キーワードを指定すると、インターネット上にあるPDF、Word、Excel、 Powerpointファイル内の文字列を検索し、該当ファイルを取得します。そして、ファイルをサーバ上で自動的にサムネイル化し視覚的に検索結果をご確認いただけるようにしております。
表示されたサムネイル画像をクリックすると画像が拡大表示されますので、ブラウザ以外のアプリケーションを使用することなく、探している文書内容を確認することが可能です。
こちらからお使いいただくことができます。
■全文検索向けサムネイル作成ページ
http://conv.antenna.co.jp/Search/
使用方法は、簡単です。まず、次の図のように、ブラウザからキーワードを入力します。そして、検索したい対象文書の形式を指定します。
(1)検索キーワードの入力画面
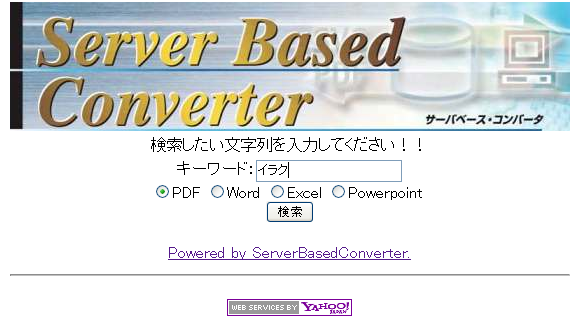
そして、検索実行ボタンを押すだけで、インターネット上を検索して、この例の場合、「イラク」というキーワードを含むPDFを探します。そして、そのPDFの内容のサマリと画像の一覧を表示します。
(2)検索結果画面

内容をもう少し詳しく見たいサムネイルをクリックしますと、画像がより大きく表示されます。
(3)画像を拡大表示した画面

このシステムでは、インターネットの検索機能に、YAHOOのAPIを利用しています。また、検索でヒットした文書をサーバ上でサムネイル化する処理は、「サーバベース・コンバータ」(SBC)を用いています。
全文検索に際して、サムネイルや画像をうまく利用することで求めている文書を探し出すのがより容易になることを体験してみていただくことができます。
なお、デモサイトでは、他に
1)PCメール向け基本機能
2)携帯電話(NTTDoCoMo)向け画像変換(+Viewer)
3)サムネイル作成サービス
をご用意しております。
デモサイトのページはこちらです。
■デモサイト メインページ
http://conv.antenna.co.jp/
あわせてお試しいただければと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月11日
日本語の文字についての用語について(1)
文字コード関係のいろいろな記事やブログ(自分も含めて)を読んでいて、どうも、用語が、それぞれで違っているのが気になります。
以前にも、少し、整理してみたことがありますが、その後、自分でも間違っていたと感じることもあります。そこで、いくつかの資料を読んで、もう一度、文字関連の用語を整理してみたいと思います。
1.「表外漢字字体表」
この数年の話題のネタの発生源が、この国語審議会の「表外漢字字体表」です。この文書は、「印刷文字において標準とすべき字体である」印刷標準字体を定めています。
この文書で定義して使っている単語に字体、書体、字形があり、また、字種、異体字、別字という言葉を使用しています。
字体 — 文字の骨組み。ある文字をある文字たらしめている点画の抽象的な構成のありかた。他の文字との弁別にかかわるものである。文字は抽象的な形態上の概念であるから、これを可視的に示そうとすれば、一定のスタイルをもつ具体的な文字として出現させる必要がある。
書体 — 文字の具体化に際して、視覚的な特徴となって現れる一定のスタイルの体系が書体である。例えば、書体のひとつである、明朝体の場合は、縦画を太くして横画の終端部にウロコという三角形の装飾を付けたスタイルで統一されている。すなわち、現実の文字は、例外なく、骨組みとしての字体を具体的に出現させた書体として存在しているものである。
書体の例としては、明朝体、ゴシック体、正楷書体、教科書体など。
字形 — 印刷文字、手書き文字を問わず、目に見える文字の形そのものを総称していう場合に用いる。
・字体の違いとデザインの違い
この「表外漢字字体表」では、字体の違いとデザインの違いについて次のようになっています。
「デザイン差とは、活字設計上の表現の差」としています。文脈上、デザイン差と対比させる形で字体の違いという言葉を使っていますので、デザイン差の範囲での字形の相違は同じ字体と見なし、デザイン差に収まらないものは別の字体と考えていることになります。
デザイン差について、具体的な分類と例があります。
1 表外漢字における字体の違いとデザインの違い
「デザイン差があてはまっても字種を分ける場合は、デザイン差には該当しない。」という一文もありますので、デザイン差は字種の同じものの範囲で意味をもつとしています。
(1) 「しんにゅう/しめすへん/しょくへん」は、(a)![]() を用いるものと、(b)
を用いるものと、(b)![]() を用いるものがあります。これらは「3部首許容」とされています。印刷字体では標準は(a)だが、(b)を使っても良いということでしょう。特に「3部首許容」と言う表現を使っているのは、これらはデザイン差でなく、別の字体だが、標準として許すといういうことのようです。それにしても、この「3部首許容」という言葉の意図がなかなか分かりにくいですね。
を用いるものがあります。これらは「3部首許容」とされています。印刷字体では標準は(a)だが、(b)を使っても良いということでしょう。特に「3部首許容」と言う表現を使っているのは、これらはデザイン差でなく、別の字体だが、標準として許すといういうことのようです。それにしても、この「3部首許容」という言葉の意図がなかなか分かりにくいですね。
(2)「くさかんむり」については、明朝体では3画を標準としています。しかし、明朝体以外では4画も制限しないということなので、書体によって、デザイン差の許容範囲が違うことになります。
・別字の例が幾つか載っています。異体字で使い分け意識があるものを、特に別字と言っているようです。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月10日
Windows Vista と日本語文字コード問題(6)
とりあえず、Microsoftの資料から、MSゴシックとMS明朝のバージョンアップについての概要をまとめてみます。
1.MS明朝、MSゴシックのバージョン
(1) Windows Vista用の標準搭載MS明朝、MSゴシックは、バージョン5.0
(2) 現行 Windows XP用の標準搭載MS明朝、MSゴシックは、バージョン2.3
(3) 次の2つのフォントパッケージが、無償提供される。
a.Windows XP SP2以上、Windows Server2003 SP1以上用のMS明朝、MSゴシックバージョン5.0
b. Windows Vista、Windows Server Longhorn向けMS明朝、MSゴシック、バージョン2.5
2.各フォント・パッケージの概要
(1) MS明朝、MSゴシック バージョン2.3 — 初版は1998年(?)。JIS X0208 6,355文字とJIS X0212の5,801文字 合計12,156文字、その他。
(2) MS明朝、MSゴシック バージョン2.5 — バージョン2.3に、JIS X0213:2004の追加文字とバージョン2.3のバグを修正したもの。字形の変更は行っていない。
(3) MS明朝、MSゴシック バージョン5.0 — JIS X0213:2004の文字セットをサポート。JIS X0208+X0212と重複しない文字を追加。Unicode 4.0の通貨記号を追加。さらに字形変更を行った。この中でJIS X0213:2004の例示字形に準拠するように字形を変更した122字形については、OpenTypeの'jp90'タグで旧字形にアクセス可能とした。(既定値では新字形、'jp90'タグで旧字形を取り出すことが可能)。
字形変更を行ったのは122字のみでなくもっと広範に行っているようです。
昨日指摘しましたように、バージョン5.0で字形を変更した部分が、以前のバージョンとの非互換なバージョンアップであって、印刷・DTP業界で混乱を引き起こす可能性があります。
OpenTypeについて詳しくない方は、OpenTypeの'jp90'タグと言っても理解できないかもしれませんが、OpenTypeは、フォントの様々な組版特性をアプリケーションから使用できるようになっています。これがタグ(正確にはfeature tag)ですが、様々なOpenTypeフォントで共通に付けるべきタグのほか、各フォント独自タグを自由に追加できます。Microsoftは自社開発したフォントに、様々な独自タグを付けていてUniscribeなどから使っています。こうした、フォントに内蔵する組版特性を利用すれば、フォントの特性を使った綺麗な組版ができます。
'jp90'タグは OpenType Layout tag registry に登録されて公開されてます。
http://www.microsoft.com/typography/otspec/features_fj.htm#jp90
これは、Registered by: Adobe でMicrosoft独自タグではないようです。
アプリケーションは'jp90'タグを使えば、MS明朝・ゴシックのバージョン5.0フォントの中から旧字形を取り出すことができるようです。このためには、アプリケーションの改造が必要です。念のために。
投票をお願いいたします
投稿者 koba : 07:55 | コメント (0) | トラックバック
2007年01月09日
Windows Vista と日本語文字コード問題(5)
2.MS明朝、MSゴシックについて
MS明朝、MSゴシックについては、「メイリオ」とは事情が違います。例えばWindowsXPに標準搭載されているMS明朝・MSゴシックのバージョンは2.3(V2.3)ですが、Vistaに標準搭載されるもののバージョンは5.0(V5.0)になります
この2つのバージョンは、フォント・ファミリー名が同じになっているため共存できません。
そして、MS明朝・MSゴシックV2.3の字形は、1990年改正のJIS規格の例示字形準拠、V5.0の字形はJIS X0213:2004の例示字形準拠とされています。つまり、V2.3とV5.0では同じコードポイントの文字を表示する字形が大幅に異なるものがある、ということです。
次の図は、「Microsoft® Windows Vista™ における JIS X 0213:2004(JIS2004)対応について」に出ているものです。

※面区点位置について、追記。
これらの文字は、JIS X0213:2004で例示字形が変更された168文字の一部です。JIS X0213の例示字形が変更されたのだから、フォントの字形も変更されるのが自然だろうと思われる方も多いと思いますが、しかし、JISの規格を読むと次のようになっています。
1.JIS X0213の規格は、コードポイントと、そこに対応付けられる抽象的概念としての字体を定めているものです。ひとつのコードポイントには、複数の字体が割り当てられていて、それを包摂(Unification)といいます。
2.X0213:2000 6.6.2 この規格は、字体の図形的実現としての字形については規定しない、とありますように、JISの規格書では字形を定めているわけではありません。
1.2についての概念図は、次のようになるでしょう。
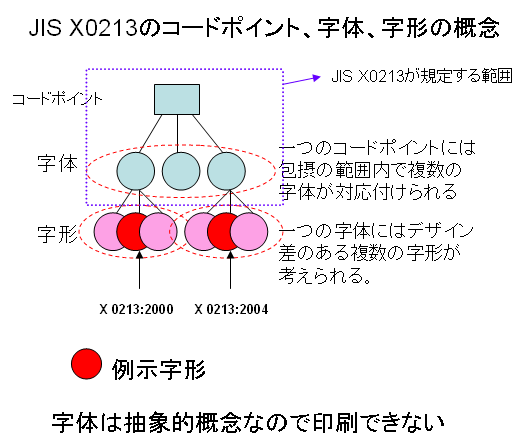
これに対して、字体にデザインを与えて具象化したものが字形です。フォントは字形をコンピュータで表すグリフデータの集合体です。フォントの種類を識別するためにフォントファミリー名を使います。そして、「フォントファミリー名が同じであれば、各文字のデザインは同じ」というのがフォント利用の基本概念と考えています。PDFを作成する場合も、フォントを埋め込まなくてもPDFを表示する環境に同一のフォントがあれば、同じ文字が表示されるということが言われていました。
このように、JIS X0213の規格とフォント技術は抽象度の階層が異なるものです。ですので、JIS X0213の例示字形が変わったからといって、必ずしもフォントの書体デザインを変更しなくても良いのです。また、多くの文字の字形を一斉に変更するのであれば、フォントファミリー名を変更するべきです。
Microsoftの上述の資料を読みますと、JISの規格が変わったから、MS明朝・MSゴシックの字形を変えたというように読めますが、上に説明しましたようにJIS規格とフォントのデザイン変更を1対1対応に解釈するのは少々単純すぎるようにも思います。
そうしたことを考えて見ますと、今回のMS明朝・MSゴシックのバージョンアップは、そのような技術の基本、常識からははずれているように思います。この結果、特に、文字の字形を重視する印刷やDTPの世界では相当な混乱が生まれることが予想されます。
【参考】
2006年03月11日 PDFとフォント(1) 書体、グリフ、フォント
2006年01月11日 PDFと文字(20) – 字体と字形
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月08日
リッチテキストPDF2 D&D ベクタープロレジ大賞にノミネート
昨年10月20日に発売しました、「リッチテキストPDF2 D&D」がベクターのプロレジ大賞にノミネートされました。
プロレジ大賞は、ベクターが年に2回行っているもので、今回のノミネート対象は、2006年7月~2006年12月の期間中にプロレジで発売されたダウンロードソフトですが、投票資格は、特に購入した人でなくても良く、誰でも投票できるようです。
ノミネートされましたのは、「文書作成部門」です。同一部門のライバルは「リッチテキストPDF2 D&D」の他に、ソースネクストの「いきなりPDF to Data2」、「本格読取」、ジャストシステムの「一太郎2006キャンペーン版 DL版」があります。
他のソフトはともかく、「いきなりPDF to Data2」だけは、絶対に負けたくないですね。
PDFからOfficeに変換するソフトについては、以前にも比較評価してみました。
2006年10月01日 PDFからWordへ 3つの変換ソフトを無慈悲に比較する (1)
2006年10月02日 PDFからWordへ 3つの変換ソフトを無慈悲に比較する (2)
2006年10月03日 PDFからWordへ 3つの変換ソフトを無慈悲に比較する (3)
2006年10月13日 PDFからWordへ 3つの変換ソフトを無慈悲に比較する (4)
そのときは、あまりはっきりとは書きませんでしたが、「いきなりPDF to Data2」の変換は、率直に申し上げて、文字認識の精度、あるいは出来上がったOffice文書の編集可能性といった面での品質が高く評価できません。
あまり良くないと感じるのは私だけではなく、製品を購入した人も同じ印象を持っているようです。このソフトの兄貴分にあたる、「いきなりPDF to Data Professional2」について、その後、アマゾンのカスタマレビューが載りました。それを見ても分かります。
いきなりPDF to Data Professional 2 (説明扉付スリムパッケージ版) アマゾンのページ
この評価を見ますと、3人の評価で3人とも5点満点中1点です。コメントを読みましても、ここまで酷評されるソフトも珍しいのではないでしょうか。それだけ購入時の期待と変換結果の落差が大きいということですが。
一般に文書コンバータは、どうしても妥協の産物になりがちで、満足度を高めるのが難しいのです。しかし、それにしても「いきなりPDF to Data」は、あまりにも顧客満足度が悪過ぎると思います。
私としては、「リッチテキストPDF2 D&D」のシェアをもっと上げて、他のソフトを間違って買ってしまう人を一人でも減らさねばならないと思っています。我田引水で申し訳けありませんが、ここまでお読みいただいた皆様、ぜひ、プロレジ大賞では「リッチテキストPDF2 D&D」に清き一票をお願いします。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月07日
Windows Vista と日本語文字コード問題(4)
昨日までのお話を一言で言いますと、JIS X0213:2004にある文字を全て取り扱うためにはUnicode処理の強化が必要。多くのアプリケーションで、いままでのままでは、正しく処理できない漢字が最低303文字、非漢字が25文字あるのではないだろうか、ということになります。
「Microsoft Windows VistaにおけるJIS X 0213:2004 (JIS2004)対応について」 2006年11月 Version 1.0(Microsoft)によりますと、Windows Vistaは、このために文字入力用のIME、文字列描画用のUniscribeとGDIといった共通のコンポーネントが強化されているそうです。
文字の処理と言っても、文字列の入力・編集・表示・検索・比較など多様です。Windows Vistaでも、IME、Uniscribe、GDIの変更のみではなく、他にもいろいろ変更になっているはずです。また、Windowsの上で動くアプリケーションの場合は、それがWindowsのコンポーネントが提供する機能をどう使っているかによってかなり事情が変わることに注意しなければなりません。結局、ユーザはアプリケーション毎に確認が必要です。
蛇足ですが、LinuxなどのWindows以外の環境で動くアプリケーションは、Windowsが用意した共通機能を享受できません。JIS X0213:2004 をサポートするには、自力で、Windowsが共通機能として提供しているものに相当する機能を強化しなければなりません。
さて、日経BP IT Pro特番ページを見ますと、「文字が化ける」という観点を強調しています。確かに、印刷・PDF化などの観点からは、文字の形がどうなったかは重要です。次にこの問題を検討します。
第二.新しいフォント「メイリオ」の搭載と「MS明朝」、「MSゴシック」のバージョンアップ
1.「メイリオ」について
「メイリオ」は、Window Vistaに標準で搭載される表示用フォントで、他のWindows環境には提供されません。
日経BPの記事では、Windows Vistaで作成した文書を、XPなどのほかのOSで表示したときの文字化け問題を取り上げていますが、そのうち大部分(前述の303+25文字を除くもの)は文字の字形の変更によるものです。
現在のマルチフォントを使う文書作成ではフォントが違えば、文字の字形デザインは違うということが前提だと思います。
Microsoft は「Windowsの次期バージョンWindows Vista(TM)において日本語フォント環境を一新」(2005年7月29日)で、メイリオは「画面上での可読性を大幅に向上させるまったく新しいデザインのフォント(フォント名:メイリオ)」と発表していますし、極論すれば、Windows Vistaで「メイリオ」を指定した文書は、「メイリオ」以外のシステムフォントをもつ環境では、そのまま表字することができないのは、格別の問題にするにあたらないと考えても良いのではないでしょうか。
「メイリオ」を指定した文書を他の環境にもっていって同じ字形で表示したいのなら、フォントを埋め込むしかないでしょう。従って、「Windows Vistaの新文字セットが引き起こすトラブル」でいろいろ述べている「文字化け」議論は雑誌社特有のあおり文書じゃないか?と私は思ってしまうのです。
文字化けだけではなく、「メイリオ」のメトリックスと「MSゴシック」のメトリックスが、同じでないとすると、「メイリオ」を指定した文書を、「メイリオ」のない環境で、表字すると文書のレイアウト自体が変わってしまいます。そういうことからも「メイリオ」は、Windows Vista専用のものであり、他の環境と字形の交換はできないと考える方が妥当と思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (6) | トラックバック
2007年01月06日
Windows Vista と日本語文字コード問題(3)
JIS X0213の付属書4に、仮名、特殊文字および罫線素片についてのUnicodeとの対応表があります。
これの2004年版を見ますと、JIS X0213では一文字になっているのに、Unicodeでは二つの文字の並びで表すようになっている文字が25文字あります。
これらの文字はUnicodeでは1つのコードポイントが与えられていないため、次の図のように2つのコードポイントの文字(または記号)を合成して表さなければなりません。
図1 文字を結合する仕組み

※以前(下記、参考の日付)にUnicodeの結合文字のお話をしましたので、この仕組みについて詳しくはそちらも参考にしてください。
これらの文字をUnicodeで表すには、基底文字と結合文字のセットで表すしか方法がないということなのです。具体的な文字の一覧を図2に示しました。
図2 JIS X0213 に1文字で定義されているがUnicodeにはコードポイントがない文字

【参考】
Unicodeの結合文字については、こちらを参照してください。
・2006年01月27日 PDFと文字 (34) – Unicodeの結合文字
・2006年01月28日 PDFと文字 (35) – 文字の合成方法
・2006年01月29日 PDFと文字 (36) – 文字の合成方法(続き)
・2006年01月30日 PDFと文字 (37) – 結合文字列の正規合成
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月05日
Windows Vista と日本語文字コード問題(2)
JIS X0213:2004の文字でUnicodeでは4バイトで1文字を表す文字がいくつあるかを調べてみました。
これを調べていて、気が付いたことは、JIS X0213:2000(制定時)は、当初はJIS X0213の文字は全てUnicodeのBMP(基本多言語面:2バイト領域)に割り当てる予定だったらしいことです。
2000年の時点ではUnicode3.0でしたが、そこには、JIS X0213:2000で追加した文字の中に、Unicode3.0にはなかったものがあったのでしょう。JIS X0213:2000の付属書11には、UnicodeとJISの文字コードの対応表がありますが、それらの文字は()付きで示されています。
2003年にUnicode4.0が制定されたのですが、その時点で、恐らく日本側の思惑とは裏腹に、一部の文字が、BMPに割り当てられずに、補助面に割り当てられてしまったんですね。
このため、補助面に割り当てられた文字は1文字を4バイトで処理しなければならなくなったという事情がありそうです。
では、実際に、どんな文字がそれに相当するかは、JIS X0213:2004の付属書6の表で、UCSの番号が2xxxxに対応されているものがそれに相当します。
数えますと、32項に302文字、33項(2004年版で追加した文字)に1文字の合計303文字です。文字の字形の一覧は次のページで確認できます。
Vistaで化ける字,化けない字の図6に示されている26文字
Vistaで化ける字,化けない字(続報)の図9に示されている277文字
これらの文字は、Unicodeを1文字2バイト固定で扱うプログラムでは正しく処理できません。
【参考】Unicode(UCS)の制定時と文字の追加について
2005年12月25日 PDFと文字(11) – UnicodeとISO 10646
2005年12月26日 PDFと文字(12) – Unicode仕様の文字
さて、JIS X0213:2004の文字をすべて完全に扱おうとしますと、Unicode文字列の処理でもう一つの問題があります。これについては明日取り上げたいと思います。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (1) | トラックバック
2007年01月04日
Windows Vista と日本語文字コード問題(1)
Windows Vistaの発売に伴い、日本語文字コードの話題が盛り上がっています。この話題は、文字コードに関心をもつ人の間では、とりたてて新しいものではないのですが、実際の製品が発売されることで、多くの人にとって身近な問題になってきたものです。印刷・DTP関係者には気をもんでいる方も多いことと思います。
日経BP IT Proでは特番ページまで用意しました:Windows Vistaの新文字セットが引き起こすトラブル
マイクロソフトが、Vista用にJIS X0213:2004をサポートする新しいフォント「メイリオ」を標準搭載したこと、および、従来よりWindowsに標準搭載されていたMS明朝が、バージョンアップされX0213:2004対応となるということが、Windows Vistaでの変更点です。
それで、なぜ、印刷・DTP業界が気をもまねばならない問題が起きてしまうかということを、私なりに説明したいと思います。
第一.Uncodeの取り扱いを変更することが必要なケースがあること
JIS X0213:2004では、文字の種類が11,233文字と非常に多くなっています。最近のパソコンのアプリケーションは、内部的にはUnicodeを使うものが多いと思いますが、UnicodeでJIS X0213:2004の全文字を正しく扱うには、一部の文字については1文字4バイトを使って表現することが必須になります。
例えば、アンテナハウスの主なアプリケーションは内部では、文字をUnicodeで取り扱っていますが、現状では、1文字を2バイトで表しています。PDF生成エンジンなども、現在のバージョンは1文字2バイトです。
※Antenna House XML Editorだけは、1文字4バイトのUnicodeで処理しています。
そこで、JIS X0213:2004を完全に取り扱うには、アプリケーションの内部で1文字を4バイトで表現するように改造するか、2バイトと4バイトを混在させることを可能にするように改造するか、どちらかの対策が必要です。
プログラム的には、1文字を4バイトで扱うようにしてしまうのが簡単ですが、そうしますと、ラテン・アルファベットのように、本来1バイトで良いものまでも、4バイトで表すことになってしまうため、あまりメモリ使用効率が良くないと思います。そこで、弊社の場合、原則として、1文字を2バイト表現と4バイト表現を混在させても問題ないようにプログラム内部を修正することを選択しています。
そんなわけで、Vistaの登場に伴ってプログラムの改造が必要になります。これは、Vista対応というよりも、Vistaに標準搭載されるフォント(従って、使用頻度も多くなるであろうもの)で表せる文字を全部正しく扱おうとすると、上の対策が必要になるということで、Vistaは単なるきっかけに過ぎません。長期的に、Unicode対応を完全に進めていく上では、避けられないことだと思います。
他の会社がどのような対応を取るかは、各社それぞれと思いますが、JIS X0213:2004が普及してくれば、どこの会社も同じような対応策をとることが必要になるでしょう。
この対応策が完了するまでは、そのアプリケーションではJIS X0213:2004の一部の文字を、正しく取り扱えないということになります。
投票をお願いいたします
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月03日
Web表示用に最適化PDFの意味、用途、効果
過去何回かわたり、PDFのWeb表示用に最適化(リニアライズドPDF)について、お話しましたが、それを整理してみました。
こちらをご覧ください。
Web表示用に最適化という機能は、いまひとつ理解が進んでいないようです。しかし、これからは、携帯電話やモバイル機器などでのPDF表示が使われる機会も増えるでしょうから、重要度が増すのではないでしょうか。
投票をお願いいたします
投稿者 koba : 08:10 | コメント (0) | トラックバック
2007年01月02日
Web最適化について 再度
WikipediaのPDFの項を見ていましたら、「また、ユーザビリティに十分配慮して作成されたHTMLドキュメントと比べると、PDFは扱いにくい面がある。 PDFのドキュメントは、ドキュメントの一部分だけを参照したい場合でも、最初から最後まですべてのデータを閲覧端末に読み込む必要がある。」(2006年12月31日時点の文章)という説明がありました。
これは、技術的に見て、少し説明が足りないと思います。そこで、蛇足ながら、また、Web最適化についてお話したいと思います。
確かに、Web最適化していないPDFでは、この説明の通りです。しかし、既に、このブログでは何度かお話しましたが、PDFにはWeb最適化(リニアライズ)という仕様があります。リニアライズしたPDFの場合、PDF Readerは、ドキュメントの特定ページを直接参照することができます。
PDF Reference 1.7では、Linearized PDFについてpp. 1021 - 1055まで35ページにわたって説明があります。
それによりますと、Linearized PDFは、PDF仕様1.2から追加された機能で、次のような目的をもつとあります。
1.PDFを開くとき、最初のページを可能な限りすばやく開く。最初のページとしては、先頭ページでなくて任意のページを指定できる。
2.ユーザが開いたページから別のページを要求したとき、可能な限りすばやくそのページを開く。
3.文書を遅い通信回線を使って配布するとき、ページを少しづつ順に表示できるようにする。
4.リンクを辿るときに、全てのページを受信して表示しなくても良いようにする。
リニアライズしたPDFでは、PDFを最後まで読まなくても表示することができます。これは、実際にPDFを作成して試してみると分かります。ご参考のために実証データを作成してみました。
Web最適化PDFの実証データ
「XSL Formatter V4.1のマニュアル (PDF)」をWeb最適化したものとしていないものを用意しました。ファイルサイズは、それぞれ約3MBです。
antenna.co.jp
Web最適化していないPDF
Web最適化したPDF
Web最適化していないPDFの150ページを直接取得
Web最適化したPDFの150ページを直接取得
antennahouse.com
こちらのWebサイトの方が、アクセスが遅いので、違いが良く分かると思います。
Web最適化していないPDF
Web最適化したPDF
Web最適化していないPDFの150ページを直接取得
Web最適化したPDFの150ページを直接取得
【ご注意】
IE6、IE7や、FireFoxで上記の設定の違いは有効です。しかし、FireFoxに「PDF Download」(http://www.pdfdownload.org/)を追加してしまうと、上の設定の違いがなくなってしまうようです。
Adobe のAcrobatでは、PDFを印刷機能から作成するとき、リニアライズする設定になっていますので、ユーザの皆さんが意識することが少ないと思いますが、リニアライズするかしないかの指定もできます。そして、あるPDFがリニアライズされているかどうかは、Adobe Readerであれば、文書のプロパティで確認できます。
次の図をご参照ください。
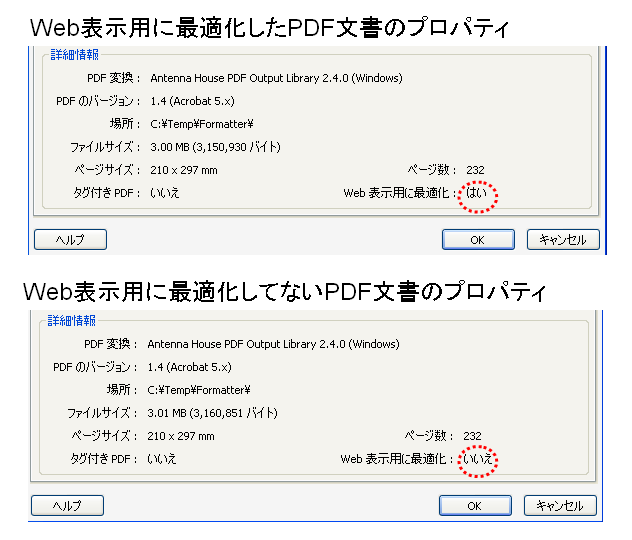
実際には、リニアライズドPDFは、PDFを一旦作成した後に、PDF内部のオブジェクトの順番を並び替えて、表示用に最適化します。
また、PDFは、一旦作成した後で、様々に情報を追加したり、更新できるようになっています。少しでも情報を追加すると、リニアライズドではなくなりますので、再度、リニアライズ処理を施す必要があります。
なお、アンテナハウスの主な製品は、PDFのリニアライズ(Web最適化)機能を持っています。PDF Driver は、V3.1からこの機能を追加しました。
【ご参考】
2006年07月03日リニアライズドPDFとは
2006年07月04日リニアライズドPDFの利用方法 バイトサービング
投稿者 koba : 08:00 | コメント (0) | トラックバック
2007年01月01日
PDFをとりまく環境とPDF製品の2007年展望 (4)
明けましておめでとうございます。
PDF千夜一夜は、暮れも正月も無くPDFに邁進ですが、1年の計は元旦にあり、ということで、今年1年の抱負をまとめてみました。
ご承知のように2005年、2006年とPDF作成ソフト、PDFの簡単な編集をするソフトは廉価になって来ました。既にお話しましたように2007年にはこの傾向が一挙に進むことでしょう。Macintosh上では、既にPDF作成・表示は、OSの標準機能になっていますが、Windows上でもPDF作成は無償・標準的な機能として考えられるようになっていくことは間違いありません。
これに伴い、Webや仕事を含めて、情報を交換するメディアとしてPDFの重要度が一段と高り、PDFがより多くの人々にとって身近なものになっていくことでしょう。
また、PDFをもっと便利に使いたいという需要が増大することも間違いのないところでしょう。
弊社では、これまで、6年以上にわたって、PDFの作成、加工、解読、表示などの基盤技術に投資してきました。これにより、Adobeにまったく依存しない独自技術をもって、かなりの部分までPDF様々な処理ができるようになってきました。しかし、まだまだ道の半ばにも到達していません。2007年は、まず、基盤技術への投資をもっと積極化していかなければならないと考えています。
また、これらの基盤技術を、様々な会社でソフトウエア製品のためのコンポーネントとして、また、社内システム構築のためのコンポーネントとして使っていただけるように提供します。コンピュータのOSと同じように、PDF技術を廉価なプラット・フォームとして提供していきたいと考えています。
デスクトップ分野では、他の会社にはできないようなPDF製品を提供していきます。PDFが普及し、身近になることで、ユーザの間には、PDFに関連して新しい様々なニーズが生まれるでしょう。PDFが紙に代わって、紙のように使われるようになるまでには、その需要を満たすために、まだまだ、新しい製品が必要と考えます。
アンテナハウスでは、今年の目標のひとつに、「ソフトウエアの無限の可能性を追求し、いままでできなかったことを実現する商品を世の中に出す。」ということを掲げています。PDF分野でも、新しい商品と市場を創出することを目標に汗を流していきたいと考えています。
投票をお願いいたします